- Last 7 days
-
-
Transformers give Clojurists some of the benefits of "Object Orientation" without many of the downsides Clojurists dislike about objects.
- Objects couple behaviors required from multiple callers into a single class, while transformers do not change existing behaviors for existing callers by default
- Objects push inheritance first design, whereas transformer inheritance is a function of shared structure between Clojure data structures derived from one another and design is driven by concrete implementation needs, like regular Clojure
- Objects couple state and methods in spaghetti ways and transformers are just immutable maps. And just like how Clojure lets you stash stateful things like atoms in functions, transformers allow you to build stateful transformers, but like Clojure the default convention is to do everything immutably
- Objects try to provide data hiding as a function of encapsulation whereas transformers are doing the opposite, exposing data otherwise hidden by a closure
There are many strategies for reusing code in the software industry. In Clojure, we use what some call a "lego" method of building small, single purpose functions that just can be used in a million different contexts, because of a tasteful use of simplicity in the right places. This works tremendously well for 95% of use cases. In certain use-cases, like for building hierarchies of functions that are highly self-similar, like with UI toolkits, transformers provide a better alternative.Transformers allow you to build a UI toolkit with 25% the code of normal function composition and 25% of the code required for evolution over time for the widgets in that hierarchy. The lego method is great for vertically composing things together, but when you want to make lateral changes for only certain callers in the tree, you have to defensively copy code between duplicative implementation trees and just call them "grandpa-function-1" and "grandpa-function-2" and then make versions 1 and 2 for all functions that wrapped the grandpa-functions afterwards. Transformers provide a solution for that situation, in the rare cases we end up in them in Clojure, without the downsides of a traditional object system.
-
-
openclassrooms.com openclassrooms.com
-
ur la branche P3C5-solution.
Je ne comprends pas bien dans la solution ce bout de code : .lien-conteneur-photo:hover.photo-hover { display: flex; } Pourquoi la class .photo-hover se trouve après la pseudo classe hover ?
-
-
-
Reviewer #2 (Public Review):
In the presented manuscript, the authors first use structured microfluidic devices with gliding filamentous cyanobacteria inside in combination with micropipette force measurements to measure the bending rigidity of the filaments. The distribution of bending rigidities is very broad.
Next, they use triangular structures to trap the bacteria with the front against an obstacle. Depending on the length and rigidity, the filaments buckle under the propulsive force of the cells. The authors use theoretical expressions for the buckling threshold to infer propulsive force, given the measured length and (mean-) stiffnesses. They find nearly identical values for both species, 𝑓 ∼ (1.0 {plus minus} 0.6) nN∕µm, nearly independent of the velocity. These measurements have to be taken with additional care, as then inferred forces depend strongly on the bending rigidity, which already shows a broad distribution.
Finally, they measure the shape of the filament dynamically to infer friction coefficients via Kirchhoff theory. In this section they report a strong correlation with velocity and report propulsive forces that vary over two orders of magnitude.
From a theoretical perspective, not many new results are presented. The authors repeat the the well-known calculation for filaments buckling under propulsive load and arrive at the literature result of buckling when the dimensionless number (f L^3/B) is larger than 30.6 as previously derived by Sekimoto et al in 1995. In my humble opinion, the "buckling theory" section belongs to methods.<br /> Finally, the Authors use molecular dynamics type simulations similar to other models to reproduce the buckling dynamics from the experiments.
Data and source code are available via trusted institutional or third-party repositories that adhere to policies that make data discoverable, accessible and usable.
-
Author response:
Reviewer 1:
The paper “Quantifying gliding forces of filamentous cyanobacteria by self-buckling” combines experiments on freely gliding cyanobacteria, buckling experiments using two-dimensional V-shaped corners, and micropipette force measurements with theoretical models to study gliding forces in these organisms. The aim is to quantify these forces and use the results to perhaps discriminate between competing mechanisms by which these cells move. A large data set of possible collision events are analyzed, bucking events evaluated, and critical buckling lengths estimated. A line elasticity model is used to analyze the onset of buckling and estimate the effective (viscous type) friction/drag that controls the dynamics of the rotation that ensues post-buckling. This value of the friction/drag is compared to a second estimate obtained by consideration of the active forces and speeds in freely gliding filaments. The authors find that these two independent estimates of friction/drag correlate with each other and are comparable in magnitude. The experiments are conducted carefully, the device fabrication is novel, the data set is interesting, and the analysis is solid. The authors conclude that the experiments are consistent with the propulsion being generated by adhesion forces rather than slime extrusion. While consistent with the data, this conclusion is inferred.
We thank the reviewer for the positive evaluation of our work.
Summary:
The paper addresses important questions on the mechanisms driving the gliding motility of filamentous cyanobacteria. The authors aim to understand these by estimating the elastic properties of the filaments, and by comparing the resistance to gliding under a) freely gliding conditions, and b) in post-buckled rotational states. Experiments are used to estimate the propulsion force density on freely gliding filaments (assuming over-damped conditions). Experiments are combined with a theoretical model based on Euler beam theory to extract friction (viscous) coefficients for filaments that buckle and begin to rotate about the pinned end. The main results are estimates for the bending stiffness of the bacteria, the propulsive tangential force density, the buckling threshold in terms of the length, and estimates of the resistive friction (viscous drag) providing the dissipation in the system and balancing the active force. It is found that experiments on the two bacterial species yield nearly identical values of f (albeit with rather large variations). The authors conclude that the experiments are consistent with the propulsion being generated by adhesion forces rather than slime extrusion.
We appreciate this comprehensive summary of our work.
Strengths of the paper:
The strengths of the paper lie in the novel experimental setup and measurements that allow for the estimation of the propulsive force density, critical buckling length, and effective viscous drag forces for movement of the filament along its contour – the axial (parallel) drag coefficient, and the normal (perpendicular) drag coefficient (I assume this is the case, since the post-buckling analysis assumes the bent filament rotates at a constant frequency). These direct measurements are important for serious analysis and discrimination between motility mechanisms.
We thank the reviewer for this positive assessment of our work.
Weaknesses:
There are aspects of the analysis and discussion that may be improved. I suggest that the authors take the following comments into consideration while revising their manuscript.
The conclusion that adhesion via focal adhesions is the cause for propulsion rather than slime protrusion is consistent with the experimental results that the frictional drag correlates with propulsion force. At the same time, it is hard to rule out other factors that may result in this (friction) viscous drag - (active) force relationship while still being consistent with slime production. More detailed analysis aiming to discriminate between adhesion vs slime protrusion may be outside the scope of the study, but the authors may still want to elaborate on their inference. It would help if there was a detailed discussion on the differences in terms of the active force term for the focal adhesion-based motility vs the slime motility.
We appreciate this critical assessment of our conclusions. Of course we are aware that many different mechanisms may lead to similar force/friction characteristics, and that a definitive conclusion on the mechanism would require the combination of various techniques, which is beyond the scope of this work. Therefore, we were very careful in formulating the discussion of our findings, refraining, in particular, from a singular conclusion on the mechanism but instead indicating “support” for one hypothesis over another, and emphasizing “that many other possibilities exist”.
The most common concurrent hypotheses for bacterial gliding suggest that either slime extrusion at the junctional pore complex [A1], rhythmic contraction of fibrillar arrays at the cell wall [A2], focal adhesion sites connected to intracellular motor-microtubule complexes [A3], or modified type-IV pilus apparati [A4] provide the propulsion forces. For the slime extrusion hypothesis, which is still abundant today, one would rather expect an anticorrelation of force and friction: more slime extrusion would generate more force, but also enhance lubrication. The other hypotheses are more conformal to the trend we observed in our experiments, because both pili and focal adhesion require direct contact with a substrate. How contraction of fibrilar arrays would micromechanically couple to the environment is not clear to us, but direct contact might still facilitate force transduction. Please note that these hypotheses were all postulated without any mechanical measurements, solely based on ultra-structural electron microscopy and/or genetic or proteomic experiments. We see our work as complementary to that, providing a mechanical basis for evaluating these hypotheses.
We agree with the referee that narrowing down this discussion to focal adhesion should have been avoided. We rewrote the concluding paragraph (page 8):
“…it indicates that friction and propulsion forces, despite being quite vari able, correlate strongly. Thus, generating more force comes, inevitably, at the expense of added friction. For lubricated contacts, the friction coefficient is proportional to the thickness of the lubricating layer (Snoeijer et al., 2013 ), and we conjecture active force and drag both increase due to a more intimate contact with the substrate. This supports mechanisms like focal adhesion (Mignot et al., 2007 ) or a modified type-IV pilus (Khayatan et al., 2015 ), which generate forces through contact with extracellular surfaces, as the underlying mechanism of the gliding apparatus of filamentous cyanobacteria: more contacts generate more force, but also closer contact with the substrate, thereby increasing friction to the same extent. Force generation by slime extrusion (Hoiczyk and Baumeister, 1998 ), in contrast, would lead to the opposite behavior: More slime generates more propulsion, but also reduces friction. Besides fundamental fluid-mechanical considerations (Snoeijer et al., 2013 ), this is rationalized by two experimental observations: i. gliding velocity correlates positively with slime layer thickness (Dhahri et al., 2013 ) and ii. motility in slime-secretion deficient mutants is restored upon exogenous addition of polysaccharide slime. Still we emphasize that many other possibilities exist. One could, for instance, postulate a regulation of the generated forces to the experienced friction, to maintain some preferred or saturated velocity.”
Can the authors comment on possible mechanisms (perhaps from the literature) that indicate how isotropic friction may be generated in settings where focal adhesions drive motility? A key aspect here would probably be estimating the extent of this adhesion patch and comparing it to a characteristic contact area. Can lubrication theory be used to estimate characteristic areas of contact (knowing the radius of the filament, and assuming a height above the substrate)? If the focal adhesions typically cover areas smaller than this lubrication area, it may suggest the possibility that bacteria essentially present a flat surface insofar as adhesion is concerned, leading to a transversely isotropic response in terms of the drag. Of course, we will still require the effective propulsive force to act along the tangent.
We thank the referee for suggesting to estimate the dimensions of the contact region. Both pili and focal adhesion sites would be of sizes below one micron [A3, A4], much smaller than the typical contact region in the lubricated contact, which is on the order of the filament radius (few microns). So indeed, isotropic friction may be expected in this situation [A5] and is assumed frequently in theoretical work [A6–A8]. Anisotropy may then indeed be induced by active forces [A9], but we are not aware of measurements of the anisotropy of friction in bacterial gliding.
For a more precise estimate using lubrication theory, rheology and extrusion rate of the secreted polysaccharides would have to be known, but we are not aware of detailed experimental characterizations.
We extended the paragraph in the buckling theory on page 5 regarding the assumption of isotropic friction:
“We use classical Kirchhoff theory for a uniform beam of length L and bending modulus B, subject to a force density ⃗b = −f ⃗t− η ⃗v, with an effective active force density f along the tangent ⃗t, and an effective friction proportional to the local velocity ⃗v, analog to existing literature (Fily et al., 2020; Chelakkot et al., 2014; Sekimoto et al., 1995 ). Presumably, this friction is dominated by the lubrication drag from the contact with the substrate, filled by a thin layer of secreted polysaccharide slime which is much more viscous than the surrounding bulk fluid. Speculatively, the motility mechanism might also comprise adhering elements like pili (Khayatan et al., 2015 ) or foci (Mignot et al., 2007 ) that increase the overall friction (Pompe et al., 2015 ). Thus, the drag due to the surrounding bulk fluid can be neglected (Man and Kanso, 2019 ), and friction is assumed to be isotropic, a common assumption in motility models (Fei et al., 2020; Tchoufag et al., 2019; Wada et al., 2013 ). We assume…”
We also extended the discussion regarding the outcome of isotropic friction (page 7):
“…Thus we plot f/v over η in Figure 4 D, finding nearly identical values over about two decades. Since f and η are not correlated with v0, this is due to a correlation between f and η. This relation is remarkable in two aspects: On the one hand, it indicates that friction is mainly isotropic. This suggests that friction is governed by an isotropic process like bond friction or lubrication from the slime layer in the contact with the substrate, the latter being consistent with the observation that mutations deficient of slime secretion do not glide but exogenous addition of slime restores motility (Khayatan et al., 2015 ). In contrast, hydrodynamic drag from the surrounding bulk fluid (Man and Kanso, 2019 ), or the internal friction of the gliding apparatus would be expected to generate strongly anisotropic friction. If the latter was dominant, a snapping-like transition into the buckling state would be expected, rather than the continuously growing amplitude that is observed in experiments. On the other hand, it indicates that friction and propulsion forces…”
I am not sure why the authors mention that the power of the gliding apparatus is not rate-limiting. The only way to verify this would be to put these in highly viscous fluids where the drag of the external fluid comes into the picture as well (if focal adhesions are on the substrate-facing side, and the upper side is subject to ambient fluid drag). Also, the friction referred to here has the form of a viscous drag (no memory effect, and thus not viscoelastic or gel-like), and it is not clear if forces generated by adhesion involve other forms of drag such as chemical friction via temporary bonds forming and breaking. In quasi-static settings and under certain conditions such as the separation of chemical and elastic time scales, bond friction may yield overall force proportional to local sliding velocities.
We agree with the referee that the origin of the friction is not easily resolved. Lubrication yields an isotropic force density that is proportional to the velocity, and the same could be generated by bond friction. Importantly, both types of friction would be assumed to be predominantly isotropic. We explicitly referred to lubrication drag because it has been shown that mutations deficient of slime extrusion do not glide [A4].
Assuming, in contrast, that in free gliding, friction with the environment is not rate limiting, but rather the internal friction of the gliding apparatus, i.e., the available power, we would expect a rather different behavior during early-buckling evolution. During early buckling, the tangential motion is stalled, and the dynamics is dominated by the growing buckling amplitude of filament regions near the front end, which move mainly transversely. For geometric reasons, in this stage the (transverse) buckling amplitude grows much faster than the rear part of the filament advances longitudinally. Thus that motion should not be impeded much by the internal friction of the gliding apparatus, but by external friction between the buckling parts of the filament and the ambient. The rate at which the buckling amplitude initially grows should be limited by the accumulated compressive stress in the filament and the transverse friction with the substrate. If the latter were much smaller than the (logitudinal) internal friction of the gliding apparatus, we would expect a snapping-like transition into the buckled state, which we did not observe.
In our paper, we do not intend to evaluate the exact origin of the friction, quantifying the gliding force is the main objective. A linear force-velocity relation agrees with our observations. A detailed analysis of friction in cyanobacterial gliding would be an interesting direction for future work.
To make these considerations more clear, we rephrased the corresponding paragraph on page 7 & 8:
“…Thus we plot f/v over η in Figure 4 D, finding nearly identical values over about two decades. Since f and η are not correlated with v0, this is due to a correlation between f and η. This relation is remarkable in two aspects: On the one hand, it indicates that friction is mainly isotropic. This suggests that friction is governed by an isotropic process like bond friction or lubrication from the slime layer in the contact with the substrate, the latter being consistent with the observation that mutations deficient of slime secretion do not glide but exogenous addition of slime restores motility (Khayatan et al., 2015 ). In contrast, hydrodynamic drag from the surrounding bulk fluid (Man and Kanso, 2019 ), or the internal friction of the gliding apparatus would be expected to generate strongly anisotropic friction. If the latter was dominant, a snapping-like transition into the buckling state would be expected, rather than the continuously growing amplitude that is observed in experiments. On the other hand, it indicates that friction and propulsion forces…”
For readers from a non-fluids background, some additional discussion of the drag forces, and the forms of friction would help. For a freely gliding filament if f is the force density (per unit length), then steady gliding with a viscous frictional drag would suggest (as mentioned in the paper) f ∼ v! L η||. The critical buckling length is then dependent on f and on B the bending modulus. Here the effective drag is defined per length. I can see from this that if the active force is fixed, and the viscous component resulting from the frictional mechanism is fixed, the critical buckling length will not depend on the velocity (unless I am missing something in their argument), since the velocity is not a primitive variable, and is itself an emergent quantity.
We are not sure what “f ∼ v! L η||” means, possibly the spelling was corrupted in the forwarding of the comments.
We assumed an overdamped motion in which the friction force density ff (per unit length of the filament) is proportional to the velocity v0, i.e. ff ∼ η v0, with a friction coefficient η. Overdamped means that the friction force density is equal and opposite to the propulsion force density, so the propulsion force density is f ∼ ff ∼ η v0. The total friction and propulsion forces can be obtained by multiplication with the filament length
L, which is not required here. In this picture, v0 is an emergent quantity and f and η are assumed as given and constant. Thus, by observing v0, f can be inferred up to the friction coefficient η. Therefore, by using two descriptive variables, L and v0, with known B, the primitive variable η can be inferred by logistic regression, and f then follows from the overdamped equation of motion.
To clarify this, we revised the corresponding section on page 5 of the paper:
“The substrate contact requires lubrication from polysaccharide slime to enable bacteria to glide (Khayatan et al., 2015 ). Thus we assume an over- damped motion with co-linear friction, for which the propulsion force f and the free gliding velocity v0 of a filament are related by f = η v0, with a friction coefficient η. In this scenario, f can be inferred both from the observed Lc ∼ (f/B)−1/3 and, up to the proportionality coefficient η, from the observed free gliding velocity. Thus, by combining the two relations, one may expect also a strong correlation between Lc and v0. In order to test this relation for consistency with our data, we include v0 as a second regressor, by setting x = (L−Lc(v0))/∆Lc in Equation 1, with Lc(v0) = (η v0/(30.5722 B))−1/3, to reflect our expectation from theory (see below). Now, η rather than f is the only unknown, and its ensemble distribution will be determined in the regression. Figure 3 E,F show the buckling behavior…”
Reviewer 2:
In the presented manuscript, the authors first use structured microfluidic devices with gliding filamentous cyanobacteria inside in combination with micropipette force measurements to measure the bending rigidity of the filaments.
Next, they use triangular structures to trap the bacteria with the front against an obstacle. Depending on the length and rigidity, the filaments buckle under the propulsive force of the cells. The authors use theoretical expressions for the buckling threshold to infer propulsive force, given the measured length and stiffnesses. They find nearly identical values for both species, f ∼ (1.0 ± 0.6) nN/µm, nearly independent of the velocity.
Finally, they measure the shape of the filament dynamically to infer friction coefficients via Kirchhoff theory. This last part seems a bit inconsistent with the previous inference of propulsive force. Before, they assumed the same propulsive force for all bacteria and showed only a very weak correlation between buckling and propulsive velocity. In this section, they report a strong correlation with velocity, and report propulsive forces that vary over two orders of magnitude. I might be misunderstanding something, but I think this discrepancy should have been discussed or explained.
We regret the misunderstanding of the reviewer regarding the velocity dependence, which indicates that the manuscript should be improved to convey these relations correctly.
First, in the Buckling Measurements section, we did not assume the same propulsion force for all bacteria. The logistic regression yields an ensemble median for Lc (and thus an ensemble median for f ), along with the width ∆Lc of the distribution (and thus also the width of the distribution of f ). Our result f ∼ (1.0 ± 0.6) nN/µm indicates the median and the width of the distribution of the propulsion force densities across the ensemble of several hundred filaments used in the buckling measurements. The large variability of the forces found in the second part is consistently reflected by this very wide distribution of active forces detected in the logistic regression in the first part.
We did small modifications to the buckling theory paragraph to clarify that in the first part, a distribution of forces rather than a constant value is inferred (page 6)
“Inserting the population median and quartiles of the distributions of bending modulus and critical length, we can now quantify the distribution of the active force density for the filaments in the ensemble from the buckling measurements. We obtain nearly identical values for both species, f ∼ (1.0±0.6) nN/µm, where the uncertainty represents a wide distribution of f across the ensemble rather than a measurement error.”
The same holds, of course, when inferring the distribution of the friction coefficients (page 5):
“The substrate contact requires lubrication from polysaccharide slime to enable bacteria to glide (Khayatan et al., 2015 ). Thus we assume an over- damped motion with co-linear friction, for which the propulsion force f and the free gliding velocity v0 of a filament are related by f = η v0, with a friction coefficient η. In this scenario, f can be inferred both from the observed Lc ∼ (f/B)−1/3 and, up to the proportionality coefficient η, from the observed free gliding velocity. Thus, by combining the two relations, one may expect also a strong correlation between Lc and v0. In order to test this relation for consistency with our data, we include v0 as a second regressor, by setting x = (L−Lc(v0))/∆Lc in Equation 1, with Lc(v0) = (η v0/(30.5722 B))−1/3, to reflect our expectation from theory (see below). Now, η rather than f is the only unknown, and its ensemble distribution will be determined in the regression. Figure 3 E,F show the buckling behavior…”
The (naturally) wide distribution of force (and friction) leads to a distribution of Lc as well. However, due to the small exponent of 1/3 in the buckling threshold Lc ∼ f 1/3, the distribution of Lc is not as wide as the distributions of the individually inferred f or η. This is visualized in panel G of Figure 3, plotting Lc as a function of v0 (v0 is equivalent to f , up to a proportionality coefficient η). The natural length distribution, in contrast, is very wide. Therefore, the buckling propensity of a filament is most strongly characterized by its length, while force variability, which alters Lc of the individual, plays a secondary role.
In order to clarify this, we edited the last paragraph of the Buckling Measurements section on page 5 of the manuscript:
“…Within the characteristic range of observed velocities (1 − 3 µm/s), the median Lc depends only mildly on v0, as compared to its rather broad distribution, indicated by the bands in Figure 3 G. Thus a possible correlation between f and v0 would only mildly alter Lc. The natural length distribution (cf. Appendix 1—figure 1 ), however, is very broad, and we conclude that growth rather than velocity or force distributions most strongly impacts the buckling propensity of cyanobacterial colonies. Also, we hardly observed short and fast filaments of K. animale, which might be caused by physiological limitations (Burkholder, 1934 ).”
Second, in the Profile analysis section, we did not report a correlation between force and velocity. As can be seen in Figure 4—figure Supplement 1, neither the active force nor the friction coefficient, as determined from the analysis of individual filaments, show any significant correlation with the velocity. This is also written in the discussion (page 7):
We see no significant correlation between L or v0 and f or η, but the observed values of f and η cover a wide range (Figure 4 B, C and Figure 4—figure Supplement 1 ).
Note that this is indeed consistent with the logistic regression: Using v0 as a second regressor did not significantly reduce the width of the distribution of Lc as compared to the simple logistic regression, indicating that force and velocity are not strongly correlated.
In order to clarify this in the manuscript, we modified that part (page 7):
“…We see no significant correlation between L or v0 and f or η, but the observed values of f and η cover a wide range (Figure 4 B,C and Figure 4— figure Supplement 1 ). This is consistent with the logistic regression, where using v0 as a second regressor did not significantly reduce the width of the distribution of critical lengths or active forces. The two estimates of the friction coefficient, from logistic regression and individual profile fits, are measured in (predominantly) orthogonal directions: tangentially for the logistic regression where the free gliding velocity was used, and transversely for the evolution of the buckling profiles. Thus we plot f/v over η in Figure 4 D, finding nearly identical values over about two decades. Since f and η are not correlated with v0, this is due to a correlation between f and η. This relation is remarkable in two aspects: On the one hand, it indicates that friction is mainly isotropic…”
From a theoretical perspective, not many new results are presented. The authors repeat the well-known calculation for filaments buckling under propulsive load and arrive at the literature result of buckling when the dimensionless number (f L3/B) is larger than 30.6 as previously derived by Sekimoto et al in 1995 [1] (see [2] for a clamped boundary condition and simulations). Other theoretical predictions for pushed semi-flexible filaments [1–4] are not discussed or compared with the experiments. Finally, the Authors use molecular dynamics type simulations similar to [2–4] to reproduce the buckling dynamics from the experiments. Unfortunately, no systematic comparison is performed.
[1] Ken Sekimoto, Naoki Mori, Katsuhisa Tawada, and Yoko Y Toyoshima. Symmetry breaking instabilities of an in vitro biological system. Physical review letters, 75(1):172, 1995.
[2] Raghunath Chelakkot, Arvind Gopinath, Lakshminarayanan Mahadevan, and Michael F Hagan. Flagellar dynamics of a connected chain of active, polar, brownian particles. Journal of The Royal Society Interface, 11(92):20130884, 2014.
[3] Rolf E Isele-Holder, Jens Elgeti, and Gerhard Gompper. Self-propelled worm-like filaments: spontaneous spiral formation, structure, and dynamics. Soft matter, 11(36):7181–7190, 2015.
[4] Rolf E Isele-Holder, Julia J¨ager, Guglielmo Saggiorato, Jens Elgeti, and Gerhard Gompper. Dynamics of self-propelled filaments pushing a load. Soft Matter, 12(41):8495–8505, 2016.
We thank the reviewer for pointing us to these publications, in particular the work by Sekimoto we were not aware of. We agree with the referee that the calculation is straight forward (basically known since Euler, up to modified boundary conditions). Our paper focuses on experimental work, the molecular dynamics simulations were included mainly as a consistency check and not intended to generate the beautiful post-buckling patterns observed in references [2-4]. However, such shapes do emerge in filamentous cyanobacteria, and with the data provided in our manuscript, simulations can be quantitatively matched to our experiments, which will be covered by future work.
We included the references in the revision of our manuscript, and a statement that we do not claim priority on these classical theoretical results.
Introduction, page 2:
“…Self-Buckling is an important instability for self-propelling rod-like micro-organisms to change the orientation of their motion, enabling aggregation or the escape from traps (Fily et al., 2020; Man and Kanso, 2019; Isele-Holder et al., 2015; Isele-Holder et al., 2016 ). The notion of self-buckling goes back to work of Leonhard Euler in 1780, who described elastic columns subject to gravity (Elishakoff, 2000 ). Here, the principle is adapted to the self-propelling, flexible filaments (Fily et al., 2020; Man and Kanso, 2019; Sekimoto et al., 1995 ) that glide onto an obstacle. Filaments buckle if they exceed a certain critical length Lc ∼ (B/f)1/3, where B is the bending modulus and f the propulsion force density…”
Buckling theory, page 5:
“…The buckling of gliding filaments differs in two aspects: the propulsion forces are oriented tangentially instead of vertically, and the front end is supported instead of clamped. Therefore, with L < Lc all initial orientations are indifferently stable, while for L > Lc, buckling induces curvature and a resultant torque on the head, leading to rotation (Fily et al., 2020; Chelakkot et al., 2014; Sekimoto et al., 1995 ). Buckling under concentrated tangential end-loads has also been investigated in literature (de Canio et al., 2017; Wolgemuth et al., 2005 ), but leads to substantially different shapes of buckled filaments. We use classical Kirchhoff theory for a uniform beam of length L and bending modulus B, subject to a force density ⃗b = −f ⃗t − η ⃗v, with an effective active force density f along the tangent ⃗t, and an effective friction proportional to the local velocity ⃗v, analog to existing literature (Fily et al., 2020; Chelakkot et al., 2014; Sekimoto et al., 1995 )…”
Further on page 6:
“To derive the critical self-buckling length, Equation 5 can be linearized for two scenarios that lead to the same Lc: early-time small amplitude buckling and late-time stationary rotation at small and constant curvature (Fily et al., 2020; Chelakkot et al., 2014 ; Sekimoto et al., 1995 ). […] Thus, in physical units, the critical length is given by Lc = (30.5722 B/f)1/3, which is reproduced in particle based simulations (Appendix Figure 2 ) analogous to those in Isele-Holder et al. (2015, 2016).”
Discussion, page 7 & 8:
“…This, in turn, has dramatic consequences on the exploration behavior and the emerging patterns (Isele-Holder et al., 2015, 2016; Abbaspour et al., 2021; Duman et al., 2018; Prathyusha et al., 2018; Jung et al., 2020 ): (L/Lc)3 is, up to a numerical prefactor, identical to the flexure number (Isele-Holder et al., 2015, 2016; Duman et al., 2018; Winkler et al., 2017 ), the ratio of the Peclet number and the persistence length of active polymer melts. Thus, the ample variety of non-equilibrium phases in such materials (Isele-Holder et al., 2015, 2016; Prathyusha et al., 2018; Abbaspour et al., 2021 ) may well have contributed to the evolutionary success of filamentous cyanobacteria.”
Reviewer 3:
Summary:
This paper presents novel and innovative force measurements of the biophysics of gliding cyanobacteria filaments. These measurements allow for estimates of the resistive force between the cell and substrate and provide potential insight into the motility mechanism of these cells, which remains unknown.
We thank the reviewer for the positive evaluation of our work. We have revised the manuscript according to their comments and detail our replies and modifications next to the individual points below.
Strengths:
The authors used well-designed microfabricated devices to measure the bending modulus of these cells and to determine the critical length at which the cells buckle. I especially appreciated the way the authors constructed an array of pillars and used it to do 3-point bending measurements and the arrangement the authors used to direct cells into a V-shaped corner in order to examine at what length the cells buckled at. By examining the gliding speed of the cells before buckling events, the authors were able to determine how strongly the buckling length depends on the gliding speed, which could be an indicator of how the force exerted by the cells depends on cell length; however, the authors did not comment on this directly.
We thank the referee for the positive assessment of our work. Importantly, we do not see a significant correlation between buckling length and gliding speeds, and we also do not see a correlation with filament length, consistent with the assumption of a propulsion force density that is more or less homogeneously distributed along the filament. Note that each filament consists of many metabolically independent cells, which renders cyanobacterial gliding a collective effort of many cells, in contrast to gliding of, e.g., myxobacteria.
In response also to the other referees’ comments, we modified the manuscript to reflect more on the absence of a strong correlation between velocity and force/critical length. We modified the Buckling measurements section on page 5 of the paper:
“The substrate contact requires lubrication from polysaccharide slime to enable bacteria to glide (Khayatan et al., 2015 ). Thus we assume an over-damped motion with co-linear friction, for which the propulsion force f and the free gliding velocity v0 of a filament are related by f = η v0, with a friction coefficient η. In this scenario, f can be inferred both from the observed Lc ∼ (f/B)−1/3 and, up to the proportionality coefficient η, from the observed free gliding velocity. Thus, by combining the two relations, one may expect also a strong correlation between Lc and v0. In order to test this relation for consistency with our data, we include v0 as a second regressor, by setting x = (L−Lc(v0))/∆Lc in Equation 1, with Lc(v0) = (η v0/(30.5722 B))−1/3, to reflect our expectation from theory (see below). Now, η rather than f is the only unknown, and its ensemble distribution will be determined in the regression. Figure 3 E, F show the buckling behavior…”
Further, we edited the last paragraph of the Buckling measurements section on page 5 of the manuscript:
“Within the characteristic range of observed velocities (1 − 3 µm/s), the median Lc depends only mildly on v0, as compared to its rather broad distribution, indicated by the bands in Figure 3 G. Thus a possible correlation between f and v0 would only mildly alter Lc. The natural length distribution (cf. Appendix 1—figure 1 ), however, is very broad, and we conclude that growth rather than velocity or force distributions most strongly impacts the buckling propensity of cyanobacterial colonies. Also, we hardly observed short and fast filaments of K. animale, which might be caused by physiological limitations (Burkholder, 1934 ).”
We also rephrased the corresponding discussion paragraph on page 7:
“…Thus we plot f/v over η in Figure 4 D, finding nearly identical values over about two decades. Since f and η are not correlated with v0, this is due to a correlation between f and η. This relation is remarkable in two aspects: On the one hand, it indicates that friction is mainly isotropic. This suggests that friction is governed by an isotropic process like bond friction or lubrication from the slime layer in the contact with the substrate, the latter being consistent with the observation that mutations deficient of slime secretion do not glide but exogenous addition of slime restores motility (Khayatan et al., 2015 ). In contrast, hydrodynamic drag from the surrounding bulk fluid (Man and Kanso, 2019 ), or the internal friction of the gliding apparatus would be expected to generate strongly anisotropic friction. If the latter was dominant, a snapping-like transition into the buckling state would be expected, rather than the continuously growing amplitude that is observed in experiments. On the other hand, it indicates that friction and propulsion forces…”
Weaknesses:
There were two minor weaknesses in the paper.
First, the authors investigate the buckling of these gliding cells using an Euler beam model. A similar mathematical analysis was used to estimate the bending modulus and gliding force for Myxobacteria (C.W. Wolgemuth, Biophys. J. 89: 945-950 (2005)). A similar mathematical model was also examined in G. De Canio, E. Lauga, and R.E Goldstein, J. Roy. Soc. Interface, 14: 20170491 (2017). The authors should have cited these previous works and pointed out any differences between what they did and what was done before.
We thank the reviewer for pointing us to these references. The paper by Wolgemuth is theoretical work, describing A-motility in myxobacteria by a concentrated propulsion force at the rear end of the bacterium, possibly stemming from slime extrusion. This model was a little later refuted by [A3], who demonstrated that focal adhesion along the bacterial body and thus a distributed force powers A-motility, a mechanism that has by now been investigated in great detail (see [A10]). The paper by Canio et al. contains a thorough theoretical analysis of a filament that is clamped at one end and subject to a concentrated tangential load on the other. Since both models comprise a concentrated end-load rather than a distributed propulsion force density, they describe a substantially different motility mechanism, leading also to substantially different buckling profiles. Consequentially, these models cannot be applied to cyanobacterial gliding.
We included both citations in the revision and pointed out the differences to our work in the introduction (page 2):
“…A few species appear to employ a type-IV-pilus related mechanism (Khayatan et al., 2015; Wilde and Mullineaux, 2015 ), similar to the better- studied myxobacteria (Godwin et al., 1989; Mignot et al., 2007; Nan et al., 2014; Copenhagen et al., 2021; Godwin et al., 1989 ), which are short, rod-shaped single cells that exhibit two types of motility: S (social) motility based on pilus extension and retraction, and A (adventurous) motility based on focal adhesion (Chen and Nan, 2022 ) for which also slime extrusion at the trailing cell pole was earlier postulated as mechanism (Wolgemuth et al., 2005 ). Yet, most gliding filamentous cyanobacteria do not exhibit pili and their gliding mechanism appears to be distinct from myxobacteria (Khayatan et al., 2015 ).”
And in Buckling theory, page 5:
“….The buckling of gliding filaments differs in two aspects: the propulsion forces are oriented tangentially instead of vertically, and the front end is supported instead of clamped. Therefore, with L < Lc all initial orientations are indifferently stable, while for L > Lc, buckling induces curvature and a resultant torque on the head, leading to rotation (Fily et al., 2020; Chelakkot et al., 2014; Sekimoto et al., 1995 ). Buckling under concentrated tangential end-loads has also been investigated in literature (de Canio et al., 2017; Wolgemuth et al., 2005 ), but leads to substantially different shapes of buckled filaments.”
The second weakness is that the authors claim that their results favor a focal adhesion-based mechanism for cyanobacterial gliding motility. This is based on their result that friction and adhesion forces correlate strongly. They then conjecture that this is due to more intimate contact with the surface, with more contacts producing more force and pulling the filaments closer to the substrate, which produces more friction. They then claim that a slime-extrusion mechanism would necessarily involve more force and lower friction. Is it necessarily true that this latter statement is correct? (I admit that it could be, but is it a requirement?)
We thank the referee for raising this interesting question. Our claim regarding slime extrusion is based on three facts: i. mutations deficient of slime extrusion do not glide, but start gliding as soon as slime is provided externally [A4]. ii. A positive correlation between speed and slime layer thickness was observed in Nostoc [A11]. iii. The fluid mechanics of lubricated sliding contacts is very well understood and predicts a decreasing resistance with increasing layer thickness.
We included these considerations in the revision of our manuscript (page 8):
“…it indicates that friction and propulsion forces, despite being quite variable, correlate strongly. Thus, generating more force comes, inevitably, at the expense of added friction. For lubricated contacts, the friction coefficient is proportional to the thickness of the lubricating layer (Snoeijer et al., 2013 ), and we conjecture active force and drag both increase due to a more intimate contact with the substrate. This supports mechanisms like focal adhesion (Mignot et al., 2007 ) or a modified type-IV pilus (Khayatan et al., 2015 ), which generate forces through contact with extracellular surfaces, as the underlying mechanism of the gliding apparatus of filamentous cyanobacteria: more contacts generate more force, but also closer contact with the substrate, thereby increasing friction to the same extent. Force generation by slime extrusion (Hoiczyk and Baumeister, 1998 ), in contrast, would lead to the opposite behavior: More slime generates more propulsion, but also reduces friction. Besides fundamental fluid-mechanical considerations (Snoeijer et al., 2013 ), this is rationalized by two experimental observations: i. gliding velocity correlates positively with slime layer thickness (Dhahri et al., 2013 ) and ii. motility in slime-secretion deficient mutants is restored upon exogenous addition of polysaccharide slime. Still we emphasize that many other possibilities exist. One could, for instance, postulate a regulation of the generated forces to the experienced friction, to maintain some preferred or saturated velocity.”
Related to this, the authors use a model with isotropic friction. They claim that this is justified because they are able to fit the cell shapes well with this assumption. How would assuming a non-isotropic drag coefficient affect the shapes? It may be that it does equally well, in which case, the quality of the fits would not be informative about whether or not the drag was isotropic or not.
The referee raises another very interesting point. Given the typical variability and uncertainty in experimental measurements (cf. error Figure 4 A), a model with a sightly anisotropic friction could be fitted to the observed buckling profiles as well, without significant increase of the mismatch. Yet, strongly anisotropic friction would not be consistent with our observations.
Importantly, however, we did not conclude on isotropic friction based on the fit quality, but based on a comparison between free gliding and early buckling (Figure 4 D). In early buckling, the dominant motion is in transverse direction, while longitudinal motion is insignificant, due to geometric reasons. Thus, independent of the underlying model, mostly the transverse friction coefficiont is inferred. In contrast, free gliding is a purely longitudinal motion, and thus only the friction coefficient for longitudinal motion can be inferred. These two friction coefficients are compared in Figure 4 D. Still, the scatter of that data would allow to fit a certain anisotropy within the error margins. What we can exclude based on out observation is the case of a strongly anisotropic friction. If there is no ab-initio reason for anisotropy, nor a measurement that indicates it, we prefer to stick with the simplest
assumption. We carefully chose our wording in the Discussion as “mainly isotropic” rather
than “isotropic” or “fully isotropic”.
We added a small statement to the Discussion on page 7 & 8:
“... Thus we plot f/v over η in Figure 4 D, finding nearly identical values over about two decades. Since f and η are not correlated with v0, this is due to a correlation between f and η. This relation is remarkable in two aspects: On the one hand, it indicates that friction is mainly isotropic. This suggests that friction is governed by an isotropic process like bond friction or lubrication from the slime layer in the contact with the substrate, the latter being consistent with the observation that mutations deficient of slime secretion do not glide but exogenous addition of slime restores motility (Khayatan et al., 2015 ). In contrast, hydrodynamic drag from the surrounding bulk fluid (Man and Kanso, 2019 ), or the internal friction of the gliding apparatus would be expected to generate strongly anisotropic friction. If the latter was dominant, a snapping-like transition into the buckling state would be expected, rather than the continuously growing amplitude that is observed in experiments. On the other hand, it indicates that friction and propulsion forces ...”
Recommendations for the authors
The discussion regarding how the findings of this paper imply that cyanobacteria filaments are propelled by adhesion forces rather than slime extrusion should be improved, as this conclusion seems questionable. There appears to be an inconsistency with a buckling force said to be only weakly dependent on the gliding velocity, while its ratio with the velocity correlates with a friction coefficient. Finally, data and source code should be made publicly available.
In the revised version, we have modified the discussion of the force generating mechanism according to the reviewer suggestions. The perception of inconsistency in the velocity dependence of the buckling force was based on a misunderstanding, as we detailed in our reply to the referee. We revised the corresponding section to make it more clear. Data and source code have been uploaded to a public data repository.
Reviewer #2 (recommendations for the authors)
Despite eLife policy, the authors do not provide a Data Availability Statement. For the presented manuscript, data and source code should be provided “via trusted institutional or third-party repositories that adhere to policies that make data discoverable, accessible and usable.” https://elifesciences.org/inside-elife/51839f0a/for-authors-updates- to-elife-s-data-sharing-policies
Most of the issues in this reviewer’s public review should be easy to correct, so I would strongly support the authors to provide an amended manuscript.
We added the Data Availability Statement in the amended manuscript.
References
[A1] E. Hoiczyk and W. Baumeister. “The junctional pore complex, a prokaryotic secretion organelle, is the molecular motor underlying gliding motility in cyanobacteria”. In: Curr. Biol. 8.21 (1998), pp. 1161–1168. doi: 10.1016/s0960-9822(07)00487-3.
[A2] N. Read, S. Connell, and D. G. Adams. “Nanoscale Visualization of a Fibrillar Array in the Cell Wall of Filamentous Cyanobacteria and Its Implications for Gliding Motility”. In: J. Bacteriol. 189.20 (2007), pp. 7361–7366. doi: 10.1128/jb.00706- 07.
[A3] T. Mignot, J. W. Shaevitz, P. L. Hartzell, and D. R. Zusman. “Evidence That Focal Adhesion Complexes Power Bacterial Gliding Motility”. In: Science 315.5813 (2007), pp. 853–856. doi: 10.1126/science.1137223.
[A4] Behzad Khayatan, John C. Meeks, and Douglas D. Risser. “Evidence that a modified type IV pilus-like system powers gliding motility and polysaccharide secretion in filamentous cyanobacteria”. In: Mol. Microbiol. 98.6 (2015), pp. 1021–1036. doi: 10.1111/mmi.13205.
[A5] Tilo Pompe, Martin Kaufmann, Maria Kasimir, Stephanie Johne, Stefan Glorius, Lars Renner, Manfred Bobeth, Wolfgang Pompe, and Carsten Werner. “Friction- controlled traction force in cell adhesion”. In: Biophysical journal 101.8 (2011), pp. 1863–1870.
[A6] Hirofumi Wada, Daisuke Nakane, and Hsuan-Yi Chen. “Bidirectional bacterial gliding motility powered by the collective transport of cell surface proteins”. In: Physical Review Letters 111.24 (2013), p. 248102.
[A7] Jo¨el Tchoufag, Pushpita Ghosh, Connor B Pogue, Beiyan Nan, and Kranthi K Mandadapu. “Mechanisms for bacterial gliding motility on soft substrates”. In: Proceedings of the National Academy of Sciences 116.50 (2019), pp. 25087–25096.
[A8] Chenyi Fei, Sheng Mao, Jing Yan, Ricard Alert, Howard A Stone, Bonnie L Bassler, Ned S Wingreen, and Andrej Kosmrlj. “Nonuniform growth and surface friction determine bacterial biofilm morphology on soft substrates”. In: Proceedings of the National Academy of Sciences 117.14 (2020), pp. 7622–7632.
[A9] Arja Ray, Oscar Lee, Zaw Win, Rachel M Edwards, Patrick W Alford, Deok-Ho Kim, and Paolo P Provenzano. “Anisotropic forces from spatially constrained focal adhesions mediate contact guidance directed cell migration”. In: Nature communications 8.1 (2017), p. 14923.
[A10] Jing Chen and Beiyan Nan. “Flagellar motor transformed: biophysical perspectives of the Myxococcus xanthus gliding mechanism”. In: Frontiers in Microbiology 13 (2022), p. 891694.
[A11] Samia Dhahri, Michel Ramonda, and Christian Marliere. “In-situ determination of the mechanical properties of gliding or non-motile bacteria by atomic force microscopy under physiological conditions without immobilization”. In: PLoS One 8.4 (2013), e61663.
Tags
Annotators
URL
-
-
vscodium.com vscodium.com
-
VSCodium Free/Libre Open Source Software Binaries of VS Code

-
-
www.biorxiv.org www.biorxiv.org
-
Reviewer #2 (Public Review):
Pyoverdines, siderophores produced by many Pseudomonads, are one of the most diverse groups of specialized metabolites and are frequently used as model systems. Thousands of Pseudomonas genomes are available, but large-scale analyses of pyoverdines are hampered by the biosynthetic gene clusters (BGCs) being spread across multiple genomic loci and existing tools' inability to accurately predict amino acid substrates of the biosynthetic adenylation (A) domains. The authors present a bioinformatics pipeline that identifies pyoverdine BGCs and predicts the A domain substrates with high accuracy. They tackled a second challenging problem by developing an algorithm to differentiate between outer membrane receptor selectivity for pyoverdines versus other siderophores and substrates. The authors applied their dataset to thousands of Pseudomonas strains, producing the first comprehensive overview of pyoverdines and their receptors and predicting many new structural variants.
The A domain substrate prediction is impressive, including the correction of entries in the MIBiG database. Their high accuracy came from a relatively small training dataset of A domains from 13 pyoverdine BGCs. The authors acknowledge that this small dataset does not include all substrates, and correctly point out that new sequence/structure pairs can be added to the training set to refine the prediction algorithm. The authors could have been more comprehensive in finding their training set data. For instance, the authors claim that histidine "had not been previously documented in pyoverdines", but the sequenced strain P. entomophila L48, incorporates His (10.1007/s10534-009-9247-y). The workflow cannot differentiate between different variants of Asp and OHOrn, and it's not clear if this is a limitation of the workflow, the training data, or both. The prediction workflow holds up well in Burkholderiales A domains, however, they fail to mention in the main text that they achieved these numbers by adding more A domains to their training set.
To validate their predictions, they elucidated structures of several new pyoverdines, and their predictions performed well. However, the authors did not include their MS/MS data, making it impossible to validate their structures. In general, the biggest limitation of the submitted manuscript is the near-empty methods section, which does not include any experimental details for the 20 strains or details of the annotation pipeline (such as "Phydist" and "Syndist"). The source code also does not contain the requisite information to replicate the results or re-use the pipeline, such as the antiSMASH version and required flags. That said, skimming through the source code and data (kindly provided upon request) suggests that the workflow itself is sound and a clear improvement over existing tools for pyoverdine BGC annotation.
Predicting outer membrane receptor specificity is likewise a challenging problem and the authors have made a promising achievement by finding specific gene regions that differentiate the pyoverdine receptor FpvA from FpvB and other receptor families. Their predictions were not tested experimentally, but the finding that only predicted FpvA receptors were proximate to the biosynthesis genes lends credence to the predictive power of the workflow. The authors find predicted pyoverdine receptors across an impressive 468 genera, an exciting finding for expanding the role of pyoverdines as public goods beyond Pseudomonas. However, whether or not these receptors can recognize pyoverdines (and if so, which structures!) remains to be investigated.
In all, the authors have assembled a rich dataset that will enable large-scale comparative genomic analyses. This dataset could be used by a variety of researchers, including those studying natural product evolution, public good eco/evo dynamics, and NRPS engineering.
-
-
-
Summary of the Talk on the Future of Web Frameworks by Ryan Carniado
-
Introduction and Background:
- Ryan Carniado, creator of SolidJS, has extensive experience in web development spanning 25 years, having worked with various technologies including ASP.NET, Rails, and jQuery.
- SolidJS was started in 2016 and reflects a shift towards new paradigms in web frameworks, particularly in the front-end JavaScript ecosystem.
- Quote: "I've been doing web development now for like 25 years... it wasn't really until the 2010s that my passion reignited for front-end JavaScript."
-
Core Themes and Concepts:
- Modern front-end development heavily relies on components (e.g., class components, function components, web components) which serve as fundamental building blocks for creating modular and composable applications.
- Components have runtime implications due to their update models and life cycles, influencing the performance and design of web applications.
- Traditional component models use either a top-down diffing approach (like virtual DOM) or rely on compilation optimizations to enhance performance.
- Quote: "Modern front-end development for years has been about components... however, in almost every JavaScript framework components have runtime implications."
-
Reactive Programming and Fine-Grained Reactivity:
- Ryan advocates for a shift towards reactive programming to manage state changes more efficiently. This approach is likened to how spreadsheets work, where changes in input immediately affect outputs without re-execution of all logic.
- Fine-grained reactivity involves three primitives: signals (atomic atoms), derived state (computeds or memos), and side effects (effects). These primitives help manage state and side effects without heavy reliance on the component architecture or compilation.
- Quote: "What if the relationship held instead? What if whenever we changed B and C, A also immediately updated? That's basically what reactive programming is."
-
Practical Demonstration and Code Examples:
- Ryan demonstrated the implementation of fine-grained reactivity using SolidJS, showing how state management and updates can be handled more efficiently compared to traditional methods that rely heavily on component re-renders and hooks.
- The examples provided emphasized how reactive programming can simplify state management and improve performance by only updating components that need to change, reducing unnecessary re-renders.
- Quote: "The problem is that if any state in this component changes, the whole thing reruns again... what if we didn't? What if components didn't dictate the boundary of our performance?"
-
Performance Implications and Advantages:
- The "reactive advantage" in SolidJS and similar frameworks lies in their ability to run components minimally, avoiding stale closures and excessive dependencies that can degrade performance.
- Ryan highlighted that in reactive frameworks, component boundaries do not dictate performance; instead, performance optimization is achieved through smarter state management and reactive updates.
- Quote: "Components run once... state is independent of components. Component boundaries are for your sake, how you want to organize your code, not for performance."
-
Future Directions and Framework Evolution:
- The talk touched on the broader impact of reactive programming and fine-grained reactivity on the evolution of web frameworks. This includes the potential integration with AI and compilers to further optimize performance and developer experience.
- Ryan suggested that the future of web development might see more frameworks adopting similar reactive principles, possibly leading to a "reactive renaissance" in the industry.
- Quote: "A revolution is not in the cards, maybe just a reactive Renaissance."
-
Q&A and Additional Insights:
- During the Q&A, Ryan discussed the potential application of SolidJS principles in environments like React Native and native code development, indicating the flexibility and broad applicability of reactive programming principles across different platforms and technologies.
- Quote: "The custom renderer and stuff is not something you need a virtual DOM to... the reactive tree as it turns out is completely independent."
-
-
-
raphlinus.github.io raphlinus.github.io
-
Summary of Raph Levien's Blog: "Towards principled reactive UI"
Introduction
- Diversity of Reactive UI Systems: The blog notes the diversity in reactive UI systems primarily sourced from open-source projects. Levien highlights a lack of comprehensive literature but acknowledges existing sources offer insights into better practices. His previous post aimed to organize these diverse patterns.
- "There is an astonishing diversity of 'literature' on reactive UI systems."
Goals of the Inquiry
- Clarifying Inquiry Goals: Levien sets goals not to review but to guide inquiry into promising avenues of reactive UI in Rust, likening it to mining for rich veins of ore rather than stamp collecting.
- "I want to do mining, not stamp collecting."
Main Principles Explored
- Observable Objects vs. Future-like Polling: Discusses the importance of how systems manage observable objects or utilize future-like polling for efficient UI updates.
- Tree Mutations: How to express mutation in the render object tree is crucial, focusing on maintaining stable node identities within the tree.
- "Then I will go into deeper into three principles, which I feel are critically important in any reactive UI framework."
Crochet: A Research Prototype
- Introduction of Crochet: Introduces 'Crochet', a prototype exploring these principles, acknowledging its current limitations and potential for development.
- "Finally, I will introduce Crochet, a research prototype built for the purpose of exploring these ideas."
Goals for Reactive UI
- Concise Application Logic: Emphasizes the need for concise, clear application logic that drives UI efficiently, with reactive UI allowing declarative state expressions of the view tree.
- "The main point of a reactive UI architecture is so that the app can express its logic clearly and concisely."
- Incremental Updates: Advocates for incremental updates in UI rendering to avoid performance issues related to full re-renders, highlighting the limitations of systems like imgui and the potential of systems like Conrod, despite its shortcomings.
- "While imgui can express UI concisely, it cheats somewhat by not being incremental."
Evaluation of Existing Systems
- Comparison with Other Systems: Mentions SwiftUI, imgui, React, and Svelte, discussing their approaches to handling reactive UI and their adaptability to Rust.
- "SwiftUI has gained considerable attention due to its excellent ergonomics in this regard."
Technical Challenges and Proposals
- Challenges in Tree Mutation and Stable Identity: Discusses the challenges in tree mutation techniques and the importance of stable identity in UI components to preserve user interaction states.
- "Mutation of the DOM is expressed through a well-specified and reasonably ergonomic, if inefficient, interface."
Conclusion and Future Work
- Future Directions and Experiments: Encourages experimentation with the Crochet prototype and discusses the ongoing development and research in making reactive UIs more efficient and user-friendly.
- "I encourage people to experiment with the Crochet code."
This blog post encapsulates Levien's ongoing exploration into developing a principled approach to reactive UI in Rust, highlighting the complexity of the task and his experimental prototype, Crochet, as a step towards solving these challenges.
- Diversity of Reactive UI Systems: The blog notes the diversity in reactive UI systems primarily sourced from open-source projects. Levien highlights a lack of comprehensive literature but acknowledges existing sources offer insights into better practices. His previous post aimed to organize these diverse patterns.
-
-
www.biorxiv.org www.biorxiv.org
-
Author response:
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public Review):
Strengths:
This work (almost didactically) demonstrates how to develop, calibrate, validate and analyze a comprehensive, spatially resolved, dynamical, multicellular model. Testable model predictions of (also non-monotonic) emergent behaviors are derived and discussed. The computational model is based on a widely-used simulation platform and shared openly such that it can be further analyzed and refined by the community.
Weaknesses:
While the parameter estimation approach is sophisticated, this work does not address issues of structural and practical non-identifiability (Wieland et al., 2021, DOI:10.1016/j.coisb.2021.03.005) of parameter values, given just tissue-scale summary statistics, and does not address how model predictions might change if alternative parameter combinations were used. Here, the calibrated model represents one point estimate (column "Value" in Suppl. Table 1) but there is specific uncertainty of each individual parameter value and such uncertainties need to be propagated (which is computationally expensive) to the model predictions for treatment scenarios.
We thank the reviewer for the excellent suggestions and observations. The CaliPro parameterization technique applied puts an emphasis on finding a robust parameter space instead of a global optimum. To address structural non-identifiability, we utilized partial rank correlation coefficient with each iteration of the calibration process to ensure that the sensitivity of each parameter was relevant to model outputs. We also found that there were ranges of parameter values that would achieve passing criteria but when testing the ranges in replicate resulted in inconsistent outcomes. This led us to further narrow the parameters into a single parameter set that still had stochastic variability but did not have such large variability between replicate runs that it would be unreliable. Additional discussion on this point has been added to lines 623-628. We acknowledge that there are likely other parameter sets or model rules that would produce similar outcomes but the main purpose of the model was to utilize it to better understand the system and make new predictions, which our calibration scheme allowed us to accomplish.
Regarding practical non-identifiability, we acknowledge that there are some behaviors that are not captured in the model because those behaviors were not specifically captured in the calibration data. To ensure that the behaviors necessary to answer the aims of our paper were included, we used multiple different datasets and calibrated with multiple different output metrics. We believe we have identified the appropriate parameters to recapitulate the dominating mechanisms underlying muscle regeneration. We have added additional discussion on practical non-identifiability to lines 621-623.
Suggested treatments (e.g. lines 484-486) are modeled as parameter changes of the endogenous cytokines (corresponding to genetic mutations!) whereas the administration of modified cytokines with changed parameter values would require a duplication of model components and interactions in the model such that cells interact with the superposition of endogenous and administered cytokine fields. Specifically, as the authors also aim at 'injections of exogenously delivered cytokines' (lines 578, 579) and propose altering decay rates or diffusion coefficients (Fig. 7), there needs to be a duplication of variables in the model to account for the coexistence of cytokine subtypes. One set of equations would have unaltered (endogenous) and another one have altered (exogenous or drugged) parameter values. Cells would interact with both of them.
Our perturbations did not include delivery of exogenously delivered cytokines and instead were focused on microenvironmental changes in cytokine diffusion and decay rates or specific cytokine concentration levels. For example, the purpose of the VEGF delivery perturbation was to test how an increase in VEGF concentrations would alter regeneration outcome metrics with the assumption that the delivered VEGF would act in the same manner as the endogenous VEGF. We have clarified the purpose of the simulations on line 410. We agree that exploring if model predictions would be altered if endogenous and exogenous were represented separately; however, we did not explore this type of scenario.
This work shows interesting emergent behavior from nonlinear cytokine interactions but the analysis does not provide insights into the underlying causes, e.g. which of the feedback loops dominates early versus late during a time course.
Indeed, analyzing the model to fully understand the time-varying interactions between the multiple feedback loops is a challenge in and of itself, and we appreciate the opportunity to elaborate on our approach to addressing this challenge. First: the crosstalk/feedback between cytokines and the temporal nature was analyzed in the heatmap (Fig. 6) and lines 474-482. Second: the sensitivity of cytokine parameters to specific outputs was included in Table 9 and full-time course sensitivity is included in Supplemental Figure 2. Further correlation analysis was also included to demonstrate how cytokine concentrations influenced specific output metrics at various timepoints (Supplemental Fig. 3). We agree that further elaboration of these findings is required; therefore, we added lines 504-509 to discuss the specific mechanisms at play with the combined cytokine interactions. We also added more discussion (lines 637-638) regarding future work that could develop more analysis methods to further investigate the complex behaviors in the model.
Reviewer #2 (Public Review):
Strengths:
The manuscript identified relevant model parameters from a long list of biological studies. This collation of a large amount of literature into one framework has the potential to be very useful to other authors. The mathematical methods used for parameterization and validation are transparent.
Weaknesses:>
I have a few concerns which I believe need to be addressed fully.
My main concerns are the following:
(1) The model is compared to experimental data in multiple results figures. However, the actual experiments used in these figures are not described. To me as a reviewer, that makes it impossible to judge whether appropriate data was chosen, or whether the model is a suitable descriptor of the chosen experiments. Enough detail needs to be provided so that these judgements can be made.
Thank you for raising this point. We created a new table (Supplemental table 6) that describes the techniques used for each experimental measurement.
(2) Do I understand it correctly that all simulations are done using the same initial simulation geometry? Would it be possible to test the sensitivity of the paper results to this geometry? Perhaps another histological image could be chosen as the initial condition, or alternative initial conditions could be generated in silico? If changing initial conditions is an unreasonably large request, could the authors discuss this issue in the manuscript?
We appreciate your insightful question regarding the initial simulation geometry in our model. The initial configuration of the fibers/ECM/microvascular structures was kept consistent but the location of the necrosis was randomly placed for each simulation. Future work will include an in-depth analysis of altered histology configuration on model predictions which has been added to lines 618-621. We did a preliminary example analysis by inputting a different initial simulation geometry, which predicted similar regeneration outcomes. We have added Supplemental Figure 5 that provides the results of that example analysis.
(3) Cytokine knockdowns are simulated by 'adjusting the diffusion and decay parameters' (line 372). Is that the correct simulation of a knockdown? How are these knockdowns achieved experimentally? Wouldn't the correct implementation of a knockdown be that the production or secretion of the cytokine is reduced? I am not sure whether it's possible to design an experimental perturbation which affects both parameters.
We appreciate that this important question has been posed. Yes, in order to simulate the knockout conditions, the cytokine secretion was reduced/eliminated. The diffusion and decay parameters were also adjusted to ensure that the concentration within the system was reduced. Lines 391-394 were added to clarify this assumption.
(4) The premise of the model is to identify optimal treatment strategies for muscle injury (as per the first sentence of the abstract). I am a bit surprised that the implemented experimental perturbations don't seem to address this aim. In Figure 7 of the manuscript, cytokine alterations are explored which affect muscle recovery after injury. This is great, but I don't believe the chosen alterations can be done in experimental or clinical settings. Are there drugs that affect cytokine diffusion? If not, wouldn't it be better to select perturbations that are clinically or experimentally feasible for this analysis? A strength of the model is its versatility, so it seems counterintuitive to me to not use that versatility in a way that has practical relevance. - I may well misunderstand this though, maybe the investigated parameters are indeed possible drug targets.
Thank you for your thoughtful feedback. The first sentence (lines 32-34) of the abstract was revised to focus on beneficial microenvironmental conditions to best reflect the purpose of the model. The clinical relevance of the cytokine modifications is included in the discussion (lines 547-558) with additional information added to lines 524-526. For example, two methods to alter diffusion experimentally are: antibodies that bind directly to the cytokine to prevent it from binding to its receptor on the cell surface and plasmins that induce the release of bound cytokines.
(5) A similar comment applies to Figure 5 and 6: Should I think of these results as experimentally testable predictions? Are any of the results surprising or new, for example in the sense that one would not have expected other cytokines to be affected as described in Figure 6?
We appreciate the opportunity to clarify the basis for these perturbations. The perturbations included in Figure 5 were designed to mimic the conditions of a published experiment that delivered VEGF in vivo (Arsic et al. 2004, DOI:10.1016/J.YMTHE.2004.08.007). The perturbation input conditions and experimental results are included in Table 8 and Supplemental Table 6 has been added to include experimental data and method description of the perturbation. The results of this analysis provide both validation and new predictions, because some the outputs were measured in the experiments while others were not measured. The additional output metrics and timepoints that were not collected in the experiment allow for a deeper understanding of the dynamics and mechanisms leading to the changes in muscle recovery (lines 437-454). These model outputs can provide the basis for future experiments; for example, they highlight which time points would be more important to measure and even provide predicted effect sizes that could be the basis for a power analysis (lines 639-640).
Regarding Figure 6, the published experimental outcomes of cytokine KOs are included in Table 8. The model allowed comparison of different cytokine concentrations at various timepoints when other cytokines were removed from the system due to the KO condition. The experimental results did not provide data on the impact on other cytokine concentrations but by using the model we were able to predict temporally based feedback between cytokines (lines 474-482). These cytokine values could be collected experimentally but would be time consuming and expensive. The results of these perturbations revealed the complex nature of the relationship between cytokines and how removal of one cytokine from the system has a cascading temporal impact. Lines 533-534 have been added to incorporate this into the discussion.
(6) In figure 4, there were differences between the experiments and the model in two of the rows. Are these differences discussed anywhere in the manuscript?
We appreciate your keen observation and the opportunity to address these differences. The model did not match experimental results for CSA output in the TNF KO and antiinflammatory nanoparticle perturbation or TGF levels with the macrophage depletion. While it did align with the other experimental metrics from those studies, it is likely that there are other mechanisms at play in the experimental conditions that were not captured by simulating the downstream effects of the experimental perturbations. We have added discussion of the differences to lines 445-454.
(7) The variation between experimental results is much higher than the variation of results in the model. For example, in Figure 3 the error bars around experimental results are an order of magnitude larger than the simulated confidence interval. Do the authors have any insights into why the model is less variable than the experimental data? Does this have to do with the chosen initial condition, i.e. do you think that the experimental variability is due to variation in the geometries of the measured samples?
Thank you for your insightful observations and questions. The lower model variability is attributed to the larger sample size of model simulations compared to experimental subjects. By running 100 simulations it narrows in the confidence interval (average 2.4 and max 3.3) compared to the experiments that typically had a sample size of less than 15. If the number of simulations had been reduced to 15 the stochasticity within the model results in a larger confidence interval (average 7.1 and max 10). There are also several possible confounding variables in the experimental protocols (i.e. variations in injury, different animal subjects for each timepoint, etc.) that are kept constant in the model simulation. We have added discussion of this point to the manuscript (lines 517519). Future work with the model will examine how variations in conditions, such as initial muscle geometry, injury, etc, alter regeneration outcomes and overall variability. This discussion has been incorporated into lines 640-643.
(8) Is figure 2B described anywhere in the text? I could not find its description.
Thank you for pointing that out. We have added a reference for Fig. 2B on line 190.
Recommendations for the authors:
Reviewer #1 (Recommendations For The Authors):
(1) The model code seems to be available from https://simtk.org/projects/muscle_regen but that website requests member status ("This is a private project. You must be a member to view its contents.") and applying for membership could violate eLife's blind review process. So, this reviewer liked to but couldn't run the model her/himself. To eLife: Can the authors upload their model to a neutral server that reviewers and editors can access anonymously?
The code has been made publicly available on the following sites:
SimTK: https://simtk.org/docman/?group_id=2635
Zendo: https://zenodo.org/records/10403014
GitHub: https://github.com/mh2uk/ABM-of-Muscle-Regeneration-with-MicrovascularRemodeling
Line 121 has been updated with the new link and the additional resources were added to lines 654-657.
(2) The muscle regeneration field typically studies 2D cross-sections and the present model can be well compared to these other 2D models but cells as stochastic and localized sources of diffusible cytokines may yield different cytokine fields in 3D vs. 2D. I would expect more broadened and smoothened cytokine fields (from sources in neighboring cross-sections) than what the 2D model predicts based on sources just within the focus cross-section. Such relations of 2D to 3D should be discussed.
We thank the reviewer for the excellent suggestions and observations. It has been reported in other Compucell3D models (Sego et al. 2017, DOI:10.1088/17585090/aa6ed4) that the convergence of diffusion solutions between 2D and 3D model configurations had similar outcomes, with the 3D simulations presenting excessive computational cost without contributing any noticeable additional accuracy. Similarly, other cell-based ABMs that incorporate diffusion mechanisms (Marino et al. 2018, DOI:10.3390/computation6040058) have found that 2D and 3D versions of the model both predict the same mechanisms and that the 2D resolution was sufficient for determining outcomes. Lines 615-618 were added to elaborate on this topic.
(3) Since the model (and title) focuses on "nonlinear" cytokine interactions, what would change if cytokine decay would not be linear (as modeled here) but saturated (with nonlinear Michaelis-Menten kinetics as ligand binding and endocytosis mechanisms would call for)?
Thank you for raising an intriguing point. The model includes a combination of cytokine decay as well as ligand binding and endocytosis mechanisms that can be saturated. For a cytokine-dependent model behavior to occur the cytokines necessary to induce that action had to reach a minimum threshold. Once that threshold was reached, that amount of the cytokine would be removed at that location to simulate ligand-receptor binding and endocytosis. These ligand binding and endocytosis mechanisms behave in a saturated way, removing a set amount when above a certain threshold or a defined ratio when under the threshold. Lines 313-315 was revised to clarify this point. There were certain concentrations of cytokines where we saw a plateau in outputs likely as a result of reaching a saturation threshold (Supplemental Fig. 3). In future work, more robust mathematical simulation of binding kinetics of cytokines (e.g., using ODEs) could be included.
(4) Limitations of the model should be discussed together with an outlook for model refinement. For example, fiber alignment and ECM ultrastructure may require anisotropic diffusion. Many of the rate equations could be considered with saturation parameters etc. There are so many model assumptions. Please discuss which would be the most urgent model refinements and, to achieve these, which would be the most informative next experiments to perform.
We appreciate your thoughtful consideration of the model's limitations and the need for a comprehensive discussion on model refinements and potential future experiments. The future direction section was expanded to discuss additional possible model refinements (lines 635-643) and additional possible experiments for model validation (lines 630-634).
(5) It is not clear how the single spatial arrangement that is used affects the model predictions. E.g. now the damaged area surrounds the lymphatic vessel but what if the opposite corner was damaged and the lymphatic vessel is deep inside the healthy area?
Thank you for highlighting the importance of considering different spatial arrangements in the model and its potential impact on predictions. We previously tested model perturbations that included specifying the injury surrounding the lymphatic vessel versus on the side opposite the vessel. Since this paper focuses more on cytokine dynamics, we plan to include this perturbation, along with other injury alterations, in a follow-on paper. We added more context about this in the future efforts section lines 640-643.
(6) It seems that not only parameter values but also the initial values of most of the model components are unknown. The parameter estimation strategy does not seem to include the initial (spatial) distributions of collagen and cytokines and other model components. Please discuss how other (reasonable) initial values or spatial arrangements will affect model predictions.
We appreciate your thoughtful consideration of unknown initial values/spatial arrangements and their potential influence on predictions. Initial cytokine levels prior to injury had a low relative concentration compared to levels post injury and were assumed to be negligible. Initial spatial distribution of cytokines was not defined as initial spatial inputs (except in knockout simulations) but are secreted from cells (with baseline resident cell counts defined from the literature). The distribution of cytokines is an emergent behavior that results from the cell behaviors within the model. The collagen distribution is altered in response to clearance of necrosis by the immune cells (decreased collagen with necrosis removal) and subsequent secretion of collagen by fibroblasts. The secretion of collagen from fibroblast was included in the parameter estimation sweep (Supplemental Table 1).
We are working on further exploring the model sensitivity to altered spatial arrangements and have added this to the future directions section (lines 618-621), as well as provided Supplemental Figure 5 to demonstrate that model outcomes are similar with altered initial spatial arrangements.
(7) Many details of the CC3D implementation are missing: overall lattice size, interaction neighborhood order, and "temperature" of the Metropolis algorithm. Are the typical adhesion energy terms used in the CPM Hamiltonian and if so, then how are these parameter values estimated?
Thank you for bringing attention to the missing details regarding the CC3D implementation in our manuscript. We have included supplemental information providing greater detail for CPM implementation (Lines 808-854). We also added two additional supplemental tables for describing the requested CC3D implementation details (Supplemental Table 4) and adhesion energy terms (Supplemental Table 5).
(8) Extending the model analysis of combinations of altered cytokine properties, which temporal schedules of administration would be of interest, and how could the timing of multiple interventions improve outcomes? Such a discussion or even analysis would further underscore the usefulness of the model.
In response to your valuable suggestion, lines 558-562 were added to discuss the potential of using the model as a tool to perturb different cytokine combinations at varying timepoints throughout regeneration. In addition, this is also included in future work in lines 636-637.
(9) The CPM is only weakly motivated, just one sentence on lines 142-145 which mentions diffusion in a misleading way as the CPM just provides cells with a shape and mechanical interactions. The diffusion part is a feature of the hybrid CompuCell3D framework, not the CPM.
Thank you for bringing up this distinction. We removed the statement regarding diffusion and updated lines 143-146 to focus on CPM representation of cellular behavior and interactions. We also added a reference to supplemental text that includes additional details on CPM.
(10) On lines 258-261 it does not become clear how the described springs can direct fibroblasts towards areas of low-density collagen ECM. Are the lambdas dependent on collagen density?
Thank you for highlighting this area for clarification. The fibroblasts form links with low collagen density ECM and then are pulled towards those areas based on a constant lambda value. The links between the fibroblast and the ECM will only be made if the collagen is below a certain threshold. We added additional clarification to lines 260-264.
(11) On line 281, what does the last part in "Fibers...were regenerating but not fully apoptotic cells" mean? Maybe rephrase this.
The last of part of that line indicates that there were some fibers surrounding the main injury site that were damaged but still had healthy portions, indicating that they were impacted by the injury and are regenerating but did not become fully apoptotic like the fiber cells at the main site of injury. We rephrased this line to indicate that the nearby fibers were damaged but not fully apoptotic.
(12) Lines 290-293 describe interactions of cells and fields with localized structures (capillaries and lymphatic vessel). Please explain in more detail how "capillary agents...transport neutrophiles and monocytes" in the CPM model formalism. Are new cells added following rules? How is spatial crowding of the lattice around capillaries affecting these rules? Moreover, how can "lymphatic vessel...drain the nearby cytokines and cells"? How is this implemented in the CPM and how is "nearby" calculated? We appreciate your detailed inquiry into the interactions of cells and fields with localized structures. The neutrophils and monocytes are added to the simulation at the lattice sites above capillaries (within the cell layer Fig. 2B) and undergo chemotaxis up their respective gradients. The recruitment of the neutrophils and monocytes are randomly distributed among the healthy capillaries that do not have an immune cell at the capillary location (a modeling artifact that is a byproduct of only having one cell per lattice site). This approach helped to prevent an abundance of crowding at certain capillaries. Because immune cells in the simulation are sufficiently small, chemotactic gradients are sufficiently large, and the simulation space is sufficiently large, we do not see aggregation of recruited immune cells in the CPM.
The lymphatic vessel uptakes cytokines at lattice locations corresponding to the lymphatic vessel and will remove cells located in lattice sites neighboring the lymphatic vessel. In addition, we have included a rule in our ABM to encourage cells to migrate towards the lymphatic vessel utilizing CompuCell3D External Potential Plugin. The influence of this rule is inversely proportional to the distance of the cells to the lymphatic vessel.
We have updated lines 294-298 and 305-309 to include the above explanation.
(13) Tables 1-4 define migration speeds as agent rules but in the typical CPM, migration speed emerges from random displacements biased by chemotaxis and other effects (like the slope of the cytokine field). How was the speed implemented as a rule while it is typically observable in the model?
We appreciate your inquiry regarding the implementation of migration speeds. To determine the lambda parameters (Table 7) for each cell type, we tested each in a simplified control simulation with a concentration gradient for the cell to move towards. We tuned the lambda parameters within this simulation until the model outputted cell velocity aligned with the literature reported cell velocity for each cell type (Tables 1-4). We have incorporated clarification on this to lines 177-180.
(14) Line 312 shows the first equation with number (5), either add eqn. (1-4) or renumber.
We have revised the equation number.
(15) Typos: Line 456, "expect M1 cell" should read "except M1 cell".
Line 452, "thresholds above that diminish fibroblast response (Supplemental Fig 3)." remains unclear, please rephrase.
Line 473, "at 28." should read "at 28 days.".
Line 474, is "additive" correct? Was the sum of the individual effects calculated and did that match?
Line 534, "complexity our model" should read "complexity in our model".
We have corrected the typos and clarified line 452 (updated line 594) to indicate that the TNF-α concentration threshold results in diminished fibroblast response. We updated terminology line 474 (updated line 512) to indicate that there was a synergistic effect with the combined perturbation.
(16) Table 7 defines cell target volumes with the same value as their diameter. This enforces a strange cell shape. Should there be brackets to square the value of the cell diameter, e.g. Value=(12µm)^2 ?
The target volume parameter values were selected to reflect the relative differences in average cell diameter as reported in the literature; however, there are no parameters that directly enforce a diameter for the cells in the CPM formalism separate from the volume. We have observed that these relative cell sizes allow the ABM to effectively reproduce cell behaviors described in the literature. Single cells that are too large in the ABM would be unable to migrate far enough per time step to carry out cell behaviors, and cells that are too small in the CPM would be unstable in the simulation environment and not persist in the simulation when they should. We removed the units for the cell shape values in Table 7 since the target volume is a relative parameter and does not directly represent µm.
(17) Table 7 gives estimated diffusion constants but they appear to be too high. Please compare them to measured values in the literature, especially for MCP-1, TNF-alpha and IL-10, or relate these to their molecular mass and compare to other molecules like FGF8 (Yu et al. 2009, DOI:10.1038/nature08391).
We utilized a previously published estimation method (Filion et al. 2004, DOI:10.1152/ajpheart.00205.2004) for estimating cytokine diffusivity within the ECM. This method incorporates the molecular masses and accounts for the combined effects of the collagen fibers and glycosaminoglycans. The paper acknowledged that the estimated value is faster than experimentally determined values, but that this was a result of the less-dense matrix composition which is more reflective of the tissue environment we are simulating in contrast to other reported measurements which were done in different environments. Using this estimation method also allowed us to more consistently define diffusion constants versus using values from the literature (which were often not recorded) that had varied experimental conditions and techniques (such as being in zebrafish embryo Yu et al. 2009, DOI:10.1038/nature08391 as opposed to muscle tissue). This also allowed for recalculation of the diffusivity throughout the simulation as the collagen density changed within the model. Lines 318-326 were updated to help clarify the estimation method.
(18) Many DOIs in the bibliography (Refs. 7,17,20,31,40,47...153) are wrong and do not resolve because the appended directory names are not allowed in the DOI, just with a journal's URL after resolution.
Thank you for bringing this to our attention. The incorrect DOIs have been corrected.
Reviewer #2 (Recommendations For The Authors):
Minor comments:
(9) On line 174, the authors say "We used the CC3D feature Flip2DimRatio to control the number of times the Cellular-Potts algorithm runs per mcs." What does this mean? Isn't one monte carlo timestep one iteration of the Cellular Potts model? How does this relate to physical timescales?
We appreciate your attention to detail and thoughtful question regarding the statement about the use of the CC3D feature Flip2DimRatio. Lines 175-177 were revised to simplify the meaning of Flip2DimRatio. That parameter alters the number of times the Cellular-Potts algorithm is run, which is the limiting factor for cell movement. The physical timescale is kept to a 15-minute timestep but a high Flip2DimRatio allows more flexibility and stability to allow the cells to move faster in one timestep.
(10) Has the costum matlab script to process histology images into initial conditions been made available?
The Matlab script along with CC3D code for histology initialization with documentation has been made available with the source code on the following sites:
SimTK: https://simtk.org/docman/?group_id=2635
Zendo: https://zenodo.org/records/10403014
GitHub: https://github.com/mh2uk/ABM-of-Muscle-Regeneration-with-MicrovascularRemodeling
(11) Equation 5 is provided without a reference or derivation. Where does it come from and what does it mean?
Thank you for highlighting the diffusion equation and seeking clarification on its origin and significance. Lines 318-326 were revised to clarify where the equation comes from. This is a previously published estimation method that we applied to calculate the diffusivity of the cytokines considering both collagen and glycosaminoglycans.
(12) Line 326: "For CSA, experimental fold-change from pre-injury was compared with fold-change in model-simulated CSA". Does this step rely on the assumption that the fold change will not depend on the CSA? If so, is this something that is experimentally known, or otherwise, can it be confirmed by simulations?
We appreciate the opportunity to clarify our rationale. The fold change was used as a method to normalize the model and experiment so that they could be compared on the same scale. Yes, this step relies on the assumption that fold change does not depend on pre-injury CSA. Experimentally it is difficult to determine the impact of initial fiber morphology on altered regeneration time course. This fold-change allows us to compare percent recovery which is a common metric utilized to assess muscle regeneration outcomes experimentally. Line 340-343 was revised to clarify.
(13) Line 355: "The final passing criteria were set to be within 1 SD for CSA recovery and 2.5 SD for SSC and fibroblast count" Does this refer to the experimental or the simulated SD?
The model had to fit within those experimental SD. Lines 371-372 was edited to specify that we are referring the experimental SD.
(14) "Following 8 iterations of narrowing the parameter space with CaliPro, we reached a set that had fewer passing runs than the previous iteration". Wouldn't one expect fewer passing runs with any narrowing of the parameter space? Why was this chosen as the stopping criterion for further narrowing?
We appreciate your observation regarding the statement about narrowing the parameter space with CaliPro. We started with a wide parameter space, expecting that certain parameters would give outputs that fall outside of the comparable data. So, when the parameter space was narrowed to enrich parts that give passing output, initially the number of passing simulations increased.
Once we have narrowed the set of possible parameters into an ideal parameter space, further narrowing will cut out viable parameters resulting in fewer passing runs. Therefore, we stopped narrowing once any fewer simulations passed the criteria that they had previously passed with the wider parameter set. Lines 375-379 have been updated to clarify this point.
(15) Line 516: 'Our model could test and optimize combinations of cytokines, guiding future experiments and treatments." It is my understanding that this is communicated as a main strength of the model. Would it be possible to demonstrate that the sentence is true by using the model to make actual predictions for experiments or treatments?
This is demonstrated by the combined cytokine alterations in Figure 7 and discussed in lines 509-513. We have also added in a suggested experiment to test the model prediction in lines 691-695.
(16) Line 456, typo: I think 'expect' should be 'except'.
Thank you for pointing that out. The typo has been corrected.
-
-
www.youtube.com www.youtube.com
-
Résumé de la vidéo [00:14:07][^1^][1] - [00:37:04][^2^][2]:
Cette vidéo présente une conférence sur le rôle de l'école en tant que territoire vivant au cœur des valeurs de la République. Les intervenants discutent de l'importance de l'école dans la transmission des valeurs républicaines, surtout dans le contexte des événements récents qui ont touché l'académie.
Points forts: + [00:14:07][^3^][3] Introduction de la conférence * Accueil par Sébastien Jaibovski, directeur de l'INSP de l'académie de Lille * Présentation du programme et des intervenants * Contextualisation de la conférence dans les événements actuels + [00:17:01][^4^][4] Allocution d'Alain Frugère * Importance de partager et transmettre les valeurs de liberté, égalité et fraternité * Rappel historique des valeurs républicaines depuis la Révolution française * Nécessité de défendre ces valeurs face aux défis contemporains + [00:23:02][^5^][5] Intervention de Madame Lower * L'école comme vecteur de l'égalité des chances et de la lutte contre les inégalités * Rôle de l'école dans la reconnaissance de la capacité de tous les enfants à apprendre * Importance de la liberté d'éducation pour l'émancipation individuelle + [00:30:03][^6^][6] Contextualisation par Sébastien Jaibovski * L'école face au poids des attentes sociales et symboliques * Réflexion sur le rôle des institutions publiques et les moyens alloués * L'école comme lieu de partage et de construction de la citoyenneté Résumé de la vidéo [00:37:07][^1^][1] - [01:02:26][^2^][2]:
Cette partie de la vidéo aborde le rôle de l'école dans la transmission des valeurs républicaines, en mettant l'accent sur une approche citoyenne. Elle souligne l'importance de l'éducation aux valeurs comme fondement de la République et la nécessité d'une pédagogie qui favorise la pensée critique et la participation active des élèves.
Points forts: + [00:37:07][^3^][3] L'importance de l'éducation aux valeurs * L'école comme lieu de découverte et de compréhension des valeurs républicaines * La transmission des valeurs comme mission centrale de l'institution scolaire * Les valeurs de liberté, égalité, fraternité, laïcité et refus des discriminations + [00:47:00][^4^][4] Approche citoyenne des valeurs * Refus de l'inculcation, éducation à la liberté * Appel à la pensée critique et à l'interrogation des valeurs * Importance de l'expérience vécue des valeurs dans l'établissement scolaire + [00:57:00][^5^][5] Engagement dans la République * La valeur comme refus du réel et espace pour l'engagement * L'écart entre les valeurs et le réel comme opportunité d'action * L'importance de l'engagement citoyen de chacun dans l'éducation aux valeurs Résumé de la vidéo 01:02:28 - 01:25:00 : La vidéo explore l'évolution de la notion des valeurs de la République dans le discours public, les médias, et le droit français depuis les années 80. Elle examine l'augmentation significative de l'utilisation de cette notion dans les années 80 et 90, sa stabilisation dans les années 2010, et son absence de définition constitutionnelle. La vidéo souligne également l'importance de l'éducation à la laïcité dans les écoles françaises et comment elle est abordée dans les programmes scolaires.
Points saillants : + [01:02:28][^1^][1] L'évolution de la notion des valeurs de la République * Augmentation dans les publications et les médias depuis les années 80 * Stabilisation dans les années 2010 * Absence de définition constitutionnelle + [01:06:02][^2^][2] L'impact sur le droit de l'éducation et le droit des étrangers * Contribution significative du code de l'éducation et du droit des étrangers * Importance de l'apprentissage et de l'intégration des valeurs + [01:10:01][^3^][3] La définition et l'enseignement de la laïcité * Présence accrue dans les programmes scolaires depuis les années 80 * Nécessité d'expliquer les règles aux élèves * Approche pédagogique pour déconstruire les oppositions + [01:18:34][^4^][4] La perception et la compréhension des élèves sur la laïcité * Bonne maîtrise de la notion par les élèves * Importance de l'éducation à la laïcité pour une société inclusive Résumé de la vidéo [01:25:02][^1^][1] - [01:38:50][^2^][2] :
Cette partie de la vidéo aborde l'importance de l'éducation à la laïcité et aux valeurs de la République dans les écoles françaises, y compris celles à l'étranger. Elle souligne les défis culturels et les différences dans l'approche de l'enseignement des valeurs universelles.
Points forts : + [01:25:02][^3^][3] La laïcité dans l'éducation * La laïcité n'est pas une hostilité envers les croyances religieuses * Importance de partager une vision positive de la laïcité * Nécessité d'adapter l'enseignement aux contextes culturels variés + [01:30:10][^4^][4] L'approche citoyenne à l'école * Utilisation de la pensée critique et de la liberté * Transformation des valeurs en réalité concrète pour les élèves * Engagement des élèves envers les valeurs de la République + [01:35:00][^5^][5] L'école, un territoire vivant * L'école est un lieu d'échange et d'apprentissage actif des valeurs républicaines * L'actualité influence l'enseignement et la perception des valeurs * L'importance de l'équilibre entre idéal et réalité dans l'éducation
Tags
Annotators
URL
-
-
www.wheresyoured.at www.wheresyoured.at
-
Five months later, a little over a year after the Code Yellow debacle, Google would make Prabhakar Raghavan the head of Google Search
author mentions this as the locking in of rotting google search.
-
n the March 2019 core update to search, which happened about a week before the end of the code yellow, was expected to be “one of the largest updates to search in a very long time. Yet when it launched, many found that the update mostly rolled back changes, and traffic was increasing to sites that had previously been suppressed by Google Search’s “Penguin” update from 2012 that specifically targeted spammy search results, as well as those hit by an update from an August 1, 2018, a few months after Gomes became Head of Search.
The start of Google search decreasing effectiveness
Tags
Annotators
URL
-
-
social-media-ethics-automation.github.io social-media-ethics-automation.github.io
-
k12 Daisuke Wakabayashi and Sapna Maheshwari. Advertisers Boycott YouTube After Pedophiles Swarm Comments on Videos of Children. The New York Times, February 2019. URL: https://www.nytimes.com/2019/02/20/technology/youtube-pedophiles.html (visited on 2023-12-07)
After reading this article I was reminded of assignment 3 where we did bot trolling and I thought of how difficult it would be to code to catch for people not obeying user policies. For instance the comments weren't blatantly explicit, commenting sexually inappropriate comments, but they would contain a string of sexually suggestive emoji or insinuate some form of sexual abuse. At this rate, making sure your platform is safe for children would be extremely difficult. The way we coded the automatic response in assignment 3, we had it recognize a specific sentence but harassment is a spectrum and it's intepreted a lot of the time (making it difficult to detect).
-
-
two-wrongs.com two-wrongs.com
-
We often think of software development as a ticket-in-code-out business but this is really only a very small portion of the entire thing. Completely independently of the work done as a programmer, there exists users with different jobs they are trying to perform, and they may or may not find it convenient to slot our software into that job. A manager is not necessarily the right person to evaluate how good a job we are doing because they also exist independently of the user–software–programmer network, and have their own sets of priorities which may or may not align with the rest of the system.
Software development as a conversation
-
-
scalar.lafayette.edu scalar.lafayette.edu
-
The Forest Code
Scherer, Glenn. “Brazil’s New Forest Code Puts Vast Areas of Protected Amazon Forest at Risk.” Mongabay Environmental News, July 18, 2019. https://news.mongabay.com/2019/03/brazils-new-forest-code-puts-vast-areas-of-protected-amazon-forest-at-risk/.
-
-
scalar.lafayette.edu scalar.lafayette.edu
-
government
The Nature Conservancy. “Brazil’s Forest Code,” July 1, 2018. https://www.nature.org/en-us/about-us/where-we-work/latin-america/brazil/stories-in-brazil/brazils-forest-code/.
-
-
www.duckofminerva.com www.duckofminerva.com
-
Quantification is ultimately linguistic: it is a form of translation. Most of our descriptions start as ‘ordinary language’, and in some cases, we ‘code’ those descriptions using numbers rather than words
So you do not think physical quantities exist out of our mind?
-
-
www.theherbalistspath.com www.theherbalistspath.com
-
With Code FIRSTAID
And remove the code because it should link to the discounted checkout cart, right?
-
-
pressbooks.library.torontomu.ca pressbooks.library.torontomu.ca
-
shorthand
a way of writing kind of like morse code
-
-
www.biorxiv.org www.biorxiv.org
-
Author response:
The following is the authors’ response to the original reviews.
Editor’s summary:
This paper by Castello-Serrano et al. addresses the role of lipid rafts in trafficking in the secretory pathway. By performing carefully controlled experiments with synthetic membrane proteins derived from the transmembrane region of LAT, the authors describe, model and quantify the importance of transmembrane domains in the kinetics of trafficking of a protein through the cell. Their data suggest affinity for ordered domains influences the kinetics of exit from the Golgi. Additional microscopy data suggest that lipid-driven partitioning might segregate Golgi membranes into domains. However, the relationship between the partitioning of the synthetic membrane proteins into ordered domains visualised ex vivo in GPMVs, and the domains in the TGN, remain at best correlative. Additional experiments that relate to the existence and nature of domains at the TGN are necessary to provide a direct connection between the phase partitioning capability of the transmembrane regions of membrane proteins and the sorting potential of this phenomenon.
The authors have used the RUSH system to study the traffic of model secretory proteins containing single-pass transmembrane domains that confer defined affinities for liquid ordered (lo) phases in Giant Plasma Membrane derived Vesicles (GPMVs), out of the ER and Golgi. A native protein termed LAT partitioned into these lo-domains, unlike a synthetic model protein termed LAT-allL, which had a substituted transmembrane domain. The authors experiments provide support for the idea that ER exit relies on motifs in the cytosolic tails, but that accelerated Golgi exit is correlated with lo domain partitioning.
Additional experiments provided evidence for segregation of Golgi membranes into coexisting lipid-driven domains that potentially concentrate different proteins. Their inference is that lipid rafts play an important role in Golgi exit. While this is an attractive idea, the experiments described in this manuscript do not provide a convincing argument one way or the other. It does however revive the discussion about the relationship between the potential for phase partitioning and its influence on membrane traffic.
We thank the editors and scientific reviewers for thorough evaluation of our manuscript and for positive feedback. While we agree that our experimental findings present a correlation between trafficking rates and raft affinity, in our view, the synthetic, minimal nature of the transmembrane protein constructs in question makes a strong argument for involvement of membrane domains in their trafficking. These constructs have no known sorting determinants and are unlikely to interact directly with trafficking proteins in cells, since they contain almost no extramembrane amino acids. Yet, the LATTMD traffics through Golgi similarly to the full-length LAT protein, but quite different from mutants with lower raft phase affinity. We suggest that these observations can be best rationalized by involvement of raft domains in the trafficking fates and rates of these constructs, providing strong evidence (beyond a simple correlation) for the existence and relevance of such domains.
We have substantially revised the manuscript to address all reviewer comments, including several new experiments and analyses. These revisions have substantially improved the manuscript without changing any of the core conclusions and we are pleased to have this version considered as the “version of record” in eLife.
Below is our point-by-point response to all reviewer comments.
ER exit:
The experiments conducted to identify an ER exit motif in the C-terminal domain of LAT are straightforward and convincing. This is also consistent with available literature. The authors should comment on whether the conservation of the putative COPII association motif (detailed in Fig. 2A) is significantly higher than that of other parts of the C-terminal domain.
Thank you for this suggestion, this information has now been included as Supp Fig 2B. While there are other wellconserved residues of the LAT C-terminus, many regions have relatively low conservation. In contrast, the essential residues of the COPII association motif (P148 and A150) are completely conserved across in LAT across all species analyzed.
One cause of concern is that addition of a short cytoplasmic domain from LAT is sufficient to drive ER exit, and in its absence the synthetic constructs are all very slow. However, the argument presented that specific lo phase partitioning behaviour of the TMDs do not have a significant effect on exit from the ER is a little confusing. This is related to the choice of the allL-TMD as the 'non-lo domain' partitioning comparator. Previous data has shown that longer TMDs (23+) promote ER export (eg. Munro 91, Munro 95, Sharpe 2005). The mechanism for this is not, to my knowledge, known. One could postulate that it has something to do with the very subject of this manuscript- lipid phase partitioning. If this is the case, then a TMD length of 22 might be a poor choice of comparison. A TMD 17 Ls' long would be a more appropriate 'non-raft' cargo. It would be interesting to see a couple of experiments with a cargo like this.
The basis for the claim that raft affinity has relatively minor influence on ER exit kinetics, especially in comparison to the effect of the putative COPII interaction motif, is in Fig 1G. We do observe some differences between constructs and they may be related to raft affinity, however we considered these relatively minor compared to the nearly 4-fold increase in ER efflux induced by COPII motifs.
We have modified the wording in the manuscript to avoid the impression that we have ruled out an effect of raft affinity of ER exit.
We believe that our observations are broadly consistent with those of Munro and colleagues. In both their work and ours, long TMDs were able to exit the ER. In our experiments, this was true for several proteins with long TMDs, either as fulllength or as TMD-only versions (see Fig 1G). We intentionally did not measure shorter synthetic TMDs because these would not have been comparable with the raft-preferring variants, which all require relatively long TMDs, as demonstrated in our previous work1,2. Thus, because our manuscript does not make any claims about the influence of TMD length on trafficking, we did not feel that experiments with shorter non-raft constructs would substantively influence our conclusions.
However, to address reviewer interest, we did complete one set of experiments to test the effect of shortening the TMD on ER exit. We truncated the native LAT TMD by removing 6 residues from the C-terminal end of the TMD (LAT-TMDd6aa). This construct exited the ER similarly to all others we measured, revealing that for this set of constructs, short TMDs did not accumulate in the ER. ER exit of the truncated variant was slightly slower than the full-length LAT-TMD, but somewhat faster than the allL-TMD. These effects are consistent with our previous measurements with showed that this shortened construct has slightly lower raft phase partitioning than the LAT-TMD but higher than allL2. While these are interesting observations, a more thorough exploration of the effect of TMD length would be required to make any strong conclusion, so we did not include these data in the final manuscript.
Author response image 1.

Golgi exit:
For the LAT constructs, the kinetics of Golgi exit as shown in Fig. 3B are surprisingly slow. About half of the protein Remains in the Golgi at 1 h after biotin addition. Most secretory cargo proteins would have almost completely exited the Golgi by that time, as illustrated by VSVG in Fig. S3. There is a concern that LAT may have some tendency to linger in the Golgi, presumably due to a factor independent of the transmembrane domain, and therefore cannot be viewed as a good model protein. For kinetic modeling in particular, the existence of such an additional factor would be far from ideal. A valuable control would be to examine the Golgi exit kinetics of at least one additional secretory cargo.
We disagree that LAT is an unusual protein with respect to Golgi efflux kinetics. In our experiments, Golgi efflux of VSVG was similar to full-length LAT (t1/2 ~ 45 min), and both of these were similar to previously reported values3. Especially for the truncated (i.e. TMD) constructs, it is very unlikely that some factor independent of their TMDs affects Golgi exit, as they contain almost no amino acids outside the membrane-embedded TMD.
Practically, it has proven somewhat challenging to produce functional RUSH-Golgi constructs. We attempted the experiment suggested by the reviewer by constructing SBP-tagged versions of several model cargo proteins, but all failed to trap in the Golgi. We speculate that the Golgin84 hook is much more sensitive to the location of the SBP on the cargo, being an integral membrane protein rather than the lumenal KDEL-streptavidin hook. This limitation can likely be overcome by engineering the cargo, but we did not feel that another control cargo protein was essential for the conclusions we presented, thus we did not pursue this direction further.
Comments about the trafficking model
(1) In Figure 1E, the export of LAT-TMD from the ER is fitted to a single-exponential fit that the authors say is "well described". This is unclear and there is perhaps something more complex going on. It appears that there is an initial lag phase and then similar kinetics after that - perhaps the authors can comment on this?
This is a good observation. This effect is explainable by the mechanics of the measurement: in Figs 1 and 2, we measure not ‘fraction of protein in ER’ but ‘fraction of cells positive for ER fluorescence’. This is because the very slow ER exit of the TMD-only constructs present a major challenge for live-cell imaging, so ER exit was quantified on a population level, by fixing cells at various time points after biotin addition and quantifying the fraction of cells with observable ER localization (rather than tracking a single cell over time).
For fitting to the kinetic model (which attempts to describe ‘fraction in ER/Golgi’) we re-measured all constructs by livecell imaging (see Supp Fig 5) to directly quantify relative construct abundance in the ER or Golgi. These data did not have the plateau in Fig 1E, suggesting that this is an artifact of counting “ER positive cells” which would be expected to have a longer lag than “fraction of protein in ER”. Notably however, t1/2 measured by both methods was similar, suggesting that the population measurement agrees well with single-cell live imaging.
We have included all these explanations and caveats in the manuscript. We have also changed the wording from “well described” to “reasonably approximated”.
(2) The model for Golgi sorting is also complicated and controversial, and while the authors' intention to not overinterpreting their data in this regard must be respected, this data is in support of the two-phase Golgi export model (Patterson et al PMID:18555781).
The reviewers are correct, our observations and model are consistent with Patterson et al and it was a major oversight that a reference to this foundational work was not included. We have now added a discussion regarding the “two phase model” of Patterson and Lippincott-Schwartz.
Furthermore contrary to the statement in lines 200-202, the kinetics of VSVG exit from the Golgi (Fig. S3) are roughly linear and so are NOT consistent with the previous report by Hirschberg et al.
Regarding kinetics of VSVG, our intention was to claim that the timescale of VSVG efflux from the Golgi was similar to previously reported in Hirschberg, i.e. t1/2 roughly between 30-60 minutes. We have clarified this in the text. Minor differences in the details between our observations and Hirschberg are likely attributable to temperature, as those measurements were done at 32°C for the tsVSVG mutant.
Moreover, the kinetics of LAT export from the Golgi (Fig. 3B) appear quite different, more closely approximating exponential decay of the signal. These points should be described accurately and discussed.
Regarding linear versus exponential fits, we agree that the reality of Golgi sorting and efflux is far more complicated than accounted for by either the phenomenological curve fitting in Figs 1-3 or the modeling in Fig 4. In addition to the possibility of lateral domains within Golgi stacks, there is transport between stacks, retrograde traffic, etc. The fits in Figs 1-3 are not intended to model specifics of transport, but rather to be phenomenological descriptors that allowed us to describe efflux kinetics with one parameter (i.e. t1/2). In contrast, the more refined kinetic modeling presented in Figure 4 is designed to test a mechanistic hypothesis (i.e. coexisting membrane domains in Golgi) and describes well the key features of the trafficking data.
Relationship between membrane traffic and domain partitioning:
(1) Phase segregation in the GPMV is dictated by thermodynamics given its composition and the measurement temperature (at low temperatures 4degC). However at physiological temperatures (32-37degC) at which membrane trafficking is taking place these GPMVs are not phase separated. Hence it is difficult to argue that a sorting mechanism based solely on the partitioning of the synthetic LAT-TMD constructs into lo domains detected at low temperatures in GPMVs provide a basis (or its lack) for the differential kinetics of traffic of out of the Golgi (or ER). The mechanism in a living cell to form any lipid based sorting platforms naturally requires further elaboration, and by definition cannot resemble the lo domains generated in GPMVs at low temperatures.
We thank the reviewers for bringing up this important point. GPMVs are a useful tool because they allow direct, quantitative measurements of protein partitioning between coexisting ordered and disordered phases in complex, cell-derived membranes. However, we entirely agree, that GPMVs do not fully represent the native organization of the living cell plasma membrane and we have previously discussed some of the relevant differences4,5. Despite these caveats, many studies have supported the cellular relevance of phase separation in GPMVs and the partitioning of proteins to raft domains therein 6-9. Most notably, elegant experiments from several independent labs have shown that fluorescent lipid analogs that partition to Lo domains in GPMVs also show distinct diffusive behaviors in live cells 6,7, strongly suggesting the presence of nanoscopic Lo domains in live cells. Similarly, our recent collaborative work with the lab of Sarah Veatch showed excellent agreement between raft preference in GPMVs and protein organization in living immune cells imaged by super-resolution microscopy10. Further, several labs6,7, including ours11, have reported nice correlations between raft partitioning in GPMVs and detergent resistance, which is a classical (though controversial) assay for raft association.
Based on these points, we feel that GPMVs are a useful tool for quantifying protein preference for ordered (raft) membrane domains and that this preference is a useful proxy for the raft-associated behavior of these probes in living cells. We propose that this approach allows us to overcome a major reason for the historical controversy surrounding the raft field: nonquantitative and unreliable methodologies that prevented consistent definition of which proteins are supposed to be present in lipid rafts and why. Our work directly addresses this limitation by relating quantitative raft affinity measurements in a biological membrane with a relevant and measurable cellular outcome, specifically inter-organelle trafficking rates.
Addressing the point about phase transition temperatures in GPMVs: this is the temperature at which macroscopic domains are observed. Based on physical models of phase separation, it has been proposed that macroscopic phase separation at lower temperatures is consistent sub-microscopic, nanoscale domains at higher temperatures8,12. These smaller domains can potentially be stabilized / functionalized by protein-protein interactions in cells13 that may not be present in GPMVs (e.g. because of lack of ATP).
(2) The lipid compositions of each of these membranes - PM, ER and Golgi are drastically different. Each is likely to phase separate at different phase transition temperatures (if at all). The transition temperature is probably even lower for Golgi and the ER membranes compared to the PM. Hence, if the reported compositions of these compartments are to be taken at face value, the propensity to form phase separated domains at a physiological temperature will be very low. Are ordered domains even formed at the Golgi at physiological temperatures?
It is a good point that the membrane compositions and the resulting physical properties (including any potential phase behavior) will be very different in the PM, ER, and Golgi. Whether ordered domains are present in any of these membranes in living cells remains difficult to directly visualize, especially for non-PM membranes which are not easily accessible by probes, are nanoscopic, and have complex morphologies. However, the fact that raft-preferring probes / proteins share some trafficking characteristics, while very similar non-raft mutants behave differently argues that raft affinity plays a role in subcellular traffic.
(3) The hypothesis of 'lipid rafts' is a very specific idea, related to functional segregation, and the underlying basis for domain formation has been also hotly debated. In this article the authors conflate thermodynamic phase separation mechanisms with the potential formation of functional sorting domains, further adding to the confusion in the literature. To conclude that this segregation is indeed based on lipid environments of varying degrees of lipid order, it would probably be best to look at the heterogeneity of the various membranes directly using probes designed to measure lipid packing, and then look for colocalization of domains of different cargo with these domains.
This is a very good suggestion, and a direction we are currently following. Unfortunately, due to the dynamic nature and small size of putative lateral membrane domains, combined with the interior of a cell being filled with lipophilic environments that overlay each other, directly imaging domains in organellar membranes with lipid packing probes remains extremely difficult with current technology (or at least available to us). We argue that the TMD probes used in this manuscript are a reasonable alternative, as they are fluorescent probes with validated selectivity for membrane compartments with different physical properties.
Ultimately, the features of membrane domains suggested by a variety of techniques – i.e. nanometric, dynamic, relatively similar in composition to the surrounding membrane, potentially diverse/heterogeneous – make them inherently difficult to microscopically visualize. This is one reason why we believe studies like ours, which use a natural model system to directly quantify raft-associated behaviors and relate them to cellular effects (in our case, protein sorting), are a useful direction for this field.
We believe we have been careful in our manuscript to avoid confusing language surrounding lipid rafts, phase separation, etc. Our experiments clearly show that mammalian membranes have the capacity to phase separate, that some proteins preferentially interact with more ordered domains, and that this preference is related to the subcellular trafficking fates and rates of these proteins. We have edited the manuscript to emphasize these claims and avoid the historical controversies and confusions.
(4) In the super-resolution experiments (by SIM- where the enhancement of resolution is around two fold or less compared to optical), the authors are able to discern a segregation of the two types of Golgi-resident cargo that have different preferences for the lo-domains in GPMVs. It should be noted that TMD-allL and the LATallL end up in the late endosome after exit of the Golgi. Previous work from the Bonafacino laboratory (PMID: 28978644) has shown that proteins (such as M6PR) destined to go to the late endosome bud from a different part of the Golgi in vesicular carriers, while those that are destined for the cell surface first (including TfR) bud with tubular vesicular carriers. Thus at the resolution depicted in Fig 5, the segregation seen by the authors could be due to an alternative explanation, that these molecules are present in different areas of the Golgi for reasons different from phase partitioning. The relatively high colocalization of TfR with the GPI probe in Fig 5E is consistent with this explanation. TfR and GPI prefer different domains in the GPMV assays yet they show a high degree of colocalization and also traffic to the cell surface.
This is a good point. Even at microscopic resolutions beyond the optical diffraction limit, we cannot make any strong claims that the segregation we observe is due to lateral lipid domains and not several reasonable alternatives, including separation between cisternae (rather than within), cargo vesicles moving between cisternae, or lateral domains that are mediated by protein assemblies rather than lipids. We have explicitly included this point in the Discussion: “Our SIM imaging suggests segregation of raft from nonraft cargo in the Golgi shortly (5 min) after RUSH release (Fig 5B), but at this level of resolution, we can only report reduced colocalization, not intra-Golgi protein distributions. Moreover, segregation within a Golgi cisterna would be very difficult to distinguish from cargo moving between cisternae at different rates or exiting via Golgi-proximal vesicles.”
We have also added a similar caveat in the Results section of the manuscript: “These observations support the hypothesis that proteins can segregate in Golgi based on their affinity for distinct membrane domains; however, it is important to emphasize that this segregation does not necessarily imply lateral lipid-driven domains within a Golgi cisterna. Reasonable alternative possibilities include separation between cisternae (rather than within), cargo vesicles moving between cisternae, or lateral domains that are mediated by protein assemblies rather than lipids.”
Finally, while probes with allL TMD do eventually end up in late endosomes (consistent with the Bonifacino lab’s findings which we include), they do so while initially transiting the PM2,11.
Minor concerns:
(1) Generally, the quantitation is high quality from difficult experimental data. Although a lot appears to be manual, it appears appropriately performed and interpreted. There are some claims that are made based on this quantitation, however, where there are no statistics performed. For example, figure 1B. Any quantitation with an accompanying conclusion should be subject to a statistical test. I think the quality of the model fits- this is particularly important.
We appreciate the thoughtful feedback, the quantifications and fits were not trivial, but we believe important. We have added statistical significance to Figure 1B and others where it was missing.
(2) Modulation of lipid levels in Fig 4E shows a significant change for the trafficking rate for the LAT-TMD construct and a not so significant change for all-TMD construct. However, these data are not convincing and appear to depend on a singular data point that appears to lower the mean value. In general, the experiment with the MZA inhibitor (Fig. 4D-F) is hard to interpret because cells will likely be sick after inhibition of sphingolipid and cholesterol synthesis. Moreover, the difference in effects for LAT-TMD and allL-TMD is marginal.
We disagree with this interpretation. Fig 4E shows the average of three experiments and demonstrates clearly that the inhibitors change the Golgi efflux rate of LAT-TMD but not allL-TMD. This is summarized in the t1/2 quantifications of Fig 4F, which show a statistically significant change for LAT-TMD but not allL-TMD. This is not an effect of a singular data point, but rather the trend across the dataset.
Further, the inhibitor conditions were tuned carefully to avoid cells becoming “sick”: at higher concentrations, cells did adopt unusual morphologies and began to detach from the plates. We pursued only lower concentrations, which cells survived for at least 48 hrs and without major morphological changes.
(3) Line 173: 146-AAPSA-152 should read either 146-AAPSA-150 or 146-AAPSAPA-152, depending on what the authors intended.
Thanks for the careful reading, we intended the former and it has been fixed.
(4) What is the actual statistical significance in Fig. 3C and Fig. 3E? There is a single asterisk in each panel of the figure but two asterisks in the legend.
Apologies, a single asterisk representing p<0.05 was intended. It has been fixed.
(5) The code used to calculate the model. is not accessible. It is standard practice to host well-annotated code on Github or similar, and it would be good to have this publicly available.
We have deposited the code on a public repository (doi: 10.5281/zenodo. 10478607) and added a note to the Methods.
(1) Lorent, J. H. et al. Structural determinants and func7onal consequences of protein affinity for membrane ra=s. Nature communica/ons 8, 1219 (2017).PMC5663905
(2) Diaz-Rohrer, B. B., Levental, K. R., Simons, K. & Levental, I. Membrane ra= associa7on is a determinant of plasma membrane localiza7on. Proc Natl Acad Sci U S A 111, 8500-8505 (2014).PMC4060687
(3) Hirschberg, K. et al. Kine7c analysis of secretory protein traffic and characteriza7on of golgi to plasma membrane transport intermediates in living cells. J Cell Biol 143, 1485-1503 (1998).PMC2132993
(4) Levental, K. R. & Levental, I. Giant plasma membrane vesicles: models for understanding membrane organiza7on. Current topics in membranes 75, 25-57 (2015)
(5) Sezgin, E. et al. Elucida7ng membrane structure and protein behavior using giant plasma membrane vesicles. Nat Protoc 7, 1042-1051 (2012)
(6) Komura, N. et al. Ra=-based interac7ons of gangliosides with a GPI-anchored receptor. Nat Chem Biol 12, 402-410 (2016)
(7) Kinoshita, M. et al. Ra=-based sphingomyelin interac7ons revealed by new fluorescent sphingomyelin analogs. J Cell Biol 216, 1183-1204 (2017).PMC5379944
(8) Stone, M. B., Shelby, S. A., Nunez, M. F., Wisser, K. & Veatch, S. L. Protein sor7ng by lipid phase-like domains supports emergent signaling func7on in B lymphocyte plasma membranes. eLife 6 (2017).PMC5373823
(9) Machta, B. B. et al. Condi7ons that Stabilize Membrane Domains Also Antagonize n-Alcohol Anesthesia. Biophys J 111, 537-545 (2016)
(10) Shelby, S. A., Castello-Serrano, I., Wisser, I., Levental, I. & S., V. Membrane phase separa7on drives protein organiza7on at BCR clusters. Nat Chem Biol in press (2023)
(11) Diaz-Rohrer, B. et al. Rab3 mediates a pathway for endocy7c sor7ng and plasma membrane recycling of ordered microdomains Proc Natl Acad Sci U S A 120, e2207461120 (2023)
(12) Veatch, S. L. et al. Cri7cal fluctua7ons in plasma membrane vesicles. ACS Chem Biol 3, 287-293 (2008)
(13) Wang, H. Y. et al. Coupling of protein condensates to ordered lipid domains determines func7onal membrane organiza7on. Science advances 9, eadf6205 (2023).PMC10132753
-
-
teachbooks.tudelft.nl teachbooks.tudelft.nl
-
a) What is the return period corresponding to an exceedance probability of 99%? b) Determine the annual maxima and rank them from highest to lowest.
the answers to exercise 7.4a and b should also be done with Python code
-
-
www.biorxiv.org www.biorxiv.org
-
Reviewer #1 (Public Review):
Summary:
Li and colleagues describe an experiment whereby sequences of dots in different locations were presented to participants while electroencephalography (EEG) was recorded. By presenting fixed sequences of dots in different locations repeatedly to participants, the authors assumed that participants had learned the sequences during the experiment. The authors also trained classifiers using event-related potential (ERP) data recorded from separate experimental blocks of dots presented in a random (i.e., unpredictable) order. Using these trained classifiers, the authors then assessed whether patterns of brain activity could be detected that resembled the neural response to a dot location that was expected, but not presented. They did this by presenting an additional set of sequences whereby only one of the dots in the learned sequence appeared, but not the other dots. They report that, in these sequences with omitted stimuli, patterns of EEG data resembled the visual response evoked by a dot location for stimuli that could be expected, but were not presented. Importantly, this only occurred for an omitted dot stimulus that would be expected to appear immediately after the dot that was presented in these partial sequences.
This exciting finding complements previous demonstrations of the ability to decode expected (but not presented) stimuli in Blom et al. (2020) and Robinson et al. (2020) that are cited in this manuscript. It suggests that the visual system is able to generate patterns of activity that resemble expected sensory events, approximately at times at which an observer would expect them.
Strengths:
The experiment was carefully designed and care was taken to rule out some confounding factors. For example, gaze location was tracked over time, and deviations from fixation were marked, in order to minimise the contributions of saccades to above-chance decoding of dot position. The use of a separate block of dots (with unpredictable locations) to train the classifiers was also useful in isolating visual responses evoked by each dot location independently of any expectations that might be formed during the experiment. A large amount of data was also collected from each participant, which is important when using classifiers to decode stimulus features from EEG data. This careful approach is commendable and draws on best practices from existing work.
Weaknesses:
While there was clear evidence of careful experiment design, there are some aspects of the data analysis and results that significantly limit the inferences that can be drawn from the data. Both issues raised here relate to the use of pre-stimulus baselines and associated problems. As these issues are somewhat technical and may not be familiar to many readers, I will try to unpack each line of reasoning below. Here, it should be noted that these problems are complex, and similar issues often go undetected even by highly experienced EEG researchers.
Relevant to both issues, the authors derived segments of EEG data relative to the time at which each dot was presented in the sequences (or would have appeared when the stimuli were omitted in the partial sequences). Segments were derived that spanned -100ms to 300ms relative to the actual or expected onset of the dot stimulus. The 300ms post-stimulus time period corresponds to the duration of each dot in the sequence (100ms) plus the inter-stimulus interval (ISI) that was 200ms in duration before the next dot appeared (or would be expected to appear in the partial sequences). Importantly, a pre-stimulus baseline was applied to each of these segments of data, meaning that the average amplitude at each electrode between -100ms and 0ms relative to (actual or expected) stimulus onset was subtracted from each segment of data (i.e., each epoch in common EEG terminology). While this type of baseline subtraction procedure is commonplace in EEG studies, in this study design it is likely to cause problematic effects that could plausibly lead to the patterns of results reported in this manuscript.
First of all, the authors compare event-related potentials (ERPs) evoked by dots in the full as compared to partial sequences, to test a hypothesis relating to attentional tuning. They reported ERP amplitude differences across these conditions, for epochs corresponding to when a dot was presented to a participant (i.e., excluding epochs time-locked to omitted dots). However, these ERP comparisons are complicated by the fact that, in the full sequences, dot presentations are preceded by the presentation of other dots in the sequence. This means that ERPs evoked by the preceding dots in the full sequences will overlap in time with the ERPs corresponding to the dots presented at the zero point in the derived epochs. Importantly, this overlap would not occur in the partial sequence conditions, where only one dot was presented in the sequence. This essentially makes any ERP comparisons between full and partial sequences very difficult to interpret, because it is unclear if ERP differences are simply a product of overlapping ERPs from previously presented dots in the full sequence conditions. For example, there are statistically significant differences observed even in the pre-stimulus baseline period for this ERP analysis, which likely reflects the contributions ERPs evoked by the preceding dots in the full sequences, which are absent in the partial sequences.
The problems with interpreting this data are also compounded by the use of pre-stimulus baselines as described above. Importantly, the use of pre-stimulus baselines relies on the assumption that the ERPs in the baseline period (here, the pre-stimulus period) do not systematically differ across the conditions that are compared (here, the full vs. partial sequences). This assumption is violated due to the overlapping ERPs issue described just above. Accordingly, the use of the pre-stimulus baseline subtraction can produce spurious effects in the time period after stimulus onset (for examples see Feuerriegel & Bode, 2022, Neuroimage). This also makes it very difficult to meaningfully compare the ERPs following dot stimulus onset in these analyses.
The second issue relates to the use of pre-stimulus baselines and concerns the key finding reported in the paper: that EEG patterns corresponding to expected but omitted events can be decoded in the partial sequences. In the partial sequences, there are two critical epochs that were derived: One time-locked to the presentation of the dot, and another that was time-locked to 300ms after the dot was presented (i.e. when the next dot would be expected to appear). The latter epoch was used to test for representations of expected, but omitted, stimulus locations.
For the epochs in which the dots were presented, above-chance decoding can be observed spanning a training time range from around 100-300ms and a testing time range of a similar duration (see the plot in Figure 4b). This plot indicates that, during the time window of around 200-300ms following dot stimulus onset, the position of the dot can be decoded not only from trained classifiers using the same time windows spanning 200-300ms, but also using classifiers trained using earlier time windows of around 100-200ms.
This is important because the 200-300ms time period after dot onset in the partial sequences is the window used for pre-stimulus baseline subtraction when deriving epochs corresponding to the first successor representation (i.e., the first stimulus that might be expected to follow from the presented dot, but did not actually appear). In other words, the 200-300ms time window from dot onset corresponds to the -100 to 0 ms time window in the first successor epochs. Accordingly, the pattern that is indicative of the preceding, actually presented dot position would be subtracted from the EEG data used to test for the successor representation. Notably, the first successor condition would always be in another visual field quadrant (90-degree rotated or the opposite quadrant) as stated in the methods. In other words, the omitted stimulus would be expected to appear in the opposite vertical and/or horizontal visual hemifield as compared to the previously presented dot in these partial sequences.
This is relevant because ERPs tend to show reversed polarity across hemifields. For example, a stimulus presented in the right hemifield will have reversed polarity patterns at the same electrode as compared to an equivalent stimulus presented in the left hemifield (e.g., Supplementary Figure 3 in the comparable study of Blom et al., 2020). By subtracting the ERP patterns evoked by the presented dot in the partial sequences during the time period of 200-300ms (corresponding to the -100 to 0ms baseline window), this would be expected to bias patterns of EEG data in the first successor epochs to resemble stimulus positions in opposite hemifields. This could plausibly produce above-chance decoding accuracy in the time windows identified in Figure 5a, where the training time windows broadly correspond to the periods of above-chance decoding during 200-300ms from dot stimulus onset in Figure 4b.
In other words, the above-chance decoding of the first successor representation may plausibly be an artefact of the pre-stimulus baseline subtraction procedure used when deriving the epochs. This casts some doubt as to whether genuine successor representations were actually detected in the study. Additional tests for successor representations using ERP baselines prior to the presented dot in the partial sequences may be able to get around this, but such analyses were not presented, and the code and data were not accessible at the time of this review.
Although the study is designed well and a great amount of care was taken during the analysis stage, these issues with ERP overlap and baseline subtraction raise some doubts regarding the interpretability of the findings in relation to the analyses currently presented.
-
-
www.biorxiv.org www.biorxiv.org
-
Reviewer #2 (Public Review):
Summary:
The authors investigate axonal and synapse development in two distinct visual feature-encoding neurons (VPN), LC4 and LPLC2. They first show that they occupy distinct regions on the GF dendrites, and likely arrive sequentially. Analysis of the VPNs' morphology throughout development, and synaptic gene and protein expression data reveals the temporal order of maturation. Functional analysis then shows that LPLC2 occupancy of the GF dendrites is constrained by LC4 presence.
Strengths:
The authors investigate an interesting and very timely topic, which will help to understand how neurons coordinate their development. The manuscript is very well written, and data are of high quality, that generally support the conclusions drawn (but see some comments for Fig. 2 below). A thorough descriptive analysis of the LC4/LPLC2 to GF connectivity is followed by some functional assessment showing that one neuron's occupancy of the GF dendrite depend on another.<br /> The manuscripts uses versatile methods to look at membrane contact, gene and protein expression (using scRNAseq data and state-of-the art genetic tools) and functional neuronal properties. I find it especially interesting and elegant how the authors combine their findings to highlight the temporal trajectory of development in this system.
Weaknesses:
After reading the summary, I was expecting a more comprehensive analysis of many VPNs, and their developmental relationships. For a better reflection of the data, the summary could state that the authors investigate *two* visual projection neurons (VPNs) and that ablation *of one cell type of VPNs* results in the expansion of the remaining VPN territory.
The manuscript is falling a bit short of putting the results into the context of what is known about synaptic partner choice/competition between different neurons during neuronal or even visual system development. Lots of work has been done in the peripheral the visual system, from the Hiesinger lab and others. Both the introduction and the discussion section should elaborate on this.
The one thing that the manuscript does not unambiguously show is when the connections between LC4 and LPLC2 become functional.
Figure 2:<br /> Figure 2A-C: I found the text related to that figure hard to follow, especially when talking about filopodia. Overall, life imaging would probably clarify at which time point there really are dynamic filopodia. For this study, high magnification images of what the authors define as filopodia would certainly help.<br /> L137ff: This section talks about filopodia between 24-48 hAPF, but only 36h APF is shown in A, where one could see filopodia. The other time points are shown in B and C, but number of filopodia is not quantified.<br /> L143: "filopodia were still present, but visibly shorter": This is hard to see, and again, not quantified.<br /> L144f: "from 72h APF to eclosion, the volume of GF dendrites significantly decreased": this is not actually quantified, comparisons are only done to 24, 36 and 48 h APF.<br /> Furthermore, 72h APF is not shown here, but in Figure 2D, so either show here, or call this figure panel already?
Figure 2D/E: to strengthen the point that LC4 and LPLC2 arrive sequentially, it would help to show all time points analyzed in Figure D/E.
L208: "significant increase ... from 60h APF to 72h APF": according to the figure caption, this comparison is marked by "+" but there is no + in the figure itself.
Figure 3:<br /> A key point of the manuscript is the sequential arrival of different VPN classes. So then why is the scRNAseq analysis in Figure 3 shown pooled across VPNs? Certainly, the reader at this point is interested in temporal differences in gene expression. The class-specific data are somewhat hidden in Supp. Fig. 9, and actually do not show temporal differences. This finding should be presented in the main data.
L438: "silencing LC4 by expressing Kir2.1... reduced the GF response": Is this claim backed by some quantification?
Figure 4K: Do the control data have error bars, which are just too small to see? And what is tested against what? Is blue vs. black quantified as well? What do red, blue, and black asterisks indicate? Please clarify in figure caption.
Optogenetics is mentioned in methods (in "fly rearing", in the genotypes, and there is an extra "Optogenetics" section in methods), but no such data are shown in the manuscripts. (If the authors have those data, it would be great to know when the VPN>GF connections become functional!)
Methods:
Antibody concentrations are not given anywhere and will be useful information for the reader
Could the authors please give more details on the re-analysis of the scRNAseq dataset? How did you identify cell type clusters in there, for example?
L785 and L794: I am curious. Why is it informative to mention what was *not* done?
Custom-written analysis code is mentioned in a few places. Is this code publicly available?
-
-
www.biorxiv.org www.biorxiv.org
-
Reviewer #1 (Public Review):
Summary:
The manuscript gives a broad overview of how to write NeuroML, and a brief description of how to use it with different simulators and for different purposes - cells to networks, simulation, optimization, and analysis. From this perspective, it can be an extremely useful document to introduce new users to NeuroML.
However, the manuscript itself seems to lose sight of this goal in many places, and instead, the description at times seems to target software developers. For example, there is a long paragraph on the board and user community. The discussion on simulator tools seems more for developers, not users. All the information presented at the level of a developer is likely to be distracting to readers..
Strengths:
The modularity of NeuroML is indeed a great advantage. For example, the ability to specify the channel file allows different channels to be used with different morphologies without redundancy. The hierarchical nature of NeuroML also is commendable, and well illustrated in Figures 2a through c.
The number of tools available to work with NeuroML is impressive.
The abstract, beginning, and end of the manuscript present and discuss incorporating NeuroML into research workflows to support FAIR principles.
Having a Python API and providing examples using this API is fantastic. Exporting to NeuroML from Python is also a great feature.
Weaknesses:
Though modularity is a strength, it is unclear to me why the cell morphology isn't also treated similarly, i.e., specify the morphology of a multi-compartmental model in a separate file, and then allow the cell file to specify not only the files containing channels, but also the file containing the multi-compartmental morphology, and then specify the conductance for different segment groups. Also, after pynml_write_neuroml2_file, you would not have a super long neuroML file for each variation of conductances, since there would be no need to rewrite the multi-compartmental morphology for each conductance variation.
This would be especially important for optimizations, if each trial optimization wrote out the neuroML file, then including the full morphology of a realistic cell would take up excessive disk space, as opposed to just writing out the conductance densities. As long as cell morphology must be included in every cell file, then NeuroML is not sufficiently modular, and the authors should moderate their claim of modularity (line 419) and building blocks (551). In addition, this is very important for downloading NeuroML-compliant reconstructions from NeuroMorpho.org. If the cell morphology cannot be imported, then the user has to edit the file downloaded from NeuroMorpho.org, and provenance can be lost. Also, Figure 2d loses the hierarchical nature by showing ion channels, synapses, and networks as separate main branches of NeuroML.
In Figure 5, the difference between the core and native simulator is unclear. What is involved in helper scripts? I thought neurons could read NeuroML? If so, why do you need the export simulator-specific scripts? In addition, it seems strange to call something the "core" simulation engine, when it cannot support multi-compartmental models. It is unclear why "other simulators" that natively support NeuroML cannot be called the core. It might be more helpful to replace this sort of classification with a user-targeted description. The authors already state which simulators support NeuroML and which ones need code to be exported. In contrast, lines 369-370 mention that not all NeuroML models are supported by each simulator. I recommend expanding this to explain which features are supported in each simulator. Then, the unhelpful separation between core and native could be eliminated.
The body of the manuscript has so much other detail that I lose sight of how NeuroML supports FAIR. It is also unclear who is the intended audience. When I get to lines 336-344, it seems that this description is too much detail for the audience. The paragraph beginning on line 691 is a great example of being unclear about who is the audience. Does someone wanting to develop NeuroML models need to understand XSD schema? If so, the explanation is not clear. XSD schema is not defined and instead explains NeuroML-specific aspects of XSD. Lines 734-735 are another example of explaining to code developers (not model developers).
-
Reviewer #2 (Public Review):
Summary:
Developing neuronal models that are shareable, reproducible, and interoperable allows the neuroscience community to make better use of published models and to collaborate more effectively. In this manuscript, the authors present a consolidated overview of the NeuroML model description system along with its associated tools and workflows. They describe where different components of this ecosystem lay along the model development pathway and highlight resources, including documentation and tutorials, to help users employ this system.
Strengths:
The manuscript is well-organized and clearly written. It effectively uses the delineated model development life cycle steps, presented in Figure 1, to organize its descriptions of the different components and tools relating to NeuroML. It uses this framework to cover the breadth of the software ecosystem and categorize its various elements. The NeuroML format is clearly described, and the authors outline the different benefits of its particular construction. As primarily a means of describing models, NeuroML also depends on many other software components to be of high utility to computational neuroscientists; these include simulators (ones that both pre-date NeuroML and those developed afterwards), visualization tools, and model databases.
Overall, the rationale for the approach NeuroML has taken is convincing and well-described. The pointers to existing documentation, guides, and the example usages presented within the manuscript are useful starting points for potential new users. This manuscript can also serve to inform potential users of features or aspects of the ecosystem that they may have been unaware of, which could lower obstacles to adoption. While much of what is presented is not new to this manuscript, it still serves as a useful resource for the community looking for information about an established, but perhaps daunting, set of computational tools.
Weaknesses:
The manuscript in large part catalogs the different tools and functionalities that have been produced through the long development cycle of NeuroML. As discussed above, this is quite useful, but it can still be somewhat overwhelming for a potential new user of these tools. There are new user guides (e.g., Table 1) and example code (e.g. Box 1), but it is not clear if those resources employ elements of the ecosystem chosen primarily for their didactic advantages, rather than general-purpose utility. I feel like the manuscript would be strengthened by the addition of clearer recommendations for users (or a range of recommendations for users in different scenarios).
For example, is the intention that most users should primarily use the core NeuroML tools and expand into the wider ecosystem only under particular circumstances? What are the criteria to keep in mind when making that decision to use alternative tools (scale/complexity of model, prior familiarity with other tools, etc.)? The place where it seems most ambiguous is in the choice of simulator (in part because there seem to be the most options there) - are there particular scenarios where the authors may recommend using simulators other than the core jNeuroML software?
The interoperability of NeuroML is a major strength, but it does increase the complexity of choices facing users entering into the ecosystem. Some clearer guidance in this manuscript could enable computational neuroscientists with particular goals in mind to make better strategic decisions about which tools to employ at the outset of their work.
-
- Apr 2024
-
www.medrxiv.org www.medrxiv.org
-
Author response:
The following is the authors’ response to the original reviews.
eLife assessment
Connelly and colleagues provide convincing genetic evidence that importation from mainland Tanzania is a major source of Plasmodium falciparum lineages currently circulating in Zanzibar. This study also reveals ongoing local malaria transmission and occasional near-clonal outbreaks in Zanzibar. Overall, this research highlights the role of human movements in maintaining residual malaria transmission in an area targeted for intensive control interventions over the past decades and provides valuable information for epidemiologists and public health professionals.
Reviewer #1 (Public Review):
Zanzibar archipelago is close to achieving malaria elimination, but despite the implementation of effective control measures, there is still a low-level seasonal malaria transmission. This could be due to the frequent importation of malaria from mainland Tanzania and Kenya, reservoirs of asymptomatic infections, and competent vectors. To investigate population structure and gene flow of P. falciparum in Zanzibar and mainland Tanzania, they used 178 samples from mainland Tanzania and 213 from Zanzibar that were previously sequenced using molecular inversion probes (MIPs) panels targeting single nucleotide polymorphisms (SNPs). They performed Principal Component Analysis (PCA) and identity by descent (IBD) analysis to assess genetic relatedness between isolates. Parasites from coastal mainland Tanzania contribute to the genetic diversity in the parasite population in Zanzibar. Despite this, there is a pattern of isolation by distance and microstructure within the archipelago, and evidence of local sharing of highly related strains sustaining malaria transmission in Zanzibar that are important targets for interventions such as mass drug administration and vector control, in addition to measures against imported malaria.
Strengths:
This study presents important samples to understand population structure and gene flow between mainland Tanzania and Zanzibar, especially from the rural Bagamoyo District, where malaria transmission persists and there is a major port of entry to Zanzibar. In addition, this study includes a larger set of SNPs, providing more robustness for analyses such as PCA and IBD. Therefore, the conclusions of this paper are well supported by data.
Weaknesses:
Some points need to be clarified:
(1) SNPs in linkage disequilibrium (LD) can introduce bias in PCA and IBD analysis. Were SNPs in LD filtered out prior to these analyses?
Thank you for this point. We did not filter SNPs in LD prior to this analysis. In the PCA analysis in Figure 1, we did restrict to a single isolate among those that were clonal (high IBD values) to prevent bias in the PCA. In general, disequilibrium is minimal only over small distances <5-10kb without selective forces at play. This is much less than the average spacing of the markers in the panel. If there is minimal LD, the conclusions drawn on relative levels and connections at high IBD are unlikely to be confounded by any effects of disequilibrium.
( 2) Many IBD algorithms do not handle polyclonal infections well, despite an increasing number of algorithms that are able to handle polyclonal infections and multiallelic SNPs. How polyclonal samples were handled for IBD analysis?
Thank you for this point. We added lines 157-161 to clarify. This section now reads:
“To investigate genetic relatedness of parasites across regions, identity by descent (IBD) estimates were assessed using the within sample major alleles (coercing samples to monoclonal by calling the dominant allele at each locus) and estimated utilizing a maximum likelihood approach using the inbreeding_mle function from the MIPanalyzer package (Verity et al., 2020). This approach has previously been validated as a conservative estimate of IBD (Verity et al., 2020).”
Please see the supplement in (Verity et al., 2020) for an extensive simulation study that validates this approach.
Reviewer #1 (Recommendations For The Authors):
(3) I think Supplementary Figures 8 and 9 are more visually informative than Figure 2.
Thank you for your response. We performed the analysis in Figure 2 to show how IBD varies between different regions and is higher within a region than between.
Reviewer #2 (Public Review):
This manuscript describes P. falciparum population structure in Zanzibar and mainland Tanzania. 282 samples were typed using molecular inversion probes. The manuscript is overall well-written and shows a clear population structure. It follows a similar manuscript published earlier this year, which typed a similar number of samples collected mostly in the same sites around the same time. The current manuscript extends this work by including a large number of samples from coastal Tanzania, and by including clinical samples, allowing for a comparison with asymptomatic samples.
The two studies made overall very similar findings, including strong small-scale population structure, related infections on Zanzibar and the mainland, near-clonal expansion on Pemba, and frequency of markers of drug resistance. Despite these similarities, the previous study is mentioned a single time in the discussion (in contrast, the previous research from the authors of the current study is more thoroughly discussed). The authors missed an opportunity here to highlight the similar findings of the two studies.
Thank you for your insights. We appreciated the level of detail of your review and it strengthened our work. We have input additional sentences on lines 292-295, which now reads:
“A recent study investigating population structure in Zanzibar also found local population microstructure in Pemba (Holzschuh et al., 2023). Further, both studies found near-clonal parasites within the same district, Micheweni, and found population microstructure over Zanzibar.”
Strengths:
The overall results show a clear pattern of population structure. The finding of highly related infections detected in close proximity shows local transmission and can possibly be leveraged for targeted control.
Weaknesses:
A number of points need clarification:
(1) It is overall quite challenging to keep track of the number of samples analyzed. I believe the number of samples used to study population structure was 282 (line 141), thus this number should be included in the abstract rather than 391. It is unclear where the number 232 on line 205 comes from, I failed to deduct this number from supplementary table 1.
Thank you for this point. We have included 282 instead of 391 in the abstract. We added a statement in the results at lines 203-205 to clarify this point, which now reads:
“PCA analysis of 232 coastal Tanzanian and Zanzibari isolates, after pruning 51 samples with an IBD of greater than 0.9 to one representative sample, demonstrates little population differentiation (Figure 1A).”
(2) Also, Table 1 and Supplementary Table 1 should be swapped. It is more important for the reader to know the number of samples included in the analysis (as given in Supplementary Table 1) than the number collected. Possibly, the two tables could be combined in a clever way.
Thank you for this advice. Rather than switch to another table altogether, we appended two columns to the original table to better portray the information (see Table 1).
Methods
(3) The authors took the somewhat unusual decision to apply K-means clustering to GPS coordinates to determine how to combine their data into a cluster. There is an obvious cluster on Pemba islands and three clusters on Unguja. Based on the map, I assume that one of these three clusters is mostly urban, while the other two are more rural. It would be helpful to have a bit more information about that in the methods. See also comments on maps in Figures 1 and 2 below.
Cluster 3 is a mix of rural/urban while the clusters 2, 4 and 5 are mostly rural. This analysis was performed to see how IBD changes in relation to local context within different regions in Zanzibar, showing that there is higher IBD within locale than between locale.
(4) Following this point, in Supplemental Figure 5 I fail to see an inflection point at K=4. If there is one, it will be so weak that it is hardly informative. I think selecting 4 clusters in Zanzibar is fine, but the justification based on this figure is unclear.
The K-means clustering experiment was used to cluster a continuous space of geographic coordinates in order to compare genetic relatedness in different regions. We selected this inflection point based on the elbow plot and based the number to obtain sufficient subsections of Zanzibar to compare genetic relatedness. This point is added to the methods at lines 174-178, which now reads:
“The K-means clustering experiment was used to cluster a continuous space of geographic coordinates in order to compare genetic relatedness in different regions. We selected K = 4 as the inflection point based on the elbow plot (Supplemental Figure 5) and based the number to obtain sufficient subsections of Zanzibar to compare genetic relatedness.”
(5) For the drug resistance loci, it is stated that "we further removed SNPs with less than 0.005 population frequency." Was the denominator for this analysis the entire population, or were Zanzibar and mainland samples assessed separately? If the latter, as for all markers <200 samples were typed per site, there could not be a meaningful way of applying this threshold. Given data were available for 200-300 samples for each marker, does this simply mean that each SNP needed to be present twice?
Population frequency is calculated based on the average within sample allele frequency of each individual in the population, which is an unbiased estimator. Within sample allele frequency can range from 0 to 1. Thus, if only one sample has an allele and it is at 0.1 within sample frequency, the population allele frequency would be 0.1/100 = 0.001. This allele is removed even though this would have resulted in a prevalence of 0.01. This filtering is prior to any final summary frequency or prevalence calculations (see MIP variant Calling and Filtering section in the methods). This protects against errors occurring only at low frequency.
Discussion:
(6) I was a bit surprised to read the following statement, given Zanzibar is one of the few places that has an effective reactive case detection program in place: "Thus, directly targeting local malaria transmission, including the asymptomatic reservoir which contributes to sustained transmission (Barry et al., 2021; Sumner et al., 2021), may be an important focus for ultimately achieving malaria control in the archipelago (Björkman & Morris, 2020)." I think the current RACD program should be mentioned and referenced. A number of studies have investigated this program.
Thank you for this point. We have added additional context and clarification on lines 275-280, which now reads:
“Thus, directly targeting local malaria transmission, including the asymptomatic reservoir which contributes to sustained transmission (Barry et al., 2021; Sumner et al., 2021), may be an important focus for ultimately achieving malaria control in the archipelago (Björkman & Morris, 2020). Currently, a reactive case detection program within index case households is being implemented, but local transmission continues and further investigation into how best to control this is warranted (Mkali et al. 2023).”
(7) The discussion states that "In Zanzibar, we see this both within and between shehias, suggesting that parasite gene flow occurs over both short and long distances." I think the term 'long distances' should be better defined. Figure 4 shows that highly related infections rarely span beyond 20-30 km. In many epidemiological studies, this would still be considered short distances.
Thank you for this point. We have edited the text at lines 287-288 to indicate that highly related parasites mainly occur at the range of 20-30km, which now reads:
“In Zanzibar, highly related parasites mainly occur at the range of 20-30km.”
(8) Lines 330-331: "Polymorphisms associated with artemisinin resistance did not appear in this population." Do you refer to background mutations here? Otherwise, the sentence seems to repeat lines 324. Please clarify.
We are referring to the list of Pfk13 polymorphisms stated in the Methods from lines 146-148. We added clarifying text on lines 326-329:
“Although polymorphisms associated with artemisinin resistance did not appear in this population, continued surveillance is warranted given emergence of these mutations in East Africa and reports of rare resistance mutations on the coast consistent with spread of emerging Pfk13 mutations (Moser et al., 2021). “
(9) Line 344: The opinion paper by Bousema et al. in 2012 was followed by a field trial in Kenya (Bousema et al, 2016) that found that targeting hotspots did NOT have an impact beyond the actual hotspot. This (and other) more recent finding needs to be considered when arguing for hotspot-targeted interventions in Zanzibar.
We added a clarification on this point on lines 335-345, which now reads:
“A recent study identified “hotspot” shehias, defined as areas with comparatively higher malaria transmission than other shehias, near the port of Zanzibar town and in northern Pemba (Bisanzio et al., 2023). These regions overlapped with shehias in this study with high levels of IBD, especially in northern Pemba (Figure 4). These areas of substructure represent parasites that differentiated in relative isolation and are thus important locales to target intervention to interrupt local transmission (Bousema et al., 2012). While a field cluster-randomized control trial in Kenya targeting these hotspots did not confer much reduction of malaria outside of the hotspot (Bousema et al. 2016), if areas are isolated pockets, which genetic differentiation can help determine, targeted interventions in these areas are likely needed, potentially through both mass drug administration and vector control (Morris et al., 2018; Okell et al., 2011). Such strategies and measures preventing imported malaria could accelerate progress towards zero malaria in Zanzibar.”
Figures and Tables:
(10) Table 2: Why not enter '0' if a mutation was not detected? 'ND' is somewhat confusing, as the prevalence is indeed 0%.
Thank you for this point. We have put zero and also given CI to provide better detail.
(11) Figure 1: Panel A is very hard to read. I don't think there is a meaningful way to display a 3D-panel in 2D. Two panels showing PC1 vs. PC2 and PC1 vs. PC3 would be better. I also believe the legend 'PC2' is placed in the wrong position (along the Y-axis of panel 2).
Supplementary Figure 2B suffers from the same issue.
Thank you for your comment. A revised Figure 1 and Supplemental Figure 2 are included, where there are separate plots for PC1 vs. PC2 and PC1 vs. PC3.
(12) The maps for Figures 1 and 2 don't correspond. Assuming Kati represents cluster 4 in Figure 2, the name is put in the wrong position. If the grouping of shehias is different between the Figures, please add an explanation of why this is.
Thank you for this point. The districts with at least 5 samples present are plotted in the map in Figure 1B. In Figure 2, a totally separate analysis was performed, where all shehias were clustered into separate groups with k-means and the IBD values were compared between these clusters. These maps are not supposed to match, as they are separate analyses. Figure 1B is at the district level and Figure 2 is clustering shehias throughout Zanzibar.
The figure legend of Figure 1B on lines 410-414 now reads:
“B) A Discriminant Analysis of Principal Components (DAPC) was performed utilizing isolates with unique pseudohaplotypes, pruning highly related isolates to a single representative infection. Districts were included with at least 5 isolates remaining to have sufficient samples for the DAPC. For plotting the inset map, the district coordinates (e.g. Mainland, Kati, etc.) are calculated from the averages of the shehia centroids within each district.”
The figure legend of Figure 2 on lines 417-425 now reads:
“Figure 2. Coastal Tanzania and Zanzibari parasites have more highly related pairs within their given region than between regions. K-means clustering of shehia coordinates was performed using geographic coordinates all shehias present from the sample population to generate 5 clusters (colored boxes). All shehias were included to assay pairwise IBD between differences throughout Zanzibar. Pairwise comparisons of within cluster IBD (column 1 of IBD distribution plots) and between cluster IBD (column 2-5 of IBD distribution plots) was done for all clusters. In general, within cluster IBD had more pairwise comparisons containing high IBD identity.”
(13) Figure 2: In the main panel, please clarify what the lines indicate (median and quartiles?). It is very difficult to see anything except the outliers. I wonder whether another way of displaying these data would be clearer. Maybe a table with medians and confidence intervals would be better (or that data could be added to the plots). The current plots might be misleading as they are dominated by outliers.
Thank you for this point and it greatly improved this figure. We changed the plotting mechanisms through using a beeswarm plot, which plots all pairwise IBD values within each comparison group.
(14) In the insert, the cluster number should not only be given as a color code but also added to the map. The current version will be impossible to read for people with color vision impairment, and it is confusing for any reader as the numbers don't appear to follow any logic (e.g. north to south).
Thank you very much for these considerations. We changed the color coding to a color blind friendly palette and renamed the clusters to more informative names; Pemba, Unguja North (Unguja_N), Unguja Central (Unguja_C), Unguja South (Unguja_S) and mainland Tanzania (Mainland).
(15) The legend for Figure 3 is difficult to follow. I do not understand what the difference in binning was in panels A and B compared to C.
Thank you for this point. We have edited the legend to reflect these changes. The legend for Figure 3 on lines 427-433 now reads:
“Figure 3. Isolation by distance is shown between all Zanzibari parasites (A), only Unguja parasites (B) and only Pemba parasites (C). Samples were analyzed based on geographic location, Zanzibar (N=136) (A), Unguja (N=105) (B) or Pemba (N=31) (C) and greater circle (GC) distances between pairs of parasite isolates were calculated based on shehia centroid coordinates. These distances were binned at 4km increments out to 12 km. IBD beyond 12km is shown in Supplemental Figure 8. The maximum GC distance for all of Zanzibar was 135km, 58km on Unguja and 12km on Pemba. The mean IBD and 95% CI is plotted for each bin.”
(16) Font sizes for panel C differ, and it is not aligned with the other panels.
Thank you for pointing this out. Figure 3 and Supplemental Figure 10 are adjusted with matching formatting for each plot.
(17) Why is Kusini included in Supplemental Figure 4, but not in Figure 1?
In Supplemental Figure 4, all isolates were used in this analysis and isolates with unique pseudohaplotypes were not pruned to a single representative infection. That is why there are additional isolates in Kusini. The legend for Supplemental Figure 4 now reads:
“Supplemental Figure 4. PCA with highly related samples shows population stratification radiating from coastal Mainland to Zanzibar. PCA of 282 total samples was performed using whole sample allele frequency (A) and DAPC was performed after retaining samples with unique pseudohaplotypes in districts that had 5 or more samples present (B). As opposed to Figure 1, all isolates were used in this analysis and isolates with unique pseudohaplotypes were not pruned to a single representative infection.”
(18) Supplemental Figures 6 and 7: What does the width of the line indicate?
The sentence below was added to the figure legends of Supplemental Figures 6 and 7 and the legends of each network plot were increased in size:
“The width of each line represents higher magnitudes of IBD between pairs.”
(19) What was the motivation not to put these lines on the map, as in Figure 4A? This might make it easier to interpret the data.
Thank you for this comment. For Supplemental Figure 8 and 9, we did not put these lines that represent lower pairwise IBD to draw the reader's attention to the highly related pairs between and within shehias.
Reviewer #2 (Recommendations For The Authors):
(1) There is a rather long paragraph (lines 300-323) on COI of asymptomatic infections and their genetic structure. Given that the current study did not investigate most of the hypotheses raised there (e.g. immunity, expression of variant genes), and the overall limited number of asymptomatic samples typed, this part of the discussion feels long and often speculative.
Thank you for your perspective. The key sections highlighted in this comment, regarding immunity and expression of variant genes, were shortened. This section on lines 300-303 now reads:
“Asymptomatic parasitemia has been shown to be common in falciparum malaria around the globe and has been shown to have increasing importance in Zanzibar (Lindblade et al., 2013; Morris et al., 2015). What underlies the biology and prevalence of asymptomatic parasitemia in very low transmission settings where anti-parasite immunity is not expected to be prevalent remains unclear (Björkman & Morris, 2020).”
(2) As a detail, line 304 mentions "few previous studies" but only one is cited. Are there studies that investigated this and found opposite results?
Thank you for this comment. We added additional studies that did not find an association between clinical disease and COI. These changes are on lines 303-308, which now reads:
“Similar to a few previous studies, we found that asymptomatic infections had a higher COI than symptomatic infections across both the coastal mainland and Zanzibar parasite populations (Collins et al., 2022; Kimenyi et al., 2022; Sarah-Matio et al., 2022). Other studies have found lower COI in severe vs. mild malaria cases (Robert et al., 1996) or no significant difference between COI based on clinical status (Earland et al. 2019; Lagnika et al. 2022; Conway et al. 1991; Kun et al. 1998; Tanabe et al. 2015)”
(3) Table 2: Percentages need to be checked. To take one of several examples, for Pfk13-K189N a frequency of 0.019 for the mutant allele is given among 137 samples. 2/137 equals to 0.015, and 3/137 to 0.022. 0.019 cannot be achieved. The same is true for several other markers. Possibly, it can be explained by the presence of polyclonal infections. If so, it should be clarified what the total of clones sequenced was, and whether the prevalence is calculated with the number of samples or number of clones as the denominator.
Thank you for this point. We mistakenly reported allele frequency instead of prevalence. An updated Table 2 is now in the manuscript. The method for calculating the prevalence is now at lines 148-151:
“Prevalence was calculated separately in Zanzibar or mainland Tanzania for each polymorphism by the number of samples with alternative genotype calls for this polymorphism over the total number of samples genotyped and an exact 95% confidence interval was calculated using the Pearson-Klopper method for each prevalence.”
-
-
gist.github.com gist.github.com
-
<realmCode code="AT"/>
START OF THE HEADER!
-
-
inst-fs-iad-prod.inscloudgate.net inst-fs-iad-prod.inscloudgate.netUntitled1
-
“ShouldIsingadifferentsong?”Iask.“No,hijo.No singing.Allyoudoisjumpandcount,jumpandcount,okay? Everydayyoutraining,youtryingtojumpalittlemore.”
Throughout Jaime Cortez’s short story Gordro, we find instances of where Gordo is assimilating to the mainstream image of a boy with masculine interests. This need of being masculine is pushed by his father and Cesar. The passage highlighted how Gordo quickly code switched from singing a girly song to doing something masculine hence counting. Although his father scolded him on counting, Gordo could’ve gone back to singing but he did not. As his first instinct to sing a song about being a princess. But Gordo wants to become more like or have his fathers approval, Gordo wants to please his fathers so he crosses a boundary to be accepted.
-
-
-
if 00:05:22 you've looked at the code in your company you'll realize that wow I've got millions of millions of lines of code there and I have more than a sneaking suspicion that a lot of that code is 00:05:34 actually in my way it doesn't represent the actual bang per line of code that we'd expect from a higher-level language
sneaking suspicion
lot code in my way
no bang per line of code
// We do not get much out of higher-level languages because people do not appreciate that "that advantage of high-level languages is notational rather then computatioal" John Allen - Anatomy of Lisp
I learn this 40 years ago.
I only realise now that the problem with Programming Languages and with Software "Enginnering#2 which is nothing of the sort
The lesson from the first NATO conference on the Software Crisis
ended up identifying that it is not angineering what we doe
that that was what was needed but clearly out of sight
yet the pretence persisted and we were kidding ourselves that what we do is ingineering
The reason is that programming languages constituted in terms of the means of primitives, means of abstractions and means of combinations,
where what is needed is to raise th level of expressive power of our notations by building everything that is needed into a coherent complex self-orgamzing system that supports such complex way of arrticulatinon that the task calls for
Articulating intent to the point where it is amenable to the pun to actuallyr un on a machine
-
-
www.biorxiv.org www.biorxiv.org
-
Author response:
Reviewer #3 (Public Review):
Software UX design is not a trivial task and a point-and-click interface may become difficult to use or misleading when such design is not very well crafted. While Phantasus is a laudable effort to bring some of the out-of-the box transcriptomics workflows closer to the broader community of point-and-click users, there are a number of shortcomings that the authors may want to consider improving.
Thank you for such an in-depth review. We really appreciate this feedback and have tried to address all of the concerns in the new version of Phantasus.
Here I list the ones I found running Phantasus locally through the available Bioconductor package:
(1) The feature of loading in one click one of the thousands of available GEO datasets is great. However, one important use of any such interfaces is the possibility for the users to analyze his/her own data. One of the standard formats for storing tables of RNA-seq counts are CSV files. However, if we try to upload from the computer a CSV file with expression data, such as the counts stored in the file GSE120660_PCamerge_hg38.csv.gz from https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE120660, a first problem is that the system does not recognize that the CSV file is compressed. A second problem is that it does not recognize that values are separated by commas, the very original CSV format, giving a cryptic error "columnVector is undefined". If we transform the CSV format into tab-separated values (TSV) format, then it works, but this constitutes already a first barrier for the target user of Phantasus.
Thank you for highlighting this issue of file formats support. We acknowledge the commonality of CSV and CSV.gz files in gene expression analysis. As a response, we have updated our data loading procedure to support these file formats. Moreover, the most recent version of our web application is able to recognize gzip-archived file in any of supported table formats: GCT, TSV, CSV and XLSX.
(2) Many RNA-seq processing pipelines use Ensembl annotations, which for the purpose of downstream interpretation of the analysis, need to be translated into HUGO gene symbols. When I try to annotate the rows to translate the Ensembl gene identifiers, I get the error
"There is no AnnotationDB on server. Ask administrator to put AnnotationDB sqlite databases in cacheDir/annotationdb folder"
Thank you for revealing this issue. Indeed, locally installed instances of the Phantatus might lose some functionality in absence of some auxiliary files. For example, gene annotation mapping is unavailable without annotation databases. Previously, the user had to perform additional setup steps to unlock a few features, which might be confusing and unclear. In order to overcome this we have revised significantly the installation procedure. Newly added ‘setupPhantasus’ function is able to create all necessary configuration files and provides an interactive dialog with the user that helps to load all necessary data files from our official cache mirror (https://alserglab.wsutl.edu/files/phantasus/minimal-cache/). Docker-based installation follows the same approach, however it is configured to install everything by default. Thus, with help of the new installation procedure locally installed Phantasus now has the whole functionality available at the official mirrors. The comprehensive installation description is now available at https://ctlab.github.io/phantasus-doc/installation.
(3) When trying to normalize the RNA-seq counts, there are no standard options such as within-library (RPKM, FPKM) or between-library (TMM) normalization procedures.
Appreciating your feedback, we've expanded the available normalization options in the updated version of Phantasus. We added support for TMM normalization as suggested by the edgeR package and voom normalization from the limma package. However, certain strategies like RPKM/FPKM or TPM rely on gene-specific effective lengths, which are challenging to infer without protocol and alignment details. As Phantasus operates on gene expression matrices and doesn't execute alignment steps, the implementation of these normalization seems infeasible. On the other hand, if the user has the matrix with FPKM or TPM gene values (for example from a core facility), such a matrix can be loaded into Phantasus and used for the analysis.
If I take log2(1+x) a new tab is created with the normalized data, but it's not easy to realize what happened because the tab has the same name as the previous one and while the colors of the heatmap changed to reflect the new scale of the data, this is quite subtle. This may cause that an unexperienced user to apply the same normalization step again on the normalized data. Ideally, the interface should lead the user through a pipeline, reducing unnecessary degrees of freedom associated with each step.
Thank you for your comment. Indeed our approach to create a new tab for each alteration to the expression values preserving the name might be the source of confusion for a user. On the other hand, generating informative tab names without overwhelming users with too much detail is also challenging. As a compromise we have an option for the user to manually rename the tab. Still, we agree that this remains an area for improvement. We also consider it to be a part of a larger issue: for example, the loaded data can already be log-scaled, so that even one round of log-scale transformation in Phantasus would be incorrect. Accordingly, we are exploring ways to address this issue in the future by adding automated checks for the tools or, as you suggested, implementing stricter pipelines.
(4.4) Phantasus allows one to filter out lowly-expressed genes by averaging expression of genes across samples and discarding/selecting genes using some cutoff value on that average. This strategy is fine, but to make an informed decision on that cutoff it would be useful to see a density plot of those averages that would allow one to identify the modes of low and high expression and decide the cutoff value that separates them.
Thank you for the suggestion. Indeed a density plot might help users to make informed decisions during gene filtration. We have added such a plot into the ‘Plot/Chart’ tool as a ‘histogram’ chart type.
It would be also nice to have an interface to the filterByExpr() function from the edgeR package, which provides more control on how to filter out lowly-expressed genes.
Thank you for proposing the inclusion of an interface for the filterByExpr() function from the edgeR package. In the recent update we have incorporated filterByExpr() as part of the voom normalization tool. For now, for simplicity, we have decided to keep only the default parameter values. However, we will explore the addition of the dedicated filtering tool in the future.
(5) When attempting a differential expression (DE) analysis, a popup window appears saying:
"Your dataset is filtered. Limma will apply to unfiltered dataset. Consider using New Heat Map tool."
One of the main purposes of filtering lowly-expressed genes is mainly to conduct a DE analysis afterwards, so it does not make sense that the tool says that such an analysis will be done on the unfiltered dataset. The reference to the "New Heat Map tool" is vague and unclear where should the user look for that other tool, without any further information or link.
Thank you for highlighting this issue. We agree that the message in the popup window and the default action were confusing. In response to your feedback, we've updated the default behavior of our DE tools to automatically use the filtered data in a new tab. Additionally, we've clarified the warning message to ensure a better understanding of this process.
(6) The DE analysis only allows for a two-sample group comparison, which is an important limitation in the question we may want to address. The construction of more complex designs could be graphically aided by using the ExploreModelMatrix Bioconductor package (Soneson et al, F1000Research, 2020).
Indeed, the ability to create complex designs and various comparisons is important for many applications for gene expression analysis. Accordingly, in the latest Phantasus version, we've introduced an advanced design feature for the DE analysis, enabling the utilization of multiple column annotations for the design matrix. Combined with the existing ability to create new annotations, this update facilitates the setup of diverse design matrices. While at the moment we do not allow setting a complex contrast, we hope that the current interface will cover most of the differential expression use cases.
(7) When trying to perform a pathway analysis with FGSEA, I get the following error:
"Couldn't load FGSEA meta information. Please try again in a moment. Error: cannot open the connection In call: file(file, "rt")
We hope that this issue should be resolved after we have implemented a more streamlined setup process. Among others, the new approach aims to eliminate the unexpected absence of metafiles in local installations. The latest Phantasus package version explicitly prompts the user to load necessary additional files automatically during the initial run, reducing options for an invalid setup.
Finally, there have been already some efforts to approach R and Bioconductor transcriptomics pipelines to point-and-click users, such as iSEE (Rue-Albrecht et al, 2018) and GeneTonic (Marini et al, 2021) but they are not compared or at least cited in the present work.
Indeed, our comparison was focused toward tools that offer non-programmatic functionalities for gene expression data analysis. While tools like iSEE and GeneTonic are adept at visualizing data and hold their own in providing extensive abilities, they do necessitate additional data preparation using R, distinguishing them from the specific scope of tools we assessed.
One nice features of these two tools that I missed in Phantasus is the possibility of generating the R code that produces the analysis performed through the interface. This is important to provide a way to ensure the reproducibility of the analyses performed.
The ability to generate R code within tools like these indeed aids in ensuring analysis reproducibility. Moreover, we have previously attempted implementing this functionality in Phantasus, however it proved to be hard to do in a useful fashion due to potential complex interactions between user and the client-side part of Phantasus. Nevertheless, we acknowledge the significance of such a feature and aim to introduce it in the future.
-
-
-
Usage is a two steps process: First, a schema is constructed using the provided types and constraints: const schema = Joi.object({ a: Joi.string() }); Note that joi schema objects are immutable which means every additional rule added (e.g. .min(5)) will return a new schema object.
Sure! Imagine you're building a structure, like a house. Before you start building, you need a plan, right? That's what a schema is in programming – it's like your blueprint.
So, in this code, we're using a tool called Joi to make our blueprint. We want our structure to have a specific type, like a string, and maybe some rules, like a minimum length.
Here's a simple explanation:
- Constructing the Schema: First, we make our blueprint using Joi. In this case, we're saying we want something called
ato be a string. Think of it like saying, "In my house blueprint, I want a room calleda, and it should be a string."
javascript const schema = Joi.object({ a: Joi.string() });- Adding Rules (Constraints): Now, let's say we want to add a rule to our blueprint, like saying that our room
amust be at least 5 characters long. When we add rules, Joi gives us back a new blueprint with that rule added. It's like updating our original blueprint with extra details.
javascript const schemaWithRule = schema.keys({ a: Joi.string().min(5) });So, in simple terms, we're creating a plan for our data, and then we can add rules to that plan to make sure our data follows certain conditions.
- Constructing the Schema: First, we make our blueprint using Joi. In this case, we're saying we want something called
-
-
www.biorxiv.org www.biorxiv.org
-
Note: This response was posted by the corresponding author to Review Commons. The content has not been altered except for formatting.
Learn more at Review Commons
Reply to the reviewers
Reviewer #1
Evidence, reproducibility and clarity
Seleit and colleagues set out to explore the genetics of developmental timing and tissue size by mapping natural genetic variation associated with segmentation clock period and presomitic mesoderm (PSM) size in different species of Medaka fish. They first establish the extent of variation between five different Medaka species of in terms of organismal size, segmentation rate, segment size and presomitic mesoderm size, among other traits. They find that these traits are species-specific but strongly correlated. In a massive undertaking, they then perform developmental QTL mapping for segmentation clock period and PSM size in a set of ~600 F2 fish resulting from the cross of Orizyas sakaizumii (Kaga) and Orizyas latipes (Cab). Correlation between segmentation period and segment size was lost among the F2s, indicating that distinct genetic modules control these traits. Although the researchers fail to identify causal variants driving these traits, they perform proof of concept perturbations by analyzing F0 Crispants in which candidate genes were knocked out. Overall, the study introduces a completely new methodology (QTL mapping) to the field of segmentation and developmental tempo, and therefore provides multiple valuable insights into the forces driving evolution of these traits.
Major comments: - The first sentence in the abstract reads "How the timing of development is linked to organismal size is a longstanding question". It is therefore disappointing that organismal size is not reported for the F2 hybrids. Was larval length measured in the F2s? If so, it should be reported. It is critical to understand whether the correlation between larval size and segmentation clock period is preserved in F2s or not, therefore determining if they represent a single or separate developmental modules. If larval length data were not collected, the authors need to be more careful with their wording.
The question the reviewer raises here is indeed a very relevant one, and a question that we also were curious about ourselves. While it was not possible (logistically) to grow the 600 F2 fish to adulthood, we did measure larval length in a subset of F2 hatchling (n=72) to ask precisely the question the reviewer raises here. Our results (new Supplementary Figure 5) show that the correlation between larval length and segmentation timing (which we report across the Oryzias species) is absent in the F2s. This indeed argues that the traits represent separate developmental modules.
In the current version of the paper, organismal size is often incorrectly equated to tissue size (e.g. PSM size, segment size). For example, in page 3 lines 33-34, the authors state that faster segmentation occurred in embryos of smaller size (Fig. 1D). However, Fig. 1D shows correlation between segmentation rate and unsegmented PSM area. The appropriate data to show would be segmentation rate vs. larval or adult length.
The reviewer is correct. We have now linked the data more clearly to data we show in Supplementary Figure 1, which shows that adult length and adult mass are strongly correlated (S1A) and that adult mass is in turn strongly correlated with segmentation rate in the different Oryzias species (S1B). Additionally main Figure 1B shows that larval length is correlated with PSM length. We have corrected the main text to reflect these relationships more clearly.
- Is my understanding correct in that the her7-venus reporter is carried by the Cab F0 but not the Kaga F0? Presumably only F2s which carried the reporter were selected for phenotyping. I would expect the location of the reporter in the genome to be obvious in Figure 3J as a region that is only Cab or het but never Kaga. Can the authors please point to the location of the reporter?
The reviewer is correct. Indeed the location of our her7-venus KI is on chromosome 16 and the recombination patterns on this chromosome overwhelmingly show either Hom Cab (green) or Het Cab/Kaga (Black). This is expected as we selected fish carrying the her7-venus KI for phenotyping.
- devQTL mapping in this study seems like a wasted opportunity. The authors perform mapping only to then hand pick their targets based on GO annotations. This biases the study towards genes known to be involved in PSM development, when part of the appeal of QTL mapping is precisely its unbiased nature and the potential to discover new functionally relevant genes. The authors need to better justify their rationale for candidate prioritization from devQTL peaks. The GO analysis should be shown as supplemental data. What criteria were used to select genes based on GO annotations?
We have now commented on these valid points and outlined our rationale in more detail in the text (page 4, lines 20-30). Our rationale now also includes selection of differentially expressed genes (n=5 genes) that fall within segmentation timing devQTL hits (for more details see below). Essentially, while we indeed finally focused on the proof of principle using known genes, these genes were previously not known to play a role in either setting the timing of segmentation or controlling the size of the PSM. Hence, we do think our strategy demonstrates the "the potential to discover new functionally relevant genes", even though the genes themselves had been involved overall in somitogenesis. We added the GO analysis as supplemental data as requested (new Supplementary Figure 7E).
- Analysis of the predicted functional consequence of divergent SNPs (Fig. S6B, F) is superficial. Among missense variants, which genes harbor the most deleterious mutations? Which missense variants are located in highly conserved residues? Which genes carry variants in splice donors/acceptors? Carefully assessing the predicted effect of SNPs in coding regions would provide an alternative, less biased approach to prioritize candidate genes.
We now included our analysis of SNPs based on the Variant effect predictor (VEP) tool from ensembl. This analysis does rank the predicted severity of the SNP on protein structure and function (Impact: low, moderate, high) and does annotate which variants can affect splice donors/acceptors. The VEP analysis for both phenotypes is now added to the manuscript as supplemental data (new Supplementary Data S2, S5).
- Another potential way to prioritize candidate genes within devQTL peaks would be to use the RNA seq data. The authors should perform differential expression analysis between Kaga and Cab RNA-seq datasets. Do any of the differentially expressed genes fall within the devQTL peaks?
As suggested we have performed this additional experiment and report the RNAseq differential analysis in new Supplement Figure 7C-D. The analysis revealed 2606 differentially expressed genes in the PSM between Kaga and Cab, five of which were candidate genes from the devQTL analysis. We now tested all of these (5 in total, 4 new and 1 previously targeted adgrg1) for segmentation timing by CRISPR/Cas9 KO in the her7-venus background, none of which showed a timing phenotype (new Supplementary Figure 7F-F'). We provide the complete set of results in new Supplementary Figure 7 , Supplementary Data file 3 (DE-genes), all data were deposited on publicly available repository Biostudies under accession number: E-MTAB-13927.
- The use of crispants to functionally test candidate genes is inappropriate. Crispants do not mimic the effect of divergent SNPs and therefore completely fail to prove causality. While it is completely understandable that Medaka fish are not amenable to the creation of multiple knock-in lines where divergent SNPs are interconverted between species, better justification is needed. For instance, is there enough data to suggest that the divergent alleles for the candidate genes tested are loss of function? Why was a knockout approach chosen as opposed to overexpression?
We agree with the reviewer that we do not address the causality of SNPs with the CRISPR/Cas9 KO approach we followed. And medaka does offer the genome editing capabilities to create tailored sequence modifications. So in principle, this can be done. In practice, however, we reasoned that any given SNP will contribute only partially to the observed phenotypes and combinatorial sequence edits are simply very laborious given the current state of the art in genome editing technologies. We therefore opted for an alternative proof of principle approach that aims to "to discover new functionally relevant genes", not SNPs.
-Along the same line, now that two candidate genes have been shown to modulate the clock period in crispants (mespb and pcdh10b), the authors should at least attempt to knock in the respective divergent SNPs for one of the genes. This is of course optional because it would imply several months of work, but it would significantly increase the impact of the study.
As above, this is in principle the correct rationale to follow though very time, cost and labour intensive. It is for the later practical consideration that we decided not to follow this option.
Minor Comments - It would be highly beneficial to describe the ecological differences between the two Medaka species. For example, do the northern O. sakaizumii inhabit a colder climate than the southern O. latipes? Is food more abundant or easily accessible for one species compared to the other? What, if anything, has been described about each species' ecology?
There are indeed differences in the ecology of both species, with the northern O.sakaizumii inhabiting a colder climate than the southern O. latipes. In addition, it is known that the breeding season is shorter in the north than the south, and also there is the fact that northern species have been shown to have a faster juvenile growth rate than southern species. While it would be premature to link those ecological factors to the timing differences we observe, we can certainly speculate. A line to this effect has been added to the main text (Page 5, line 28-30).
- The authors describe two different methods for quantifying segmentation clock period (mean vs. intercept). It is still unclear what is the difference between Figs. 3A (clock period), S4A (mean period) and S4B (intercept period). Is clock period just mean period? Are the data then shown twice? How do Fig. 3A and S4A differ?
The clock period shown in all the main figures is the intercept period, which was also used for the devQTL analysis. Both measurements (mean and intercept) are indeed highly correlated and we include both in supplement for completeness.
- devQTL as shorthand for developmental QTL should be defined in page 4 line 1 (where the term first appears), not later in line 12 of the same page.
Noted and corrected, we thank the reviewer for spotting this error.
- Python code for period quantification should be uploaded to Github and shared with reviewers.
All period quantification code that was used in this study was obtained from the publicly available tool Pyboat (https://www.biorxiv.org/content/10.1101/2020.04.29.067744v3). All code that is used in PyBoat is available from the Github page of the creator of the tool (https://github.com/tensionhead/pyBOAT). Both are linked in the references and materials and methods sections.
- RNA-seq data should be uploaded to a publicly accessible repository and the reviewer token shared with reviewers.
We have uploaded all RNA-sequencing Data to public repository BioStudies under accession numbers : E-MTAB-13927, E-MTAB-13928. This information is now also added to material and methods in the manuscript text.
Why are the maintenance (27-28C) vs. imaging (30C) temperatures different?
Medaka fish have a wide range of temperatures they can physiologically tolerate, i.e. 17-33. The temperature 30C was chosen for practical reasons, i.e. a slightly faster developmental rate enables higher sample throughput in overnight real-time imaging experiments.
- For Crispants, control injections should have included a non-targeting sgRNA control instead of simply omitting the sgRNA.
We agree a non-targeting sgRNA control can be included, though we choose a different approach. For clarity, we now also include a control targeting Oca2, a gene involved in the pigmentation of the eye to probe for any injection related effect on timing and PSM size. As expected, 3 sgRNAs + Cas9 against Oca2 had no impact on timing or PSM size. This data is now shown in new Supplementary Figure 9 F-G'.
It is difficult to keep track of the species and strains. It would be most helpful if Fig. S1 appeared instead in main figure 1.
We agree and included an overview of the phylogenetic relationship of all species and their geographical locales in new Figure 1 A-B.
Significance
- The study introduces a new way of thinking about segmentation timing and size scaling by considering natural variation in the context of selection. This new framing will have an important impact on the field.
- Perhaps the most significant finding is that the correlation between segment timing and size in wild populations is driven not by developmental constraints but rather selection pressure, whereas segment size scaling does form a single developmental module. This finding should be of interest to a broad audience and will influence how researchers in the field approach future studies.
- It would be helpful to add to the conclusion the author's opinion on whether segmentation timing is a quantitative trait based on the number of QTL peaks identified.
- The authors should be careful not to assign any causality to the candidate genes that they test in crispants.
- The data and results are generally well-presented, and the research is highly rigorous.
- Please note I do have the expertise to evaluate the statistical/bioinformatic methods used for devQTL mapping.
Reviewer #2
Evidence, reproducibility and clarity
Seleit et al. investigate the correlation between segment size, presomitic mesoderm and the rhythm of periodic oscilations in the segmentation clock of developing medaka fish. Specifically, they aim to identify the genetic determinants for said traits. To do so, they employ a common garden approach and measure such traits in separate strains (F0) and in interbreedings across two generations (F1 and F2). They find that whereas presomitic mesoderm and segment size are genetically coupled, the tempo of her7 oscilations it is not. Genetic mapping of the F0 and F2 progeny allows them to identify regions associated to said traits. They go on an perturb 7 loci associated to the segmentation clock and X related to segment size. They show that 2/7 have a tempo defect, and 2/ affect size.
Major comments: The conclusions are convincing and well supported by the data. I think the work could be published as is in its current state, and no additional experiments that I can think of are needed to support the claims in the paper.
Minor comments: - The authors could provide a more detailed characterization of the identified SNPs associated to the clock and to PSM size. For the segmentation clock, the authors identify 46872 SNPs, most of which correspond to non-coding regions and are associated to 57 genes. They narrow down their approach to those expressed in the PSM of Cab Kaga. Was the RNA selected from F1 hybrids? I wonder if this would impact the analysis for tempo and or size in any way, as F2 are derived from these, and they show broader variability in the clock period than the F0 and F1 fishes.
The RNA was obtained from the pure F0 strains and we have now extended this analysis by deep bulk-RNA sequencing and differential gene expression analysis. As indicated also to reviewer 1, this revealed 2606 differentially expressed genes in the unsegmented tails of Kaga and Cab embryos, some of which occurred in devQTL peaks. Based on this information we expanded our list of CRISPR/Cas9 KOs by targeting all differentially expressed genes (5 in total, 4 new and 1 previously targeted) for segmentation timing, none of which showed a timing phenotype (new Supplementary figure 7C-D). We provide the complete set of results in new Supplementary Figure 7, Supplementary Data file 3 (DE-genes). All data were deposited on publicly available repository Biostudies under accession number: E-MTAB-13927.
It would be good if the authors could discuss if there were any associated categories or overall functional relationships between the SNPs/genes associated to size. And what about in the case of timing?
In the case of PSM size there were no clear GO terms or functional relationships between the genes that passed the significance threshold on chromosome 3.
For the 35 genes related to segmentation timing, there were a number of GO enrichment terms directly related to somitogenesis. We have included the GO analysis in the new Supplementary Figure 7E.
- Have any of the candidate genes or regulatory loci been associated to clock defects (57) or segment size (204) previously in the literature?
To the best of our knowledge none of the genes have been associated with clock or PSM size defects so far. It might be worthwhile using our results to probe their function in other systems enabling higher throughput functional analysis, such as newly developed organoid models.
- When the authors narrow down the candidate list, it is not clear if the genes selected as expressed in the PSM are tissue specific. If they are, I wonder if genes with ubiquitous expression would be more informative to investigate tempo of development more broadly. It would be good if the authors could specifically discuss this point in the manuscript.
We have not addressed the spatial expression pattern of the 35 identified PSM genes in this study, so we cannot speculate further. But the reviewer raises an important point, how timing of individual processes (body axis segmentation) are linked at organismal scale is indeed a fundamental, additional, question that will be addressed in future studies, indeed the in-vivo context we follow here would be ideal for such investigations.
Can the authors speculate mechanistically why mespb or pchd10b accelerates the period of her7 oscillations?
While we do not have a mechanistic explanation yet, an additional experiment we performed, i.e. bulk-RNAsequencing on WT and mespb mutant tails, provided additional insight, we now added this data to the manuscript . This analysis revealed 808 differentially expressed genes between wt and mespb mutants. Interestingly, many of these affected genes are known to be expressed outside of the mespb domain, i.e. in the most posterior PSM (i.e. tbxt, foxb1,msgn1, axin2, fgf8, amongst others). This indicates that the effect of mespb downregulation is widespread and possibly occurs at an earlier developmental stage. This requires more follow up studies. This data is now shown in new Supplementary figure 9A, Supplementary Data file S4. We now comment on this point in the revised manuscript.
- Are there any size difference associated to the functionally validated clock mutants?
We addressed this point directly and added this analysis as supplementary Figure 9H-H'. While pcdh10b mutants do not show any detectable difference in PSM size, we find a small, statistically significant reduction in PSM size (area but not length) in mespb mutants. All this data is now included in the revised manuscript.
-Ref 27 shows a lack of correlation between body size and the segmentation period in various species of mammals. The work supports their findings, and it would be good to see this discussed in the text.
We are not certain how best to compare our in-vivo results in externally developing fish embryos to in-vitro mammalian 2-D cell cultures. In our view, the correlation of embryo size, larval and adult size that we find in Oryzias might not necessarily hold in mammalian species, which would make a comparison more difficult. We do cite the work mentioned so the reader is pointed towards this interesting, complementary literature.
Significance
The work is quite remarkable in terms of the multigenerational genetic analysis performed. The authors have analysed >600 embryos from three separate generations to obtain quantitative data to answer their question (herculean task!). Moreover, they have associated this characterization to specific SNPs. Then, to go beyond the association, they have generated mutant lines and identified specific genes associated to the traits they set out to decipher.
To my knowledge, this is the first project that aims to identify the genetic determinants for developmental timing. Recent work on developmental timing in mammals has focused on interspecies comparisons and does not provide genetic evidence or insight into how tempo is regulated in the genome. As for vertebrates, recent work from zebrafish has profiled temperature effects on cell proportions and developmental timing. However, the genetic approach of this work is quite elegant and neat.
Conceptually, it is quite important and unexpected that overall size and tempo are not related. Body size, lifespan, basal metabolic rates and gestational period correlate positively and we tend to think that mechanistically they would all be connected to one another. This paper and Lazaro et al. 2023 (ref 27) are one of the first in which this preconception is challenged in a very methodical and conclusive manner. I believe the work is a breakthrough for the field and this work would be interesting for the field of biological timing, for the segmentation clock community and more broadly for all developmental biologists.
My field is quantitative stem cell biology and I work on developmental timing myself, so I acknowledge that I am biased in the enthusiasm for the work. It should be noted that as an expert on the field, I have identified instances where other work hasn't been as insightful or well developed in comparison to this piece. It is also worth noting that I am not an expert in fish development, phylogenetic studies or GWAS analyses, so I am not capable to asses any pitfalls in that respect.
__Reviewer #3 (Evidence, reproducibility and clarity (Required)): __
__Summary: __
This manuscript explores the temporal and spatial regulation of vertebrate body axis development and patterning. In the early stages of vertebrate embryo development, the axial mesoderm (presomitic mesoderm - PSM) undergoes segmentation, forming structures known as somites. The exact genetic regulation governing somite and PSM size, and their relationship to the periodicity of somite formation remains unclear.
To address this, the authors used two evolutionarily closely related Medaka species, Oryzias sakaizumii and Oryzias latipes, which, although having distinct characteristics, can produce viable offspring. Through analysis spanning parental (generation F0) and offspring (generations F1 and F2) generations, the authors observed a correlation between PSM and somite size. However, they found that size scaling does not correlate with the timing of somitogenesis.
Furthermore, employing developmental quantitative trait loci (devQTL) mapping, the authors identified several new candidate loci that may play a role during somitogenesis, influencing timing of segment formation or segment size. The significance of these loci was confirmed through an innovative CRISPR-Cas9 gene editing approach.
This study highlights that the spatial and temporal aspects of vertebrate segmentation are independently controlled by distinct genetic modular mechanisms.
__Major comments: __
1) In the main text page 3, lines 11 and 12, the authors state that the periodicity of the embryo clock of the F1 generation is the intermediate between the parental F0 lineages. However, the authors look only at the periodicity of the Cab strain (Oryzias latipes) segmentation clock. The authors should have a reporter fish line for the Kaga strain (Oryzias sakaizumii) to compare the segmentation clock of both parental strains and their offspring. Since it could be time consuming and laborious, I advise to alternatively rephrase the text of the manuscript.
We agree a careful distinction between segment forming rate (measured based on morphology) and clock period (measured using the novel reporter we generated) is essential. We show that both measures correlate very well in Cab, in both F0 and F1 and F2 carrying the Cab allele. For Kaga F0, we indeed can only provide the rate of somite formation, which nevertheless allows comparison due to the strong correlation to the clock period we have found. We have rephrased the text accordingly.
2) It is evident that only a few F0 and F1 animals were analyzed in comparison with the F2 generation. Could the authors kindly explain whether and how this could bias or skew the observed results?
We provide statistical evidence through the F-test of equality that the variances between the F0, F1 and F2 samples are equal. Additionally if we sub-sample and separate the F2 data into groups of 100 embryos (instead of all 638) we get the same distribution of the F2s. We therefore believe that this is sufficient evidence against a bias or skew in the results.
3) It would be interesting to create fish lines with the validated CRISPR-Cas9 gene manipulations in different genetic contexts (Cab or Kaga) to analyze the true impact on the segmentation clock and/or PSM & somite sizes.
We agree with the reviewer this would in principle be of interest indeed, please see our response to reviewer 1 earlier.
4) Please add the results of the Go Analysis as supplementary material.
We have added the GO analysis in new Supplementary Figure 7E.
__Minor comments: __
1) In the main text, page 2, line 29, Supplementary Figure 1D should be referenced.
We have added a clearer phylogeny and geographical location of the different species in new Figure 1 A-B. And reference it at the requested location.
2) In the main text, page 2, line 32, the authors refer to Figure 1B, but it should be 1C.
We have corrected the information.
3) Regarding the topic "Correlation of segmentation timing and size in the Oryzias genus" the authors should also give information on the total time of development of the different Oryzias species, as well as the total number of formed somites.
We follow this recommendation and have added this information in new Supplementary Figure 5. We also now include segment number measured in F2 embryos. We indeed view segmentation rate as a proxy for developmental rate, which however needs to be distinguished from total developmental time. The latter can be measured for instance by quantifying hatching time, which we did. These measurements show that Kaga, Cab and O.hubbsi embryos kept at constant 28 degrees started hatching on the same day while O.minutillus and O.mekongensis embryos started hatching one day earlier. We have not included this data in the manuscript because we think a distinction should be made between rate of development and total development time.
4) In Figures 3A and B, please add info on the F1 lines for comparison.
The information on F1 lines is provided in Supplementary Figure 3
5) Supplementary Figures 2F shows that the generation F1 PSM is similar to Cab F0, and not an intermediate between Kaga F0 and Cab F0. This is interesting and should be discussed.
We show that the F1 PSM is indeed closer to the PSM of Cab than it is to the Kaga PSM. This is indeed intriguing and we have now commented on this point directly in the text.
6) Supplementary Figures 6C to H are not mentioned either in the main text or in the extended information. Please add/mention accordingly.
We have added references to both in the text
7) The order of Supplementary Figure 8 E to H and A to D appears to be not correct and not following the flow of the text. Please update/correct accordingly.
We have updated the text accordingly.
8) The authors should choose between "Fig.", "Fig", "fig.", "fig" or "Figure". All 'variants' can be found in the text.
Noted, and updated. Fig. is used for main figures and fig. is used for supplementary figures.
9) The color scheme of several figures (graphs with colored dots) should be revised. Several appear to be difficult to discern and analyze.
We have enhanced the colours and increased the font on the figure panels. The colour panel was chosen to be colour-blind friendly.
10) Please address/discuss following questions: What are the known somitogenesis regulating genes in Medaka? How do they correlate with the new candidates?
The candidates we found and tested had not been implicated in regulating the tempo of segmentation or PSM size, while for some a role in somite formation had been previously established, hence the enrichment in GO analysis Somitogenesis.
Reviewer #3 (Significance (Required)):
General assessment:
This interesting manuscript describes a novel approach to study and find new players relevant to the regulation of vertebrate segmentation. By employing this innovative methodology, the authors could elegantly demonstrate that the segmentation clock periodicity is independent from the sizes of the PSM and forming somites. The authors were further able to find new genes that may be involved in the regulation of the segmentation clock periodicity and/or the size of the PSM & somites. A limitation of this study is the fact that the results mainly rely on differences between the two species. The integration of additional Medaka species would be beneficial and may help uncover relevant genes and genetic contexts.
Advance:
To my best knowledge this is the first time that such a methodology was employed to study the segmentation clock and axial development. Although the topic has been extensively studied in several model organisms, such as mice, chicken, and zebrafish, none of them correlated the size of the embryonic tissues and the periodicity of the embryo clock. This study brings novel technological and functional advances to the study of vertebrate axial development.
Audience:
This work is particularly interesting to basic researchers, especially in the field of developmental biology and represents a fresh new approach to study a core developmental process. This study further opens the exciting possibility of using a similar methodology to investigate other aspects of vertebrate development. It is a timely and important manuscript which could be of interest to a wider scientific audience and readership.
-
Note: This preprint has been reviewed by subject experts for Review Commons. Content has not been altered except for formatting.
Learn more at Review Commons
Referee #1
Evidence, reproducibility and clarity
Seleit and colleagues set out to explore the genetics of developmental timing and tissue size by mapping natural genetic variation associated with segmentation clock period and presomitic mesoderm (PSM) size in different species of Medaka fish. They first establish the extent of variation between five different Medaka species of in terms of organismal size, segmentation rate, segment size and presomitic mesoderm size, among other traits. They find that these traits are species-specific but strongly correlated. In a massive undertaking, they then perform developmental QTL mapping for segmentation clock period and PSM size in a set of ~600 F2 fish resulting from the cross of Orizyas sakaizumii (Kaga) and Orizyas latipes (Cab). Correlation between segmentation period and segment size was lost among the F2s, indicating that distinct genetic modules control these traits. Although the researchers fail to identify causal variants driving these traits, they perform proof of concept perturbations by analyzing F0 Crispants in which candidate genes were knocked out. Overall, the study introduces a completely new methodology (QTL mapping) to the field of segmentation and developmental tempo, and therefore provides multiple valuable insights into the forces driving evolution of these traits.
Major comments:
- The first sentence in the abstract reads "How the timing of development is linked to organismal size is a longstanding question". It is therefore disappointing that organismal size is not reported for the F2 hybrids. Was larval length measured in the F2s? If so, it should be reported. It is critical to understand whether the correlation between larval size and segmentation clock period is preserved in F2s or not, therefore determining if they represent a single or separate developmental modules. If larval length data were not collected, the authors need to be more careful with their wording. In the current version of the paper, organismal size is often incorrectly equated to tissue size (e.g. PSM size, segment size). For example, in page 3 lines 33-34, the authors state that faster segmentation occurred in embryos of smaller size (Fig. 1D). However, Fig. 1D shows correlation between segmentation rate and unsegmented PSM area. The appropriate data to show would be segmentation rate vs. larval or adult length.
- Is my understanding correct in that the her7-venus reporter is carried by the Cab F0 but not the Kaga F0? Presumably only F2s which carried the reporter were selected for phenotyping. I would expect the location of the reporter in the genome to be obvious in Figure 3J as a region that is only Cab or het but never Kaga. Can the authors please point to the location of the reporter?
- devQTL mapping in this study seems like a wasted opportunity. The authors perform mapping only to then hand pick their targets based on GO annotations. This biases the study towards genes known to be involved in PSM development, when part of the appeal of QTL mapping is precisely its unbiased nature and the potential to discover new functionally relevant genes. The authors need to better justify their rationale for candidate prioritization from devQTL peaks. The GO analysis should be shown as supplemental data. What criteria were used to select genes based on GO annotations?
- Analysis of the predicted functional consequence of divergent SNPs (Fig. S6B, F) is superficial. Among missense variants, which genes harbor the most deleterious mutations? Which missense variants are located in highly conserved residues? Which genes carry variants in splice donors/acceptors? Carefully assessing the predicted effect of SNPs in coding regions would provide an alternative, less biased approach to prioritize candidate genes.
- Another potential way to prioritize candidate genes within devQTL peaks would be to use the RNA seq data. The authors should perform differential expression analysis between Kaga and Cab RNA-seq datasets. Do any of the differentially expressed genes fall within the devQTL peaks?
- The use of crispants to functionally test candidate genes is inappropriate. Crispants do not mimic the effect of divergent SNPs and therefore completely fail to prove causality. While it is completely understandable that Medaka fish are not amenable to the creation of multiple knock-in lines where divergent SNPs are interconverted between species, better justification is needed. For instance, is there enough data to suggest that the divergent alleles for the candidate genes tested are loss of function? Why was a knockout approach chosen as opposed to overexpression?
- Along the same line, now that two candidate genes have been shown to modulate the clock period in crispants (mespb and pcdh10b), the authors should at least attempt to knock in the respective divergent SNPs for one of the genes. This is of course optional because it would imply several months of work, but it would significantly increase the impact of the study.
Minor Comments
- It would be highly beneficial to describe the ecological differences between the two Medaka species. For example, do the northern O. sakaizumii inhabit a colder climate than the southern O. latipes? Is food more abundant or easily accessible for one species compared to the other? What, if anything, has been described about each species' ecology?
- The authors describe two different methods for quantifying segmentation clock period (mean vs. intercept). It is still unclear what is the difference between Figs. 3A (clock period), S4A (mean period) and S4B (intercept period). Is clock period just mean period? Are the data then shown twice? How do Fig. 3A and S4A differ?
- devQTL as shorthand for developmental QTL should be defined in page 4 line 1 (where the term first appears), not later in line 12 of the same page.
- Python code for period quantification should be uploaded to Github and shared with reviewers.
- RNA-seq data should be uploaded to a publicly accessible repository and the reviewer token shared with reviewers.
- Why are the maintenance (27-28C) vs. imaging (30C) temperatures different?
- For Crispants, control injections should have included a non-targeting sgRNA control instead of simply omitting the sgRNA.
- It is difficult to keep track of the species and strains. It would be most helpful if Fig. S1 appeared instead in main figure 1.
Significance
- The study introduces a new way of thinking about segmentation timing and size scaling by considering natural variation in the context of selection. This new framing will have an important impact on the field.
- Perhaps the most significant finding is that the correlation between segment timing and size in wild populations is driven not by developmental constraints but rather selection pressure, whereas segment size scaling does form a single developmental module. This finding should be of interest to a broad audience and will influence how researchers in the field approach future studies.
- It would be helpful to add to the conclusion the author's opinion on whether segmentation timing is a quantitative trait based on the number of QTL peaks identified.
- The authors should be careful not to assign any causality to the candidate genes that they test in crispants.
- The data and results are generally well-presented, and the research is highly rigorous.
- Please note I do have the expertise to evaluate the statistical/bioinformatic methods used for devQTL mapping.
-
-
social-media-ethics-automation.github.io social-media-ethics-automation.github.io
-
Multi-factor authentication. December 2023. Page Version ID: 1188119370. URL: https://en.wikipedia.org/w/index.php?title=Multi-factor_authentication&oldid=1188119370 (visited on 2023-12-06).
Multifactor authentication is a system where a site will only allow access to the site when 2 or more pieces of authenticating evidence are presented. this may come in the form of a password along with a code sent through SMS or email. This allows for a site to be more secure when multiple factors of authentication are presented to avoid unwanted access.
-
-
www.e-flux.com www.e-flux.com
-
But stepping back even further, one can only see this imagined software as an enhancement to Latour’s larger model of interplay in his actor-network theory, a theory that does not need software or special equipment to exist. The activity in a spatial environment is not reliant on the digital environment. It may be enhanced by a code/text-based software, but a spatial software or protocol can be any platform that establishes variables for space as information
-
We are not accustomed to the idea that non-human, inanimate objects possess agency and activity, just as we are not accustomed to the idea that they can carry information unless they are endowed with code/text-based information technologies. While accepting that a technology like mobile telephony has become the world’s largest shared platform for information exchange, we are perhaps less accustomed to the idea of space as a technology or medium of information—undeclared information that is not parsed as text or code. Indeed, the more ubiquitous code/text-based information devices become, the harder it is to see spatial technologies and networks that are independent of the digital. Few would look at a concrete highway system or an electrical grid and perceive agency in their static arrangement. Agency might only be ascribed to the moving cars or the electrical current. Spaces and urban arrangements are usually treated as collections of objects or volumes, not as actors. Yet the organization itself is active. It is doing something, and changes in the organization constitute information. Even so, the idea that information is carried in activity, or what we might call active form, must still struggle against many powerful habits of mind.
-
-
josephg.com josephg.com
-
He said no way - using haskell he was convinced he could implement anything I could implement, faster and better and with less code. We didn't test the claim - but I still wonder - is he right?
Both are correct. This aspirational ideal - crafting a program with a small, tight, and beautiful core - is possible if a program is intended to be an artifact.
One definition of an artifact - a program designed to serve a specific use case in a specific point of time forever. It is crafted then left untouched.
By contrast, software to most businesses is a living, breathing beast - we have strict time constraints to implement, modify, adjust to, and tack on features or the business dies. This business of crafting a perfect, beautiful core would require a rewrite of the entire system every time you intended to add a new feature or reinvestigate the model.
Software engineering is, then, a process of compromising - continuously declaring that edge X is the one least likely to shoot yourself in the foot.
-
-
expressjs.com expressjs.com
-
es.redirect([status,] path) Redirects to the URL derived from the specified path, with specified status, a positive integer that corresponds to an HTTP status code. If not specified, status defaults to 302 "Found". res.redirect('/foo/bar') res.redirect('http://example.com') res.redirect(301, 'http://example.com') res.redirect('../login') Redirects can be a fully-qualified URL for redirecting to a different site: res.redirect('http://google.com') Redirects can be relative to the root of the host name. For example, if the application is on http://example.com/admin/post/new, the following would redirect to the URL http://example.com/admin: res.redirect('/admin') Redirects can be relative to the current URL. For example, from http://example.com/blog/admin/ (notice the trailing slash), the following would redirect to the URL http://example.com/blog/admin/post/new. res.redirect('post/new') Redirecting to post/new from http://example.com/blog/admin (no trailing slash), will redirect to http://example.com/blog/post/new. If you found the above behavior confusing, think of path segments as directories (with trailing slashes) and files, it will start to make sense. Path-relativ
-
-
-
la place de la chiropraxi citons Wikipédia la Fédération Mondiale de chirropractique 00:11:12 WFC est membre de l'OMS depuis 1993 la chiropratique est reconnue comme profession de santé complémentaire par le Comité international olympique depuis 00:11:25 1992 la chiropratique est en 2009 la 3e profession de santé aux États-Unis après la médecine générale et la chirurgie dentaire en France la chyopraxie est 00:11:37 reconnue depuis la loi du 4 mars 2002 cette pratique est rattachée au code de la santé publique par l'article 75 comme profession de santé fin de citations de 00:11:48 Wikipédia
-
-
www.biorxiv.org www.biorxiv.org
-
Note: This response was posted by the corresponding author to Review Commons. The content has not been altered except for formatting.
Learn more at Review Commons
Reply to the reviewers
Manuscript number: RC-2023-02218R
Corresponding author(s): Steven, McMahon
1. General Statements [optional]
*We were pleased to receive the encouraging critiques and very much appreciate the Reviewer's specific comments and suggestions. In this revised version of our manuscript, we have made a number of substantive additions and modifications in response to these comments/suggestions. We hope you agree that the study is now improved to the point where it is suitable for publication. *
2. Point-by-point description of the revisions
Reviewer #1 (Evidence, reproducibility and clarity (Required)):
Summary This study describes efforts to characterize differences in the roles of the two related human decapping factors Dcp1a and Dcp1b by assessing mRNA decay and protein associations in knockdown and knockout cell lines. The authors conclude that these proteins are non-redundant based on the observations that loss of DCp1a versus Dcp1b impacts the decapping complex (interactome) and the transcriptome differentially.
Major comments • While the experiments appear to be well designed and executed and the data of generally high quality, the conclusions are drawn without sufficient consideration for the fact that these two proteins form a heterotrimeric complex. The authors assume that there are distinct homotrimeric complexes rather than a single complex with both proteins in. Homotrimers may have new/different functions not normally seen when both proteins are expressed. Thus while it is acceptable to infer that the functions of these two proteins within the decapping complex are distinct, it is not clear that they act separately, or that complexes naturally exist without one or the other. A careful evaluation of the relative ratios of Dcp1a and b overall and in decapping complexes would be informative if the authors want to make stronger statements about the roles of these two factors.
RESPONSE: Thank you for this valuable comment. We have substantially edited the manuscript to incorporate these points. Examples include a detailed analysis of iBAQ values for the DDX6, DCP1a, and DCP1b interactomes (which now allows us to estimate the ratios of DCP1a and DCP1b in these complexes) and cellular fractionation to interrogate complex integrity (using Superose 6).
- The concept of buffering is not adequately introduced and the interpretation of observations that RNAs with increased half life do not show increased protein abundance - that Dcp1a/b are involved in transcript buffering is nebulous. In order to support this interpretation, the mRNA abundances (NOT protein abundances) should be assessed, and even then, there is no way to rule out indirect effects. RESPONSE: Thank you for this comment. In the revised version of the manuscript, we introduced the concept of transcript buffering at an earlier stage as one of the potential explanations for our findings. We were also able to use a new algorithm (grandR) to estimate half-lives and synthesis rates from our data. These new data add strength to the argument that DCP1a and DCP1b are linked to transcript buffering pathways.
• It might be interesting to see what happens when both factors are depleted to get an idea of the overall importance of each one.
RESPONSE: In our work we tried to emphasize the differences between the two paralogs. We believe that doing double knockout or knockdown would mask the distinct impacts of the paralogs. In data not included in this study, we have shown that cells lacking both DCP1a and DCP1b are viable. We did check PARP cleavage in the CRISPR generated cell pools of DCP1a KO, DCP1b KO, and the double KO. The WB measuring the PARP cleavage is shown in the supplemental material (Supplementary Material: Replicates)
• The algorithms etc used for data analysis should be included at the time of publication. Version number and settings used for SMART to define protein domains, and webgestalt should be indicated
RESPONSE: We apologize for this oversight. Version number and settings used for the webtools (SMART, Webgestalt) are now included. The analysis pipeline for half-lives and synthesis rates estimation as well as all the files and the code needed to generate the figures in the paper are available on zenodo (https://zenodo.org/records/10725429).
• Statistical analysis is not provided for the IP experiments, the number of replicates performed is not indicated and quantification of KD efficiency are not provided.
RESPONSE: The number of replicates performed in each experiment is now clearly indicated and quantifications of knockdown efficiency are provided (Supplemental Figure 3A and 3B, Figure 3A, Figure 3B).
• The possibility that the IP Antibody interferes with protein-protein interactions is not mentioned.
RESPONSE: Thank you for this comment. The revised manuscript includes a discussion of the antibody epitope location and the potential for impact on protein-protein interactions.
Minor comments • P4 - "This translational repression of mRNA associated with decapping can be reversed, providing another point at which gene expression can be regulated (21)" - implies that decapping can be reversed or that decapped RNAs are translated. I don't think this is technically true.
RESPONSE: There have been several studies that document the reversal of decapping. These findings are summarized in the following reviews.
Schoenberg, D. R., & Maquat, L. E. (2009). Re-capping the message. Trends in biochemical sciences, 34(9), 435-442.
Trotman, J. B., & Schoenberg, D. R. (2019). A recap of RNA recapping. Wiley Interdisciplinary Reviews: RNA, 10(1), e1504.
-
P11 - how common is it for higher eukaryotes to have 2 DCP genes? *RESPONSE: Metazoans have 2 DCP1 genes. *
-
Fig S1 - says "mammalian tissues" in the text but the data is all human. The statement that "expression analyses revealed that DCP1a and DCP1b have concordant rather than reciprocal expression patterns across different mammalian tissues (Supplemental Figure 1)" is a bit misleading as no evidence for correlation or anti-correlation is provided. Also co-expression is not strong support for the idea that these genes have non-redundant functions. Both genes are just expressed in all tissues - there's no evidence provided that they are concordantly expressed. In bone marrow it may be worth noting that one is high and the other low - i.e. reciprocal. *RESPONSE: We appreciate this comment. We have corrected the interpretation of the aforementioned dataset. We have also incorporated a more detailed discussion in the text of the paper. As the Reviewer pointed out, there are a subset of tissues where their expression appears to be reciprocal. *
-
Fig 1A - it is not clear what the different colors mean. Does Sc DCP1 have 1 larger EVH or 2 distinct ones. Are the low complexity regions in Sc DCP2 the SLiMs. *RESPONSE: Thank you for this comment. We have corrected this ambiguity to reflect that Sc DCP1 has one EVH1 domain that is interconnected by a flexible hinge. The low-complexity regions typically contain short linear motifs (SLIMs), however, not all low-complexity regions have been verified to contain them. In the figure, only low-complexity regions are shown. The text of the paper refers only to verified SLIMs . *
-
P11 - why were HCT116 cells selected? RESPONSE: HCT116 cells are an easily transfectable human cell line and have been widely used in biochemical and molecular studies, including studies of mRNA decapping (see references below). Since decapping is impacted by viral proteins we avoided the use of other commonly used cell models such as HEK293T or HeLa.
https://pubmed.ncbi.nlm.nih.gov/?term=decapping+hct116&sort=date&size=200
-
Fig 1B - what are the asterisks by the RNA names? Might be worth noting that over-expression of DCP1b reduced IP of DCP1a. There's no quantification and no indication of the number of times this experiment was repeated. Data from replicates and quantification of the knockdown efficiency in each replicate would be nice to see. *RESPONSE: Thank you for this comment. Asterisks indicate that those bands were from a second gel, as DCP1a and DCP1b run at approximately the same molecular weight. We have now included a note in our figure legend to indicate this. The knockdown efficiency is provided (Figure 3 and Supplemental Figure 3). We also noted the number of replicas for each IP in figure 1. The replicas are provided as supplementary material (Supplementary Materials: Replicates). *
-
Fig 1C/1D - why are there 3 bands in the DCP1a blot? Quantification of the IP bands is necessary to say whether there is an effect or not of over-expression/KO. RESPONSE: The additional bands in DCP1a blots are background. When we stained the whole blot for DCP1a, in cells which with complete DCP1a KO cells (clone A3), these bands still appear (Supplementary Material: Validation of the KO clones). Quantifications of the bands in the overexpression experiments is now provided.
-
Fig 3 - is it possible that differences are due to epitope positions for the antibodies used for IP? RESPONSE: We do not believe so. DCP1a antibody binds roughly 300-400 residues on DCP1a, and DCP1b antibody binds around Val202. Antibodies therefore do not bind DCP1a or DCP1b low-complexity regions (which are largely responsible for interacting with the decapping complex interactome). Antibodies don't bind the EVH1 domains or the trimerization domain, which are needed for their interaction with DCP2 and each other.
-
Fig 5A - the legend doesn't match the colors in the figure. It is not clear how the pRESPONSE: Thank you for this comment. We have corrected this issue in the revised version of the paper. High-confidence proteins are those with pRESPONSE: Thank you for this comment. We have corrected this issue in the revised version of the paper.*
-
There are a few more recent studies on buffering that should be cited and more discussion of this in the introduction is necessary if conclusions are going to be drawn about buffering. *RESPONSE: We have included a discussion of transcript buffering in the introduction. *
-
The heatmaps in figure 2 are hard to interpret. RESPONSE: To clarify the heatmaps, we included a more detailed description in the figure legends, have enlarged the heatmaps themselves, and have added more extensive labeling.
Reviewer #1 (Significance (Required)):
• Strengths: The experiments appear to be done well and the datasets should be useful for the field. • Limitations: The results are overinterpreted - different genes are affected by knocking down one or other of these two similar proteins but this does not really tell us all that much about how the two proteins are functioning in a cell where both are expressed. • Audience: This study will appeal most to a specialized audience consisting of those interested in the basic mechanisms of mRNA decay. Others may find the dataset useful. • This study might complement and/or be informed by another recent study in BioRXiv - https://doi.org/10.1101/2023.09.04.556219 • My field of expertise is mRNA decay - I am qualified to evaluate the findings within the context of this field. I do not have much experience of LC-MS-MS and therefore cannot evaluate the methods/analysis of this part of the study.
Reviewer #2 (Evidence, reproducibility and clarity (Required)):
The authors provide evidence that Dcp1a and Dcp1b - two paralogous proteins of the mRNA decapping complex - may have divergent functions in a cancer cell line. In the first part, the authors show that interaction of Dcp2 with EDC4 is diminished upon depletion of Dcp1a but not affected by depletion of Dcp1b. The results have been controlled by overexpression of Dcp1b as it may be limiting factor (i.e. expression levels too low to compensate for depletion of Dcp1a reduced interaction with EDC3/4 while depletion of Dcp1b lead to opposite and increase interactions). They then defined the protein interactome of DDX6 in parental and Dcp1a or Dcp1b depleted cells. Here, the authors show some differential association with EDC4 again, which is along results shown in the first part. The authors further performed SLAM-seq and identified subsets of mRNA whose decay rates are common but also different upon depletion with Dcp1a and Dcp1b. Interestingly, it seems that Dcp1a preferentially targets mRNAs for proteins regulating lymphocyte differentiation. To further test whether changes in RNA decay rates are also reflected at the protein levels, they finally performed an MS analysis with Dcp1a/b depleted cells. However no significant overlap with mRNAs showing altered stability could be observed; and the authors suggested that the lack of congruence reflects translational repression.
Major comments: 1. While functional difference between Dcp1a and Dcp1b are interesting and likely true, there are overinterpretations that need correction or further evidence for support. Sentences like "DCP1a regulates RNA cap binding proteins association with the decapping complex and DCP1b controls translational initiation factors interactions (Figure 2E)" sound misleading. While differential association with proteins has been recognised with MS-data, it does not necessary implement an active process of control/regulation. To make the claim on 'control/regulation', and inducible system or introduction of mutants would be required.
RESPONSE: This set of comments were particularly useful in helping us refine the presentation of our findings. We have edited our manuscript to be more specific about the limits of our data.
- The MS analysis is not clearly described in the text and it is unclear how authors selected high-confident proteins. The reader needs to consider the supplemental tables to find out what controls were used. Furthermore, the authors should show correlation plots of MS data between replicates. For instance, there seems to be limited correlation among some of the replicates (e.g. Dcp1b_ko3 sample, Fig. 2c). Any explanation in this variance?
*RESPONSE: We have now included a clear description of how all high-confidence proteins were selected in the Methods and Results sections. The revised manuscript also includes a more thorough description of the controls used and the number of replicates for individual experiments. The PCA plots have now been included where appropriate. The variance in this sample is likely technical. *
- GO analysis for the proteome analysis should consider the proteome and not the genome as the background. The authors should also indicate the corrected P-values (multiple testing) FDRs.
*RESPONSE: Webgestalt uses a reference set of IDs to recognize the input IDs, and it does not use it for the background analysis in the classical sense. We repeated a subset of our proteome analyses using the 'genome-protein coding' as background and obtained the same result as in our original analysis. All ontology analyses now include raw p-values and/or FDRs when appropriate. *
- Fig 2E. The figures display GO enrichments needs better explanation and additional data can be added. The enrichment ratio is not explained (is this normalised?) and p-values and FDRs, number of proteins in respective GO category should be added. *RESPONSE: More thorough explanations of the GO enrichments are now included. The supplemental data contains all p-values (raw and adjusted), as well as the number of proteins in each GO category. The Enrichment ratio is normalized and contains information about the number of proteins that are redundant in multiple groups. GO Ontology analyses are now displayed with p-values and/or FDR values, and in this case the enrichment ratio contains information regarding the number of proteins found in our input set and the number of expected proteins in the GO group. The network analysis shows the FDR values and the number of proteins found in the groups compared. *
Minor: 5. These studies were performed in a colorectal carcinoma cell line (HCT116). The authors should justify the choice of this specialised cell line. Furthermore, one wonders whether similar conclusions can be drawn with other cell lines or whether findings are specific to this cancer line.
RESPONSE: The study that is currently in pre-print in BioRxiv (https://doi.org/10.1101/2023.09.04.556219*) utilized HEK293Ts and found similar results to ours when examining the various relationships between the core decapping core members. *
-
Fig. 1B. It is unclear what DCP1b* refers to? There are bands of different size that are not mentioned by the authors - are those protein isoforms or what are those referring to? A molecular marker should be added to each Blots. Uncropped Western images and markers should be provided in the Supplement. *RESPONSE: The asterisk indicates that these images came from a second western blot gel (DCP1a and DCP1b have a similar molecular weight and cannot be probed on the same membrane). Uncropped western blot images and markers (as available) are provided in the supplement. *
-
MS data submitted to public repository with access. No. indicated in the manuscript.
RESPONSE: MS data is submitted as supplementary datasets to the paper. It contains the analyzed data as well as the LCMSMS output. We are in the process of submitting the raw LSMSMS data to a public repository.
Fig 3. A Venn Diagram displaying the overlap of identified proteins should be added. GO analysis should be done considering the proteome as background (as mentioned above).
*RESPONSE: A Venn diagram showing the overlap among the proteins identified is now included in the revised version. *
Reviewer #2 (Significance (Required)):
Overall, this is a large-scale integrative -omics study that suggest functional difference between Dcp1 paralogues. While it seems clear that both paralogous have some different functions and impact, there are overinterpretations in place and further evidence would to be provided to substantiate conclusions made in the paper. For instance, while the interactions with Dcp2/Ddx6 in the absence of Dcp1a,b with EDC4/3 may be altered (Fig. 1, 2), the functional implications of this changed associations remains unresolved and not further discussed. As such, it remains somehow disconnected with the following experiments and compromises the flow of the study. The observed differences in decay-rates for distinct functionally related sets of mRNAs is interesting; however, it remains unclear whether those are direct or rather indirect effects. This is further obscured by the absence of any correlation to changes in protein levels, which the authors interpreted as 'transcriptional buffering'. In this regard, it is puzzling how the authors can make a statement about transcriptional buffering? While this may be an interesting aspect and concept of the discussion, there is no primary data showing such a functional impact.
As such, the study is interesting as it claims functional differences between DCP1a/b paralogous in a cancer cell line. Nevertheless, I am not sure how trustful the MS analysis and decay measurements are as there is not further validation. It woudl be interesting if the authors could go a bit further and draw some hypothesis how the selectivty could be achieved i.e interaction with RNA-binding proteins that may add some specificity towards the target RNAs for differential decay. As such, the study remains unfortunately rather descriptive without further functional insight.
Reviewer #3 (Evidence, reproducibility and clarity (Required)):
Review on "Non-redundant roles for the human mRNA decapping cofactor paralogs DCP1a and DCP1b" by Steven McMahon and co-workers mRNA decay is a critical step in the regulation of gene expression. In eukaryotes, mRNA turnover typically begins with the removal of the poly(A) tail, followed by either removal of the 5' cap structure or exonucleolytic 3'-5' decay catalyzed by the exosome. The decapping enzyme DCP2 forms a complex with its co-activator DCP1, which enhances decapping activity. Mammals are equipped with two DCP1 paralogs, namely DCP1a and DCP1b. Metazoans' decapping complexes feature additional components, such as enhancer of decapping 4 (EDC4), which supports the interaction between DCP1 and DCP2, thereby amplifying the efficiency of decapping. This work focuses on DCP1a and DCP1b and investigates their distinct functions. Using DCP1a- and DCP1a-specific knockdowns as well as K.O. cell lines, the authors find surprising differences between the DCP1 paralogs. While DCP1a is essential for the assembly of EDC4-containig decapping complexes and interactions with mRNA cap binding proteins, DCP1b mediates interactions with the translational machinery. Furthermore, DCP1a and DCP1b target different mRNAs for degradation, indicating that they execute non-overlapping functions. The findings reported here expand our understanding of mRNA decapping in human cells, shedding light on the unique contributions of DCP1a and DCP1b to mRNA metabolism. The manuscript tackles an interesting subject. Historically, the emphasis has been on studying DCP1a, while DCP1b has been deemed a functionally redundant homolog of DCP1a. Therefore, it is commendable that the authors have taken on this topic and, with the help of knockout cell lines, aimed to dissect the function of DCP1a and DCP1b. Despite recognizing the significance of the subject and approach, the manuscript falls short of persuading me. Following a promising start in Figure 1 (which still has room for improvement), there is a distinct decline in overall quality, with only relatively standard analyses being conducted. However, I do not want to give the authors a detailed advice on maximizing the potential of their data and presenting it convincingly. So, here are just a few key points for improvement: Figure 1C: Upon closer examination, a faint band is still visible at the size of DCP1a in the DCP1a knockout cells. Could this be leaky expression of DCP1a? The authors should provide an in-depth characterization of their cells (possibly as supplementary material), including identification of genomic changes (e.g. by sequencing of the locus) and Western blots with longer exposure, etc.
*RESPONSE: Thank you for this comment. The in-depth characterization of our cells is now included in the Supplementary Material. DCP1a KO cells and DCP1b KO cells indicated as single cell clones have been confirmed to have no DCP1a or DCP1b expression. In Figure 1D and Figure 3, polyclonal pool cells were used as indicated (only for DCP1a KO). *
Figure 2: It is great to see that the effects of the KOs are also visible in the DDX6 immunoprecipitation. However, I wonder if the IP clearly confirms that the KO cells indeed do not express DCP1a or DCP1b. In the heatmap in Figure 2B, it appears as if the proteins are only reduced by a log2-fold change of approximately 1.5? Additionally, Figure 2 shows a problem that persists in the subsequent figures. The visual presentation is not particularly appealing, and essential details, such as the scale of the heatmap in 2B (is it log2 fold?), are lacking.
*RESPONSE: The in-depth characterization of our cells is included in the Supplementary Materials and confirms the presence of single-cell clones where indicated. As noted above, only Figure 1D and Figure 3 used DCP1a KO pooled cells. The heatmap in Figure 2B is scaled by row using the pheatfunction in R studio. The actual data for the heatmap comes from protein intensities from the LC-MS/MS analysis. We have improved the visual presentation in the revised manuscript. *
Figure 3: I wonder why there are no primary data shown here, only processed GO analyses. Wouldn't one expect that DCP2 interacts mainly with DCP1a, but less with DCP1b? Is this visible in the data? Moreover, such analyses are rather uninformative (as reflected in the GO terms themselves, for instance, "oxoglutarate dehydrogenase complex" doesn't provide much meaningful insight). The authors should rather try to derive functional and mechanistic insights from their data.
RESPONSE: We have now revised this Figure to include primary data as well as the IP of DCP1a in DCP1b KO cells (single cell clones) and the IP of DCP1b in DCP1a KO cells (pooled cells). We identified EDC3 in the high-confidence protein pool. The EDC3:DCP1a interaction is enhanced in DCP1b KO cells. We also found that the EDC3:DCP1b interaction is less abundant in DCP1a KO cells. This is consistent with our data in Figures 1 and 2. DCP2 was not identified in the interactomes of either DCP1a or DCP1b. This is not unusual as DCP2 is highly flexible and the association between DCP1s with DCP2 is transient and facilitated by other proteins.
In Fig. 4 the potential of the approach is not fully exploited. Firstly, I would advocate for omitting the GO analyses, as, in my opinion, they offer little insight. Again, crucial information is missing to assess the results. While 75 nt reads are mentioned in the methods, the sequencing depth remains unspecified. Figure 4b should be included in the supplements. Furthermore, I strongly recommend concentrating on insights into the mechanisms of DCP1a and DCP1b-containing complexes. E.g. what characteristics distinguish DCP1a and DCP1b-dependent mRNAs? Are these targets inherently unstable? Why are they degraded? Are they known decapping substrates?
*RESPONSE: Thank you for this comment. We have now revised this figure and have included information about sequencing depth and other pertinent information. We have been able to use a newly available algorithm (grandR) and were able to estimate half-lives and synthesis rates. This is a significant addition to the paper. We were also able to compare significantly impacted mRNAs (by DCP1a or DCP1b loss) to the established DCP2 target list. *
In general, I suggest the authors revise the manuscript with a focus on the potential readers. Reduce Gene Ontology (GO) analyses and heatmaps, and instead, incorporate more analyses regarding the molecular processes associated with the different decapping complexes.
*RESPONSE: We removed selected GO analyses and heatmaps from the main body of the manuscript (included as Supplementary Figures instead). For our LC-MS/MS datasets, we added iBAQ analyses of the DDX6 IP, DCP1a IP, and DCP1b IP in the control conditions. Cellular fractionation studies (using Superose 6 chromatography) were also added to the paper and allow us to interrogate decapping complex composition in more detail. The revised version of the manuscript includes a new 4SU labeling experiment (pulse-chase) as well as estimation of half-lives and synthesis rates in our conditions. Also included is relevant information about DCP1b transcriptional regulation. *
Reviewer #3 (Significance (Required)):
The manuscript in its current form could benefit from substantial revisions for it to be considered impactful for researchers in the field.
-
-
www.biorxiv.org www.biorxiv.org
-
Note: This response was posted by the corresponding author to Review Commons. The content has not been altered except for formatting.
Learn more at Review Commons
Reply to the reviewers
*Reviewer #1 (Evidence, reproducibility and clarity (Required)):
I have trialled the package on my lab's data and it works as advertised. It was straightforward to use and did not require any special training. I am confident this is a tool that will be approachable even to users with limited computational experience. The use of artificial data to validate the approach - and to provide clear limits on applicability - is particularly helpful.
The main limitation of the tool is that it requires the user to manually select regions. This somewhat limits the generalisability and is also more subjective - users can easily choose "nice" regions that better match with their hypothesis, rather than quantifying the data in an unbiased manner. However, given the inherent challenges in quantifying biological data, such problems are not easily circumventable.
*
* I have some comments to clarify the manuscript:
- A "straightforward installation" is mentioned. Given this is a Method paper, the means of installation should be clearly laid out.*
__This sentence is now modified. In the revised manuscript we now describe how to install the toolset and we give the link to the toolset website if further information is needed. __On this website, we provide a full video tutorial and a user manual. The user manual is provided as a supplementary material of the manuscript.
* It would be helpful if there was an option to generate an output with the regions analysed (i.e., a JPG image with the data and the drawn line(s) on top). There are two reasons for this: i) A major problem with user-driven quantification is accidental double counting of regions (e.g., a user quantifies a part of an image and then later quantifies the same region). ii) Allows other users to independently verify measurements at a later time.*
We agree that it is helpful to save the analyzed regions. To answer this comment and the other two reviewers' comments pointing at a similar feature, we have now included an automatic saving of the regions of interest. The user will be able to reopen saved regions of interest using a new function we included in the new version of PatternJ.
* 3. Related to the above point, it is highlighted that each time point would need to be analysed separately (line 361-362). It seems like it should be relatively straightforward to allow a function where the analysis line can be mapped onto the next time point. The user could then adjust slightly for changes in position, but still be starting from near the previous timepoint. Given how prevalent timelapse imaging is, this seems like (or something similar) a clear benefit to add to the software.*
We agree that the analysis of time series images can be a useful addition. We have added the analysis of time-lapse series in the new version of PatternJ. The principles behind the analysis of time-lapse series and an example of such analysis are provided in Figure 1 - figure supplement 3 and Figure 5, with accompanying text lines 140-153 and 360-372. The analysis includes a semi-automated selection of regions of interest, which will make the analysis of such sequences more straightforward than having to draw a selection on each image of the series. The user is required to draw at least two regions of interest in two different frames, and the algorithm will automatically generate regions of interest in frames in which selections were not drawn. The algorithm generates the analysis immediately after selections are drawn by the user, which includes the tracking of the reference channel.
* Line 134-135. The level of accuracy of the searching should be clarified here. This is discussed later in the manuscript, but it would be helpful to give readers an idea at this point what level of tolerance the software has to noise and aperiodicity.
*
We agree with the reviewer that a clarification of this part of the algorithm will help the user better understand the manuscript.__ We have modified the sentence to clarify the range of search used and the resulting limits in aperiodicity (now lines 176-181). __Regarding the tolerance to noise, it is difficult to estimate it a priori from the choice made at the algorithm stage, so we prefer to leave it to the validation part of the manuscript. We hope this solution satisfies the reviewer and future users.
*
**Referees cross-commenting**
I think the other reviewer comments are very pertinent. The authors have a fair bit to do, but they are reasonable requests. So, they should be encouraged to do the revisions fully so that the final software tool is as useful as possible.
Reviewer #1 (Significance (Required)):
Developing software tools for quantifying biological data that are approachable for a wide range of users remains a longstanding challenge. This challenge is due to: (1) the inherent problem of variability in biological systems; (2) the complexity of defining clearly quantifiable measurables; and (3) the broad spread of computational skills amongst likely users of such software.
In this work, Blin et al., develop a simple plugin for ImageJ designed to quickly and easily quantify regular repeating units within biological systems - e.g., muscle fibre structure. They clearly and fairly discuss existing tools, with their pros and cons. The motivation for PatternJ is properly justified (which is sadly not always the case with such software tools).
Overall, the paper is well written and accessible. The tool has limitations but it is clearly useful and easy to use. Therefore, this work is publishable with only minor corrections.
*We thank the reviewer for the positive evaluation of PatternJ and for pointing out its accessibility to the users.
*
Reviewer #2 (Evidence, reproducibility and clarity (Required)):
# Summary
The authors present an ImageJ Macro GUI tool set for the quantification of one-dimensional repeated patterns that are commonly occurring in microscopy images of muscles.
# Major comments
In our view the article and also software could be improved in terms of defining the scope of its applicability and user-ship. In many parts the article and software suggest that general biological patterns can be analysed, but then in other parts very specific muscle actin wordings are used. We are pointing this out in the "Minor comments" sections below. We feel that the authors could improve their work by making a clear choice here. One option would be to clearly limit the scope of the tool to the analysis of actin structures in muscles. In this case we would recommend to also rename the tool, e.g. MusclePatternJ. The other option would be to make the tool about the generic analysis of one-dimensional patterns, maybe calling the tool LinePatternJ. In the latter case we would recommend to remove all actin specific wordings from the macro tool set and also the article should be in parts slightly re-written.
*
We agree with the reviewer that our initial manuscript used a mix of general and muscle-oriented vocabulary, which could make the use of PatternJ confusing especially outside of the muscle field. To make PatternJ useful for the largest community, we corrected the manuscript and the PatternJ toolset to provide the general vocabulary needed to make it understandable for every biologist. We modified the manuscript accordingly.
* # Minor/detailed comments
# Software
We recommend considering the following suggestions for improving the software.
## File and folder selection dialogs
In general, clicking on many of the buttons just opens up a file-browser dialog without any further information. For novel users it is not clear what the tool expects one to select here. It would be very good if the software could be rewritten such that there are always clear instructions displayed about which file or folder one should open for the different buttons.*
We experienced with the current version of macOS that the file-browser dialog does not display any message; we suspect this is the issue raised by the reviewer. This is a known issue of Fiji on Mac and all applications on Mac since 2016. We provided guidelines in the user manual and on the tutorial video to correct this issue by changing a parameter in Fiji. Given the issues the reviewer had accessing the material on the PatternJ website, which we apologize for, we understand the issue raised. We added an extra warning on the PatternJ website to point at this problem and its solution. Additionally, we have limited the file-browser dialog appearance to what we thought was strictly necessary. Thus, the user will experience fewer prompts, speeding up the analysis.
*
## Extract button
The tool asks one to specify things like whether selections are drawn "M-line-to-M-line"; for users that are not experts in muscle morphology this is not understandable. It would be great to find more generally applicable formulations. *
We agree that this muscle-oriented vocabulary can make the use of PatternJ confusing. We have now corrected the user interface to provide both general and muscle-specific vocabulary ("center-to-center or edge-to-edge (M-line-to-M-line or Z-disc-to-Z-disc)").*
## Manual selection accuracy
The 1st step of the analysis is always to start from a user hand-drawn profile across intensity patterns in the image. However, this step can cause inaccuracy that varies with the shape and curve of the line profile drawn. If not strictly perpendicular to for example the M line patterns, the distance between intensity peaks will be different. This will be more problematic when dealing with non-straight and parallelly poised features in the image. If the structure is bended with a curve, the line drawn over it also needs to reproduce this curve, to precisely capture the intensity pattern. I found this limits the reproducibility and easy-usability of the software.*
We understand the concern of the reviewer. On curved selections this will be an issue that is difficult to solve, especially on "S" curved or more complex selections. The user will have to be very careful in these situations. On non-curved samples, the issue may be concerning at first sight, but the errors go with the inverse of cosine and are therefore rather low. For example, if the user creates a selection off by 5 degrees, which is visually obvious, lengths will be affected by an increase of only 0.38%. The point raised by the reviewer is important to discuss, and we therefore added a paragraph to comment on the choice of selection (lines 94-98) and a supplementary figure to help make it clear (Figure 1 - figure supplement 1).*
### Reproducibility
Since the line profile drawn on the image is the first step and very essential to the entire process, it should be considered to save together with the analysis result. For example, as ImageJ ROI or ROIset files that can be re-imported, correctly positioned, and visualized in the measured images. This would greatly improve the reproducibility of the proposed workflow. In the manuscript, only the extracted features are being saved (because the save button is also just asking for a folder containing images, so I cannot verify its functionality). *
We agree that this is a very useful and important feature. We have added ROI automatic saving. Additionally, we now provide a simplified import function of all ROIs generated with PatternJ and the automated extraction and analysis of the list of ROIs. This can be done from ROIs generated previously in PatternJ or with ROIs generated from other ImageJ/Fiji algorithms. These new features are described in the manuscript in lines 120-121 and 130-132.
*
## ? button
It would be great if that button would open up some usage instructions.
*
We agree with the reviewer that the "?" button can be used in a better way. We have replaced this button with a Help menu, including a simple tutorial showing a series of images detailing the steps to follow by the user, a link to the user website, and a link to our video tutorial.
* ## Easy improvement of workflow
I would suggest a reasonable expansion of the current workflow, by fitting and displaying 2D lines to the band or line structure in the image, that form the "patterns" the author aims to address. Thus, it extracts geometry models from the image, and the inter-line distance, and even the curve formed by these sets of lines can be further analyzed and studied. These fitted 2D lines can be also well integrated into ImageJ as Line ROI, and thus be saved, imported back, and checked or being further modified. I think this can largely increase the usefulness and reproducibility of the software.
*
We hope that we understood this comment correctly. We had sent a clarification request to the editor, but unfortunately did not receive an answer within the requested 4 weeks of this revision. We understood the following: instead of using our 1D approach, in which we extract positions from a profile, the reviewer suggests extracting the positions of features not as a single point, but as a series of coordinates defining its shape. If this is the case, this is a major modification of the tool that is beyond the scope of PatternJ. We believe that keeping our tool simple, makes it robust. This is the major strength of PatternJ. Local fitting will not use line average for instance, which would make the tool less reliable.
* # Manuscript
We recommend considering the following suggestions for improving the manuscript. Abstract: The abstract suggests that general patterns can be quantified, however the actual tool quantifies specific subtypes of one-dimensional patterns. We recommend adapting the abstract accordingly.
*
We modified the abstract to make this point clearer.
* Line 58: Gray-level co-occurrence matrix (GLCM) based feature extraction and analysis approach is not mentioned nor compared. At least there's a relatively recent study on Sarcomeres structure based on GLCM feature extraction: https://github.com/steinjm/SotaTool with publication: *https://doi.org/10.1002/cpz1.462
- *
We thank the reviewer for making us aware of this publication. We cite it now and have added it to our comparison of available approaches.
* Line 75: "...these simple geometrical features will address most quantitative needs..." We feel that this may be an overstatement, e.g. we can imagine that there should be many relevant two-dimensional patterns in biology?!*
We have modified this sentence to avoid potential confusion (lines 76-77).
-
*
-
Line 83: "After a straightforward installation by the user, ...". We think it would be convenient to add the installation steps at this place into the manuscript. *
__This sentence is now modified. We now mention how to install the toolset and we provide the link to the toolset website, if further information is needed (lines 86-88). __On the website, we provide a full video tutorial and a user manual.
* Line 87: "Multicolor images will give a graph with one profile per color." The 'Multicolor images' here should be more precisely stated as "multi-channel" images. Multi-color images could be confused with RGB images which will be treated as 8-bit gray value (type conversion first) images by profile plot in ImageJ. *
We agree with the reviewer that this could create some confusion. We modified "multicolor" to "multi-channel".
* Line 92: "...such as individual bands, blocks, or sarcomeric actin...". While bands and blocks are generic pattern terms, the biological term "sarcomeric actin" does not seem to fit in this list. Could a more generic wording be found, such as "block with spike"? *
We agree with the reviewer that "sarcomeric actin" alone will not be clear to all readers. We modified the text to "block with a central band, as often observed in the muscle field for sarcomeric actin" (lines 103-104). The toolset was modified accordingly.
* Line 95: "the algorithm defines one pattern by having the features of highest intensity in its centre". Could this be rephrased? We did not understand what that exactly means.*
We agree with the reviewer that this was not clear. We rewrote this paragraph (lines 101-114) and provided a supplementary figure to illustrate these definitions (Figure 1 - figure supplement 2).
* Line 124 - 147: This part the only description of the algorithm behind the feature extraction and analysis, but not clearly stated. Many details are missing or assumed known by the reader. For example, how it achieved sub-pixel resolution results is not clear. One can only assume that by fitting Gaussian to the band, the center position (peak) thus can be calculated from continuous curves other than pixels. *
Note that the two sentences introducing this description are "Automated feature extraction is the core of the tool. The algorithm takes multiple steps to achieve this (Fig. S2):". We were hoping this statement was clear, but the reviewer may refer to something else. We agree that the description of some of the details of the steps was too quick. We have now expanded the description where needed.
* Line 407: We think the availability of both the tool and the code could be improved. For Fiji tools it is common practice to create an Update Site and to make the code available on GitHub. In addition, downloading the example file (https://drive.google.com/file/d/1eMazyQJlisWPwmozvyb8VPVbfAgaH7Hz/view?usp=drive_link) required a Google login and access request, which is not very convenient; in fact, we asked for access but it was denied. It would be important for the download to be easier, e.g. from GitHub or Zenodo.
*
We are sorry for issues encountered when downloading the tool and additional material. We thank the reviewer for pointing out these issues that limited the accessibility of our tool. We simplified the downloading procedure on the website, which does not go through the google drive interface nor requires a google account. Additionally, for the coder community the code, user manual and examples are now available from GitHub at github.com/PierreMangeol/PatternJ, and are provided as supplementary material with the manuscript. To our knowledge, update sites work for plugins but not for macro toolsets. Having experience sharing our codes with non-specialists, a classical website with a tutorial video is more accessible than more coder-oriented websites, which deter many users.
* Reviewer #2 (Significance (Required)):
The strength of this study is that a tool for the analysis of one-dimensional repeated patterns occurring in muscle fibres is made available in the accessible open-source platform ImageJ/Fiji. In the introduction to the article the authors provide an extensive review of comparable existing tools. Their new tool fills a gap in terms of providing an easy-to-use software for users without computational skills that enables the analysis of muscle sarcomere patterns. We feel that if the below mentioned limitations could be addressed the tool could indeed be valuable to life scientists interested in muscle patterning without computational skills.
In our view there are a few limitations, including the accessibility of example data and tutorials at sites.google.com/view/patternj, which we had trouble to access. In addition, we think that the workflow in Fiji, which currently requires pressing several buttons in the correct order, could be further simplified and streamlined by adopting some "wizard" approach, where the user is guided through the steps.
*As answered above, the links on the PatternJ website are now corrected. Regarding the workflow, we now provide a Help menu with:
- __a basic set of instructions to use the tool, __
- a direct link to the tutorial video in the PatternJ toolset
- a direct link to the website on which both the tutorial video and a detailed user manual can be found. We hope this addresses the issues raised by this reviewer.
*Another limitation is the reproducibility of the analysis; here we recommend enabling IJ Macro recording as well as saving of the drawn line ROIs. For more detailed suggestions for improvements please see the above sections of our review. *
We agree that saving ROIs is very useful. It is now implemented in PatternJ.
We are not sure what this reviewer means by "enabling IJ Macro recording". The ImageJ Macro Recorder is indeed very useful, but to our knowledge, it is limited to built-in functions. Our code is open and we hope this will be sufficient for advanced users to modify the code and make it fit their needs.*
Reviewer #3 (Evidence, reproducibility and clarity (Required)):
Summary In this manuscript, the authors present a new toolset for the analysis of repetitive patterns in biological images named PatternJ. One of the main advantages of this new tool over existing ones is that it is simple to install and run and does not require any coding skills whatsoever, since it runs on the ImageJ GUI. Another advantage is that it does not only provide the mean length of the pattern unit but also the subpixel localization of each unit and the distributions of lengths and that it does not require GPU processing to run, unlike other existing tools. The major disadvantage of the PatternJ is that it requires heavy, although very simple, user input in both the selection of the region to be analyzed and in the analysis steps. Another limitation is that, at least in its current version, PatternJ is not suitable for time-lapse imaging. The authors clearly explain the algorithm used by the tool to find the localization of pattern features and they thoroughly test the limits of their tool in conditions of varying SNR, periodicity and band intensity. Finally, they also show the performance of PatternJ across several biological models such as different kinds of muscle cells, neurons and fish embryonic somites, as well as different imaging modalities such as brightfield, fluorescence confocal microscopy, STORM and even electron microscopy.
This manuscript is clearly written, and both the section and the figures are well organized and tell a cohesive story. By testing PatternJ, I can attest to its ease of installation and use. Overall, I consider that PatternJ is a useful tool for the analysis of patterned microscopy images and this article is fit for publication. However, i do have some minor suggestions and questions that I would like the authors to address, as I consider they could improve this manuscript and the tool:
*We are grateful to this reviewer for this very positive assessment of PatternJ and of our manuscript.
* Minor Suggestions: In the methodology section is missing a more detailed description about how the metric plotted was obtained: as normalized intensity or precision in pixels. *
We agree with the reviewer that a more detailed description of the metric plotted was missing. We added this information in the method part and added information in the Figure captions where more details could help to clarify the value displayed.
* The validation is based mostly on the SNR and patterns. They should include a dataset of real data to validate the algorithm in three of the standard patterns tested. *
We validated our tool using computer-generated images, in which we know with certainty the localization of patterns. This allowed us to automatically analyze 30 000 images, and with varying settings, we sometimes analyzed 10 times the same image, leading to about 150 000 selections analyzed. From these analyses, we can provide with confidence an unbiased assessment of the tool precision and the tool capacity to extract patterns. We already provided examples of various biological data images in Figures 4-6, showing all possible features that can be extracted with PatternJ. In these examples, we can claim by eye that PatternJ extracts patterns efficiently, but we cannot know how precise these extractions are because of the nature of biological data: "real" positions of features are unknown in biological data. Such validation will be limited to assessing whether a pattern was found or not, which we believe we already provided with the examples in Figures 4-6.
* The video tutorial available in the PatternJ website is very useful, maybe it would be worth it to include it as supplemental material for this manuscript, if the journal allows it. *
As the video tutorial may have been missed by other reviewers, we agree it is important to make it more prominent to users. We have now added a Help menu in the toolset that opens the tutorial video. Having the video as supplementary material could indeed be a useful addition if the size of the video is compatible with the journal limits.
* An example image is provided to test the macro. However, it would be useful to provide further example images for each of the three possible standard patterns suggested: Block, actin sarcomere or individual band.*
We agree this can help users. We now provide another multi-channel example image on the PatternJ website including blocks and a pattern made of a linear intensity gradient that can be extracted with our simpler "single pattern" algorithm, which were missing in the first example. Additionally, we provide an example to be used with our new time-lapse analysis.
* Access to both the manual and the sample images in the PatternJ website should be made publicly available. Right now they both sit in a private Drive account. *
As mentioned above, we apologize for access issues that occurred during the review process. These files can now be downloaded directly on the website without any sort of authentication. Additionally, these files are now also available on GitHub.
* Some common errors are not properly handled by the macro and could be confusing for the user: When there is no selection and one tries to run a Check or Extraction: "Selection required in line 307 (called from line 14). profile=getProfile( ;". A simple "a line selection is required" message would be useful there. When "band" or "block" is selected for a channel in the "Set parameters" window, yet a 0 value is entered into the corresponding "Number of bands or blocks" section, one gets this error when trying to Extract: "Empty array in line 842 (called from line 113). if ( ( subloc . length == 1 ) & ( subloc [ 0 == 0) ) {". This error is not too rare, since the "Number of bands or blocks" section is populated with a 0 after choosing "sarcomeric actin" (after accepting the settings) and stays that way when one changes back to "blocks" or "bands".*
We thank the reviewer for pointing out these bugs. These bugs are now corrected in the revised version.
* The fact that every time one clicks on the most used buttons, the getDirectory window appears is not only quite annoying but also, ultimately a waste of time. Isn't it possible to choose the directory in which to store the files only once, from the "Set parameters" window?*
We have now found a solution to avoid this step. The user is only prompted to provide the image folder when pressing the "Set parameter" button. We kept the prompt for directory only when the user selects the time-lapse analysis or the analysis of multiple ROIs. The main reason is that it is very easy for the analysis to end up in the wrong folder otherwise.
* The authors state that the outputs of the workflow are "user friendly text files". However, some of them lack descriptive headers (like the localisations and profiles) or even file names (like colors.txt). If there is something lacking in the manuscript, it is a brief description of all the output files generated during the workflow.*
PatternJ generates multiple files, several of which are internal to the toolset. They are needed to keep track of which analyses were done, and which colors were used in the images, amongst others. From the user part, only the files obtained after the analysis All_localizations.channel_X.txt and sarcomere_lengths.txt are useful. To improve the user experience, we now moved all internal files to a folder named "internal", which we think will clarify which outputs are useful for further analysis, and which ones are not. We thank the reviewer for raising this point and we now mention it in our Tutorial.
I don't really see the point in saving the localizations from the "Extraction" step, they are even named "temp".
We thank the reviewer for this comment, this was indeed not necessary. We modified PatternJ to delete these files after they are used.
* In the same line, I DO see the point of saving the profiles and localizations from the "Extract & Save" step, but I think they should be deleted during the "Analysis" step, since all their information is then grouped in a single file, with descriptive headers. This deleting could be optional and set in the "Set parameters" window.*
We understand the point raised by the reviewer. However, the analysis depends on the reference channel picked, which is asked for when starting an analysis, and can be augmented with additional selections. If a user chooses to modify the reference channel or to add a new profile to the analysis, deleting all these files would mean that the user will have to start over again, which we believe will create frustration. An optional deletion at the analysis step is simple to implement, but it could create problems for users who do not understand what it means practically.
* Moreover, I think it would be useful to also save the linear roi used for the "Extract & Save" step, and eventually combine them during the "Analysis step" into a single roi set file so that future re-analysis could be made on the same regions. This could be an optional feature set from the "Set parameters" window. *
We agree with the reviewer that saving ROIs is very useful. ROIs are now saved into a single file each time the user extracts and saves positions from a selection. Additionally, the user can re-use previous ROIs and analyze an image or image series in a single step.
* In the "PatternJ workflow" section of the manuscript, the authors state that after the "Extract & Save" step "(...) steps 1, 2, 4, and 5 can be repeated on other selections (...)". However, technically, only steps 1 and 5 are really necessary (alternatively 1, 4 and 5 if the user is unsure of the quality of the patterning). If a user follows this to the letter, I think it can lead to wasted time.
*
We agree with the reviewer and have corrected the manuscript accordingly (line 119-120).
- *
*I believe that the "Version Information" button, although important, has potential to be more useful if used as a "Help" button for the toolset. There could be links to useful sources like the manuscript or the PatternJ website but also some tips like "whenever possible, use a higher linewidth for your line selection" *
We agree with the reviewer as pointed out in our previous answers to the other reviewers. This button is now replaced by a Help menu, including a simple tutorial in a series of images detailing the steps to follow, a link to the user website, and a link to our video tutorial.
* It would be interesting to mention to what extent does the orientation of the line selection in relation to the patterned structure (i.e. perfectly parallel vs more diagonal) affect pattern length variability?*
As answered to reviewer 1, we understand this concern, which needs to be clarified for readers. The issue may be concerning at first sight, but the errors grow only with the inverse of cosine and are therefore rather low. For example, if the user creates a selection off by 3 degrees, which is visually obvious, lengths will be affected by an increase of only 0.14%. The point raised by the reviewer is important to discuss, and we therefore have added a comment on the choice of selection (lines 94-98) as well as a supplementary figure (Figure 1 - figure supplement 1).
* When "the algorithm uses the peak of highest intensity as a starting point and then searches for peak intensity values one spatial period away on each side of this starting point" (line 133-135), does that search have a range? If so, what is the range? *
We agree that this information is useful to share with the reader. The range is one pattern size. We have modified the sentence to clarify the range of search used and the resulting limits in aperiodicity (now lines 176-181).
* Line 144 states that the parameters of the fit are saved and given to the user, yet I could not find such information in the outputs. *
The parameters of the fits are saved for blocks. We have now clarified this point by modifying the manuscript (lines 186-198) and modifying Figure 1 - figure supplement 5. We realized we made an error in the description of how edges of "block with middle band" are extracted. This is now corrected.
* In line 286, authors finish by saying "More complex patterns from electron microscopy images may also be used with PatternJ.". Since this statement is not backed by evidence in the manuscript, I suggest deleting it (or at the very least, providing some examples of what more complex patterns the authors refer to). *
This sentence is now deleted.
* In the TEM image of the fly wing muscle in fig. 4 there is a subtle but clearly visible white stripe pattern in the original image. Since that pattern consists of 'dips', rather than 'peaks' in the profile of the inverted image, they do not get analyzed. I think it is worth mentioning that if the image of interest contains both "bright" and "dark" patterns, then the analysis should be performed in both the original and the inverted images because the nature of the algorithm does not allow it to detect "dark" patterns. *
We agree with the reviewer's comment. We now mention this point in lines 337-339.
* In line 283, the authors mention using background correction. They should explicit what method of background correction they used. If they used ImageJ's "subtract background' tool, then specify the radius.*
We now describe this step in the method section.
*
Reviewer #3 (Significance (Required)):
- Describe the nature and significance of the advance (e.g. conceptual, technical, clinical) for the field. Being a software paper, the advance proposed by the authors is technical in nature. The novelty and significance of this tool is that it offers quick and simple pattern analysis at the single unit level to a broad audience, since it runs on the ImageJ GUI and does not require any programming knowledge. Moreover, all the modules and steps are well described in the paper, which allows easy going through the analysis.
- Place the work in the context of the existing literature (provide references, where appropriate). The authors themselves provide a good and thorough comparison of their tool with other existing ones, both in terms of ease of use and on the type of information extracted by each method. While PatternJ is not necessarily superior in all aspects, it succeeds at providing precise single pattern unit measurements in a user-friendly manner.
- State what audience might be interested in and influenced by the reported findings. Most researchers working with microscopy images of muscle cells or fibers or any other patterned sample and interested in analyzing changes in that pattern in response to perturbations, time, development, etc. could use this tool to obtain useful, and otherwise laborious, information. *
We thank the reviewer for these enthusiastic comments about how straightforward for biologists it is to use PatternJ and its broad applicability in the bio community.
-
Note: This preprint has been reviewed by subject experts for Review Commons. Content has not been altered except for formatting.
Learn more at Review Commons
Referee #2
Evidence, reproducibility and clarity
Summary
The authors present an ImageJ Macro GUI tool set for the quantification of one-dimensional repeated patterns that are commonly occurring in microscopy images of muscles.
Major comments
In our view the article and also software could be improved in terms of defining the scope of its applicability and user-ship. In many parts the article and software suggest that general biological patterns can be analysed, but then in other parts very specific muscle actin wordings are used. We are pointing this out in the "Minor comments" sections below. We feel that the authors could improve their work by making a clear choice here. One option would be to clearly limit the scope of the tool to the analysis of actin structures in muscles. In this case we would recommend to also rename the tool, e.g. MusclePatternJ. The other option would be to make the tool about the generic analysis of one-dimensional patterns, maybe calling the tool LinePatternJ. In the latter case we would recommend to remove all actin specific wordings from the macro tool set and also the article should be in parts slightly re-written.
Minor/detailed comments
Software
We recommend considering the following suggestions for improving the software.
File and folder selection dialogs
In general, clicking on many of the buttons just opens up a file-browser dialog without any further information. For novel users it is not clear what the tool expects one to select here. It would be very good if the software could be rewritten such that there are always clear instructions displayed about which file or folder one should open for the different buttons.
Extract button
The tool asks one to specify things like whether selections are drawn "M-line-to-M-line"; for users that are not experts in muscle morphology this is not understandable. It would be great to find more generally applicable formulations.
Manual selection accuracy
The 1st step of the analysis is always to start from a user hand-drawn profile across intensity patterns in the image. However, this step can cause inaccuracy that varies with the shape and curve of the line profile drawn. If not strictly perpendicular to for example the M line patterns, the distance between intensity peaks will be different. This will be more problematic when dealing with non-straight and parallelly poised features in the image. If the structure is bended with a curve, the line drawn over it also needs to reproduce this curve, to precisely capture the intensity pattern. I found this limits the reproducibility and easy-usability of the software.
Reproducibility
Since the line profile drawn on the image is the first step and very essential to the entire process, it should be considered to save together with the analysis result. For example, as ImageJ ROI or ROIset files that can be re-imported, correctly positioned, and visualized in the measured images. This would greatly improve the reproducibility of the proposed workflow. In the manuscript, only the extracted features are being saved (because the save button is also just asking for a folder containing images, so I cannot verify its functionality).
? button
It would be great if that button would open up some usage instructions.
Easy improvement of workflow
I would suggest a reasonable expansion of the current workflow, by fitting and displaying 2D lines to the band or line structure in the image, that form the "patterns" the author aims to address. Thus, it extracts geometry models from the image, and the inter-line distance, and even the curve formed by these sets of lines can be further analyzed and studied. These fitted 2D lines can be also well integrated into ImageJ as Line ROI, and thus be saved, imported back, and checked or being further modified. I think this can largely increase the usefulness and reproducibility of the software.
Manuscript
We recommend considering the following suggestions for improving the manuscript. Abstract: The abstract suggests that general patterns can be quantified, however the actual tool quantifies specific subtypes of one-dimensional patterns. We recommend adapting the abstract accordingly.
Line 58: Gray-level co-occurrence matrix (GLCM) based feature extraction and analysis approach is not mentioned nor compared. At least there's a relatively recent study on Sarcomeres structure based on GLCM feature extraction: https://github.com/steinjm/SotaTool with publication: https://doi.org/10.1002/cpz1.462
Line 75: "...these simple geometrical features will address most quantitative needs..." We feel that this may be an overstatement, e.g. we can imagine that there should be many relevant two-dimensional patterns in biology?!
Line 83: "After a straightforward installation by the user, ...". We think it would be convenient to add the installation steps at this place into the manuscript.
Line 87: "Multicolor images will give a graph with one profile per color." The 'Multicolor images' here should be more precisely stated as "multi-channel" images. Multi-color images could be confused with RGB images which will be treated as 8-bit gray value (type conversion first) images by profile plot in ImageJ.
Line 92: "...such as individual bands, blocks, or sarcomeric actin...". While bands and blocks are generic pattern terms, the biological term "sarcomeric actin" does not seem to fit in this list. Could a more generic wording be found, such as "block with spike"?
Line 95: "the algorithm defines one pattern by having the features of highest intensity in its centre". Could this be rephrased? We did not understand what that exactly means.
Line 124 - 147: This part the only description of the algorithm behind the feature extraction and analysis, but not clearly stated. Many details are missing or assumed known by the reader. For example, how it achieved sub-pixel resolution results is not clear. One can only assume that by fitting Gaussian to the band, the center position (peak) thus can be calculated from continuous curves other than pixels.
Line 407: We think the availability of both the tool and the code could be improved. For Fiji tools it is common practice to create an Update Site and to make the code available on GitHub. In addition, downloading the example file (https://drive.google.com/file/d/1eMazyQJlisWPwmozvyb8VPVbfAgaH7Hz/view?usp=drive_link) required a Google login and access request, which is not very convenient; in fact, we asked for access but it was denied. It would be important for the download to be easier, e.g. from GitHub or Zenodo.
Significance
The strength of this study is that a tool for the analysis of one-dimensional repeated patterns occurring in muscle fibres is made available in the accessible open-source platform ImageJ/Fiji. In the introduction to the article the authors provide an extensive review of comparable existing tools. Their new tool fills a gap in terms of providing an easy-to-use software for users without computational skills that enables the analysis of muscle sarcomere patterns. We feel that if the below mentioned limitations could be addressed the tool could indeed be valuable to life scientists interested in muscle patterning without computational skills.
In our view there are a few limitations, including the accessibility of example data and tutorials at sites.google.com/view/patternj, which we had trouble to access. In addition, we think that the workflow in Fiji, which currently requires pressing several buttons in the correct order, could be further simplified and streamlined by adopting some "wizard" approach, where the user is guided through the steps. Another limitation is the reproducibility of the analysis; here we recommend enabling IJ Macro recording as well as saving of the drawn line ROIs. For more detailed suggestions for improvements please see the above sections of our review.
-
-
-
Under the new license, cloud service providers hosting Redis offerings will no longer be permitted to use the source code of Redis free of charge. For example, cloud service providers will be able to deliver Redis 7.4 only after agreeing to licensing terms with Redis, the maintainers of the Redis code. These agreements will underpin support for existing integrated solutions and provide full access to forthcoming Redis innovations.
¿Cómo afectará esto a los clientes finales?
Microsoft seguramente comience a ofrecer como alternativa su propio software equivalente a Redis, https://github.com/microsoft/garnet
-
-
www.biorxiv.org www.biorxiv.org
-
Author response:
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public Review):
Summary:
In this manuscript, Bell et al. provide an exhaustive and clear description of the diversity of a new class of predicted type IV restriction systems that the authors denote as CoCoNuTs, for their characteristic presence of coiled-coil segments and nuclease tandems. Along with a comprehensive analysis that includes phylogenetics, protein structure prediction, extensive protein domain annotations, and an in-depth investigation of encoding genomic contexts, they also provide detailed hypotheses about the biological activity and molecular functions of the members of this class of predicted systems. This work is highly relevant, it underscores the wide diversity of defence systems that are used by prokaryotes and demonstrates that there are still many systems to be discovered. The work is sound and backed-up by a clear and reasonable bioinformatics approach. I do not have any major issues with the manuscript, but only some minor comments.
Strengths:
The analysis provided by the authors is extensive and covers the three most important aspects that can be covered computationally when analysing a new family/superfamily: phylogenetics, genomic context analysis, and protein-structure-based domain content annotation. With this, one can directly have an idea about the superfamily of the predicted system and infer their biological role. The bioinformatics approach is sound and makes use of the most current advances in the fields of protein evolution and structural bioinformatics.
Weaknesses:
It is not clear how coiled-coil segments were assigned if only based on AF2-predicted models or also backed by sequence analysis, as no description is provided in the methods. The structure prediction quality assessment is based solely on the average pLDDT of the obtained models (with a threshold of 80 or better). However, this is not enough, particularly when multimeric models are used. The PAE matrix should be used to evaluate relative orientations, particularly in the case where there is a prediction that parts from 2 proteins are interacting. In the case of multimers, interface quality scores, such as the ipTM or pDockQ, should also be considered and, at minimum, reported.
A description of the coiled-coil predictions has been added to the Methods. For multimeric models, PAE matrices and ipTM+pTM scores have been included in Supplementary Data File S1.
Reviewer #2 (Public Review):
Summary:
In this work, using in-depth computational analysis, Bell et al. explore the diverse repertoire of type IV McrBC modification-dependent restriction systems. The prototypical two-component McrBC system has been structurally and functionally characterised and is known to act as a defence by restricting phage and foreign DNA containing methylated cytosines. Here, the authors find previously unanticipated complexity and versatility of these systems and focus on detailed analysis and classification of a distinct branch, the so-called CoCoNut, named after its composition of coiled-coil structures and tandem nucleases. These CoCoNut systems are predicted to target RNA as well as DNA and to utilise defence mechanisms with some similarity to type III CRISPR-Cas systems.
Strengths:
This work is enriched with a plethora of ideas and a myriad of compelling hypotheses that now await experimental verification. The study comes from the group that was amongst the first to describe, characterize, and classify CRISPR-Cas systems. By analogy, the findings described here can similarly promote ingenious experimental and conceptual research that could further drive technological advances. It could also instigate vigorous scientific debates that will ultimately benefit the community.
Weaknesses:
The multi-component systems described here function in the context of large oligomeric complexes. Some of the single chain AF2 predictions shown in this work are not compatible, for example, with homohexameric complex formation due to incompatible orientation of domains. The recent advances in protein structure prediction, in particular AlphaFold2 (AF2) multimer, now allow us to confidently probe potential protein-protein interactions and protein complex formation. This predictive power could be exploited here to produce a better glimpse of these multimeric protein systems. It can also provide a more sound explanation for some of the observed differences amongst different McrBC types.
Hexameric CnuB complexes with CnuC stimulatory monomers for Type I-A, I-B, I-C, II, and III-A CoCoNuT systems have been modeled with AF2 and included in Supplementary Data File S1, albeit without the domains fused to the GTPase N-terminus (with the exception of Type I-B, which lacks the long coiled-coil domain fused to the GTPase and was modeled with its entire sequence). Attempts to model the other full-length CnuB hexamers did not lead to convincing results.
Recommendations for the authors:
Reviewing Editor:
The detailed recommendations by the two reviewers will help the authors to further strengthen the manuscript, but two points seem particularly worth considering: 1. The methods are barely sketched in the manuscript, but it could be useful to detail them more closely. Particularly regarding the coiled-coil segments, which are currently just statists, useful mainly for the name of the family, more detail on their prediction, structural properties, and purpose would be very helpful. 2. Due to its encyclopedic nature, the wealth of material presented in the paper makes it hard to penetrate in one go. Any effort to make it more accessible would be very welcome. Reviewer 1 in particular has made a number of suggestions regarding the figures, which would make them provide more support for the findings described in the text.
A description of the techniques used to identify coiled-coil segments has been added to the Methods. Our predictions ranged from near certainty in the coiled-coils detected in CnuB homologs, to shorter helices at the limit of detection in other factors. We chose to report all probable coiled-coils, as the extensive coiled-coils fused to CnuB, which are often the only domain present other than the GTPase, imply involvement in mediating complex formation by interacting with coiled-coils in other factors, particularly the other CoCoNuT factors. The suggestions made by Reviewer 1 were thoughtful and we made an effort to incorporate them.
Reviewer #1 (Recommendations For The Authors):
I do not have any major issues with the manuscript. I have however some minor comments, as described below.
- The last sentence of the abstract at first reads as a fact and not a hypothesis resulting from the work described in the manuscript. After the second read, I noticed the nuances in the sentence. I would suggest a rephrasing to emphasize that the activity described is a theoretical hypothesis not backed-up by experiments.
This sentence has been rephrased to make explicit the hypothetical nature of the statement.
- In line 64, the authors rename DUF3578 as ADAM because indeed its function is not unknown. Did the authors consider reaching out to InterPro to add this designation to this DUF? A search in interpro with DUF3578 results in "MrcB-like, N-terminal domain" and if a name is suggested, it may be worthwhile to take it to the IntrePro team.
We will suggest this nomenclature to InterPro.
- I find Figure 1E hard to analyse and think it occupies too much space for the information it provides. The color scheme, the large amount of small slices, and the lack of numbers make its information content very small. I would suggest moving this to the supplementary and making it instead a bar plot. If removed from Figure 1, more space is made available for the other panels, particularly the structural superpositions, which in my opinion are much more important.
We have removed Figure 1E from the paper as it adds little information beyond the abundance and phyletic distribution of sequenced prokaryotes, in which McrBC systems are plentiful.
- In Figure 2, it is not clear due to the presence of many colorful "operon schemes" that the tree is for a single gene and not for the full operon segment. Highlighting the target gene in the operons or signalling it somehow would make the figure easy to understand even in the absence of the text and legend. The same applies to Supplementary Figure 1.
The legend has been modified to show more clearly that this is a tree of McrB-like GTPases.
- In line 146, the authors write "AlphaFold-predicted endonucelase fold" to say that a protein contains a region that AF2 predicts to fold like an endonuclease. This is a weird way of writing it and can be confusing to non-expert readers. I would suggest rephrasing for increased clarity.
This sentence has been rephrased for greater clarity.
- In line 167, there is a [47]. I believe this is probably due to a previous reference formatting.
Indeed, this was a reference formatting error and has been fixed.
- In most figures, the color palette and the use of very similar color palettes for taxonomy pie charts, genomic context composition schemes, and domain composition diagrams make it really hard to have a good understanding of the image at first. Legends are often close to each other, and it is not obvious at first which belong to what. I would suggest changing the layouts and maybe some color schemes to make it easier to extract the information that these figures want to convey.
It seemed that Figure 4 was the most glaring example of these issues, and it has been rearranged for easier comprehension.
- In the paragraph that starts at line 199, the authors mention an Ig-like domain that is often found at the N-terminus of Type I CoCoNuTs. Are they all related to each other? How conserved are these domains?
These domains are all predicted to adopt a similar beta-sandwich fold and are found at the N-terminus of most CoCoNuT CnuC homologs, suggesting they are part of the same family, but we did not undertake a more detailed sequenced-based analysis of these regions.
We also find comparable domains in the CnuC/McrC-like partners of the abundant McrB-like NxD motif GTPases that are not part of CoCoNuT systems, and given the similarity of some of their predicted structures to Rho GDP-dissociation inhibitor 1, we suspect that they have coevolved as regulators of the non-canonical NxD motif GTPase type. Our CnuBC multimer models showing consistent proximity between these domains in CnuC and CnuB GTPase domains suggest this could indeed be the case. We plan to explore these findings further in a forthcoming publication.
- In line 210, the authors write "suggesting a role in overcrowding-induced stress response". Why so? In >all other cases, the authors justify their hypothesis, which I really appreciated, but not here.
A supplementary note justifying this hypothesis has been added to Supplementary Data File S1.
- At the end of the paragraph that starts in line 264, the authors mention that they constructed AF2 multimeric models to predict if 2 proteins would interact. However, no quality scores were provided, particularly the PAE matrix. This would allow for a better judgement of this prediction, and I would suggest adding the PAE matrix as another panel in the figure where the 3D model of the complex is displayed.
The PAE matrix and ipTM+pTM scores for this and other multimer models have been added to Supplementary Data File S1. For this model in particular, the surface charge distribution of the model has been presented to support the role of the domains that have a higher PAE in RNA binding.
- In line 306, "(supplementary data)" refers to what part of the file?
This file has been renamed Supplementary Table S3 and referenced as such.
- In line 464, the authors suggest that ShdA could interact with CoCoNuTs. Why not model the complex as done for other cases? what would co-folding suggest?
As we were not able to convincingly model full-length CnuB hexamers with N-terminal coiled-coils, we did not attempt modeling of this hypothetical complex with another protein with a long coiled-coil, but it remains an interesting possibility.
- In line 528, why and how were some genes additionally analyzed with HHPred?
Justification for this analysis has been added to the Methods, but briefly, these genes were additionally analyzed if there were no BLAST hits or to confirm the hits that were obtained.
- In the first section of the methods, the first and second (particularly the second) paragraphs are extremely long. I would suggest breaking them to facilitate reading.
This change has been made.
- In line 545, what do the authors mean by "the alignment (...) were analyzed with HHPred"?
A more detailed description of this step has been added to the Methods.
- The authors provide the models they produced as well as extensive supplementary tables that make their data reusable, but they do not provide the code for the automated steps, as to excise target sequence sections out of multiple sequence alignments, for example.
The code used for these steps has been in use in our group at the NCBI for many years. It will be difficult to utilize outside of the NCBI software environment, but for full disclosure, we have included a zipped repository with the scripts and custom-code dependencies, although there are external dependencies as well such as FastTree and BLAST. In brief, it involves PSI-BLAST detection of regions with the most significant homology to one of a set of provided alignments (seals-2-master/bin/wrappers/cog_psicognitor). In this case, the reference alignments of McrB-like GTPases and DUF2357 were generated manually using HHpred to analyze alignments of clustered PSI-BLAST results. This step provided an output of coordinates defining domain footprints in each query sequence, which were then combined and/or extended using scripts based on manual analysis of many examples with HHpred (footprint_finders/get_GTPase_frags.py and footprint_finders/get_DUF2357_frags.py), then these coordinates were used to excise such regions from the query amino acid sequence with a final script (seals-2-master/bin/misc/fa2frag).
Reviewer #2 (Recommendations For The Authors):
(1) Page 4, line 77 - 'PUA superfamily domains' could be more appropriate to use instead of "EVE superfamily".
While this statement could perhaps be applied to PUA superfamily domains, our previous work we refer to, which strongly supports the assertion, was restricted to the EVE-like domains and we prefer to retain the original language.
(2) Page 5. lines 128-130 - AF2 multimer prediction model could provide a more sound explanation for these differences.
Our AF2 multimer predictions added in this revision indeed show that the NxD motif McrB-like CoCoNuT GTPases interact with their respective McrC-like partners such that an immunoglobulin-like beta-sandwich domain, fused to the N-termini of the McrC homologs and similar to Rho GDP-dissociation inhibitor 1, has the potential to physically interact with the GTPase variants. However, we did not probe this in greater detail, as it is beyond the scope of this already highly complex article, but we plan to study it in the future.
(3) Page 8, line 252 - The surface charge distribution of CnuH OB fold domain looks very different from SmpB (pdb3iyr). In fact, the regions that are in contact with RNA in SmpB are highly acidic in CoCoNut CnuH. Although it looks likely that this domain is involved in RNA binding, the mode of interaction should be very different.
We did not detect a strong similarity between the CnuH SmpB-like SPB domain and PDB 3IYR, but when we compare the surface charge distribution of PDB 1WJX and the SPB domain, while there is a significant area that is positively charged in 1WJX that is negatively charged in SPB, there is much that overlaps with the same charge in both domains.
The similarity between SmpB and the SPB domain is significant, but definitely not exact. An important question for future studies is: If the domains are indeed related due to an ancient fusion of SmpB to an ancestor of CnuH, would this degree of divergence be expected?
In other words, can we say anything about how the function of a stand-alone tmRNA-binding protein could evolve after being fused to a complex predicted RNA helicase with other predicted RNA binding domains already present? Experimental validation will ultimately be necessary to resolve these kinds of questions, but for now, it may be safe to say that the presence of this domain, especially in conjunction with the neighboring RelE-like RTL domain and UPF1-like helicase domain, signals a likely interaction with the A-site of the ribosome, and perhaps restriction of aberrant/viral mRNA.
-
-
-
Here is a detailed summary of the article "Super Charging Fine-Grained Reactive Performance" by Milo:
-
Introduction to Reactivity in JavaScript
- Definition and Importance: "Reactivity allows you to write lazy variables that are efficiently cached and updated, making it easier to write clean and fast code."
- Introduction to Reactively: "I've been working on a new fine grained reactivity library called Reactively inspired by my work on the SolidJS team."
-
Characteristics of Fine-Grained Reactivity Libraries
- Library Examples and Usage: "Fine-grained reactivity libraries... Examples include new libraries like Preact Signals, µsignal, and now Reactively, as well as longer-standing libraries like Solid, S.js, and CellX."
- Functionality and Advantages: "With a library like Reactively, you can easily add lazy variables, caching, and incremental recalculation to your typescript/javascript programs."
-
Core Concepts in Reactively
- Dependency Graphs: "Reactive libraries work by maintaining a graph of dependencies between reactive elements."
- Implementation Example: "import { reactive } from '@reactively/core'; const nthUser = reactive(10);"
-
Goals and Features of Reactive Libraries
- Efficiency and State Consistency: "Efficient: Never overexecute reactive elements... Glitch free: Never allow user code to see intermediate state where only some reactive elements have updated."
-
Comparison Between Lazy and Eager Evaluation
- Evaluation Strategies: "A lazy library... will first ask B then C to update, then update D after the B and C updates have been completed."
- Algorithm Challenges: "The first challenge is what we call the diamond problem... The second challenge is the equality check problem."
-
Algorithm Descriptions
- MobX: "MobX uses a two pass algorithm, with both passes proceeding from A down through its observers... MobX stores a count of the number of parents that need to be updated with each reactive element."
- Preact Signals: "Preact checks whether the parents of any signal need to be updated before updating that signal... Preact also has two phases, and the first phase 'notifies' down from A."
- Reactively: "Reactively uses one down phase and one up phase. Instead of version numbers, Reactively uses only graph coloring."
-
Benchmarking Results
- Performance Observations: "In early experiments with the benchmarking tool, what we've discovered so far is that Reactively is the fastest."
- Framework Comparisons: "The Solid algorithm performs best on wider graphs... The Preact Signal implementation is fast and very memory efficient."
This summary encapsulates the key concepts, methodologies, and findings presented in the article, focusing on the innovations and performance of various fine-grained reactivity libraries, especially the newly introduced Reactively.
-
-
-
arxiv.org arxiv.org
-
Author Response
The following is the authors’ response to the original reviews.
eLife assessment
This work provides a valuable contribution and assessment of what it means to replicate a null study finding, and what are the appropriate methods for doing so (apart from a rote p-value assessment). Through a convincing re-analysis of results from the Reproducibility Project: Cancer Biology using frequentist equivalence testing and Bayes factors, the authors demonstrate that even when reducing 'replicability success' to a single criterion, how precisely replication is measured may yield differing results. Less focus is directed to appropriate replication of non-null findings.
Reviewer #1 (Public Review):
Summary:
The goal of Pawel et al. is to provide a more rigorous and quantitative approach for judging whether or not an initial null finding (conventionally with p ≥ 0.05) has been replicated by a second similarly null finding. They discuss important objections to relying on the qualitative significant/non-significant dichotomy to make this judgment. They present two complementary methods (one frequentist and the other Bayesian) which provide a superior quantitative framework for assessing the replicability of null findings.
Strengths:
Clear presentation; illuminating examples drawn from the well-known Reproducibility Project: Cancer Biology data set; R-code that implements suggested analyses. Using both methods as suggested provides a superior procedure for judging the replicability of null findings.
Weaknesses:
The proposed frequentist and the Bayesian methods both rely on binary assessments of an original finding and its replication. I'm not sure if this is a weakness or is inherent to making binary decisions based on continuous data.
For the frequentist method, a null finding is considered replicated if the original and replication 90% confidence intervals for the effects both fall within the equivalence range. According to this approach, a null finding would be considered replicated if p-values of both equivalences tests (original and replication) were, say, 0.049, whereas would not be considered replicated if, for example, the equivalence test of the original study had a p-value of 0.051 and the replication had a p-value of 0.001. Intuitively, the evidence for replication would seem to be stronger in the second instance. The recommended Bayesian approach similarly relies on a dichotomy (e.g., Bayes factor > 1).
Thanks for the suggestions, we now emphasize more strongly in the “Methods for assessing replicability of null results” and “Conclusions” sections that both TOST p-values and Bayes factors are quantitative measures of evidence that do not require dichotomization into “success” or “failure”.
Reviewer #2 (Public Review):
Summary:
The study demonstrates how inconclusive replications of studies initially with p > 0.05 can be and employs equivalence tests and Bayesian factor approaches to illustrate this concept. Interestingly, the study reveals that achieving a success rate of 11 out of 15, or 73%, as was accomplished with the non-significance criterion from the RPCB (Reproducibility Project: Cancer Biology), requires unrealistic margins of Δ > 2 for equivalence testing.
Strengths:
The study uses reliable and shareable/open data to demonstrate its findings, sharing as well the code for statistical analysis. The study provides sensitivity analysis for different scenarios of equivalence margin and alfa level, as well as for different scenarios of standard deviations for the prior of Bayes factors and different thresholds to consider. All analysis and code of the work is open and can be replicated. As well, the study demonstrates on a case-by-case basis how the different criteria can diverge, regarding one sample of a field of science: preclinical cancer biology. It also explains clearly what Bayes factors and equivalence tests are.
Weaknesses:
It would be interesting to investigate whether using Bayes factors and equivalence tests in addition to p-values results in a clearer scenario when applied to replication data from other fields. As mentioned by the authors, the Reproducibility Project: Experimental Philosophy (RPEP) and the Reproducibility Project: Psychology (RPP) have data attempting to replicate some original studies with null results. While the RPCB analysis yielded a similar picture when using both criteria, it is worth exploring whether this holds true for RPP and RPEP. Considerations for further research in this direction are suggested. Even if the original null results were excluded in the calculation of an overall replicability rate based on significance, sensitivity analyses considering them could have been conducted. The present authors can demonstrate replication success using the significance criteria in these two projects with initially p < 0.05 studies, both positive and non-positive.
Other comments:
-
Introduction: The study demonstrates how inconclusive replications of studies initially with p > 0.05 can be and employs equivalence tests and Bayesian factor approaches to illustrate this concept. Interestingly, the study reveals that achieving a success rate of 11 out of 15, or 73%, as was accomplished with the non-significance criterion from the RPCB (Reproducibility Project: Cancer Biology), requires unrealistic margins of Δ > 2 for equivalence testing.
-
Overall picture vs. case-by-case scenario: An interesting finding is that the authors observe that in most cases, there is no substantial evidence for either the absence or the presence of an effect, as evidenced by the equivalence tests. Thus, using both suggested criteria results in a picture similar to the one initially raised by the paper itself. The work done by the authors highlights additional criteria that can be used to further analyze replication success on a case-by-case basis, and I believe that this is where the paper's main contributions lie. Despite not changing the overall picture much, I agree that the p-value criterion by itself does not distinguish between (1) a situation where the original study had low statistical power, resulting in a highly inconclusive non-significant result that does not provide evidence for the absence of an effect and (2) a scenario where the original study was adequately powered, and a non-significant result may indeed provide some evidence for the absence of an effect when analyzed with appropriate methods. Equivalence testing and Bayesian factor approaches are valuable tools in both cases.
Regarding the 0.05 threshold, the choice of the prior distribution for the SMD under the alternative H1 is debatable, and this also applies to the equivalence margin. Sensitivity analyses, as highlighted by the authors, are helpful in these scenarios.
Thank you for the thorough review and constructive feedback. We have added an additional “Appendix C: Null results from the RPP and EPRP” that shows equivalence testing and Bayes factor analyses for the RPP and EPRP null results.
Reviewer #3 (Public Review):
Summary:
The paper points out that non-significance in both the original study and a replication does not ensure that the studies provide evidence for the absence of an effect. Also, it can not be considered a "replication success". The main point of the paper is rather obvious. It may be that both studies are underpowered, in which case their non-significance does not prove anything. The absence of evidence is not evidence of absence! On the other hand, statistical significance is a confusing concept for many, so some extra clarification is always welcome.
One might wonder if the problem that the paper addresses is really a big issue. The authors point to the "Reproducibility Project: Cancer Biology" (RPCB, Errington et al., 2021). They criticize Errington et al. because they "explicitly defined null results in both the original and the replication study as a criterion for replication success." This is true in a literal sense, but it is also a little bit uncharitable. Errington et al. assessed replication success of "null results" with respect to 5 criteria, just one of which was statistical (non-)significance.
It is very hard to decide if a replication was "successful" or not. After all, the original significant result could have been a false positive, and the original null-result a false negative. In light of these difficulties, I found the paper of Errington et al. quite balanced and thoughtful. Replication has been called "the cornerstone of science" but it turns out that it's actually very difficult to define "replication success". I find the paper of Pawel, Heyard, Micheloud, and Held to be a useful addition to the discussion.
Strengths:
This is a clearly written paper that is a useful addition to the important discussion of what constitutes a successful replication.
Weaknesses:
To me, it seems rather obvious that non-significance in both the original study and a replication does not ensure that the studies provide evidence for the absence of an effect. I'm not sure how often this mistake is made.
Thanks for the feedback. We do not have systematic data on how often the mistake of confusing absence of evidence with evidence of absence has been made in the replication context, but we do know that it has been made in at least three prominent large-scale replication projects (the RPP, RPEP, RPCB). We therefore believe that there is a need for our article.
Moreover, we agree that the RPCB provided a nuanced assessment of replication success using five different criteria for the original null results. We emphasize this now more in the “Introduction” section. However, we do not consider our article as “a little bit uncharitable” to the RPCB, as we discuss all other criteria used in the RPCB and note that our intent is not to diminish the important contributions of the RPCB, but rather to build on their work and provide constructive recommendations for future researchers. Furthermore, in response to comments made by Reviewer #2, we have added an additional “Appendix B: Null results from the RPP and EPRP” that shows equivalence testing and Bayes factor analyses for null results from two other replication projects, where the same issue arises.
Reviewer #1 (Recommendations For The Authors):
The authors may wish to address the dichotomy issue I raise above, either in the analysis or in the discussion.
Thank you, we now emphasize that Bayes factors and TOST p-values do not need to be dichotomized but can be interpreted as quantitative measures of evidence, both in the “Methods for assessing replicability of null results” and the “Conclusions” sections.
Reviewer #2 (Recommendations For The Authors):
Given that, here follow additional suggestions that the authors should consider in light of the manuscript's word count limit, to avoid confusing the paper's main idea:
2) Referencing: Could you reference the three interesting cases among the 15 RPCB null results (specifically, the three effects from the original paper #48) where the Bayes factor differs qualitatively from the equivalence test?
We now explicitly cite the original and replication study from paper #48.
3) Equivalence testing: As the authors state, only 4 out of the 15 study pairs are able to establish replication success at the 5% level, in the sense that both the original and the replication 90% confidence intervals fall within the equivalence range. Among these 4, two (Paper #48, Exp #2, Effect #5 and Paper #48, Exp #2, Effect #6) were initially positive with very low p-values, one (Paper #48, Exp #2, Effect #4) had an initial p of 0.06 and was very precisely estimated, and the only one in which equivalence testing provides a clearer picture of replication success is Paper #41, Exp #2, Effect #1, which had an initial p-value of 0.54 and a replication p-value of 0.05. In this latter case (or in all these ones), one might question whether the "liberal" equivalence range of Δ = 0.74 is the most appropriate. As the authors state, "The post-hoc specification of equivalence margins is controversial."
We agree that the post hoc choice of equivalence ranges is a controversial issue. The margins define an equivalence region where effect sizes are considered practically negligible, and we agree that in many contexts SMD = 0.74 is a large effect size that is not practically negligible. We therefore present sensitivity analyses for a wide range of margins. However, we do not think that the choice of this margin is more controversial for the mentioned studies with low p-values than for other studies with greater p-values, since the question of whether a margin plausibly encodes practically negligible effect sizes is not related to the observed p-value of a study. Nevertheless, for the new analyses of the RPP and EPRP data in Appendix B, we have added additional sensitivity analyses showing how the individual TOST p-values and Bayes factors vary as a function of the margin and the prior standard deviation. We think that these analyses provide readers with an even more transparent picture regarding the implications of the choice of these parameters than the “project-wise” sensitivity analyses in Appendix A.
4) Bayes factor suggestions: For the Bayes factor approach, it would be interesting to discuss examples where the BF differs slightly. This is likely to occur in scenarios where sample sizes differ significantly between the original study and replication. For example, in Paper #48, Exp #2 and Effect #4, the initial p is 0.06, but the BF is 8.1. In the replication, the BF dramatically drops to < 1/1000, as does the p-value. The initial evidence of 8.1 indicates some evidence for the absence of an effect, but not strong evidence ("strong evidence for H0"), whereas a p-value of 0.06 does not lead to such a conclusion; instead, it favors H1. It would be interesting if the authors discussed other similar cases in the paper. It's worth noting that in Paper #5, Exp #1, Effect #3, the replication p-value is 0.99, while the BF01 is 2.4, almost indicating "moderate" evidence for H0, even though the p-value is inconclusive.
We agree that some of the examples nicely illustrate conceptual differences between p-values and Bayes factors, e.g., how they take into account sample size and effect size. As methodologists, we find these aspects interesting ourselves, but we think that emphasizing them is beyond the scope of the paper and would distract eLife readers from the main messages.
Concerning the conceptual differences between Bayes factors and TOST p-values, we already discuss a case where there are qualitative differences in more detail (original paper #48). We added another discussion of this phenomenon in the Appendix C as it also occurs for the replication of Ranganath and Nosek (2008) that was part of the RPP.
5) p-values, magnitude and precision: It's noteworthy to emphasize, if the authors decide to discuss this, that the p-value is influenced by both the effect's magnitude and its precision, so in Paper #9, Exp #2, Effect #6, BF01 = 4.1 has a higher p-value than a BF01 = 2.3 in its replication. However, there are cases where both p-values and BF agree. For example, in Paper #15, Exp #2, Effect #2, both the original and replication studies have similar sample sizes, and as the p-value decreases from p = 0.95 to p = 0.23, BF01 decreases from 5.1 ("moderate evidence for H0") to 1.3 (region of "Absence of evidence"), moving away from H0 in both cases. This also occurs in Paper #24, Exp #3, Effect #6.
We appreciate the suggestions but, as explained before, think that the message of our paper is better understood without additional discussion of more general differences between p-values and Bayes factors.
6) The grey zone: Given the above topic, it is important to highlight that in the "Absence of evidence grey zone" for the null hypothesis, for example, in Paper #5, Exp #1, Effect #3 with a p = 0.99 and a BF01 = 2.4 in the replication, BF and p-values reach similar conclusions. It's interesting to note, as the authors emphasize, that Dawson et al. (2011), Exp #2, Effect #2 is an interesting example, as the p-value decreases, favoring H1, likely due to the effect's magnitude, even with a small sample size (n = 3 in both original and replications). Bayes factors are very close to one due to the small sample sizes, as discussed by the authors.
We appreciate the constructive comments. We think that the two examples from Dawson et al. (2011) and Goetz et al. (2011) already nicely illustrate absence of evidence and evidence of absence, respectively, and therefore decided not to discuss additional examples in detail, to avoid redundancy.
7) Using meta-analytical results (?): For papers from RPCB, comparing the initial study with the meta-analytical results using Bayes factor and equivalence testing approaches (thus, increasing the sample size of the analysis, but creating dependency of results since the initial study would affect the meta-analytical one) could change the conclusions. This would be interesting to explore in initial studies that are replicated by much larger ones, such as: Paper #9, Exp #2, Effect #6; Goetz et al. (2011), Exp #1, Effect #1; Paper #28, Exp #3, Effect #3; Paper #41, Exp #2, Effect #1; and Paper #47, Exp #1, Effect #5).
Thank you for the suggestion. We considered adding meta-analytic TOST p-values and Bayes factors before, but decided that Figure 3 and the results section are already quite technical, so adding more analyses may confuse more than help. Nevertheless, these meta-analytic approaches are discussed in the “Conclusions” section.
8) Other samples of fields of science: It would be interesting to investigate whether using Bayes factors and equivalence tests in addition to p-values results in a clearer scenario when applied to replication data from other fields. As mentioned by the authors, the Reproducibility Project: Experimental Philosophy (RPEP) and the Reproducibility Project: Psychology (RPP) have data attempting to replicate some original studies with null results. While the RPCB analysis yielded a similar picture when using both criteria, it is worth exploring whether this holds true for RPP and RPEP. Considerations for further research in this direction are suggested. Even if the original null results were excluded in the calculation of an overall replicability rate based on significance, sensitivity analyses considering them could have been conducted. The present authors can demonstrate replication success using the significance criteria in these two projects with initially p < 0.05 studies, both positive and non-positive.
Thank you for the excellent suggestion. We added an Appendix B where the null results from the RPP and EPRP are analyzed with our proposed approaches. The results are also discussed in the “Results” and “Conclusions” sections.
9) Other approaches: I am curious about the potential impact of using an approach based on equivalence testing (as described in https://arxiv.org/abs/2308.09112). It would be valuable if the authors could run such analyses or reference the mentioned work.
Thank you. We were unaware of this preprint. It seems related to the framework proposed by Stahel W. A. (2021) New relevance and significance measures to replace p-values. PLoS ONE 16(6): e0252991. https://doi.org/10.1371/journal.pone.0252991
We now cite both papers in the discussion.
10) Additional evidence: There is another study in which replications of initially p > 0.05 studies with p > 0.05 replications were also considered as replication successes. You can find it here: https://www.medrxiv.org/content/10.1101/2022.05.31.22275810v2. Although it involves a small sample of initially p > 0.05 studies with already large sample sizes, the work is currently under consideration for publication in PLOS ONE, and all data and materials can be accessed through OSF (links provided in the work).
Thank you for sharing this interesting study with us. We feel that it is beyond the scope of the paper to include further analyses as there are already analyses of the RPCB, RPP, and EPRP null results. However, we will keep this study in mind for future analysis, especially since all data are openly available.
11) Additional evidence 02: Ongoing replication projects, such as the Brazilian Reproducibility Initiative (BRI) and The Sports Replication Centre (https://ssreplicationcentre.com/), continue to generate valuable data. BRI is nearing completion of its results, and it promises interesting data for analyzing replication success using p-values, equivalence regions, and Bayes factor approaches.
We now cite these two initiatives as examples of ongoing replication projects in the introduction. Similarly as for your last point, we think that it is beyond the scope of the paper to include further analyses as there are already analyses of the RPCB, RPP, and EPRP null results.
Reviewer #3 (Recommendations For The Authors):
I have no specific recommendations for the authors.
Thank you for the constructive review.
Reviewing Editor (Recommendations For the Authors):
I recognize that it was suggested to the authors by the previous Reviewing Editor to reduce the amount of statistical material to be made more suitable for a non-statistical audience, and so what I am about to say contradicts advice you were given before. But, with this revised version, I actually found it difficult to understand the particulars of the construction of the Bayes Factors and would have appreciated a few more sentences on the underlying models that fed into the calculations. In my opinion, the provided citations (e.g., Dienes Z. 2014. Using Bayes to get the most out of non-significant results) did not provide sufficient background to warrant a lack of more technical presentation here.
Thank you for the feedback. We added a new “Appendix C: Technical details on Bayes factors” that provides technical details on the models, priors, and calculations underlying the Bayes factors.
-
Tags
Annotators
URL
-
-
social-media-ethics-automation.github.io social-media-ethics-automation.github.io
-
When we’ve been accessing Reddit through Python and the “PRAW” code library. The praw code library works by sending requests across the internet to Reddit, using what is called an “application programming interface” [h3] or API for short. APIs have a set of rules for what requests you can make, what happens when you make the request, and what information you can get back.
The explanation provided about how the PRAW library functions as a mediator between Python applications and Reddit through the use of APIs is quite illuminating. APIs, as described, serve as the bridge that facilitates these interactions under a set of defined rules and protocols. This brings to mind the essential nature of understanding the limits and capabilities of any API when developing software that depends on external services. It would be interesting to explore further how robust the error handling capabilities of the PRAW library are. Specifically, how does PRAW manage or relay errors that arise from API limitations or disruptions in Reddit's service? This is crucial for developers to ensure their applications can gracefully handle such issues and maintain a good user experience.
-
When we’ve been accessing Reddit through Python and the “PRAW” code library. The praw code library works by sending requests across the internet to Reddit, using what is called an “application programming interface” [h3] or API for short. APIs have a set of rules for what requests you can make, what happens when you make the request, and what information you can get back.
I am not well informed on how API works but it sounds like it has a lot of connection to the internet and other kind of information systems. Going back to the sources of social media data, one of the things that platforms could record are what users click on, when they log on or off, etc. What arises from this I think ties back in with the ethical frameworks we were talking about in chapter 2. The discussion becomes what course of action is correct because even if the platform records information on the behavior of user interaction, it boils down to the idea that even if it's to mazimize user experience, should platforms be allowed to record information that could be personal?
-
-
queue.acm.org queue.acm.org
-
the 31,085 lines of configure for libtool still check if <sys/stat.h> and <stdlib.h> exist, even though the Unixen, which lacked them, had neither sufficient memory to execute libtool nor disks big enough for its 16-MB source code.
yummy
-
-
bloclibrary.dev bloclibrary.dev
-
One of the biggest advantages of using Cubit is simplicity. When creating a Cubit, we only have to define the state as well as the functions which we want to expose to change the state. In comparison, when creating a Bloc, we have to define the states, events, and the EventHandler implementation. This makes Cubit easier to understand and there is less code involved.
Cubit和Bloc的区别:
Cubit只需要定义state和能改变state的function
Bloc要定义state,event和event handler
-
-
kelsienabben.substack.com kelsienabben.substack.com
-
The “DAO Model Law” guide by COALA researchers outlines 11 technical and governance requirements for DAOs to meet the requirements for legal recognition as an entity, including:1. Deployed on a blockchain,2. Provide a unique public address for others to review its operations,3. Open source software code,4. Get code audited,5. Have at least one interface for laypeople to read critical information on DAO smart contracts and tokens,6. Have by-laws that are comprehensible to lay people,7. Have governance that is technically decentralized (i.e. not controlled by a single party),8. Have at least one member at any given time,9. Have a specific way for people to contact the DAO,10. Have a binding internal dispute resolution mechanism for participants,11. Have an external dispute resolution mechanism to resolve disputes with third-parties (e.g. service providers).These factors and considerations constitute a legal basis for conceptualizing DAOs.
Tags
Annotators
URL
-
-
social-media-ethics-automation.github.io social-media-ethics-automation.github.io
-
Nicole Nguyen. Here's Who Facebook Thinks You Really Are. September 2016. Section: Tech. URL: https://www.buzzfeednews.com/article/nicolenguyen/facebook-ad-preferences-pretty-accurate-tbh (visited on 2024-01-30).
In the article it mentioned that many non facebook sites use JavaScript code that tells the mothership what kind of content you're looking at when you're not on Facebook's site and apps. Even if done legally, that doesn't make it the most ethical choice. I think there are better and more ethical ways to understand the target market of your audience. I think this is smart to engage and understand users better but it just doesn't feel right to be about in someone's own personal life when they don't know about it.
-
-
dev-10.teachable.com dev-10.teachable.com
-
toString Returns a String representation of an object. By default, it returns the class name and a hexidecimal representation of the hashCode. That's not very useful, so it's common to override this method. hashCode Returns an int code that's used for storing an object in hashed data structures. getClass Returns the Class associated to the object. An instance of a Class contains meta-data (names, parameters, annotations) associated to a class. equals Returns a boolean that indicates if this instance is equal to another object. By default, it evaluates to true if the objects share the same memory location -- called reference equality -- they share the same reference. It's common to override this method to inspect individual values instead of comparing references.
Object methods
-
Code changes:
The person has-a student and instructor rather than the student is-a person (inheritance)
-
-
pressbooks.online.ucf.edu pressbooks.online.ucf.edu
-
Instructions: Step 1: Briefly summarize the “best fit occupations” results of the combined assessment (about 100 words). Step 2: Reflect on the combined results of your assessments as they relate to your current career interest (about 400 words). Consider responding to one or more of following prompts: In the Work Interest assessment, what is your Holland Code (please use the letters and descriptive titles)? How well do these three descriptors fit your current career interest? How might these descriptors help you select a better fitting career goal? In the Leisure Interest assessment, what are your top three leisure interests? How well do these three descriptors fit your current career interest? How might these descriptors help you select a better fitting career goal? What “best fit” occupation recommendations do you agree with? What recommendations do you disagree with? Why? Which of the five assessments (work, leisure, skills, personality, values) are most important to you personally? Select three assessments and run another combined report. Are the results any different? Did the results provide you with any new insights? You may also comment on the insights gained from the Focus 2 Career Assessment and how they relate to the results of previous assessment you have completed while in LEAD Scholars including True Colors, Strengths, and 16-Personalities. Step 3: Provide one personal insight about your career path gained from this learning activity.
delete instructions
-
-
-
You can find the source code of these lessons in the lhcb/first-analysis-steps repository,
课程代码仓库
-
-
openclassrooms.com openclassrooms.com
-
créer une liste non ordonnée
suite à la création de la liste non ordonnée une erreur Prettier s'affiche dans la console et Prettier ne met plus en page le code comme auparavant. quelqu'un sait il pourquoi ?
-
Vous pouvez théoriquement mettre plusieurs balises <br> d'affilée pour faire plusieurs sauts de lignes, mais on considère que c'est une mauvaise pratique qui rend le code délicat à maintenir.
L'utilisation de plusieurs balises
pour avoir le même résultat est-elle également considéré comme une mauvaise pratique ?
-
-
www.biorxiv.org www.biorxiv.org
-
Author response:
The following is the authors’ response to the original reviews.
Reviewer 1
(1) Given the low trial numbers, and the point of sequential vs clustered reactivation mentioned in the public review, it would be reassuring to see an additional sanity check demonstrating that future items that are currently not on-screen can be decoded with confidence, and if so, when in time the peak reactivation occurs. For example, the authors could show separately the decoding accuracy for near and far items in Fig. 5A, instead of plotting only the difference between them.
We have now added the requested analysis showing the raw decoded probabilities for near and distant items separately in Figure 5A. We have also chosen to replace Figure 5B with the new figure as we think it provides more information than the previous Figure 5B. Instead, we have moved Figure 5B to the supplement. The median peak decoded accuracy for near and distant items is equivalent. We have added the following description to the figure:
“Decoded raw probabilities for off-screen items, that were up to two steps ahead of the current stimulus cue (‘near’,) vs. distant items that were more than two steps away on the graph, on trials with correct answers. The median peak decoded probability for near and distant items was at the same time point for both probability categories. Note that displayed lines reflect the average probability while, to eliminate influence of outliers, the peak displays the median.”
(2) The non-sequential reactivation analyses often use a time window of peak decodability, and it was not entirely clear to me what data this time window is determined on, e.g., was it determined based on all future reactivations irrespective of graph distance? This should be clarified in the methods.
Thank you for raising this. We now clarify this in the relevant section to read: “First, we calculated a time point of interest by computing the peak probability estimate of decoders across all trials, i.e., the average probability for each timepoint of all trials (except previous onscreen items) of all distances, which is equivalent to the peak of the differential reactivation analysis”
(3) Fig 4 shows evidence for forward and backward sequential reactivation, suggesting that both forward and backward replay peak at a lag of 40-50msec. It would be helpful if this counterintuitive finding could be picked up in the discussion, explaining how plausible it is, physiologically, to find forward and backward replay at the same lag, and whether this could be an artifact of the TDLM method.
This is an important point and we agree that it appears counterintuitive. However, we would highlight this exact time range has been reported in previous studies, though t never for both forward and backward replay. We now include a discussion of this finding. The section now reads:
“[… ] Even though we primarily focused on the mean sequenceness scores across time lags, there appears s to be a (non-significant) peak at 40-60 milliseconds. While simultaneous forward and backward replay is theoretically possible, we acknowledge that it is somewhat surprising and, given our paradigm, could relate to other factors such as autocorrelations (Liu, Dolan, et al., 2021).”
(4) It is reported that participants with below 30% decoding accuracy are excluded from the main analyses. It would be helpful if the manuscript included very specific information about this exclusion, e.g., was the criterion established based on the localizer cross-validated data, the temporal generalisation to the cued item (Fig. 2), or only based on peak decodability of the future sequence items? If the latter, is it applied based on near or far reactivations, or both?
We now clarify this point to include more specific information, which reads:
“[…] Therefore, we decided a priori that participants with a peak decoding accuracy of below 30% would be excluded from the analysis (nine participants in all) as obtained from the cross-validation of localizer trials”
(5) Regarding the low amount of data for the reactivation analysis, the manuscript should be explicit about the number of trials available for each participant. For example, Supplemental Fig. 1 could provide this information directly, rather than the proportion of excluded trials.
We have adapted the plot in the supplement to show the absolute number of rejected epochs per participant, in addition to the ratio.
(6) More generally, the supplements could include more detailed information in the legends.
We agree and have added more extensive explanation of the plots in the supplement legends.
(7) The choice of comparing the 2 nearest with all other future items in the clustered reactivation analysis should be better motivated, e.g., was this based on the Wimmer et al. (2020) study?
We have added our motivation for taking the two nearest items and contrasting them with the items further away. The paragraph reads:
“[…] We chose to combine the following two items for two reasons: First, this doubled the number of included trials; secondly, using this approach the number of trials for each category (“near” and “distant”) was more balanced. […]”
Reviewer 2
(1) Focus exclusively on retrieval data (and here just on the current image trials).
If I understand correctly, you focus all your analyses (behavioural as well as MEG analyses) on retrieval data only and here just on the current image trials. I am surprised by that since I see some shortcomings due to that. These shortcomings can likely be addressed by including the learning data (and predecessor image trials) in your analyses.
a) Number of trials: During each block, you presented each of the twelve edges once. During retrieval, participants then did one "single testing session block". Does that mean that all your results are based on max. 12 trials? Given that participants remembered, on average, 80% this means even fewer trials, i.e., 9-10 trials?
This is correct and a limitation of the paper. However, while we used only correct trials for the reactivation analysis, the sequential analysis was conducted using all trials disregarding the response behaviour. To retain comparability with previous studies we mainly focused on data from after a consolidation phase. Nevertheless, despite the trial limitation we consider the results are robust and worth reporting. Additionally, based on the suggestion of the referee, we now include results from learning blocks (see below).
b) Extend the behavioural and replay/reactivation analysis to predecessor images.
Why do you restrict your analyses to the current image trials? Especially given that you have such a low trial number for your analyses, I was wondering why you did not include the predecessor trials (except the non-deterministic trials, like the zebra and the foot according to Figure 2B) as well.
We agree it would be great to increase power by adding the predecessor images to the current image cue analysis, excluding the ambiguous trials, we did not do so as we considered the underlying retrieval processes of these trial types are not the same, i.e. cannot be simply combined. Nevertheless, we have performed the suggested analysis to check if it increases our power. We found, that the reactivation effect is robust and significant at the same time point of 220-230 ms. However, the effect size actually decreased: While before, peak differential reactivation was at 0.13, it is now at 0.07. This in fact makes conceptual sense. We suspect that the two processes that are elicited by showing a single cue and by showing a second, related, cue are distinct insofar as the predecessor image acts as a primer for the current image, potentially changing the time course/speed of retrieval. Given our concerns that the two processes are not actually the same we consider it important to avoid mixing these data.
We have added a statement to the manuscript discussing this point. The section reads:
“Note that we only included data from the current image cue, and not from the predecessor image cue, as we assume the retrieval processes differ and should not be concatenated.”
c) Extend the behavioural and replay/reactivation analysis to learning trials.
Similar to point 1b, why did you not include learning trials in your analyses?
The advantage of including (correct and incorrect) learning trials has the advantage that you do not have to exclude 7 participants due to ceiling performance (100%).
Further, you could actually test the hypothesis that you outline in your discussion: "This implies that there may be a switch from sequential replay to clustered reactivation corresponding to when learned material can be accessed simultaneously without interference." Accordingly, you would expect to see more replay (and less "clustered" reactivation) in the first learning blocks compared to retrieval (after the rest period).
To track reactivation and replay over the course of learning is a great idea. We have given a lot of thought as to how to integrate these findings but have not found a satisfying solution. Thus, analysis of the learning data turned out to be quite tricky: We decided that each participant should perform as many blocks as necessary to reach at least 80% (with a limit of six and lower bound of two, see Supplement figure 4). Indeed, some participant learned 100% of the sequence after one block (these were mostly medical students, learning things by hard is their daily task). With the benefit of hindsight, we realise our design means that different blocks are not directly comparable between participants. In theory, we would expect that replay emerges in parallel with learning and then gradually changes to clustered reactivation as memory traces become consolidated/stronger. However, it is unclear when replay should emerge and when precisely a switch to clustered reactivation would happen. For this reason, we initially decided not to include the learning trials into the paper.
Nevertheless, to provide some insight into the learning process, and to see how consolidation impacts differential reactivation and replay, we have split our data into pre and post resting state, aggregating all learning trials of each participant. While this does not allow us to track processes on a block basis, it does offer potential (albeit limited) insight into the hypothesis we outline in the discussion.
For reactivation, we see emergence of a clear increase, further strengthening the outlined hypothesis, however, for replay the evidence is less clear, as we do not know over how many learning blocks replay is expected.
We calculated individual trajectories of how reactivation and replay changes from learning to retrieval and related these to performance. Indeed, we see an increase of reactivation is nominally associated with higher learning performance, while an increase in replay strength is associated with lower performance (both non-significant). However, due to the above-mentioned reasons we think it would premature to add this weak evidence to the paper.
To mitigate problems of experiment design in relation to this question we are currently implementing a follow-study, where we aim to normalize the learning process across participants and index how replay/reactivation changes over the course of learning and after consolidation.
We have added plots showing clustered reactivation sequential replay measures during learning (Figure 5D and Supplement 8)
The added section(s) now read:
“To provide greater detail on how the 8-minute consolidation period affected reactivation we, post-hoc, looked at relevant measures across learning trials in contrast to retrieval trials. For all learning trials, for each participant, we calculated differential reactivation for the same time point we found significant in the previous analysis (220-260 milliseconds). On average, differential reactivation probability increased from pre to post resting state (Figure 5D). […]
Nevertheless, even though our results show a nominal increase in reactivation from learning to retrieval (see Figure 5D), due to experimental design features our data do not enable us to test for an hypothesized switch for sequential replay (see also “limitations” and Supplement 8).”
d) Introduction (last paragraph): "We examined the relationship of graph learning to reactivation and replay in a task where participants learned a ..." If all your behavioural analyses are based on retrieval performance, I think that you do not investigate graph learning (since you exclusively focus the analyses on retrieving the graph structure). However, relating the graph learning performance and replay/reactivation activity during learning trials (i.e., during graph learning) to retrieval trials might be interesting but beyond the scope of this paper.
We agree. We have changed the wording to be more accurate. Indeed, we do not examine graph learning but instead examine retrieval from a graph, after graph learning. The mentioned sentence now read
“[…] relationship of retrieval from a learned graph structure to reactivation [...]”
e) It is sometimes difficult to follow what phase of the experiment you refer to since you use the terms retrieval and test synonymously. Not a huge problem at all but maybe you want to stick to one term throughout the whole paper.
Thank you for pointing this out. We have now adapted the manuscript to exclusively refer to “retrieval” and not to “test”.
(2) Is your reactivation clustered?
In Figure 5A, you compare the reactivation strength of the two items following the cue image (i.e., current image trials) with items further away on the graph. I do not completely understand why your results are evidence for clustered reactivation in contrast to replay.
First, it would be interesting to see the reactivation of near vs. distant items before taking the difference (time course of item probabilities).
(copied answer from response to Reviewer 1, as the same remark was raised)
We have added the requested analysis showing the raw decoded probabilities for near and distant items separately in Figure 5A. We have chosen to replace Figure 5B with the new figure as we think that it offers more information than the previous Figure 5B. Instead, we have moved Figure 5B to the supplement. The median peak decoded accuracy for near and distant items is equivalent. We have added the following description to the figure:
“Decoded raw probabilities for off-screen items, that were up to two steps ahead of the current stimulus cue (‘near’,) vs. distant items that were more than two steps away on the graph, on trials with correct answers. The median peak decoded probability for near and distant items was at the same time point for both probability categories. Note that displayed lines reflect the average probability while, to eliminate influence of outliers, the peak displays the median. .”
Second, could it still be that the first item is reactivated before the second item? By averaging across both items, it becomes not apparent what the temporal courses of probabilities of both items look like (and whether they follow a sequential pattern). Additionally, the Gaussian smoothing kernel across the time dimension might diminish sequential reactivation and favour clustered reactivation. (In the manuscript, what does a Gaussian smoothing kernel of = 1 refer to?). Could you please explain in more detail why you assume non-sequential clustered reactivation here and substantiate this with additional analyses?
We apologise for the unclear description. Note the Gaussian kernel is in fact only used for the reactivation analysis and not the replay analysis, so any small temporal successions would have been picked up by the sequential analysis. We now clarify this in the respective section of the sequential analysis and also explain the parameter of delta= 1 in the reactivation analysis section. The paragraph now reads
“[…] As input for the sequential analysis, we used the raw probabilities of the ten classifiers corresponding to the stimuli. [...]
[…] Therefore, to address this we applied a Gaussian smoothing kernel (using scipy.ndimage.gaussian_filter with the default parameter of σ=1 which corresponds approximately to taking the surrounding timesteps in both direction with the following weighting: current time step: 40%, ±1 step: 25%, ±2 step: 5%, ±3 step: 0.5%) [...]”
(3) Replay and/or clustered reactivation?
The relationship between the sequential forward replay, differential reactivation, and graph reactivation analysis is not really apparent. Wimmer et al. demonstrated that high performers show clustered reactivation rather than sequential reactivation. However, you did not differentiate in your differential reactivation analysis between high vs. low performers. (You point out in the discussion that this is due to a low number of low performers.)
We agree that a split into high vs low performers would have been preferably for our analysis. However, there is one major obstacle that made us opt for a correlational analysis instead: We employed criteria learning, rendering a categorical grouping conceptually biased. Even though not all participants reached the criteria of 80%, our sample did not naturally split between high and low performers but was biased towards higher performance, leaving the groups uneven. The median performance was 83% (mean ~81%), with six of our subjects (~1/4th of included participant) having this exact performance. This makes a median or mean split difficult, as either binning assignment choice would strongly affect the results. We have added a limitations section in which we extensively discuss this shortcoming and reasoning for not performing a median split as in Wimmer et al (2020). The section now reads:
“There are some limitations to our study, most of which originate from a suboptimal study design. [...], as we performed criteria learning, a sub-group analysis as in Wimmer et al., (2020) was not feasible, as median performance in our sample would have been 83% (mean 81%), with six participants exactly at that threshold. [...]”
It might be worth trying to bring the analysis together, for example by comparing sequential forward replay and differential reactivation at the beginning of graph learning (when performance is low) vs. retrieval (when performance is high).
Thank you for the suggestion to include the learning segments, which we think improves the paper quite substantially. However, analysis of the learning data turned out to be quite tricky> We had decided that each participant should perform as many blocks as necessary to reach at least 80% accuracy (with a limit of six and lower bound of two, see Supplement figure 4). Some participants learned 100% of the sequence after one block (these were mostly medical students, learning things by hard is their daily task). This in hindsight is an unfortunate design feature in relation to learning as it means different blocks are not directly comparable between participants.
In theory, we would expect that replay emerges in parallel with learning and then gradually change to clustered reactivation, as memory traces get consolidated/stronger. However, it is unclear when replay would emerge and when the switch to reactivation would happen. For this reason, we initially decided not to include the learning trials into the paper at all.
Nevertheless, to give some insight into the learning process and to see how consolidation effects differential reactivation and replay, we have split our data into pre and post resting state, aggregating all learning trials of each participant. While this does not allow us to track measures of interest on a block basis, it gives some (albeit limited) insight into the hypothesis outlined in our discussion.
For reactivation, we see a clear increase, further strengthening the outlined hypothesis, However, for replay the evidence is less obvious, potentially due to that fact that we do not know across how many learning blocks replay is to be expected.
The added section(s) now read:
“To examine how the 8-minute consolidation period affected reactivation we, post-hoc, looked at relevant measures during learning trials in contrast to retrieval trials. For all learning trial, for each participant, we calculated differential reactivation for the time point we found significant during the previous analysis (220-260 milliseconds). On average, differential reactivation probability increased from pre to post resting state (Figure 5D).
[…]
Nevertheless, even though our results show a nominal increase in reactivation from learning to retrieval (see Figure 5D), our data does not enable us to show an hypothesized switch for sequential replay (see also “limitations” and Supplement 8).”
Additionally, the main research question is not that clear to me. Based on the introduction, I thought the focus was on replay vs. clustered reactivation and high vs. low performance (which I think is really interesting). However, the title is more about reactivation strength and graph distance within cognitive maps. Are these two research questions related? And if so, how?
We agree we need to be clearer on this point. We have added two sentences to the introduction, which should address this point. The section now reads:
“[…] In particular, the question remains how the brain keeps track of graph distances for successful recall and whether the previously found difference between high and low performers also holds true within a more complex graph learning context.”
(4) Learning the graph structure.
I was wondering whether you have any behavioural measures to show that participants actually learn the graph structure (instead of just pairs or triplets of objects). For example, do you see that participants chose the distractor image that was closer to the target more frequently than the distractor image that was further away (close vs. distal target comparison)? It should be random at the beginning of learning but might become more biased towards the close target.
Thanks, this is an excellent suggestion. Our analysis indeed shows that people take the near lure more often than the far lure in later blocks, while it is random in the first block.
Nevertheless, we have decided to put these data into the supplement and reference it in the text. This is because analysis of the learning blocks is challenging and biased in general. Each participant had a different number of learning blocks based on their learning rate, and this makes it difficult to compare learning across participants. We have tried our best to accommodate and explain these difficulties in the figure legend. Nevertheless, we thank the referee for guidance here and this analysis indeed provides further evidence that participants learned the actual graph structure.
The added section reads
“Additionally, we have included an analysis showing how wrong answers participants provided were random in the first block and biased towards closer graph nodes in later blocks. This is consistent with participants actually learning the underlying graph structure as opposed to independent triplets (see figure and legend of Supplement 6 for details).”
(5) Minor comments
a) "Replay analysis relies on a successive detection of stimuli where the chance of detection exponentially decreases with each step (e.g., detecting two successive stimuli with a chance of 30% leaves a 9% chance of detecting the replay event). " Could you explain in more detail why 30% is a good threshold then?
Thank you. We have further clarified the section. As we are working mainly with probabilities, it is useful to keep in mind that accuracy is a class metric that only provides a rough estimate of classifier ability. Alternatively, something like a Top-3-Accuracy would be preferable, but also slightly silly in the context of 10 classes.
Nevertheless, subtle changes in probability estimates are present and can be picked up by the methods we employ. Therefore, the 30% is a rough lower bound and decided based on pilot data that showed that clean MEG data from attentive participants can usually reach this threshold. The section now reads:
“(e.g., detecting two successive stimuli with a chance of 30% leaves a 9% chance of detecting a replay event). However, one needs to bear in mind that accuracy is a “winnertakes-all” metric indicating whether the top choice also has the highest probability, disregarding subtle, relative changes in assigned probability. As the methods used in this analysis are performed on probability estimates and not class labels, one can expect that the 30% are a rough lower bound and that the actual sensitivity within the analysis will be higher. Additionally, based on pilot data, we found that attentive participants were able to reach 30% decodability, allowing us to use decodability as a data quality check. “
b) Could you make explicit how your decoders were designed? Especially given that you added null data, did you train individual decoders for one class vs. all other classes (n = 9 + null data) or one class vs. null data?
We added detail to the decoder training. The section now reads
“Decoders were trained using a one-vs-all approach, which means that for each class, a separate classifier was trained using positive examples (target class) and negative examples (all other classes) plus null examples (data from before stimulus presentation, see below). In detail, null data was.”
c) Why did you choose a ratio of 1:2 for your null data?
Our choice for using a higher ratio was based upon previous publications reporting better sensitivity of TDLM using higher ratios, as spatial sensor correlations are decreasing. Nevertheless, this choice was not well investigated beforehand. We have added more information to this to the manuscript
d) You could think about putting the questionnaire results into the supplement if they are sanity checks.
We have added the questionnaire results. However, due to the size of the tables, we have decided to add them as excel files into the supplementary files of the code repository. We have mentioned the existence file in the publication.
e) Figure 2. There is a typo in D: It says "Precessor Image" instead of "Predecessor Image".
Fixed typo in figure.
f) You write "Trials for the localizer task were created from -0.1 to 0.5 seconds relative to visual stimulus onset to train the decoders and for the retrieval task, from 0 to 1.5 seconds after onset of the second visual cue image." But the Figure legend 3D starts at -0.1 seconds for the retrieval test.
We have now clarified this. For the classifier cross-validation and transfer sanity check and clustered analysis we used trials from -0.1 to 0.5s, whereas for the sequenceness analysis of the retrieval, we used trials from 0 to 1.5 seconds
-
-
datascienceschool.net datascienceschool.net
-
소스 코드(source code)
컴퓨터 소프트웨어의 제작에 사용되는 설계도.
-
-
jverzani.github.io jverzani.github.io
-
Taking values near 15/11 shows nothing too unusual:
The following code is not working getting the following error: julia> [xs i.(xs)] ERROR: UndefVarError: i not defined Stacktrace: [1] top-level scope @ REPL[41]:1
-
-
blog.stackblitz.com blog.stackblitz.com
-
All code execution happens inside the browser’s security sandbox, not on remote VMs or local binaries.
All running in the browser not on remote WMs
-
-
pressbooks.online.ucf.edu pressbooks.online.ucf.edu
-
ons: Step 1: Briefly summarize the “best fit occupations” results of the combined assessment (about 100 words). Step 2: Reflect on the combined results of your assessments as they relate to your current career interest (about 400 words). Consider responding to one or more of following prompts: In the Work Interest assessment, what is your Holland Code (please use the letters and descriptive titles)? How well do these three descriptors fit your current career interest? How might these descriptors help you select a better fitting career goal? In the Leisure Interest assessment, what are your top three leisure interests? How well do these three descriptors fit your current career interest? How might these descriptors help you select a better fitting career goal? What “best fit” occupation recommendations do you agree with? What recommendations do you disagree with? Why? Which of the five assessments (work, leisure, skills, personality, values) are most important to you personally? Select three assessments and run another combined report. Are the results any different? Did the results provide you with any new insights? You may also comment on the insights gained from the Focus 2 Career Assessment and how they relate to the results of previous assessment you have completed while in LEAD Scholars including True Colors, Strengths, and 16-Personalities. Step 3: Provide one personal insight about your career path gained from this learning activity. My best fit occupations included a Toy designer, an Architect, an Actor/Actress, and Funeral Director. I picked the top four to discuss. It’s interesting to me because the only occupation out of those four that have really interested me would be the architect. The Toy designer occupation seems very interesting, it has to do with arts and entertainment. I consider myself a very creative person so I could see why I got this occupation. It said that my values, personality, skills, and leisure all aligned with this occupation. The second one was an Architect. This occupation has to do with Architecture and engineering. This occupation has interested me before, because of the creativity it involves. It said that my values, skills, and leisures all aligned with this occupation. The third one was an actress. This one was very cool to see, but the last time I performed in a play was 7 years ago in middle school. I was never a theater kid or interested in being one. For this one it said my personality and leisure aligned. And lastly, a funeral director. I really did not know what to think about this one when I saw it. For this one it said work, personality, and skills all aligned. My current career interest is becoming a Pediatric Nurse Practitioner. I love to work with kids because they are so happy all the time, and I also love science and how the human body works. Lastly I want to do something in my life that is meaningful, like helping others. It was interesting to see how this assessment played out regarding my current career interest. In the leisure assessment, my top three leisure interests include Aesthetic (The creators), Correct (The Organizers) and Eager (The persuaders). I can 100% agree with these interests.It says The creators Tend to be creative and intuitive, enjoy activities like writing, painting, sculpturing, playing a musical instrument, performing, and more, enjoy working in an unstructured environment where they can use their imagination and creativity, and often described as being: open, imaginative, original, intuitive, emotional, independent, idealistic, and unconventional. It says that the The Organizers like to be involved in activities that follow set procedures and routines, like to work with data and details, have clerical or numerical ability, and carry out tasks in great detail, and often described as being conforming, practical, careful, obedient, thrifty, efficient, orderly, conscientious, and persistent. And lastly it says that The persuaders like to influence others, enjoy persuading others to see their point of view, like to work with people and ideas, rather than things, and often described as being adventurous, energetic, optimistic, agreeable, extroverted, popular, sociable, self-confident, and ambitious. All of these characteristics perfectly describe me. I don’t really think that any of the “best fit” occupations are for me. The only one I could see myself being in is an architect, but again that is nothing close to a nurse practitioner. The most important out of the five assessments to me would be values. I decided to run another report with just values, personality and skills to see what I would get. The occupation that fit me the most with those three was a clinical psychologist. Now this is more into the occupation I could see myself in. It’s more into the sciences which I liked. As I scrolled through the careers that matched, I realized the only one that was remotely close to a Nurse Practitioner was a Family Practitioner, which I would have to get a medical degree in. In conclusion, I very much enjoyed completing this assessment, and it made me realize other career options I could consider based on my personality, values, leisure, work interest, and skills.
delete the session on your best fit occupations--that info goes into your Career Ready Portfolio, not the SLJ.
-
-
www.biorxiv.org www.biorxiv.org
-
Author response:
The following is the authors’ response to the previous reviews.
eLife assessment
This important study advances our understanding of how past and future information is jointly considered in visual working memory by studying gaze biases in a memory task that dissociates the locations during encoding and memory tests. The evidence supporting the conclusions is convincing, with state-of-the-art gaze analyses that build on a recent series of experiments introduced by the authors. This work, with further improvements incorporating the existing literature, will be of broad interest to vision scientists interested in the interplay of vision, eye movements, and memory.
We thank the Editors and the Reviewers for their enthusiasm and appreciation of our task, our findings, and our article. We also wish to thank the Reviewers for their constructive comments that we have embraced to improve our article. Please find below our point-by-point responses to this valuable feedback, where we also state relevant revisions that we have made to our article.
In addition, please note that we have now also made our data and code publicly available.
Reviewer 1, Comments:
In this study, the authors offer a fresh perspective on how visual working memory operates. They delve into the link between anticipating future events and retaining previous visual information in memory. To achieve this, the authors build upon their recent series of experiments that investigated the interplay between gaze biases and visual working memory. In this study, they introduce an innovative twist to their fundamental task. Specifically, they disentangle the location where information is initially stored from the location where it will be tested in the future. Participants are tasked with learning a novel rule that dictates how the initial storage location relates to the eventual test location. The authors leverage participants' gaze patterns as an indicator of memory selection. Intriguingly, they observe that microsaccades are directed toward both the past encoding location and the anticipated future test location. This observation is noteworthy for several reasons. Firstly, participants' gaze is biased towards the past encoding location, even though that location lacks relevance to the memory test. Secondly, there's a simultaneous occurrence of an increased gaze bias towards both the past and future locations. To explore this temporal aspect further, the authors conduct a compelling analysis that reveals the joint consideration of past and future locations during memory maintenance. Notably, microsaccades biased towards the future test location also exhibit a bias towards the past encoding location. In summary, the authors present an innovative perspective on the adaptable nature of visual working memory. They illustrate how information relevant to the future is integrated with past information to guide behavior.
Thank you for your enthusiasm for our article and findings as well as for your constructive suggestions for additional analyses that we respond to in detail below.
This short manuscript presents one experiment with straightforward analyses, clear visualizations, and a convincing interpretation. For their analysis, the authors focus on a single time window in the experimental trial (i.e., 0-1000 ms after retro cue onset). While this time window is most straightforward for the purpose of their study, other time windows are similarly interesting for characterizing the joint consideration of past and future information in memory. First, assessing the gaze biases in the delay period following the cue offset would allow the authors to determine whether the gaze bias towards the future location is sustained throughout the entire interval before the memory test onset. Presumably, the gaze bias towards the past location may not resurface during this delay period, but it is unclear how the bias towards the future location develops in that time window. Also, the disappearance of the retro cue constitutes a visual transient that may leave traces on the gaze biases which speaks again for assessing gaze biases also in the delay period following the cue offset.
Thank you for raising this important point. We initially focused on the time window during the cue given that our central focus was on gaze-biases associated with mnemonic item selection. By zooming in on this window, we could best visualize our main effects of interest: the joint selection (in time) of past and future memory attributes.
At the same time, we fully agree that examining the gaze biases over a more extended time window yields a more comprehensive view of our data. To this end, we have now also extended our analysis to include a wider time range that includes the period between cue offset (1000 ms after cue onset) and test onset (1500 ms after cue onset). We present these data below. Because we believe our future readers are likely to be interested in this as well, we have now added this complementary visualization as Supplementary Figure 4 (while preserving the focus in our main figure on the critical mnemonic selection period of interest).
Author response image 1.
Supplementary Figure 4. Gaze biases in extended time window as a complement to Figure 1 and Supplementary Figure 2. This extended analysis reveals that while the gaze bias towards the past location disappears around 600 ms after cue onset, the gaze bias towards the future location persists (panel a) and that while the early (joint) future bias occurs predominantly in the microsaccade range below 1 degree visual angle, the later bias to the future location incorporates larger eye movement that likely involve preparing for optimally perceiving the anticipated test stimulus (panel b).

This extended analysis reveals that while the gaze bias towards the past location disappears around 600 ms after cue onset (consistent with our prior reports of this bias), the gaze bias towards the future location persists. Moreover, as revealed by the data in panel b above, while the early (joint) future bias occurs predominantly in the microsaccade range below 1 degree visual angle, the later bias to the future location incorporates larger eye movement that likely involve preparing for optimally perceiving the anticipated test stimulus.
We now also call out these additional findings and figure in our article:
Page 2 (Results): “Gaze biases in both axes were driven predominantly by microsaccades (Supplementary Fig. 2) and occurred similarly in horizontal-to-vertical and vertical-tohorizontal trials (Supplementary Fig. 3). Moreover, while the past bias was relatively transient, the future bias continued to increase in anticipation of the of the test stimulus and increasingly incorporated eye-movements beyond the microsaccade range (see Supplementary Fig. 4 for a more extended time range)”.
Moreover, assessing the gaze bias before retro-cue onset allows the authors to further characterize the observed gaze biases in their study. More specifically, the authors could determine whether the future location is considered already during memory encoding and the subsequent delay period (i.e., before the onset of the retro cue). In a trial, participants encode two oriented gratings presented at opposite locations. The future rule indicates the test locations relative to the encoding locations. In their example (Figure 1a), the test locations are shifted clockwise relative to the encoding location. Thus, there are two pairs of relevant locations (each pair consists of one stimulus location and one potential test location) facing each other at opposite locations and therefore forming an axis (in the illustration the axis would go from bottom left to top right). As the future rule is already known to the participants before trial onset it is possible that participants use that information already during encoding. This could be tested by assessing whether more microsaccades are directed along the relevant axis as compared to the orthogonal axis. The authors should assess whether such a gaze bias exists already before retro cue onset and discuss the theoretical consequences for their main conclusions (e.g., is the future location only jointly used if the test location is implicitly revealed by the retro cue).
Thank you – this is another interesting point. We fully agree that additional analysis looking at the period prior to retrocue onset may also prove informative. In accordance with the suggested analysis, we have therefore now also analysed the distribution of saccade directions (including in the period from encoding to retrocue) as a function of the future rule (presented below, and now also included as Supplementary Fig. 5). Complementary recent work from our lab has shown how microsaccade directions can align to the axis of memory contents during retention (see de Vries & van Ede, eNeuro, 2024). Based on this finding, one may predict that if participants retain the items in a remapped fashion, their microsaccades may align with the axis of the future rule, and this could potentially already happen prior to cue onset.
These complementary analyses show that saccade directions are predominantly influenced by the encoding locations rather than the test locations, as seen most clearly by the saccade distribution plots in the middle row of the figure below. To obtain time-courses, we categorized saccades as occurring along the axis of the future rule or along the orthogonal axis (bottom row of the figure below). Like the distribution plots, these time course plots also did not reveal any sign of a bias along the axis of the future rule itself.
Importantly, note how this does not argue against our main findings of joint selection of past and future memory attributes, as for that central analysis we focused on saccade biases that were specific to the selected memory item, whereas the analyses we present below focus on biases in the axes in which both memory items are defined; not only the cued/selected memory item.
Author response image 2.
Supplementary Figure 5. Distribution of saccade directions relative to the future rule from encoding onset. (Top panel) The spatial layouts in the four future rules. (Middle panel) Polar distributions of saccades during 0 to 1500 ms after encoding onset (i.e., the period between encoding onset and cue onset). The purple quadrants represent the axis of the future rule and the grey quadrants the orthogonal axis. (Bottom panel) Time courses of saccades along the above two axes. We did not observe any sign of a bias along the axis of the future rule itself.

We agree that these additional results are important to bring forward when we interpret our findings. Accordingly, we now mention these findings at the relevant section in our Discussion:
Page 5 (Discussion): “First, memory contents could have directly been remapped (cf. 4,24–26) to their future-relevant location. However, in this case, one may have expected to exclusively find a future-directed gaze bias, unlike what we observed. Moreover, using a complementary analysis of saccade directions along the axis of the future rule (cf. 24), we found no direct evidence for remapping in the period between encoding and cue (Supplementary Fig. 5)”.
Reviewer 2, Comments:
The manuscript by Liu et al. reports a task that is designed to examine the extent to which "past" and "future" information is encoded in working memory that combines a retro cue with rules that indicate the location of an upcoming test probe. An analysis of microsaccades on a fine temporal scale shows the extent to which shifts of attention track the location of the location of the encoded item (past) and the location of the future item (test probe). The location of the encoded grating of the test probe was always on orthogonal axes (horizontal, vertical) so that biases in microsaccades could be used to track shifts of attention to one or the other axis (or mixtures of the two). The overall goal here was then to (1) create a methodology that could tease apart memory for the past and future, respectively, (2) to look at the time-course attention to past/future, and (3) to test the extent to which microsaccades might jointly encode past and future memoranda. Finally, some remarks are made about the plausibility of various accounts of working memory encoding/maintenance based on the examination of these time courses.
Strengths:
This research has several notable strengths. It has a clear statement of its aims, is lucidly presented, and uses a clever experimental design that neatly orthogonalizes "past" and "future" as operationalized by the authors. Figure 1b-d shows fairly clearly that saccade directions have an early peak (around 300ms) for the past and a "ramping" up of saccades moving in the forward direction. This seems to be a nice demonstration the method can measure shifts of attention at a fine temporal resolution and differentiate past from future-oriented saccades due to the orthogonal cue approach. The second analysis shown in Figure 2, reveals a dependency in saccade direction such that saccades toward the probe future were more likely also to be toward the encoded location than away from the encoded direction. This suggests saccades are jointly biased by both locations "in memory".
Thank you for your overall appreciation of our work and for highlighting the above strengths. We also thank you for your constructive comments and call for clarifications that we respond to below.
Weaknesses:
(1) The "central contribution" (as the authors characterize it) is that "the brain simultaneously retains the copy of both past and future-relevant locations in working memory, and (re)activates each during mnemonic selection", and that: "... while it is not surprising that the future location is considered, it is far less trivial that both past and future attributes would be retained and (re)activated together. This is our central contribution." However, to succeed at the task, participants must retain the content (grating orientation, past) and probe location (future) in working memory during the delay period. It is true that the location of the grating is functionally irrelevant once the cue is shown, but if we assume that features of a visual object are bound in memory, it is not surprising that location information of the encoded object would bias processing as indicated by microsaccades. Here the authors claim that joint representation of past and future is "far less trivial", this needs to be evaluaed from the standpoint of prior empirical data on memory decay in such circumstances, or some reference to the time-course of the "unbinding" of features in an encoded object.
Thank you. We agree that our participants have to use the future rule – as otherwise they do not know to which test stimulus they should respond. This was a deliberate decision when designing the task. Critically, however, this does not require (nor imply) that participants have to incorporate and apply the rule to both memory items already prior to the selection cue. It is at least as conceivable that participants would initially retain the two items at their encoded (past) locations, then wait for the cue to select the target memory item, and only then consider the future location associated with the target memory item. After all, in every trial, there is only 1 relevant future location: the one associated with the cued memory item. The time-resolved nature of our gaze markers argues against such a scenario, by virtue of our observation of the joint (simultaneous) consideration of past and future memory attributes (as opposed to selection of past-before-future). These temporal dynamics are central to the insights provided by our study.
In our view, it is thus not obvious that the rule would be applied at encoding. In this sense, we do not assume that the future location is part of both memory objects from encoding, but rather ask whether this is the case – and, if so, whether the future location takes over the role of the past location, or whether past and future locations are retained jointly.
Our statements regarding what is “trivial” and what is “less trivial” regard exactly this point: it is trivial that the future is considered (after all, our task demanded it). However, it is less trivial that (1) the future location was already available at the time of initial item selection (as reflected in the simultaneous engagement of past and future locations), and (2) that in presence of the future location, the past location was still also present in the observed gaze biases.
Having said that, we agree that an interesting possibility is that participants remap both memory items to their future-relevant locations ahead of the cue, but that the past location is not yet fully “unbound” by the time of the cue. This may trigger a gaze bias not only to the new future location but also to the “sticky” (unbound) past location. We now acknowledge this possibility in our discussion (also in response to comment 3 below) where we also suggest how future work may be able to tap into this:
Page 6 (Discussion): “In our study, the past location of the memory items was technically irrelevant for the task and could thus, in principle, be dropped after encoding. One possibility is that participants remapped the two memory items to their future locations soon after encoding, and had started – but not finished – dropping the past location by the time the cue arrived. In such a scenario, the past signal is merely a residual trace of the memory items that serves no purpose but still pulls gaze. Alternatively, however, the past locations may be utilised by the brain to help individuate/separate the two memory items. Moreover, by storing items with regard to multiple spatial frames (cf. 37) – here with regard to both past and future visual locations – it is conceivable that memories may become more robust to decay and/or interference. Also, while in our task past locations were never probed, in everyday life it may be useful to remember where you last saw something before it disappeared behind an occluder. In future work, it will prove interesting to systematically vary to the delay between encoding and cue to assess whether the reliance on the past location gradually dissipates with time (consistent with dropping an irrelevant feature), or whether the past trace remains preserved despite longer delays (consistent with preserving utility for working memory).”
(2) The authors refer to "future" and "past" information in working memory and this makes sense at a surface level. However, once the retrocue is revealed, the "rule" is retrieved from long-term memory, and the feature (e.g. right/left, top/bottom) is maintained in memory like any other item representation. Consider the classic test of digit span. The digits are presented and then recalled. Are the digits of the past or future? The authors might say that one cannot know, because past and future are perfectly confounded. An alternative view is that some information in working memory is relevant and some is irrelevant. In the digit span task, all the digits are relevant. Relevant information is relevant precisely because it is thought be necessary in the future. Irrelevant information is irrelevant precisely because it is not thought to be needed in the immediate future. In the current study, the orientation of the grating is relevant, but its location is irrelevant; and the location of the test probe is also relevant.
Thank you for this stimulating reflection. We agree that in our set-up, past location is technically “task-irrelevant” while future location is certainly “task-relevant”. At the same time, the engagement of the past location suggests to us that the brain uses past location for the selection – presumably because the brain uses spatial location to help individuate/separate the items, even if encoded locations are never asked about. Therefore, whether something is relevant or irrelevant ultimately depends on how one defines relevance (past location may be relevant/useful for the brain even if technically irrelevant from the perspective of the task). In comparison, the use of “past” and “future” may be less ambiguous.
It is also worth noting how we interpret our findings in relation to demands on visual working memory, inspired by dynamic situations whereby visual stimuli may be last seen at one location but expected to re-appear at another, such as a bird disappearing behind a building (the example in our introduction). Thus, past for us does not refer to the memory item perse (like in the digit span analogue) but, rather, quite specifically to the past location of a dynamic visual stimulus in memory (which, in our experiment, was operationalised by the future rule, for convenience).
(3) It is not clear how the authors interpret the "joint representation" of past and future. Put aside "future" and "past" for a moment. If there are two elements in memory, both of which are associated with spatial bindings, the attentional focus might be a spatial average of the associated spatial indices. One might also view this as an interference effect, such that the location of the encoded location attracts spatial attention since it has not been fully deleted/removed from working memory. Again, for the impact of the encoded location to be exactly zero after the retrieval cue, requires zero interference or instantaneous decay of the bound location information. It would be helpful for the authors to expand their discussion to further explain how the results fit within a broader theoretical framework and how it fits with empirical data on how quickly an irrelevant feature of an object can be deleted from working memory.
Thank you also for this point (that is related to the two points above). As we stated in our reply to comment 1 above, we agree that one possibility is that the past location is merely “sticky” and pulls the task-relevant future bias toward the past location. If so, our time courses suggest that such “pulling” occurs only until approximately 600 ms after cue onset, as the past bias is only transient. An alternative interpretation is that the past location may not be merely a residual irrelevant trace, but actually be useful and used by the brain.
For example, the encoded (past) item locations provide a coordinate system in which to individuate/separate the two memory items. While the future locations also provide such a coordinate system, the brain may benefit from holding onto both coordinate systems at the same time, rendering our observation of joint selection in both frames. Indeed, in a recent VR experiment in which we had participants (rather than the items) rotate, we also found evidence for the joint use of two spatial frames, even if neither was technically required for the upcoming task (see Draschkow, Nobre, van Ede, Nature Human Behaviour, 2022). Though highly speculative at this stage, such reliance on multiple spatial frames may make our memories more robust to decay and/or interference. Moreover, while past location was never explicitly probed in our task, in daily life the past location may sometimes (unexpectedly) become relevant, hence it may be useful to hold onto it, just in case. Thus, considering the past location merely as an “irrelevant feature” (that takes time to delete) may not do sufficient justice to the potential roles of retaining past locations of dynamic visual objects held in working memory.
As also stated in response to comment 1 above, we now added these relevant considerations to our Discussion:
Page 5 (Discussion): “In our study, the past location of the memory items was technically irrelevant for the task and could thus, in principle, be dropped after encoding. One possibility is that participants remapped the two memory items to their future locations soon after encoding, and had started – but not finished – dropping the past location by the time the cue arrived. In such a scenario, the past signal is merely a residual trace of the memory items that serves no purpose but still pulls gaze. Alternatively, however, the past locations may be utilised by the brain to help individuate/separate the two memory items. Moreover, by storing items with regard to multiple spatial frames (cf. 37) – here with regard to both past and future visual locations – it is conceivable that memories may become more robust to decay and/or interference. Also, while in our task past locations were never probed, in everyday life it may be useful to remember where you last saw something before it disappeared behind an occluder. In future work, it will prove interesting to systematically vary to the delay between encoding and cue to assess whether the reliance on the past location gradually dissipates with time (consistent with dropping an irrelevant feature), or whether the past trace remains preserved despite longer delays (consistent with preserving utility for working memory).”
Reviewer 3, Comments:
This study utilizes saccade metrics to explore, what the authors term the "past and future" of working memory. The study features an original design: in each trial, two pairs of stimuli are presented, first a vertical pair and then a horizontal one. Between these two pairs comes the cue that points the participant to one target of the first pair and another of the second pair. The task is to compare the two cued targets. The design is novel and original but it can be split into two known tasks - the first is a classic working memory task (a post-cue informs participants which of two memorized items is the target), which the authors have used before; and the second is a classic spatial attention task (a pre-cue signal that attention should be oriented left or right), which was used by numerous other studies in the past. The combination of these two tasks in one design is novel and important, as it enables the examination of the dynamics and overlapping processes of these tasks, and this has a lot of merit. However, each task separately is not new. There are quite a few studies on working memory and microsaccades and many on spatial attention and microsaccades. I am concerned that the interpretation of "past vs. future" could mislead readers to think that this is a new field of research, when in fact it is the (nice) extension of an existing one. Since there are so many studies that examined pre-cues and post-cues relative to microsaccades, I expected the interpretation here to rely more heavily on the existing knowledge base in this field. I believe this would have provided a better context of these findings, which are not only on "past" vs. "future" but also on "working memory" vs. "spatial attention".
Thank you for considering our findings novel and important, while at the same time reminding us of the parallels to prior tasks studying spatial attention in perception and working memory. We fully agree that our task likely engages both attention to the (past) memory item as well as spatial attention to the upcoming (future) test stimulus. At the same time, there is a critical difference in spatial attention for the future in our task compared with ample prior tasks engaging spatial cueing of attention for perception. In our task, the cue never directly cues the future location. Rather, it exclusively cues the relevant memory item. It is the memory item that is associated with the relevant future location, according to the future rule. This integration of the rule-based future location into the memory representation is distinct from classical spatial-attention tasks in which attention is cued directly to a specific location via, for example, a spatial cue such as an arrow.
Thus, if we wish to think about our task as engaging cueing of spatial attention for perception, we have to at least also invoke the process of cueing the relevant location via the appropriate memory item. We feel it is more parsimonious to think of this as attending to both the past and future location of a dynamic visual object in working memory.
If we return to our opening example, when we see a bird disappear behind a building, we can keep in working memory where we last saw it, while anticipating where it will re-appear to guide our external spatial attention. Here too, spatial attention is fully dependent on working-memory content (the bird itself) – mirroring the dynamic semng in our study. Thus, we believe our findings contribute a fresh perspective, while of course also extending established fields. We now contextualize our finding within the literature and clarify our unique contribution in our revised manuscript:
Page 5 (Discussion): “Building on the above, at face value, our task may appear like a study that simply combines two established tasks: tasks using retro-cues to study attention in working memory (e.g.,2,31-33) and tasks using pre-cues to study orienting of spatial attention to an upcoming external stimulus (e.g., 31,32,34–36). A critical difference with common pre-cue studies, however, is that the cue in our task never directly informed the relevant future location. Rather, as also stressed above, the future location was a feature of the cued memory item (according to the future rule), and not of the cue itself. Note how this type of scenario may not be uncommon in everyday life, such as in our opening example of a bird flying behind a building. Here too, the future relevant location is determined by the bird – i.e. the memory content – itself.”
Reviewer 2, Recommendations:
It would be helpful to set up predictions based on existing working memory models. Otherwise, the claim that the joint coding of past/future is "not trivial" is simply asserted, rather than contradicting an existing model or prior empirical results. If the non-trivial aspect is simply the ability to demonstrate the joint coding empirical through a good experimental design, make it clear that this is the contribution. For example, it may be that prevailing models predict exactly this finding, but nobody has been able to demonstrate it cleanly, as the authors do here. So the non-triviality is not that the result contradicts working memory models, but rather relates to the methodological difficulty of revealing such an effect.
Thank you for your recommendation. First, please see our point-by-point responses to the individual comments above, where we also state relevant changes that we have made to our article, and where we clarify what we meant with “non trivial”. As we currently also state in our introduction, our work took as a starting point the framework that working memory is inherently about the past while being for the future (cf. van Ede & Nobre, Annual Review of Psychology, 2023). By virtue of our unique task design, we were able to empirically demonstrate that visual contents in working memory are selected via both their past and their future-relevant locations – with past and future memory attributes being engaged together in time. With “not trivial” we merely intend to make clear that there are viable alternatives than the findings we observed. For example, past could have been replaced by the future, or it could have been that item selection (through its past location) was required before its future-relevant location could be considered (i.e. past-before-future, rather than joint selection as we reported). We outline these alternatives in the second paragraph of our Discussion:
Page 5 (Discussion): “Our finding of joint utilisation of past and future memory attributes emerged from at least two alternative scenarios of how the brain may deal with dynamic everyday working memory demands in which memory content is encoded at one location but needed at another.
First, [….]”
Our work was not motivated from a particular theoretical debate and did not aim to challenge ongoing debates in the working-memory literature, such as: slot vs. resource, active vs. silent coding, decay vs. interference, and so on. To our knowledge, none of these debates makes specific claims about the retention and selection of past and future visual memory attributes – despite this being an important question for understanding working memory in dynamics everyday semngs, as we hoped to make clear by our opening example.
Reviewer 3, Recommendations:
I recommend that the present findings be more clearly interpreted in the context of previous findings on working memory and attention. The task design includes two components - the first (post-cue) is a classic working memory task and the second (the pre-cue) is a classic spatial attention design. Both components were thoroughly studied in the past and this previous knowledge should be better integrated into the present conclusions. I specifically feel uncomfortable with the interpretation of past vs. future. I find this framework to be misleading because it reads like this paper is on a topic that is completely new and never studied before, when in fact this is a study on the interaction between working memory and spatial attention. I recommend the authors minimize this past-future framing or be more explicit in explaining how this new framework relates to the more common terminology in the field and make sure that the findings are not presented in a vacuum, as another contribution to the vibrant field that they are part of.
Thank you for these recommendations. Please also see our point-by-point responses to the individual comments above. Here, we explained our logic behind using the terminology of past vs. future (in addition, see also our response to point 2 or reviewer 2). Here, we also stated relevant changes that we have made to our manuscript to explain how our findings complement – but are also distinct from – prior tasks that used pre-cues to direct spatial attention to an upcoming stimulus. As we explained above, in our task, the cue itself never contained information about the upcoming test location. Rather, the upcoming test location was a property of the memory item (given the future rule). Hence, we referred to this as a “future attribute” of the cued memory item, rather than as the “cued location” for external spatial attention. Still, we agree the future bias likely (also) reflects spatial allocation to the upcoming test array, and we explicitly acknowledge this in our discussion. For example:
Page 5 (Discussion): “This signal may reflect either of two situations: the selection of a future-copy of the cued memory content or anticipatory attention to its the anticipated location of its associated test-stimulus. Either way, by the nature of our experimental design, this future signal should be considered a content-specific memory attribute for two reasons. First, the two memory contents were always associated with opposite testing locations, hence the observed bias to the relevant future location must be attributed specifically to the cued memory content. Second, we cued which memory item would become tested based on its colour, but the to-be-tested location was dependent on the item’s encoding location, regardless of its colour. Hence, consideration of the item’s future-relevant location must have been mediated by selecting the memory item itself, as it could not have proceeded via cue colour directly.”
Page 6 (Discussion): “Building on the above, at face value, our task may appear like a study that simply combines two established tasks: tasks using retro-cues to study attention in working memory (e.g.,2,31-33) and tasks using pre-cues to study orienting of spatial attention to an upcoming external stimulus (e.g., 31,32,34–36). A critical difference with common pre-cue studies, however, is that the cue in our task never directly informed the relevant future location. Rather, as also stressed above, the future location was a feature of the cued memory item (according to the future rule), and not of the cue itself. Note how this type of scenario may not be uncommon in everyday life, such as in our opening example of a bird flying behind a building. Here too, the future relevant location is determined by the bird – i.e. the memory content – itself.”
-
-
www.biorxiv.org www.biorxiv.org
-
Author response:
The following is the authors’ response to the previous reviews.
Public Reviews:
Reviewer #1 (Public Review):
Gap junction channels establish gated intercellular conduits that allow the diffusion of solutes between two cells. Hexameric connexin26 (Cx26) hemichannels are closed under basal conditions and open in response to CO2. In contrast, when forming a dodecameric gapjunction, channels are open under basal conditions and close with increased CO2 levels. Previous experiments have implicated Cx26 residue K125 in the gating mechanism by CO2, which is thought to become carbamylated by CO2. Carbamylation is a labile post-translational modification that confers negative charge to the K125 side chain. How the introduction of a negative charge at K125 causes a change in gating is unclear, but it has been proposed that carbamylated K125 forms a salt bridge with the side chain at R104, causing a conformational change in the channel. It is also unclear how overall gating is controlled by changes in CO2, since there is significant variability between structures of gap-junction channels and the cytoplasmic domain is generally poorly resolved. Structures of WT Cx26 gap-junction channels determined in the presence of various concentrations of CO2 have suggested that the cytoplasmatic N-terminus changes conformation depending on the concentration of the gas, occluding the pore when CO2 levels are high.
In the present manuscript, Deborah H. Brotherton and collaborators use an intercellular dyetransfer assay to show that Cx26 gap-junction channels containing the K125E mutation, which mimics carbamylation caused by CO2, is constitutively closed even at CO2 concentrations where WT channels are open. Several cryo-EM structures of WT and mutant Cx26 gap junction channels were determined at various conditions and using classification procedures that extracted more than one structural class from some of the datasets. Together, the features on each of the different structures are generally consistent with previously obtained structures at different CO2 concentrations and support the mechanism that is proposed in the manuscript. The most populated class for K125E channels determined at high CO2 shows a pore that is constricted by the N-terminus, and a cytoplasmic region that was better resolved than in WT channels, suggesting increased stability. The K125E structure closely resembles one of the two major classes obtained for WT channels at high CO2. These findings support the hypothesis that the K125E mutation biases channels towards the closed state, while WT channels are in an equilibrium between open and closed states even in the presence of high CO2. Consistently, a structure of K125E obtained in the absence of CO2 appeared to also represent a closed state but at lower resolution, suggesting that CO2 has other effects on the channel beyond carbamylation of K125 that also contribute to stabilizing the closed state. Structures determined for K125R channels, which are constitutively open because arginine cannot be carbamylated, and would be predicted to represent open states, yielded apparently inconclusive results.
A non-protein density was found to be trapped inside the pore in all structures obtained using both DDM and LMNG detergents, suggesting that the density represents a lipid rather than a detergent molecule. It is thought that the lipid could contribute to the process of gating, but this remains speculative. The cytoplasmic region in the tentatively closed structural class of the WT channel obtained using LMNG was better resolved. An additional portion of the cytoplasmic face could be resolved by focusing classification on a single subunit, which had a conformation that resembled the AlphaFold prediction. However, this single-subunit conformation was incompatible with a C6-symmetric arrangement. Together, the results suggest that the identified states of the channel represent open states and closed states resulting from interaction with CO2. Therefore, the observed conformational changes illuminate a possible structural mechanism for channel gating in response to CO2.
Some of the discussion involving comparisons with structures of other gap junction channels are relatively hard to follow as currently written, especially for a general readership. Also, no additional functional experiments are carried out to test any of the hypotheses arising from the data. However, structures were determined in multiple conditions, with results that were consistent with the main hypothesis of the manuscript. No discussion is provided, even if speculative, to explain the difference in behavior between hemichannels and gap junction channels. Also, no attempt was made to measure the dimensions of the pore, which is relevant because of the importance of identifying if the structures indeed represent open or closed states of the channel.
We have considerably revised the manuscript in an attempt to make it more tractable. We respond to the individual comments below.
Reviewer #2 (Public Review):
Summary:
The manuscript by Brotherton et al. describes a structural study of connexin-26 (Cx26) gap junction channel mutant K125E, which is designed to mimic the CO2-inhibited form of the channel. In the wild-type Cx26, exposure to CO2 is presumed to close the channel through carbamylation of the residue K125. The authors mutated K125 to a negatively charged residue to mimic this effect, and they observed by cryo-EM analysis of the mutated channel that the pore of the channel is constricted. The authors were able to observe conformations of the channel with resolved density for the cytoplasmic loop (in which K125 is located). Based on the observed conformations and on the position of the N-terminal helix, which is involved in channel gating and in controlling the size of the pore, the authors propose the mechanisms of Cx26 regulation.
Strengths:
This is a very interesting and timely study, and the observations provide a lot of new information on connexin channel regulation. The authors use the state of the art cryo-EM analysis and 3D classification approaches to tease out the conformations of the channel that can be interpreted as "inhibited", with important implications for our understanding of how the conformations of the connexin channels controlled.
Weaknesses:
My fundamental question to the premise of this study is: to what extent can K125 carbamylation by recapitulated by a simple K125E mutation? Lysine has a large side chain, and its carbamylation would make it even slightly larger. While the authors make a compelling case for E125-induced conformational changes focusing primarily on the negative charge, I wonder whether they considered the extent to which their observation with this mutant may translate to the carbamoylated lysine in the wild-type Cx26, considering not only the charge but also the size of the modified side-chain.
This is an important point. We agree that the difference in size will have a different effect on the structure. For kinases, aspartate or glutamate are often used as mimics of phosphorylated serine or threonine and these will have the same issues. The fact that we cannot resolve the relevant side-chains in the density may be indicative that the mutation doesn’t give the whole story. It may be able to shift the equilibrium towards the closed conformation, but not stably trap the molecule in that conformation. We include a comment to this effect in the revised manuscript.
Reviewer #3 (Public Review):
Summary:
The mechanism underlying the well-documented CO2-regulated activity of connexin 26 (Cx26) remains poorly understood. This is largely due to the labile nature of CO2-mediated carbamylation, making it challenging to visualize the effects of this reversible posttranslational modification. This paper by Brotherton et al. aims to address this gap by providing structural insights through cryo-EM structures of a carbamylation-mimetic mutant of the gap junction protein.
Strengths:
The combination of the mutation, elevated PCO2, and the use of LMNG detergent resulted in high-resolution maps that revealed, for the first time, the structure of the cytoplasmic loop between transmembrane helix (TM) 2 and 3.
Weaknesses:
The presented maps merely reinforce their previous findings, wherein wildtype Cx26 favored a closed conformation in the presence of high PCO2. While the structure of the TM2-TM3 loop may suggest a mechanism for stabilizing the closed conformation, no experimental data was provided to support this mechanism. Additionally, the cryo-EM maps were not effectively presented, making it difficult for readers to grasp the message.
We have extensively revised the manuscript so that the novelty of this study is more apparent. There are three major points
(1) The carbamylation mimetic pushes the conformation towards the closed conformation. Previously we just showed that CO2 pushes the conformation towards this conformation. Though we could show this was not due to pH, and could speculate this was due to carbamylation as suggested by previous mutagenesis studies, our data did not provide any mechanism whereby Lys125 was involved.
(2) In going from the open to closed conformations, not only is a conformational change in TM2 involved, as we saw previously, but also a conformational change in TM1, the linker to the N-terminus and the cytoplasmic loop. Thus there is a clear connection between Lys125 and the conformation of the pore-closing N-terminus.
(3) We observe for the first time in any connexin structure, density for the cytoplasmic loop. Since this loop is important in regulation, knowing how it might influence the positions of the transmembrane helices is important information if we are to understand how connexins can be regulated.
Reviewing Editor:
The reviewers have agreed on a list of suggested revisions that would improve the eLife assessment if implemented, which are as follows:
(1) For completeness, Figure 1 could be supplied with an example of how the experiment would look like in the presence of CO2 - for the wild-type and for the K125E mutant. presumably for the wild-type this has been done previously in exactly this assay format, but this control would be an important part of characterization for the mutant. Page 4, lines 105106; "unsurprisingly, Cx26K125E gap junctions remain closed at a PCO2 of 55 mmHg." The data should be presented in the manuscript.
We have now included the data with a PCO2 of 55mmH. This is now Figure 4 in our revised manuscript.
(2) Would AlphaFold predictions show any interpretable differences in the E125 mutant, compared to the K125 (the wild-type)?
We tried this in response to the reviewer’s suggestion. We did not see any interpretable differences. In general AlphaFold is not recognised as giving meaningful information around point mutations.
(3) The K125R mutant appears to be a more effective control for extracting significant features from the K125E maps. Given that the use of a buffer containing high PCO2 is essential for obtaining high-resolution maps, wildtype Cx26 is unsuitable as an appropriate control. The K125R map, obtained at a high resolution (2.1Å), supports its suitability as a robust control.
Though we are unsure what the referee is referring to here, we have rewritten this section and compare against the K125R map (figure 5a) as well as that derived from the wild-type protein. The important point is that the K125E mutant, causes a structural change that is consistent with the closure of the gap junctions that we observe in the dye-transfer assays.
(4) Likewise, the rationale for using wildtype Cx26 maps obtained in DDM is unclear. Wildtype Cx26 seems to yield much better cryo-EM maps in LMNG. We suggest focusing the manuscript on the higher-quality maps, and providing supporting information from the DDM maps to discuss consistency between observations and the likely possibility that the nonprotein density in the pore is lipid and not detergent.
The rationale for comparing the mutants against the wt Cx26 maps obtained in DDM was because the mutants were also solubilised in DDM. However, taking the lead from the referees’ comments, we have now rewritten the manuscript so that we first focus on the data we obtain from protein solubilised in LMNG. We feel this makes our message much clearer.
(5) In general, the rationale for utilizing cryo-EM maps with the entire selected particles is unclear. Although the overall resolutions may slightly improve in this approach, the regions of interest, such as the N-terminus and the cytoplasmic loop, appear to be better ordered afer further classifications. The paper would be more comprehensible if it focuses solely on the classes representing the pore-constricting N-terminus (PCN) and the pore-open flexible Nterminus (POFN) conformations. Also, the nomenclatures used in the manuscript, such as "WT90-Class1", "K125E90-1", "LMNG90-class1", "LMNG90-mon-pcn" are confusing.
LMNG90s are also wildtype; K125E-90-1 is in Class1 for this mutant and is similar to WT90Class2, which represents the PCN conformation. More consistent and intuitive nomenclatures would be helpful.
We agree with the referees’ comments. This should now be clearer with our rewritten manuscript where we have simplified this considerably. We now call the conformations NConst (N-terminus defined and constricting the pore) and NFlex (N-terminus not visible) and keep this consistent throughout.
(6) A potential salt bridge between the carbamylated K125 and R104 is proposed to account for the prevalence of Class-1 (i.e., PCN) in the majority of cryo-EM particles. However, the side chain densities are not well-defined, suggesting that such an interaction may not be strong enough to trap Cx26 in a closed conformation. Furthermore, the absence of experimental data to support this mechanism makes it unclear how likely this mechanism may be. Combining simple mutagenesis, such as R104E, with a dye transfer assay could offer support for this mechanism. Are there any published experimental results that could help address this question without the need for additional experimental work? Alternatively, as acknowledged in the discussion, this mechanism may be deemed as an "over-simplification." What is an alternative mechanism?
R104 has been mutated to alanine in gap junctions and tested in a dye transfer assay as now mentioned in the text (Nijar et al, J Physiol 2021) supporting this role. In hemichannels R104 has been mutated to both alanine and glutamate and tested through dye loading assays Meigh et al, eLife 2013). Also in hemichannels R104 and K125 have been mutated to cysteines allowing them to be cross-linked through a disulphide bond. This mutant responds to a change in redox potential in a similar way to which the wild type protein responds to CO2 (Meigh et al, Open Biol 2015). Therefore, there is no doubt that the residues are important for the mechanism and the salt-bridge interaction seems a plausible mechanism to reconcile the mutagenesis data, however we cannot be sure that there are not other interactions involved that are necessary for closure. This information has now been included in the text.
(7) The cryo-EM maps presented in the manuscript propose that gap junctions are constitutively open under normal PCO2 as the flexible N-terminus clears the solute permeation pathway in the middle of the channel. However, hemichannels appear to be closed under normal PCO2. It is puzzling how gap junctions can open when hemichannels are closed under normal PCO2 conditions. If this question has been addressed in previous studies, the underlying mechanism should be explicitly described in the introduction. If it remains an open question, differences in the opening mechanisms between hemichannels and gap junctions should be investigated.
We suspect this is due to the difference in flexibility of gap junctions relative to hemichannels. However, a discussion of this is beyond this paper and would be complete speculation based on hemichannel structures of other connexins, performed in different buffering systems. There are no high resolution structures of Cx26 hemichannels.
(8) A mystery density likely representing a lipid is abruptly introduced, but the significance of this discovery is unclear. It is hard to place the lipid on Figure S6 in the wider context of everything else that is discussed in the text. It would be helpful for readers if a figure were provided to show where the density is located in relation to all the other regions that are extensively discussed in the text.
In the revised text this section has been completely rewritten. We have now include a more informative view in a new figure (Figure 1 – figure supplement 3).
(9) Including and displaying even tentative pore-diameter measurements for the different states - this would be helpful for readers and provide a more direct visual cue as to the difference between open and closed states.
We have purposely avoided giving precise measurements to the pore-diameter, since this depends on how we model the N-terminus. The first three residues are difficult to model into the density without causing stearic clashes with the neighbouring subunits.
(10) Given that no additional experiments for channel function were carried out, it would be useful if to provide a more detailed discussion of additional mutagenesis results from the literature that are related to the experimental results presented.
We have amplified this in the discussion (see answer to point 6).
The reviewers also agreed that improvements in the presentation of the data would strengthen the manuscript. Here is a summary list of suggestions by reviewers aimed at helping improve how the data is presented:
(1) Why is the pipette bright green in the top image, but rather weakly green in the bottom image in Figure 1 - is this the case for all images?
(Now figure 4) This depends on whether the pipette was in the focal plane of view or not. The important point of these images is the difference in intensity of the donor vs the recipient cell. The graphs in figure 4c illustrate clearly the difference between the wild-type and the mutant gap junctions.
(2) In figures 2-5, labels would help a lot in understanding what is shown - while the legends do provide the information on what is presented, it would help the reader to see the models/maps with labels directly in the panel. For example, Figure 2a/b - just indicating "WT90 Cx26" in pink and "K125E90" in blue directly in the panel would reduce the work for the reader.
We have extensively modified the labels in the figures to address this issue.
(3) Figure 4 - magenta and pink are fairly close, and to avoid confusion it might be useful to use a different color selection. This is especially true when structures are overlayed, as in this figure - the presentation becomes rather complicated, so the less confusion the color code can introduce, the better.
(Now Figure 2) We have now changed pink to blue.
(4) Figure 5 - a remarkably under-labelled figure.
Now added labels.
(5) Figure 6 - it would be interesting to add a comparison to Cx32 here as well for completeness, since the structure has been published in the meantime.
Cx32 has now been included.
(6) Figure 7 - please add equivalent labels on both sides of the model, left and right. Add the connecting lines for all of the tubes TM helices - this will help trace the structural elements shown. The legend does not quite explain the colors.
We have modified the figure as suggested and explained the colours in the legend.
(8) Fig.1 legend; Unclear what mCherry fluorescence represents. State that Cx26 was expressed as a translational fusion with mCherry.
Now figure 4. We have now written “Montages each showing bright field DIC image of HeLa cells with mCherry fluorescence corresponding to the Cx26K125E-mCherry fusion superimposed (leftmost image) and the permeation of NBDG from the recorded cell to coupled cells.”
(9) Fig. 3 b); Show R104 in the figure. Also E129-R98/R99 interaction is hard to acknowledge from the figure. It seems that the side chain density of E129 is not strong enough to support the modeled orientation.
This is now Figure 1c. While the density in this region is sufficient to be confident of the main chain, we agree that the side chain density for the E129-R98/R99 interaction is not sufficiently clear to draw attention to and have removed the associated comment from the figure legend. The density is focussed on the linker between TM1 and the N-terminus and the KVRIEG motif. We prefer to omit R104, in order to keep the focus on this region. As described in the manuscript, the density for the R104 side chain is poor.
(10) Fig. 3 c); Label the N-terminus and KVRIEG motif in the figure.
Now Figure 1b. We have labelled the N-terminus. The KVRIEG motif is not visible in this map.
(11) Page 9, lines 246-248; Restate, "We note, however, density near to Lys125, between Ser19 in the TM1-N-term linker, Tyr212 of TM4 and Tyr97 on TM3 of the neighbouring subunit, which we have been unable to explain with our modelling."
We have reworded this.
(12) Page 14, line 399; Patch clamp recording is not included in the manuscript.
Patch clamp recordings were used to introduce dye into the donor cell.
(13) On the same Figure 2, clashes are mentioned but these are hard to appreciate in any of the figures shown. Perhaps would be useful to include an inset showing this.
We have modified Figure 2b slightly and added an explanation to highlight the clash. It is slightly confusing because the residues involved belong to neighbouring subunits.
(14) The discussion related to Figure 6 is very hard to follow for readers who are not familiar with the context of abbreviations included on the figure labels. This figure could be improved to allow a general readership to identify more clearly each of the features and structural differences that are discussed in the text.
We have extensively changed the text and updated the labels on the figure to make it much easier for the reader to follow.
Below, you can find the individual reviews by each of the three reviewers.
Reviewer #1 (Recommendations For The Authors):
(1) In Figure 2d-e, the text discusses differences between K125E 90-1 and WT 90-class2 (7QEW), yet the figure compares K125E with 7QEQ. I suggest including a figure panel with a comparison between the two structures discussed in the manuscript text.
This has been changed in the revised manuscript.
Other comments have been addressed above.
-
-
www.biorxiv.org www.biorxiv.org
-
Author response:
The following is the authors’ response to the previous reviews.
The reviewers thoughtful comments have helped us make the manuscript both more comprehensive and clearer. Thank you for your time and effort. We know that this is a long and technical paper. In our responses we refer to three documents:
-
Original: the first original submission
-
Revision: the revised document (02 MillardFranklinHerzog2023 v2.pdf)
-
Difference: a document that shows the changes made to text (but not figures or tables) from the original to revision (03 MillardFranklinHerzog2023 diff.pdf).
Reviewer #1 (Recommendations For The Authors):
(1) In general, the paper is well written and addresses important questions of muscle mechanics and muscle modeling. In the current version, the model limitations are briefly summarized in the abstract. However, the discussion needs a more complete description of limitations as well as a discussion of types of data (in vivo, ex vivo, single fiber, wholes muscle, MTU, etc.) that can be modeled using this approach.
Please see the response to comment 23 for more details of the limitations that have been added to the revised document.
(2) The choice of a model with several tendon parameters for simulating single muscle fiber experiments is not well justified.
A rigid-tendon model with a slack length of zero was, in fact, used for these simulations for both the VEXAT and Hill models. In case this is still not clear: a rigid-tendon model of zero length is equivalent to no tendon at all. The text that first mentions the tendon model has now been modified to make it clearer that the parameters of the model were set to be consistent with no tendon at all:
Please see the following text:
Original:
-
page 17, column 1, line 28 ”... rigid tendon of zero length,”
-
page 17, column 1, line 51 ”... rigid tendon of zero length.”
Revision:
-
page 19, column 1, line 19 ”... we used a rigid-tendon of zero length (equivalent to ignoring the tendon)”
-
page 19, column 1, line 38 ”... coupled with a rigid-tendon of zero-length.”
Difference:
-
page 21, column 1, line 19 ”... we used a rigid-tendon... ”
-
page 21, column 1, line 45 ”... rigid-tendon of zero length ...”
(3) A table that clarifies how all model parameters were estimated needs to be included in the main part of the manuscript.
Two tables have been added to the manuscript that detail the parameters of the elastic-tendon cat soleus model (in the main body of the text) and the rabbit psoas fibril model (in an appendix). Each table includes:
-
A plain language parameter name
-
The mathematical symbol for the parameter
-
The value and unit of the parameter
-
A coded reference to the data source that indicates both the experimental animal and how the data was used to evaluate the parameter.
Please see the following text:
Revision:
-
page 11
-
page 42
Difference:
-
page 11
-
page 46
(4) The supplemental information is not properly referenced in the main text. There are a number of smaller issues that also need to be addressed.
Thank for your attention to detail. The following problems related to Appendix referencing have been fixed:
-
Appendices are now parenthetically referenced at the end of a sentence. However, a few references to figures (that are contained within anAppendix) still appear in the body of the sentence since moving these figure references makes the text difficult to understand.
-
All Appendices are now referenced in the main body of the text.
(5) Abstract, line 6: While it is commonly assumed that the short range stiffness of muscle is due to cross bridges, Rack & Westbury (1974) noted that it occurs over a distance of 25-35 nm, and that many cross-bridges must be stretched even farther than this distance (their p. 348 middle). It seems unlikely that cross-bridges alone can actually account for the short-range stiffness.
There are three parts to our response to this comment:
(a) Rack & Westbury’s definition of short-range-stiffness and unrealistic cross-bridge stretches
(b) Rack & Westbury’s definition of short-range-stiffness vs. linear-timeinvariant system theory
(c) Updates to the paper
a. Rack & Westbury’s definition of short-range-stiffness and unrealistic cross-bridge stretches.
As you note, on page 348, Rack and Westbury write that ”If the short range stiffness is to be explained in terms of extension of cross-bridges, then many of them must be extended further than the 25-35 nm mentioned above.” Having re-read the paper, its not clear how these three factors are being treated in the 25−35 nm estimate:
-
the elasticity of the tendon and aponeurosis,
-
the elasticity of actin and myosin filaments,
-
and the cycling rate of the cross-bridges.
Obviously the elasticity of the tendon, aponeurosis, actin, and myosin filaments will reduce the estimated amount of crossbridge strain during Rack and Westbury’s experiments. A potentially larger factor is the cycling rate of each cross-bridge. If each crossbridge cycles faster than 11 Hz (the maximum frequency Rack and Westbury used), then no single crossbridge would stretch by 25-35 nm. So why didn’t Rack and Westbury consider the cycling rate of crossbridges?
Rack and Westbury’s reasoned that a perfectly elastic work loop would necessarily mean that all crossbridges stayed attached: as soon as a crossbridge cycles it would release its stored elastic energy and the work loop would no longer be elastic. Since Rack and Westbury measured some nearly perfect elastic work loops (the smallest loops in Fig. 2,3, and 4), I guess they assumed crossbridges remained attached during the 25-35 nm crossbridge stretch estimate. However, even Rack and Westbury note that none of the work loops they measured were perfectly elastic and so there is room to entertain the idea that crossbridges are cycling.
Fortunately, for this discussion, crossbridge cycling rates have been measured.
In-vitro measurements by Uyeda et al. show that crossbridges are cycling at 30 Hz when moving at 0.5-1.2 length/s. At this rate, there would be enough time for a single crossbridge to cycle nearly 2.72 times for every cycle of the 11 Hz sinusoidal perturbations, reducing its expected strain from 25-35 nm down to 9.2−12.9µm. This effect becomes even more pronounced if crossbridge cycling rate is used to explain the difference in sliding velocity between Uyeda et al.’s in-vitro data (0.5-1.2 length/s) and the maximum contraction velocity of an in-situ cat soleus (4.65 lengths/s, Scott et al.).
b. Rack & Westbury’s definition of short-range-stiffness vs. linear-time-invariant system theory
Rack and Westbury defined short-range-stiffness to describe a specific kind of force response of the muscle to cyclical length changes:
-
muscle force is linear with length change,
-
and independent of velocity.
Rack and Westbury’s definition therefore fails when viscous forces become noticeable, because viscous forces are velocity dependent.
On line 6 of the abstract the term ‘short-range-stiffness’ is not used because Rack and Westbury’s definition is too narrow for our purposes. Instead we are using the more general approach of approximating muscle as a linear-timeinvariant (LTI) system, where it is assumed that
-
the response of the system is linear
-
and time invariant.
To unpack that a little, a muscle is considered in the ‘short-range’ in our work if it meets the criteria of a linear time-invariant (LTI) system:
-
the force response of muscle can be accurately described as a linear function of its length and velocity (its state)
-
and its response is not a function of time (which means constant stimulation, and no fatigue).
In contrast to Rack and Westbury’s definition, the ‘short-range’ in linear systems theory is general enough to accommodate both elastic and viscous forces. In physical terms, small for an LTI approximation of muscle is larger than the short-range defined by Rack and Westbury: an LTI system can include velocity dependence, while short-range-stiffness ends when velocity dependence begins.
c. Updates to the paper
To make the differences between Rack and Westbury’s ‘short-range-stiffness’ and LTI system theory clearer: - We have removed all occurrences of ‘short-range’ that were associated with Kirsch et al. and have replaced this phrase with ‘small’.
- On the first mention of Kirsch’s work we have made the wording more specific
Revision:
-
page 1, column 1, lines 4,5
-
page 1, column 2, lines 14-21 ”Under constant activation ...”
Difference: page 1, column 2, line 19-26
-
page 1, column 1, lines 4,5
-
page 1, column 2, lines 20-27 ”Under constant activation ...”
-
A footnote has been added to contrast the definition of ‘small’ in the context of an linear time invariant system to ‘short-range’ in the context of Rack and Westbury’s definition of short-range-stiffness.
Revision: page 1, column 2, bottom
Difference: page 1, column 2, bottom
- In addition, we have added a brief overview of LTI system theory to make the analysis and results more easily understood:
Revision: Figure 4 paragraph beginning on page 10, column 2, line 15 ”As long as ...”
Difference: Figure 4 paragraph beginning on page 12, column 1, line 46 ”As long as ...”
(6) Page 3, lines 6-8: It also seems unlikely that 25% of cross-bridges are attached at one time (Howard, 1997) even for supramaximal isometric stimulation. The number should be less than 20%. What would the ratio of load path stiffness be for low force movements such as changing the direction of a frictionless manipulandum or slow walking? The range of relative stiffnesses is of more interest than the upper limit.
We have made the following updates to address this comment:
-
A 20% duty cycle now defines the upper bound stiffness of the actinmyosin load path.
-
We have also evaluated the lower bound actin-myosin stiffness when a single crossbridge is attached.
-
The stiffness of titin from Kellermayer et al. has been digitized at a length of 2 µm and 4 µm to more accurately capture the length dependence of titin’s stiffness.
-
We have added a new figure (Figure 14) to make it easier to compare the range of actin-myosin stiffness to titin-actin stiffness.
-
The text in the main body of the paper and the Appendix has been updated.
-
The script ’main ActinMyosinAndTitinStiffness.m’ used to perform the calculations and generate the figure is now a part of the code repository.
Please see the following text:
Revision
-
The paragraph beginning at page 2, column 2, line 45 ”The addition of a titin element ...”
-
Appendix A
-
Figure 14 (in Appendix A)
Difference
-
The paragraph beginning at page 3, column 1, line 6: ”The addition of a titin element ...”
-
Appendix A
-
Figure 14 (in Appendix A)
(7) Page 5, line 12: A word seems to be missing here, ”...together to further...”.
Thank you for your attention to detail. The sentence has been corrected.
Please see the following text:
-
Revision: page 4, column 2, line 40 ”... into a single ...”
-
Difference: page 5, column 1, line 18
(8) Page 5, line 24-27: These ”theories” are not mutually exclusive, and it is misleading to suggest they are. There is evidence for binding of titin to actin at multiple locations and there is no reason why evidence supporting one binding location must detract from the evidence supporting other binding locations.
The text has been modified to make it clear to readers that the different titinactin binding locations are not mutually exclusive. Please see the following text:
-
Revision: page 5, column 1, lines 17-19, the sentence beginning ”As previously mentioned, ...”
-
Difference: page 5, column 1, lines 41-44
(9) Page 5, lines 48-51: Should cite Kellermayer and Granzier (1996) not Kellermayer et al. (1997).
The reference to ‘Kellermayer et al.’ has been changed to ‘Kellermayer and Granzier’. The comment that the year of the reference should be changed from (1997) to (1996) is confusing: the 1996 paper is being referenced.
For further details please see:
-
Revision: page 5, column 1, 39-40
-
Difference: page 5, column 2, line 19-22
(10) Also, Dutta et al. (2018) should be cited as further showing that N2A titin by itself slows actin motility on myosin.
Thank you for the suggestion. The sentence has been modified to include Dutta et al.:
For further details please see:
-
Revision: page 5, column 1, 40
-
Difference: page 5, column 2, line 19-22
(11) Figure 2 legend and elsewhere: it is odd to say that experiments used ”a cat soleus” when more than one cat coleus was used. Change to ”cat coleus”. See also page 15, line 15.
Thank you for your attention to detail. All occurrences of ‘a cat soleus’ have been changed, with some sentence revision, to ‘cat soleus’.
(12) Page 6, line 10: It is not clear why an MTU was used to simulate single muscle fiber experiments. What is the justification for choosing this particular model? Also, the choice of model might explain why the version with stiff tendon performs better than the version with an elastic tendon, but this is never mentioned. Why not use a muscle model with no tendon (e.g., Wakeling et al., 2021 J. Biomech.)?
Please see the response to comment 2.
(13) Millard et al.’s activation dynamics model also fails to capture the lengthdependence of activation dynamics (Shue and Crago, 1998; Sandercock and Heckman, 1997), which should be noted in the discussion along with other limitations.
An additional limitations paragraph is in the revised manuscript that addresses this comment specifically. However, we have used Stephenson and Wendt as a reference for the shift in peak isometric force that comes with submaximal activation. In addition, we also reference Chow and Darling for the property that the maximum shortening velocity is reduced with submaximal activations.
-
Revision: page 22, column 1, line 41 ”Finally, the VEXAT model ...”
-
Difference: page 24, column 2, line 12 ”Finally, the VEXAT model ...”
In addition, please see the response to comment 23.
(14) Page 6, line 22: ”An underbar...”.
Thank you for your attention to detail, this correction has been made.
(14) Page 7, lines 27-32: This and other issues should be described in the Discussion under a heading of model limitations.
Please see the response to comment 23.
(15) Page 7, lines 43-44: Numerous papers from the last author’s laboratory contradict the claim that there is no force enhancement on the ascending limb by demonstrating that force enhancement does occur on the ascending limb (see e.g., Leonard & Herzog 2002, Peterson et al., 2004 and several papers from the Rassier laboratory).
Thank you for your attention to detail. This statement is in error and has been removed. To improve this section of the paper, a paragraph has been added to briefly mention the experimental observations of residual force enhancement before proceeding to explain how this phenomena is represented by the model.
Please see the following text:
Revision:
-
the paragraph starting on page 7, column 2, line 43 ”When active muscle is lengthened, ...”
-
and the following paragraph starting on page 8, column 1, line 3 “To develop RFE, ”
Difference:
-
the paragraph starting on page 8, column 2, line 15
-
and the following paragraph starting on page 9, column 1, line 6
(17) Figure 3 legend and elsewhere: The authors use Prado et al. (2005) to determine several titin parameters, however the simulations seem to focus on cat soleus, but Prado et al.’s paper is on rabbits. More clarity is needed about which specific results from which species and muscles were used to parameterize the model.
The new parameter table includes coded entries to indicate the literature source for experimental data, the animal it came from, and how the data was used. For example, the ‘ECM fraction’ has a source of ‘R[57]’ to show that the data came from rabbits from reference 57. For further details, please see the response to comment #3
Please see the following text:
-
Revision: page 11, column 2, table section H: ‘ECM fraction’.
-
Difference: page 11, column 2, table section H: ‘ECM fraction’.
To address this comment in a little more detail, we have had to use Prado et al. (2005) to give us estimates for only one parameter: P, the fraction of the passive force-length relation that is due to titin. Prado et al.’s measurements relating to P are unique to our knowledge: these are the only measurements we have to estimate P in any muscle, cat soleus or otherwise. Here we use the average of the values for P across the 5 muscles measured by Prado et al. as a plausible default value for all of our simulations.
(18) Figure 4 seems unnecessary.
Figure 4 has been removed.
(19) Page 10, lines 17-18: provide the abbreviation (VAF) here with the definition (variance accounted for).
Thank you for your attention to detail. The abbreviation has been added.
Please see these parts of the manuscripts for details:
-
Revision: page 12, column 2, line 13
-
Difference: page 13, column 2, line 32
(20) Page 11, lines 2-3: Here and elsewhere, it is clear that some model parameters have been optimized to fit the model. The main paper should include a table that lists all model parameters and how they were chosen or optimized, including but not limited to the information in Table 1 of the supplemental information section.
See response to comment 3.
(20) Page 17, lines 45 -49: Again, a substantial number of ad hoc adjustments to the model appear to be required. These should be described in the Discussion under limitations, and accounted for in the parameters table. See also legends to Fig. 12 and 13, page 19, lines 23-26.
Please see the response to comment #3: a coded entry now appears to indicate the data source, the animal used in the experiment, and the method used to process the data. This includes entries for parameters which were estimated
‘E’ so that the model produced acceptable results in the simulations presented. In addition, the new discussion paragraph includes a number of sentences that use the adjustment to the active-titin-damping coefficient as an opening to discuss the limitations of the VEXAT’s titin-actin bond model and the circumstances under which the model’s parameters would need to be adjusted.
Please see responses to comments 3 and 23 for additional details. In addition, please see the specific discussion text mentioning the change to βoPEVK:
-
Revision: page 22, column 1, line 30 ”In Sec. 3.3 we had ...”
-
Difference: page 24, column 1, line 49
(22) Page 20, lines 50-11: It should be noted here that Tahir et al.’s (2018) model has both series and parallel elastic elements, provided by superposition of rotation (series) and translation (parallel) of a pulley.
While it is true that Tahir et al.’s (2018) model has series and parallel elements, as do the other models mentioned, these models do not have the correct structure to yield a gain and phase response that mimics biological muscle. The text that I originally wrote attempted to explain this without going into the details. As you note, this explanation leaves something to be desired. The original text commenting on the models of Forcinito et al, Tahir et al, Haeufle et al., and Gunther et al. has been updated to be more specific.¨ Please see the parts of the following manuscripts for details:
-
Revision: page 22, column 2, line 20, the paragraph beginning ”The models of Forcinito ...”
-
Difference: page 24, column 2, line 44
(23) Discussion: This section should include a description of model limitations, including the relatively large number of ad hoc modifications and how many parameters must be found by optimization in practice. The authors should discuss what types of data are most compatible for use with the model (ex vivo, in vivo, single fiber, whole muscle, MTU), requirements for applying the model to different types of data, and impediments to using the model on different types of data.
An additional limitations paragraph has been added to the discussion.
Please see the following text:
-
Revision: the paragraph beginning on page 22, column 1, line 11 ”Both the viscoelastic ...”
-
Difference: the paragraph beginning on page 24, column 1, line 27.
Reviewer #2 (Recommendations For The Authors):
(1) If it is possible to compare the output of this model to other more contemporary models which incorporate titin but are also simple enough to implement in whole-body simulation (such as the winding filament model), this would seem to greatly strengthen the paper.
That’s an excellent idea, though beyond the scope of this already lengthy paper. Even though the Hill model we evaluated is a bit old it is widely used, and so, many readers will be interested in seeing the benchmark results. As benchmarking work is both difficult to fund and undertake, we do hope that others will evaluate their own models using the code and data we have provided.
(2) I’m a little unclear on the basis for the transition between short- and midrange length changes, both in reality and in the model. And also about the range of strains that qualify as ”short”. It seems like there is potential for short range stiffness, although I would have thought more in the range of 1-2% strains than >3%, to be due to currently attached crossbridges. There is clear evidence that active titin is responsible for the low stiffness at very large strains that exceed actin-myosin overlap. But I am not clear on how a transitional stiffness on the descending limb of the force-length relationship is implemented in the model, and what aspect of physiology this is replicating. It may be helpful to clarify this further and indicate where in the model this stiffness arises.
This question has several parts to it which I will paraphrase here:
A Short-range stiffness acts over smaller strains than 3.8%. How is shortrange defined?
B Where is the transition made between short-range and mid-range force response, both in reality and in the model. Also how does this change on the descending limb?
C What components in the model contribute to the stiffness of the CE?
A. Short-range stiffness acts over smaller strains than 3.8%. How is shortrange defined?
The response to Reviewer 1’s comment # 5 directly addresses this question.
B. Where is the transition made between short-range and mid-range forceresponse, both in reality and in the model. Also how does this change on the descending limb? We are going to rephrase the question because of changes in terminology that we have made in response to Reviewer 1’s comment #5.
(i) What is the basis for the transition between the muscle behaving like an LTI system? Both in reality, and in the model. (ii) What happens outside the LTI range? (iii) Also how does this change on the descending limb?
We will address this question one part at a time:
(i) What is the basis for the transition between the muscle behaving like an LTI system? Both in reality, and in the model.
A system’s response can be approximated as a linear-time-invariant (LTI) system as long as it is time-invariant, and its output can be expressed as a linear function of its input. In the context of Kirsch et al.’s experiment, the ‘system’ is the muscle, the ‘input’ is the time series of length data, and the ‘output’ is the time series of force data. Due to the requirement for timeinvariance, two experimental conditions must be met to approximate muscle as an LTI system:
• the nominal length of the muscle stays constant over long periods of time,
• and the nominal activation of the muscle stays constant.
These conditions were met by default in Kirch et al.’s experiment, and also in our simulations of this experiment. The one remaining condition to assess is whether or not the muscle’s response is linear.
To evaluate whether the muscle’s force is a linear function of the length change, Kirch et al. evaluated (Cxy)2 the coherence squared between the length and force time-series data. Even though the mathematical underpinnings of (Cxy)2 are complicated, the interpretation of (Cxy)2 is simple: muscle can be accurately approximated as a linear system if (Cxy)2 is close to 1, but the accuracy of this approximation becomes poor as (Cxy)2 approaches 0. Kirsch et al. used (Cxy)2 to identify a bandwidth in which the response of the muscle to the 1−3.8%ℓoM length changes was sufficiently linear for analysis: a lower bound of 4 Hz was identified using (Cxy)2 and the bandwidth of the input signal (15 Hz, 35 Hz, or 90 Hz) set the upper bound. In Fig. 3 of Kirsch et al. the (Cxy)2 at 4 Hz has a value of at least 0.67 for the 15 Hz and 90 Hz signals. To minimize error in our analysis and yet be consistent with Kirsch et al., we analyze the bandwidth common to both (Cxy)2 ≥ 0.67 and Kirsch et al.’s defined range. Though the bandwidth defined by the criteria (Cxy)2 ≥ 0.67 is usually larger than the one defined by Kirsch et al., there are some exceptions where the lower frequency bound of the models is higher than 4 Hz (now reported in Tables 4D and 5D).
(ii) What happens outside the LTI range?
When a muscle’s output cannot be considered a LTI it means that either that its length or activation is time-varying, or the relationship between length and force is no longer linear. In short, that the muscle is behaving as one would normally expect: time-varying and non-linearly. The wonderful part of Kirsch et al.’s work is that they found a surprisingly large region in the frequency domain where muscle behaves linearly and can be analyzed using the powerful tools of linear systems and signals.
(iii) Also how does this change on the descending limb?
Since nominal length of Kirsch et al.’s experiments is ℓoM it is not clear how the results of the perturbation experiments will change if the nominal length is moved firmly to the descending limb. However, we can see how the stiffness and damping values will change by examining Figure 9C and 9D which shows the calculated stiffness and damping of the VEXAT and Hill models as ℓM is lengthened from ℓoM down the descending limb: the stiffness and damping of the VEXAT model does not change much, while the Hill model’s stiffness changes sign and the damping coefficient changes a lot. What cannot be seen from Figure 9C and 9D is how the bandwidth over which the models are considered linear changes.
We have made a number of updates to the text to more clearly communicate these details of our response to part (i):
• Text has been edited so that it is clear that the terms ’short-range stiffness’ and ’small’ from Rack and Westbury’s work is not confused with ’stiffness’ and ’small’ from the LTI system’s analysis. Please see our response to comment # 5 for details.
• We have added text to the main body of the paper to explain how the coherence squared metric was used to select a bandwidth in which the response of the system is approximately linear:
- Revision: the paragraph that starts on page 11, column 1, line 3 ”Kirsch et al. used system identification ...”
– Difference: page 13, column 2, line 1
– Coherence is defined in Appendix D
– Coherence is now also included in the example script ‘main SystemIdentificationExample.m’
• The bandwidth over which model output can be considered linear (coherence squared > 0.67) has been added to Tables 4 and 5
– Revision: see Table 4D, and Table 5D in Appendix E
– Difference: see Table 4D, and Table 5D in Appendix E
• Figures 6 and Figures 16 are annotated now if the plotted signal does not meet the linearity requirement of Cxy > 0.67.
C. What components in the model contribute to the stiffness of the CE?
There are three components that contribute to the stiffness of the CE which are pictured in Figure 1, appear in Eqn. 15, and are listed explicitly in Eqn. 76:
(a) The XE, as represented by the afL(ℓ˜S+L˜M)k˜oX term in Eqn. 15.
(b) The elasticity of the distal segment of titin, f2(ℓ˜2). Only f2(ℓ˜2) appears in Eqn. 15 because ℓ˜1 is a model state.
(c) The extracellular matrix, as represented by the fECM(ℓ˜ECM)
There is also a compressive element fKE, but it plays no role in the simulations presented in this work because it only begins to produce force at extremely short CE lengths (ℓ˜M < 0.1ℓoM).
We have made the following changes to make these components clearer
Figure 1A has been updated:
– The symbols for a spring and a damper are now defined in Figure 1A
– The ECM now has a spring symbol. Now all springs and dampers have the correct symbol in Figure 1A.
– The caption now explicitly lists the rigid, viscoelastic, and elastic elements in the model
The equations for the VEXAT’s CE stiffness and damping are now compared and contrasted to the the Hill model’s stiffness and damping in Sec. 3.1.
– Revision: starting at page 14, column 2, line 1: Eqn. 28 and Eqn. 29 and surrounding text
– Difference: page 17, column 1, line 22
(3) This model appears to be an amalgamation of a phenomenological (forcelength and force-velocity relationships) and a mechanistic (crossbridge and titin stiffness and damping) model. While this may improve predictions, and so potentially be useful, it also seems like it limits the interpretation of physiological underpinnings of any findings. It may be helpful to explore in greater detail the implications of this approach.
We have added a limitations paragraph to the discussion which addresses this comment and can be found in:
• Revision: the paragraph beginning on page 22, column 1, line 11 ”Both the viscoelastic ...”
• Difference: the paragraph beginning on page 24, column 1, line 27
(4)As a biologist, I found the interpretation of phase and gain a little difficult and it may help the reader to show in greater detail the time series data and model predictions to highlight conditions under which the models do not accurately capture the magnitude and timing of force production.
It is important that the ideas of phase and gain are understood, especially because little information can be gleaned from the time series data directly. There is some time series data in the paper already that compares each model’s response to its spring-damper of best fit: plots of the force response of each model and its spring damper of best fit can be found in Figures 6A, 6D, 6G, 6J, 16A, 16D, 16G, and 16J in the revised manuscript. While it is clear that models with a higher VAF more closely match the spring-damper of best fit, there is not much more that can be taken from time series data: the systematic differences, particularly in phase, are just not visually apparent in the time-domain but are clear in gain and phase plots in the frequency-domain.
To make the meaning of phase and gain plots clearer, Figure 4 (Figure 5 in the first submission) has been completely re-made and includes plots that illustrate the entire process of going from two length and force timedomain signals to gain and phase plots in the frequency-domain. Included in this figure is a visual representation of transforming a signal from the time to the frequency domain (Fig. 4B and 4C), and also an illustration of the terms gain and phase (Fig. 4D). In addition, a small example file ’main SystemIdentificationExample.m’ has been added to the matlab code repository in the elife2023 branch to accompany Appendix D, which goes through the mathematics used to transform input and output time domain signals into gain and phase plots of the input-output relation. Small updates have been made to Figure 6 and 16 in the revised paper (Figures 7 and 18 in the first submission) to make the time domain signals from the spring-damper of best fit and the model output clearer. Finally, I have re-calculated the gain and phase profiles using a more advanced numerical method that trades off some resolution in frequency for more accuracy in the magnitude. This has allowed me to make Figures 6 and 16 easier to follow because the gain and phase responses are now lines rather than a scattering of points. We hope that these additions make the interpretation of gain and phase clearer.
Please see
Revision:
– Figure 4 and caption on page 12
– The opening 2 paragraphs of Sec 3.1 starting on page 10, column 2, line 4 ”In Kirsch et al.’s ...”
– Figure 6 & 16: spring damper and model annotation added, plotted the gain and phase as lines
– Appendix D: Updated to include coherence and the more advanced method used to evaluate the system transfer function, gain, and phase.
Difference:
– Figure 4 and caption on page 12
– The opening 2 paragraphs of Sec 3.1 starting on page 12, column 1, line 34 and ending on page 13, column 2, line 29
– Figure 6 & 16: spring damper and model annotation added
– Appendix D
(5) The actin-myosin and actin-titin load pathways are depicted as distinct in the model. However, given titin’s position in the center of myosin and the crossbridge connections between actin and myosin, this would seem to be an oversimplification. It seems worth considering whether the separation of these pathways is justified if it has any effect on the conclusions or interpretation.
We have reworked one of the discussion paragraphs to focus on how our simulations would be affected by two mechanisms (Nishikawa et al.’s winding filament theory and DuVall et al.’s titin entanglement hypothesis) that make it possible for crossbridges to do mechanical work on titin.
• Revision: the paragraph beginning on page 21, column 2, line 42 “The active titin model ...”
• Difference: the paragraph beginning on page 23, column 2, line 48
References
Nishikawa KC, Monroy JA, Uyeno TE, Yeo SH, Pai DK, Lindstedt SL. Is titin a ‘winding filament’? A new twist on muscle contraction. Proceedings of the royal society B: Biological sciences. 2012 Mar 7;279(1730):981-90.
DuVall M, Jinha A, Schappacher-Tilp G, Leonard T, Herzog W. I-Band Titin Interaction with Myosin in the Muscle Sarcomere during Eccentric Contraction: The Titin Entanglement Hypothesis. Biophysical Journal. 2016 Feb 16;110(3):302a.
-
-
-
www.medrxiv.org www.medrxiv.org
-
Author response:
Reviewer #1 (Public Review):
In this manuscript, Naseri et al. present a new strategy for identifying human genetic variants with recessive effects on disease risk by the genome-wide association of phenotype with long runs-of-homozygosity (ROH). The key step of this approach is the identification of long ROH segments shared by many individuals (termed "shared ROH diplotype clusters" by the authors), which is computationally intensive for large-scale genomic data. The authors circumvented this challenge by converting the original diploid genotype data to (pseudo-)haplotype data and modifying the existing positional Burrow-Wheeler transformation (PBWT) algorithms to enable an efficient search for haplotype blocks shared by many individuals. With this method, the authors identified over 1.8 million ROH diplotype clusters (each shared by at least 100 individuals) and 61 significant associations with various non-cancer diseases in the UK Biobank dataset.
Overall, the study is well-motivated, highly innovative, and potentially impactful. Previous biobank-based studies of recessive genetic effects primarily focused on genome-wide aggregated
ROH content, but this metric is a poor proxy for homozygosity of the recessive alleles at causal loci. Therefore, searching for the association between phenotype and specific variants in the homozygous state is a key next step towards discovering and understanding disease genes/alleles with recessive effects. That said, I have some concerns regarding the power and error rate of the methods, for both identification of ROH diplotype clusters and subsequent association mapping. In addition, some of the newly identified associations need further validation and careful consideration of potential artifacts (such as cryptic relatedness and environment sharing).
1) Identification of ROH diplotype clusters.
The practice of randomly assigning heterozygous sites to a homozygous state is expected to introduce errors, leading to both false positives and false negatives. An advantage that the authors claim for this practice is to reduce false negatives due to occasional mismatch (possibly due to genotyping error, or mutation), but it's unclear how much the false positive rate is reduced compared to traditional ROH detection algorithm. The authors also justified the "random allele drawing" practice by arguing that "the rate of false positives should be low" for long ROH segments, which is likely true but is not backed up with quantitative analysis. As a result, it is unclear whether the trade-off between reducing FNs and introducing FPs makes the practice worthwhile (compared to calling ROHs in each individual with a standard approach first followed by scanning for shared diplotypes across individuals using BWT). I would like to see a combination of back-of-envelope calculation, simulation (with genotyping errors), and analysis of empirical data that characterize the performance of the proposed method.
In particular, I find the high number of ROH clusters in MHC alarming, and I am not convinced that this can be fully explained by a high density of SNPs and low recombination rate in this region. The authors may provide further support for their hypothesis by examining the genome-wide relationship between ROH cluster abundance and local recombination rate (or mutation rate).
Thanks for this insightful comment. Through additional experiments, we confirmed that the excessive number of ROH clusters in the MHC region is due to the higher density of markers per centimorgan. As discussed above at Essential Revision 2, we took this opportunity to modify our code to search for clusters with the minimum length in terms of cM instead of sites. We have also provided the genetic distance for reported clusters in the MHC region with significant association (genetic length (cM) column in Tables 1 and 2). We include the following in the main text:
“We searched for ROH clusters using a minimum target length of 0.1 cM (Figure 3–figure supplement 1). As shown in the figure, there is no excessive number of ROH clusters in chromosome 6 as was spotted using a minimum number of variant sites.”
Methods section, ROH algorithm subsection:
“We implemented ROH-DICE to allow direct use of genetic distances in addition to variant sites for L. The program can take minimum target length L directly in cM and detect all ROH clusters greater than or equal to the target length in cM. The program holds a genetic mapping table for all the available sites, and cPBWT was modified to work directly with the genetic length instead of the number of sites.”
2) Power of ROH association. Given that the authors focused on long segments only (which is a limitation of the current method), I am concerned about the power of the association mapping strategy, because only a small fraction of causal alleles are expected to be present in long, homozygous haplotypes shared by many individuals. It would be useful to perform a power analysis to estimate what fraction of true causal variants with a given effect size can be detected with the current method. To demonstrate the general utility of this method, the authors also need to characterize the condition(s) under which this method could pick up association signals missed by standard GWAS with recessive effects considered. I suspect some variants with truly additive effects can also be picked up by the ROH association, which should be discussed in the manuscript to guide the interpretation of results.
We added a new experiment in the Results section “Evaluation of ROH clusters in simulated data” under Power of ROH-DICE in association studies. We compared the power of the ROH cluster with additive, recessive, and dominant models. Our simulation shows that using ROH clusters outperforms standard GWAS when a phenotype is associated with a set of consecutive homozygous sites. We added the following text:
“...We calculated the p-values for both ROH clusters and all variant sites. We used a p-value cut-off of 0.05 divided by the number of tests for each phenotype to determine whether the calculated p-value was smaller than the threshold, indicating an association. For GWAS, only one variant site within the ROH cluster, contributing to the phenotype, was required. We tested for all additive, dominant, and recessive effects (Figure 1–figure supplement 3). The figure demonstrates that ROH-DICE outperforms GWAS when a phenotype is associated with a set of consecutive homozygous sites. The maximum effect size of 0.3 resulted in ROH clusters achieving a power of 100%, whereas the additive model only achieved 11%, and the dominant and recessive models achieved 52% and 70%, respectively. The GWAS with recessive effect yields the best results among other GWAS tests, however, its power is still lower than using ROH clusters.”
3) False positives of ROH association. GWAS is notoriously prone to confounding by population and environmental stratification. Including leading principal components in association testing alleviates this issue but is not sufficient to remove the effects of recent demographic structure and local environment (Zaidi and Mathieson 2020 eLife). Similar confounding likely applies to homozygosity mapping and should be carefully considered. For example, it is possible that individuals who share a lot of ROH diplotypes tend to be remotely related and live near each other, thus sharing similar environments. Such scenarios need to be excluded to further support the association signals.
We acknowledge that there could be confounding factors that may affect the association's results. To address this, we utilized principal component (PC) values and additional covariates while using PHESANT after our initial Chi-square tests. We also included your comments in our Discussion section:
"We used age, gender, and genetic principal components as confounding variables in the association analysis. Genetic principal components can reduce the confounding effect brought on by population structure but it may be insufficient to completely eliminate the effects of recent demographic structure and the local environment45. For example, individuals sharing excessive ROH diplotypes may share similar environments since they are closely related and reside close to one another. Since we did not rule out related individuals, some of the reported GWAS signals may not be attributable to ROH.”
4) Validation of significant associations. It is reassuring that some of the top associations are indirectly corroborated by significant GWAS associations between the same disease and individual SNPs present in the ROH region (Tables 1 and 2). However, more sanity checks should be done to confirm consistency in direction of effect size (e.g., risk alleles at individual SNPs should be commonly present in risk-increasing ROH segment, and vice versa) and the presence of dominance effect.
The beta values for effect size are now included in all reported tables. All beta values for ROH-DICE are positive indicating carriers of these ROH diplotypes may increase the risk of certain non-cancerous diseases. Moreover, we conducted the suggested sanity check to confirm the consistency of the direction of risk-inducing ROH diplotypes and risk alleles.
We also computed D’ as a measure of linkage between the reported GWAS results and ROH clusters. We found that most of the GWAS results and ROH clusters are strongly correlated. However, in a few cases, D' is small or close to zero. In such cases, the reported p-value from GWAS was also insignificant, while the ROH cluster indicated a significant association. We included these points in the Results section.
Reviewer #3 (Public Review):
A classic method to detect recessive disease variants is homozygosity mapping, where affected individuals in a pedigree are scanned for the presence of runs of homozygosity (ROH) intersecting in a given region. The method could in theory be extended to biobanks with large samples of unrelated individuals; however, no efficient method was available (to the best of my knowledge) for detecting overlapping clusters of ROH in such large samples. In this paper, the authors developed such a method based on the PBWT data structure. They applied the method to the UK biobank, finding a number of associations, some of them not discovered in single SNP associations.
Major strengths:
• The method is innovative and algorithmically elegant and interesting. It achieves its purpose of efficiently and accurately detecting ROH clusters overlapping in a given region. It is therefore a major methodological advance.
• The method could be very useful for many other researchers interested in detecting recessive variants associated with any phenotype.
• The statistical analysis of the UK biobank data is solid and the results that were highlighted are interesting and supported by the data.
Major weaknesses:
• The positions and IDs of the ROH clusters in the UK biobank are not available for other researchers. This means that other researchers will not be able to follow up on the results of the present paper.
We included the SNP IDs, positions, and consensus alleles for all reported loci in the main tables. Moreover, additional information including beta and D’ values were added. The current information should allow researchers to follow up on the results. Supplementary File 2 contains beta, D’ values for all reported clusters.
Supplementary File 3 contains the SNP IDs and consensus alleles for all reported clusters in Tables 1 and 2. The consensus allele denotes the allele with the highest occurrence in the reported clusters.
• The vast majority of the discoveries were in regions already known to be associated with their respective phenotypes based on standard GWAS.
We agree that a majority of the ROH regions are indeed consistent with GWAS. However, some regions were missed by standard GWAS (e.g. chr6:25969631-26108168, hemochromatosis). Our message is that our method is a complementary approach to standard GWAS and will not replace standard GWAS analysis. See our response to Reviewer #2 Point Six.
• The running time seems rather long (at least for the UK biobank), and therefore it will be difficult for other researchers to extensively experiment with the method in very large datasets. That being said, the method has a linear running time, so it is already faster than a naïve algorithm.
Thank you for your input. The algorithm used to locate matching blocks is efficient and the total CPU hours it consumed was the reported run time. Since it consumes very little memory and resources, it can be executed simultaneously for all chromosomes. We also noticed that a significant time was being spent parsing the input file and slightly modified our script to improve the parsing. We also re-ran it for all chromosomes in parallel and reported the elapsed time which was only 18 hours and 54 minutes.
“This was achieved by running the ROH-DICE program, with a wall clock time of 18 hours and 54 minutes where the program was executed for all chromosomes in parallel (total CPU hours of ~ 242.5 hours). The maximum residence size for each chromosome was approximately 180 MB.”
-
-
www.practicereproducibleresearch.org www.practicereproducibleresearch.org
-
when provided with identical source code, input data, software, and computing environment configurations, that an independent party can exactly reproduce the results of the original work -- especially published results. Thi
The reproduction of the original source giving as a result the same source code, input data, software and configurations in the system might be considered as Computational reproducibility
-
reproducibility, which emphasizes transparency of data analysis the logical path to scientific conclusio
According to Patil, P et al. (2016) state that "everyone agrees that scientific studies should be reproducible and replicable. The problem is almost no one agrees upon what those terms mean. A major initiative in psychology used the term
reproducibility'' to refer to completely redoing experiments including data collection (1). In cancer biologyreproducibility'' has been used to refer to the re calculation of results using a fixed set of data and code." (pag. 1)A possible approach to statistical reproducibility is to re-do experiments over and over again gathering all the data available to get the findings, but emphasising in the analysis with transparency in the information to have accurate conclusions.
References
Prasad Patil, Roger D. Peng, Jeffrey T. Leek. (2016). A statistical definition for reproducibility and replicability. see on https://www.biorxiv.org/content/10.1101/066803v1.full.pdf
-
-
Local file Local file
-
Relative gene abundance
Please add the legend of color code
-
-
-
Testrpc
TestRPC Related Pages
- Ganache CLI Install - <q>testRPC/ganache-cli testRPC/ganache-cli is a node.js Ethereum client for testing and development of the Smart… by technological.</q>
- Ethereum TestRPC and Tester Client - <q>This provider automatically spins up the eth-testrpc server for you so that you can test your web3.py code against an in memory EVM. This provides lightning …</q>
- Ethereum TestRPC vs. Geth - <q>Ethereum TestRPC vs. Geth explains that TestRPC is a client for testing and developing. While Geth is a full GO language client for connecting to the blockchain.</q>
- TestRPC & Ethereum Smart Contracts - <q>… testrpc. For truffle test, testrpc or geth is required to be run explicitly. Else, you get the following error: $ truffle test Could not connect to your …</q>
-
-
openclassrooms.com openclassrooms.com
-
Si besoin, voici la liste complète des codes de langue.
Comment configurer cela pour un site utilisé a l'international ? Par exemple sur Youtube, faut-il créer un code différent pour chaque langues utilisées ?
-
-
snarfed.org snarfed.org
-
Moderate people, not code by [[Ryan Barrett]]
-
Moderate people, not code.
-
-
-
Today, we explore whether memory still has a practical place in the world of big data and computing. As a science writer, Lynne has written 18 books including The Memory Code. Her research showed that without writing, people used the most extraordinary suite of memory techniques to memorise massive amounts of practical information. This explains the purpose of monuments like Stonehenge, the Nazca Lines and the statues of Easter Island. Her next book, Unlocking The Memory Code explains the most effective memory methods from around the world and throughout time. Lynne shows how these can be invaluable in modern world.
I need to read this book. And re-review this video with a notecard handy. (I wonder if there's a way to use hypothes.is for notes on video/audio?)
-
-
www.biorxiv.org www.biorxiv.org
-
Data availability
Will the code to run these analyses be available on Github? It would be helpful to follow along with the many steps used across these analyses.
-
-
www.biorxiv.org www.biorxiv.org
-
Importantly, it must be pointed out that gsea-3.0.jar, utilized in protocols published by Reimand et al [37], is affected by serious security vulnerabilities due to the use of the Java-based logging utility Apache Log4j in GSEA versions earlier than 4.2.3. Moreover, as reported by the GSEA Team, version 3.0 contained microarray-specific code (mostly related to Affymetrix) that may cause issues with RNA-seq data analysis, which was removed in later GSEA updates.
Did you do anything to account for these things in your analysis?
-
https://github.com/juliancandia/GSEARNASeq_Benchmarks
I get a "Page not found" error when i navigate to this URL. Is the repo still private or is there a typo in the URL? I would love to look at/give feedback on the code as well!
-
-
mirror2.openwrt.org mirror2.openwrt.org
-
Raven
An old code name for this product maybe?
-
-
-
Author response:
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public Review):
Summary:
In this manuscript, Ngo et al. report a peculiar effect where a single base mismatch (CC) can enhance the mechanical stability of a nucleosome. In previous studies, the same group used a similar state-of-the-art fluorescence-force assay to study the unwrapping dynamics of 601-DNA from the nucleosome and observed that force-induced unwrapping happens more slowly for DNA that is more bendable because of changes in sequence or chemical modification. This manuscript appears to be a sequel to this line of projects, where the effect of CC is tested. The authors confirmed that CC is the most flexible mismatch using the FRET-based cyclization assay and found that unwrapping becomes slower when CC is introduced at three different positions in the 601 sequence. The CC mismatch only affects the local unwrapping dynamics of the outer turn of nucleosomal DNA.
Strengths:
These results are in good agreement with the previously established correlation between DNA bendability and nucleosome mechanical stability by the same group. This well-executed, technically sound, and well-written experimental study contains novel nucleosome unwrapping data specific to the CC mismatch and 601 sequence, the cyclizability of DNA containing all base pair mismatches, and the unwrapping of 601-DNA from xenophus and yeast histones. Overall, this work will be received with great interest by the biophysics community and is definitely worth attention.
Weaknesses:
The scope and impact of this study are somewhat limited due to the lack of sequence variation. Whether the conclusion from this study can be generalized to other sequences and other bendability-enhancing mismatches needs further investigation.
Major questions:
(1) As pointed out by the authors, the FRET signal is not sensitive to nucleosome position; therefore, the increasing unwrapping force in the presence of CC can be interpreted as the repositioning of the nucleosome upon perturbation. It is then also possible that CC-containing DNA is not positioned exactly the same as normal DNA from the start upon nucleosome assembly, leading to different unwrapping trajectories. What is the experimental evidence that supports identical positioning of the nucleosomes before the first stretch?
We added the following and refer to our recent publication1 to address this question.
“This is consistent with a previous single nucleotide resolution mapping of dyad position from of a library of mismatches in all possible positions along the 601 sequence or a budding yeast native sequence which showed that a single mismatch (A-A or T-T) does not affect the nucleosome position27.”
(2) The authors chose a constant stretching rate in this study. Can the authors provide a more detailed explanation or rationale for why this rate was chosen? At this rate, the authors found hysteresis, which indicates that stretching is faster than quasi-static. But it must have been slow and weak enough to allow for reversible unwrapping and wrapping of a CC-containing DNA stretch longer than one helical turn. Otherwise, such a strong effect of CC at a single location would not be seen. I am also curious about the biological relevance of the magnitude of the force. Can such force arise during nucleosome assembly in vivo?
To address the comment about the magnitude of force, we added the following paragraph to Introduction. “RNA polymerase II can initiate transcription at 4 pN of hindering force2 and its elongation activity continues until it stalls at ~ 10 pN of hindering force3,4. Therefore, the transcription machinery can generate picoNewtons of force on chromatin as long as both the machinery and the chromatin segment in contact are tethered to stationary objects in the nucleus. Another class of motor protein, chromatin remodeling enzymes, was also shown to induce processive and directional sliding of single nucleosomes when the DNA is under similar amount of tension (~ 5 pN)5. Therefore, measurements of nucleosomes at a few pN of force will expand our knowledge of the physiology roles of nucleosome structure and dynamics.”
To address the comment about the stretching rate, we added the following to Results. We note that the physiological loading rate has been challenging to determine for any biomolecular interactions, and the only quantitative measurement we are aware of is that of an integrin that we are citing.
“The force increases nonlinearly and the loading rate, i.e. the rate at which the force increases, was approximately in the range of 0.2 pN/s to 6 pN/s, similar to the cellular loading rates for a mechanosensitive membrane receptor6.”
(3) In this study, the CC mismatch is the only change made to the 601 sequence. For readers to truly appreciate its unique effect on unwrapping dynamics as a base pair defect, it would be nice to include the baseline effects of other minor changes to the sequence. For example, how robust is the unwrapping force or dynamics against a single-bp change (e.g., AT to GC) at the three chosen positions?
Unfortunately, we are unable to perform the suggested unwrapping experiment in a timely manner because the instrument has been disassembled during our recent move. However, we previously performed unwrapping experiments not only as a function of sequence but also as a function of cytosine modification and showed that we can detect even more subtle effects7,8. In addition, please note that we are not claiming that simply changing basepair at the chosen sites changes the mechanical stability of a nucleosome so we do not believe the requested experiment is necessary.
(4) The last section introduces yeast histones. Based on the theme of the paper, I was expecting to see how the effect of CC is or is not preserved with a different histone source. Instead, the experiment only focuses on differences in the unwrapping dynamics. Although the data presented are important, it is not clear how they fit or support the narrative of the paper without the effect of CC.
We apologize for giving the reviewer a wrong impression. We included the data because we believe that information on how the histone core can determine the translation of DNA mechanics into nucleosome mechanical stability will be of interest to the readers of this manuscript. We now mention explicitly that the observation was made using intact DNA, i.e. no mismatch, in the abstract and elsewhere.
(5) It is stated that tRNA was excluded in experiments with yeast-expressed nucleosomes. What is the reason for excluding it for yeast nucleosomes? Did the authors rule out the possibility that tRNA causes the measured difference between the two nucleosome types?
We normally include tRNA because we found that it reduces sticking of beads to the surface over several hours of experiments. In yeast nucleosomes, we found that tRNA causes the nucleosome to disassemble. Therefore, we did not include tRNA in yeast nucleosome experiments. We now mention this in Methods as reproduced below.
“tRNA, which we normally include to reduce sticking of beads to the surface over the hours of single molecule experiments in a sealed chamber, was excluded in experiments with yeastexpressed nucleosomes because tRNA induced disassembly of nucleosomes assembled using yeast histones.”
We cannot not formally rule out the possibility that tRNA causes the measured difference between Xenopus - vs Yeast- nucleosomes. However, we have shown in our previous publication7 that the asymmetric unwrapping in Xenopus nucleosomes was modulated by the DNA sequence. When we swapped the sequence of the inner turn between the two sides, while tRNA was included in all experiments, we observed stochastic unwrapping instead. As part of our response to another reviewer’s comments, we also added the following on the relevant differences between the species in Discussion.
“The crystal structure of the yeast nucleosome suggests that yeast nucleosome architecture is subtly destabilized in comparison with nucleosomes from higher eukaryotes9. Yeast histone protein sequences are not well conserved relative to vertebrate histones (H2A, 77%; H2B, 73%; H3, 90%; H4, 92% identities), and this divergence likely contributes to differences in nucleosome stability. Substitution of three residues in yeast H3 a3-helix (Q120, K121, K125) very near the nucleosome dyad with corresponding human H3.1/H3.3 residues (QK…K replaced with MP…Q) caused severe growth defects, elevated nuclease sensitivity, reduced nucleosome positioning and nucleosome relocation to preferred locations predicted by DNA sequence alone 10. The yeast histone octamer harboring wild type H3 may be less capable of wrapping DNA over the histone core, leading to reduced resistance to the unwrapping force for the more flexible half of the 601positioning sequence.”
Reviewer #2 (Public Review):
Summary:
Mismatches occur as a result of DNA polymerase errors, chemical modification of nucleotides, during homologous recombination between near-identical partners, as well as during gene editing on chromosomal DNA. Under some circumstances, such mismatches may be incorporated into nucleosomes but their impact on nucleosome structure and stability is not known. The authors use the well-defined 601 nucleosome positioning sequence to assemble nucleosomes with histones on perfectly matched dsDNA as well as on ds DNA with defined mismatches at three nucleosomal positions. They use the R18, R39, and R56 positions situated in the middle of the outer turn, at the junction between the outer turn and inner turn, and in the middle of the inner turn, respectively. Most experiments are carried out with CC mismatches and Xenopus histones. Unwrapping of the outer DNA turn is monitored by singlemolecule FRET in which the Cy3 donor is incorporated on the 68th nucleotide from the 5'-end of the top strand and the Cy5 acceptor is attached to the 7th nucleotide from the 5' end of the bottom strand. Force is applied to the nucleosomal DNA as FRET is monitored to assess nucleosome unwrapping. The results show that a CC mismatch enhances nucleosome mechanical stability. Interestingly, yeast and Xenopus histones show different behaviors in this assay. The authors use FRET to measure the cyclization of the dsDNA substrates to test the hypothesis that mismatches enhance the flexibility of the 601 dsDNA fragment and find that CC, CA, CT, TT, and AA mismatches decrease looping time, whereas GA, GG, and GT mismatches had little to no effect. These effects correlate with the results from DNA buckling assays reported by Euler's group (NAR 41, 2013) using the same mismatches as an orthogonal way to measure DNA kinking. The authors discuss that substitution rates are higher towards the middle of the nucleosome, suggesting that mismatches/DNA damage at this position are less accessible for repair, consistent with the nucleosome stability results.
Strengths:
The single-molecule data show clear and consistent effects of mismatches on nucleosome stability and DNA persistence length.
Weaknesses:
It is unclear in the looping assay how the cyclization rate relates to the reporting looping time. The biological significance and implications such as the effect on mismatch repair or nucleosome remodelers remain untested. It is unclear whether the mutational pattern reflects the behavior of the different mismatches. Such a correlation could strengthen the argument that the observed effects are relevant for mutagenesis.
Reviewer #3 (Public Review):
Summary:
The mechanical properties of DNA wrapped in nucleosomes affect the stability of nucleosomes and may play a role in the regulation of DNA accessibility in eukaryotes. In this manuscript, Ngo and coworkers study how the stability of a nucleosome is affected by the introduction of a CC mismatched base pair, which has been reported to increase the flexibility of DNA. Previously, the group has used a sophisticated combination of single-molecule FRET and force spectroscopy with an optical trap to show that the more flexible half of a 601 DNA segment provides for more stable wrapping as compared to the other half. Here, it is confirmed with a single-molecule cyclization essay that the introduction of a CC mismatch increases the flexibility of a DNA fragment. Consistent with the previous interpretation, it also increased the unwrapping force for the half of the 601 segment in which the CC mismatch was introduced, as measured with single-molecule FRET and force spectroscopy. Enhanced stability was found up to 56 bp into the nucleosome. The intricate role of mechanical stability of nucleosomes was further investigated by comparing force-induced unwrapping profiles of yeast and Xenopus histones. Intriguingly, asymmetric unwrapping was more pronounced for yeast histones.
Strengths:
(1) High-quality single-molecule data.
(2) Novel mechanism, potentially explaining the increased prominence of mutations near the dyads of nucleosomes.
(3) A clear mechanistic explanation of how mismatches affect nucleosome stability.
Weaknesses:
(1) Disconnect between mismatches in nucleosomes and measurements comparing Xenopus and yeast nucleosome stability.
(2) Convoluted data in cyclization experiments concerning the phasing of mismatches and biotin site. ---
Recommendations for the authors:
Reviewer #1 (Recommendations For The Authors):
Specific comments:
In Figure 1 legend, "the black diamonds on the DNA bends represent the mismatch position with R18 and R39 on minor grooves and R56 on a major groove." Minor and major grooves should be phrased as histone-facing minor and major grooves.
We fixed the problem.
In Materials and Methods, the sentence that describes the stretching rate cites reference 1, which does not seem to be relevant.
We fixed the problem.
Reviewer #2 (Recommendations For The Authors):
(1) In the introduction, the authors should also discuss the context of mismatches occurring during homologous recombination in meiosis or somatic cells in non-allelic recombination between near identical repeats.
Introduction now has the following.
“DNA base-base mismatches are generated by nucleotide misincorporation during DNA synthesis, meiotic recombination, somatic recombination between nearly identical repeats, or chemical modification such as hydrolytic deamination of cytosine.”
(2) Generally, it seems counter-intuitive in terms of biology that mismatches containing nucleosomes are more stable, as mismatches require repair and/or detection for heteroduplex rejection during recombination. Some discussion of this apparent paradox should be added.
To address this comment, we added the following to Discussion.
“The higher frequency of substitutions in the nucleosomal DNA may be attributed to the difficulty of accessing the extra-stable nucleosomes. We also note that even without an enhanced stability, a mismatch within a nucleosome would be more difficult to detect for mismatch repair machineries compared to a mismatch in a non-nucleosomal DNA. Because mismatch repair machineries accompany the replisome, most of nascent mismatches may be detected for repair before nucleosome deposition. Therefore, the decrease in accessibility predicted based on our data here may be important only in rare cases a mismatch is not detected prior to the deposition of a nucleosome on the nascent DNA or in cases where a mismatch is generated via a non-replicative mechanism.”
(3) The authors discuss that the substitution rate is higher while the indel (insertion and deletion) rate is lower nearer the center of a positioned nucleosome. Are the differences between individual mismatches reported in Figure 6 reflected in the mutagenic profile?
We cannot currently compare them because the mutagenic profile even when it is available is a complex convolution of mismatch generation, mismatch repair and selection. Mismatch generation occurs through several different processes and how they are affected by nucleosomes and their mismatch type and sequence context is unknown. Mismatch repair process itself depends on mismatch type and sequence context as recently shown by a high throughput in vivo study11. And because the population genetics does not simply reflect de novo mutation profiles due to selection, comparison between mismatch-induced DNA mechanical changes and mutagenic profiles is further complicated. We added the following to the revision.
“If and how the mismatch type-dependent DNA mechanics affects the sequence-dependent mismatch repair efficiency in vivo, as recently determined in a high through study in E. coli11, remains to be investigated. Comparison of mismatch-type dependent DNA mechanics to population genetics data is challenging because mutation profiles reflect a combined outcome of mismatch-generation, mismatch repair and selection in addition to other mutational processes.”
(4) The looping assay should be explained better, especially how the cyclization rate is related to the reported looping time.
We modified Figure 5 to include examples of looping time determination through fitting of the looped fraction vs time, and added the following to the figure caption.
“To calculate the looping time, the fraction of looped molecules (high FRET) as a function of time is fitted to an exponential function, 𝑒−𝑡⁄(𝑙𝑜𝑜𝑝𝑖𝑛𝑔 𝑡𝑖𝑚𝑒) (right panel for one run of experiments).
Furthermore, we added the following sentence to Results.
“The rate of loop formation, which is the inverse of looping time determined from an exponential fitting of loop fraction vs time, was used as a measure of apparent DNA flexibility influenced by a mismatch 12,13.”
*Reviewer #3 (Recommendations For The Authors):
I have some concerns that, when addressed upon revision, would improve the manuscript:
(1) Page 6 and Supplementary Figure S1C: Though the FRET levels are the same for all nucleosomes, the distribution between the two levels is not. The nucleosomes with CC mismatches appear to have a larger fraction in the low-FRET population. This seems to contradict the higher mechanical stability. A comment on this should clarify it, or make this conundrum explicit.
Thank you for the comment. The low FRET population also includes the nucleosomes that do not have an active acceptor the fraction of which varies between preparations. We now note this in the supplementary figure caption.
(2) It is intriguing that a more stable nucleosome forms after several pulling cycles and it is argued that this might be due to shifting of the nucleosome. This seems reasonable and has important consequences both for the interpretation of the current experimental data and for the general mechanisms involved in nucleosome maintenance and remodeling. It is puzzling though how this would work mechanistically since it only seems to happen when nucleosomes are half-wrapped and when the unwrapped half contains the mismatch. From the previous work of the group and the current manuscript, it seems that shift does not occur in DNA without mismatches (Correct?). Does shifting happen for the 601-R18 and 601-R56 nucleosomes as well?
The mismatch-containing half is the half that is mechanically less stable in an intact, mismatch-free 601 nucleosome. So indeed, that is the half that is unwrapped in an intact nucleosome. But because the introduction of mismatch makes that half more mechanically stable, it can stay wrapped until higher forces, and the resulting structural distortion may cause the shift although we acknowledge that this interpretation remains speculative. Shifting occurs for all three constructs with a mismatch but not for the intact nucleosome without a mismatch.
(3) Could the shifting be related to the differences in sub-population distribution observed in Supplementary Figure S1C?
/See our response to comment (1) above.
(4) The paper would have more impact if the mechanism of possible shifting could be clarified. This can be done experimentally with a fluorescent histone, as suggested in the manuscript. But having a FRET pair on positions in the DNA that would shift to closer proximity upon shifting, either at the ED2 or at the ED1 site will also work, is in line with the current experiments and seems feasible.
We revised the text as follows in order not to exclude labeling configurations with both fluorophores on the DNA while reporting on the shift. We are also happy to add an appropriate reference if the reviewer can help us identify an existing study that measured dyad position shifts through such a labeling configuration.
“However, since the FRET values in our DNA construct are not sensitive to the nucleosome position, further experiments with fluorophores conjugated to strategic positions that allow discrimination between different dyad positions14 will be required to test this hypothesis.”
(5) Figures 5 and 6: To appreciate the quality of the data, state the number of molecules that contributed to the cyclization essay, or better, share a figure of the number of looped molecules as a function of time as supplementary data.
We added the requested figures to Figure 5 and a new supplementary Figure 2, and added the following to Methods.
“Approximately 2500 – 3500 molecules were quantified at each timestamp during the experiment, and three independent experiments were performed for each sequence (Supplemental Figure S2).”
(6) Page 8/9: A control is added to confirm that the phasing of the biotin relative to the end affects the observed cyclization rate. However, the mismatch sites were chosen such that they included 5 bp phase shifts. This convolutes the outcomes, as the direction of flexibility due to the phasing of the mismatch relative to the biotin may also influence the rate. Was this checked?
We would like to clarify that the phasing of the biotin is not so much as with respect to the end, as it is with respect to the full molecule. Static curvature and poloidal angle associated with the DNA molecule (which is something that is ultimately determined by the full chemical composition of the molecule, including its sequence and the mismatch) could make the molecule prefer a looped configuration where the biotin points towards the “inside” of the molecule. Such a configuration would be sterically unfavoured during the single molecule looping reaction where the biotin is attached to a surface via avidin. However, if the biotin is moved by half the helical repeat (or an off multiple of half the helical repeat, essentially 16 nt as done in the manuscript), it would now point to the “outside” of the molecule. Therefore, to make sure that the difference between the looping rates of any two DNA constructs (say the 601-RH and 601-R18-RH) is a better reflection of differences in dynamic flexibility, we ensure that the difference persists even when the biotin is moved by an odd multiple of half the helical repeat. We revised the section as follows.
“For example, moving the location of the biotin tether by half the helical repeat (~ 5 bp) can lead to a large change in cyclization rate15, likely due to the preferred poloidal angle of a given DNA16 that determines whether the biotin is facing towards the inside of the circularized DNA, thereby hindering cyclization due to steric hindrance caused by surface tethering.”
(7) Page 9/10: The comparison of yeast vs Xenopus is interesting, albeit a bit disconnected. Since the single-molecule statistics are relatively small, did the nucleosomes show similar bulk FRET distributions, or did they also show a shift in FRET levels?
We included the data because we believe that information on how the histone core can determine the translation of DNA mechanics into nucleosome mechanical stability will be of interest to the readers of this manuscript. The FRET values were similarly distributed.
(8) The discussion calls for a more detailed analysis of the structural differences of the histones of the two species to rationalize the observed asymmetry in flexibility dependence: why would yeast nucleosomes be less sensitive to sequence asymmetries?
We added the following to Discussion to address this comment.
“The crystal structure of the yeast nucleosome suggests that yeast nucleosome architecture is subtly destabilized in comparison with nucleosomes from higher eukaryotes9. Yeast histone protein sequences are not well conserved relative to vertebrate histones (H2A, 77%; H2B, 73%; H3, 90%; H4, 92% identities), and this divergence likely contributes to differences in nucleosome stability. Substitution of three residues in yeast H3 3-helix (Q120, K121, K125) very near the nucleosome dyad with corresponding human H3.1/H3.3 residues (QK…K replaced with MP…Q) caused severe growth defects, elevated nuclease sensitivity, reduced nucleosome positioning and nucleosome relocation to preferred locations predicted by DNA sequence alone 10. The yeast histone octamer harboring wild type H3 may be less capable of wrapping DNA over the histone core, leading to reduced resistance to the unwrapping force for the more flexible half of the 601positioning sequence.”
(9) It would also be interesting if the increased stability due to the introduction of mismatches observed on Xenopus nucleosomes holds in yeast. Or does the reduced stability remove this effect? This is relevant to substantiate the broad claims in the context of evolution and cancer that are discussed in the manuscript.
Unfortunately, we are unable to perform the suggested unwrapping experiment in a timely manner because the instrument has been disassembled during our recent move. However, in terms of cancer relevance, our mismatch dependence experiments were performed using vertebrate nucleosomes (Xenopus) so repeating this for yeast nucleosomes would not provide relevant information.
Minor comments:
(1) Supplementary Figure S1 misses the label '(C)' in its caption.
We fixed it.
(2) The supplementary data sequences for the fleezer measurements contain entrees 'R39 construct' and miss the positions of the Cy3 and Cy labels; the color code (levels of grey) is not explained.
We fixed the labeling mistake and added detailed annotations of the highlighted features.
References
(1) Park, S., Brandani, G.B., Ha, T. & Bowman, G.D. Bi-directional nucleosome sliding by the Chd1 chromatin remodeler integrates intrinsic sequence-dependent and ATP-dependent nucleosome positioning. Nucleic Acids Res 51, 10326-10343 (2023).
(2) Fazal, F.M., Meng, C.A., Murakami, K., Kornberg, R.D. & Block, S.M. Real-time observation of the initiation of RNA polymerase II transcription. Nature 525, 274-7 (2015).
(3) Galburt, E.A., Grill, S.W., Wiedmann, A., Lubkowska, L., Choy, J., Nogales, E., Kashlev, M. & Bustamante, C. Backtracking determines the force sensitivity of RNAP II in a factor-dependent manner. Nature 446, 820-3 (2007).
(4) Schweikhard, V., Meng, C., Murakami, K., Kaplan, C.D., Kornberg, R.D. & Block, S.M. Transcription factors TFIIF and TFIIS promote transcript elongation by RNA polymerase II by synergistic and independent mechanisms. Proc Natl Acad Sci U S A 111, 6642-7 (2014).
(5) Kim, J.M., Carcamo, C.C., Jazani, S., Xie, Z., Feng, X.A., Yamadi, M., Poyton, M., Holland, K.L., Grimm, J.B., Lavis, L.D., Ha, T. & Wu, C. Dynamic 1D Search and Processive Nucleosome Translocations by RSC and ISW2 Chromatin Remodelers. bioRxiv (2024). (6) Jo, M.H., Meneses, P., Yang, O., Carcamo, C.C., Pangeni, S. & Ha, T. Determination of singlemolecule loading rate during mechanotransduction in cell adhesion. Science (in press).
(7) Ngo, T.T., Zhang, Q., Zhou, R., Yodh, J.G. & Ha, T. Asymmetric unwrapping of nucleosomes under tension directed by DNA local flexibility. Cell 160, 1135-44 (2015).
(8) Ngo, T.T., Yoo, J., Dai, Q., Zhang, Q., He, C., Aksimentiev, A. & Ha, T. Effects of cytosine modifications on DNA flexibility and nucleosome mechanical stability. Nat Commun 7, 10813 (2016).
(9) White, C.L., Suto, R.K. & Luger, K. Structure of the yeast nucleosome core particle reveals fundamental changes in internucleosome interactions. EMBO J 20, 5207-18 (2001).
(10) McBurney, K.L., Leung, A., Choi, J.K., Martin, B.J., Irwin, N.A., Bartke, T., Nelson, C.J. & Howe, L.J. Divergent Residues Within Histone H3 Dictate a Unique Chromatin Structure in Saccharomyces cerevisiae. Genetics 202, 341-9 (2016).
(11) Kayikcioglu, T., Zarb, J.S., Lin, C.-T., Mohapatra, S., London, J.A., Hansen, K.D., Rishel, R. & Ha, T. Massively parallel single molecule tracking of sequence-dependent DNA mismatch repair in vivo. bioRxiv, 2023.01.08.523062 (2023).
(12) Jeong, J., Le, T.T. & Kim, H.D. Single-molecule fluorescence studies on DNA looping. Methods 105, 34-43 (2016).
(13) Jeong, J. & Kim, H.D. Base-Pair Mismatch Can Destabilize Small DNA Loops through Cooperative Kinking. Phys Rev Lett 122, 218101 (2019).
(14) Blosser, T.R., Yang, J.G., Stone, M.D., Narlikar, G.J. & Zhuang, X. Dynamics of nucleosome remodelling by individual ACF complexes. Nature 462, 1022-7 (2009).
(15) Basu, A., Bobrovnikov, D.G., Qureshi, Z., Kayikcioglu, T., Ngo, T.T.M., Ranjan, A., Eustermann, S., Cieza, B., Morgan, M.T., Hejna, M., Rube, H.T., Hopfner, K.P., Wolberger, C., Song, J.S. & Ha, T. Measuring DNA mechanics on the genome scale. Nature 589, 462-467 (2021).
(16) Yoo, J., Park, S., Maffeo, C., Ha, T. & Aksimentiev, A. DNA sequence and methylation prescribe the inside-out conformational dynamics and bending energetics of DNA minicircles. Nucleic Acids Res 49, 11459-11475 (2021).
-
-
-
fears of thine own making
Imagined -> religion is about consequences and punishment
Religion to Bianca is a moral code and to the duke it is about human perceptions
-
-
social-media-ethics-automation.github.io social-media-ethics-automation.github.io
-
In order to loop a set number of times, we can use the range function to effectively make a list of numbers to go over, so we can loop that many times. For example, if we wanted to ask “Are we there yet?” repeatedly, 10 times, we can do this:
Where should I put sleep in this code? Just after the print?
-
-
www.biorxiv.org www.biorxiv.org
-
Author response:
The following is the authors’ response to the previous reviews.
eLife assessment
This study presents valuable data on the antigenic properties of neuraminidase proteins of human A/H3N2 influenza viruses sampled between 2009 and 2017. The antigenic properties are found to be generally concordant with genetic groups. Additional analysis have strengthened the revised manuscript, and the evidence supporting the claims is solid.
Public Reviews:
Reviewer #1 (Public Review):
Summary
The authors investigated the antigenic diversity of recent (2009-2017) A/H3N2 influenza neuraminidases (NAs), the second major antigenic protein after haemagglutinin. They used 27 viruses and 43 ferret sera and performed NA inhibition. This work was supported by a subset of mouse sera. Clustering analysis determined 4 antigenic clusters, mostly in concordance with the genetic groupings. Association analysis was used to estimate important amino acid positions, which were shown to be more likely close to the catalytic site. Antigenic distances were calculated and a random forest model used to determine potential important sites.
This revision has addressed many of my concerns of inconsistencies in the methods, results and presentation. There are still some remaining weaknesses in the computational work.
Strengths
(1) The data cover recent NA evolution and a substantial number (43) of ferret (and mouse) sera were generated and titrated against 27 viruses. This is laborious experimental work and is the largest publicly available neuraminidase inhibition dataset that I am aware of. As such, it will prove a useful resource for the influenza community.
(2) A variety of computational methods were used to analyse the data, which give a rounded picture of the antigenic and genetic relationships and link between sequence, structure and phenotype.
(3) Issues raised in the previous review have been thoroughly addressed.
Weaknesses
(1). Some inconsistencies and missing data in experimental methods Two ferret sera were boosted with H1N2, while recombinant NA protein for the others. This, and the underlying reason, are clearly explained in the manuscript. The authors note that boosting with live virus did not increase titres. Additionally, one homologous serum (A/Kansas/14/2017) was not generated, although this would not necessarily have impacted the results.
We agree with the reviewer and this point was addressed in the previous rebuttal.
(2) Inconsistency in experimental results
Clustering of the NA inhibition results identifies three viruses which do not cluster with their phylogenetic group. Again this is clearly pointed out in the paper and is consistent with the two replicate ferret sera. Additionally, A/Kansas/14/2017 is in a different cluster based on the antigenic cartography vs the clustering of the titres
We agree with the reviewer and this point was addressed in the previous rebuttal.
(3) Antigenic cartography plot would benefit from documentation of the parameters and supporting analyses
a. The number of optimisations used
We used 500 optimizations. This information is now included in the Methods section.
b. The final stress and the difference between the stress of the lowest few (e.g. 5) optimisations, or alternatively a graph of the stress of all the optimisations. Information on the stress per titre and per point, and whether any of these were outliers
The stress was obtained from 1, 5, 500, or even 5000 optimizations (resulting in stress values of respectively, 1366.47, 1366.47, 2908.60, and 3031.41). Besides limited variation or non-conversion of the stress values after optimization, the obtained maps were consistent in multiple runs. The map was obtained keeping the best optimization (stress value 1366.47, selected using the keepBestOptimization() function).
Author response image 1.
The stress per point is presented in the heat map below.

The heat map indicates stress per serum (x-axis) and strain (y-axis) in blue to red scale.
c. A measure of uncertainty in position (e.g. from bootstrapping)
Bootstrap was performed using 1000 repeats and 100 optimizations per repeat. The uncertainty is represented in the blob plot below.
Author response image 2.

(4) Random forest
The full dataset was used for the random forest model, including tuning the hyperparameters. It is more robust to have a training and test set to be able to evaluate overfitting (there are 25 features to classify 43 sera).
Explicit cross validation is not necessary for random forests as the out of bag process with multiple trees implicitly covers cross validation. In the random forest function in R this is done by setting the mtry argument (number of variables randomly sampled as candidates at each split). R samples variables with replacement (the same variable can be sampled multiple times) of the candidates from the training set. RF will then automatically take the data that is not selected as candidates as test set. Overfit may happen when all data is used for training but the RF method implicitly does use a test set and does not use all data for training.
Code:
rf <- randomForest(X,y=Y,ntree=1500,mtry=25,keep.forest=TRUE,importance=TRUE)
Reviewer #2 (Public Review):
Summary:
The authors characterized the antigenicity of N2 protein of 43 selected A(H3N2) influenza A viruses isolated from 2009-2017 using ferret and mice immune sera. Four antigenic groups were identified, which the authors claimed to be correlated with their respective phylogenic/ genetic groups. Among 102 amino acids differed by the 44 selected N2 proteins, the authors identified residues that differentiate the antigenicity of the four groups and constructed a machine-learning model that provides antigenic distance estimation. Three recent A(H3N2) vaccine strains were tested in the model but there was no experimental data to confirm the model prediction results.
Strengths:
This study used N2 protein of 44 selected A(H3N2) influenza A viruses isolated from 2009-2017 and generated corresponding panels of ferret and mouse sera to react with the selected strains. The amount of experimental data for N2 antigenicity characterization is large enough for model building.
Weaknesses:
The main weakness is that the strategy of selecting 43 A(H3N2) viruses from 2009-2017 was not explained. It is not clear if they represent the overall genetic diversity of human A(H3N2) viruses circulating during this time. In response to the reviewer's comment, the authors have provided a N2 phylogenetic tree using180 randomly selected N2 sequences from human A(H3N2) viruses from 2009-2017. While the 43 strains seems to scatter across the N2 tree, the four antigenic groups described by the author did not correlated with their respective phylogenic/ genetic groups as shown in Fig. 2. The authors should show the N2 phylogenic tree together with Fig. 2 and discuss the discrepancy observed.
The discrepancies between the provided N2 phylogenetic tree using 180 selected N2 sequences was primarily due to visualization. In the tree presented in Figure 2 the phylogeny was ordered according to branch length in a decreasing way. Further, the tree represented in the rebuttal was built with PhyML 3.0 using JTT substitution model, while the tree in figure 2 was build in CLC Workbench 21.0.5 using Bishop-Friday substitution model. The tree below was built using the same methodology as Figure 2, including branch size ordering. No discrepancies are observed.
Phylogenetic tree representing relatedness of N2 head domain. N2 NA sequences were ordered according to the branch length and phylogenetic clusters are colored as follows: G1: orange, G2: green, G3: blue, and G4: purple. NA sequences that were retained in the breadth panel are named according to the corresponding H3N2 influenza viruses. The other NA sequences are coded.
Author response image 3.

The second weakness is the use of double-immune ferret sera (post-infection plus immunization with recombinant NA protein) or mouse sera (immunized twice with recombinant NA protein) to characterize the antigenicity of the selected A(H3N2) viruses. Conventionally, NA antigenicity is characterized using ferret sera after a single infection. Repeated influenza exposure in ferrets has been shown to enhance antibody binding affinity and may affect the cross-reactivity to heterologous strains (PMID: 29672713). The increased cross-reactivity is supported by the NAI titers shown in Table S3, as many of the double immune ferret sera showed the highest reactivity not against its own homologous virus but to heterologous strains. In response to the reviewer's comment, the authors agreed the use of double-immune ferret sera may be a limitation of the study. It would be helpful if the authors can discuss the potential effect on the use of double-immune ferret sera in antigenicity characterization in the manuscript.
Our study was designed to understand the breadth of the anti-NA response after the incorporation of NA as a vaccine antigens. Our data does not allow to conclude whether increased breadth of protection is merely due to increased antibody titers or whether an NA boost immunization was able to induce antibody responses against epitopes that were not previously recognized by primary response to infection. However, we now mention this possibility in the discussion and cite Kosikova et al. CID 2018, in this context.
Another weakness is that the authors used the newly constructed a model to predict antigenic distance of three recent A(H3N2) viruses but there is no experimental data to validate their prediction (eg. if these viruses are indeed antigenically deviating from group 2 strains as concluded by the authors). In response to the comment, the authors have taken two strains out of the dataset and use them for validation. The results is shown as Fig. R7. However, it may be useful to include this in the main manuscript to support the validity of the model.
The removal of 2 strains was performed to illustrate the predictive performance of the RF modeling. However, Random Forest does not require cross-validation. The reason is that RF modeling already uses an out-of-bag evaluation which, in short, consists of using only a fraction of the data for the creation of the decision trees (2/3 of the data), obviating the need for a set aside the test set:
“…In each bootstrap training set, about one-third of the instances are left out. Therefore, the out-of-bag estimates are based on combining only about one- third as many classifiers as in the ongoing main combination. Since the error rate decreases as the number of combinations increases, the out-of-bag estimates will tend to overestimate the current error rate. To get unbiased out-of-bag estimates, it is necessary to run past the point where the test set error converges. But unlike cross-validation, where bias is present but its extent unknown, the out-of-bag estimates are unbiased…” from https://www.stat.berkeley.edu/%7Ebreiman/randomforest2001.pdf
Reviewer #3 (Public Review):
Summary:
This paper by Portela Catani et al examines the antigenic relationships (measured using monotypic ferret and mouse sera) across a panel of N2 genes from the past 14 years, along with the underlying sequence differences and phylogenetic relationships. This is a highly significant topic given the recent increased appreciation of the importance of NA as a vaccine target, and the relative lack of information about NA antigenic evolution compared with what is known about HA. Thus, these data will be of interest to those studying the antigenic evolution of influenza viruses. The methods used are generally quite sound, though there are a few addressable concerns that limit the confidence with which conclusions can be drawn from the data/analyses.
Strengths:
- The significance of the work, and the (general) soundness of the methods. -Explicit comparison of results obtained with mouse and ferret sera
Weaknesses:
- Approach for assessing influence of individual polymorphisms on antigenicity does not account for potential effects of epistasis (this point is acknowledged by the authors).
We agree with the reviewer and this point was addressed in the previous rebuttal.
- Machine learning analyses neither experimentally validated nor shown to be better than simple, phylogenetic-based inference.
We respectfully disagree with the reviewer. This point was addressed in the previous rebuttal as follows.
This is a valid remark and indeed we have found a clear correlation between NAI cross reactivity and phylogenetic relatedness. However, besides achieving good prediction of the experimental data (as shown in Figure 5 and in FigureR7), machine Learning analysis has the potential to rank or indicate major antigenic divergences based on available sequences before it has consolidated as new clade. ML can also support the selection and design of broader reactive antigens. “
Recommendations for the authors:
Reviewer #2 (Recommendations For The Authors):
(1) Discuss the discrepancy between Fig. 2 and the newly constructed N2 phylogenetic tree with 180 randomly selected N2 sequences of A(H3N2) viruses from 2009-2017. Specifically please explain the antigenic vs. phylogenetic relationship observed in Fig. 2 was not observed in the large N2 phylogenetic tree.
Discrepancies were due to different method and visualization. A new tree was provided.
(2) Include a sentence to discuss the potential effect on the use of double-immune ferret sera in antigenic characterization.
We prefer not to speculate on this.
(3) Include the results of the exercise run (with the use of Swe17 and HK17) in the manuscript as a way to validate the model.
The exercise was performed to illustrate predictive potential of the RF modeling to the reviewer. However, cross-validation is not a usual requirement for random forest, since it uses out-of-bag calculations. We prefer to not include the exercise runs within the main manuscript.
-
-
ipese-web.epfl.ch ipese-web.epfl.ch
-
linear_fit = lambda x: slope * x + intercept
I added this because linewar_fit was not declared causing an error in the code further down
-
-
www.biorxiv.org www.biorxiv.org
-
Author response:
The following is the authors’ response to the original reviews.
eLife assessment
This study presents a new and valuable theoretical account of spatial representational drift in the hippocampus. The evidence supporting the claims is convincing, with a clear and accessible explanation of the phenomenon. Overall, this study will likely attract researchers exploring learning and representation in both biological and artificial neural networks.
We would like to ask the reviewers to consider elevating the assessment due to the following arguments. As noted in the original review, the study bridges two different fields (machine learning and neuroscience), and does not only touch a single subfield (representational drift in neuroscience). In the revision, we also analysed data from four different labs, strengthening the evidence and the generality of the conclusions.
Public Reviews:
Reviewer #1 (Public Review):
The authors start from the premise that neural circuits exhibit "representational drift" -- i.e., slow and spontaneous changes in neural tuning despite constant network performance. While the extent to which biological systems exhibit drift is an active area of study and debate (as the authors acknowledge), there is enough interest in this topic to justify the development of theoretical models of drift.
The contribution of this paper is to claim that drift can reflect a mixture of "directed random motion" as well as "steady state null drift." Thus far, most work within the computational neuroscience literature has focused on the latter. That is, drift is often viewed to be a harmless byproduct of continual learning under noise. In this view, drift does not affect the performance of the circuit nor does it change the nature of the network's solution or representation of the environment. The authors aim to challenge the latter viewpoint by showing that the statistics of neural representations can change (e.g. increase in sparsity) during early stages of drift. Further, they interpret this directed form of drift as "implicit regularization" on the network.
The evidence presented in favor of these claims is concise. Nevertheless, on balance, I find their evidence persuasive on a theoretical level -- i.e., I am convinced that implicit regularization of noisy learning rules is a feature of most artificial network models. This paper does not seem to make strong claims about real biological systems. The authors do cite circumstantial experimental evidence in line with the expectations of their model (Khatib et al. 2022), but those experimental data are not carefully and quantitatively related to the authors' model.
We thank the reviewer for pushing us to present stronger experimental evidence. We now analysed data from four different labs. Two of those are novel analyses of existing data (Karlsson et al, Jercog et al). All datasets show the same trend - increasing sparsity and increasing information per cell. We think that the results, presented in the new figure 3, allow us to make a stronger claim on real biological systems.
To establish the possibility of implicit regularization in artificial networks, the authors cite convincing work from the machine-learning community (Blanc et al. 2020, Li et al., 2021). Here the authors make an important contribution by translating these findings into more biologically plausible models and showing that their core assumptions remain plausible. The authors also develop helpful intuition in Figure 4 by showing a minimal model that captures the essence of their result.
We are glad that these translation efforts are appreciated.
In Figure 2, the authors show a convincing example of the gradual sparsification of tuning curves during the early stages of drift in a model of 1D navigation. However, the evidence presented in Figure 3 could be improved. In particular, 3A shows a histogram displaying the fraction of active units over 1117 simulations. Although there is a spike near zero, a sizeable portion of simulations have greater than 60% active units at the end of the training, and critically the authors do not characterize the time course of the active fraction for every network, so it is difficult to evaluate their claim that "all [networks] demonstrated... [a] phase of directed random motion with the low-loss space." It would be useful to revise the manuscript to unpack these results more carefully. For example, a histogram of log(tau) computed in panel B on a subset of simulations may be more informative than the current histogram in panel A.
The previous figure 3A was indeed confusing. In particular, it lumped together many simulations without proper curation. We redid this figure (now Figure 4), and added supplementary figures (Figures S1, S2) to better explain our results. It is now clear that the simulations with a large number of active units were either due to non-convergence, slow timescale of sparsification or simulations featuring label noise in which the fraction of active units is less affected. Regarding the log(tau) calculation, while it could indeed be an informative plot, it could not be calculated in a simple manner for all simulations. This is because learning curves are not always exponential, but sometimes feature initial plateaus (see also Saxe et al 2013, Schuessler et al 2020). We added a more detailed explanation of this limitation in the methods section, and we believe the current figure exemplifies the effect in a satisfactory manner.
Reviewer #2 (Public Review):
Summary:
In the manuscript "Representational drift as a result of implicit regularization" the authors study the phenomenon of representational drift (RD) in the context of an artificial network that is trained in a predictive coding framework. When trained on a task for spatial navigation on a linear track, they found that a stochastic gradient descent algorithm led to a fast initial convergence to spatially tuned units, but then to a second very slow, yet directed drift which sparsified the representation while increasing the spatial information. They finally show that this separation of timescales is a robust phenomenon and occurs for a number of distinct learning rules.
Strengths:
This is a very clearly written and insightful paper, and I think people in the community will benefit from understanding how RD can emerge in such artificial networks. The mechanism underlying RD in these models is clearly laid out and the explanation given is convincing.
We thank the reviewer for the support.
Weaknesses:
It is unclear how this mechanism may account for the learning of multiple environments.
There are two facets to the topic of multiple environments. First, are the results of the current paper relevant when there are multiple environments? Second, what is the interaction between brain mechanisms of dealing with multiple environments and the results of the current paper?
We believe the answer to the first question is positive. The near-orthogonality of representations between environments implies that changes in one can happen without changes in the other. This is evident, for instance, in Khatib et al and Geva et al - in both cases, drift seems to happen independently in two environments, even though they are visited intermittently and are visually similar.
The second question is a fascinating one, and we are planning to pursue it in future work. While the exact way in which the brain achieves this near-independence is an open question, remapping is one possible window into this process.
We extended the discussion to make these points clear.
The process of RD through this mechanism also appears highly non-stationary, in contrast to what is seen in familiar environments in the hippocampus, for example.
The non-stationarity noted by the reviewer is indeed a major feature of our observations, and is indeed linked to familiarity. We divide learning into three phases (now more clearly stated in Table 1 and Figure 4C). The first, rapid phase, consists of improvement of performance - corresponding to initial familiarity with the environment. The third phase, often reported in the literature of representational drift, is indeed stationary and obtained after prolonged familiarity. Our work focuses on the second phase, which is not as immediate as the first one, and can take several days. We note in the discussion that experiments which include a long familiarization process can miss this phase (see also Table 3). Furthermore, we speculate that real life is less stationary than a lab environment, and this second phase might actually be more relevant there.
Reviewer #3 (Public Review):
Summary:
Single-unit neural activity tuned to environmental or behavioral variables gradually changes over time. This phenomenon, called representational drift, occurs even when all external variables remain constant, and challenges the idea that stable neural activity supports the performance of well-learned behaviors. While a number of studies have described representational drift across multiple brain regions, our understanding of the underlying mechanism driving drift is limited. Ratzon et al. propose that implicit regularization - which occurs when machine learning networks continue to reconfigure after reaching an optimal solution - could provide insights into why and how drift occurs in neurons. To test this theory, Ratzon et al. trained a Feedforward Network trained to perform the oft-utilized linear track behavioral paradigm and compare the changes in hidden layer units to those observed in hippocampal place cells recorded in awake, behaving animals.
Ratzon et al. clearly demonstrate that hidden layer units in their model undergo consistent changes even after the task is well-learned, mirroring representational drift observed in real hippocampal neurons. They show that the drift occurs across three separate measures: the active proportion of units (referred to as sparsification), spatial information of units, and correlation of spatial activity. They continue to address the conditions and parameters under which drift occurs in their model to assess the generalizability of their findings.
However, the generalizability results are presented primarily in written form: additional figures are warranted to aid in reproducibility.
We added figures, and a Github with all the code to allow full reproducibility.
Last, they investigate the mechanism through which sparsification occurs, showing that the flatness of the manifold near the solution can influence how the network reconfigures. The authors suggest that their findings indicate a three-stage learning process: 1) fast initial learning followed by 2) directed motion along a manifold which transitions to 3) undirected motion along a manifold.
Overall, the authors' results support the main conclusion that implicit regularization in machine learning networks mirrors representational drift observed in hippocampal place cells.
We thank the reviewer for this summary.
However, additional figures/analyses are needed to clearly demonstrate how different parameters used in their model qualitatively and quantitatively influence drift.
We now provide additional figures regarding parameters (Figures S1, S2).
Finally, the authors need to clearly identify how their data supports the three-stage learning model they suggest.
Their findings promise to open new fields of inquiry into the connection between machine learning and representational drift and generate testable predictions for neural data.
Strengths:
(1) Ratzon et al. make an insightful connection between well-known phenomena in two separate fields: implicit regularization in machine learning and representational drift in the brain. They demonstrate that changes in a recurrent neural network mirror those observed in the brain, which opens a number of interesting questions for future investigation.
(2) The authors do an admirable job of writing to a large audience and make efforts to provide examples to make machine learning ideas accessible to a neuroscience audience and vice versa. This is no small feat and aids in broadening the impact of their work.
(3) This paper promises to generate testable hypotheses to examine in real neural data, e.g., that drift rate should plateau over long timescales (now testable with the ability to track single-unit neural activity across long time scales with calcium imaging and flexible silicon probes). Additionally, it provides another set of tools for the neuroscience community at large to use when analyzing the increasingly high-dimensional data sets collected today.
We thank the reviewer for these comments. Regarding the hypotheses, these are partially confirmed in the new analyses we provide of data from multiple labs (new Figure 3 and Table 3) - indicating that prolonged exposure to the environment leads to more stationarity.
Weaknesses:
(1) Neural representational drift and directed/undirected random walks along a manifold in ML are well described. However, outside of the first section of the main text, the analysis focuses primarily on the connection between manifold exploration and sparsification without addressing the other two drift metrics: spatial information and place field correlations. It is therefore unclear if the results from Figures 3 and 4 are specific to sparseness or extend to the other two metrics. For example, are these other metrics of drift also insensitive to most of the Feedforward Network parameters as shown in Figure 3 and the related text? These concerns could be addressed with panels analogous to Figures 3a-c and 4b for the other metrics and will increase the reproducibility of this work.
We note that the results from figures 3 and 4 (original manuscript) are based on abstract tasks, while in figure 2 there is a contextual notion of spatial position. Spatial position metrics are not applicable to the abstract tasks as they are simple random mapping of inputs, and there isn’t necessarily an underlying latent variable such as position. This transition between task types is better explained in the text now. In essence the spatial information and place field correlation changes are simply signatures of the movements in parameter space. In the abstract tasks their change becomes trivial, as the spatial information becomes strongly correlated with sparsity and place fields are simply the activity vectors of units. These are guaranteed to change as long as there are changes in the activity statistics. We present here the calculation of these metrics averaged over simulations for completeness.
Author response image 1.
PV correlation between training time points averaged over 362 simulations. (B) Mean SI of units normalized to first time step, averaged over 362 simulations. Red line shows the average time point of loss convergence, the shaded area represents one standard deviation.

(2) Many caveats/exceptions to the generality of findings are mentioned only in the main text without any supporting figures, e.g., "For label noise, the dynamics were qualitatively different, the fraction of active units did not reduce, but the activity of the units did sparsify" (lines 116-117). Supporting figures are warranted to illustrate which findings are "qualitatively different" from the main model, which are not different from the main model, and which of the many parameters mentioned are important for reproducing the findings.
We now added figures (S1, S2) that show this exactly. We also added a github to allow full reproduction.
(3) Key details of the model used by the authors are not listed in the methods. While they are mentioned in reference 30 (Recanatesi et al., 2021), they need to be explicitly defined in the methods section to ensure future reproducibility.
The details of the simulation are detailed in the methods sections. We also added a github to allow full reproducibility.
(4) How different states of drift correspond to the three learning stages outlined by the authors is unclear. Specifically, it is not clear where the second stage ends, and the third stage begins, either in real neural data or in the figures. This is compounded by the fact that the third stage - of undirected, random manifold exploration - is only discussed in relation to the introductory Figure 1 and is never connected to the neural network data or actual brain data presented by the authors. Are both stages meant to represent drift? Or is only the second stage meant to mirror drift, while undirected random motion along a manifold is a prediction that could be tested in real neural data? Identifying where each stage occurs in Figures 2C and E, for example, would clearly illustrate which attributes of drift in hidden layer neurons and real hippocampal neurons correspond to each stage.
Thanks for this comment, which urged us to better explain these concepts.
The different processes (reduction in loss, reduction in Hessian) happen in parallel with different timescales. Thus, there are no sharp transitions between the phases. This is now explained in the text in relation to figure 4C, where the approximate boundaries are depicted.
The term drift is often used to denote a change in representation without a change in behavior. In this sense, both the second and third phases correspond to drift. Only the third stage is stationary. This is now emphasized in the text and in the new Table 1. Regarding experimental data, apart from the new figure 3 with four datasets, we also summarize in Table 3 the relation between duration of familiarity and stationarity of the data.
Recommendations for the authors:
The reviewers have raised several concerns. They concur that the authors should address the specific points below to enhance the manuscript.
(1) The three different phases of learning should be clearly delineated, along with how they are determined. It remains unclear in which exact phase the drift is observed.
This is now clearly explained in the new Table 1 and Figure 4C. Note that the different processes (reduction in loss, reduction in Hessian) happen in parallel with different timescales. Thus, there are no sharp transitions between the phases. This is now explained in the text in relation to figure 4C, where the approximate boundaries are depicted.
The term drift is often used to denote a change in representation without a change in behavior. In this sense, both the second and third phases correspond to drift. Only the third stage is stationary. This is now emphasized in the text and in the new Table 1. Regarding experimental data, apart from the new figure 3 with four datasets, we also summarize in Table 3 the relation between duration of familiarity and stationarity of the data.
(2) The term "sparsification" of unit activity is not fully clear. Its meaning should be more explicitly explained, especially since, in the simulations, a significant number of units appear to remain active (Fig. 3A).
We now define precisely the two measures we use - Active Fraction, and Fraction Active Units. There is a new section with an accompanying figure in the Methods section. As Figure S2 shows, the noise statistics (label noise vs. update noise) differentially affects these two measures.
(3) While the study primarily focuses on one aspect of representational drift-the proportion of active units-it should also explore other features traditionally associated with representational drift, such as spatial information and the correlation between place fields.
This absence of features is related to the abstract nature of some of the tasks simulated in our paper. In our original submission the transition between a predictive coding task to more abstract tasks was not clearly explained, creating some confusion regarding the measured metrics. We now clarified the motivation for this transition.
Both the initial simulation and the new experimental data analysis include spatial information (Figures 2,3). The following simulations (Figure 4) with many parameter choices use more abstract tasks, for which the notion of correlation between place cells and spatial information loses its meaning as there is no spatial ordering of the inputs, and every input is encountered only once. Spatial information becomes strongly correlated with the inverse of the active fraction metric. The correlation between place cells is also directly linked to increase in sparseness for these tasks.
(4) There should be a clearer illustration of how labeling noise influences learning dynamics and sparsification.
This was indeed confusing in the original submission. We removed the simulations with label noise from Figure 4, and added a supplementary figure (S2) illustrating the different effects of label noise.
(5) The representational drift observed in this study's simulations appears to be nonstationary, which differs from in vivo reports. The reasons for this discrepancy should be clarified.
We added experimental results from three additional labs demonstrating a change in activity statistics (i.e. increase in spatial information and increase in sparseness) over a long period of time. We suggest that such a change long after the environment is already familiar is an indication for the second phase, and stress that this change seems to saturate at some point, and that most drift papers start collecting data after this saturation, hence this effect was missed in previous in vivo reports. Furthermore, these effects are become more abundant with the advent on new calcium imaging methods, as the older electrophysiological regording methods did not usually allow recording of large amounts of cells for long periods of time. The new Table 3 surveys several experimental papers, emphasizing the degree of familiarity with the environment.
(6) A distinctive feature of the hippocampus is its ability to learn different spatial representations for various environments. The study does not test representational drift in this context, a topic of significant interest to the community. Whether the authors choose to delve into this is up to them, but it should at least be discussed more comprehensively, as it's only briefly touched upon in the current manuscript version.
There are two facets to the topic of multiple environments. First, are the results of the current paper relevant when there are multiple environments? Second, what is the interaction between brain mechanisms of dealing with multiple environments and the results of the current paper?
We believe the answer to the first question is positive. The near-orthogonality of representations between environments implies that changes in one can happen without changes in the other. This is evident, for instance, in Khatib et al and Geva et al - in both cases, drift seems to happen independently in two environments, even though they are visited intermittently and are visually similar.
The second question is a fascinating one, and we are planning to pursue it in future work. While the exact way in which the brain achieves this near-independence is an open question, remapping is one possible window into this process.
We extended the discussion to make these points clear.
(7) The methods section should offer more details about the neural nets employed in the study. The manuscript should be explicit about the terms "hidden layer", "units", and "neurons", ensuring they are defined clearly and not used interchangeably..
We changed the usage of these terms to be more coherent and made our code publicly available. Specifically, “units” refer to artificial networks and “neurons” to biological ones.
In addition, each reviewer has raised both major and minor concerns. These are listed below and should be addressed where possible.
Reviewer #1 (Recommendations For The Authors):
I recommend that the authors edit the text to soften their claims. For example:
In the abstract "To uncover the underlying mechanism, we..." could be changed to "To investigate, we..."
Agree. Done
On line 21, "Specifically, recent studies showed that..." could be changed to "Specifically, recent studies suggest that..."
Agree. Done
On line 100, "All cases" should probably be softened to "Most cases" or more details should be added to Figure 3 to support the claim that every simulation truly had a phase of directed random motion.
The text was changed in accordance with the reviewer’s suggestion. In addition, the figure was changed and only includes simulations in which we expected unit sparsity to arise (without label noise). We also added explanations and supplementary figures for label noise.
Unless I missed something obvious, there is no new experimental data analysis reported in the paper. Thus, line 159 of the discussion, "a phenomenon we also observed in experimental data" should be changed to "a phenomenon that recently reported in experimental data."
We thank the reviewer for drawing our attention to this. We now analyzed data from three other labs, two of which are novel analyses on existing data. All four datasets show the same trends of sparseness with increasing spatial information. The new Figure 3 and text now describe this.
On line 179 of the Discussion, "a family of network configurations that have identical performance..." could be softened to "nearly identical performance." It would be possible for networks to have minuscule differences in performance that are not detected due to stochastic batch effects or limits on machine precision.
The text was changed in accordance with the reviewer’s suggestion.
Other minor comments:
Citation 44 is missing the conference venue, please check all citations are formatted properly.
Corrected.
In the discussion on line 184, the connection to remapping was confusing to me, particularly because the cited reference (Sanders et al. 2020) is more of a conceptual model than an artificial network model that could be adapted to the setting of noisy learning considered in this paper. How would an RNN model of remapping (e.g. Low et al. 2023; Remapping in a recurrent neural network model of navigation and context inference) be expected to behave during the sparsifying portion of drift?
We now clarified this section. The conceptual model of Sanders et al includes a specific prediction (Figure 7 there) which is very similar to ours - a systematic change in robustness depending on duration of training. Regarding the Low et al model, using such mechanistic models is an exciting avenue for future research.
Reviewer #2 (Recommendations For The Authors):
I only have two major questions.
(1) Learning multiple representations: Memory systems in the brain typically must store many distinct memories. Certainly, the hippocampus, where RD is prominent, is involved in the ongoing storage of episodic memories. But even in the idealized case of just two spatial memories, for example, two distinct linear tracks, how would this learning process look? Would there be any interference between the two learning processes or would they be largely independent? Is the separation of time scales robust to the number of representations stored? I understand that to answer this question fully probably requires a research effort that goes well beyond the current study, but perhaps an example could be shown with two environments. At the very least the authors could express their thoughts on the matter.
There are two facets to the topic of multiple environments. First, are the results of the current paper relevant when there are multiple environments? Second, what is the interaction between brain mechanisms of dealing with multiple environments and the results of the current paper?
We believe the answer to the first question is positive. The near-orthogonality of representations between environments implies that changes in one can happen without changes in the other. This is evident, for instance, in Khatib et al and Geva et al - in both cases, drift seems to happen independently in two environments, even though they are visited intermittently and are visually similar.
The second question is a fascinating one, and we are planning to pursue it in future work. While the exact way in which the brain achieves this near-independence is an open question, remapping is one possible window into this process.
We extended the discussion to make these points clear.
(2) Directed drift versus stationarity: I could not help but notice that the RD illustrated in Fig.2D is not stationary in nature, i.e. the upper right and lower left panels are quite different. This appears to contrast with findings in the hippocampus, for example, Fig.3e-g in (Ziv et al, 2013). Perhaps it is obvious that a directed process will not be stationary, but the authors note that there is a third phase of steady-state null drift. Is the RD seen there stationary? Basically, I wonder if the process the authors are studying is relevant only as a novel environment becomes familiar, or if it is also applicable to RD in an already familiar environment. Please discuss the issue of stationarity in this context.
The non-stationarity noted by the reviewer is indeed a major feature of our observations, and is indeed linked to familiarity. We divide learning into three phases (now more clearly stated in Table 1 and Figure 4C). The first, rapid, phase consists of improvement of performance - corresponding to initial familiarity with the environment. The third phase, often reported in the literature of representational drift, is indeed stationary and obtained after prolonged familiarity. Our work focuses on the second phase, which is not as immediate as the first one, and can take several days. We note in the discussion that experiments which include a long familiarization process can miss this phase (see also Table 3). Furthermore, we speculate that real life is less stationary than a lab environment, and this second phase might actually be more relevant there.
Reviewer #3 (Recommendations For The Authors):
Most of my general recommendations are outlined in the public review. A large portion of my comments regards increasing clarity and explicitly defining many of the terms used which may require generating more figures (to better illustrate the generality of findings) or modifying existing figures (e.g., to show how/where the three stages of learning map onto the authors' data).
Sparsification is not clearly defined in the main text. As I read it, sparsification is meant to refer to the activity of neurons, but this needs to be clearly defined. For example, lines 262-263 in the methods define "sparseness" by the number of active units, but lines 116-117 state: "For label noise, the dynamics were qualitatively different, the fraction of active units did not reduce, but the activity of the units did sparsify." If the fraction of active units (defined as "sparseness") did not change, what does it mean that the activity of the units "sparsified"? If the authors mean that the spatial activity patterns of hidden units became more sharply tuned, this should be clearly stated.
We now defined precisely the two measures we use - Active Fraction, and Fraction Active Units. There is a new section with an accompanying figure in the Methods section. As Figure S2 shows, the noise statistics (label noise vs. update noise) differentially affects these two measures.
Likewise, it is unclear which of the features the authors outlined - spatial information, active proportion of units, and spatial correlation - are meant to represent drift. The authors should clearly delineate which of these three metrics they mean to delineate drift in the main text rather than leave it to the reader to infer. While all three are mentioned early on in the text (Figure 2), the authors focus more on sparseness in the last half of the text, making it unclear if it is just sparseness that the authors mean to represent drift or the other metrics as well.
The main focus of our paper is on the non-stationarity of drift. Namely that features (such as these three) systematically change in a directed manner as part of the drift process. This is in The new analyses of experimental data show sparseness and spatial information.
The focus on sparseness in the second half of the paper is because we move to more abstract These are also easy to study in the more abstract tasks in the second part of the paper. In our original submission the transition between a predictive coding task to more abstract tasks was not clearly explained, creating some confusion regarding the measured metrics. We now clarified the motivation for this transition.
It is not clear if a change in the number of active units alone constitutes "drift", especially since Geva et al. (2023) recently showed that both changes in firing rate AND place field location drive drift, and that the passage of time drives changes in activity rate (or # cells active).
Our work did not deal with purely time-dependent drift, but rather focused on experience-dependence. Furthermore, Geva et al study the stationary phase of drift, where we do not expect a systematic change in the total number of cells active. They report changes in the average firing rate of active cells in this phase, as a function of time - which does not contradict our findings.
"hidden layer", "units", and "neurons" seem to be used interchangeably in the text (e.g., line 81-85). However, this is confusing in several places, in particular in lines 83-85 where "neurons" is used twice. The first usage appears to refer to the rate maps of the hidden layer units simulated by the authors, while the second "neurons" appears to refer to real data from Ziv 2013 (ref 5). The authors should make it explicit whether they are referring to hidden layer units or actual neurons to avoid reader confusion.
We changed the usage of these terms to be more coherent. Specifically, “units” refer to artificial networks and “neurons” to biological ones.
The authors should clearly illustrate which parts of their findings support their three-phase learning theory. For example, does 2E illustrate these phases, with the first tenth of training time points illustrating the early phase, time 0.1-0.4 illustrating the intermediate phase, and 0.4-1 illustrating the last phase? Additionally, they should clarify whether the second and third stages are meant to represent drift, or is it only the second stage of directed manifold exploration that is considered to represent drift? This is unclear from the main text.
The different processes (reduction in loss, reduction in Hessian) happen in parallel with different timescales. Thus, there are no sharp transitions between the phases. This is now explained in the text in relation to figure 4C, where the approximate boundaries are depicted.
The term drift is often used to denote a change in representation without a change in behavior. In this sense, both the second and third phases correspond to drift. Only the third stage is stationary. This is now emphasized in the text and in the new Table 1. Regarding experimental data, apart from the new figure 3 with four datasets, we also summarize in Table 3 the relation between duration of familiarity and stationarity of the data.
Line 45 - It appears that the acronym ML is not defined above here anywhere.
Added.
Line 71: the ReLU function should be defined in the text, e.g., sigma(x) = x if x > 0 else 0.
Added.
106-107: Figures (or supplemental figures) to demonstrate how most parameters do not influence sparsification dynamics are warranted. As written, it is unclear what "most parameters" mean - all but noise scale. What about the learning rule? Are there any interactions between parameters?
We now removed the label noise from Figure 4, and added two supplementary figures to clearly explain the effect of parameters. Figure 4 itself was also redone to clarify this issue.
2F middle: should "change" be omitted for SI?
The panel was replaced by a new one in Figure 3.
116-119: A figure showing how results differ for label noise is warranted.
This is now done in Figure S1, S2.
124: typo, The -> the
Corrected.
127-129: This conclusion statement is the first place in the text where the three stages are explicitly outlined. There does not appear to be any support or further explanation of these stages in the text above.
We now explain this earlier at the end of the Introduction section, along with the new Table 1 and marking on Figure 4C.
132-133 seems to be more of a statement and less of a prediction or conclusion - do the authors mean "the flatness of the loss landscape in the vicinity of the solution predicts the rate of sparsification?"
We thank the reviewer for this observation. The sentence was rephrased:
Old: As illustrated in Fig. 1, different solutions in the zero-loss manifold might vary in some of their properties. The specific property suggested from theory is the flatness of the loss landscape in the vicinity of the solution.
New: As illustrated in Fig. 1, solutions in the zero-loss manifold have identical loss, but might vary in some of their properties. The authors of [26] suggest that noisy learning will slowly increase the flatness of the loss landscape in the vicinity of the solution.
135: typo, it's -> its
Corrected.
Line 135-136 "Crucially, the loss on the 136 entire manifold is exactly zero..." This appears to contradict the Figure 4A legend - the loss appears to be very high near the top and bottom edges of the manifold in 4A. Do the authors mean that the loss along the horizontal axis of the manifold is zero?
The reviewer is correct. The manifold mentioned in the sentence is indeed the horizontal axis. We changed the text and the figure to make it clearer.
Equation 6: This does not appear to agree with equation 2 - should there be an E_t term for an expectation function?
Corrected.
Line 262-263: "Sparseness means that a unit has become inactive for all inputs." This should also be stated explicitly as the definition of sparseness/sparsification in the main text.
We now define precisely the two measures we use - Active Fraction, and Fraction Active Units. There is a new section with an accompanying figure in the Methods section. As Figure S2 shows, the noise statistics (label noise vs. update noise) differentially affects these two measures.
-
-
www.biorxiv.org www.biorxiv.org
-
Author response:
The following is the authors’ response to the original reviews.
eLife assessment
This is a valuable computational study that applies the machine learning method of bilinear modeling to the problem of relating gene expression to connectivity. Specifically, the author attempts to use transcriptomic data from mouse retinal neurons to predict their known connectivity. The results are promising, although the reviewers felt that demonstration of the general applicability of the approach required testing it against a second data set. Hence the present results were felt to provide borderline incomplete support for a key premise of the paper.
We thank the reviewers for their insightful and constructive feedback. In response to the reviews, we have undertaken a comprehensive revision of our manuscript, incorporating changes and improvements as outlined below:
(1) New results have been included showcasing the application of our bilinear model to a seconddataset focusing on C. elegans gap junction connectivity. This extension validates our model with a biological context other than mouse retina and facilitates a direct comparison with the spatial connectome model (SCM).
(2) A new section titled "Previous Approaches" has been added to background, situating our studywithin the broader landscape of existing modeling methodologies.
(3) The discussion sections have been expanded to fully incorporate the suggestions and insightsoffered by the reviewers. This includes a deeper exploration of the implications of our findings, potential applications of our model, and a more thorough consideration of its limitations and future directions.
(4) To streamline the main text and ensure that the core narrative remains focused and accessible, select figures and tables have been relocated to the "Supplementary Materials" section.
Reviewer 1 (Public Review):
Summary of what the author was trying to achieve: In this study, the author aimed to develop a method for estimating neuronal-type connectivity from transcriptomic gene expression data, specifically from mouse retinal neurons. They sought to develop an interpretable model that could be used to characterize the underlying genetic mechanisms of circuit assembly and connectivity.
Strengths:
The proposed bilinear model draws inspiration from commonly implemented recommendation systems in the field of machine learning. The author presents the model clearly and addresses critical statistical limitations that may weaken the validity of the model such as multicollinearity and outliers. The author presents two formulations of the model for separate scenarios in which varying levels of data resolution are available. The author effectively references key work in the field when establishing assumptions that affect the underlying model and subsequent results. For example, correspondence between gene expression cell types and connectivity cell types from different references are clearly outlined in Tables 1-3. The model training and validation are sufficient and yield a relatively high correlation with the ground truth connectivity matrix. Seemingly valid biological assumptions are made throughout, however, some assumptions may reduce resolution (such as averaging over cell types), thus missing potentially important single-cell gene expression interactions.
Thank you for recognizing the strengths of our work, particularly the clarity of the model presentation and its foundation in recommendation systems. In the revised manuscript we have also extended the model’s capabilities to analyze gene interactions for neural connectivity at single-cell resolution, when gene expression and connectivity of each cell are known simultaneously.
Weaknesses:
The main results of the study could benefit from replication in another dataset beyond mouse retinal neurons, to validate the proposed method. Dimensionality reduction significantly reduces the resolution of the model and the PCA methodology employed is largely non-deterministic. This may reduce the resolution and reproducibility of the model. It may be worth exploring how the PCA methodology of the model may affect results when replicating. Figure 5, ’Gene signatures associated with the two latent dimensions’, lacks some readability and related results could be outlined more clearly in the results section. There should be more discussion on weaknesses of the results e.g. quantification of what connectivity motifs were not captured and what gene signatures might have been missed.
We acknowledge the significance of validating our method across different datasets. In line with this, our revised manuscript now includes an expanded analysis utilizing a C. elegans gap junction connectivity dataset, which not only broadens the method’s demonstrated applicability but also underscores its versatility across varied neuronal systems.
To address the concern of resolution and reproducibility associated with PCA preprocessing, we have conducted a comparative analysis from five replicates of the bilinear model, presenting the results in the revised manuscript (Figure S3). This analysis confirms the consistency of the solutions, as evidenced by the similarity metrics. Furthermore, we discussed alternative methodologies, such as L1 or L2 regularization, to tackle multicollinearity, offering flexibility in preprocessing choices.
In response to feedback on the original Figure 5’s clarity, we have replaced the original Figure 5e-h with Table S4, which summarizes the gene ontology (GO) enrichment results and quantifies the number of genes associated with aspects of neural development and synaptic organization. This revision aims to improve the interpretability and accessibility of the results, ensuring a clearer presentation of the model’s insights.
Finally, we have expanded our discussion to address the study’s limitations more comprehensively. This includes exploration of potentially missed connections and gene signatures, such as transcription factors, which might not be captured by a linear model due to its inherent preference for predictors with strong correlations to the target variable.
The main weakness is the lack of comparison against other similar methods, e.g. methods presented in Barabási, Dániel L., and Albert-László Barabási. "A genetic model of the connectome." Neuron 105.3 (2020): 435-445. Kovács, István A., Dániel L. Barabási, and Albert-László Barabási. "Uncovering the genetic blueprint of the C. elegans nervous system." Proceedings of the National Academy of Sciences 117.52 (2020): 33570-33577. Taylor, Seth R., et al. "Molecular topography of an entire nervous system." Cell 184.16 (2021): 4329-4347.
We value your suggestion to compare our model with established methods. The revised manuscript now includes a comparative analysis with the spatial connectome model (SCM) using the same C. elegans dataset. In addition, a section reviewing previous approaches has been included in the background part, and the discussion part has been extended for the comparison.
Appraisal of whether the author achieved their aims, and whether results support their conclusions: The author achieved their aims by recapitulating key connectivity motifs from single-cell gene expression data in the mouse retina. Furthermore, the model setup allowed for insight into gene signatures and interactions, however could have benefited from a deeper evaluation of the accuracy of these signatures. The author claims the method sets a new benchmark for single-cell transcriptomic analysis of synaptic connections. This should be more rigorously proven. (I’m not sure I can speak on the novelty of the method)
In the revised manuscript. we emphasized the bilinear model’s innovative application in the context of neuronal connectivity analysis, inspired by collaborative filtering in recommendation systems. We present quantitative performance metrics, such as the ROC-AUC score and Pearson correlation coefficient, as well as its comparison with the SCM, to benchmark our model’s efficacy in reconstructing connectivity matrices. We also quantified the overlap of the genetic interactions revealed by the bilinear model and the SCM (using the C. elegans dataset), and reported the percentage of the top genes associated with neural development and synaptic organization (using the mouse retina dataset). These numbers set a precedent for future methodological comparisons.
Discussion of the likely impact of the work on the field, and the utility of methods and data to the community : This study provides an understandable bilinear model for decoding the genetic programming of neuronal type connectivity. The proposed model leaves the door open for further testing and comparison with alternative linear and/or non-linear models, such as neural networkbased models. In addition to more complex models, this model can be built on to include higher resolution data such as more gene expression dimensions, different types of connectivity measures, and additional omics data.
We are grateful for your recognition of the study’s potential impact. The bilinear model indeed offers a foundation for future explorations, allowing for integration with more complex models, higher-resolution data, and diverse connectivity measures.
Reviewer 1 (Recommendations For The Authors):
The inclusion of predicted connectivity (Figure 6) of unknown BC neurons is useful as it shows that this is a strong hypothesis generation tool. This utility should potentially be showcased more as it is also brought up in the abstract, "genetic manipulation of circuit wiring", with an explanation of how the model could be leveraged as such. The discussion may benefit from a summarizing sentence regarding which key gene signatures were identified and are in line with the literature, which key gene signatures/connectivity motifs may have been missed, and which gene signatures are novel.
Thank you for the insightful recommendation on emphasizing the model’s utility in generating hypotheses, particularly regarding predicting connectivity. In the revised manuscript, we have expanded the discussion on how our model can be leveraged to guide genetic manipulations at altering circuit wiring and highlighted its potential impact in the field.
We have discussed key gene signatures identified from our model that are in line with existing literature, such as plexins and cadherins, which have been previously recognized for their involvement in synaptic connection formation and maintenance. We have also introduced potential new candidates, such as delta-protocadherins. In the revised manuscript, we summarized potentially missed gene signatures or synaptic connections, to provide a comprehensive view of our findings.
Reviewer 2 (Public Review):
Summary:
In this study, Mu Qiao employs a bilinear modeling approach, commonly utilized in recommendation systems, to explore the intricate neural connections between different pre- and post-synaptic neuronal types. This approach involves projecting single-cell transcriptomic datasets of pre- and post-synaptic neuronal types into a latent space through transformation matrices. Subsequently, the cross-correlation between these projected latent spaces is employed to estimate neuronal connectivity. To facilitate the model training, connectomic data is used to estimate the ground-truth connectivity map. This work introduces a promising model for the exploration of neuronal connectivity and its associated molecular determinants. However, it is important to note that the current model has only been tested with Bipolar Cell and Retinal Ganglion Cell data, and its applicability in more general neuronal connectivity scenarios remains to be demonstrated.
Strengths:
This study introduces a succinct yet promising computational model for investigating connections between neuronal types. The model, while straightforward, effectively integrates singlecell transcriptomic and connectomic data to produce a reasonably accurate connectivity map, particularly within the context of retinal connectivity. Furthermore, it successfully recapitulates connectivity patterns and helps uncover the genetic factors that underlie these connections.
Thank you for your positive assessment of the paper.
Weaknesses:
(1) The study lacks experimental validation of the model’s prediction results.
We recognize the importance of experimental validation in substantiating the predictions made by computational models. While the primary focus of this study remains computational, we have dedicated a section in the revised manuscript, titled "Experimental Validation of Candidate Genes", to outline proposed methodologies for the empirical verification of our model’s predictions. This section specifically discusses the experimental exploration of novel candidate genes, such as deltaprotocadherins, within the mouse retina using AAV-mediated CRISPR/Cas9 genetic manipulation. We plan to collaborate with experimental laboratories to facilitate the validation. Given the extensive nature of experimental work, both in terms of time and resources, it is more pragmatic to present a comprehensive experimental investigation in a follow-up study.
(2) The model’s applicability in other neuronal connectivity settings has not been thoroughly explored.
The question of the model’s broader applicability is well-taken. In response, we have expanded our analysis to include additional neuronal data and connectivity settings. Specifically, the revised manuscript includes results where we apply the model to a dataset of C. elegans gap junction connectivity, demonstrating its potential in different neuronal systems. This extension serves to illustrate the model’s adaptability and potential applicability to a broader range of neuronal connectivity studies.
(3) The proposed method relies on the availability of neuronal connectomic data for model training,which may be limited or absent in certain brain connectivity settings.
We acknowledge the limitations posed by the model’s dependency on comprehensive connectomic data, which may not be readily available across all research contexts. To address this, we have discussed in the revised manuscript several alternative strategies to adapt our model to the available data. This includes exploring the potential of applying the model to available data such as projectome, and integrating other data modalities such as electrophysiological measurements. These initiatives aim to enhance the model’s applicability and ensure its utility in a broader spectrum of brain connectivity studies, especially in scenarios where detailed connectomic data are not available.
Reviewer 2 (Recommendations For The Authors):
Q1. In this work, the author has mainly been studying the retina neuronal type connectivity, it will be interesting to see whether the model works for other brain regions or other neuronal type connectivity as well.
We value your interest in the model’s applicability to other brain regions and neuronal types. To address this, we have extended our analysis in the revised manuscript to include a study on gap junction connectivity between C. elegans neurons. This extension demonstrates the model’s versatility and its potential applicability across various nervous systems and connectivity types.
Q2. Whether the authors can use the same transformation matrices trained from the retina data to predict neuronal connectivity in other brain regions? Or an easier case, the connectivity between RGC types to the neuronal types in SC, dLGN, or other post-RGC-synaptic brain regions. As the neuronal connection mechanisms are conserved and widely shared between different neuronal types, one would expect the same transformation matrices may work in predicting other neuronal type connectivity as well (at least to some extent).
The idea to use the same transformation matrices for predicting connectivity in other brain regions is intriguing. While direct application of these matrices to different regions remains challenging, we discussed the potential scalability of our model to other brain areas. By applying the model to combined datasets from various regions, we could uncover conserved neuronal connection mechanisms. This approach is theoretically feasible and is supported by the demonstrated scalability of the bilinear model and its deep learning variants in industrial applications.
Q3. Section 5.2 Connectivity metric generation: in this work, the author uses the stratification profiles of the neurons to estimate the connectivity metric, how reliable this method is? There will be a scenario where though two neuronal types project to a similar inner plexiform layer, they may not have any connection. Have the authors considered combining other experimental data (like electrophysiology data or neuron tracing data)?
We discussed the reliability of using stratification profiles for estimating connectivity metrics, acknowledging potential limitations. In the revised manuscript, we added discussion on how the integration of additional experimental data, such as electrophysiological and neuron tracing data, could enhance the accuracy of the connectivity metrics.
Q4. Section 6 Model training and validation: does the author have a potential hypothesis as to why 2 dimensions are the best latent feature spaces dimensionality? One would imagine with more dimensionality, the model will give better results. Could it be that the connectivity data that is used to train the model is only considering the two-dimensional space of the neuronal stratification?
The selection of two dimensions for the latent feature space was informed by 5-fold cross-validation, aimed at optimizing model generalization to unseen data. Here while increasing dimensionality improves performance on the training set, it does not necessarily enhance generalization to the validation set. Thus, the choice of two dimensions ensures good performance without overfitting to the training data.
Q5. Could the author provide the source code for the analysis? Or could the author make it a python/R package so that non-computational biologists can easily apply the method to their own data?
We have included a "Data and Code Availability" section in the revised manuscript. This section provides a link to the source code with pointers to datasets used in our study, facilitating the application of our methods by researchers from various backgrounds.
Q6. I know it may be difficult for the author to do, but is it possible to design and perform some experiments to validate the model prediction results, either connectivity partners of transcriptomicallydefined RGC types or the function of the key genetic molecules (which hasn’t been discovered before)? The author may consider collaborating with some experimental labs. The author may even consider predicting the connectivity between RGC with some of its post-synaptic neurons in the brain regions, like SC or dLGN, as recently there are a lot of single-cell sequencing data as well as connectivity data.
We appreciate your suggestion regarding experimental validation. As a future direction, we have discussed potential experimental approaches to validate the model’s predictions in the "Experimental Validation of Candidate Genes" section. Specifically, we propose an experimental design involving the manipulation of delta-protocadherins using AAV-mediated CRISPR/Cas9 and subsequent examination of connectivity phenotypes. We are also open to collaborating with experimental labs to further explore the model’s predictions, particularly in predicting connectivity between RGCs and their post-synaptic neurons in other brain regions.
-
-
www.biorxiv.org www.biorxiv.org
-
Reviewer #3 (Public Review):
Summary:
The manuscript addresses a question inspired by the Baroceptor Hypothesis and its links to visual awareness and interoception. Specifically, the reported study aimed to determine if the effects of cardiac contraction (systole) on binocular rivalry (BR) are facilitatory or suppressive. The main experiment - relying on a technically challenging procedure of presenting stimuli synchronised with the heartbeats of participants - has been conducted with great care, and numerous manipulation checks the authors report convincingly show that the methods they used work as intended. Moreover, the control experiment allows for excluding alternative explanations related to participants being aware of their heartbeats. Therefore, the study convincingly shows the effect of cardiac activity on BR - and this is an important finding. The results, however, do not allow for unambiguously determining if this effect is facilitatory or suppressive (see details below), which renders the study not as informative as it could be.
While the authors strongly focus on interoception and awareness, this study will be of interest to researchers studying BR as such. Moreover, the code and the data the authors share can facilitate the adoption of their methods in other labs.
Strengths:
(1) The study required a complex technical setup and the manuscript both describes it well and demonstrates that it was free from potential technical issues (e.g. in section 3.3. Manipulation check).
(2) The sophisticated statistical methods the authors used, at least for a non-statistician like me, appear to be well-suited for their purpose. For example, they take into account the characteristics of BR (gamma distributions of dominance durations). Moreover, the authors demonstrate that at least in one case their approach is more conservative than a more basic one (Binomial test) would be.
(3) Finally, the control experiment, and the analysis it enabled, allow for excluding a multitude of alternative explanations of the main results.
(4) The authors share all their data and materials, even the code for the experiment.
(5) The manuscript is well-written. In particular, it introduces the problem and methods in a way that should be easy to understand for readers coming from different research fields.
Weaknesses:
(1) The interpretation of the main result in the context of the Baroceptor hypothesis is not clear. The manuscript states: The Baroreceptor Hypothesis would predict that the stimulus entrained to systole would spend more time suppressed and, conversely, less time dominant, as cortical activity would be suppressed each time that stimulus pulses. The manuscript does not specify why this should be the case, and the term 'entrained' is not too helpful here (does it refer to neural entrainment? or to 'being in phase with'?). The answer to this question is provided by the manuscript only implicitly, and, to explain my concern, I try to spell it out here in a slightly simplified form.
During systole (cardiac contraction), the visual system is less sensitive to external information, so it 'ignores' periods when the systole-synchronised stimulus is at the peak of its pulse. Conversely, the system is more sensitive during diastole, so the stimulus that is at the peak of its pulse then should dominate for longer, because its peaks are synchronised with the periods of the highest sensitivity of the visual system when the information used to resolve the rivalry is sampled from the environment. This idea, while indeed being a clever test of the hypothesis in question, rests on one critical assumption: that the peak of the stimulus pulse (as defined in the manuscript) is the time when the stimulus is the strongest for the visual system. The notion of 'stimulus strength' is widely used in the BR literature (see Brascamp et al., 2015 for a review). It refers to the stimulus property that, simply speaking, determines its tendency to dominate in the BR. The strength of a stimulus is underpinned by its low-level visual properties, such as contrast and spatial frequency content. Coming back to the manuscript, the pulsing of the stimuli affected at least spatial frequency (and likely other low-level properties), and it is unknown if it was in phase with the pulsing of the stimulus strength, or not. If my understanding of the premise of the study is correct, the conclusions drawn by the authors stand only if it was.
In other words, most likely the strength of one of the stimuli was pulsating in sync with the systole, but is it not clear which stimulus it was. It is possible that, for the visual system, the stimulus meant to pulse in sync with the systole was pulsing strength-wise in phase with the diastole (and the one intended to pulse with in sync with the diastole strength-wise pulsed with the systole). If this is the case, the predictions of the Baroceptor Hypothesis hold, which would change the conclusion of the manuscript.
(2) Using anaglyph goggles necessitates presenting stimuli of a different colour to each eye. The way in which different colours are presented can impact stimulus strength (e.g. consider that different anaglyph foils can attenuate the light they let through to different degrees). To deal with such effects, at least some studies on BR employed procedures of adjusting the colours for each participant individually (see Papathomas et al., 2004; Patel et al., 2015 and works cited there). While I think that counterbalancing applied in the study excludes the possibility that colour-related effects influenced the results, the effects of interest still could be stronger for one of the coloured foils.
(3) Several aspects of the methods (e.g. the stimuli), are not described at the level of detail some readers might be accustomed to. The most important issue here is the task the participants performed. The manuscript says that they pressed a button whenever they experienced a switch in perception, but it is only implied that there were different buttons for each stimulus.
Brascamp, J. W., Klink, P. C., & Levelt, W. J. M. (2015). The 'laws' of binocular rivalry: 50 years of Levelt's propositions. Vision Research, 109, 20-37. https://doi.org/10.1016/j.visres.2015.02.019<br /> Papathomas, T. V., Kovács, I., & Conway, T. (2004). Interocular grouping in binocular rivalry: Basic attributes and combinations. In D. Alais & R. Blake (Eds.), Binocular Rivalry (pp. 155-168). MIT Press<br /> Patel, V., Stuit, S., & Blake, R. (2015). Individual differences in the temporal dynamics of binocular rivalry and stimulus rivalry. Psychonomic Bulletin and Review, 22(2), 476-482. https://doi.org/10.3758/s13423-014-0695-1
-
-
pressbooks.online.ucf.edu pressbooks.online.ucf.edu
-
ccording to my Holland code which was IRC which stands for investigative, realistic, and conventional.
incomplete sentence
-
-
www.biorxiv.org www.biorxiv.org
-
Author response:
The following is the authors’ response to the original reviews.
Reviewer #1 (Public Review):
Summary:
In this study, Pan DY et al. discovered that the clearance of senescent osteoclasts can lead to a reduction in sensory nerve innervation. This reduction is achieved through the attenuation of Netrin-1 and NGF levels, as well as the regulation of H-type vessels, resulting in a decrease in pain-related behavior. The experiments are well-designed. The results are clearly presented, and the legends are also clear and informative. Their findings represent a potential treatment for spine pain utilizing senolytic drugs.
Strengths:
Rigorous data, well-designed experiments as well as significant innovation make this manuscript stand out.
Weaknesses:
Quantification of histology and detailed statistical analysis will further strengthen this manuscript.
I have the following specific comments.
(1) Since defining senescent cells solely based on one or two markers (SA-β-gal and p16) may not provide a robust characterization, it would be advisable to employ another wellestablished senescence marker, such as γ-H2AX or HMGB1, to corroborate the observed increase in senescent osteoclasts following LSI and aging.
We value the comments provided by the reviewer. In accordance with your suggestion, we have performed co-staining of HMGB1 with Trap in Supplementary Figure 1 to corroborate the observed augmentation of senescent osteoclasts following LSI and aging.
Author response image 1.

(2) The connection between heightened Netrin-1 secretion by senescent osteoclasts following LSI or aging and its relevance to pain warrants thorough discussion within the manuscript to provide a comprehensive understanding of the entire narrative.
We appreciate the reviewer's insightful comments. We have thoroughly addressed the entire narrative in the revised manuscript, as outlined below:
During lumbar spine instability (LSI) or aging, endplates undergo ossification, leading to elevated osteoclast activity and increased porosity1-4. The progressive porous transformation of endplates, accompanied by a narrowed intervertebral disc (IVD) space, is a hallmark of spinal degeneration4,5. Considering that pain arises from nociceptors, it is plausible that low back pain (LBP) may be attributed to sensory innervation within endplates. Additionally, porous endplates exhibit higher nerve density compared to normal endplates or degenerative nucleus pulposus6. Netrin-1, a crucial axon guidance factor facilitating nerve protrusion, has been implicated in this process7-9. The receptor mediating Netrin-1-induced neuronal sprouting, deleted in colorectal cancer (DCC), was found to co-localize with CGRP+ sensory nerve fibers in endplates after LSI surgery10,11. In summary, during LSI or aging, osteoclastic lineage cells secrete Netrin-1, inducing extrusion and innervation of CGRP+ sensory nerve fibers within the spaces created by osteoclast resorption. This Netrin-1/DCC-mediated pain signal is subsequently transmitted to the dorsal root ganglion (DRG) or higher brain levels.
(3) It appears that the quantitative data for TRAP staining in Figure 1j is missing.
We appreciate the reviewer's comments. We have added the statistical data of TRAP staining (Figure. 1p) to Figure 1 in the revised manuscript.
Author response image 2.

(4) Regarding Figure 6, could you please specify which panels were analyzed using a t-test and which ones were subjected to ANOVA? Alternatively, were all the panels in Figure 6 analyzed using ANOVA?
We appreciate the reviewer’s comments here. Upon careful review, we have ensured that quantitative data in panels b, c, and f are analyzed using t-tests, while panels d, e, and g are subjected to one-way ANOVA. These updates have been reflected in the revised figure legend.
Reviewer #2 (Public Review):
Summary:
This manuscript examined the underlying mechanisms between senescent osteoclasts (SnOCs) and lumbar spine instability (LSI) or aging. They first showed that greater numbers of SnOCs are observed in mouse models of LSI or aging, and these SnOCs are associated with induced sensory nerve innervation, as well as the growth of H-type vessels, in the porous endplate. Then, the deletion of senescent cells by administration of the senolytic drug Navitoclax (ABT263) results in significantly less spinal hypersensitivity, spinal degeneration, porosity of the endplate, sensory nerve innervation, and H-type vessel growth in the endplate. Finally, they also found that there is greater SnOCmediated secretion of Netrin-1 and NGF, two well-established sensory nerve growth factors, compared to non-senescent OCs. The study is well conducted and data strongly support the idea. However, some minor issues need to be addressed.
(1) In Figure 2C, "Number of SnCs/mm2", SnCs should be SnOCs.
We apologize for the oversight. This has been rectified in the revised manuscript.
Author response image 3.

(2) In Figure 3A-E, is there any statistical difference between groups Young and Aged+PBS?
We appreciate the reviewer's comments. Following your recommendation, we conducted additional statistical analyses to compare the young and PBS-treated aged mice, and we have incorporated these findings into the revised manuscript. The data reveals a significant increased paw withdrawal frequency (PWF) in aged mice treated with PBS compared with young mice, particularly at 0.4g instead of 0.07g (Figure 3a, 3b). Moreover, aged mice treated with PBS exhibited a significant reduction in both distance traveled and active time when compared to young mice (Figure. 3d, 3e). Additionally, PBS-treated aged mice demonstrated a significantly shortened heat response time relative to young mice (Figure. 3c).
Author response image 4.

(3) Again, is there any statistical difference between the Young and Aged+PBS groups in Figure 4F-K?
We appreciate the reviewer's comments. As per your suggestion, we conducted a thorough analysis to determine the statistical differences between the young and aged+PBS groups, and these statistical results have been implemented in the revised manuscript. The caudal endplates of L4/5 in PBS-treated aged mice exhibited a significant increase in endplate porosity (Figure. 4f) and trabecular separation (Tb.Sp) (Figure. 4g) compared to young mice.
Additionally, PBS-treated aged mice showed a significant elevation in endplate score (Figure. 4h), as well as an increased distribution of MMP13 and ColX within the endplates when compared to young mice (Figure. 4i, 4j). Furthermore, TRAP staining revealed a significant increase in TRAP+ osteoclasts within the endplates of PBS-treated aged mice as compared to young mice (Figure. 4k).
Author response image 5.

(4) What is the figure legend of Figure 7?
The legend for Figure 7 (as below) is included in a separate PDF file labeled 'Figures and Legends.' We have carefully checked the revised manuscript and made sure all the legends are included.
“Fig. 7. (a) Representative images of immunofluorescent analysis of CD31, an angiogenesis marker (green), Emcn, an endothelial cell marker (red) and nuclei (DAPI; blue) of adult sham, LSI and aged mice injected with PBS or ABT263. (b) Quantitative analysis of the intensity mean value of CD31 per mm2 in sham, LSI mice treated with PBS or ABT263. (c) Quantitative analysis of the intensity mean value of CD31 per mm2 in aged mice treated with PBS or ABT263. (d) Quantitative analysis of the intensity mean value of Emcn per mm2 in sham, LSI mice treated with PBS or ABT263. (e) Quantitative analysis of the intensity mean value of Emcn per mm2 in aged mice treated with PBS or ABT263. n ≥ 4 per group. Statistical significance was determined by one-way ANOVA, and all data are shown as means ± standard deviations. “
(5) In "Mice" section, an Ethical code is suggested to be added.
We appreciate the reviewer's comments. In accordance with your suggestion, we have included the Johns Hopkins University animal protocol number in the revised manuscript. The relevant paragraph has been updated to read: “All mice were maintained at the animal facility of The Johns Hopkins University School of Medicine (protocol number: MO21M276).”
(6) In "Methods" section, please indicate the primers of GAPDH.
We apologize for the absence of the GAPDH primers. Upon review, the GAPDH primers used were as follows: forward primer 5'-ATGTGTCCGTCGTGGATCTGA-3' and reverse primer 5'-ATGCCTGCTTCACCACCTTCTT-3'. These primer sequences have been included in the revised manuscript.
(7) Preosteoclasts are regarded to be closely related to H-type vessel growth, so do the authors have any comments on this? Any difference or correlation between SnCs and preosteoclasts?
The pre-osteoclast plays a crucial role in secreting anabolic growth factors that facilitate H-type vessel formation, osteoblast chemotaxis, proliferation, differentiation, and mineralization. The osteoclast represents the terminal differentiation phase, ultimately leading to the induction of resorption.
Senescent cells, including senescent osteoclasts, are characterized by permanent cell cycle arrest and changes in their secretory profile, which can impact their function. In the context of osteoclasts, senescence can lead to a reduction in bone resorption capacity and impaired bone remodeling. Senescent osteoclasts are believed to contribute to age-related bone loss and bonerelated diseases, such as osteoporosis.
Reviewer #3 (Public Review):
Summary:
This research article reports that a greater number of senescent osteoclasts (SnOCs), which produce Netrin-1 and NGF, are responsible for innervation in the LSI and aging animal models.
Strengths:
The research is based on previous findings in the authors' lab and the fact that the IVD structure was restored by treatment with ABT263. The logic is clear and clarifies the pathological role of SnOCs, suggesting the potential utilization of senolytic drugs for the treatment of LBP. Generally, the study is of good quality and the data is convincing.
Weaknesses:
There are some points that can be improved:
(1) Since this work primarily focuses on ABT263, it resembles a pharmacological study for this drug. It is preferable to provide references for the ABT263 concentration and explain how the administration was determined.
Thank you for your comment. ABT263 has been extensively employed in diverse research studies12-15. The concentration and administration of ABT263 followed the protocol outlined in the published paper13. The reference on how to use ABT263 is cited in the method section: “ABT263 was administered to mice by gavage at a dosage of 50 mg per kg body weight per day (mg/kg/d) for a total of 7 days per cycle, with two cycles conducted and a 2-week interval between them39”.
(2) It would strengthen the study to include at least 6 mice per group for each experiment and analysis, which would provide a more robust foundation.
Thank you for your comment here. In response, we conducted a new set of experiments, augmenting the majority of the sample size to six, and updated the corresponding statistical data in the revised manuscript.
(3) In Figure 4, either use "adult" or "young" consistently, but not both. Additionally, it's important to define "sham," "young," and "adult" explicitly in the methods section.
Thank you for your comment. We have addressed the inconsistency in the labeling of Figure 4. Additionally, we have explicitly defined "sham," "young," and "adult" in the methods section as follows: The control group (sham group) for the LSI group refers to C57BL/6J mice that did not undergo LSI surgery, while the control group (young group) for the Aged group refers to 4-month-old C57BL/6J mice.
Author response image 6.
(4) Assess the protein expression of Netrin 1 and NGF.
Thank you for your comment here. We employed ELISA to assess the protein expression of Netrin-1 and NGF in the L3 to L5 endplates. The data revealed that compared to the young sham mice, LSI was associated with significantly greater protein expression of Netrin1 and NGF, which was substantially attenuated by ABT263 treatment in LSI mice (Supplementary Fig. 2a, 2b)
Author response image 7.

Reference
(1) Bian, Q. et al. Excessive Activation of TGFbeta by Spinal Instability Causes Vertebral Endplate Sclerosis. Sci Rep 6, 27093, doi:10.1038/srep27093 (2016).
(2) Bian, Q. et al. Mechanosignaling activation of TGFbeta maintains intervertebral disc homeostasis. Bone Res 5, 17008, doi:10.1038/boneres.2017.8 (2017).
(3) Papadakis, M., Sapkas, G., Papadopoulos, E. C. & Katonis, P. Pathophysiology and biomechanics of the aging spine. Open Orthop J 5, 335-342, doi:10.2174/1874325001105010335 (2011).
(4) Rodriguez, A. G. et al. Morphology of the human vertebral endplate. J Orthop Res 30, 280-287, doi:10.1002/jor.21513 (2012).
(5) Taher, F. et al. Lumbar degenerative disc disease: current and future concepts of diagnosis and management. Adv Orthop 2012, 970752, doi:10.1155/2012/970752 (2012).
(6) Fields, A. J., Liebenberg, E. C. & Lotz, J. C. Innervation of pathologies in the lumbar vertebral end plate and intervertebral disc. Spine J 14, 513-521, doi:10.1016/j.spinee.2013.06.075 (2014).
(7) Hand, R. A. & Kolodkin, A. L. Netrin-Mediated Axon Guidance to the CNS Midline Revisited. Neuron 94, 691-693, doi:10.1016/j.neuron.2017.05.012 (2017).
(8) Moore, S. W., Zhang, X., Lynch, C. D. & Sheetz, M. P. Netrin-1 attracts axons through FAK-dependent mechanotransduction. J Neurosci 32, 11574-11585, doi:10.1523/JNEUROSCI.0999-12.2012 (2012).
(9) Serafini, T. et al. Netrin-1 is required for commissural axon guidance in the developing vertebrate nervous system. Cell 87, 1001-1014, doi:10.1016/s0092-8674(00)81795-x (1996).
(10) Forcet, C. et al. Netrin-1-mediated axon outgrowth requires deleted in colorectal cancer-dependent MAPK activation. Nature 417, 443-447, doi:10.1038/nature748 (2002).
(11) Shu, T., Valentino, K. M., Seaman, C., Cooper, H. M. & Richards, L. J. Expression of the netrin-1 receptor, deleted in colorectal cancer (DCC), is largely confined to projecting neurons in the developing forebrain. J Comp Neurol 416, 201-212, doi:10.1002/(sici)1096-9861(20000110)416:2<201::aid-cne6>3.0.co;2-z (2000).
(12) Born, E. et al. Eliminating Senescent Cells Can Promote Pulmonary Hypertension Development and Progression. Circulation 147, 650-666, doi:10.1161/CIRCULATIONAHA.122.058794 (2023).
(13) Chang, J. et al. Clearance of senescent cells by ABT263 rejuvenates aged hematopoietic stem cells in mice. Nat Med 22, 78-83, doi:10.1038/nm.4010 (2016).
(14) Lim, S. et al. Local Delivery of Senolytic Drug Inhibits Intervertebral Disc Degeneration and Restores Intervertebral Disc Structure. Adv Healthc Mater 11, e2101483, doi:10.1002/adhm.202101483 (2022).
(15) Yang, H. et al. Navitoclax (ABT263) reduces inflammation and promotes chondrogenic phenotype by clearing senescent osteoarthritic chondrocytes in osteoarthritis. Aging (Albany NY) 12, 12750-12770, doi:10.18632/aging.103177 (2020).
-
-
social-media-ethics-automation.github.io social-media-ethics-automation.github.io
-
Gene Demby. How Code-Switching Explains The World. NPR, April 2013. URL: https://www.npr.org/sections/codeswitch/2013/04/08/176064688/how-code-switching-explains-the-world (visited on 2023-11-24).
In the article "How Code-Switching Explains The World" from NRP, they talks about how different people "code switch" depending on the scenario. In the article, they showed famous celebrities such as Obama, Beyonce and other YouTube videos changing their tone of voice while still being themselves. This is because code switching can help benefit you depending on where you are and what situation you are in. The article also states that code switching is how we can "try to feel each other out." Code switching is a valuable skill to develope as it can give you an advantage in certain scenarios.
-
Gene Demby. How Code-Switching Explains The World.
I read "How Code-Switching Explains The World" from NPR. The article, in their own words, aims to "exploring are the different spaces we each inhabit and the tensions of trying to navigate between them. In one sense, code-switching is about dialogue that spans cultures." The article gives a few different examples through videos from people like Obama and Beyonce. When people code switch, they are still themselves - they are switching to a voice that suits them best in that scenario. Code-switching is one of the ways "we interact with one another and try to feel each other out."
-
-
social-media-ethics-automation.github.io social-media-ethics-automation.github.io
-
The way we present ourselves to others around us (our behavior, social role, etc.) is called our public persona [f20]. We also may change how we behave and speak depending on the situation or who we are around, which is called code-switching [f21].
The concept of code-switching is not just limited to personal interactions but is also prevalent in professional environments. It is similar to how companies rebrand themselves in different markets, showcasing the versatility and strategic thinking individuals employ in various aspects of life.
-
-
social-media-ethics-automation.github.io social-media-ethics-automation.github.io
-
In the 1980s and 1990s, Bulletin board system (BBS) [e6] provided more communal ways of communicating and sharing messages. In these systems, someone would start a “thread” by posting an initial message. Others could reply to the previous set of messages in the thread.
I've never seen or heard about this system. This is similar to Reddit nowadays. It allows people to communicate with each other, and provides a platform for people to share useful information. Some disadvantages in this system is that the style of this system makes it hard to look through comments, because it looks like original code. Further, I'm wondering how it manages information. Does misinformation exist in this system?
-
-
github.com github.com
-
Code examples that accompany the MDN JavaScript/ECMAScript documentation
-
-
arxiv.org arxiv.org
-
Author Response
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public Review):
This study examined a universal fractal primate brain shape. However, the paper does not seem well structured and is not well written. It is not clear what the purpose of the paper is. And there is a lack of explanation for why the proposed analysis is necessary. As a result, it is challenging to clearly understand what novelty in the paper is and what the main findings are.
We have now restructured the paper, including a summary of the main purpose and findings as follows:
“Compared to previous literature, we can summarise our main contribution and advance as follows:
(i) We are showing for the first time that representative primate species follow the exact same fractal scaling – as opposed to previous work showing that they have a similar fractal dimension [Hofman1985, Hofman1991], i.e. slope, but not necessarily the same offset, as previous methods had no consistent way of comparing offsets.
(ii) Previous work could also not show direct agreement in morphometrics between the coarse-grained brains of primate species and other non-primate mammalian species.
(iii) Demonstrating in proof-of-principle that multiscale morphometrics, in practice, can have much larger effect sizes for classification applications. This moves beyond our previous work where we only showed the scaling law across [Mota2015] and within species [Wang2016], but all on one (native) scale with comparable effect sizes for classification applications [Wang2021].
In simple terms: we know that objects can have the same fractal dimension, but differ greatly in a range of other shape properties. However, we demonstrate here, that representative primate brains and mammalian brain indeed share a range of other key shape properties, on top of agreeing in fractal dimension. This suggests a universal blueprint for mammalian brain shape and a common set of mechanisms governing cortical folding. As a practical additional outcome of our study, we could show that our novel method of deriving multiscale metrics of brain shape can differentiate subtle shape changes much better than the metrics we have been using so far at a single native scale.”
We plan to use the second paragraph as a plain-language summary of our work.
Additionally, several terms are introduced without adequate explanation and contextualization, further complicating comprehension.
We have now made sure that potential jargon is introduced with context and explanation. For example in Introduction: “This scaling law, relating powers of cortical thickness and surface area metrics, […]”
Does the second section, "2. Coarse-graining procedure", serve as an introduction or a method?
We have now renamed this section to “Coarse-graining Method” to indicate that this is a section about methods. However, to describe the methods adequately, we also expanded this section with introductory texts around the history and motivation of the method to provide context and explanations, as the reviewer rightly requested.
Moreover, the rationale behind the use of the coarse-graining procedure is not adequately elucidated. Overall, it is strongly recommended that the paper undergoes significant improvements in terms of its structure, explanatory depth, and overall clarity to enhance its comprehensibility.
To specifically explain the rationale behind the coarse-graining method, we added several clarifications, including the following paragraph:
“As a starting point for such a coarse-graining procedure, we suggest to turn to a well-established method that measures fractal dimension of objects: the so-called box-counting algorithm [Kochunov2007, Madan2019]. Briefly, this algorithm fills the object of interest (say the cortex in our case) with boxes, or voxels of increasingly larger sizes and counts the number of boxes in the object as a function of box size. As the box size increases, the number of boxes decreases; and in a log-log plot, the slope of this relationship indicates the fractal dimension of the object. In our case, this method would not only provide us with the fractal dimension of the cortex, but, with increasing box size, the filled cortex would also contain less and less detail of the folded shape of the cortex. Intuitively, with increasing box size, the smaller details, below the resolution of a single box, would disappear first, and increasingly larger details will follow -- precisely what we require from a coarse-graining method. We therefore propose to expand the traditional box-counting method beyond its use to measure fractal dimension, but to also analyse the reconstructed cortices as different realisations of the original cortex at the specified spatial scale.”
Reviewer #2 (Public Review):
In this manuscript, Wang and colleagues analyze the shapes of cerebral cortices from several primate species, including subgroups of young and old humans, to characterize commonalities in patterns of gyrification, cortical thickness, and cortical surface area. The work builds on the scaling law introduced previously by co-author Mota, and Herculano-Houzel. The authors state that the observed scaling law shares properties with fractals, where shape properties are similar across several spatial scales. One way the authors assess this is to perform a "cortical melting" operation that they have devised on surface models obtained from several primate species. The authors also explore differences in shape properties between the brains of young (~20 year old) and old (~80) humans. My main criticism of this manuscript is that the findings are presented in too abstract a manner for the scientific contribution to be recognized.
We recognise that our work is at the intersection of complex mathematical concepts and a perplexing biological phenomenon. Therefore, our paper has to strike a balance between scientifically accurate and succinct descriptions whilst giving sufficient space to provide context and explanations.
Throughout, we have now added text to provide more context, but also repeat key statements in plain-english terms.
For example, we added the following text to highlight our key contributions.
“In simple terms: we know that objects can have the same fractal dimension, but differ greatly in a range of other shape properties. However, we demonstrate here, that representative primate brains and mammalian brain indeed share a range of other key shape properties, on top of agreeing in fractal dimension. This suggests a universal blueprint for mammalian brain shape and a common set of mechanisms governing cortical folding. As a practical additional outcome of our study, we could show that our novel method of deriving multiscale metrics of brain shape can differentiate subtle shape changes much better than the metrics we have been using so far at a single native scale.”
(1) The series of operations to coarse-grain the cortex illustrated in Figure 1, constitute a novel procedure, but it is not strongly motivated, and it produces image segmentations that do not resemble real brains.
To specifically explain the rationale behind the coarse-graining method, we added several clarifications, including the following paragraph:
“As a starting point for such a coarse-graining procedure, we suggest to turn to a well-established method that measures fractal dimension of objects: the so-called box-counting algorithm [Kochunov2007, Madan2019]. Briefly, this algorithm fills the object of interest (say the cortex in our case) with boxes, or voxels of increasingly larger sizes and counts the number of boxes in the object as a function of box size. As the box size increases, the number of boxes decreases; and in a log-log plot, the slope of this relationship indicates the fractal dimension of the object. In our case, this method would not only provide us with the fractal dimension of the cortex, but, with increasing box size, the filled cortex would also contain less and less detail of the folded shape of the cortex. Intuitively, with increasing box size, the smaller details, below the resolution of a single box, would disappear first, and increasingly larger details will follow -- precisely what we require from a coarse-graining method. We therefore propose to expand the traditional box-counting method beyond its use to measure fractal dimension, but to also analyse the reconstructed cortices as different realisations of the original cortex at the specified spatial scale.”
We also note in several places in the text that the coarse-grained brains are not to be understood as exact reconstructions of actual brains, but serve the purpose of a model:
“[…] nor are the coarse-grained versions of human brains supposed to exactly resemble the location/pattern/features of gyri and sulci of other primates. The similarity we highlighted here are on the level of summary metrics, and our goal was to highlight the universality in such metrics to point towards highly conserved quantities and mechanisms.”
“Note, of course, that the coarse-grained brain surfaces are an output of our algorithm alone and not to be directly/naively likened to actual brain surfaces, e.g. in terms of the location or shape of the folds. Our comparisons here between coarse-grained brains and actual brains is purely on the level of morphometrics across the whole cortex.”
The process to assign voxels in downsampled images to cortex and white matter is biased towards the former, as only 4 corners of a given voxel are needed to intersect the original pial surface, but all 8 corners are needed to be assigned a white matter voxel (section S2). This causes the cortical segmentation, such as the bottom row of Figure 1B, to increase in thickness with successive melting steps, to unrealistic values. For the rightmost figure panel, the cortex consists of several 4.9-sided voxels and thus a >2 cm thick cortex. A structure with these morphological properties is not consistent with the anatomical organization of a typical mammalian neocortex.
Specifically on the point on increasing cortical thickness with increased level of coarse-graining, we have now added the following paragraph:
“The observation that with increasing voxel sizes, the coarse-grained cortices tend to be smoother and thicker is particularly interesting: the scaling law in Eq. 1 can be understood as thicker cortices (T) form larger folds (or are smoother i.e. less surface area At) when brain size is kept constant (Ae). This way of understanding has also been vividly illustrated by using the analogy of forming paper balls with papers of varying thickness in [Mota2015]: to achieve the same size of a paper ball (Ae), the one that uses thicker paper (T) will show larger folds (or is smoother i.e. less surface area At) than the one using thinner paper. The scaling law can therefore be understood as a physically and biologically plausible statement, and here, we are encouraged that our algorithm yields results in line with the scaling law.”
(2) For the comparison between 20-year-old and 80-year-old brains, a well-documented difference is that the older age group possesses more cerebral spinal fluid due to tissue atrophy, and the distances between the walls of gyri becomes greater. This difference is born out in the left column of Figure 4c. It seems this additional spacing between gyri in 80-year-olds requires more extensive down-sampling (larger scale values in Figure 4a) to achieve a similar shape parameter K as for the 20-year-olds. A case could be made that the familiar way of describing brain tissue - cortical volume, white matter volume, thickness, etc. - is a more direct and intuitive way to describe differences between young and old adult brains than the obscure shape metric described in this manuscript. At a minimum, a demonstration of an advantage of the Figure 4a and 4b analyses over current methods for interpreting age-related differences would be valuable.
We have demonstrated the utility of our new shape metrics in a separate paper [Wang2021]. However, we agree with the reviewer that, in this specific instance, it is much easier to understand the key message without considering the less traditional metrics. We have therefore completely revised this part of the Results section to highlight the advantage of multiscale morphometrics, and used the traditional metric of surface area to illustrate the point. The reasoning in surface area is much easier to follow, both visually and conceptually, exactly as the reviewer described.
(3) In Discussion lines 199-203, it is stated that self-similarity, operating on all length scales, should be used as a test for existing and future models of gyrification mechanisms. First, the authors do not show, (and it would be surprising if it were true) that self-similarity is observed for length scales smaller than the acquired MRI data for any of the datasets analyzed. The analysis is restricted to coarse (but not fine)-graining.
To clarify this point, we have added a supplementary section and the following sentence: “Note this method has also no direct dependency on the original MR image resolution, as the inputs are smooth grey and white matter surface meshes reconstructed from the images using strong (bio-)physical assumptions and therefore containing more fine-grained spatial information than the raw images (also see Suppl. Text 3).”
We are indeed sampling at resolutions down to 0.2mm, which is below MR image resolution. The reviewer is, however, correct that we are only coarse-graining, not “fine-graining”. Coarse-graining, here, relates to more coarse than the smooth surface meshes though, not the MR image.
Therefore, self-similarity on all length scales would seem to be too strong a constraint. Second, it is hard to imagine how this test could be used in practice. Specific examples of how gyrification mechanisms support or fail to support the generation of self-similarity across any length scale, would strengthen the authors' argument.
We agree that spatial scales much below 0.2mm resolution may not be of interest, as these scales are only measuring the fractal properties, or “bumpiness”, of the surface meshes at the vertex level. We have therefore revised our statement in Discussion and clarified it with an example: “Finally, this dual universality is also a more stringent test for existing and future models of cortical gyrification mechanisms at relevant scales, and one that moreover is applicable to individual cortices. For example, any models that explicitly simulate a cortical surface could be directly coarse-grained with our method and compared to actual human and primate data provided here.”
Some additional, specific comments are as follows:
(4) The definition of the term A_e as the "exposed surface" was difficult to follow at first. It might be helpful to state that this parameter is operationally defined as the convex hull surface area.
We agree and introduced this term now at first use: “The exposed surface area can be thought of as the surface area of a piece of cling film wrapped around the brain. Mathematically, for the remaining paper it is the convex hull of the brain surface.”
Also, for the pial surface, A_t, there are several who advocate instead for the analysis of a cortical mid-thickness surface area, as the pial surface area is subject to bias depending on the gyrification index and the shape of the gyri. It would be helpful to understand if the same results are obtained from mid-thickness surfaces.
This point is indeed being investigated independently of this study. Our provisional understanding is that in healthy human brains, at native scale, using the mid (or the white matter) surface introduced a systematic offset shift in the scaling law, but does not affect the scaling slope of 1.25. However, this requires a more in-depth investigation in a range of other conditions, and in the context of the coarse-grained shapes, which is on-going. Nevertheless, the scaling law, at first introduction already, has been using the pial surface area [Mota2015] and all subsequent follow-up studies followed this convention. To make our paper here accessible and directly comparable, we therefore used the same metric. Future work will investigate the utility of other metrics.
(5) In Figure 2c, the surfaces get smaller as the coarse-graining increases, making it impossible to visually assess the effects of coarse-graining on the shapes. Why aren't all cortical models shown at the same scale?
The purpose of rescaling the surfaces is to match the scaling plot (Fig 2A) directly, which are showing shrinking surface areas Ae and At with increasing coarse-graining. Here, we are effectively keeping the size of the box constant and resizing the cortical surface instead, which is mathematically equivalent to changing the box size and keeping the cortical surface constant.
An alternative interpretation of the “shrinking” is, therefore, that with increasingly smaller cortical surfaces, the folding details disappear, as we require from our coarse-graining method. This is also visually apparent, as the reviewer points out. We have added this to the explanation in the text.
If we, however, changed the box size instead, the scaling law plot would be meaningless: for example, Ae would barely change with coarse-graining. We would therefore have needed to introduce more complexity in our analysis in terms of how we can measure the scaling law. Thus, we opted to present the simpler method and interpretation here.
Nevertheless, we agree that a direct comparison would be beneficial and have thus added the videos for each species in supplementary under this link: https://bit.ly/3CDoqZQ Upon completed peer-review, we hope to integrate these directly into eLife’s interactive displays for this figure.
(6) Text in Section 3.2 emphasizes that K is invariant with scale (horizontal lines in Figure 3), and asserts this is important for the formation of all cortices. However, I might be mistaken, but it appears that K varies with scale in Figure 4a, and the text indicates that differences in the S dependence are of importance for distinguishing young vs. old brains. Is this an inconsistency?
We agree that it may be confusing to emphasise a “constant K” in the first set of results across species, and then later highlight a changing K in the human ageing results. To clarify, in the first set of results, we find a constant K relative to a changing S: the range in K across melted primate brains is less than 0.1, whereas in S it is over 1.2. In other words, S changes are an order of magnitude higher than K changes. Hence, we described K as “constant” relative to S.
Nevertheless, K shows subtle changes within individuals, which is what we were describing in the human ageing results. These changes are within the range of K values described in the across species results.
However, in the interest of clarity, we followed the reviewer’s suggestion of simplifying the last set of results on human ageing and therefore the variable K in human ageing now only appears in Supplementary. We have now added clarifications to the supplementary on this point.
Reviewer #3 (Public Review):
Summary:
Through a detailed methodology, the authors demonstrated that within 11 different primates, the shape of the brain matched a fractal of dimension 2.5. They enhanced the universality of this result by showing the concordance of their results with a previous study investigating 70 mammalian brains, and the discordance of their results with other folded objects that are not brains. They incidentally illustrated potential applications of this fractal property of the brain by observing a scale-dependent effect of aging on the human brain.
Strengths:
- New hierarchical way of expressing cortical shapes at different scales derived from the previous report through the implementation of a coarse-graining procedure.
Positioning of results in comparison to previous works reinforcing the validity of the observation.
- Illustration of scale-dependence of effects of brain aging in the human.
Weaknesses:
- The impact of the contribution should be clarified compared to previous studies (implementation of new coarse graining procedure, dimensionality of primate brain vs previous studies, and brain aging observations).
We have now made these changes, particularly by adding two paragraphs to the start of Discussion. One summarising the main contributions above previous work, and one paraphrasing the former in plain English for accessibility.
- The rather small sample sizes, counterbalanced by the strength of the effect demonstrated.
We have now increased the sample size of the human ageing analysis substantially to over 100 subjects and observe the same trends, but with an even stronger effect. We therefore believe that this revision serves as an additional internal validation of our data and methods.
- The use of either averaged or individual brains for the different sub-studies could be made clearer.
We have now added this to our Suppl methods: with the exception of the Marmoset, all brain surface data were derived from healthy individual brains.
- The model discussed hypothetically in the discussion is not very clear, and may not be state-of-the-art (axonal tension driving cortical folding? cf. https://doi.org/10.1115/1.4001683).
We have now added this citation to our Discussion and given it context:
“Indeed, our previously proposed model [Mota2015] for cortical gyrification is very simple, assuming only a self-avoiding cortex of finite thickness experiencing pressures (e.g. exerted by white matter pulling, or by CSF pressure). The offset K, or 'tension term', precisely relates to these pressures, leading us to speculate that subtle changes in K correlate with changes in white matter property [Wang2016, Wang2021]. In the same vein of speculation, the scale-dependence of K shown in this work might therefore be related to different types of white matter that span different length scales, such as superficial vs. deep white matter, or U-fibres vs. major tracts. However, there are also challenges to the axonal tension hypothesis [Xu2010]. Indeed, white matter tension differentials in the developed brain may not explain location of folds, but instead white matter tension may contribute to a whole-brain scale 'pressure' during development that drives the folding process overall.”
Reviewer #3 (Recommendations For The Authors):
Many thanks to the authors for this elegant article. I will only report here on the cosmetics of the article.
We thank the reviewer for their kind words and attention to detail and have made all the suggested changes and revised the paper generally for readability, grammar and spelling.
p2: last line of abstract: 'for a range of conditions in the future'.
p3 l.37: I would not self-describe this method as elegant as this is a subjective property .
p3 l.38: 'that will render' -> I wouldn't use the future here.
p.4 l.59: double spacing before ref [9]?
p.6 l.99: 'approximate a fractal' -> why is 'a' italicized?
p.7 fig.2: I would expect the colours to be detailed in the legend. Are there two data points per species because both hemispheres are treated separately?
p.9 l.134-135: 'similar to and in terms of the universal law 'as valid as' -> please add commas for reading comfort: 'similar to, and, in terms of the universal law, 'as valid as'.
p.9 l. 141: For all the cortices we analysed.
p.9 Fig 3: I find the colours a bit confusing in Figs B and C. I find Fig C a bit confusing: what are all the lines representative of, and more specifically, the two lower lines with a different trajectory?
p.10 l.155: '1̃500' -> '~1500'.
p.13 l. 209: either 'speculate that' of 'wonder if'.
p.14 l.232: 'neuron numbers' -> 'number of neurons'.
p.26 S2 second paragraph: 'gryi' -> 'gyri'.
p.30 l.3: please refrain from starting a sentence with I.e..
p.30 last line before S3.2: 'The algorithmic implementation in MATLAB can be found on Zenodo: TBA' - I guess this is linked to you disclosing the code upon acceptance, but please complete before final submission.
p.34 middle/bottom of page: 'The scheme described in Sec. S3.1' -> double spacing before S3.1?
p.35 l.1: 'We simply replace' -> 'we simply replace' (no capital).
p.36 Fig S5.1: explicit the same colouring of the points and boxes in legend
p.38 Fig. S6.1: briefly describe the use of colours in the legend.
p.39 Fig. S7.1: detail colours in the legend.
p.41 Fig. S7.3: detail colours in the legend.
Tags
Annotators
URL
-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
The following is the authors’ response to the current reviews.
Public Reviews:
Reviewer #1 (Public Review):
The author studies a family of models for heritable epigenetic information, with a focus on enumerating and classifying different possible architectures. The key aspects of the paper are:
-
Enumerate all 'heritable' architectures for up-to 4 constituents.
-
A study of whether permanent ("genetic") or transient ("epigenetic") perturbations lead to heritable changes
-
Enumerated the connectivity of the "sequence space" formed by these heritable architectures
-
Incorporating stochasticity, the authors explore stability to noise (transient perturbations)
-
A connection is made with experimental results on C elegans.
The study is timely, as there is a renewed interest in the last decade in non-genetic, heritable heterogeneity (e.g., from single-cell transcriptomics). Consequently, there is a need for a theoretical understanding of the constraints on such systems. There are some excellent aspects of this study: for instance, the attention paid to how one architecture "mutates" into another. Unfortunately, the manuscript as a whole does not succeed in formalising nor addressing any particular open questions in the field. Aside from issues in presentation and modelling choices (detailed below), it would benefit greatly from a more systematic approach rather than the vignettes presented.
Despite being foundational, this work was systematic in that (1) for the simple architectures modeled using ordinary differential equations (ODEs) with continuity assumptions, parameters that support steady states were systematically determined for each architecture and then every architecture was explored using genetic changes exhaustively, although epigenetic perturbations were not examined exhaustively because of their innumerable variety; and (2) for the more realistic modeling of architectures as Entity-Sensor-Property systems, the behavior of systems with respect to architecture as well as parameter space that lead to particular behaviors (persistence, heritable epigenetic change, etc.) was systematically explored. A more extensive exploration of parameter space that also includes the many ways that the interaction between any two entities/nodes could be specified using an equation is a potentially ever-expanding challenge that is beyond the scope of any single paper.
Specific aspects that remain to be addressed include the application of multiple notions of heritability to real networks of arbitrary size, considering different types of equations for change of each entity/node, and classifying different behavioral regimes for different sets of parameters.
The key contribution of the paper is an articulation of the crucial questions to ask of any regulatory architecture in living systems rather than the addressing of any question that a field has recognized as ‘open’. Specifically, through the exhaustive listing of small regulatory architectures that can be heritable and the systematic analysis of arbitrary Entity-Sensor-Property systems that more realistically capture regulatory architectures in living systems, this work points the way to constrain inferences after experiments on real living systems. Currently, most experimental biologists engaged in reductionist approaches and some systems biologists examining the function or prevalence of network motifs do not explicitly constrain their models for heritability or persistence. It is hoped that this paper will raise awareness in both communities and lead to more constrained models that minimize biases introduced by incomplete knowledge of the network, which is always the case when analyzing living systems.
Terminology
The author introduces a terminology for networks of interacting species in terms of "entities" and "sensors" -- the former being nodes of a graph, and the latter being those nodes that receive inputs from other nodes. In the language of directed graphs, "entities" would seem to correspond to vertices, and "sensors" those vertices with positive indegree and outdegree. Unfortunately, the added benefit of redefining accepted terminology from the study of graphs and networks is not clear.
The Entities-Sensors-Property (ESP) framework is based on underlying biology and not graph theory, making an ESP system not entirely equivalent to a network or graph, which is much less constrained. The terms ‘entity’, ‘sensor’, and ‘property’ were defined and justified in a previous paper (Jose, J R. Soc. Interface, 2020). While nodes of a network can be parsed arbitrarily and the relationship between them can also be arbitrary, entities and sensors are molecules or collections of molecules that are constrained such that the sensors respond to changes in particular properties of other entities and/or sensors. When considered as digraphs, sensors can be seen as vertices with positive indegree and outdegree. The ESP framework can be applied across any scale of organization in living systems and this specific way of parsing interactions also discretizes all changes in the values of any property of any entity. In short, ESP systems are networks, but not all networks are ESP systems. Therefore, the results of network theory that remain applicable for ESP systems need further investigation.
The key utility of the ESP framework is that it is aligned with the development of mechanistic models for the functions of living systems while being consistent with heredity. In contrast, widely analyzed networks like protein-interaction networks, signaling networks, gene regulatory networks, etc., are not always constrained using these principles.
Model
The model seems to suddenly change from Figure 4 onwards. While the results presented here have at least some attempt at classification or statistical rigour (i.e. Fig 4 D), there are suddenly three values associated with each entity ("property step, active fraction, and number"). Furthermore, the system suddenly appears to be stochastic. The reader is left unsure what has happened, especially after having made the effort to deduce the model as it was in Figs 1 through 3. No respite is to be found in the SI, either, where this new stochastic model should have been described in sufficient detail to allow one to reproduce the simulation.
The Supplementary Information section titled ‘Simulation of simple ESP systems’ provides the requested detailed information and revisions to the writing provide the biologically grounded justification for parsing interacting regulators as ESP systems.
Perturbations
Inspired especially by experimental manipulations such as RNAi or mutagenesis, the author studies whether such perturbations can lead to a heritable change in network output. While this is naturally the case for permanent changes (such as mutagenesis), the author gives convincing examples of cases in which transient perturbations lead to heritable changes. Presumably, this is due the the underlying multistability of many networks, in which a perturbation can pop the system from one attractor to another.
Unfortunately, there appears to be no attempt at a systematic study of outcomes, nor a classification of when a particular behaviour is to be expected. Instead, there is a long and difficult-to-read description of numerical results that appear to have been sampled at random (in terms of both the architecture and parameter regime chosen). The main result here appears to be that "genetic" (permanent) and "epigenetic" (transient) perturbations can differ from each other -- and that architectures that share a response to genetic perturbation need not behave the same under an epigenetic one. This is neither surprising (in which case even illustrative evidence would have sufficed) nor is it explored with statistical or combinatorial rigour (e.g. how easy is it to mistake one architecture for another? What fraction share a response to a particular perturbation?)
As an additional comment, many of the results here are presented as depending on the topology of the network. However, each network is specified by many kinetic constants, and there is no attempt to consider the robustness of results to changes in parameters.
The systematic study of all arbitrary regulatory architectures is beyond the scope of this paper and, indeed, beyond the scope of any one paper. Nevertheless 225,000 arbitrary Entity-Sensor-Property systems were systematically explored and collections of parameters that lead to different behaviors provided (e.g., 78,285 are heritable). These ESP systems more closely mimic regulation in living systems than the coupled ODE-based specification of change in a regulatory architecture.
The example questions raised here are not only difficult to answer, but subjective and present a moving target for future studies. One, ‘how easy is it to mistake one architecture for another?’. Mistaking one architecture for another clearly depends on the number of different types of experiments one can perform on an architecture and the resolution with which changes in entities can be measured to find distinguishing features. Two, ‘What fraction share a response to a particular perturbation?’. ‘Sharing a response’ also depends on the resolution of the measurement after perturbation.
DNA analogy
At two points, the author makes a comparison between genetic information (i.e. DNA) and epigenetic information as determined by these heritable regulatory architectures. The two claims the author makes are that (i) heritable architectures are capable of transmitting "more heritable information" than genetic sequences, and (ii) that, unlike DNA, the connectivity (in the sense of mutations) between heritable architectures is sparse and uneven (i.e. some architectures are better connected than others).
In both cases, the claim is somewhat tenuous -- in essence, it seems an unfair comparison to consider the basic epigenetic unit to be an "entity" (e.g., an entire transcription factor gene product, or an organelle), while the basic genetic unit is taken to be a single base-pair. The situation is somewhat different if the relevant comparison was the typical size of a gene (e.g., 1 kb).
Considering every base being the unit of stored information in the DNA sequence results in the maximal possible storage capacity of a genome of given length. Any other equivalence between entity and units within the genome (e.g., 1 kb gene) will only reduce the information stored in the genome.
Nevertheless, the claim was modified to say that the information content of an ESP system can [italics added] be more extensive than the information content of the genome. This accounts for the possibility of an organism that has an inordinately large genome such that maximal information that can be stored in a particular genome sequence exceeds that stored in a particular configuration of all the contents in a cell.
I thank the reviewer for providing further explanation of this misunderstanding in the second round of review, which helps draw future readers to the sections in the paper that discusses this important point (also see response to Recommendations for the authors).
Recommendations for the authors:
Reviewer #1 (Recommendations For The Authors):
I thank the author for their efforts in replying to the comments. I have updated my review accordingly; in particular, I have:
(1) Removed my complaint that Heritability is nowhere defined
(2) Removed issues with the presentation of the ODE model in the supplementary information.
I thank the reviewer for raising these issues and acknowledging the improvements made.
However, given that the manuscript is broadly unchanged from the initial one, many of my prior comments remain justified. Some key points:
(1) The manuscript continues to be difficult to read, for the same reasons as I mentioned when reviewing the paper previously.
(2) The utility of the "ESP" formalism is still unclear.
-
As the author notes, continuous ODEs are of course an idealisation of a system with discrete copy number.
-
However, discussing this is standard fare in any textbook dealing with chemical dynamics and stochastic processes -- see, for instance, the standard textbook by van Kampen.
-
This seems little reason to reject ODEs and implement a poorly defined formalism/simulation scheme.
(3) The author claims that many questions raised are "beyond the scope of this study". Indeed, answering all of these questions are beyond the scope of any one study. However, as I initially wrote, the paper would be much stronger if it focused on a particular problem rather than the many vignettes depicted.
The broad scope of this foundational paper necessitates addressing many issues, which may make it a difficult read for some readers. I hope that future work where each paper focuses on one of the aspects raised here will enable the extensive treatment of limited scope as suggested by the reviewer.
The utility of ODEs is much appreciated and was indeed a computationally efficient way of exploring the vast space of regulatory architectures. As stated in the response to the public reviews, the Entity-Sensors-Property framework provides a biologically grounded way of parsing interacting regulators. This approach is aligned with the development of mechanistic models for the functions of living systems while being consistent with heredity. In contrast, widely analyzed networks like protein-interaction networks, signaling networks, gene regulatory networks, etc., are not always constrained using these principles.
On a final note, on the subject of the comparison with DNA:
Perhaps I have misunderstood something. I simply meant that comparing the "maximal information" with 4 HRAs (12.45 bits) is certainly more than the "maximal information" with 4 basepairs (8 bits), but definitely less than the "maximal information" for four 1-kb genes (4^(4000) combinations, so 8000 bits...)
Perhaps the author means that the growth in information of HRAs is faster than exponential. If so, that should be shown and then remarked on.
For this reason, I maintain my comment that the comparison is tenuous.
This issue was addressed once in the results section and again in the discussion section.
The results section states that “The combinatorial growth in the numbers of HRAs with the number of interactors can thus provide vastly more capacity for storing information in larger HRAs compared to that afforded by the proportional growth in longer genomes.”
The discussion section states that “Despite imposing heritability, regulated non-isomorphic directed graphs soon become much more numerous than unregulated non-isomorphic directed graphs as the number of interactors increase (125 vs. 5604 for 4 interactors, Table 1). With just 10 interactors, there are >3x1020 unregulated non-isomorphic directed graphs [60] and HRAs are expected to be more numerous. This tremendous variety highlights the vast amount of information that a complex regulatory architecture can represent and the large number of changes that are possible despite sparsity of the change matrix (Fig. 3).”
Thus, indeed as the reviewer surmises, the combinatorial explosion in information of HRAs with increases in interacting entities is faster than the proportional growth in information of genome sequence with increases in length.
In summary, I thank the reviewers and editors for their help in improving the paper and would like to make the current manuscript the Version of Record.
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public Review):
The author studies a family of models for heritable epigenetic information, with a focus on enumerating and classifying different possible architectures. The key aspects of the paper are:
-
Enumerate all 'heritable' architectures for up to 4 constituents.
-
A study of whether permanent ("genetic") or transient ("epigenetic") perturbations lead to heritable changes.
-
Enumerated the connectivity of the "sequence space" formed by these heritable architectures.
-Incorporating stochasticity, the authors explore stability to noise (transient perturbations). - A connection is made with experimental results on C elegans.
The study is timely, as there has been a renewed interest in the last decade in nongenetic, heritable heterogeneity (e.g., from single-cell transcriptomics). Consequently, there is a need for a theoretical understanding of the constraints on such systems. There are some excellent aspects of this study: for instance:
-
The attention paid to how one architecture "mutates" into another, establishing the analogue of a "sequence space" for network motifs (Fig 3).
-
The distinction is drawn between permanent ("genetic") and transient ("epigenetic") perturbations that can lead to heritable changes.
-
The interplay between development, generational timescales, and physiological time (as in Fig. 5).
I thank the reviewer for highlighting these aspects of the work.
The manuscript would be very interesting if it focused on explaining and expanding these results. Unfortunately, as a whole, it does not succeed in formalising nor addressing any particular open questions in the field. Aside from issues in presentation and modelling choices (detailed below), it would benefit greatly from a more systematic approach rather than the vignettes presented.
This first paper is foundational and therefore cannot be expected to solve all aspects of the problem of heredity. The work was nevertheless systematic in that (1) for the simple architectures modeled using ordinary differential equations (ODEs) with continuity assumptions, parameters that support steady states were systematically determined for each architecture and then every architecture was explored using genetic changes exhaustively, although epigenetic perturbations were not examined exhaustively because of their wide variety; and (2) for the more realistic modeling of architectures as Entity-Sensor-Property systems, the behavior of systems with respect to architecture as well as parameter space that lead to particular behaviors (persistence, heritable epigenetic change, etc.) was systematically explored. A more extensive exploration of parameter space that also includes the many ways that the interaction between any two entities/nodes could be specified using an equation is a potentially ever-expanding challenge that is beyond the scope of any single paper (see response to additional comments below).
Specific aspects that remain to be addressed include the application of multiple notions of heritability to real networks of arbitrary size, considering different types of equations for change of each entity/node, and classifying different behavioral regimes for different sets of parameters. As is evident from this list of combinatorial possibilities, the space to be explored is vast and beyond the scope of this foundational paper.
The key contribution of the paper is an articulation of the crucial questions to ask of any regulatory architecture in living systems rather than the addressing of any question that a field has recognized as ‘open’. Specifically, through the exhaustive listing for small regulatory architectures that can be heritable and the systematic analysis of arbitrary Entity-Sensor-Property systems that more realistically capture regulatory architectures in living systems, this work points the way to constrain inferences after experiments on real living systems. Currently, most experimental biologists engaged in reductionist approaches and some systems biologists examining the function or prevalence of network motifs do not explicitly constrain their models for heritability or persistence. It is hoped that this paper will raise awareness in both communities and lead to more constrained models that minimize biases introduced by incomplete knowledge of the network, which is always the case when analyzing living systems.
Terminology
The author introduces a terminology for networks of interacting species in terms of "entities" and "sensors" -- the former being nodes of a graph, and the latter being those nodes that receive inputs from other nodes. In the language of directed graphs, "entities" would seem to correspond to vertices, and "sensors" those vertices with positive indegree and outdegree. Unfortunately, the added benefit of redefining accepted terminology from the study of graphs and networks is not clear.
The Entities-Sensors-Property (ESP) framework is based on underlying biology and not graph theory, making an ESP system not entirely equivalent to a network or graph, which is much less constrained. The terms ‘entity’, ‘sensor’, and ‘property’ were defined and justified in a previous paper (Jose, J R. Soc. Interface, 2020). While nodes of a network can be parsed arbitrarily and the relationship between them can also be arbitrary, entities and sensors are molecules or collections of molecules that are constrained such that the sensors respond to changes in particular properties of other entities and/or sensors. When considered as digraphs, sensors can be seen as vertices with positive indegree and outdegree. The ESP framework can be applied across any scale of organization in living systems and this specific way of parsing interactions also discretizes all changes in the values of any property of any entity. In short, ESP systems are networks, but not all networks are ESP systems. Therefore, the results of network theory that remain applicable for ESP systems need further investigation. This justification is now repeated in the paper.
The key utility of the ESP framework is that it is aligned with the development of mechanistic models for the functions of living systems while being consistent with heredity. In contrast, widely analyzed networks like protein-interaction networks, signaling networks, gene regulatory networks, etc., are not always constrained using these principles. In addition, the language of digraphs where sensors can be seen as vertices with positive indegree and outdegree has been also added to aid readers who are familiar with graph theory.
Heritability
The primary goal of the paper is to analyse the properties of those networks that constitute "heritable regulatory architectures". The definition of heritability is not clearly stated anywhere in the paper, but it appears to be that the steady-state of the network must have a non-zero expression of every entity. As this is the heart of the paper, it would be good to have the definition of heritable laid out clearly in either the main text or the SI.
I have now defined the term as used in this paper early, which is indeed as surmised by the reviewer simply the preservation of the architecture and non-zero levels of all entities. I have also highlighted additional notions of heredity that are possible, which will be the focus of future work. These can range from precise reproduction of the concentration and the localization of every entity to a subset of the entities being reproduced with some error while the rest keep varying from generation to generation (as illustrated in Fig. 2 of Jose, BioEssays, 2018). Importantly, it is currently unclear which of these possibilities reflects heredity in real living systems.
Model
As described in the supplementary, but not in the main text, the author first chooses to endow these networks with simple linear dynamics; something like $\partial_t \vec{x} = A x - T x$, where the vector $x$ is the expression level of each entity, $A$ has the structure of the adjacency matrix of the directed graph, and $T$ is a diagonal matrix with positive entries that determines the degradation or dilution rate of each entity. From a readability standpoint, it would greatly aid the reader if the long list of equations in the SI were replaced with the simple rule that takes one from a network diagram to a set of ODEs.
I have abridged the description by eliminating the steady state expression for every HRA as suggested and simply pointed to the earlier version of the paper for those readers who might prefer the explicit derivations of these simple expressions. An overview is now provided for going from any network diagram to a set of ODEs.
The implementation of negative regulation is manifestly unphysical if the "entities" represent the expression level of, say, gene products. For instance, in regulatory network E, the value of the variable z can go negative (for instance, if the system starts with z= and y=0, and x > 0).
Negative values for any entity were avoided in simulations by explicitly setting all such values to zero. This constraint has been added as a note in the section describing the equations for the change of each node/entity in each regulatory network. Specifically, the levels of each entity/sensor was set to zero during any time step when the computed value for that entity/sensor was less than zero. This bounding of the function allows for any approach to zero while avoiding negative values. I apologize for the omission of this constraint from the supplemental material in the last submission. This constraint was used in all the simulations and therefore this change does not affect any of the results presented. In this way, it is ensured that the presence of negative regulation does not lead to negative values.
Formally, the promotion or inhibition of an entity or sensor can be modeled using any function that is either increasing (for promotion) or decreasing (for inhibition). This diversity of possibilities is one of the challenges that prevents exhaustive exploration of all functions. In fact, the use of ODEs after assuming a continuous function is an idealization that facilitates understanding of general principles but is not in keeping with the discreteness of entities or step changes in their values (amount, localization, etc.) observed in living systems. Other commonly used continuous functions include Hill functions for the rate of production of y given as xn/(k + xn) for x activating y, which increases to ~1 as x increases, or given as k/(k + xn) for x inhibiting y, which decreases to ~0 as x increases. Increasing values of ‘n’ result in steeper sigmoidal curves. In reality, levels of all entities/sensors are expected to be discretized by measurement in living systems and the form of the function for any regulation needs empirical measurement in vivo (see response to comment below).
The model seems to suddenly change from Figure 4 onwards. While the results presented here have at least some attempt at classification or statistical rigour (i.e. Fig 4 D), there are suddenly three values associated with each entity ("property step, active fraction, and number"). Furthermore, the system suddenly appears to be stochastic. The reader is left unsure of what has happened, especially after having made the effort to deduce the model as it was in Figs 1 through 3. No respite is to be found in the SI, either, where this new stochastic model should have been described in sufficient detail to allow one to reproduce the simulation.
While ODEs are easier to simulate and understand, they are less realistic as explained above. I have now added more explanation justifying the need for the subsequent simulation of Entity-Sensor-Property systems. I have also expanded the information provided for each aspect of the model (previously outlined in Fig. 4A and detailed within the code) in a Supplementary Information section titled ‘Simulation of simple ESP systems’.
Perturbations
Inspired especially by experimental manipulations such as RNAi or mutagenesis, the author studies whether such perturbations can lead to a heritable change in network output. While this is naturally the case for permanent changes (such as mutagenesis), the author gives convincing examples of cases in which transient perturbations lead to heritable changes. Presumably, this is due the the underlying mutlistability of many networks, in which a perturbation can pop the system from one attractor to another.
Unfortunately, there appears to be no attempt at a systematic study of outcomes, nor a classification of when a particular behaviour is to be expected. Instead, there is a long and difficult-to-read description of numerical results that appear to have been sampled at random (in terms of both the architecture and parameter regime chosen). The main result here appears to be that "genetic" (permanent) and "epigenetic" (transient) perturbations can differ from each other -- and that architectures that share a response to genetic perturbation need not behave the same under an epigenetic one. This is neither surprising (in which case even illustrative evidence would have sufficed) nor is it explored with statistical or combinatorial rigour (e.g. how easy is it to mistake one architecture for another? What fraction share a response to a particular perturbation?)
The systematic study of all arbitrary regulatory architectures is beyond the scope of this paper and, as stated earlier, beyond the scope of any one paper. Nevertheless 225,000 arbitrary Entity-Sensor-Property systems were systematically explored and collections of parameters that lead to particular behaviors provided (e.g., 78,285 are heritable). These ESP systems more closely mimic regulation in living systems than the coupled ODE-based specification of change in a regulatory architecture.
The example questions raised here are not only difficult to answer, but subjective and present a moving target for future studies. One, ‘how easy is it to mistake one architecture for another?’. Mistaking one architecture for another clearly depends on the number of different types of experiments one can perform on an architecture and the resolution with which changes in entities can be measured to find distinguishing features. Two, ‘What fraction share a response to a particular perturbation?’. ‘Sharing a response’ also depends on the resolution of the measurement of entities after perturbation.
As an additional comment, many of the results here are presented as depending on the topology of the network. However, each network is specified by many kinetic constants, and there is no attempt to consider the robustness of results to changes in parameters.
The interpretations presented are conservative determinations of heritability based on the topology of the architecture. In other words, architectures that can be heritable for some set of parameters. Of course, parameter sets can be found that make any regulatory architecture not heritable. As stated earlier, exploring all parameters for even one architecture is beyond the scope of a single study because of the infinitely many ways that the interaction between any two entities can be specified.
DNA analogy
At two points, the author makes a comparison between genetic information (i.e. DNA) and epigenetic information as determined by these heritable regulatory architectures. The two claims the author makes are that (i) heritable architectures are capable of transmitting "more heritable information" than genetic sequences, and (ii) that, unlike DNA, the connectivity (in the sense of mutations) between heritable architectures is sparse and uneven (i.e. some architectures are better connected than others).
In both cases, the claim is somewhat tenuous -- in essence, it seems an unfair comparison to consider the basic epigenetic unit to be an "entity" (e.g., an entire transcription factor gene product, or an organelle), while the basic genetic unit is taken to be a single base-pair. The situation is somewhat different if the relevant comparison was the typical size of a gene (e.g., 1 kb).
Considering every base being the unit of stored information in the DNA sequence results in the maximal possible storage capacity of a genome of given length. Any other equivalence between entity and units within the genome (e.g., 1 kb gene) will only reduce the information stored in the genome.
Nevertheless, the claim has been modified to say that the information content of an ESP system can [italics added] be more extensive than the information content of the genome. This accounts for the possibility of an organism that has an inordinately large genome such that maximal information that can be stored in a particular genome sequence exceeds that stored in a particular configuration of all the contents in a cell.
Reviewer #2 (Public Review):
Summary:
This manuscript uses an interesting abstraction of epigenetic inheritance systems as partially stable states in biological networks. This follows on previous review/commentary articles by the author. Most of the molecular epigenetic inheritance literature in multicellular organisms implies some kind of templating or copying mechanisms (DNA or histone methylation, small RNA amplification) and does not focus on stability from a systems biology perspective. By contrast, theoretical and experimental work on the stability of biological networks has focused on unicellular systems (bacteria), and neglects development. The larger part of the present manuscript (Figures 1-4) deals with such networks that could exist in bacteria. The author classifies and simulates networks of interacting entities, and (unsurprisingly) concludes that positive feedback is important for stability. This part is an interesting exercise but would need to be assessed by another reviewer for comprehensiveness and for originality in the systems biology literature. There is much literature on "epigenetic" memory in networks, with several stable states and I do not see here anything strikingly new.
The key utility of the initial part of the paper is the exhaustive enumeration of all small heritable regulatory architectures. The implications for the abundance of ‘network motifs’ and more generally any part of a network proposed to perform a particular function is that all such parts need to be compatible with heredity. This principle is generally not followed in the literature, resulting in incomplete networks being interpreted as having motifs or modules with autonomous function. Therefore, while the need for positive feedback for stability is indeed obvious, it is not consistently applied by all. For example, the famous synthetic circuit ‘the repressilator’ (Elowitz and Leibler, “A synthetic oscillatory network of transcriptional regulators”, Nature, 2000), which is presented as an example of ‘rational network design’, has three transcription factors that all sequentially inhibit the production of another transcription factor in turn forming a feedback loop of inhibitory interactions. Therefore, the contributions of the factors that promote the expression of each entity is unknown and yet essential for heritability. The comprehensive listing of the heritable regulatory architectures that are simple provide the basis for true synthetic biology where the contributing factors for observed behavior of the network are explicitly considered only after constraining for heredity. Using this principle, the minimal autonomous architecture that can implement the repressilator is the HRA ‘Z’ (Fig. 1).
An interesting part is then to discuss such networks in the framework of a multicellular organism rather than dividing unicellular organisms, and Figure 5 includes development in the picture. Finally, Figure 6 makes a model of the feedback loops in small RNA inheritance in C. elegans to explain differences in the length of inheritance of silencing in different contexts and for different genes and their sensitivity to perturbations. The proposed model for the memory length is distinct from a previously published model by Karin et al. (ref 49).
I thank the reviewer for appreciating this aspect of the paper.
Strengths:
A key strength of the manuscript is to reflect on conditions for epigenetic inheritance and its variable duration from the perspective of network stability.
I thank the reviewer for appreciating the importance of the overall topic.
Weaknesses:
- I found confusing the distinction between the architecture of the network and the state in which it is. Many network components (proteins and RNAs) are coded in the genome, so a node may not disappear forever.
I have added language to clarify the many states of a network versus its architecture (also illustrated in Fig. 4 for ESP systems). Even loss of expression below a threshold can lead to permanent loss if there is not sufficient noise to induce re-expression. For example, consider the simple case of a transcription factor that binds to its own promoter, requiring 10 molecules for the activation of the promoter and thus production of more of the same transcription factor. If an epigenetic change (e.g., RNA interference) reduces the levels to fewer than 10 molecules and if the noise in the system never results in the numbers of the transcription factor increasing beyond 10, the transcription factor has been effectively lost permanently. In this way, reduction of a regulator can lead to permanent change despite the presence of the DNA. Many papers in the field of RNA silencing in C. elegans have provided strong experimental evidence to support this assertion.
- From the Supplementary methods, the relationship between two nodes seems to be all in the form of dx/dt = Kxy . Y, which is just one way to model biological reactions. The generality of the results on network architectures that are heritable and robust/sensitive to change is unclear. Other interactions can have sigmoidal effects, for example. Is there no systems biology study that has addressed (meta)stability of networks before in a more general manner?
Indeed, the relationship between any two entities can in principle be modeled using any function. Extensive exploration of the behavior of any regulatory architecture – even the simplest ones – require simplifications. For example, early work by Stuart Kauffman explored Boolean networks (see ref. 10 in the paper for history and extensive explanations). However, allowing all possible ways of specifying the interactions between components of a network makes analysis both a computational and conceptual challenge.
- Why is auto-regulation neglected? As this is a clear cause of metastable states that can be inherited, I was surprised not to find this among the networks.
Auto-regulation in the sense of some molecule/entity ultimately leading to the production of more of itself is present in every heritable regulatory architecture. Specifically, all auto-regulatory loops rely on a sequence of interactions between two or more kinds of molecules. For example, a transcription factor (TF) binding to the promoter of its own gene sequence, resulting in the production of more TF protein is a positive feedback loop that relies on many interacting factors (transcription, translation, nuclear import, etc.) and can be considered as ‘auto-regulation’ as it is sometimes referred to in the literature. In this sense, every HRA (A through Z) includes ‘auto-regulation’ or more appropriately positive feedback loops. For example, in the HRA ‘A’, x ‘auto-regulates’ itself via y.
- I did not understand the point of using the term "entity-sensor-property". Are they the same networks as above, now simulated in a computer environment step by step (thus allowing delays)?
Please see response to the other reviewer regarding the need for the Entity-SensorProperty framework and how it is distinct from generic networks. Briefly, the ODE-based simple networks, while easy to analyze, are not realistic because of the assumptions of continuity. In contrast ESP systems are more realistic with measurement discretizing changes in property values as is expected in real living systems.
- The final part applies the network modeling framework from above to small RNA inheritance in C. elegans. Given the positive feedback, what requires explanation is how fast the system STOPs small RNA inheritance. A previous model (Karin et al., ref. 49) builds on the fact that factors involved in inheritance are in finite quantity hence the different small RNAs "compete" for amplification and those targeting a given gene may eventually become extinct.
The present model relies on a simple positive feedback that in principle can be modulated, and this modulation remains outside the model. A possibility is to add negative regulation by factors such as HERI-1, that are known to limit the duration of the silencing.
The duration of silencing differs between genes. To explain this, the author introduces again outside the model the possibility of piRNAs acting on the mRNA, which may provide a difference in the stability of the system for different transcripts. At the end, I do not understand the point of modeling the positive feedback.
The previous model (Karin et al., Cell Systems, 2023) can describe populations of genes that are undergoing RNA silencing but cannot explain the dynamics of silencing particular genes. Furthermore, this model also cannot explain cases of effectively permanent silencing of genes that have been reported (e.g., Devanapally et al., Nature Communications, 2021 and Shukla et al., Current Biology, 2021). Finally, the observations of susceptibility to, recovery from, and even resistance to trans silencing (e.g., Fig. 5a in Devanapally et al., Nature Communications, 2021) require an explanation that includes modulation of the HRDE-1-dependent positive feedback loop that maintains silencing across generations.
The specific qualitative predictions regarding the relationship between piRNA-mediated regulation genome-wide and HRDE-1-dependent silencing of a particular gene across generations could guide the discovery of potential regulators of heritable RNA silencing. The equations (4) and (5) in the paper for the extent of modulation needed for heritable epigenetic change provide specific quantitative predictions that can be tested experimentally in the future. I have also revised the title of the section to read ‘Tuning of positive feedback loops acting across generations can explain the dynamics of heritable RNA silencing in C. elegans’ to emphasize the above points.
- From the initial analysis of abstract networks that do not rely on templating, I expected a discussion of possible examples from non-templated systems and was a little surprised by the end of the manuscript on small RNAs.
The heritability of any entity relies on regulatory interactions regardless of whether a templated mechanism is also used or not. For example, DNA replication relies on the interactions between numerous regulators, with only the sequence being determined by the template DNA. The field of small RNA-mediated silencing facilitates analysis of epigenetic changes at single-gene resolution (Chey and Jose, Trends in Genetics, 2022). It is therefore likely to continue to provide insights into heritable epigenetic changes and how they can be modulated. Unfortunately, there are currently no known cases of epigenetic inheritance where the role of any templated mechanism has been conclusively excluded. Future research will improve our understanding of epigenetic states and their modulation in terms of changes in positive feedback loops as proposed in this study and potentially lead to the discovery of such mechanisms that act entirely independent of any template-dependent entity.
Recommendations for the authors:
I thank the reviewers for their specific suggestions to improve the paper.
Reviewer #1 (Recommendations For The Authors):
The paper has many long paragraphs that attempt to explain results, make illustrations, and give intuition. Unfortunately, these are difficult to read. It would aid the reader greatly if these were, say, converted into cartoons (even if only in the SI), or made more accessible in some other way.
I agree with the importance of making the material accessible to readers in multiple ways. I have now added a figure with schematics in the SI titled ‘Illustrations of key concepts’ (new Fig. S2), which collects concepts that are relevant throughout the paper and might aid some readers.
The bulk of the supplementary is currently a collection of elementary mathematics results: to whit, pages 26 to 33 of the combined manuscript carry no more information than a quick description of the general model and the diagrams in Fig 1. Similarly, pages 34 to 39 (non-zero dilution rate), and pages 39 through 58 (response to permanent changes) each express a trivial mathematical point that is more than sufficiently made with one illustrative example.
I agree with the reviewer and have condensed these pages as suggested. I have added a pointer to the earlier version as containing further details for the readers who might prefer the explicit listing of these equations.
Overall, the paper appears to be a collection of numerical results obtained from different models, united by uncertain terminology that is not fully defined in this paper. The most promising aspects of the paper lie either in (a) combinatorially complete enumeration of all regulatory architectures, or (b) relating experimental manipulations in C. elegans to possible underlying regulatory architectures. Focusing on one or the other might improve the readability of the paper.
The two sections of the paper are complementary and when presented together help with the integration of concepts rather than the siloed pursuit of theory versus experimental analysis. When this work was presented at meetings before submission, it was clear that different researchers appreciated different aspects. This divergence is also apparent in the two reviews, with each reviewer appreciating different aspects. I have repeated the definitions and justifications from the earlier paper (Jose, J R Soc Interface, 2020) to provide a more fluid transition between the two complementary sections of the paper. Knowing both sides could aid in the development of models that are not only consistent with measurable quantities (e.g., anything that can be considered an entity) but are also logically constrained (e.g., entities matched with sensors while avoiding any entities that do not have a source of production – i.e., avoiding nodes with indegree = 0).
However, having said that many results of these types are well-known in models of regulatory networks, and it is unclear what precisely warrants the new framework that the author is proposing. Indeed, it would be good to understand in what way the framework here is novel, and how it is distinguished from prior studies of regulatory networks.
The key novelty of the work is the consideration of heritability for any regulation. With the explicit definition of the heritability for a regulatory architecture and the acknowledgement that there can be more than one notion of heredity, this paper now sets the foundation for examining many real networks in this light. I hope that the added justifications for the current framework in the revised paper strengthen these arguments. Future literature reviews on networks in general and how they address heritability or persistence will better define the prevalence of these considerations. Currently, most experimental biologists engaged in reductionist approaches and some systems biologists examining the function or prevalence of network motifs do not explicitly constrain their models for heritability or persistence. It is hoped that this work will raise awareness in both communities and lead to more constrained models that acknowledge incomplete knowledge of the network, which is always the case when analyzing living systems.
Reviewer #2 (Recommendations For The Authors):
Minor points/clarity
- page 1 line 57: "transgenerational waveforms that preserve form and function" is unclear.
This phrase was expanded upon in a previous paper (Jose, BioEssays, 2020). I have now added more explanation in this paper for completeness. The section now reads ‘For example, the localization and activity of many kinds of molecules are recreated in successive generations during comparable stages [1-3]. These recurring patterns can change throughout development such that following the levels and/or localizations of each kind of molecule over time traces waveforms that return in phase with the similarity of form and function across generations [2].’
- page 7 line 3-6: the sentence has an ambiguous structure.
I have now edited this long sentence to read as follows: ‘For systematic analysis, architectures that could persist for ~50 generations without even a transient loss of any entity/sensor were considered HRAs. Each HRA was perturbed (loss-of-function or gain-of-function) after five different time intervals since the start of the simulation (i.e., phases). The response of each HRA to such perturbations were compared with that of the unperturbed HRA.’
- page 9 lines 25-27: the sentence is convoluted: are you defining epigenetic inheritance?
I have simplified this sentence describing prior work by others (Karin et al., Cell Systems, 2023) and moved a clause to the subsequent sentence. This section now reads: ‘Recent considerations of competition for regulatory resources in populations of genes that are being silenced suggest explanations for some observations on RNA silencing in C. elegans [49]. Specifically, based on Little’s law of queueing, with a pool of M genes silenced for an average duration of T, new silenced genes arise at a rate that is given by M = T’. I have also provided more context by preceding this section with: ‘Although the release of shared regulators upon loss of piRNA-mediated regulation in animals lacking PRG-1 could be adequate to explain enhanced HRDE-1-dependent transgenerational silencing initiated by dsRNA in prg-1(-) animals, such a competition model alone cannot explain the observed alternatives of susceptibility, recovery and resistance (Fig. 6A).’
- page 13 lines 51-53. This last sentence of the discussion is ambiguous/unclear.
I have now rephrased this sentence to read: ‘This pathway for increasing complexity through interactions since before the origin of life suggests that when making synthetic life, any form of high-density information storage that interacts with heritable regulatory architectures can act as the ‘genome’ analogous to DNA.’
- Figure 2: the letters in the nodes are hard to read; the difference between full and dotted lines in the graphs also.
I have enlarged the nodes and widened the gap in the dotted lines to make them clearer. I have also similarly edited Fig. 1 and Fig. S3 to Fig. S9.
-
-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
The following is the authors’ response to the original reviews.
Reviewer #1 (Recommendations For The Authors):
(1) More explanation/description of Fig 3C and 3D would be helpful for readers, including the color code of 3D and black lines shown in both panels.
We have added more description to the legend of Figure 3, and we have used the same color code as in Figure 2, which we now specifically note in the figure legend as well.
(2) Differences between cranial and trunk NCC could be experimentally shown or discussed. Fig 4C shows some differences between these two populations, but in situ, results using Dlc1/Sp5/Pak3 probes in the trunk region may be informative, like Fig 5 supplement 2 for cranial NCCs.
This is an important point. The focus of our study was on cranial neural crest cells, and the single cell sequencing data is therefore truly reflective of only cranial neural crest cells. We have not functionally tested for the roles of Dlc1/Sp5/Pak3 in trunk neural crest cells, however, based on the expression and loss-of-function phenotypes of Sp5 or Pak3 knockout mice, we predict they individually may not play a significant role. It remains plausible that Dlc1 could play an important role in the delamination of trunk neural crest cells, but we have not tested that definitively. Nonetheless, Sabbir et al 2010 showed in a gene trap mouse mutant that Dlc1 is expressed in trunk neural crest cells. Regarding the similarities and differences between cranial and trunk neural crest cells as noted by the reviewer with respect to Figure 4, it’s important to recognize the temporal differences illustrated in Figure 4. Neural crest cell delamination proceeds in a progressive wave from anterior to posterior, but also that the analysis was designed to quantify cell cycle status before and during neural crest cell delamination. We have compared cranial and trunk neural crest cells in more detail in the discussion and also speculate what might happen in the trunk based on what we know from other species.
(3) Discussion can be added about the potential functions of Dlc1 for NCC migration and/or differentiation based on available info from KO mice.
We have added specific details regarding the published Dlc1 knockout mouse phenotype to the discussion, particularly with respect to the craniofacial anomalies which included frontonasal prominence and pharyngeal arch hyperplasia, and defects in neural tube closure and heart development. Although the study didn’t investigate the mechanisms underpinning the Dlc1 knockout phenotype, the craniofacial morphological anomalies would be consistent with a deficit in neural crest cell delamination reducing the number of migrating neural crest cells, as we observed in our Dlc1 knockdown experiments.
Reviewer #2 (Recommendations For The Authors):
The authors used the (Tg(Wnt1-cre)11Rth Tg(Wnt1-GAL4)11Rth/J) line but work from the Bush lab (see Lewis et al., 2013) has demonstrated fully penetrant abnormal phenotypes that affect the midbrain neuroepithelium, increased CyclinD1 expression and overt cell proliferation as measured by BrdU incorporation. The authors should explain why they used this mouse line instead of the Wnt1-Cre2 mice (129S4-Tg(Wnt1-cre)1Sor/J) in the Jackson Laboratory (which lacks the phenotypic effects of the original Wnt1-Cre line), or a "Cre-only" control, or at a minimum explain the steps they took to ensure there were no confounding effects on their study, especially since cell proliferation was a major outcome measure.
This is an important point, and we thank the reviewer for raising it. Yes, it has been reported that the original Wnt1Cre mice exhibit a midbrain phenotype (Ace et al. 2013). However, it has also been noted that Wnt1Cre2 can exhibit recombination in the male germline leading to ubiquitous recombination (Dinsmore et al., 2022). Therefore, to avoid any potential for bias, we used an equal number of cells derived from the Wnt1 and F10N transgenic line embryos in our scRNA-seq, and this included multiple non-Cre embryos. Our scRNA-seq analysis was therefore not dependent upon Wnt1-Cre, but also because we used whole heads not fluorescence sorted cells. However, Wnt1-Cre lineage tracing was advantageous from a computational perspective to help define cells that were premigratory and migratory in concert with Mef2c-lacZ ¬based on their expression of YFP, LacZ or both. We note these specifics more clearly in the methods.
The Results section (line 122) states that scRNA-seq was performed on dissociated cranial tissues but the Methods section (lines 583-584) implies that whole E8.5 mouse embryos were dissociated. Which was dissociated, whole embryos or just cranial tissues? Obviously, the latter would be a better strategy to enrich for cranial neural crest, but the authors also examine the trunk neural crest. This should be clarified in the text.
We apologize that some of the details regarding the tissue isolation were confusing and we have clarified this in the methods and the text. For the record, after isolating E8.5 embryos, we then dissected the head from those embryos, and performed scRNA-seq on dissociated cranial tissues. As the reviewer correctly noted, this approach strategically enriches for cranial neural crest cells.
The authors do not justify why they chose a knockdown strategy, which has its limitations including its systemic injection into the amniotic cavity, its likely global and more variable effects, and its need to be conducted in culture. Why the authors did not instead use a Wnt1-Cre-mediated deletion of Dlc1, which would have been "cleaner" and more specific to the neural crest, is not clear (maybe so they could specifically target different Dcl1 isoforms?). Also, the authors use Sox10 as a marker to count neural crest cells, but Sox10 may only label a subset of neural crest cells and thus some unaffected lineages may not have been counted. The authors should mention what is known about the regulation of Dcl1 by Sox10 in the neural crest. Although the data are persuasive, a second marker for counting neural crest cells following knockdown would make the analysis more robust. Can the authors explain why they did not simply use the Mef2c-F10N-LacZ line and count LacZ-positive cells (if fluorescence signal was required for the quantification workflow, then could they have used an anti-beta Galactosidase antibody to label cells)?
We thank the reviewer for raising these important considerations. It has previously been noted that although Wnt1-Cre is the gold standard for conditional deletion analyses in neural crest cell development, especially migration and differentiation, it is not a good tool for functional studies of the specification and delamination of neural crest cells due to the timing of Wnt1 expression and Cre activation and excision (see Barriga et al., 2015). Therefore, we chose a knockdown strategy instead, and also because it allows us to more rapidly evaluate gene function. We agree that there are limitations to the approach with respect to variability, however, this is outweighed by the ability to repeatedly perform the knockdown at multiple and more relevant temporal stages such as E7.5 (which is prior to the onset of Wnt1-Cre activity), as well as target different isoforms, and also treat large numbers of embryos for quantitative analyses. The advantage of using Sox10 as a marker for counting neural crest cells is that at the time of analysis, cranial neural crest cells are still migrating towards the frontonasal prominences and pharyngeal arches, and the overwhelming majority of these cells are Sox10 positive. Moreover, we can therefore assay every Dlc1 knockdown embryo for Sox10 expression and count the number of migrating neural crest cells. The limitation of using the Mef2c-F10N-LacZ line is that this transgenic line is maintained as a heterozygote, and thus only half the embryos in a litter could reasonably be expected to be lacZ+. But combining Sox10 and Mef2c-F10N-LacZ fluorescent immunostaining for similar analyses in the future is a great idea.
Reviewer #3 (Recommendations For The Authors):
The putative intermediate cells differentially express mRNAs for genes involved in cell adhesion, polarity, and protrusion relative to bona fide premigratory cells (Fig. 2E). This is persuasive evidence, but only differentially expressed genes are shown. Discussing those markers that have not yet changed, e.g. Cdh1 or Zo1 (?), would be instructive and help to clarify the order of events.
We thank the author for this suggestion and we have provided more detail about adherens junction and tight junctions. Cdh1 is not expressed, and although Myh9 and Myh10 are expressed, we did not detect any significant changes. ZO1 is a tight junction protein encoded by the gene Tjp1, which along with other tight junctions protein encoding genes, is downregulated in intermediate NCCs as shown in the Figure 2E.
It is unclear whether the two putative intermediate state clusters differ other than their stage of the cell cycle. Based on the trajectory analysis in Fig. 3C-D, the authors state that these two populations form simultaneously and independently but then merge into a single population. However, without further differential expression, it seems more plausible that they represent a single population that is temporarily bifurcated due to cell cycle asynchrony.
We have addressed the cell cycle question in the discussion by noting that while it is possible the transition states represent a single population that is temporarily bifurcated due to cell cycle asynchrony, if this were true, then we should expect S phase inhibition to eliminate both transition state groups. Instead, our trajectory analyses suggest that the transition states are initially independent, and furthermore, S phase inhibition did not affect delamination of the other population of neural crest cells.
The authors do not present an in-depth comparison of these neural crest intermediate states to previously reported cancer intermediate states. This analysis would reveal how similar the signatures are and thus how extrapolatable these and future findings in delaminating neural crest are to different types of cancer.
We have also added more detail to the discussion to address the potential for similarities and differences in neural crest intermediate states compared to previously reported cancer intermediate states. The challenge, however, is that none of the cancer intermediate states have been characterized at a molecular level. Nonetheless, with the limited molecular markers available, we have not identified any similarities so far, but our datasets are now available for comparison with future cancer EMP datasets.
The reduction in SOX10+ cells may be in part or wholly attributable to inhibition of proliferation AFTER delamination. Showing that there are premigratory NCCs in G2/M at ~E8.0 would bolster the argument that this population is present from the earliest stages.
The presence of premigratory neural crest cells in G2/M is shown by the scRNA-seq data and cell cycle staining data in the neural plate border.
Lines 248-249: The pseudo-time analysis in Fig 3C/D does indicate that the two most mature cell clusters (pharyngeal arch and frontonasal mesenchyme) may arise from common or similar migratory progenitors. However, given the decades of controversy about fate restriction of neural crest cells, the statement that "EMT intermediate NCC and their immediate lineages are not fate restricted to any specific cranial NCC derivative at this timepoint" should be toned down so as to not give the impression that they have identified common progenitors of ectomesenchyme and neuro/glial/pigment derivatives.
We appreciate this comment, because as the reviewer noted, there has been considerable literature and debate about the fate restriction and plasticity of neural crest cells, and indeed we did not intend to imply we have identified common progenitors of ectomesenchyme and neuro/glial/pigment derivatives. That can only be truly functionally demonstrated by clonal lineage tracing analyses. Rather, we interpret our pseudo-time analyses to indicate that irrespective of cell cycle status at the time of delamination, these two populations come together with equivalent mesenchymal and migratory properties, but in the absence of fate determination in the collective of cells. This does not mean that individual cells are common progenitors of both ectomesenchyme and neuro/glial/pigment derivatives. The nuance is important, and we address this more carefully in the text.
Lines 320-321: "...this overlap in expression was notably not observed in older embryos in areas where EMT had concluded". It is unclear whether the markers no longer overlap in older embryos (i.e. segregate to distinct populations) or are simply no longer expressed.
The data in Figure 5 demonstrates the dynamic and overlapping expression of Dlc1, Sp5 and Pak3 in the different clusters of cells as they transition from being neuroepithelial to mesenchymal. In contrast to Sp5 and Pak3, Dlc1 is not expressed by premigratory neural crest cells but is expressed at high levels in all EMT intermediate stage neural crest cells. Later as Dlc1 continues to be expressed in migrating neural crest cells, Pak3 and Sp5 are downregulated. But the absence of overlapping expression in the dorsolateral neural plate at the conclusion of EMT coincides with their downregulation in that territory.
In the final results section on Dlc1, the previously published mutant mouse lines are referenced as having "craniofacial malformation phenotypes". The lack of detail given on what those malformations are (assuming descriptions are available) makes the argument that they may be related to insufficient delamination less persuasive. The degree of knockdown correlates so well with the percentage reduction in migratory neural crest (Fig. 6) that one would imagine a null mutant to have a very severe phenotype.
The inference from the reviewer is correct and indeed Dlc1 null mutant mice do have a severe phenotype. We have added more specific details regarding the craniofacial and other phenotypes of the Dlc1 mutant mice to the discussion. Of note the frontonasal prominences and the pharyngeal arches are hypoplastic in E10.5 Dlc1 mutant embryos, which would be consistent with a neural crest cell deficit. Although a deficit in neural crest cells can be caused my multiple distinct mechanisms, our Dlc1 knockdown analyses suggest that the phenotype is due to an effect on neural crest cell delamination which diminishes the number of migrating neural crest cells.
Use the same y-axis for Fig. 4C/D
This has been corrected.
Fig. 6C: Please note in the panel which gene is being measured by qPCR
This has been corrected to denoted Dlc1.
Lines 108-117: More concise language would be appropriate here.
As requested, we were more succinct in our language and have shortened this section.
The SABER-FISH images are very dim. I realize the importance of not saturating the pixels, but the colors are difficult to make out.
We thank the reviewer for pointing this out and have endeavored to make the SABER-FISH images brighter and easier to see.
-
-
-
As Smith et al. put it, most hacklabs, makerspaces, and fablabs have policies and cultural norms via which “all code, designs, and instructions in the making and repairing of something are made freely available for people to access, adopt and modify, so long as the source is acknowledged
En el contexto colombiano, hay un gran vacío en la formación en tecnología: se nos suele formar como usuarios de dispositivos y tecnologías, y en general se busca estandarizar esta formación. La perspectiva crítica y transgresora que supone otro tipo de acciones tecnológicas, como las mencionadas acá, está supeditada a espacios alternativos y divergentes, y se convierten en apuesta política contrahegménonica de los sistemas sociotécnico imperantes.
-
-
theconversation.com theconversation.com
-
La prévention peut se faire au niveau de la médecine du travail. Malheureusement, celle-ci demeure souvent impuissante surtout depuis la réforme apportée par la loi travail qui a porté la périodicité des visites de suivi de 2 à 5 ans. Le manager quant à lui, s’il est en mesure de détecter le moindre signe avant-coureur devra alerter le service RH. Les 35 suicides au sein de France Telecom en 2008/2009 ont conduit les pouvoirs publics au lancement d’un plan d’urgence pour la prévention du stress au travail en octobre 2009. Une prise de conscience managériale devient nécessaire. L’employeur engage d’ailleurs sa responsabilité lorsqu’un salarié est victime d’un burn-out lié à la dégradation de ses conditions de travail dans l’entreprise, ce que confirme la Cour de cassation (Cass. soc 13 mars 2013 n° 11-22082). Il est alors intéressant de rappeler que dans le cadre du contrat de travail, l’employeur est tenu à une obligation de sécurité (obligation de résultat prévue à l’article L 4121-1 du Code du travail). Il doit donc prendre les mesures nécessaires pour assurer la sécurité et protéger la santé physique et mentale des travailleurs.
Les éléments du cadre législatif et histrorique du problématique sont réutilisés pour le renforcement du premier argument épistémique et pour l'introduction du deuxième argument: la responsabilité d'employeur de veiller à la santé mentale des travailleurs, en plus de la santé physique. C'est donc le 2ème argument épistémique.
-
En 2015 déjà, la loi relative au dialogue social et à l’emploi, dite loi Rebsamen, en son article 27 a consacré la reconnaissance des pathologies psychiques comme maladies professionnelles au niveau de la loi en modifiant l’article L461-1 du code de la sécurité sociale, précisant que « les pathologies psychiques peuvent être reconnues comme maladies professionnelles ». Le décret du 7 juin 2016 vient quant à lui mettre en place des mesures permettant de renforcer l’expertise médicale pour la reconnaissance des pathologies psychiques et précise les modalités applicables aux dossiers concernés.
Le cadre historique et législatif du problématique qui est posé.
-
-
haleandquick.substack.com haleandquick.substack.com
-
from marking to doing.
Invisible code here for poets or poet wannabees: all poems are phase shifters. That makes them concrete. This poem, for example, does a little turn in the middle, like a sonnet, where it moves from observing and writing down to judging and moving on. At some point you mark the phase changes as done and you share your voice. That is pretty concrete.
One thing that this AI work with Claude has done is to make me articulate the liminality and the phase shifts in my poetry in order to make it better. Clearer and less prideful.
-
-
impedagogy.com impedagogy.com
-
from marking to doing.
Invisible code here for poets or poet wannabees: all poems are phase shifters. That makes them concrete. This poem, for example, does a little turn in the middle, like a sonnet, where it moves from observing and writing down to judging and moving on. At some point you mark the phase changes as done and you share your voice. That is pretty concrete.
One thing that this AI work with Claude has done is to make me articulate the liminality and the phase shifts in my poetry in order to make it better. Clearer and less prideful.
-
-
github.com github.com
-
About A simple code sandbox for playing around with HTMX. No setup needed!
📖✍️- 🎮| 🅈 ann0te - HTMX Playground
from - 📖✍️- 🎮| 🅈 ann0te - HTMX Playground | 🅈
-
-
openeducationalberta.ca openeducationalberta.ca
-
The inclusion of AI technology in the classroom can alleviate some aspects of a teacher’s workload and can also benefit student learning and achievement. Some AI that is available as assistive technology can be chosen and “tailored to fit individual student rates and styles of learning . . . but not replace the work of human teachers” (Johnson, 2020, para. 17), because teachers are better equipped to determine which teaching methods will meet the needs of each student. Teachers can work with machine learning technology to solve problems and challenges, and when used correctly, it can help their students become better learners and members of society (Atlantic Re:think, 2018; HubSpot, 2017).
AI is now into classroom in multiple ways, the most recent one is ChatGPT. Many professors are not ready to let ChatGPT to be use in assignment yet, which I totally understand. I also agree to this article that AI cannot replace real teachers, because many teachers "teach students according to their aptitude" AI is pre-code which means it teach in same ways
-
-
aggiehonor.tamu.edu aggiehonor.tamu.edu
-
The intentional invention of any information or citation on an assignment or document. This includes using generative Artificial Intelligence (AI) or other electronic resources in an unauthorized manner to create academic work and represent it as one's own.
The use of generative AI in an unauthorized manner to create academic work and present it as your own may be an example of fabrication as described in the Aggie Honor Code 20.1.2.3.2 part 4.
-
-
brimorganot.weebly.com brimorganot.weebly.com
-
fundamentals of practice/code of ethics
Capitalize formal names of sections
-
-
runestone.academy runestone.academy
-
To see this for yourself, write a line of code below to print the value of the expression 0.3 == 0.1 + 0.2; it will be false!
0.3==0.2+0.1 will show as false, but 0.5==0.4+0.1 will be shown as true???
-
-
-
Vous pourrez écouter cette émission qui dure trente minute en suivant notre lien vers France Inter. googletag.cmd.push(function() { googletag.defineSlot('/53015287,22658405138/actualitte.com_d_728x90_2', [728, 90], 'div-gpt-ad-1407836076451-0').addService(googletag.pubads()); googletag.display('div-gpt-ad-1407836076451-0'); }); yieldlove_cmd.push(function () { YLHH.utils.lazyLoad('div-gpt-ad-1407836076451-0', function () { YLHH.bidder.startAuction('/53015287,22658405138/actualitte.com_d_728x90_2') }) }) Commenter cet article Poster mon commentaire googletag.cmd.push(function() { googletag.defineSlot('/53015287,22658405138/actualitte.com_d_728x90_3', [728, 90], 'div-gpt-ad-1407836161652-0').addService(googletag.pubads()); googletag.display('div-gpt-ad-1407836161652-0'); }); yieldlove_cmd.push(function () { YLHH.utils.lazyLoad('div-gpt-ad-1407836161652-0', function () { YLHH.bidder.startAuction('/53015287,22658405138/actualitte.com_d_728x90_3') }) }) Plus d'articles sur le même thème À la loupe Interviews Aux Deux Magots, “la littérature est éternelle” #PrixdesDeuxMagots2023 – Le Prix des Deux Magots, l'une des récompenses littéraires les plus prestigieuses de France, a célébré son 90e anniversaire dans une ambiance festive et solennelle. Étienne de Montety, président du jury, a partagé avec nous l'essence de cette édition mémorable. 25/09/2023, 17:36 À la loupe Interviews Kevin Lambert : l’architecture, 1er art et miroir de l'époque Le jeune romancier Kevin Lambert fait l’actualité de cette rentrée littéraire : d’abord en s’inscrivant avec son troisième roman publié au Nouvel Attila, Que notre joie demeure, dans plusieurs listes de prix, dont celle du Goncourt. Le lauréat 2018 de la plus prestigieuse récompense française, Nicolas Mathieu, a remis une pièce dans la machine en s’étonnant de l’ « orgueil surprenant » avec laquelle l’éditeur du Québécois affirme que son auteur a eu recours à une « Sensitivity reader », « comme s’il s’agissait tout à la fois d’un gage de qualité littéraire, de modernité (rire) et de vertu ». 19/09/2023, 17:36 À la loupe Interviews “Je suis sans cesse rattrapé, happé par la vie.” Né en 1964 au Havre, Jean-François Jacq vit actuellement à Vierzon, où il poursuit une intense activité théâtrale et littéraire. Auteur de plusieurs biographies de rock-stars, de groupes, l’homme dévoile également un parcours de vie à la fois chaotique et douloureux à travers plusieurs livres autobiographiques, aux titres évocateurs (Heurt-limite, Hémorragie à l’errance, etc.). Propos recueillis par Etienne Ruhaud. 19/09/2023, 11:38 À la loupe Interviews Bibliocollector vise le record de cartes de bibliothèque Adolescent lyonnais de 16 ans, Adam s'est lancé dans un projet fou : battre un record du monde en collectant le plus grand nombre de cartes de bibliothèques du monde entier. Pour que sa collection soit officiellement reconnue, plusieurs critères s'imposent, mais qu'importe, le Bibliocollector est lancé dans son projet. Entretien. 01/04/2024, 11:06 À la loupe Interviews Géopolitique, conspirations : “XIII est un survivant” (Yves Sente) AnniversaireXIII – Le plus amnésique des héros apparut en 1984, sous l’impulsion du scénariste Jean Van Hamme et du dessinateur William Vance : à la recherche d’un passé fuyant, accusé d’assassinat d’un président des États-Unis et toujours pris dans une conspiration politique sans fin, XIII fête ses quarante années d’aventures, de manipulation et de faux-semblants. Retour avec Yves Sente, le scénariste qui prolonge depuis 13 ans déjà cette épopée américaine avec le dessinateur Iouri Jigounov. 14/03/2024, 15:43 À la loupe Interviews Nancy Huston : “Tout romancier qui se respecte est trans” L'autrice française d'origine canadienne, Nancy Huston et l'écrivain, réalisateur, poète et militant écologiste, Cyril Dion, se connaissent, ils sont amis. Ils éprouvent l’un pour l’autre de l’affection et de l’estime. Les éditions Actes Sud ont proposé une rencontre pour parler de Francia, le dernier texte de Nancy Huston, publié par la maison le 6 mars dernier. Propos recueillis par Estelle Lemaître. 14/03/2024, 15:24 À la loupe Interviews À Madagascar, Karné offre une évasion aux jeunes insulaires Tout sourire et pleine d’entrain, Ravaka a l’air de fonctionner à mille à l’heure. Dès qu’elle s’exprime, on sent un grand enthousiasme et une vraie curiosité. Une envie de comprendre et d’agir se dégage d’emblée de sa personnalité positive. Elle a créé Karné, un concept unique : un magazine bilingue (malgache-français), coloré, vivant, instructif, ludique qui sait prendre sa place sur ce marché. Propos recueillis par Agnès Debiage, fondatrice d’ADCF Africa. 14/03/2024, 13:17 À la loupe Interviews Frédéric Taddeï : "L’âge est un sujet qui n’existe pas" « Quand on vous dit que François Ier a gagné la bataille de Marignan en 1515 on ne vous dit pas quel âge il avait, il avait 20 ans ». Le présentateur Frédéric Taddeï a une obsession qu’on ne lui connaissait pas encore : l’âge. Nous l’avons rencontré pour la sortie des Birthday books le 6 mars 2024, l’occasion de discourir sur ces « quartiers de la vie que l’on habite tous ensemble ». 29/02/2024, 15:46 À la loupe Interviews “Nos points communs sont simples : le territoire et le livre.” #Noshorizonsdesirables – Durant cinq années de librairie au Québec chez Pantoute, Benoît Vanbeselaere est passé de la communication et de l’événementiel à la direction générale d’une des deux succursales. Depuis avril 2023, il a pris ses fonctions comme coordinateur de l’Association des éditeurs des Hauts-de-France. En marge des Rencontres régionales du Livre et de la Lecture 2024, à Boulogne-sur-Mer, il revient avec nous sur les actions menées et à mener. 26/02/2024, 15:13 À la loupe Interviews Partage de la valeur : cette étude “apporte des éléments de compréhension” (SNE) L'étude du Syndicat national de l'édition (SNE) consacrée au partage de la valeur entre auteurs et éditeurs, présentée au début de ce mois de février, a été accueillie froidement par les organisations d'auteurs. Ces dernières reprochaient une approche « biaisée » et des résultats qui masquaient la situation économique des écrivains. Renaud Lefebvre, directeur général du SNE, répond aux critiques. 22/02/2024, 11:49 À la loupe Interviews Barbara Kingsolver, Prix Pulitzer 2023 : “Je ne crois pas au talent” Le Prix Pulitzer de la fiction, qui récompense un roman qui raconte cette démente Amérique, a été décerné à deux auteurs ex-aequo en 2023 : Hernan Diaz pour son texte sur les coulisses de la Grande Dépression des années 30, Trust, et Barbara Kingsolver. D’un côté, le gros argent, de l'autre, les prolos d'une campagne des Appalaches, à travers les aventures de Demon Copperhead. Un David Copperfield contemporain dans les terres contrariées de l'OxyconTin et des champs de tabac… 21/02/2024, 16:00 À la loupe Interviews Pour le livre de Turin, "un salon qui aide au dialogue" Du 9 du 13 mai, le Salon international du livre de Turin incarne un événement majeur autour du livre sur le territoire italien. Entre défis antérieurs et direction nouvelle, Annalena Benini, directrice du Salon pour cette édition, fait part à Actualitté des conditions à réunir, pour mener à bien les ambitions prochaines, notamment quant à la jeunesse. 19/02/2024, 12:07 À la loupe Interviews “Le livre et la lecture comme biens communs” Noshorizonsdesirables – Dans le paysage littéraire des Hauts-de-France, une révolution jusqu’alors silencieuse entend faire grand bruit. François Annycke, directeur de l’Agence Régionale du Livre Hauts-de-France (AR2L), inaugurera les 21 et 22 février deux journées professionnelles. Objectif : collaborer, en redéfinissant le rôle de l’Agence et de ses partenaires, pour plus d’efficacité. 16/02/2024, 12:00 À la loupe Interviews “Le lecteur français veut comprendre l'Italie à travers sa littérature” Dans une interview menée par Federica Malinverno, Florence Raut revient sur la création de La libreria, librairie-café parisienne cofondée aux côtés d'Andrea De Ritis en 2006, se définissant comme un « espace petit mais riche dédié à l’Italie, situé dans le cœur du IXe arrondissement de Paris ». 13/02/2024, 11:38 À la loupe Interviews “Pour être un libraire, il faut porter la casquette d’agent culturel” Pleine d’énergie et toute souriante, Prudientienne Gbaguidi est une figure de la librairie francophone en Afrique de l’Ouest. Très engagée pour faire rayonner son métier, elle suit tout ce qui se publie dans la sous-région. A la tête de la librairie Savoir d’Afrique (Bénin), elle est aussi présidente de l’Association des Libraires professionnels du Bénin (ALPB) et vice-présidente de l’Association internationale des Libraires francophones (AILF). Propos recueillis par Agnès Debiage, fondatrice d’ADCF Africa. 06/02/2024, 13:07 À la loupe Interviews Statut européen des artistes-auteurs : “C'est un nouvel espoir” Depuis plusieurs semaines, des organisations françaises d'auteurs de l'écrit se sont lancées dans une campagne de soutien à une initiative législative du Parlement européen. L'objectif ? Inciter la Commission européenne à agir pour améliorer les conditions de vie des artistes-auteurs, notamment par la création d'un statut. 18/01/2024, 15:15 À la loupe Interviews Résolument ancré dans la Fantasy, Leha crée Majik sa collection poche ENTRETIEN – Apparu en 2017 dans le paysage des Littératures de l’Imaginaire, Leha Editions amorce 2024 avec un gros dossier : la création d’une collection de poche, Majik. Un pari audacieux, autant qu’une nouvelle corde à l’arc de cet éditeur, installé à Marseille depuis quelques années. 17/01/2024, 10:08 À la loupe Interviews Louise Boudonnat : traduire, “c’est aussi une rencontre avec soi-même” Dans une interview menée par Federica Malinverno, Louise Boudonnat revient sur son travail de traduction (de l'italien) de l'ouvrage Absolutely Nothing. Histoires et disparitions dans les déserts américains, de Giorgio Vasta et Ramak Fazel, paru aux éditions Verdier en 2023. 02/01/2024, 14:52 À la loupe Interviews Line Papin et les Lettres Zola : "Cette démarche me garde constamment en éveil" LaLettreZola — La première Lettre Zola est toujours disponible à la prévente sur la plateforme KissKissBankBank. La première romancière à offrir aux futurs lecteurs un texte inédit, entre réel et fiction, est Blandine Rinkel. Mais chaque mois est l'occasion de découvrir une nouvelle plume, et pour ce faire, Louis Vendel, créateur de ce singulier et enthousiasmant concept, a dû façonner une véritable équipe autour de lui. Une trentaine de trentenaires, parmi lesquels Line Papin, qui triche un peu, puisqu'elle a 27 ans, mais déjà six ouvrages derrière elle. 26/12/2023, 17:06 À la loupe Interviews David Duchovny : “Les écrivains ont le devoir d'écrire tout ce qu'ils veulent” David Duchovny, pour les plus anciens, c’est l’agent Fox Mulder, pour les plus au fait, le romancier Hank Moody de Californication. L’enfant de New York est aussi un écrivain : son premier texte fut un conte animalier, Oh la vache ! (trad. Claro, Grasset) « entre Georges Orwell et Tex Avery », rien que ça. Le second publié en France, La Reine du Pays-sous-la-Terre, est un texte étonnant, riche, non sans humour et d'un beau romantisme suranné. 20/12/2023, 18:08 À la loupe Interviews Main à plume : la résistance surréaliste sous l'Occupation Épisode aussi bref qu’intense, aujourd’hui oublié, l’aventure de la « Main à plume » constitue pourtant un des éléments majeurs de l’histoire du surréalisme. En 1940, suite au départ d’André Breton, plusieurs jeunes créateurs se regroupent pour résister à l’occupant, tout en poursuivant une intense activité créatrice, avec la publication de plaquettes, aujourd’hui introuvables. Huit de vingt-trois membres périront : déportés, fusillés, ou tombés au front. Docteure ès Lettres, mais aussi traductrice et autrice, Léa Nicolas-Teboul a retracé le parcours du groupe. Propos recueillis par Étienne Ruhaud. 06/12/2023, 15:37 À la loupe Interviews L'édition jeunesse au Maroc : rencontre avec Nadia Essalmi Nadia Essalmi est une femme de cœur et d’engagement. Une fonceuse qui ne se pose pas mille questions en amont mais qui agit pour faire bouger les lignes et surtout pour apporter aux autres. C’est aussi une grande rêveuse qui suit son cœur, mais n’est-ce pas le moteur pour innover et avancer ? Editrice jeunesse, promotrice culturelle, militante associative, Nadia est sur tous les fronts quand il s’agit de défendre et valoriser le livre et la lecture au Maroc. Propos recueillis par Agnès Debiage, fondatrice d’ADCF Africa. 05/12/2023, 13:07 À la loupe Interviews Malaise dans l'Éducnat : “Mes élèves me donnent matière à espérance” Qu’est-ce que la précarité ? Qu’est-ce que le démantèlement méthodique du service public ? Qu’est-ce qu’être un professeur précaire dans le secondaire, de surcroît « (grand) remplaçant » dans les territoires abandonnés de la République ? Qu’est-ce qu’enseigner et transmettre ? Autant de questions qui interpellent notre temps. Propos recueillis par Faris Lounis. 04/12/2023, 14:54 À la loupe Interviews “Stig Dagerman va plus loin que Camus : il supprime l’espoir” Claude Le Manchec, essayiste et traducteur français, nous parle de l’œuvre de Stig Dagerman (1923-1954), de sa place et de sa réception en France, en évoquant son étude Stig Dagerman, la vérité pressentie de tous (Éditions du Cygne, Paris, 2020). Propos recueillis par Karim El Haddady 04/12/2023, 12:22 À la loupe Interviews Pour une industrie du livre plus forte en Italie Dans un entretien accordé à ActuaLitté, le président de l'Associazione Italiana Editori dévoile ses objectifs pour l'industrie du livre en Italie. Il aborde la nécessité d'une croissance culturelle, la promotion de la lecture, l'internationalisation de l'édition italienne et les défis du dialogue avec les institutions. 27/11/2023, 15:29 À la loupe Interviews Tom Buron : "Le danger est un élément central de mon travail" Jeune poète francilien, Tom Buron pratique la boxe, écoute du jazz, écrit de brefs recueils percutants. Dernier en date, La Chambre et le Barillet (éditions « Angle mort », 2023), présente une suite de vers-libres, souvent rageurs, parfois énigmatiques. Familier de l’univers urbain, guidé par un certain rythme incantatoire, habitué des scènes poétiques, l’auteur semble refuser la tyrannie du sens, de l’intelligibilité, tout en favorisant l’oralité. Propos recueillis par Étienne Ruhaud. 27/11/2023, 10:04 À la loupe Interviews Anarchie en Haïti : “Que les Américains nous lâchent un peu” Gary Victor, « le romancier haïtien le plus lu dans son pays » selon son éditeur Mémoire d'encrier, ne peut plus aujourd'hui vivre dans sa maison, dans le quartier de Carrefour-Feuilles à Port-au-Prince, pris dans la guerre des gangs. La situation dans le pays de Dany Laferrière est cataclysmique, mais il faut continuer de vivre, et pour le Prix littéraire des Caraïbes 2008, cela passe par l'écriture : à la rentrée, il a fait paraître en France Le Violon d'Adrien, où il s'appuie sur un épisode de son enfance qui l'a particulièrement marqué... 14/11/2023, 11:40 À la loupe Interviews Tikoulou : un héros mauricien qui unit les cultures À l’Ile Maurice, Pascale Siew est devenue indissociable du personnage qu’elle a créé : Tikoulou, le petit Mauricien. Cette éditrice passionnée est depuis longtemps une référence sur l’île mais, dans ce cadre idyllique, Pascale Siew avoue se sentir très isolée professionnellement. Elle nous raconte cette belle aventure des éditions Vizavi qui dure depuis trois décennies. Propos recueillis par Agnès Debiage, fondatrice d’ADCF Africa. 13/11/2023, 10:42 À la loupe Interviews De l'ombre du 93 à la lumière littéraire : “Je lui serai toujours redevable” (Olivier Norek) Le décès de Huguette Maure, survenu ce 29 octobre, a assombri un week-end déjà maussade. Parmi les écrivains que la responsable éditoriale avait soutenus, Olivier Norek lui rend hommage. « Elle a façonné mon parcours : elle représente les fondations de l'écrivain que je suis devenu. » Notamment grâce à la confiance qu'elle fut la première à lui témoigner, en choisissant de publier son premier roman, Code 93. 30/10/2023, 11:04 À la loupe Interviews “La consommation de l’actualité s’opère sans prise de conscience” Benoît Couzi, directeur des éditions Le Lys bleu, avait dernièrement lancé une pétition pour attirer l’attention sur le coût croissant des livres en France. Malheureusement, malgré une diffusion à près de 200.000 personnes, seulement 4 000 ont choisi de signer. Une réalité qui, selon Benoit Couzi, « dit quelque chose de l’implication de l’individu dans la société ». 26/10/2023, 17:02 À la loupe Interviews Les chiens ne se baignent jamais deux fois dans la même Rivière Décalé, mystérieux, Les chiens nus nous parle, comme son nom l’indique, de nos amis quadrupèdes. Mais loin d’avoir rédigé un (banal) traité d’éthologie, ou un énième guide sur les chiens, Alain Rivière nous embarque pour un déroutant voyage, dans lequel l’animal semble essentiellement nous renvoyer à nous, à notre condition mortelle. Propos recueillis par Étienne Ruhaud. 26/10/2023, 11:24 À la loupe Interviews “La réécriture par les ayants droit, ce n'est plus la même oeuvre” Déposée en mai 2023 à l'Assemblée nationale par le député Les Républicains Jean-Louis Thiériot (Seine-et-Marne), la proposition de loi visant à protéger l’intégrité des œuvres des réécritures idéologiques a fait son retour, au mois d'octobre. Un texte inchangé, mais cette fois soutenu par d'autres représentants de la droite, Éric Ciotti en tête. 23/10/2023, 12:24 À la loupe Interviews Elias Khoury : héraut d'un monde arabe en quête de modernité Le romancier libanais Elias Khoury publie chez Actes Sud L’Étoile de la mer, son dernier roman, et deuxième partie d’une trilogie (trad. Rania Samara). Farouk Mardam-Bey, directeur chez Actes Sud de la collection Sindbad, se souvient avec émotion de sa première rencontre avec l'écrivain, à Paris. 10/10/2023, 12:06 À la loupe Interviews Frédéric Pillot, un Roland passionnément furieux LEP23 – Dès son enfance, Frédéric Pillot a trouvé du plaisir dans le dessin. Avec le temps, cette passion s'est transformée en une évidence : allier le dessin à la narration. La réflexion s'est alors orientée vers une activité génératrice de revenus. Une constellation d'idées s'est formée, mêlant le plaisir de raconter à celui de dessiner. Malgré des doutes et des impasses, Frédéric a persévéré. Aujourd'hui, il est un illustrateur reconnu, inspirant ceux qui souhaitent transformer leur passion en métier. 08/10/2023, 17:18 À la loupe Interviews Ange Mbelle : “Tisser des liens pour le livre africain” Une approche pragmatique du marché, un parler franc et une vraie dynamique entrepreneuriale, Ange Mbelle a créé GVG, une structure de distribution. Basée à Douala (Cameroun), elle rayonne dans plusieurs pays de la région. Attentive aux pratiques des éditeurs, elle encourage les libraires et autres points de vente à développer leur offre de livres. Propos recueillis par Agnès Debiage, fondatrice d’ADCF Africa. 02/10/2023, 15:01 À la loupe Interviews La Lettre Zola : redéfinir le lien entre écrivains et lecteurs LaLettreZola – Dans le monde de l'édition, il est rare de trouver des projets qui marient avec autant de finesse la littérature et le journalisme. Louis Vendel, fondateur de la revue "La Lettre Zola", nous parle de cette initiative unique qui fait la jonction entre ces deux univers. 28/09/2023, 15:38 À la loupe Interviews Aux Deux Magots, “la littérature est éternelle” #PrixdesDeuxMagots2023 – Le Prix des Deux Magots, l'une des récompenses littéraires les plus prestigieuses de France, a célébré son 90e anniversaire dans une ambiance festive et solennelle. Étienne de Montety, président du jury, a partagé avec nous l'essence de cette édition mémorable. 25/09/2023, 17:36 À la loupe Interviews Kevin Lambert : l’architecture, 1er art et miroir de l'époque Le jeune romancier Kevin Lambert fait l’actualité de cette rentrée littéraire : d’abord en s’inscrivant avec son troisième roman publié au Nouvel Attila, Que notre joie demeure, dans plusieurs listes de prix, dont celle du Goncourt. Le lauréat 2018 de la plus prestigieuse récompense française, Nicolas Mathieu, a remis une pièce dans la machine en s’étonnant de l’ « orgueil surprenant » avec laquelle l’éditeur du Québécois affirme que son auteur a eu recours à une « Sensitivity reader », « comme s’il s’agissait tout à la fois d’un gage de qualité littéraire, de modernité (rire) et de vertu ». 19/09/2023, 17:36 À la loupe Interviews “Je suis sans cesse rattrapé, happé par la vie.” Né en 1964 au Havre, Jean-François Jacq vit actuellement à Vierzon, où il poursuit une intense activité théâtrale et littéraire. Auteur de plusieurs biographies de rock-stars, de groupes, l’homme dévoile également un parcours de vie à la fois chaotique et douloureux à travers plusieurs livres autobiographiques, aux titres évocateurs (Heurt-limite, Hémorragie à l’errance, etc.). Propos recueillis par Etienne Ruhaud. 19/09/2023, 11:38 À la loupe Interviews Bibliocollector vise le record de cartes de bibliothèque Adolescent lyonnais de 16 ans, Adam s'est lancé dans un projet fou : battre un record du monde en collectant le plus grand nombre de cartes de bibliothèques du monde entier. Pour que sa collection soit officiellement reconnue, plusieurs critères s'imposent, mais qu'importe, le Bibliocollector est lancé dans son projet. Entretien. 01/04/2024, 11:06 À la loupe Interviews Géopolitique, conspirations : “XIII est un survivant” (Yves Sente) AnniversaireXIII – Le plus amnésique des héros apparut en 1984, sous l’impulsion du scénariste Jean Van Hamme et du dessinateur William Vance : à la recherche d’un passé fuyant, accusé d’assassinat d’un président des États-Unis et toujours pris dans une conspiration politique sans fin, XIII fête ses quarante années d’aventures, de manipulation et de faux-semblants. Retour avec Yves Sente, le scénariste qui prolonge depuis 13 ans déjà cette épopée américaine avec le dessinateur Iouri Jigounov. 14/03/2024, 15:43 À la loupe Interviews Nancy Huston : “Tout romancier qui se respecte est trans” L'autrice française d'origine canadienne, Nancy Huston et l'écrivain, réalisateur, poète et militant écologiste, Cyril Dion, se connaissent, ils sont amis. Ils éprouvent l’un pour l’autre de l’affection et de l’estime. Les éditions Actes Sud ont proposé une rencontre pour parler de Francia, le dernier texte de Nancy Huston, publié par la maison le 6 mars dernier. Propos recueillis par Estelle Lemaître. 14/03/2024, 15:24 À la loupe Interviews À Madagascar, Karné offre une évasion aux jeunes insulaires Tout sourire et pleine d’entrain, Ravaka a l’air de fonctionner à mille à l’heure. Dès qu’elle s’exprime, on sent un grand enthousiasme et une vraie curiosité. Une envie de comprendre et d’agir se dégage d’emblée de sa personnalité positive. Elle a créé Karné, un concept unique : un magazine bilingue (malgache-français), coloré, vivant, instructif, ludique qui sait prendre sa place sur ce marché. Propos recueillis par Agnès Debiage, fondatrice d’ADCF Africa. 14/03/2024, 13:17 À la loupe Interviews Frédéric Taddeï : "L’âge est un sujet qui n’existe pas" « Quand on vous dit que François Ier a gagné la bataille de Marignan en 1515 on ne vous dit pas quel âge il avait, il avait 20 ans ». Le présentateur Frédéric Taddeï a une obsession qu’on ne lui connaissait pas encore : l’âge. Nous l’avons rencontré pour la sortie des Birthday books le 6 mars 2024, l’occasion de discourir sur ces « quartiers de la vie que l’on habite tous ensemble ». 29/02/2024, 15:46 À la loupe Interviews “Nos points communs sont simples : le territoire et le livre.” #Noshorizonsdesirables – Durant cinq années de librairie au Québec chez Pantoute, Benoît Vanbeselaere est passé de la communication et de l’événementiel à la direction générale d’une des deux succursales. Depuis avril 2023, il a pris ses fonctions comme coordinateur de l’Association des éditeurs des Hauts-de-France. En marge des Rencontres régionales du Livre et de la Lecture 2024, à Boulogne-sur-Mer, il revient avec nous sur les actions menées et à mener. 26/02/2024, 15:13 À la loupe Interviews Partage de la valeur : cette étude “apporte des éléments de compréhension” (SNE) L'étude du Syndicat national de l'édition (SNE) consacrée au partage de la valeur entre auteurs et éditeurs, présentée au début de ce mois de février, a été accueillie froidement par les organisations d'auteurs. Ces dernières reprochaient une approche « biaisée » et des résultats qui masquaient la situation économique des écrivains. Renaud Lefebvre, directeur général du SNE, répond aux critiques. 22/02/2024, 11:49 À la loupe Interviews Barbara Kingsolver, Prix Pulitzer 2023 : “Je ne crois pas au talent” Le Prix Pulitzer de la fiction, qui récompense un roman qui raconte cette démente Amérique, a été décerné à deux auteurs ex-aequo en 2023 : Hernan Diaz pour son texte sur les coulisses de la Grande Dépression des années 30, Trust, et Barbara Kingsolver. D’un côté, le gros argent, de l'autre, les prolos d'une campagne des Appalaches, à travers les aventures de Demon Copperhead. Un David Copperfield contemporain dans les terres contrariées de l'OxyconTin et des champs de tabac… 21/02/2024, 16:00 À la loupe Interviews Pour le livre de Turin, "un salon qui aide au dialogue" Du 9 du 13 mai, le Salon international du livre de Turin incarne un événement majeur autour du livre sur le territoire italien. Entre défis antérieurs et direction nouvelle, Annalena Benini, directrice du Salon pour cette édition, fait part à Actualitté des conditions à réunir, pour mener à bien les ambitions prochaines, notamment quant à la jeunesse. 19/02/2024, 12:07 À la loupe Interviews “Le livre et la lecture comme biens communs” Noshorizonsdesirables – Dans le paysage littéraire des Hauts-de-France, une révolution jusqu’alors silencieuse entend faire grand bruit. François Annycke, directeur de l’Agence Régionale du Livre Hauts-de-France (AR2L), inaugurera les 21 et 22 février deux journées professionnelles. Objectif : collaborer, en redéfinissant le rôle de l’Agence et de ses partenaires, pour plus d’efficacité. 16/02/2024, 12:00 À la loupe Interviews “Le lecteur français veut comprendre l'Italie à travers sa littérature” Dans une interview menée par Federica Malinverno, Florence Raut revient sur la création de La libreria, librairie-café parisienne cofondée aux côtés d'Andrea De Ritis en 2006, se définissant comme un « espace petit mais riche dédié à l’Italie, situé dans le cœur du IXe arrondissement de Paris ». 13/02/2024, 11:38 À la loupe Interviews “Pour être un libraire, il faut porter la casquette d’agent culturel” Pleine d’énergie et toute souriante, Prudientienne Gbaguidi est une figure de la librairie francophone en Afrique de l’Ouest. Très engagée pour faire rayonner son métier, elle suit tout ce qui se publie dans la sous-région. A la tête de la librairie Savoir d’Afrique (Bénin), elle est aussi présidente de l’Association des Libraires professionnels du Bénin (ALPB) et vice-présidente de l’Association internationale des Libraires francophones (AILF). Propos recueillis par Agnès Debiage, fondatrice d’ADCF Africa. 06/02/2024, 13:07 À la loupe Interviews Statut européen des artistes-auteurs : “C'est un nouvel espoir” Depuis plusieurs semaines, des organisations françaises d'auteurs de l'écrit se sont lancées dans une campagne de soutien à une initiative législative du Parlement européen. L'objectif ? Inciter la Commission européenne à agir pour améliorer les conditions de vie des artistes-auteurs, notamment par la création d'un statut. 18/01/2024, 15:15 À la loupe Interviews Résolument ancré dans la Fantasy, Leha crée Majik sa collection poche ENTRETIEN – Apparu en 2017 dans le paysage des Littératures de l’Imaginaire, Leha Editions amorce 2024 avec un gros dossier : la création d’une collection de poche, Majik. Un pari audacieux, autant qu’une nouvelle corde à l’arc de cet éditeur, installé à Marseille depuis quelques années. 17/01/2024, 10:08 À la loupe Interviews Louise Boudonnat : traduire, “c’est aussi une rencontre avec soi-même” Dans une interview menée par Federica Malinverno, Louise Boudonnat revient sur son travail de traduction (de l'italien) de l'ouvrage Absolutely Nothing. Histoires et disparitions dans les déserts américains, de Giorgio Vasta et Ramak Fazel, paru aux éditions Verdier en 2023. 02/01/2024, 14:52 À la loupe Interviews Line Papin et les Lettres Zola : "Cette démarche me garde constamment en éveil" LaLettreZola — La première Lettre Zola est toujours disponible à la prévente sur la plateforme KissKissBankBank. La première romancière à offrir aux futurs lecteurs un texte inédit, entre réel et fiction, est Blandine Rinkel. Mais chaque mois est l'occasion de découvrir une nouvelle plume, et pour ce faire, Louis Vendel, créateur de ce singulier et enthousiasmant concept, a dû façonner une véritable équipe autour de lui. Une trentaine de trentenaires, parmi lesquels Line Papin, qui triche un peu, puisqu'elle a 27 ans, mais déjà six ouvrages derrière elle. 26/12/2023, 17:06 À la loupe Interviews David Duchovny : “Les écrivains ont le devoir d'écrire tout ce qu'ils veulent” David Duchovny, pour les plus anciens, c’est l’agent Fox Mulder, pour les plus au fait, le romancier Hank Moody de Californication. L’enfant de New York est aussi un écrivain : son premier texte fut un conte animalier, Oh la vache ! (trad. Claro, Grasset) « entre Georges Orwell et Tex Avery », rien que ça. Le second publié en France, La Reine du Pays-sous-la-Terre, est un texte étonnant, riche, non sans humour et d'un beau romantisme suranné. 20/12/2023, 18:08 À la loupe Interviews Main à plume : la résistance surréaliste sous l'Occupation Épisode aussi bref qu’intense, aujourd’hui oublié, l’aventure de la « Main à plume » constitue pourtant un des éléments majeurs de l’histoire du surréalisme. En 1940, suite au départ d’André Breton, plusieurs jeunes créateurs se regroupent pour résister à l’occupant, tout en poursuivant une intense activité créatrice, avec la publication de plaquettes, aujourd’hui introuvables. Huit de vingt-trois membres périront : déportés, fusillés, ou tombés au front. Docteure ès Lettres, mais aussi traductrice et autrice, Léa Nicolas-Teboul a retracé le parcours du groupe. Propos recueillis par Étienne Ruhaud. 06/12/2023, 15:37 À la loupe Interviews L'édition jeunesse au Maroc : rencontre avec Nadia Essalmi Nadia Essalmi est une femme de cœur et d’engagement. Une fonceuse qui ne se pose pas mille questions en amont mais qui agit pour faire bouger les lignes et surtout pour apporter aux autres. C’est aussi une grande rêveuse qui suit son cœur, mais n’est-ce pas le moteur pour innover et avancer ? Editrice jeunesse, promotrice culturelle, militante associative, Nadia est sur tous les fronts quand il s’agit de défendre et valoriser le livre et la lecture au Maroc. Propos recueillis par Agnès Debiage, fondatrice d’ADCF Africa. 05/12/2023, 13:07 À la loupe Interviews Malaise dans l'Éducnat : “Mes élèves me donnent matière à espérance” Qu’est-ce que la précarité ? Qu’est-ce que le démantèlement méthodique du service public ? Qu’est-ce qu’être un professeur précaire dans le secondaire, de surcroît « (grand) remplaçant » dans les territoires abandonnés de la République ? Qu’est-ce qu’enseigner et transmettre ? Autant de questions qui interpellent notre temps. Propos recueillis par Faris Lounis. 04/12/2023, 14:54 À la loupe Interviews “Stig Dagerman va plus loin que Camus : il supprime l’espoir” Claude Le Manchec, essayiste et traducteur français, nous parle de l’œuvre de Stig Dagerman (1923-1954), de sa place et de sa réception en France, en évoquant son étude Stig Dagerman, la vérité pressentie de tous (Éditions du Cygne, Paris, 2020). Propos recueillis par Karim El Haddady 04/12/2023, 12:22 À la loupe Interviews Pour une industrie du livre plus forte en Italie Dans un entretien accordé à ActuaLitté, le président de l'Associazione Italiana Editori dévoile ses objectifs pour l'industrie du livre en Italie. Il aborde la nécessité d'une croissance culturelle, la promotion de la lecture, l'internationalisation de l'édition italienne et les défis du dialogue avec les institutions. 27/11/2023, 15:29 À la loupe Interviews Tom Buron : "Le danger est un élément central de mon travail" Jeune poète francilien, Tom Buron pratique la boxe, écoute du jazz, écrit de brefs recueils percutants. Dernier en date, La Chambre et le Barillet (éditions « Angle mort », 2023), présente une suite de vers-libres, souvent rageurs, parfois énigmatiques. Familier de l’univers urbain, guidé par un certain rythme incantatoire, habitué des scènes poétiques, l’auteur semble refuser la tyrannie du sens, de l’intelligibilité, tout en favorisant l’oralité. Propos recueillis par Étienne Ruhaud. 27/11/2023, 10:04 À la loupe Interviews Anarchie en Haïti : “Que les Américains nous lâchent un peu” Gary Victor, « le romancier haïtien le plus lu dans son pays » selon son éditeur Mémoire d'encrier, ne peut plus aujourd'hui vivre dans sa maison, dans le quartier de Carrefour-Feuilles à Port-au-Prince, pris dans la guerre des gangs. La situation dans le pays de Dany Laferrière est cataclysmique, mais il faut continuer de vivre, et pour le Prix littéraire des Caraïbes 2008, cela passe par l'écriture : à la rentrée, il a fait paraître en France Le Violon d'Adrien, où il s'appuie sur un épisode de son enfance qui l'a particulièrement marqué... 14/11/2023, 11:40 À la loupe Interviews Tikoulou : un héros mauricien qui unit les cultures À l’Ile Maurice, Pascale Siew est devenue indissociable du personnage qu’elle a créé : Tikoulou, le petit Mauricien. Cette éditrice passionnée est depuis longtemps une référence sur l’île mais, dans ce cadre idyllique, Pascale Siew avoue se sentir très isolée professionnellement. Elle nous raconte cette belle aventure des éditions Vizavi qui dure depuis trois décennies. Propos recueillis par Agnès Debiage, fondatrice d’ADCF Africa. 13/11/2023, 10:42 À la loupe Interviews De l'ombre du 93 à la lumière littéraire : “Je lui serai toujours redevable” (Olivier Norek) Le décès de Huguette Maure, survenu ce 29 octobre, a assombri un week-end déjà maussade. Parmi les écrivains que la responsable éditoriale avait soutenus, Olivier Norek lui rend hommage. « Elle a façonné mon parcours : elle représente les fondations de l'écrivain que je suis devenu. » Notamment grâce à la confiance qu'elle fut la première à lui témoigner, en choisissant de publier son premier roman, Code 93. 30/10/2023, 11:04 À la loupe Interviews “La consommation de l’actualité s’opère sans prise de conscience” Benoît Couzi, directeur des éditions Le Lys bleu, avait dernièrement lancé une pétition pour attirer l’attention sur le coût croissant des livres en France. Malheureusement, malgré une diffusion à près de 200.000 personnes, seulement 4 000 ont choisi de signer. Une réalité qui, selon Benoit Couzi, « dit quelque chose de l’implication de l’individu dans la société ». 26/10/2023, 17:02 À la loupe Interviews Les chiens ne se baignent jamais deux fois dans la même Rivière Décalé, mystérieux, Les chiens nus nous parle, comme son nom l’indique, de nos amis quadrupèdes. Mais loin d’avoir rédigé un (banal) traité d’éthologie, ou un énième guide sur les chiens, Alain Rivière nous embarque pour un déroutant voyage, dans lequel l’animal semble essentiellement nous renvoyer à nous, à notre condition mortelle. Propos recueillis par Étienne Ruhaud. 26/10/2023, 11:24 À la loupe Interviews “La réécriture par les ayants droit, ce n'est plus la même oeuvre” Déposée en mai 2023 à l'Assemblée nationale par le député Les Républicains Jean-Louis Thiériot (Seine-et-Marne), la proposition de loi visant à protéger l’intégrité des œuvres des réécritures idéologiques a fait son retour, au mois d'octobre. Un texte inchangé, mais cette fois soutenu par d'autres représentants de la droite, Éric Ciotti en tête. 23/10/2023, 12:24 À la loupe Interviews Elias Khoury : héraut d'un monde arabe en quête de modernité Le romancier libanais Elias Khoury publie chez Actes Sud L’Étoile de la mer, son dernier roman, et deuxième partie d’une trilogie (trad. Rania Samara). Farouk Mardam-Bey, directeur chez Actes Sud de la collection Sindbad, se souvient avec émotion de sa première rencontre avec l'écrivain, à Paris. 10/10/2023, 12:06 À la loupe Interviews Frédéric Pillot, un Roland passionnément furieux LEP23 – Dès son enfance, Frédéric Pillot a trouvé du plaisir dans le dessin. Avec le temps, cette passion s'est transformée en une évidence : allier le dessin à la narration. La réflexion s'est alors orientée vers une activité génératrice de revenus. Une constellation d'idées s'est formée, mêlant le plaisir de raconter à celui de dessiner. Malgré des doutes et des impasses, Frédéric a persévéré. Aujourd'hui, il est un illustrateur reconnu, inspirant ceux qui souhaitent transformer leur passion en métier. 08/10/2023, 17:18 À la loupe Interviews Ange Mbelle : “Tisser des liens pour le livre africain” Une approche pragmatique du marché, un parler franc et une vraie dynamique entrepreneuriale, Ange Mbelle a créé GVG, une structure de distribution. Basée à Douala (Cameroun), elle rayonne dans plusieurs pays de la région. Attentive aux pratiques des éditeurs, elle encourage les libraires et autres points de vente à développer leur offre de livres. Propos recueillis par Agnès Debiage, fondatrice d’ADCF Africa. 02/10/2023, 15:01 À la loupe Interviews La Lettre Zola : redéfinir le lien entre écrivains et lecteurs LaLettreZola – Dans le monde de l'édition, il est rare de trouver des projets qui marient avec autant de finesse la littérature et le journalisme. Louis Vendel, fondateur de la revue "La Lettre Zola", nous parle de cette initiative unique qui fait la jonction entre ces deux univers. 28/09/2023, 15:38 À la loupe Interviews Aux Deux Magots, “la littérature est éternelle” #PrixdesDeuxMagots2023 – Le Prix des Deux Magots, l'une des récompenses littéraires les plus prestigieuses de France, a célébré son 90e anniversaire dans une ambiance festive et solennelle. Étienne de Montety, président du jury, a partagé avec nous l'essence de cette édition mémorable. 25/09/2023, 17:36 À la loupe Interviews Kevin Lambert : l’architecture, 1er art et miroir de l'époque Le jeune romancier Kevin Lambert fait l’actualité de cette rentrée littéraire : d’abord en s’inscrivant avec son troisième roman publié au Nouvel Attila, Que notre joie demeure, dans plusieurs listes de prix, dont celle du Goncourt. Le lauréat 2018 de la plus prestigieuse récompense française, Nicolas Mathieu, a remis une pièce dans la machine en s’étonnant de l’ « orgueil surprenant » avec laquelle l’éditeur du Québécois affirme que son auteur a eu recours à une « Sensitivity reader », « comme s’il s’agissait tout à la fois d’un gage de qualité littéraire, de modernité (rire) et de vertu ». 19/09/2023, 17:36 À la loupe Interviews “Je suis sans cesse rattrapé, happé par la vie.” Né en 1964 au Havre, Jean-François Jacq vit actuellement à Vierzon, où il poursuit une intense activité théâtrale et littéraire. Auteur de plusieurs biographies de rock-stars, de groupes, l’homme dévoile également un parcours de vie à la fois chaotique et douloureux à travers plusieurs livres autobiographiques, aux titres évocateurs (Heurt-limite, Hémorragie à l’errance, etc.). Propos recueillis par Etienne Ruhaud. 19/09/2023, 11:38 Autres articles de la rubrique À la loupe À la loupe Reportages “Nutri-score” et autres projets d’avenir pour une édition écologique D’après Erri de Luca, l’impossible caractérise « ce qui n’a pas encore été fait » (trad. Danièle Valin). La chaîne du livre — mais par cette dénomination, ne réduit-on pas ses acteurs à des maillons ignorants les uns des autres ? — était conviée à une journée de réflexion, ce 29 janvier. Dans les locaux du groupe Bayard, on se réunissait pour « décarboner le livre et l’édition ». 29/01/2024, 20:08 À la loupe Humeurs Au-delà de la polémique Tesson, “faire vivre le Printemps des poètes” « Au-delà des polémiques de toutes sortes, il nous appartient de faire vivre cette édition du Printemps des Poètes coûte que coûte, et de penser d'abord au public », déclarent les cofondateurs des éditions Doucey. Cette réaction intervient peu après l'annonce de la démission de Sophie Nauleau, directrice artistique du Printemps des Poètes. 27/01/2024, 12:21 À la loupe Humeurs Vers le Kirghizistan, à la recherche de la fraicheur perdue #AVeloEntreLesLignes — C'est l'aventure de Zoé David-Rigot et Jaroslav Kocourek, deux cyclistes qui se sont donné pour challenge de rejoindre Oulan-Bator depuis Paris, à la force de leurs cuisses. En chemin, ils visitent autant de librairies qu'ils peuvent. ActuaLitté suit ce périple en publiant leurs récits. 26/01/2024, 14:40 À la loupe Humeurs “Nous croyons que la poésie peut captiver les coeurs” Partout dans le monde, la poésie peut exprimer l'indicible, sans en avoir l'air. Cette puissance en fait aussi une cible de tous les extrêmes, et en particulier des régimes liberticides. Dans un texte prononcé à l'Université de Lille, le 22 mars 2024, la poète, écrivaine et militante des droits des femmes en Afghanistan Somaia Ramish célèbre la poésie et appelle à la défendre, encore et toujours. 05/04/2024, 12:28 À la loupe Tribunes Livres pour malvoyants : “Il ne suffit pas d’agrandir la police de caractères” La Librairie des Grands Caractères, basée dans le 5e arrondissement de Paris, publie ici son « coup de gueule » sur certains éditeurs dont les pratiques lui semblent douteuses. L'établissement pointe notamment le fait que certaines règles à suivre dans l'édition de livres pour malvoyants sont trop régulièrement ignorées par des acteurs du secteur. 02/04/2024, 13:15 À la loupe Reportages Pause soupe de nouilles à minuit : ultimes heures avant la Mongolie #AVeloEntreLesLignes – Partir à la découverte du plus grand nombre de librairies possible, entre Paris et Oulan-Bator, le défi est de taille. À vélo, c'est confirmé : c'est de la folie douce. C’est pourtant l’aventure que Zoé David-Rigot et Jaroslav Kocourek ont démarrée en août 2022. ActuaLitté les accompagne, en publiant leur récit de ce périple, À vélo, entre les lignes. 01/04/2024, 08:03 À la loupe Humeurs “J’habite une maison vieille qui embrasse les formes de mon corps” Carnetdebord – Pour la rentrée littéraire 2024, les éditions du Tripode publieront le nouveau roman d'Audrée Wilhelmy. Pour accompagner cette parution, la romancière a trouvé dans nos colonnes une place à part : un Carnet de Bord pour raconter cette aventure, jusqu'aux librairies. 30/03/2024, 17:05 À la loupe Tribunes Pour un renouveau documentaire dans les universités françaises L'Association des Directeurs et des personnels de direction des Bibliothèques Universitaires et de la Documentation (ADBU) et le Syndicat National de l'Édition (SNE) s'unissent pour interpeller le gouvernement et les autorités sur la nécessité critique d'un élan majeur en faveur des ressources documentaires. Ils insistent sur la nécessité d'investissements immédiats pour assurer le développement d'une documentation universitaire compétitive au niveau européen, et de maintenir la France au cœur des débats scientifiques et éducatifs mondiaux. 27/03/2024, 12:51 À la loupe Tribunes IA : un rapport “équilibré” remis à Emmanuel Macron Alors que la « Commission IA » remettait son rapport au Président de la République le 13 mars 2024, les réactions continuent d'affluer concernant le positionnement de la France face aux enjeux de l'intelligence artificielle. Si des associations de traducteurs telles que En Chair et en Os et l'Association des traducteurs littéraires de France appelaient à sauver « le geste humain », une nouvelle tribune d'un collectif rassemblant divers acteurs des milieux culturels salue, elle, « un rapport équilibré ». 27/03/2024, 10:08 À la loupe Humeurs Peau-de-sang, expérience physique et sensorielle: “Bienvenue, Audrée...” Carnetdebord – Au cours des prochaines semaines, ActuaLitté accueillera le Carnet de Bord d'Audrée Wilhelmy. Romancière québécoise, elle publiera son prochain ouvrage aux éditions du Tripode. Ce seront tout à la fois les récits d'une attente, d'un espoir, d'une envie. Ce seront les récits d'un à-venir. En guise de prélude, Frédéric Martin, fondateur de la maison, nous présente cette autrice, d'ores et déjà adoptée. 27/03/2024, 08:01 À la loupe Reportages Annonciation faite à Dati : les auteurs ressuscitent le rapport Racine Devant la Comédie française, ce 25 mars – date de l'annonce à Marie de sa maternité divine –, ils étaient près de deux cents présents pour le retour d’un vieux compagnon. La première Nuit des auteurs et autrices aura vibré au son des les mariachis qui abreuvaient la place Colette de musiques. La promesse d’un rassemblement politique, collectif et festif était tenue… mais les soirées parisiennes prennent parfois des tournures inattendues. 26/03/2024, 11:56 À la loupe Tribunes “Produire un livre écologique n’est pas possible” La Volte annonce donc son vingtième anniversaire : vingt ans d'aventures éditoriales où se retrouvent des histoires d'émancipation, de la science-fiction sociale et politique, avec une passion pour les jeux de langage. Elle avait déjà annoncé en janvier qu'elle renforcerait cette année son engagement écologique et affirmerait son identité visuelle. Maintenant, place aux projets. 23/03/2024, 15:38 À la loupe Reportages La zone secrète entre Russie et Chine, blague de géographe #AVeloEntreLesLignes – Partir à la découverte du plus grand nombre de librairies possible, entre Paris et Oulan-Bator, le défi est de taille. À vélo, c'est confirmé : c'est de la folie douce. C’est pourtant l’aventure que Zoé David-Rigot et Jaroslav Kocourek ont démarrée en août 2022. ActuaLitté les accompagne, en publiant leur récit de ce périple, À vélo, entre les lignes. 23/03/2024, 15:25 À la loupe Reportages Sacrilège ! Une histoire française de l’offense au pouvoir Aux Archives nationales à l’Hôtel de Soubise, du 20 mars au 1er juillet prochain, plongez au cœur de l'histoire tumultueuse du sacrilège, où le spirituel et le temporel travaillent à ne faire qu’un, mais lequel ? Le dernier discours de Robespierre, l'œil de Léon Gambetta, le testament de Louis XVI… Des trésors historiques et autres documents d'archives inédits, pour une expérience solennelle, et parfois moqueuse, aux frontières du divin et du pouvoir. 22/03/2024, 17:32 À la loupe Tribunes “Faire front commun face à la massification annoncée des IA dans le travail” Après le collectif En Chair et en Os, c'est au tour de l'Association des traducteurs littéraires de France (ATLF) de réagir au rapport, IA : notre ambition pour la France, remis au Président de la République le 13 mars dernier. Ces membres, après l'avoir lu « avec beaucoup de colère », appellent les pouvoirs publics à « ne pas céder aux sirènes de la compétitivité mondiale, et l’ensemble des artistes-auteurs à faire front commun face à la massification annoncée des intelligences artificielles dans leur travail ». 22/03/2024, 13:31 À la loupe Tribunes Bastien Vivès, condamnable ou martyr de la liberté d'expression ? L’Observatoire de la liberté de création (OLC) dénonce « une loi absurde et son application ubuesque » dans l’affaire Bastien Vivès. Dans une tribune, ses membres justifient leur positionnement : à chacun de se faire un point de vue... 22/03/2024, 11:26 À la loupe Tribunes Pour une traduction humaine : “Il en va de l'avenir de nos professions” Quelques jours après la présentation du rapport de la commission IA au Président de la République, qui en salue les recommandations prônant le tout-IA dans de nombreux domaines, le collectif En Chair et en Os, « pour une traduction humaine », s'adresse aujourd'hui à toute l'édition, et appelle le monde du livre et de la culture à se mobiliser pour préserver le geste humain, sans céder au technosolutionnisme. 18/03/2024, 11:42 À la loupe Reportages De l'Altaï russe à la Mongolie en passant par l'édition kirghize #AVeloEntreLesLignes — Zoé David-Rigot et Jaroslav Kocourek ont entrepris un voyage en vélo entre Paris et Oulan-Bator en août 2022, avec l'objectif de visiter le maximum de librairies sur leur route. ActuaLitté documentera cette expédition en publiant le récit intitulé "À vélo, entre les lignes". 17/03/2024, 12:13 À la loupe Tribunes Expression, publication, lecture : des libertés à défendre Depuis la Foire du Livre de Londres, cinq organisations internationales représentant les auteurs, éditeurs, libraires et bibliothécaires cosignent une déclaration. Ce texte, reproduit en intégralité ci-dessous, constitue un appel aux gouvernements et aux sociétés dans leur ensemble à veiller sur des libertés fondamentales autour des textes et de leurs auteurs : expression, publication et lecture. 14/03/2024, 11:14 À la loupe Tribunes Traduire par l'IA, le risque d'“un appauvrissement sensible de la langue” Face à la montée de l'intelligence artificielle dans le domaine de la traduction, l'Association des Autrices et Auteurs de Suisse (AdS) tire la sonnette d'alarme. Lors de son 15e Symposium suisse, l'association a publié une prise de position vigoureuse, soulignant les limites de l'IA en matière de traduction littéraire et réclamant une régulation claire pour protéger les droits et la valeur du travail humain. 06/03/2024, 12:54 À la loupe Enquêtes Moon Knight, justicier lunaire et passablement tordu L’identité secrète est le propre du super héros – ça et les collants trop moulants. Apparu dans Werewolf by Night #32 en 1975, Marc Spector fêtera ses 50 ans de lutte contre le crime à New York : il protège les voyageurs, chers au dieu égyptien qui l’a choisi pour avatar. Non sans l’avoir sauvé de la mort. Mais ce personnage, atteint d’un trouble dissociatif, coexiste mentalement avec trois autres personnes. De quoi en faire un justicier atypique, dont les méthodes effraient. 06/03/2024, 12:16 À la loupe Reportages Où en est la lecture dans les campagnes françaises de 2024 ? En février 1967, l'ORTF diffusait un numéro de sa Bibliothèque de poche, dans lequel le journaliste disparu en 2012, Michel Polac, partait à la rencontre de bergers pour discuter de leurs lectures. ActuaLitté reprend le principe à l'occasion du Salon de l'Agriculture, en interrogeant des acteurs du secteur primaire, afin de vérifier : où en est le rapport au livre dans les campagnes de 2024 ? 01/03/2024, 18:53 À la loupe Edito Plutôt BFM que CNews : Isabelle Saporta, bientôt la porte ? Dans quel monde une salariée dénigrerait publiquement l’une des sociétés de son employeur, sans se faire tirer l’oreille ? Mieux : présenterait comme plus brillante une entreprise concurrente, du même secteur d’activité ? Eh bien… soit les anti-Bolloré reverront leur copie quant aux “méthodes” (censure, liberté de parole brimée, etc.) chez Vivendi… Soit Isabelle Saporta prépare son départ de chez Fayard ? 29/02/2024, 15:42 À la loupe Tribunes "Les IA génératives menacent aujourd’hui l’activité des auteurs des arts visuels" L'ADAGP l'affirme : « Les systèmes d’intelligence artificielle (IA) générative, capables de produire instantanément des contenus visuels à la demande des utilisateurs, menacent aujourd’hui l’activité des auteurs des arts visuels. » En réaction à ce constat, la société de perception et de répartition des droits d'auteur a publié une déclaration générale d’opposition. Elle s'explique dans un communiqué, reproduit ici par ActuaLitté. 23/02/2024, 17:08 À la loupe Tests Librimania : le jeu que toute l'édition va s'arracher #Noshorizonsdesirables – Foin des IUT et autres Masters pros Métiers du livre : voici le futur compagnon et prochain best-seller en librairie — s’il est un jour commercialisé — Librimania plonge les joueurs dans l’univers impitoyable… du monde du livre. Accrochez-vous à un dictionnaire ou une encyclopédie, ça décoiffe ! 21/02/2024, 19:22 À la loupe Tribunes Mort d'Alexeï Navalny : “Il n’a jamais reculé devant le pouvoir” Le décès d’Alexeï Navalny, survenu ce 16 février au centre pénitentiaire de Kharp à l'âge de 47 ans, provoque un soulèvement — et les regards fusent vers Vladimir Poutine, qui se serait définitivement débarrassé d’un opposant. Le Pen Club français a diffusé un hommage, ici proposé en intégralité. 17/02/2024, 10:49 À la loupe Humeurs Une nuit dans une yourte kirghize, bercés par la pluie #AVeloEntreLesLignes — Partis à la conquête de nouveaux horizons, Zoé David-Rigot et Jaroslav Kocourek pédalent à travers une odyssée littéraire. Leur défi ? Explorer le plus grand nombre possible de librairies sur un itinéraire qui les mène à vélo de Paris jusqu'à Oulan-Bator. Ils partagent avec ActuaLitté leurs aventures et découvertes dans ce journal de voyage. 16/02/2024, 15:24 À la loupe Tribunes L'étude sur le partage de la valeur du SNE, “un éclairage partiel et biaisé” Dévoilée le 1er février dernier, l'étude sur le partage de la valeur du livre, commandée par le Syndicat national de l'édition, n'a pas vraiment convaincu. La quasi-totalité des organisations d'auteurs ont dénoncé ses résultats, assimilés à une pure et simple tentative de manipulation. L'Association des traducteurs littéraires français (ATLF) ajoute sa voix revendicative, dans un texte reproduit ci-dessous. 15/02/2024, 10:03 À la loupe Tribunes Une étude sur les revenus qui “ne reflète en rien la réalité” des auteurs Le Syndicat national de l'édition, organisation patronale du secteur, a présenté le 1er février les données de son étude sur le partage de la valeur du livre entre les maisons d'édition et les auteurs. Une étude dont les méthodes et la présentation des résultats ont été largement décriées par les auteurs et leurs représentants. Le Conseil Permanent des Écrivains (CPE), dans un texte reproduit ci-dessous, signifie ses propres réserves, mais aussi ses attentes vis-à-vis du ministère de la Culture. 14/02/2024, 11:46 À la loupe Humeurs À vélo entre les montagnes et les yourtes #AVeloEntreLesLignes — Zoé David-Rigot et Jaroslav Kocourek se sont lancés dans une aventure exceptionnelle, celle de parcourir la distance entre Paris et Oulan-Bator à vélo. Tout au long de leur parcours, ils font escale dans autant de librairies que possible. Leur odyssée est couverte par ActuaLitté, qui partage leurs histoires au fur et à mesure. 14/02/2024, 10:33 À la loupe Humeurs Livres audio : saga, c'est plus fort que toi Dans un nouvel article, Nathan Hull, responsable de la stratégie de Beat Technology, s'intéresse aux sagas littéraires et à leur capacité à captiver les lecteurs sur le long terme. Comment expliquer ce succès durable ? Et, surtout, comment le reproduire dans un domaine bien particulier, celui du livre audio numérique ? 13/02/2024, 12:48 À la loupe Humeurs “Il faut tenir sur le fil, à la frontière, et c’est de là que nait la littérature” #PrixFrontieres2024 – L'édition 2024 du prix Frontières a été lancée, avec la liste des 10 titres retenus. La lauréate de 2023, la romancière Dima Abdallah avait été été saluée pour son deuxième roman Bleu nuit aux éditions Sabine Wespieser. Présidente d'honneur du jury de cette édition 2024, elle nous délivre un texte, en exclusivité pour ActuaLitté, sur ce terme étrange... frontières... 12/02/2024, 16:35 À la loupe Edito Durant les JO, il est important de rester à Paris... en télétravail Les usagers occasionnels du métro parisien n’ont pas manqué la campagne de communication orchestrée dans les rames : l’invitation au RTT – Reste chez Toi Travailler. À l’approche des Jeux olympiques, les injonctions contradictoires pleuvent : rester ou ne pas rester sur Paris, prendre ou ne pas prendre les transports, travailler ou ne pas travailler… On ne fait pas d’Hamlet, sans casser des noeuds…. 12/02/2024, 14:46 À la loupe Tribunes “La juste rémunération des auteurs et autrices est cruciale” La Ligue des auteurs professionnels a pris connaissance de l'étude du Syndicat National de l'Édition (SNE) publiée le 1er février dernier. Dans une tribune adressée à ActuaLitté, l'organisation remet en cause la méthodologie, déjà amplement pointée. Leur texte est ici diffusé dans son intégralité. 06/02/2024, 11:03 À la loupe Tribunes L'étude irréelle où “les éditeurs sont moins payés que les auteurs” Au moment même où l’Europe envisage de légiférer sur un statut professionnel pour les auteurs, incluant notamment de meilleures rémunérations et une lutte contre les contrats abusifs, le Syndicat national de l’édition a publié une enquête sur « le partage de la valeur entre auteurs et éditeurs ». Or, la présentation des données a révélé un biais tel qu’il laisse entendre que les éditeurs sont moins bien payés que les auteurs. La Charte des auteurs et illustrateurs jeunesse réagit dans les colonnes de ActuaLitté. 04/02/2024, 10:15 À la loupe Tribunes L'industrie du livre redoute le projet européen sur les délais de paiement En Belgique, l'interprofession s'est regroupée pour interpeller les députés européens, sur la question des retards de paiements. Le projet qu’examinent en effet le Parlement et le Conseil ramènerait à 30 jours le délai maximum. Une modification que l’industrie du livre ne supportera pas sans de lourdes conséquences. 31/01/2024, 10:19 À la loupe Reportages “Nutri-score” et autres projets d’avenir pour une édition écologique D’après Erri de Luca, l’impossible caractérise « ce qui n’a pas encore été fait » (trad. Danièle Valin). La chaîne du livre — mais par cette dénomination, ne réduit-on pas ses acteurs à des maillons ignorants les uns des autres ? — était conviée à une journée de réflexion, ce 29 janvier. Dans les locaux du groupe Bayard, on se réunissait pour « décarboner le livre et l’édition ». 29/01/2024, 20:08 À la loupe Humeurs Au-delà de la polémique Tesson, “faire vivre le Printemps des poètes” « Au-delà des polémiques de toutes sortes, il nous appartient de faire vivre cette édition du Printemps des Poètes coûte que coûte, et de penser d'abord au public », déclarent les cofondateurs des éditions Doucey. Cette réaction intervient peu après l'annonce de la démission de Sophie Nauleau, directrice artistique du Printemps des Poètes. 27/01/2024, 12:21 À la loupe Humeurs Vers le Kirghizistan, à la recherche de la fraicheur perdue #AVeloEntreLesLignes — C'est l'aventure de Zoé David-Rigot et Jaroslav Kocourek, deux cyclistes qui se sont donné pour challenge de rejoindre Oulan-Bator depuis Paris, à la force de leurs cuisses. En chemin, ils visitent autant de librairies qu'ils peuvent. ActuaLitté suit ce périple en publiant leurs récits. 26/01/2024, 14:40 À la loupe Humeurs “Nous croyons que la poésie peut captiver les coeurs” Partout dans le monde, la poésie peut exprimer l'indicible, sans en avoir l'air. Cette puissance en fait aussi une cible de tous les extrêmes, et en particulier des régimes liberticides. Dans un texte prononcé à l'Université de Lille, le 22 mars 2024, la poète, écrivaine et militante des droits des femmes en Afghanistan Somaia Ramish célèbre la poésie et appelle à la défendre, encore et toujours. 05/04/2024, 12:28 À la loupe Tribunes Livres pour malvoyants : “Il ne suffit pas d’agrandir la police de caractères” La Librairie des Grands Caractères, basée dans le 5e arrondissement de Paris, publie ici son « coup de gueule » sur certains éditeurs dont les pratiques lui semblent douteuses. L'établissement pointe notamment le fait que certaines règles à suivre dans l'édition de livres pour malvoyants sont trop régulièrement ignorées par des acteurs du secteur. 02/04/2024, 13:15 À la loupe Reportages Pause soupe de nouilles à minuit : ultimes heures avant la Mongolie #AVeloEntreLesLignes – Partir à la découverte du plus grand nombre de librairies possible, entre Paris et Oulan-Bator, le défi est de taille. À vélo, c'est confirmé : c'est de la folie douce. C’est pourtant l’aventure que Zoé David-Rigot et Jaroslav Kocourek ont démarrée en août 2022. ActuaLitté les accompagne, en publiant leur récit de ce périple, À vélo, entre les lignes. 01/04/2024, 08:03 À la loupe Humeurs “J’habite une maison vieille qui embrasse les formes de mon corps” Carnetdebord – Pour la rentrée littéraire 2024, les éditions du Tripode publieront le nouveau roman d'Audrée Wilhelmy. Pour accompagner cette parution, la romancière a trouvé dans nos colonnes une place à part : un Carnet de Bord pour raconter cette aventure, jusqu'aux librairies. 30/03/2024, 17:05 À la loupe Tribunes Pour un renouveau documentaire dans les universités françaises L'Association des Directeurs et des personnels de direction des Bibliothèques Universitaires et de la Documentation (ADBU) et le Syndicat National de l'Édition (SNE) s'unissent pour interpeller le gouvernement et les autorités sur la nécessité critique d'un élan majeur en faveur des ressources documentaires. Ils insistent sur la nécessité d'investissements immédiats pour assurer le développement d'une documentation universitaire compétitive au niveau européen, et de maintenir la France au cœur des débats scientifiques et éducatifs mondiaux. 27/03/2024, 12:51 À la loupe Tribunes IA : un rapport “équilibré” remis à Emmanuel Macron Alors que la « Commission IA » remettait son rapport au Président de la République le 13 mars 2024, les réactions continuent d'affluer concernant le positionnement de la France face aux enjeux de l'intelligence artificielle. Si des associations de traducteurs telles que En Chair et en Os et l'Association des traducteurs littéraires de France appelaient à sauver « le geste humain », une nouvelle tribune d'un collectif rassemblant divers acteurs des milieux culturels salue, elle, « un rapport équilibré ». 27/03/2024, 10:08 À la loupe Humeurs Peau-de-sang, expérience physique et sensorielle: “Bienvenue, Audrée...” Carnetdebord – Au cours des prochaines semaines, ActuaLitté accueillera le Carnet de Bord d'Audrée Wilhelmy. Romancière québécoise, elle publiera son prochain ouvrage aux éditions du Tripode. Ce seront tout à la fois les récits d'une attente, d'un espoir, d'une envie. Ce seront les récits d'un à-venir. En guise de prélude, Frédéric Martin, fondateur de la maison, nous présente cette autrice, d'ores et déjà adoptée. 27/03/2024, 08:01 À la loupe Reportages Annonciation faite à Dati : les auteurs ressuscitent le rapport Racine Devant la Comédie française, ce 25 mars – date de l'annonce à Marie de sa maternité divine –, ils étaient près de deux cents présents pour le retour d’un vieux compagnon. La première Nuit des auteurs et autrices aura vibré au son des les mariachis qui abreuvaient la place Colette de musiques. La promesse d’un rassemblement politique, collectif et festif était tenue… mais les soirées parisiennes prennent parfois des tournures inattendues. 26/03/2024, 11:56 À la loupe Tribunes “Produire un livre écologique n’est pas possible” La Volte annonce donc son vingtième anniversaire : vingt ans d'aventures éditoriales où se retrouvent des histoires d'émancipation, de la science-fiction sociale et politique, avec une passion pour les jeux de langage. Elle avait déjà annoncé en janvier qu'elle renforcerait cette année son engagement écologique et affirmerait son identité visuelle. Maintenant, place aux projets. 23/03/2024, 15:38 À la loupe Reportages La zone secrète entre Russie et Chine, blague de géographe #AVeloEntreLesLignes – Partir à la découverte du plus grand nombre de librairies possible, entre Paris et Oulan-Bator, le défi est de taille. À vélo, c'est confirmé : c'est de la folie douce. C’est pourtant l’aventure que Zoé David-Rigot et Jaroslav Kocourek ont démarrée en août 2022. ActuaLitté les accompagne, en publiant leur récit de ce périple, À vélo, entre les lignes. 23/03/2024, 15:25 À la loupe Reportages Sacrilège ! Une histoire française de l’offense au pouvoir Aux Archives nationales à l’Hôtel de Soubise, du 20 mars au 1er juillet prochain, plongez au cœur de l'histoire tumultueuse du sacrilège, où le spirituel et le temporel travaillent à ne faire qu’un, mais lequel ? Le dernier discours de Robespierre, l'œil de Léon Gambetta, le testament de Louis XVI… Des trésors historiques et autres documents d'archives inédits, pour une expérience solennelle, et parfois moqueuse, aux frontières du divin et du pouvoir. 22/03/2024, 17:32 À la loupe Tribunes “Faire front commun face à la massification annoncée des IA dans le travail” Après le collectif En Chair et en Os, c'est au tour de l'Association des traducteurs littéraires de France (ATLF) de réagir au rapport, IA : notre ambition pour la France, remis au Président de la République le 13 mars dernier. Ces membres, après l'avoir lu « avec beaucoup de colère », appellent les pouvoirs publics à « ne pas céder aux sirènes de la compétitivité mondiale, et l’ensemble des artistes-auteurs à faire front commun face à la massification annoncée des intelligences artificielles dans leur travail ». 22/03/2024, 13:31 À la loupe Tribunes Bastien Vivès, condamnable ou martyr de la liberté d'expression ? L’Observatoire de la liberté de création (OLC) dénonce « une loi absurde et son application ubuesque » dans l’affaire Bastien Vivès. Dans une tribune, ses membres justifient leur positionnement : à chacun de se faire un point de vue... 22/03/2024, 11:26 À la loupe Tribunes Pour une traduction humaine : “Il en va de l'avenir de nos professions” Quelques jours après la présentation du rapport de la commission IA au Président de la République, qui en salue les recommandations prônant le tout-IA dans de nombreux domaines, le collectif En Chair et en Os, « pour une traduction humaine », s'adresse aujourd'hui à toute l'édition, et appelle le monde du livre et de la culture à se mobiliser pour préserver le geste humain, sans céder au technosolutionnisme. 18/03/2024, 11:42 À la loupe Reportages De l'Altaï russe à la Mongolie en passant par l'édition kirghize #AVeloEntreLesLignes — Zoé David-Rigot et Jaroslav Kocourek ont entrepris un voyage en vélo entre Paris et Oulan-Bator en août 2022, avec l'objectif de visiter le maximum de librairies sur leur route. ActuaLitté documentera cette expédition en publiant le récit intitulé "À vélo, entre les lignes". 17/03/2024, 12:13 À la loupe Tribunes Expression, publication, lecture : des libertés à défendre Depuis la Foire du Livre de Londres, cinq organisations internationales représentant les auteurs, éditeurs, libraires et bibliothécaires cosignent une déclaration. Ce texte, reproduit en intégralité ci-dessous, constitue un appel aux gouvernements et aux sociétés dans leur ensemble à veiller sur des libertés fondamentales autour des textes et de leurs auteurs : expression, publication et lecture. 14/03/2024, 11:14 À la loupe Tribunes Traduire par l'IA, le risque d'“un appauvrissement sensible de la langue” Face à la montée de l'intelligence artificielle dans le domaine de la traduction, l'Association des Autrices et Auteurs de Suisse (AdS) tire la sonnette d'alarme. Lors de son 15e Symposium suisse, l'association a publié une prise de position vigoureuse, soulignant les limites de l'IA en matière de traduction littéraire et réclamant une régulation claire pour protéger les droits et la valeur du travail humain. 06/03/2024, 12:54 À la loupe Enquêtes Moon Knight, justicier lunaire et passablement tordu L’identité secrète est le propre du super héros – ça et les collants trop moulants. Apparu dans Werewolf by Night #32 en 1975, Marc Spector fêtera ses 50 ans de lutte contre le crime à New York : il protège les voyageurs, chers au dieu égyptien qui l’a choisi pour avatar. Non sans l’avoir sauvé de la mort. Mais ce personnage, atteint d’un trouble dissociatif, coexiste mentalement avec trois autres personnes. De quoi en faire un justicier atypique, dont les méthodes effraient. 06/03/2024, 12:16 À la loupe Reportages Où en est la lecture dans les campagnes françaises de 2024 ? En février 1967, l'ORTF diffusait un numéro de sa Bibliothèque de poche, dans lequel le journaliste disparu en 2012, Michel Polac, partait à la rencontre de bergers pour discuter de leurs lectures. ActuaLitté reprend le principe à l'occasion du Salon de l'Agriculture, en interrogeant des acteurs du secteur primaire, afin de vérifier : où en est le rapport au livre dans les campagnes de 2024 ? 01/03/2024, 18:53 À la loupe Edito Plutôt BFM que CNews : Isabelle Saporta, bientôt la porte ? Dans quel monde une salariée dénigrerait publiquement l’une des sociétés de son employeur, sans se faire tirer l’oreille ? Mieux : présenterait comme plus brillante une entreprise concurrente, du même secteur d’activité ? Eh bien… soit les anti-Bolloré reverront leur copie quant aux “méthodes” (censure, liberté de parole brimée, etc.) chez Vivendi… Soit Isabelle Saporta prépare son départ de chez Fayard ? 29/02/2024, 15:42 À la loupe Tribunes "Les IA génératives menacent aujourd’hui l’activité des auteurs des arts visuels" L'ADAGP l'affirme : « Les systèmes d’intelligence artificielle (IA) générative, capables de produire instantanément des contenus visuels à la demande des utilisateurs, menacent aujourd’hui l’activité des auteurs des arts visuels. » En réaction à ce constat, la société de perception et de répartition des droits d'auteur a publié une déclaration générale d’opposition. Elle s'explique dans un communiqué, reproduit ici par ActuaLitté. 23/02/2024, 17:08 À la loupe Tests Librimania : le jeu que toute l'édition va s'arracher #Noshorizonsdesirables – Foin des IUT et autres Masters pros Métiers du livre : voici le futur compagnon et prochain best-seller en librairie — s’il est un jour commercialisé — Librimania plonge les joueurs dans l’univers impitoyable… du monde du livre. Accrochez-vous à un dictionnaire ou une encyclopédie, ça décoiffe ! 21/02/2024, 19:22 À la loupe Tribunes Mort d'Alexeï Navalny : “Il n’a jamais reculé devant le pouvoir” Le décès d’Alexeï Navalny, survenu ce 16 février au centre pénitentiaire de Kharp à l'âge de 47 ans, provoque un soulèvement — et les regards fusent vers Vladimir Poutine, qui se serait définitivement débarrassé d’un opposant. Le Pen Club français a diffusé un hommage, ici proposé en intégralité. 17/02/2024, 10:49 À la loupe Humeurs Une nuit dans une yourte kirghize, bercés par la pluie #AVeloEntreLesLignes — Partis à la conquête de nouveaux horizons, Zoé David-Rigot et Jaroslav Kocourek pédalent à travers une odyssée littéraire. Leur défi ? Explorer le plus grand nombre possible de librairies sur un itinéraire qui les mène à vélo de Paris jusqu'à Oulan-Bator. Ils partagent avec ActuaLitté leurs aventures et découvertes dans ce journal de voyage. 16/02/2024, 15:24 À la loupe Tribunes L'étude sur le partage de la valeur du SNE, “un éclairage partiel et biaisé” Dévoilée le 1er février dernier, l'étude sur le partage de la valeur du livre, commandée par le Syndicat national de l'édition, n'a pas vraiment convaincu. La quasi-totalité des organisations d'auteurs ont dénoncé ses résultats, assimilés à une pure et simple tentative de manipulation. L'Association des traducteurs littéraires français (ATLF) ajoute sa voix revendicative, dans un texte reproduit ci-dessous. 15/02/2024, 10:03 À la loupe Tribunes Une étude sur les revenus qui “ne reflète en rien la réalité” des auteurs Le Syndicat national de l'édition, organisation patronale du secteur, a présenté le 1er février les données de son étude sur le partage de la valeur du livre entre les maisons d'édition et les auteurs. Une étude dont les méthodes et la présentation des résultats ont été largement décriées par les auteurs et leurs représentants. Le Conseil Permanent des Écrivains (CPE), dans un texte reproduit ci-dessous, signifie ses propres réserves, mais aussi ses attentes vis-à-vis du ministère de la Culture. 14/02/2024, 11:46 À la loupe Humeurs À vélo entre les montagnes et les yourtes #AVeloEntreLesLignes — Zoé David-Rigot et Jaroslav Kocourek se sont lancés dans une aventure exceptionnelle, celle de parcourir la distance entre Paris et Oulan-Bator à vélo. Tout au long de leur parcours, ils font escale dans autant de librairies que possible. Leur odyssée est couverte par ActuaLitté, qui partage leurs histoires au fur et à mesure. 14/02/2024, 10:33 À la loupe Humeurs Livres audio : saga, c'est plus fort que toi Dans un nouvel article, Nathan Hull, responsable de la stratégie de Beat Technology, s'intéresse aux sagas littéraires et à leur capacité à captiver les lecteurs sur le long terme. Comment expliquer ce succès durable ? Et, surtout, comment le reproduire dans un domaine bien particulier, celui du livre audio numérique ? 13/02/2024, 12:48 À la loupe Humeurs “Il faut tenir sur le fil, à la frontière, et c’est de là que nait la littérature” #PrixFrontieres2024 – L'édition 2024 du prix Frontières a été lancée, avec la liste des 10 titres retenus. La lauréate de 2023, la romancière Dima Abdallah avait été été saluée pour son deuxième roman Bleu nuit aux éditions Sabine Wespieser. Présidente d'honneur du jury de cette édition 2024, elle nous délivre un texte, en exclusivité pour ActuaLitté, sur ce terme étrange... frontières... 12/02/2024, 16:35 À la loupe Edito Durant les JO, il est important de rester à Paris... en télétravail Les usagers occasionnels du métro parisien n’ont pas manqué la campagne de communication orchestrée dans les rames : l’invitation au RTT – Reste chez Toi Travailler. À l’approche des Jeux olympiques, les injonctions contradictoires pleuvent : rester ou ne pas rester sur Paris, prendre ou ne pas prendre les transports, travailler ou ne pas travailler… On ne fait pas d’Hamlet, sans casser des noeuds…. 12/02/2024, 14:46 À la loupe Tribunes “La juste rémunération des auteurs et autrices est cruciale” La Ligue des auteurs professionnels a pris connaissance de l'étude du Syndicat National de l'Édition (SNE) publiée le 1er février dernier. Dans une tribune adressée à ActuaLitté, l'organisation remet en cause la méthodologie, déjà amplement pointée. Leur texte est ici diffusé dans son intégralité. 06/02/2024, 11:03 À la loupe Tribunes L'étude irréelle où “les éditeurs sont moins payés que les auteurs” Au moment même où l’Europe envisage de légiférer sur un statut professionnel pour les auteurs, incluant notamment de meilleures rémunérations et une lutte contre les contrats abusifs, le Syndicat national de l’édition a publié une enquête sur « le partage de la valeur entre auteurs et éditeurs ». Or, la présentation des données a révélé un biais tel qu’il laisse entendre que les éditeurs sont moins bien payés que les auteurs. La Charte des auteurs et illustrateurs jeunesse réagit dans les colonnes de ActuaLitté. 04/02/2024, 10:15 À la loupe Tribunes L'industrie du livre redoute le projet européen sur les délais de paiement En Belgique, l'interprofession s'est regroupée pour interpeller les députés européens, sur la question des retards de paiements. Le projet qu’examinent en effet le Parlement et le Conseil ramènerait à 30 jours le délai maximum. Une modification que l’industrie du livre ne supportera pas sans de lourdes conséquences. 31/01/2024, 10:19 À la loupe Reportages “Nutri-score” et autres projets d’avenir pour une édition écologique D’après Erri de Luca, l’impossible caractérise « ce qui n’a pas encore été fait » (trad. Danièle Valin). La chaîne du livre — mais par cette dénomination, ne réduit-on pas ses acteurs à des maillons ignorants les uns des autres ? — était conviée à une journée de réflexion, ce 29 janvier. Dans les locaux du groupe Bayard, on se réunissait pour « décarboner le livre et l’édition ». 29/01/2024, 20:08 À la loupe Humeurs Au-delà de la polémique Tesson, “faire vivre le Printemps des poètes” « Au-delà des polémiques de toutes sortes, il nous appartient de faire vivre cette édition du Printemps des Poètes coûte que coûte, et de penser d'abord au public », déclarent les cofondateurs des éditions Doucey. Cette réaction intervient peu après l'annonce de la démission de Sophie Nauleau, directrice artistique du Printemps des Poètes. 27/01/2024, 12:21 À la loupe Humeurs Vers le Kirghizistan, à la recherche de la fraicheur perdue #AVeloEntreLesLignes — C'est l'aventure de Zoé David-Rigot et Jaroslav Kocourek, deux cyclistes qui se sont donné pour challenge de rejoindre Oulan-Bator depuis Paris, à la force de leurs cuisses. En chemin, ils visitent autant de librairies qu'ils peuvent. ActuaLitté suit ce périple en publiant leurs récits. 26/01/2024, 14:40 Top Articles La suite de Shōgun, la saga culte derrière la série Disney La Grande Librairie : ce que “partir” veut dire Le Prix des Libraires 2024 dévoile sa liste finale Étude Babelio : les lecteurs de romance en France Lettre d'information Flux RSS Contact Qui sommes nous ? Mentions légales Connexion Politique de confidentialité Charte commentaires Furet.com Decitre.fr Edistat Publier un livre Depositphotos Tendances et Célébrités © 2007 - 2024 - Actualitte.com. Tous droits réservés.
Rappel de la source primaire
-
-
academic.oup.com academic.oup.com
-
This suggests that contemporaries regarded physical injuries as a species of insult; just as lying with a man’s female slave was an affront to his honour, so too was breaking his rib.28
So rather than having offences within Æthelberhts code. it would be more proper to refer to them as being insults, for which a compensatory sum was attached.
-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
The following is the authors’ response to the original reviews.
eLife assessment
This fundamental study provides an unprecedented understanding of the roles of different combinations of NaV channel isoforms in nociceptors' excitability, with relevance for the design of better strategies targeting NaV channels to treat pain. Although the experimental combination of electrophysiological, modeling, imaging, molecular biology, and behavioral data is convincing and supports the major claims of the work, some conclusions need to be strengthened by further evidence or discussion. The work may be of broad interest to scientists working on pain, drug development, neuronal excitability, and ion channels.
Reviewer #1 (Public Review):
Summary:
In this work, Xie, Prescott, and colleagues have reevaluated the role of Nav1.7 in nociceptive sensory neuron excitability. They find that nociceptors can make use of different sodium channel subtypes to reach equivalent excitability. The existence of this degeneracy is critical to understanding neuronal physiology under normal and pathological conditions and could explain why Nav subtype-selective drugs have failed in clinical trials. More concretely, nociceptor repetitive spiking relies on Nav1.8 at DIV0 (and probably under normal conditions in vivo), but on Nav1.7 and Nav1.3 at DIV4-7 (and after inflammation in vivo).
The conclusions of this paper are mostly well supported by data, and these findings should be of broad interest to scientists working on pain, drug development, neuronal excitability, and ion channels.
Strengths:
(1.1) The authors have employed elegant electrophysiology experiments (including specific pharmacology and dynamic clamp) and computational simulations to study the excitability of a subpopulation of DRGs that would very likely match with nociceptors (they take advantage of using transgenic mice to detect Nav1.8-expressing neurons). They make a strong point showing the degeneracy that occurs at the ion channel expression level in nociceptors, adding this new data to previous observations in other neuronal types. They also demonstrate that the different Nav subtypes functionally overlap and are able to interchange their "typical" roles in action potential generation. As Xie, Prescott, and colleagues argue, the functional implications of the degenerate character of nociceptive sensory neuron excitability need to be seriously taken into account regarding drug development and clinical trials with Nav subtype-selective inhibitors.
Weaknesses:
(1.2) The next comments are minor criticisms, as the major conclusions of the paper are well substantiated. Most of the results presented in the article have been obtained from experiments with DRG neuron cultures, and surely there is a greater degree of complexity and heterogeneity about the degeneracy of nociceptors excitability in the "in vivo" condition. Indeed, the authors show in Figures 7 and 8 data that support their hypothesis and an increased Nav1.7's influence on nociceptor excitability after inflammation, but also a higher variability in the nociceptors spiking responses. On the other hand, DRG neurons targeted in this study (YFP (+) after crossing with Nav1.8-Cre mice) are >90% nociceptors, but not all nociceptors express Nav1.8 in vivo. As shown by Li et al., 2016 ("Somatosensory neuron types identified by high-coverage single-cell RNA-sequencing and functional heterogeneity"), there is a high heterogeneity of neuron subtypes within sensory neurons. Therefore, some caution should be taken when translating the results obtained with the DRG neuron cultures to the more complex "in vivo" panorama.
We agree that most but not all Nav1.8+ DRG cells are nociceptors and that not all nociceptors express Nav1.8. We targeted small neurons that also express (or at some point expressed) Nav1.8, thus excluding larger neurons that express Nav1.8. This allowed us to hone in on a relatively homogeneous set of neurons, which is crucial when testing different neurons to compare between conditions (as opposed to testing longitudinally in the same neuron, which is not feasible). We expect all neurons are degenerate but likely on the basis of different ion channel combinations. Indeed, even within small Nav1.8+ neurons, other channels that we did not consider likely contribute to the degenerate regulation (as now better reflected in the revised Discussion).
That said, there are multiple sources of heterogeneity. We suspect that heterogeneity is more increased after inflammation than after axotomy because all DRG neurons experience axotomy when cultured whereas neurons experience inflammation differently in vivo depending on whether their axon innervates the inflamed area (now explained on lines 214-215). This is not so much about whether the insult occurs in vivo or in vitro, but about how homogeneously neurons are affected by the insult. Granted, neurons are indeed more likely to be heterogeneously affected in vivo since conditions are more complex. But our goal in testing PF-71 in behavioral tests (Fig. 8) was to show that changes observed in nociceptor excitability in Figure 7, despite heterogeneity, were predictive of changes in drug efficacy. In short, we establish Nav interchangeability by comparing neurons in culture (Figs 1-6), but we then show that similar Nav shifts can develop in vivo (Fig 7) with implications for drug efficacy (Fig 8). Such results should alert readers to the importance of degeneracy for drug efficacy (which is our main goal) even without a complete picture of nociceptor degeneracy or DRG neuron heterogeneity. Additions to the Discussion (lines 248-259, 304-308) are intended to highlight these considerations.
(1.3) Although the authors have focused their attention on Nav channels, it should be noted that degeneracy concerning other ion channels (such as potassium ion channels) could also impact the nociceptor excitability. The action potential AHP in Figure 1, panel A is very different comparing the DIV0 (blue) and DIV4-7 examples. Indeed, the conductance density values for the AHP current are higher at DIV0 than at DIV7 in the computational model (supplementary table 5). The role of other ion channels in order to obtain equivalent excitability should not be underestimated.
We completely agree. We focused on Nav channels because of our initial observation with TTX and because of industry’s efforts to develop Nav subtype-selective inhibitors, whose likelihood of success is affected by the changes we report. But other channels are presumably changing, especially given observed changes in the AHP shape (now mentioned on lines 304-308). Investigation should be expanded to include these other channels in future studies.
Reviewer #2 (Public Review):
Summary:
The authors have noted in preliminary work that tetrodotoxin (TTX), which inhibits NaV1.7 and several other TTX-sensitive sodium channels, has differential effects on nociceptors, dramatically reducing their excitability under certain conditions but not under others. Partly because of this coincidental observation, the aim of the present work was to re-examine or characterize the role of NaV1.7 in nociceptor excitability and its effects on drug efficacy. The manuscript demonstrates that a NaV1.7-selective inhibitor produces analgesia only when nociceptor excitability is based on NaV1.7. More generally and comprehensively, the results show that nociceptors can achieve equivalent excitability through changes in differential NaV inactivation and NaV expression of different NaV subtypes (NaV 1.3/1.7 and 1.8). This can cause widespread changes in the role of a particular subtype over time. The degenerate nature of nociceptor excitability shows functional implications that make the assignment of pathological changes to a particular NaV subtype difficult or even impossible.
Thus, the analgesic efficacy of NaV1.7- or NaV1.8-selective agents depends essentially on which NaV subtype controls excitability at a given time point. These results explain, at least in part, the poor clinical outcomes with the use of subtype-selective NaV inhibitors and therefore have major implications for the future development of Nav-selective analgesics.
Strengths:
(2.1) The above results are clearly and impressively supported by the experiments and data shown. All methods are described in detail, presumably allow good reproducibility, and were suitable to address the corresponding question. The only exception is the description of the computer model, which should be described in more detail.
We failed to report basic information such as the software, integration method and time step in the original text. This information is now provided on lines 476-477. Notably, the full code is available on ModelDB plus all equations including the values for all gating parameters are provided in Supplementary Table 5 and values for maximal conductance densities for DIV0 and DIV7 models are provided in Supplementary Table 6. Changes in conductance densities to simulate different pharmacological conditions are reported in the relevant figure legends (now shown in red). We did not include model details in the main text to avoid disrupting the flow of the presentation, but all the model details are reported in the Methods, tables and/or figure legends.
(2.2) The results showing that nociceptors can achieve equivalent excitability through changes in differential NaV inactivation and expression of different NaV subtypes are of great importance in the fields of basic and clinical pain research and sodium channel physiology and pharmacology, but also for a broad readership and community. The degenerate nature of nociceptor excitability, which is clearly shown and well supported by data has large functional implications. The results are of great importance because they may explain, at least in part, the poor clinical outcomes with the use of subtype-selective NaV inhibitors and therefore have major implications for the future development of Nav-selective analgesics.
In summary, the authors achieved their overall aim to enlighten the role of NaV1.7 in nociceptor excitability and the effects on drug efficacy. The data support the conclusions, although the clinical implications could be highlighted in a more detailed manner.
Weaknesses:
As mentioned before, the results that nociceptors can achieve equivalent excitability through changes in differential NaV inactivation and NaV expression of different NaV subtypes are impressive. However, there is some "gap" between the DRG culture experiments and acutely dissociated DRGs from mice after CFA injection. In the extensive experiments with cultured DRG neurons, different time points after dissociation were compared. Although it would have been difficult for functional testing to examine additional time points (besides DIV0 and DIV47), at least mRNA and protein levels should have been determined at additional time points (DIV) to examine the time course or whether gene expression (mRNA) or membrane expression (protein) changes slowly and gradually or rapidly and more abruptly.
Characterizing the time course of NaV expression changes is worthwhile but, insofar as such details are not necessary to establish that excitability is degenerate, it was not include in the current study. Furthermore, since mRNA levels do not parallel the functional changes in Nav1.7 (Figure 6A), we do not think it would be helpful to measure mRNA levels at intermediate time points. Measuring protein levels would be more informative, however, as now explained on lines 362-369, neurons were recorded at intermediate time points in initial experiments and showed a lot of variability. Methods that could track fluorescently-tagged NaV channels longitudinally (i.e. at different time points in the same cell) would be well suited for this sort of characterization, but will invariably lead to more questions about membrane trafficking, phosphorylation, etc. We agree that a thorough characterization would be interesting but we think it is best left for a future study.
It would also be interesting to clarify whether the changes that occur in culture (DIV0 vs. DIV47) are accompanied by (pro-)inflammatory changes in gene and protein expression, such as those known for nociceptors after CFA injection. This would better link the following data demonstrating that in acutely dissociated nociceptors after CFA injection, the inflammationinduced increase in NaV1.7 membrane expression enhances the effect of (or more neurons respond to) the NaV1.7 inhibitor PF-71, whereas fewer CFA neurons respond to the NaV1.8 inhibitor PF-24.
These are some of the many good questions that emerge from our results. We are not particularly keen to investigate what happens over several days in culture, since this is not so clinically relevant, but it would be interesting to compare changes induced by nerve injury in vivo (which usually involves neuroinflammatory changes) and changes induced by inflammation. Many previous studies have touched on such issues but we are cautious about interpreting transcriptional changes, and of course all of these changes need to be considered in the context of cellular heterogeneity. It would be interesting to decipher if changes in NaV1.7 and NaV1.8 are directly linked so that an increase in one triggers a decrease in the other, and vice versa. But of course many other channels are also likely to change (as discussed above), and they too warrant attention, which makes the problem quite difficult. We look forward to tackling this in future work.
The results shown explain, at least in part, the poor clinical outcomes with the use of subtypeselective NaV inhibitors and therefore have important implications for the future development of Nav-selective analgesics. However, this point, which is also evident from the title of the manuscript, is discussed only superficially with respect to clinical outcomes. In particular, the promising role of NaV1.7, which plays a role in nociceptor hyperexcitability but not in "normal" neurons, should be discussed in light of clinical results and not just covered with a citation of a review. Which clinical results of NaV1.7-selective drugs can now be better explained and how?
We wish to avoid speculating on which particular clinical results are better explained because our study was not designed for that. Instead, our take-home message (which is well supported; see Discussion on lines 309-321) is that NaV1.7-selective drugs may have a variable clinical effect because nociceptors’ reliance on NaV1.7 is itself variable – much more than past studies would have readers believe. At the end of the results (line 235), which is, we think, what prompted the reviewer’s comment, we point to the Discussion. The corollary is that accounting for degeneracy could help account for variability in drug efficacy, which would of course be beneficial. The challenge (as highlighted in the Abstract, lines 21-22) is that identifying the dominant Nav subtype to predict drug efficacy is difficult. We certainly don’t have all the answers, but we hope our results will point readers in a new direction to help answer such questions.
Another point directly related to the previous one, which should at least be discussed, is that all the data are from rodents, or in this case from mice, and this should explain the clinical data in humans. Even if "impediment to translation" is briefly mentioned in a slightly different context, one could (as mentioned above) discuss in more detail which human clinical data support the existence of "equivalent excitability through different sodium channels" also in humans.
We are not aware of human data that speak directly to nociceptor degeneracy but degeneracy has been observed in diverse species; if anything, human neurons are probably even more degenerate based on progressive expansion of ion channel types, splice variants, etc. over evolution. Of course species differences extend beyond degeneracy and are always a concern for translation, because of a species difference in the drug target itself or because preclinical pain testing fails to capture the most clinically important aspects of pain (which we mention on line 35). Line 39 now reiterates that these explanations for translational difficulties are not mutually exclusive, but that degeneracy deserves greater consideration that is has hitherto received. Indeed, throughout our paper we imply that degeneracy may contribute to the clinical failure of Nav subtype-specific drugs, but those failures are certainly not evidence of degeneracy. In the Discussion (line 320-321), we now cite a recent review article on degeneracy in the context of epilepsy, and point out how parallels might help inform pain research. We wish we had a more direct answer to the reviewer’s request; in the absence of this, we hope our results motivate readers to seek out these answers in future research.
Although speculative, it would be interesting for readers to know whether a treatment regimen based on "time since injury" with NaV1.7 and NaV1.8 inhibitors might offer benefits. Based on the data, could one hypothesize that NaV1.7 inhibitors are more likely to benefit (albeit in the short term) in patients with neuropathic pain with better patient selection (e.g., defined interval between injury and treatment)?
We like that our data prompt this sort of prediction. However, this is potentially complicated since the injury may be subtle, which is to say that the exact timing may not be known. There are scenarios (e.g. postoperative pain) where the timing of the insult is known, but in other cases (e.g. diabetic neuropathy) the disease process is quite insidious, and different neurons might have progressed through different stages depending on how they were exposed to the insult. Our own experiments with CFA are a case in point. Notwithstanding the potential difficulties about gauging the time course, any way of predicting which Nav subtype is dominant could help more strategically choose which drug to use.
Reviewer #3 (Public Review):
Summary:
In this study, the authors used patch-clamp to characterize the implication of various voltagegated Na+ channels in the firing properties of mouse nociceptive sensory neurons. They report that depending on the culture conditions NaV1.3, NaV1.7, and NaV1.8 have distinct contributions to action potential firing and that similar firing patterns can result from distinct relative roles of these channels. The findings may be relevant for the design of better strategies targeting NaV channels to treat pain.
Strengths:
The paper addresses the important issue of understanding, from an interesting perspective, the lack of success of therapeutic strategies targeting NaV channels in the context of pain. Specifically, the authors test the hypothesis that different NaV channels contribute in a plastic manner to action potential firing, which may be the reason why it is difficult to target pain by inhibiting these channels. The experiments seem to have been properly performed and most conclusions are justified. The paper is concisely written and easy to follow.
Weaknesses:
(1) The most critical issue I find in the manuscript is the claim that different combinations of NaV channels result in equivalent excitability. For example, in the Abstract it is stated that: "...we show that nociceptors can achieve equivalent excitability using different combinations of NaV1.3, NaV1.7, and NaV1.8". The gating properties of these channels are not identical, and therefore their contributions to excitability should not be the same. I think that the culprit of this issue is that the authors reach their conclusion from the comparison of the (average) firing rate determined over 1 s current stimulation in distinct conditions. However, this is not the only parameter that determines how sensory neurons convey information. For instance, the time dependence of the instantaneous frequency, the actual firing pattern, may be important too. Moreover, the use of 1 s of current stimulation might not be sufficient to characterize the firing pattern if one wants to obtain conclusions that could translate to clinical settings (i.e., sustained pain). A neuron in which NaV1.7 is the main contributor is expected to have a damping firing pattern due to cumulative channel inactivation, whereas another depending mainly on NaV1.8 is expected to display more sustained firing. This is actually seen in the results of the modelling.
This concern seems to boil down to how equivalent is equivalent? The spike shape or the full inputoutput curve for a DIV0 neuron (Nav1.8-dominant) is never equivalent to what’s seen in a DIV47 neuron (Nav1.7-dominant), but nor are any two DIV0 neurons strictly equivalent, and likewise for any two DIV4-7 neurons. Our point is that DIV0 and DIV4-7 neurons are a far more similar (less discriminable) in their excitability than expected from the qualitative difference in their TTX sensitivity (and from repeated claims in the literature that Nav1.7 is necessary for spike generation in nociceptors). Nav isoforms need not be identical to operate similarly; for instance, Nav1.8 tends to activate at “suprathreshold” voltages, but this depends on the value of threshold; if threshold increases, Nav1.8 can activate at subthreshold voltages (see Fig 5). We have modified lines 155- 175 to help clarify this.
We completely agree that firing rate is not the only way to convey sensory information, and of course injecting current directly into the cell body via a patch pipette is not a natural stimulus. These are all factors to keep in mind when interpreting our data. Nonetheless, our data show that excitability is similar between DIV0 and DIV 4-7, so much so that data from any one neuron (without pharmacological tests or capacitance measurements) would likely not reveal if that cell is DIV0 or DIV4-7; this “indiscriminability” qualifies as “equivalent” for our purposes, and is consistent with phrasing used by other authors studying degeneracy. Notably, not every DIV4-7 neuron exhibits spike height attenuation (see Fig. 1A), likely because of concomitant changes in the AHP that were not captured in our computer model or directly tested in our experiments. This highlights that other channel changes may also contribute to degeneracy and the maintenance of repetitive spiking.
(2) In Fig. 1, is 100 nM TTX sufficient to inhibit all TTX-sensitive NaV currents? More common in literature values to fully inhibit these currents are between 300 to 500 nM. The currents shown as TTX-sensitive in Fig. 1D look very strange (not like the ones at Baseline DIV4-7). It seems that 100 nM TTX was not enough, leading to an underestimation of the amplitude of the TTXsensitive currents.
As now summarized in Supplementary Table 3 (which is newly added), 100 nM TTX is >20x the EC50 for Nav1.3 and Nav1.7 (but is still far below the EC50 for Nav1.8). Based on this, TTXsensitive channels are definitely blocked in our TTX experiments.
(3) Page 8, the authors conclude that "Inflammation caused nociceptors to become much more variable in their reliance of specific NaV subtypes". However, how did the authors ensure that all neurons tested were affected by the CFA model? It could be that the heterogeneity in neuron properties results from distinct levels of effects of CFA.
We agree with the reviewer. We also believe that variable exposure to CFA is the most likely explanation for the heightened variability in TTX-sensitivity reported in Figure 7 (now more clearly explained on lines 214-215). One could try co-injecting a retrograde dye with the CFA to label cells innervating the injection site, but differential spread of the CFA and dye are liable to preclude any good concordance. Alternatively, a pain model involving more widespread (systemic) inflammation might cause a more homogeneous effect. But, our main goal with CFA injections was to show that a Nav1.8®Nav1.7 switch can occur in vivo (and is therefore not unique to culturing), and that demonstration is true even if some neurons do not switch. Subsequent testing in Figure 8 shows that enough neurons switch to have a meaningful effect in terms of the behavioral pharmacology. So, notwithstanding tangential concerns, we think our CFA experiments succeeded in showing that Nav channels can switch in vivo and that this impacts drug efficacy.
Recommendations for the authors:
All reviewers agreed that these results are solid and interesting. However, the reviewers also raised several concerns that should be addressed by the authors to improve the strength of the evidence presented. Revisions considered to be essential include:
(1) Discuss how degeneracy concerning other ion channels (such as potassium ion channels) could also impact nociceptor excitability (reviewer #1). Additionally, the translation of results from DRG neuron cultures to "in vivo" nociceptors should be better discussed.
We have added a new paragraph to the Discussion (line 248-259) to remind readers that despite our focus on Nav channels, other ion channels likely also change (and that these changes involve diverse regulatory mechanisms that require further investigation). Likewise, despite our focus on the changes caused by culturing neurons, we remind readers that subtler, more clinically relevant in vivo perturbations can likewise cause a multitude of changes. We end that paragraph by emphasizing that although accounting for all the contributing components is required to fully understand a degenerate system, meaningful progress can be made by studying a subset of the components. We want to emphasize this because there is some middle ground between focusing on one component at a time (which is the norm) vs. trying to account for everything (which is an infeasible ideal). Additional text on lines 304-308 also addresses related points.
(2) Discuss how different combinations of NaV channels result in equivalent excitability, in the context of the experimental conditions used (see main comment by reviewer #3). It should also be discussed in more detail which human clinical data support the existence of "equivalent excitability through different sodium channels" also in humans (reviewer #2).
Regarding the first part of this comment, reviewer 3 wrote in the public review that “The gating properties of these channels are not identical, and therefore their contributions to excitability should not be the same.” Differences in gating properties are commonly used to argue that different Nav subtypes mediate different phases of the spike, for example, that Nav1.7 initiates the spike whereas Nav1.8 mediates subsequent depolarization because Nav1.7 and Nav1.8 activate at perithreshold and suprathrehold voltages, respectively (see lines 134-135, now shown in red). But such comparison is overly simplistic insofar as it neglects the context in which ion channels operate. For instance, if Nav1.7 is not expressed or fully inactivates, voltage threshold will be less negative, enabling Nav1.8 to contribute to spike initiation; in other words, previously “suprathreshold” voltages become “perithreshold”. Figure 5 is dedicated to explaining this context-sensitivity; specifically, we demonstrate with simulations how Nav1.8 takes over responsibility for initiating a spike when Na1.7 is absent or inactivated. Text on lines 155- 184 has been edited to help clarify this. Regarding the second part of this comment, we are not aware of any direct evidence from human sensory neurons that different sodium channels produce equivalent excitability, but that is certainly what we expect. We suggest that failure of Nav subtype-specific drugs is, at least in part, because of degeneracy, but such failures do not demonstrate degeneracy unless other contributing factors can be excluded (which they can’t). Recognizing degeneracy is difficult, and so variability that might be explained by degeneracy will go unexplained or attributed to other factors unless, by design or serendipity, experiments quantify the effects of degeneracy (as we have attempted to do here). We now cite a recent review article on degeneracy and epilepsy (line 320), which addresses relevant themes that might help inform pain research; for instance, most existing antiseizure medications act on multiple targets whereas more recently developed single-target drugs have proven largely ineffective. This is similar to but better documented than for analgesics. With this in mind, we revised the text to emphasize the circumstantial nature of existing evidence and the need to test more directly for degeneracy (lines 320-323).
(3) Extend the discussion about the poor clinical outcomes with the use of subtype-selective NaV inhibitors. In particular, the promising role of NaV1.7, which plays a role in nociceptor hyperexcitability but not in "normal" neurons, should be discussed in light of clinical results and not just covered with a citation of a review. Which clinical results of NaV1.7-selective drugs can now be better explained and how? (reviewer #2)
As discussed above, we are cautious avoid speculating on which clinical results are attributable to degeneracy. Instead, our take-home message (see Discussion, lines 309-323) is that NaV1.7selective drugs may have a variable clinical effect because nociceptors’ reliance on NaV1.7 is itself variable – much more than past studies would have readers believe. The corollary is that accounting for degeneracy could help account for variability in drug efficacy, which would of course be beneficial. The challenge (as highlighted in the Abstract, lines 21-22) is that identifying the dominant Nav subtype to predict drug efficacy is not trivial. Interpreting clinical data is also complicated by the fact that we are either dealing with genetic mutations (with unclear compensatory changes) or pharmacological results (where NaV1.7-selective drugs have a multitude of problems that might contribute to their lack of efficacy, separate from effects of degeneracy). We have striven to contextualize our results (e.g. last paragraph of results, lines 222-235). We think this is the most we can reasonably say based on the limitations of existing clinical data.
(4) Provide a clearer and more detailed description of the computational model (reviewers #2 and #3).
We added important details on line 476-477 but, in our honest opinion, we think our computational model is thoroughly explained. The issue seems to boil down to whether details are included in the Results vs. being left for the Methods, tables and figure legends. We prefer the latter.
(5) Better clarify the effects of the CFA model, to provide further evidence relating inflammation with nociceptors variability (reviewers #2 and #3)
As explained in response to a specific point by reviewer #3, we believe that variable exposure to CFA explains the heightened variability in TTX-sensitivity reported in Figure 7 (now explained on lines 214-215). One could try co-injecting a retrograde dye with the CFA to label cells innervating the injection site, but differential spread of the inflammation and dye are liable to preclude any good concordance. Alternatively, a pain model involving more widespread (systemic) inflammation might cause a more homogeneous effect. But, our main goal with CFA injections was to show that a Nav1.8®Nav1.7 switch can occur in vivo (and is therefore not unique to culturing); that demonstration holds true even if some neurons do not switch. Subsequent testing (Fig 8) shows that enough neurons switch to drug efficacy assessed behaviorally. This is emphasized with new text on lines 225-227. Overall, we think our CFA experiments succeed in showing that Nav channels can switch in vivo and, despite variability, that this occurs in enough neurons to impact drug efficacy.
(6) Revise the text according to all recommendations raised by the reviewers and listed in the individual reviews.
Detailed responses are provided below for all feedback and changes to the text were made whenever necessary, as identified in our responses.
Reviewer #1 (Recommendations For The Authors):
Minor points/recommendations:
Protein synthesis inhibition by cercosporamide could be the direct cause of a smaller-thanexpected increase in Nav1.7 levels at DIV5. But for Nav1.8, there is a mitigation in the increased levels at DIV5, that only could be explained by several indirect mechanisms, including membrane trafficking and posttranslational modifications (phosphorylation, SUMOylation, etc.) on Nav1.8 or protein regulators of Nav1.8 channels. The authors suggest that "translational regulation is crucial", but also insinuate that other processes (membrane trafficking, etc.) could contribute to the observed outcome. It is difficult to assess the relative importance of these different explanations without knowing the exact mechanisms that are acting here.
We agree. We relied on electrophysiology (and pharmacology) to measure functional changes, but we wanted to verify those data with another method. We expected mRNA levels to parallel the functional changes but, when that did not pan out, we proceeded to look at protein levels. Perhaps we should have stopped there, but by blocking protein translation, we show that there is not enough Nav1.7 protein already available that can be trafficked to the membrane. That does not explain why Nav1.8 levels drop. Our immunohistochemistry could not tease apart membrane expression from overall expression, which limits interpretation. We have enhanced the text to discuss this (lines 200-204), but further experiments are needed. Though admittedly incomplete, our initial finding help set the stage for future experiments on this matter.
Page 15, typo: "contamination from genomic RNA" -> "contamination from genomic DNA" (appears twice).
This has been corrected on lines 420 and 421.
Page 17: I could not find the computer code at ModelDB (http://modeldb.yale.edu/267560). It seems to be an old web link. It should be available at some web repository.
We confirmed that the link works. Entry is password-protected (password = excitability; see line 476). Password protection will be removed once the paper is officially published.
Page 19, reference 36, typo: "Inhibitio of" -> "Inhibition of".
This has been corrected (line 557).
Page 33, typo: "are significantly larger than differences at DIV1" -> "are significantly larger than differences at DIV0".
This has been corrected (line 796).
Page 35, figure 6 legend. The number of experiments (n) is not indicated for panel C data.
N = 3 is now reported (line 828).
Reviewer #2 (Recommendations For The Authors):
p. 3/4 and Data of Fig. 6: It should be commented on why days 1-3 were not investigated. An investigation of the time course (by higher frequency testing) would certainly have an added value because it would be possible to deduce whether the changes develop slowly and gradually, or whether the excitability induced by different NaVs changes suddenly. At least mRNA and protein levels should be determined at additional time points to examine the time course or whether gene expression (mRNA) or membrane expression (protein) changes slowly and gradually or rapidly and more abruptly. It would also be interesting to clarify whether the changes that occur in culture (DIV0 vs. DIV4-7) are accompanied by (pro-)inflammatory changes in gene and protein expression, such as those known for nociceptors after CFA injection. Or is the latter question clear in the literature?
We now explain (lines 362-369) that intermediate time points (DIV1-3) were tested in initial current clamp recordings. Those data showed that TTX-sensitivity stabilized by DIV4 and differed from the TTX-insensitivity observed at DIV0. TTX-sensitivity was mixed at DIV1-3 and crosscell variability complicated interpretation. Subsequent experiments were prioritized to clarify why NaV1.7 is not always critical for nociceptor excitability, contrary to past studies. Our efforts to measure mRNA and protein levels were primarily to validate our electrophysiological findings; we are also interested in deciphering the underlying regulatory processes but this is an entire study on its own. Unfortunately, the existing literature does not help or point to an explanation for the Nav1.7/1.8 shift we observed.
Our evidence that mRNA levels do not parallel functional changes argues against pursuing transcriptional changes in Nav1.7, though transcriptional changes in other factors might be important. Interpretation of immuno quantification would be complicated by the high variability we observed with the physiology at intermediate time points and, furthermore, we cannot resolve surface expression from overall expression based on available antibodies. Methods conducive to longitudinal measurements would be more appropriate (as now mentioned on line 367-369). In short, a lot more work is required to understand the mechanisms involved in the switch, but we think the existing demonstration suffices to show that NaV1.7 and NaV1.8 protein levels vary, with crucial implications for which Nav subtype controls nociceptor excitability, and important implications for drug efficacy. Explaining why and how quickly those protein levels change will be no small feat is best left for a future study.
p. 4 and following: In order to enable the interpretation of the used concentration of PF-24, PF71, and ICA, the respective IC50 should be indicated.
A table (now Supplementary Table 3; line 861) has been added to report EC50 values for all drugs for blocking NaV1.7, NaV1.8 and NaV1.3. The concentrations we used are included on that table for easy comparison.
p. 5, end of the middle paragraph: Here it should be briefly explained -for less familiar readers- why NaV1.1 cannot be causative (ICA inhibits NaV1.1 and 1.3).
We now explain (lines 117-120) that NaV1.1 is expressed almost exclusively in medium-diameter (A-delta) neurons whereas NaV1.3 is known to be upregulated in small-diameter neurons, and so the effect we observe in small neurons is most likely via blockade NaV1.3.
p. 6, lines 4/5: At least once it should read computer model instead of model.
“Computer” has been added the first time we refer to DIV0 or DIV4-7 computer models (lines 138-139)
p. 6: the difference between Fig. 4B and Fig. 4 - Figure suppl. 1 should be mentioned briefly.
We now explain (lines 150-154) that Fig. 4B involves replacing a native channel with a different virtual channel (to demonstrate their interchangeability) whereas and Fig. 4 - Figure supplement 1 involves replacing a native channel with the equivalent virtual channel (as a positive control).
p. 6/7: the text and the conclusions regarding Figure 5 are difficult to follow. Somewhat more detailed explanations of why which data demonstrate or prove something would be helpful.
The text describing Figure 5 (lines 155-175) has been revised to provide more detail.
p. 7, last sentence of the first paragraph: How is this supported by the data? Or should this sentence be better moved to the discussion?
This sentence (now lines 182-184) is designed as a transition. The first half – “a subtype’s contribution shifts rapidly (because of channel inactivation)” – summarizes the immediately preceding data (Figure 5). The second half – “or slowly (because of [changes in conductance density])” – introduces the next section. The text show in square brackets has been revised. We hope this will be clearer based on revisions to the associated text.
p. 7, second paragraph, line 3: Please delete one "at both".
Corrected
p. 7, second paragraph: Please explain why different time points (DIV4-7, DIV5, or DIV7) were used or studied.
Initial electrophysiological experiments determined that TTX sensitivity stabilized by DIV 4 (see response to opening point) and we did not maintain neurons longer than 7 days, and so neurons recorded between DIV4 and 7 were pooled. If non-electrophysiological tests were conducted on a specific day within that range, we report the specific day, but any day within the DIV4-7 range is expected to give comparable results. This is now explained on lines 365-367.
p. 8: the text regarding Fig. 7 should also include the important data (e.g. percentage of neurons showing repetitive spinking) mentioned in the legend.
This text (lines 216-220) has been revised to include the proportion of neurons converted by PF71 and PF-24 and the associated statistical results.
Fig. 1: third panel (TTX-sensitive current...) of D & Fig. 2 subpanel of A (Nav1.8 current...). These panels should be explained or mentioned in the text and/or legends.
We now explain in the figure legends (lines 708-710; 714-715; 736-738) how those currents are found through subtraction.
Fig. 2 - figure supplement 2. One might consider taking Panel A to Fig. 2 so that the comparison to DIV0 is apparent without switching to Suppl. Figs.
We left this unchanged so that Figures 2 and 3 are equivalently organized, with negative control data left to the supplemental figures. Elife formatting makes it easy to reach the supplementary figure from the main figure, so we hope this won’t be an impediment to readers.
Fig. 6 C, middle graph (graph of Nav1.7): Please re-check, whether DIV5 none vs. 24 h and none vs. 120 h are really significantly different with such a low p-value.
We re-checked the statistics and the difference pointed out by the reviewer is significant at p=0.007. We mistakenly reported p<0.001 for all comparisons, and so this p value has been corrected; all the other p values are indeed <0.001. Notably, the data are summarized as median ± quartile because of their non-Gaussian distribution; this is now explained on line 827 (as a reminder to the statement on lines 461-462). Quartiles are more comparable to SD than to SEM (in that quartiles and SD represent the distribution rather than confidence in estimating the mean, like SEM), and so medians can differ very significantly even if quartiles overlap, as in this case.
Reviewer #3 (Recommendations For The Authors):
(1) A critical issue in the manuscript is the use of teleological language. It is likely that this is not the intention, but careful revision of the language should be done to avoid the use of expressions that confer purpose to a biological process. Please, find below a list of statements that I consider require correction.
- In the Abstract, the first sentence: "Nociceptive sensory neurons convey pain signals to the CNS using action potentials". Neurons do not really "use" action potentials, they have no will or purpose to do so. Action potentials are not tools or means to be "used" by neurons. Other examples of misuse of the verb "use" are found in several other sentences:
"...nociceptors can achieve equivalent excitability using different combinations of NaV1.3, NaV1.7, and NaV1.8"
"Flexible use of different NaV subtypes - an example of degeneracy - compromises..."
"Nociceptors can achieve equivalent excitability using different sodium channel subtypes" "...degeneracy - the ability of a biological system to achieve equivalent function using different components..."
"...nociceptors can achieve equivalent excitability using different sodium channel subtypes..."
"Our results show that nociceptors can achieve similar excitability using different NaV channels" "...the spinal dorsal horn circuit can achieve similar output using different synaptic weight combinations..."
"Contrary to the view that certain ion channels are uniquely responsible for certain aspects of neuronal function, neurons use diverse ion channel combinations to achieve similar function" "In summary, our results show that nociceptors can achieve equivalent excitability using different NaV subtypes"
“Use” can mean to put into action (without necessarily implying intention). Based on definitions of the word in various dictionaries, we feel we are well within the realm of normal usage of this term. In trying to achieve a clear and succinct writing style, we have stuck with our original word choice.
- At the end of page 5 and in the legend of Fig. 7, the word "encourage" is not properly used in the sentence "The ability of NaV1.3, NaV1.7 and NaV1.8 to each encourage repetitive spiking is seemingly inconsistent with the common view...". Encouraging is really an action of humans or animals on other humans or animals.
Like for “use”, we verified our usage in various dictionaries and we do not think that most readers will be confused or disturbed by our word choice. We use “encourage” to explain that increasing NaV1.3, NaV1.7 or NaV1.8 can increase the likelihood of repetitive spiking; we avoided “cause” because the probability of repetitive spiking is not raised to 100%, since other factors must always be considered.
- In the Abstract and other places in the manuscript, the word "responsibility" seems to be wrongly employed. It is true that one can say, for instance, on page 4 last paragraph "we sought to identify the NaV subtype responsible for repetitive spiking at each time point". However, to confer channels with the human quality of having "responsibility" for something does not seem appropriate. See also page 8 last paragraph, the first paragraph of the Discussion, and the three paragraphs of page 11.
Again, we must respectfully disagree with the reviewer. We appreciate that this reviewer does not like our writing style but we do not believe that our style violates English norms.
(2) In the first sentence of the Abstract, nociceptive sensory neurons do not convey "pain signals". Pain is a sensation that is generated in the brain.
“Pain” is used as an adjective for “signal” and is used to help identify the type of signal. Nonetheless, since the word count allowed for it, we now refer to “pain-related signals” (line 10).
(3) I do not see the point of plotting the firing rate as a function of relative stimulus amplitude (normalized to the rheobase, e.g., Fig. 1A bottom panels, Fig. 2B, bottom-right, Fig. 2 Supp2A right, Fig. 3 B bottom panels, etc) instead of as a function of the actual stimulus amplitude. I have the impression that this maneuver hides information. This is equivalent to plotting the current amplitudes as a function of the voltage normalized by the voltage threshold for current activation, which is obviously not done.
This is how the experiments were performed, so it would be impossible to perform the statistical analysis using the absolute amplitudes post-hoc; specifically, stimulus intensities were tested at increments defined relative to rheobase rather than in absolute terms. There are pros and cons to each approach, and both approaches are commonly used. Notably, we report the value of rheobase on the figures so that readers can, with minimal arithmetic, convert to absolute stimulus intensities. No information is hidden by our approach.
(4) On page 4 it is stated that "We show later that similar changes develop in vivo following inflammation with consequences for drug efficacy assessed behaviourally (see Fig. 8), meaning the NaV channel reconfiguration described above is not a trivial epiphenomenon of culturing". However, what happens in culture may have nothing in common with what happens in vivo during inflammation. Thus, the latter data may not serve to answer whether the culture conditions induce artifacts or not. I suggest tuning down this statement by changing "meaning" to "suggesting".
On line 97, we now write “suggesting”.
(5) Page 5, first paragraph, I miss a clear description of the mathematical models. Having to skip to the Methods section to look for the details of the models as the artifices introduced to simulate different conditions is rather inconvenient.
So as not to disrupt the flow of the presentation with methodological details, we only provide a short description of the model in the Results. We have slightly expanded this to point out that the conductance-based model is also single-compartment (line 111). We provide a very thorough description of our model in the Methods, especially considering all the details provided in Supplementary Tables 1, 5 and 6. We also report conductance densities and % changes in figure legends (lines 722, 747-748; now shown in red). This is also true for Figure 3-figure supplement 2 (lines 756-759). We tried very hard to find a good balance that we hope most readers will appreciate.
(6) Page 6, second paragraph, simulations do not serve to "measure" currents.
The sentence been revised to indicate that simulations were used to “infer” currents during different phases of the spike (line 155).
(7) Page 7, regarding the tile of the subsection "Control of changes in NaV subtype expression between DIV0 and DIV4-7", the authors measured the levels of expression, but not really the mechanisms "controlling" them. I suggest writing "changes in NaV subtype expression between DIV0 and DIV4-7"
We have removed “control of” from the section title (line 185)
(8) What was the reason for adding a noise contribution in the model?
We now explain that noise was added to reintroduce the voltage noise that is otherwise missing from simulations (line 474). For instance, in the absence of noise, membrane potential can approach voltage threshold very slowly without triggering a spike, which does not happen under realistically noisy conditions. Of course membrane potential fluctuates noisily because of stochastic channel opening and a multitude of other reasons. This is not a major issue for this study, and so we think our short explanation should suffice.
(9) Please, define the concept of degeneracy upon first mention.
Degeneracy is now succinctly defined in the abstract (line 20).
-
Reviewer #2 (Public Review):
Summary:
The authors have noted in preliminary work that tetrodotoxin (TTX), which inhibits NaV1.7 and several other TTX-sensitive sodium channels, has differential effects on nociceptors, dramatically reducing their excitability under certain conditions but not under others. Partly because of this coincidental observation, the aim of the present work was to re-examine or characterize the role of NaV1.7 in nociceptor excitability and the effects on drug efficacy. The manuscript demonstrates that a NaV1.7-selective inhibitor produces analgesia only when nociceptor excitability is based on NaV1.7. More generally and comprehensively, the results show that nociceptors can achieve equivalent excitability through changes in differential NaV inactivation and NaV expression of different NaV subtypes (NaV 1.3/1.7 and 1.8). This can cause widespread changes in the role of a particular subtype over time. The degenerate nature of nociceptor excitability shows functional implications that make the assignment of pathological changes to a particular NaV subtype difficult or even impossible.
Thus, the analgesic efficacy of NaV1.7- or NaV1.8-selective agents depends essentially on which NaV subtype controls excitability at a given time point. These results explain, at least in part, the poor clinical outcomes with the use of subtype-selective NaV inhibitors and therefore have major implications for the future development of Nav-selective analgesics.
Strengths:
The results are clearly and impressively supported by the experiments and data shown. During the revision, the manuscript was consistently improved and the concerns of the first reviews were resolved. All methods are described in detail, and presumably, allow good reproducibility and were suitable to address the scientific question.
The results showing that nociceptors can achieve equivalent excitability through changes in differential NaV inactivation and expression of different NaV subtypes are of great importance in the fields of basic and clinical pain research and sodium channel physiology and pharmacology, but also for a broad readership and community. The degenerate nature of nociceptor excitability, which is clearly shown and well supported by data has large functional implications. The results are of great importance because they may explain, at least in part, the poor clinical outcomes with the use of subtype-selective NaV inhibitors and therefore have major implications for the future development of Nav-selective analgesics.
In summary, the authors achieved their overall aim to enlighten the role of the NaV1.7 in nociceptor excitability and the effects on drug efficacy. The data support the conclusions and clinical implications are highlighted as far as is currently justifiable due to the still limited experience in translation. This appears well-considered, not too speculative, and ultimately appropriate.
The main weaknesses of the first version were fixed during the revision:
(i) After revising the manuscript, the initial weakness that the computer model was described superficially has been fixed. Important information was added to the main text and additional information, including the full code and equations and values are deposited on ModelDB or are given in the Supplementary information (Suppl. Table 5 & 6).
(ii) The authors now comment that corresponding studies on protein levels or e.g. neuroinflammatory changes could support the characterization of the time course of membrane expression and cellular changes, but this should be addressed in future studies, as these analyses would also raise new questions, such as about membrane trafficking, post-translational modifications, etc. This is plausible and has now been appropriately addressed in the text.
(iii) During the initial review the authors were asked to discuss the promising role of NaV1.7 in the light of clinical results. In their response, the authors confidently state that they „wish to avoid speculating on which particular clinical results are better explained because our study was not designed for that." They, however, emphasize their take-home message, which is well supported "Instead, our take-home message (which is well supported; see Discussion on lines 309-321) is that NaV1.7-selective drugs may have a variable clinical effect because nociceptors' reliance on NaV1.7 is itself variable - much more than past studies would have readers believe. ... The challenge (as highlighted in the Abstract, lines 21-22) is that identifying the dominant Nav subtype to predict drug efficacy is difficult."
Against the background of this argumentation, it must be admitted that the decision not to present as yet unproven speculations is probably appropriate from a scientific point of view and that this ultimately proves the critical assessment of one's own data and the limitations of the study. This is undoubtedly acceptable and - in retrospect - probably the right way to go.
-
-
www.biorxiv.org www.biorxiv.org
-
Reviewer #1 (Public Review):
Summary:
In this study, the authors distinguished afferent inputs to different cell populations in the VTA using dimensionality reduction approaches and found significantly distinct patterns between normal and drug treatment conditions. They also demonstrated negative correlations of the inputs induced by drugs with gene expression of ion channels or proteins involved in synaptic transmission and demonstrated the knockdown of one of the voltage-gated calcium ion channels caused decreased inputs.
Weaknesses:
(1) For quantifications of brain regions in this study, boundaries were based on the Franklin-Paxinos (FP) atlas according to previous studies (Beier KT et al 2015, Beier KT et al 2019). It has been reported significant discrepancies exist between the anatomical labels on the FP atlas and the Allen Brain Atlas (ref: Chon U et al., Nat Commun 2019). Although a summary of conversion is provided as a sheet, the authors need to describe how consistent or different the brain boundaries they defined in the manuscript with Allen Brain Atlas by adding histology images. Also, I wonder how reliable the annotations were for over a hundred of animals with manual quantification. The authors should briefly explain it rather than citing previous studies in the Material and Methods Section.
(2) Regarding the ellipsoids in the PC, although it's written in the manuscript that "Ellipsoids were centered at the average coordinate of a condition and stretched one standard deviation along the primary and secondary axes", it's intuitively hard to understand in some figures such as Figure 2O, P and Figure S1. The authors need to make their data analysis methods more accessible by providing source code to the public.
(3) In histology images (Figure 1B and 3K), the authors need to add dashed lines or arrows to guide the reader's attention.
(4) In Figure 2A and G, apparently there are significant differences in other brain regions such as NAcMed or PBN. If they are also statistically significant, the authors should note them as well and draw asterisks(*).
(5) In Figure 2N about the spatial distribution of starter cells, the authors need to add histology images for each experimental condition (i.e. saline, fluoxetine, cocaine, methamphetamine, amphetamine, nicotine, and morphine) as supplement figures.
(6) In the manuscript, it is necessary to explain why Cacna1e was selected among other calcium ion channels.
-
-
racheljeneff.weebly.com racheljeneff.weebly.com
-
While at Regional One, a client reported that he was going to sell his medication once he was discharged. I educated him on that being illegal and he reported that he was joking with me. I did not want to take the chance, so I reported this news to my educator. She reported that the rehab team, including the pharmacist and doctor, was aware and that this was not the first time he mentioned this. Katie Heismann, OTR/L reports "Rachel adheres to AOTA's code of ethics and also adheres to any safety protocols."
can you find a synonym for the verb "report"? You use it repetitively in this section.
-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
The following is the authors’ response to the original reviews.
We want to thank the reviewers for their thoughtful analysis and questions.
A brief overview of the changes to the manuscript is provided here, with individual responses to the reviewer comments following.
The methods section has been expanded to better explain the techniques used in our analyses. CTCF binding data section has likewise been expanded, to include more detail on the dataset and our analysis of its contents. All other requested clarifications have been added to areas of the results.
Beyond specific requests from the reviewers, we made the following changes.
We felt that a particular terminology choice on our part resulted in some confusion: the use of “SNPs” to refer to genetic variants within our Diversity Outbred samples. While we used SNPs that lay closest to the center of our haplotype predictions as our representative loci for each linkage disequilibrium block, this was done for computational purposes only. We did not focus most of our analyses on the haplotypes themselves, because of the uncertainty of which variants within an LD block actually participated in the genetic-epigenetic interactions we imputed.
Thus, we edited the text to remove mention of “SNPs” unless our analysis did directly and deliberately profile SNPs themselves. In all other cases, we now refer to “haplotypes”, “genetic variants”, or “variants”. This should help increase clarity in the manuscript as a whole.
A small error was discovered within the labelling and processing of regression model outputs in chromosome 14. A consistency check was run on all chromosomes, finding that only Chr 14 was affected. Chr 14 was rerun in its entirety to verify its results, with the previous results now archived within our databases uploaded on Synapse (see Methods for a link). All relevant calculations and figures were regenerated, resulting in an average shift of 1% or less across the manuscript. All analyses remain highly statistically significant.
Responses to comments from Reviewer #1
Methods
-
Sequencing depth was retrieved from the original publication on the primary multiomics dataset. (Line 105-106)
-
A line was added regarding initial mouse genome alignment for the original publication: we explain the GigaMUGA genotyping array, used for the DO mESC samples. For our ChIP-seq data, we reword to specify: we used liftovers from imputed strain-specific genomes to B6 mm10. (Lines 108-110; 116-120; 168-170)
-
Aneuploidy removal is expanded upon in a similar fashion: the original QC identified chromosome-level gene expression differences to remove aneuploid samples. (Line 111)
-
Mention of the pre-publication use of an alternative null model has been removed, given its lack of relevance to the rest of the text. While it was interesting to compare to the standard null model, it amounts to a side note that distracts from the focus of the paper. (Line 137-139).
-
Descriptive subheadings have been added.
Results - Line 179 (now Line 191) now points to Methods.
-
Line 189-200 (now Line 188-204): language altered to better explain our intent: We wished to perform an intrachromosomal scan across the whole genome for non-additive genetic-epigenetic interactions. However, there were computational limits to how many possible combinations of gene, haplotype, and ATAC-seq peak we could feasibly test. We thus generated a random subset of possible combinations. This was also performed to identify target regions for focused analyses.
-
Line 195 (now line 206, expanded on in Line 210): Clarification added on the significance of our result: if non-additive genetic-epigenetic interactions were not a significant explanatory factor for gene expression, we would expect to see no enrichment of low p-value results. Instead, we see 0.07% of our models coming in at adj. p < 1x10-7.
-
Line 199 (now Line 216): The requested calculations were run, and are now included in table S3. We found that within 4 Mb of a given gene, less than 10% of variants and ATAC peaks within clustered closer to each other than they did to the gene they affected.
Please note that this figure has a level of uncertainty due to linkage disequilibrium. Thus, rather than precisely answering the question “[are there haplotype-ATAC pairs] that are in the same locality but further away from the gene?”, we asked "is the ATAC peak closer than the gene to the point where we have the highest confidence of correctly calling the interacting genotype?". The relevant code has been deposited in our Synapse repository (see Methods for link).
-
Line 205 (now restructured in Line 221-228): The text has been edited to specify our intent. We are referring to a set of TAD-focused regression models we generated (see Methods) that comprehensively included all possible interactions between genes, and all haplotypes and ATAC peaks within +/- 1 TAD of the gene.
-
(Line 227): We specified that the previously-published TAD boundary dataset we used was retrieved from the Bing Ren lab’s Hi-C projects, which imputed locations of TAD boundaries in B6 mESCs.
-
We have relabeled Figure 1 and tweaked the surrounding text to clear up some confusing aspects. The Euler plots in Figure 1D-E reflect the fact that each ATAC-seq peak and haplotype can be in multiple relationships with local genes and regulatory factors. Some of these relationships will be simple correlation between their presence and gene expression, while others may co-regulate alongside independent regulatory factors, or engage in non-additive regulatory interactions.
Because these non-additive regulatory interactions have not been comprehensively studied, we wished to determine whether there were any regulatory factors within our data that would not be detected as significant via more conventional methods, such as correlation analysis, mediation analysis, or regression analysis without an interaction term. Our Euler plots show that there are large subsets of both ATAC-seq peaks and haplotypes that are exclusively found in non-additive interactions. Thus, our justification for focusing on non-additive interactions for the rest of the paper.
-
Line 256 (now Line 252-255): We further clarified the above in this section: correlation and mediation analyses were previously completed by the team which initially analyzed the DO mESC dataset (Skelly et al. 2020, Cell Stem Cell). They performed a correlation analysis between open chromatin and gene expression (Skelly et al. Fig. 2A), and identified expression quantitative trait loci (eQTL) (Skelly et al. Fig. 2E). We felt that more direct comparisons to the Skelly et al. data would distract readers from our focus on genetic-epigenetic interactions. Thus, we limited our discussion of non-interacting regulatory relationships to Figures 1-2, and a brief mention in Figure 5.
-
Line 290 (now Line 337): We pulled promoter locations from the FANTOM5 database of mouse promoters, and included analysis in both the text and Figure S4A-B.
-
(Line 475-476): we clarified “DO founder SNPs” to “SNPs from the non-reference DO founder strains”.
-
Line 472 (restructured in Lines 531-564): We have expanded on this section, including answers to the reviewer’s questions regarding ChIP-seq peak counts, overlap with the TAD map we used for our other analyses, and expanded upon strain-specific CTCF binding we identified in our ChIP-seq analysis.
Responses to comments from Reviewer #2:
(1) Typo corrected.
(2) Lines 194-195 (now line 206, expanded on in Line 210): We have expanded upon the intent and expectations of our analysis. In summary: if non-additive genetic-epigenetic interactions were not a significant explanatory factor for gene expression, we would expect to see no enrichment of low p-value results. Thus, we would expect 0.0000001% of results to reach adj. p < 1x10-7. Instead, we see 0.07% of our models coming in at adj. p < 1x10-7, four orders of magnitude greater than expected.
(3) Lines 226-230 (Expanded on in Lines 252-276): We have relabeled Figure 1 and tweaked the surrounding text to clear up some confusing aspects. The percentages in the text are derived from the data summarized in the Euler plots in Figure 1D-E. These plots reflect the fact that each ATAC-seq peak and haplotype can be in multiple relationships with local genes and regulatory factors. Some of these relationships will be simple correlation between their presence and gene expression, while others may co-regulate alongside independent regulatory factors, or engage in non-additive regulatory interactions.
(4) Line 261-263 (now lines 299-300): A companion to Figure 2B has been added (Fig. S3), which provides interaction counts for each ATAC-seq peak that contributed to Figure 2B. A horizontal line is included to highlight the locations of the highly-interacting ATAC peaks.
(5) Analysis regarding Figure 3B had been removed from its original context. It has now been restored to the manuscript (Line 368-371).
-
-
-
docdrop.org docdrop.org
-
." To teacb effectively a diverse student body, I bave to learn tbese codes. And so do students
How do you apply different “cultural codes” in one classroom setting? And why students need to adapt this code as well?
-
-
www.linkedin.com www.linkedin.com
-
We made also some a screen-recording for every chapter
Here is the introduction to hashtag#JavaScript in LiaScript, where we had re-imagined the usage and the capabilities of JavaScript. In our case JavaScript is used as a component, that serve multiple purposes:
-
In can simply perform a calculation and directly output the result as part of the text.
-
It can also output HTML or LiaScript
-
Users can interact with scripts, since they can be combined with different input elements
-
Users can inspect every calculation by double-clicking onto the result
-
Users can modify and rerun this code
-
Scripts can be combined with animations
-
Scripts can be combined with other scripts to form an execution graph, when on script finished, its result can trigger the execution of another script
-
Scripts can be combined with the Internationalization API for optimized formatting
-
And much more ;-)
-
-
-
-
Index of LiaScript Templates
- Algebrite is a Javascript library for symbolic mathematics (technically, CoffeeScript) designed to be comprehensible and easily extensible.
- a high-level grammar of interactive graphics. It provides a concise JSON syntax for rapidly generating visualizations to support analysis plantUML diagrams
- Sequence Usecase Class Activity Component, State Object Deployment Timing ...
MermaidJS - generating charts from text
rextester - Support for 45 different programming languages
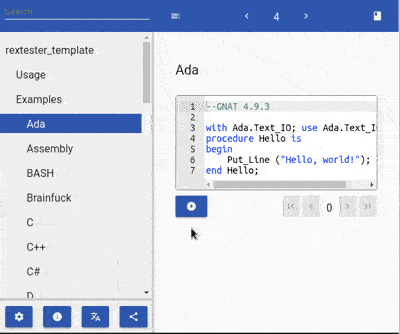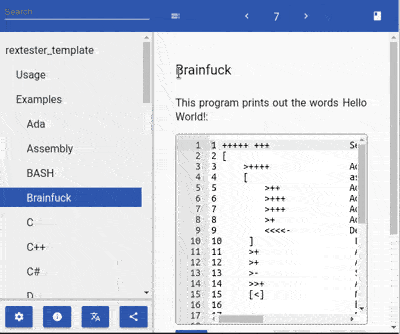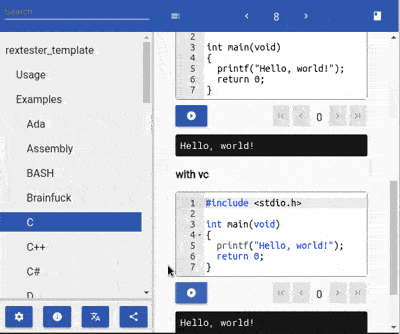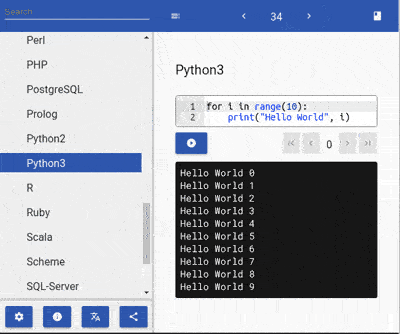
Tau-Prolog - functional Prolog-Interpreter for JavaScript
Curiosity-Prolog - Prolog-Interpreter implemented in 160 lines of JavaScript code.
Skulpt: - Skulpt is an entirely in-browser implementation of Python. No preprocessing, plugins, or server-side support required, just write Python and reload.
Pyodide: - The Python scientific stack, compiled to WebAssembly. It provides transparent conversion of objects between Javascript and Python. When inside a browser, this means Python has full access to the Web APIs.
BiwaScheme: - a Scheme interpreter written in JavaScript.
AlaSQL - is a lightweight client-side in-memory SQL database designed to work in browser and Node.js.
Turtle - A port of tiny-turtle.js to LiaScript,
Web Development - A general template that can be used to create online curses on web development including HTML, CSS, and JavaScript.
-
-
www.biorxiv.org www.biorxiv.org
-
This is awesome!!! The impact/relevance of your work is incredibly clear, all data/code is on GitHub (with a very robust README) and you candidly express the limitations of the predictive models (e.g. inaccuracy when predicting oxygen tolerance for certain genera or phyla, thus requiring follow-up on the relationship between AAs and metabolic niches or how the lack of precision of the models may not be helpful for cultured microorganisms). I’m looking forward to trying this out myself!
Summary: In this manuscript, Barnum et al. created computational models — favoring simple logistic regression models — that can predict the ideal oxygen tolerance, temperature, salinity and pH conditions of novel taxonomic microbial families (requiring only an unannotated, and potentially incomplete, genome from the user).
The authors leveraged the empirical data of 15.5k+ microbes and curated the dataset to omit microbes that did not have multiple measured values for a growth phenotype, had minor differences between the minimum and maximum value tested for the phenotype (<1.5 pH, 10C, 1.5% NaCl unless salinity was <0.5%), or had fewer than 4 total measurements recorded. Haloarchaea with a salinity optima <3.7% were also excluded and finally, the data set was further balanced to reduce taxonomic bias.
The authors then measured correlations between DNA and protein sequence features and oxygen tolerance, temperature, salinity and pH conditions (expressed as a Spearman’s rank correlation coefficient). No correlations between the tested DNA sequence features and the four physiochemical conditions were identified but numerous correlations between protein sequence features and the physiochemical conditions were identified. For example, a negative correlation between oxygen tolerance and cysteine frequency was revealed (p=-0.49).
Estimators were then evaluated on their ability to accurately predict the four physiochemical conditions based on 9 different sets of features and the authors found that amino acid features alone were sufficient for accurate prediction. Three models were then selected for each condition (optimum, minimum and maximum value predictions). When testing the selected models with family-level holdouts, the predictions were made with lower accuracy albeit their performance was consistent with training and cross-validation data. The models also predicted extreme growth conditions less accurately (e.g. salinity > 15% or pH > 5).
To test the models’ vulnerability to phylogenetic bias, the selected models were compared to models where the prediction was a random value or the average value of the closest relatives. As expected, the chosen models considerably outperformed the models strongly influenced by phylogeny.
To test the models’ vulnerability to genome completeness, protein and genome sequences were subsampled to 10-100% completeness for 20 different species in each condition range and evaluated for prediction accuracy. The selected models showed negligible differences between 10% and 100% genome completeness for oxygen tolerance, temperature and salinity. pH prediction experienced a bigger impact by genome completeness.
The selected models were then used to predict the ideal growth conditions of 85k+ bacteria and archaea. As expected, many of the uncultivated species were predicted to grow in more extreme conditions. The ideal growth conditions of 3.3k+ metagenomes were predicted and compared to the growth conditions of the environment from which the samples were derived. Predicted growth conditions mostly aligned with the organism’s habitat but the authors found that predicted individual genomes can deviate from the conditions of the source environment.
-
-
social-media-ethics-automation.github.io social-media-ethics-automation.github.io
-
Now, there are many reasons one might be suspicious about utilitarianism as a cheat code for acting morally, but let’s assume for a moment that utilitarianism is the best way to go. When you undertake your utility calculus, you are, in essence, gathering and responding to data about the projected outcomes of a situation. This means that how you gather your data will affect what data you come up with. If you have really comprehensive data about potential outcomes, then your utility calculus will be more complicated, but will also be more realistic. On the other hand, if you have only partial data, the results of your utility calculus may become skewed. If you think about the potential impact of a set of actions on all the people you know and like, but fail to consider the impact on people you do not happen to know, then you might think those actions would lead to a huge gain in utility, or happiness.
This passage informs me about the limitations of utilitarianism in moral decision-making, especially the importance of data collection and interpretation. It reveals an issue from a personal perspective: our decisions are often influenced by personal biases, which can lead to biases in utility calculations. This makes me aware of the importance of considering comprehensive and objective data when applying utilitarianism in practice.
-
-
nationalhumanitiescenter.org nationalhumanitiescenter.org
-
But the Revolutionary Theatre, even if it is Western, must be anti-Western.
anti western revolutionary theatre results in a kind of code reversal for western conceptions of victimhood and heroism
-
-
social-media-ethics-automation.github.io social-media-ethics-automation.github.io
-
All data is a simplification of reality.
Last quarter, I took CSE 121 and we sort of touched on how data is oversimplified. We didn't really get into the ethics of this topic in class, but I could only imagine how programming and code, exclude marginalized groups of people. I find that most of the servers and extensions I use on a daily basis, aren't user-friendly to all. And by this I mean people who are visually impaired and hard of hearing. That just goes to show that most of the companies who go on to hire programmers to make their sites and such, always don't have accommodations and the interest of people different than them in mind.
-
-
social-media-ethics-automation.github.io social-media-ethics-automation.github.io
-
Address
I choose Address. We can store the Address by a structured object, including street address, city, state/province, country, and postal code. The constraints for Address would be it must allow for international variations in address formats.
-
-
academic.oup.com academic.oup.com
-
eighth century
given that the roman legal customs of objection to written law appeared to persist, it's a fair assumption that this assembly existed before 700 AD and at the time of the creation of the code
-
promoted peace without compromising pride. It was also more consistent with Christian teaching than revenge-killing.
which was a key aspect ins regards to insuring that the code was actually used in practice, given the significant role that honour and reputation played within Kentish society at the time
-
A more uniform influence from the same period was that of the Christian Church, which after the arrival of St Augustine’s mission from Rome (597 ad)
An event which would directly influence/encourage the inception of Æthelberhts code
-
-
theconversation.com theconversation.com
-
Le télétravail a été introduit dans le Code du travail à l’article 1222-9 par la loi du 23 mars 2012 (l’article 46 de la loi dite Warsmann définit le télétravail). Cette loi prévoit des mesures de protection des données et de préservation de la vie privée.
Deuxième argument épistémique. Le télétravail est inclus dans le Code du travail. Par conséquent, la frontière vie personnelle/professionnelle du télétravailleur devrait être respectée et davantage surveillée par le pouvoir juridique.
-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
The following is the authors’ response to the original reviews.
We would like to thank the reviewers for their insightful comments and recommendations. We have extensively revised the manuscript in response to the valuable feedback. We believe the results is a more rigorous and thoughtful analysis of the data. Furthermore, our interpretation and discussion of the findings is more focused and highlights the importance of the circuit and its role in the response to stress. Thank you for helping to improve the presented science.
Key changes made in response to the reviewers comments include:
• Revision of statistical analyses for nearly all figures, with the addition of a new table of summary statistics to include F and/or t values alongside p-values.
• Addition of statistical analyses for all fiber photometry data.
• Examination of data for possible sex dependent effects.
• Clarification of breeding strategies and genotype differences, with added details to methods to improve clarity.
• Addressing concerns about the specificity of virus injections and the spread, with additional details added to methods.
• Modification of terminology related to goal-directed behavior based on reviewer feedback, including removal of the term from the manuscript.
• Clarification and additional data on the use of photostimulation and its effects, including efforts to inactivate neurons for further insight, despite technical challenges.
• Correction of grammatical errors throughout the manuscript.
Reviewer 1:
Despite the manuscript being generally well-written and easy to follow, there are several grammatical errors throughout that need to be addressed.
Thank you for highlighting this issue. Grammatical errors have been fixed in the revised version of the manuscript.
Only p values are given in the text to support statistical differences. This is not sufficient. F and/or t values should be given as well.
In response to this critique and similar comments from Reviewer 2, we re-evaluated our approach to statistical analyses and extensively revised analyses for nearly all figures. We also added a new table of summary statistics (Supplemental Table 1) containing the type of analysis, statistic, comparison, multiple comparisons, and p value(s). For Figures 4C-E, 5C, 6C-E, 7H-I, and 8H we analyzed these data using two-way repeated measures (RM) ANOVA that examined the main effect of time (either number of sessions or stimulation period) in the same animal and compared that to the main effect of genotype of the animal (Cre+ vs Cre-), and if there was an interaction. For Supplemental Figure 7A we also conducted a two-way RM ANOVA with time as a factor and activity state (number of port activations in active vs inactive nose port) as the other in Cre+ mice. For Figures 5D-E we conducted a two-way mixed model ANOVA that accounted and corrected for missing data. In figures that only compared two groups of data (Figures 5F-L, 6F, 8C-D, 8I, and Supp 6F-G) we used two-tailed t-test for the analysis. If our question and/or hypothesis required us to conduct multiple comparisons between or within treatments, we conducted Bonferroni’s multiple comparisons test for post hoc analysis (we note which groups we compared in Supplemental Table 1). For figures that did or did not show a change in calcium activity (Figure 3G, 3I-K, 7B, 7D-E, 8E-F), we compared waveform confidence intervals (Jean-Richard-Dit-Bressel, Clifford, McNally, 2020). The time windows we used as comparison are noted in Supplemental Table 1, and if the comparisons were significant at 95%, 99%, and 99.9% thresholds.
None of prior comparisons in prior analyses that were significant were found to have fallen below thresh holds for significance. Of those found to be not significantly different, only one change was noted. In Figure 6E there was now a significant baseline difference between Cre+ and Cre- mice with Cre- mice taking longer to first engage the port compared to Cre+ mice (p=0.045). Although the more rigorous approach the statistical analyses did not change our interpretations we feel the enhanced the paper and thank the reviewer for pushing this improvement.
Moreover, the fibre photometry data does not appear to have any statistical analyses reported - only confidence intervals represented in the figures without any mention of whether the null hypothesis that the elevations in activity observed are different from the baseline.
This is particularly important where there is ambiguity, such as in Figure 3K, where the spontaneous activity of the animal appears to correlate with a spike in activity but the text mentions that there is no such difference. Without statistics, this is difficult to judge.
Thank you for highlighting this critical point and providing an opportunity to strengthen our manuscript. We added statistical analyses of all fiber photometry data using a recently described approach based on waveform confidence intervals (Jean-Richard-Dit-Bressel, Clifford, McNally, 2020). In the statistical summary (Supplemental Table 1) we note the time window that we used for comparison in each analysis and if the comparisons were significant at 95%, 99%, and 99.9% thresholds. Thank you from highlighting this and helping make the manuscript stronger.
With respect to Figure 3K, we are not certain we understood the spike in activity the reviewer referred to. Figure 3J and K include both velocity data (gold) and Ca2+ dependent signal (blue). We used episodes of velocity that were comparable to the avoidance respond during the ambush test and no significant differences in the Ca2+ signal when gating around changes in velocity in the absence of stressor (Supplemental Table1). This is in contrast to the significant change in Ca2+ signal following a mock predator ambush (Figure 3J). We interpret these data together to indicate that locomotion does not correlate with an increase in calcium activity in SuMVGLUT2+::POA neurons, but that coping to a stressor does. This conclusion is further examined in supplemental Figure 5, including examining cross-correlation to test for temporally offset relationship between velocity and Ca2+ signal in SUMVGLUT2+::POA neurons.
The use of photostimulation only is unfortunate, it would have been really nice to see some inactivation of these neurons as well. This is because of the well-documented issues with being able to determine whether photostimulation is occurring in a physiological manner, and therefore makes certain data difficult to interpret. For instance, with regards to the 'active coping' behaviours - is this really the correct characterisation of what's going on? I wonder if the mice simply had developed immobile responding as a coping strategy but when they experience stimulation of these neurons that they find aversive, immobility is not sufficient to deal with the summative effects of the aversion from the swimming task as well as from the neuronal activation? An inactivation study would be more convincing.
We agree with the point of the reviewer, experiments demonstrating necessity of SUMVGLUT2+::POA neurons would have added to the story here. We carried out multiple experiments aimed at addressing questions about necessity of SuMVGLUT2+::POA neurons in stress coping behaviors, specifically the forced swim assay. Efforts included employing chemogenetic, optogenetic, and tetanus toxin-based methods. We observed no effects on locomotor activity or stress coping. These experiments are both technically difficult and challenging to interpret. Interpretation of negative results, as we obtained, is particularly difficult because of potential technical confounds. Selective targeting of SuMVGLUT2+::POA neurons for inhibition requires a process requiring three viral injections and two recombination steps, increasing variability and reducing the number of neurons impacted. Alternatively, photoinhibition targeting SuMVGLUT2+::POA cells can be done using Retro-AAV injected into POA and a fiber implant over SuM. We tried both approaches. Data obtained were difficult to interpret because of questions about adequate coverage of SuMVGLUT2+::POA population by virally expressed constructs and/or light spread arose. The challenge of adequate coverage to effectively prevent output from the targeted population is further confounded by challenges inherent in neural inhibition, specifically determining if the inhibition created at the cellular level is adequate to block output in the context of excitatory inputs or if neurons must be first engaged in a particular manner for inhibition to be effective. Baseline neural activity, release probability, and post-synaptic effects could all be relevant, which photo-inhibition will potentially not resolve. So, while the trend is to always show “necessary and sufficient” effects, we’ve tried nearly everything, and we simply cannot conclude much from our mixed results. There are also wellestablished problems with existing photo-inhibition methods, which while people use them and tout them, are often ignored. We have a lot of expertise in photo-inhibition optogenetics, and indeed have used it with some success, developed new methods, yet in this particular case we are unable to draw conclusions related to inhibition. People have experienced similar challenges in locus coeruleus neurons, which have very low basal activity, and inhibition with chemogenetics is very hard, as well as with optogenetic pump-based approaches, because the neurons fire robust rebound APs. We have spent almost 2.5 years trying to get this to work in this circuit because reviews have been insistent on this result for the paper to be conclusive. Unfortunately, it simply isn’t possible in our view until we know more about the cell types involved. This is all in spite of experience using the approach in many other publications.
We also employed less selective approaches, such as injecting AAV-DIO-tetanus toxin light chain (Tettox) constructs directly into SuM VGLUT2-Cre mice but found off target effects impacting animal wellbeing and impeding behavioral testing due viral spread to surrounding areas.
While we are disappointed for being unable to directly address questions about necessity of SuMVGLUT2+::POA neurons in active coping with experimental data, we were unable to obtain results allowing for clear interpretation across numerous other domains the reviewers requested. We also feel strongly that until we have a clear picture of the molecular cell type architecture in the SuM, and Cre-drivers to target subsets of neurons, this question will be difficult to resolve for any group. We are working now on RNAseq and related spatial transcriptomics efforts in the SuM and examining additional behavioral paradigm to resolve these issues, so stay tuned for future publications.
Accordingly, we avoid making statements relating to necessity in the manuscript. In spite of having several lines of physiological data with strong robust correlations behavior related to the SuMVGLUT2+::POA circuit.
Nose poke is only nominally instrumental as it cannot be shown to have a unique relationship with the outcome that is independent of the stimuli-outcome relationships (in the same way that a lever press can, for example). Moreover, there is nothing here to show that the behaviours are goal-directed.
Thank you for highlighting this point. Regarding goal-direct terminology, we removed this terminology from the manuscript. Since the mice perform highly selective (active vs inactive) port activation robustly across multiple days of training the behavior likely transitions to habitual behavior. We only tested the valuation of stimuli termination of the final day of training with time limited progressive ratio test. With respect to lever press versus active port activation, we are unclear how using a lever in this context would offer a different interpretation. Lever pressing may be more sensitive to changes in valuation when compared to nose poke port activation (Atalayer and Rowland 2008); however, in this study the focus of the operant behavior is separating innate behaviors for learned action–outcome instrumental learned behaviors for threat response (LeDoux and Daw 2018). The robust highly selective activation of the active port illustrated in Figure 6 fits as an action–outcome instrumental behavior wherein mice learn to engage the active but not inactive port to terminate photostimulation. The first activation of the port occurs through exploration of the arena but as demonstrated by the number of active port activations and the decline in time of the first active port engagement, mice expressing ChR2eYFP learn to engage the port to terminate the stimulation. To aid in illustrating this point we have added Supplemental Figure 7 showing active and inactive port activations for both Cre+ and Cre- mice. This adds clarity to high rate of selective port activation driven my stimulation of SUMVGLUT2+::POA neurons compared to controls. The elimination of goal directed and providing additional data narrows and supports one of the key points of the operant experiment.
With regards to Figure 1: This is a nice figure, but I wonder if some quantification of the pathways and their density might be helpful, perhaps by measuring the intensity of fluorescence in image J (as these are processes, not cell bodies that can be counted)? Mind you, they all look pretty dense so perhaps this is not necessary! However, because the authors are looking at projections in so-called 'stress-engaged regions', the amygdala seems conspicuous by its absence. Did the authors look in the amygdala and find no projections? If so it seems that this would be worth noting.
This is an interesting question but has proven to be a very technically challenging question. We consulted with several leaders who routinely use complimentary viral tracing methods in the field. We were unable to devise a method to provide a satisfactorily meaningful quantitative (as opposed to qualitative) approach to compare SUMVGLUT2+::POA to SuMVGLUT2+ projections. A few limitations are present that hinder a meaningful quantitative approach. One limitation was the need for different viral strategies to label the two populations. Labeling SuMVGLUT2+::POA neurons requires using VGLUT2-Flp mice with two injections into the POA and one into SuM. Two recombinase steps were required, reducing efficiency of overlap. This combination of viral injections, particularly the injections of RetroAAVs in the POA, can induce significant quantitative variability due to tropism, efficacy, and variability of retro-viral methods, and viral infection generally. These issues are often totally ignored in similar studies across the “neural circuit” landscape, but it doesn’t make them less relevant here.
Although people do this in the field, and show quantification, we actually believe that it can be a quite misleading read-out of functionally relevant circuitry, given that neurotransmitter release ultimately is amplified by receptors post-synaptically, and many examples of robust behavioral effects have been observed with low fiber tracing complimentary methods (McCall, Siuda et al. 2017). In contrast, the broader SuMVGLUT2+ population was labeled using a single injection into the SuM. This means there like more efficient expression of the fluorophore. Additionally, in areas that contain terminals and passing fibers understanding and interpreting fluorescent signal is challenging. Together, these factors limit a meaningful quantitative comparison and make an interpretation difficult to make. In this context, we focused on a conservative qualitative presentation to demonstrate two central points. That 1) SuMVGLUT2+::POA neurons are subset of SuMVGLUT2+ neurons that project to specific areas and that exclude dentate gyrus, and they 2) arborize extensively to multiple areas which have be linked to threat responses. We agree that there is much to be learned about how different populations in SuM connect to targets in different regions of the brain and to continue to examine this question with different techniques. A meaningful quantitative study comparing projections is technically complex and, we feel, beyond our ability for this study.
Also, for the reasons above we do not believe that quantification provides exceptional clarity with respect to the putative function of the circuit, glutamate released, or other cotransmitters given known amplification at the post-synaptic side of the circuit.
With regard to the amygdala, other studies on SuM projections have found efferent projections to amygdala (Ottersen, 1980; Vertes, 1992). In our study we were unable to definitively determine projections from SuMVGLUT2+::POA neurons to amygdala, which if present are not particularly dense. For this reason we were conservative and do not comment on this particular structure.
I would suggest removing the term goal-directed from the manuscript and just focusing on the active vs. passive distinction.
We removed the use of goal-directed. Thank you for helping us clarify our terminology.
The effect observed in Figure 7I is interesting, and I'm wondering if a rebound effect is the most likely explanation for this. Did the authors inhibit the VGAT neurons in this region at any other times and observe a similar rebound? If such a rebound was not observed it would suggest that it is something specific about this task that is producing the behaviour. I would like it if the authors could comment on this.
We agree that results showing the change in coping strategy (passive to active) in forced swim after but not during stimulation of SuMVGAT+ neurons is quite interesting (Figure 7I). This experiment activated SuMVGAT+ neurons during a section of the forced swim assay and mice showed a robust shift to mobility after the stimulation of SuMVGAT+ neurons stopped. We did not carry out inhibition of SuMVGAT+ neurons in this manuscript. As the reviewer suggested, strong inhibition of local SuM neurons, including SUMVGLUT2+::POA neurons, could lead to rebound activity that may shift coping behaviors in confusing ways. We agree this is an interesting idea but do not have data to support the hypothesis further at this time.
Reviewer 2
(1) These are very difficult, small brain regions to hit, and it is commendable to take on the circuit under investigation here. However, there is no evidence throughout the manuscript that the authors are reliably hitting the targets and the spread is comparable across experiments, groups, etc., decreasing the significance of the current findings. There are no hit/virus spread maps presented for any data, and the representative images are cropped to avoid showing the brain regions lateral and dorsal to the target regions. In images where you can see the adjacent regions, there appears expression of cell bodies (such as Supp 6B), suggesting a lack of SuM specificity to the injections.
We agree with the reviewer that the areas studied are small and technically challenging to hit. This was one of driving motivations for using multiple tools in tandem to restrict the area targeted for stimulation. Approaches included using a retrograde AAVs to express ChR2eFYP in SUMVGLUT2+::POA neurons; thereby, restricting expression to VGLUT2+ neurons that project to the POA. Targeting was further limited by placement of the optic fiber over cell bodies on SuM. Thus, only neurons that are VGLUT2+, project to the POA, and were close enough to the fiber were active by photostimulation. Regrettably, we were not able to compile images from mice where the fiber was misplaced leading to loss of behavioral effects. We would have liked to provide that here to address this comment. Unfortunately, generating heat maps for injections is not possible for anatomic studies that use unlabeled recombinase as part of an intersectional approach. Also determining the point of injection of a retroAAV can be difficult to accurately determine its location because neurons remote to injection site and their processes are labeled.
Experiments described in Supplemental Figure 6B on VGAT neurons in SuM were designed and interpreted to support the point that SUMVGLUT2+::POA neurons are a distinct population that does not overlap with GABAergic neurons. For this point it is important that we targeted SuM, but highly confined targeting is not needed to support the central interpretation of the data. We do see labeling in SuM in VGAT-Cre mice but photo stimulation of SuMVGAT+ neurons does not generate the behavioral changes seen with activation of SUMVGLUT2+::POA neurons. As the reviewer points out, SuM is small target and viral injection is likely to spread beyond the anatomic boundaries to other VGAT+ neurons in the region, which are not the focus here. The activation would be restricted by the spread of light from the fiber over SuM (estimated to be about a 200um sphere in all directions). We did not further examine projections or localization of VGAT+ neurons in this study but focused on the differential behavioral effects of SUMVGLUT2+::POA neurons.
(2) In addition, the whole brain tracing is very valuable, but there is very little quantification of the tracing. As the tracing is the first several figures and supp figure and the basis for the interpretation of the behavior results, it is important to understand things including how robust the POA projection is compared to the collateral regions, etc. Just a rep image for each of the first two figures is insufficient, especially given the above issue raised. The combination of validation of the restricted expression of viruses, rep images, and quantified tracing would add rigor that made the behavioral effects have more significance.
For example, in Fig 2, how can one be sure that the nature of the difference between the nonspecific anterograde glutamate neuron tracing and the Sum-POA glutamate neuron tracing is real when there is no quantification or validation of the hits and expression, nor any quantification showing the effects replicate across mice? It could be due to many factors, such as the spread up the tract of the injection in the nonspecific experiment resulting in the labeling of additional regions, etc.
Relatedly, in Supp 4, why isn’t C normalized to DAPI, which they show, or area? Similar for G what is the mcherry coverage/expression, and why isn’t Fos normalized to that?
Thank you for highlighting the importance of anatomy and the value of anatomy. Two points based on the anatomic studies are central to our interpretation of the experimental data. First, SUMVGLUT2+::POA are a distinct population within the SuM. We show this by demonstrating they are not GABAergic and that they do not project to dentate gyrus. Projections from SuM to dentate gyrus have been described in multiple studies (Boulland et al., 2009; Haglund et al., 1987; Hashimotodani et al., 2018; Vertes, 1992) and we demonstrate them here for SuMVGLUT2+ cells. Using an intersectional approach in VGLUT2-Flp mice we show SUMVGLUT2+::POA neurons do not project to dentate gyrus. We show cell bodies of SUMVGLUT2+::POA neurons located in SuM across multiple figures including clear brain images. Thus, SUMVGLUT2+::POA neurons are SuM neurons that do not project to dentate gyrus, are not GABAergic, send projections to a distinct subset of targets, most notably excluding dentate gyrus. Second, SUMVGLUT2+::POA neurons arborize sending projections to multiple regions. We show this using a combinatorial genetic and viral approach to restrict expression of eYFP to only neurons that are in SuM (based on viral injection), project to the POA (based on retrograde AAV injection in POA), and VGLUT2+ (VGLUT2-Flp mice). Thus, any eYFP labeled projection comes from SUMVGLUT2+::POA neurons. We further confirmed projections using retroAAV injection into areas identified using anterograde approaches (Supplemental Figure 2). As discussed above in replies to Reviewer 1, we feel limitations are present that preclude meaningful quantitative analysis. We thus opted for a conservative interpretation as outlined.
Prior studies have shown efferent projections from SuM to many areas, and projections to dentate gyrus have received substantial attention (Bouland et al., 2009; Haglund, Swanson, and Kohler, 1984; Hashimotodani et al., 2018; Soussi et al., 2010; Vertes, 1992; Pan and McNaugton, 2004). We saw many of the same projections from SuMVGLUT2+ neurons. We found no projections from SUMVGLUT2+::POA neurons to dentate gyrus (Figure 2). Our description of SuM projection to dentate gyrus is not new but finding a population of neurons in SuM that does not project to dentate gyrus but does project to other regions in hippocampus is new. This finding cannot be explained by spread of the virus in the tract or non-selective labeling.
(3) The authors state that they use male and female mice, but they do not describe the n’s for each experiment or address sex as a biological variable in the design here. As there are baseline sex differences in locomotion, stress responses, etc., these could easily factor into behavioral effects observed here.
Sex specific effects are possible; however, the studies presented here were not designed or powered to directly examine them. A point about experimental design that helps mitigate against strong sex dependent effect is that often the paradigm we used examined baseline (pre-stimulation) behavior, how behavior changed during stimulation, and how behavior returned (or not) to baseline after stimulation. Thus, we test changes in individual behaviors. Although we had limited statistical power, we conducted analyses to examine the effects of sex as variable in the experiments and found no differences among males and females.
(4) In a similar vein as the above, the authors appear to use mice of different genotypes (however the exact genotypes and breeding strategy are not described) for their circuit manipulation studies without first validating that baseline behavioral expression, habituation, stress responses are not different. Therefore, it is unclear how to interpret the behavioral effects of circuit manipulation. For example in 7H, what would the VGLUT2-Cre mouse with control virus look like over time? Time is a confound for these behaviors, as mice often habituate to the task, and this varies from genotype to genotype. In Fig 8H, it looks like there may be some baseline differences between genotypes- what is normal food consumption like in these mice compared to each other? Do Cre+ mice just locomote and/or eat less? This issue exists across the figures and is related to issues of statistics, potential genotype differences, and other experimental design issues as described, as well as the question about the possibility of a general locomotor difference (vs only stress-induced). In addition, the authors use a control virus for the control groups in VGAT-Cre manipulation studies but do not explain the reasoning for the difference in approach.
Thank you for highlighting the need for greater clarity about the breeding strategies used and for these related questions. We address the breeding strategy and then move to address the additional concerns raised. We have added details to the methods section to address this point. For VGLUT2-Cre mice we use litter mates controls from Cre/WT x WT/WT cross. The VGLUT2-Cre line (RRID:IMSR_JAX:028863) (Vong L , et al. 2011) used here been used in many other reports. We are not aware of any reports indicating a phenotype associated with the addition of the IRES-Cre to the Slc17a6 loci and there is no expected impact of expression of VGLUT2. Also, we see in many of the experiments here that the baseline (Figures 4, 5, and 7) behaviors are not different between the Cre+ and Cre- mice. For VGAT-Cre mice we used a different breeding strategy that allowed us to achieve greater control of the composition of litters and more efficient cohorts cohort. A Cre/Cre x WT/WT cross yielded all Cre/WT litters. The AAV injected, ChR2eYFP or eYFP, allowed us to balance the cohort.
Regarding Figure 7H, which shows time immobile on the second day of a swim test, data from the Cre- mice demonstrate the natural course of progression during the second day of the test. The control mice in the VGAT-Cre cohort (Figure 7I) have similar trend. The change in behavior during the stimulation period in the Cre+ mice is caused by the activation of SUMVGLUT2+::POA neurons. The behavioral shift largely, but not completely, returns to baseline when the photostimulation stops. We have no reason to believe a VGLUT2-Cre+ mouse injected with control AAV to express eYFP would be different from WT littermate injected with AVV expressing ChR2eYFP in a Cre dependent manner.
Turning to concerns related to 8H, which shows data from fasted mice quantify time spent interacting with food pellet immediately after presentation of a chow pellet, we found no significant difference between the control and Cre+ mice. We unaware of any evidence indicating that the two groups should have a different baseline since the Cre insertion is not expected to alter gene expression and we are unaware of reports of a phenotype relating to feeding and the presence of the transgene in this mouse line. Even if there were a small baseline shift this would not explain the large abrupt shift induced by the photostimulation. As noted above, we saw shifts in behavior abruptly induced by the initiation of photostimulation when compared to baseline in multiple experiments. This shift would not be explained by a hypothetical difference in the baseline behaviors of litter mates.
(5) The statistics used throughout are inappropriate. The authors use serial Mann-Whitney U tests without a description of data distributions within and across groups. Further, they do not use any overall F tests even though most of the data are presented with more than two bars on the same graph. Stats should be employed according to how the data are presented together on a graph. For example, stats for pre-stim, stim, and post-stim behavior X between Cre+ and Cre- groups should employ something like a two-way repeated measures ANOVA, with post-hoc comparisons following up on those effects and interactions. There are many instances in which one group changes over time or there could be overall main effects of genotype. Not only is serially using Mann-Whitney tests within the same panel misleading and statistically inaccurate, but it cherry-picks the comparisons to be made to avoid more complex results. It is difficult to comprehend the effects of the manipulations presented without more careful consideration of the appropriate options for statistical analysis.
We thank the reviewer for pointing this out and suggesting alterative analyses, we agree with the assessment on this topic. Therefore, we have extensively revised the statical approach to our data using the suggested approach. Reviewer 1 also made a similar comment, and we would like to point to our reply to reviewer 1’s second point in regard to what we changed and added to the new statistical analyses. Further, we have added a full table detailing the statical values for each figure to the paper.
Conceptual:
(6) What does the signal look like at the terminals in the POA? Any suggestion from the data that the projection to the POA is important?
This is an interesting question that we will pursue in future investigations into the roles of the POA. We used the projection to the POA from SuM to identify a subpopulation in SuM and we were surprised to find the extensive arborization of these neurons to many areas associated with threat responses. We focused on the cell bodies as “hubs” with many “spokes”. Extensive studies are needed to understand the roles of individual projections and their targets. There is also the hypothetical technical challenge of manipulating one projection without activating retrograde propagation of action potentials to the soma. At the current time we have no specific insights into the roles of the isolated projection to POA. Interpretation of experiments activating only “spoke” of the hub would be challenging. Simple terminal stimulation experiments are challenged by the need to separate POA projections from activation of passing fibers targeting more anterior structures of the accumbens and septum.
(7) Is this distinguishing active coping behavior without a locomotor phenotype? For example, Fig. 5I and other figure panels show a distance effect of stimulation (but see issues raised about the genotype of comparison groups). In addition, locomotor behavior is not included for many behaviors, so it is hard to completely buy the interpretation presented.
We agree with the reviewer and thank them for highlighting this fundamental challenge in studies examining active coping behaviors in rodents, which requires movement. Additionally, actively responding to threatening stressors would include increased locomotor activity. Separation of movement alone from active coping can be challenging. Because of these concerns we undertook experiments using diverse behavioral paradigms to examine the elicited behaviors and the recruitment of SuMVGLUT2+::POA neurons to stressors. We conducted experiments to directly examine behaviors evoked by photoactivation of SuMVGLUT2+::POA. In these experiments we observed a diversity of behaviors including increased locomotion and jumping but also treading/digging (Figure 4). These are behaviors elicited in mice by threatening and noxious stimuli. An Increase of running or only jumping could signify a specific locomotor effect, but this is not what was observed. Based on these behaviors, we expected to find evidence of increase movement in open field (Figure 5G-I) and light dark choice (Figure 5J-L) assays. For many of the assays, reporting distance traveled is not practical. An important set of experiments that argues against a generic increase in locomotion is the operant behavior experiments, which require the animal to engage in a learned behavior while receiving photostimulation of SuMVGLUT2+::POA neurons (Figure 6). This is particularly true for testing using a progressive ratio when the time of ongoing photostimulation is longer, yet animals actively and selectively engage the active port (Figure 6G-H). Further, we saw a shift in behavioral strategy induce by photoactivation in forced swim test (Figure 7H). Thus, activation of SUMVGLUT2+::POA neurons elicited a range of behaviors that included swimming, jumping, treading, and learned response, not just increased movement. Together these data strongly argue that SuMVGLUT2+::POA neurons do not only promote increased locomotor behavior. We interpret these data together with the data from fiber photometry studies to show SuMVGLUT2+::POA neurons are recruited during acute stressors, contribute to aversive affective component of stress, and promote active behaviors without constraining the behavioral pattern.
Regarding genotype, we address this in comments above as well but believe that clarifying the use of litter mates, the extensive use of the VGLUT2-Cre line by multiple groups, and experimental design allowing for comparison to baseline, stimulation evoked, and post stimulation behaviors within and across genotypes mitigate possible concerns relating to the genotype.
(8) What is the role of GABA neurons in the SuM and how does this relate to their function and interaction with glutamate neurons? In Supp 8, GABA neuron activation also modulates locomotion and in Fig 7 there is an effect on immobility, so this seems pretty important for the overall interpretation and should probably be mentioned in the abstract.
Thank you for noting these interesting findings. We added text to highlight these findings to the abstract. Possible roles of GABAergic neurons in SuM extend beyond the scope of the current study particularly since SuM neurons have been shown to release both GABA and glutamate (Li Y, Bao H, Luo Y, et al. 2020, Root DH, Zhang S, Barker DJ et al. 2018). GABAergic neurons regulate dentate gyrus (Ajibola MI, Wu JW, Abdulmajeed WI, Lien CC 2021), REM sleep (Billwiller F, Renouard L, Clement O, Fort P, Luppi PH 2017), and novelty processing Chen S, He L, Huang AJY, Boehringer R et al. 2020). The population of exclusively GABAergic vs dual neurotransmitter neurons in SuM requires further dissection to be understood. How they may relate to SUMVGLUT2+::POA neurons require further investigation.
Questions about figure presentation:
(9) In Fig 3, why are heat maps shown as a single animal for the first couple and a group average for the others?
Thank you for highlighting this point for further clarification. We modified the labels in the figure to help make clear which figures are from one animal across multiple trials and those that are from multiple animals. In the ambush assay each animal one had one trial, to avoid habituation to the mock predator. Accordingly, we do not have multiple trials for each animal in this test. In contrast, the dunk assay (10 trial/animal) and the shock (5 trials/animal) had multiple trials for each animal. We present data from a representative animal when there are multiple trials per animal and the aggerate data.
Why is the temporal resolution for J and K different even though the time scale shown is the same?
Thank you for noticing this error carried forward from a prior draft of the figure so we could correct it. We replaced the image in 3J with a more correctly scaled heatmap.
What is the evidence that these signal changes are not due to movement per se?
Thank you for the question. There are two points of evidence. First, all the 465 nm excitation (Ca2+ dependent) data was collected in interleaved fashion with 415 nm (isosbestic) excitation data. The isosbestic signal is derived from GCaMP emission but is independent of Ca2+ binding (Martianova E, Aronson S, Proulx CD. 2019). This approach, time-division multiplexing, can correct calcium-dependent for changes in signal most often due to mechanical change. The second piece of evidence is experimental. Using multiple cohorts of mice, we examined if the change in Ca2+ signal was correlated with movement. We used the threshold of velocity of movement seen following the ambush. We found no correlation between high velocity movements and Ca2+ signal (Figure 3K) including cross correlational analysis (Supplemental figure 5). Based on these points together we conclude the change in the Ca2+ signal in SUMVGLUT2+::POA neurons is not due to movement induced mechanical changes and we find no correlation to movement unless a stressor is present, i.e. mock predator ambush or forced swim. Further, the stressors evoke very different locomotor responses fleeing, jumping, or swimming.
(10) In Fig 4, the authors carefully code various behaviors in mice. While they pick a few and show them as bars, they do not show the distribution of behaviors in Cre- vs Cre+ mice before manipulation (to show they have similar behaviors) or how these behaviors shift categories in each group with stimulation. Which behaviors in each group are shifting to others across the stim and post-stim periods compared to pre-stim?
This is an important point. We selected behaviors to highlight in Figure4 C-E because these behaviors are exhibited in response to stress (De Boer & Koolhaas, 2003; van Erp et al., 1994). For the highlighted behaviors, jumping, treading/digging, grooming, we show baseline (pre photostimulation), stimulation, and post stimulation for Cre+ and Cre- mice with the values for each animal plotted. We show all nine behaviors as a heat map in Figure 4B. The panels show changes that may occur as a function of time and show changes induced by photostimulation.
The heatmaps demonstrate that photostimulation of SUMVGLUT2+::POA neurons causes a suppression of walking, grooming, and immobile behaviors with an increase in jumping, digging/treading, and rapid locomotion. After stimulation stops, there is an increase in grooming and time immobile. The control mice show a range of behaviors with no shifts noted with the onset or termination of photostimulation.
Of note, issues of statistics, genotype, and SABV are important here. For example, the hint that treading/digging may have a slightly different pre-stim basal expression, it seems important to first evaluate strain and sex differences before interpreting these data.
We examined the effects of sex as a biological variable in the experiments reported in the manuscript and found no differences among males and females in any of the experiments where we had enough animals in each sex (minimum of 5 mice) for meaningful comparisons. We did this by comparing means and SEM of males and females within each group (e.g. Cre+ males vs Cre+ female, Cre- males vs Cre- females) and then conducted a t-test to see if there was a difference. For figures that show time as a variable (e.g Figure 6C-E), we compared males and females with time x sex as main factors and compared them (including multiple comparisons if needed). We found no significant main effects or interactions between males and females. Because of this, and to maximize statistical power, we decided to move forward to keep males and females together in all the analyses presented in the manuscript. It is worth noting also that the core of the experimental design employed is a change in behavior caused by photostimulation. The mice are also the same strain with only difference being the modification to add an IRES and sequence for Cre behind the coding sequence of the Slc17A6 (VGLUT2) gene.
(11) Why do the authors use 10 Hz stimulation primarily? is this a physiologically relevant stim frequency? They show that they get effects with 1 Hz, which can be quite different in terms of plasticity compared to 10 Hz.
Thank you for the raising this important question. Because tests like open field and forced swim are subject to habituation and cannot be run multiple times per animal a test frequency was needed to use across multiple experiments for consistency. The frequency of 10Hz was selected because it falls within the rate of reported firing rates for SuM neurons (Farrel et al., 2021; Pedersen et al., 2017) and based on the robust but sub maximal effects seen in the real-time place preference assays. Identification of the native firing rates during stress response would be ideal but gathering this data for the identified population remains a dauting task.
(12) In Fig 5A-F, it is unclear whether locomotion differences are playing a role. Entrances (which are low for both groups) are shown but distance traveled or velocity are not.
In B, there is no color in the lower left panel. where are these mice spending their time? How is the entirety of the upper left panel brighter than the lower left? If the heat map is based on time distribution during the session, there should be more color in between blue and red in the lower left when you start to lose the red hot spots in the upper left, for example. That is, the mice have to be somewhere in apparatus. If the heat map is based on distance, it would seem the Cre- mice move less during the stim.
We appreciate the opportunity to address this question, and the attention to detail the reviewer applied to our paper. In the real time place preference test (RTPP) stimulation would only be provided while the animal was on the stimulation side. Mice quickly leave the stimulation side of the arena, as seen in the supplemental video, particularly at the higher frequencies. Thus, the time stimulation is applied is quite low. The mice often retreat to a corner from entering the stimulation side during trials using higher frequency stimulation. Changing locomotor activity along could drive changes in the number entrances but we did not find this. In regard to the heat map, the color scale is dynamically set for each of the paired examples that are pulled from a single trial. To maximize the visibility between the paired examples the color scale does not transfer between the trials. As a result, in the example for 10 Hz the mouse spent a larger amount of time in the in the area corresponding to the lower right corner of the image and the maximum value of the color scale is assigned to that region. As seen in the supplemental video, mice often retreated to the corner of the non-stimulation side after entering the stimulation side. The control animal did not spend a concentrated amount of time in any one region, thus there is a lack of warmer colors. In contrast the baseline condition both Cre+ and Cre- mice spent time in areas disturbed on both sides of arena, as expected. As a result, the maximum value in the heat map is lower and more area are coded in warmer colors allowing for easier visual comparison between the pair. Using the scale for the 10 Hz pair across all leads to mostly dark images. We considered ways to optimized visualization across and within pairs and focused on the within pair comparison for visualization.
(13) By starting with 1 hz, are the experimenters inducing LTD in the circuit? what would happen if you stop stimming after the first epoch? Would the behavioral effect continue? What does the heat map for the 1 hz stim look like?
Relatedly, it is a lot of consistent stimulation over time and you likely would get glutamate depletion without a break in the stim for that long.
Thank you for the opportunity to add clarity around this point regarding the trials in RTPP testing. Importantly, the trials were not carried out in order of increasing frequency of stimulation, as plotted. Rather, the order of trials was, to the extent possible with the number of mice, counterbalanced across the five conditions. Thus, possible contribution of effects of one trial on the next were minimized by altering the order of the trials.
We have added a heat map for the 1 Hz condition to figure 5B.
For experiments on RTPP the average stimulation time at 10Hz was less than 10 seconds per event. As a result, the data are unlikely to be affected by possible depletion of synaptic glutamate. For experiments using sustained stimulation (open field or light dark choice assays) we have no clear data to address if this might be a factor where 10Hz stimulation was applied for the entire trial.
(14) In Fig 6, the authors show that the Cre- mice just don't do the task, so it is unclear what the utility of the rest of the figure is (such as the PR part). Relatedly, the pause is dependent on the activation, so isn't C just the same as D? In G and H, why ids a subset of Cre+ mice shown?
Why not all mice, including Cre- mice?
Thank you for the opportunity to improve the clarity of this section. A central aspect of the experiments in Figure 6 is the aversiveness of SUMVGLUT2+::POA neuron photostimulation, as shown in Figure 5B-F. The aversion to photostimulation drives task performance in the negative reinforcer paradigm. The mice perform a task (active port activation) to terminate the negative reinforcer (photostimulation of SuMVGLUT2+::POA neurons). Accordingly, control mice are not expected to perform the task because SuMVGLUT2+::POA neurons are not activated and, thus the mice are not motivated to perform the task.
A central point we aim to covey in this figure is that while SuMVGLUT2+::POA neurons are being stimulated, mice perform the operant task. They selectively activated the active port (Supplemental Figure 7). As expected, control mice activate the active port at a low level in the process of exploring the arena. This diminishes on subsequent trials as mice habituate to the arena (Figure 6D). The data in Figures 6 C and D are related but can be divergent. Each pause in stimulation requires a port activation of a FR1 test but the number of port activations can exceed the pauses, which are 10 seconds long, if the animal continues to activate the port. Comparing data in Figures 6 C and D revels that mice generally activated the port two to three times for each pause earned with a trend towards greater efficiency on day 4 with more rewards and fewer activations.
The purpose of the progressive ratio test is to examine if photostimulation of SuMVGLUT2+::POA continues to drive behavior as the effort required to terminate the negative stimuli increases. As seen in Figures 6 G and H, the stimulation of SuMVGLUT2+::POA neurons remains highly motivating. In the 20-minute trial we did not find a break point even as the number of port activations required to pause the stimulation exceed 50. We do not show the Cre- mice is Figure 6G and H because they did not perform the task, as seen in Figure 6F. For technical reasons in early trials, we have fully timely time stamped data for rewards and port activations from a subset of the Cre+ mice. Of note, this contains both the highest and lowest performing mice from the entire data set.
Taken together, we interpret the results of the operant behavioral testing as demonstrating that SuMVGLUT2+::POA neuron activation is aversive, can drive performance of an operant tasks (as opposed to fixed escape behaviors), and is highly motivating.
(15) In Fig 7, what does the GCaMP signal look like if aligned to the onset of immobility? It looks like since the hindpaw swimming is short and seems to precede immobility, and the increase in the signal is ramping up at the onset of hindpaw swimming, it may be that the calcium signal is aligned with the onset of immobility.
What does it look like for swimming onset?
In I, what is the temporal resolution for the decrease in immobility? Does it start prior to the termination of the stim, or does it require some elapsed time after the termination, etc?
Thank for the opportunity to addresses these points and improve that clarity of our interpretation of the data. Regarding aligning the Ca2+ signal from fiber photometry recordings to swimming onset and offset, it is important to note that the swimming bouts are not the same length. As a result, in the time prior to alignment to offset of behaviors animals will have been swimming for different lengths of time. In Figure 7 C, we use the behavioral heat map to convey the behavioral average. Below we show the Ca2+ dependent signal aligned at the offset of hindpaw swim for an individual mouse (A) and for the total cohort (B). This alignment shows that the Ca2+ dependent signal declines corresponding to the termination of hindpaw swimming. Because these bouts last less than the total the widow shown, the data is largely included in Figure 7 C and D, which is aligned to onset. Due to the nuance of the difference is the alignment and the partial redundancy, we elected to include the requested alignment to swimming offset in the reply rather in primary figure.
Author response image 1.

Turning to the question regarding swimming onset, the animals started swimming immediately when placed in the water and maintained swimming and climbing behaviors until shifting behaviors as illustrated in Figure 7A and B. During this time the Ca2+-dependent signal was elevated but there is only one trial per animal. This question can perhaps be better addressed in the dunk assay presented in Figure 3C, F and G and Supplemental Figure 4 H and I. Here swimming started with each dunk and the Ca2+ signal increased.
Regarding the question for about figure 7I. We scored for entire periods (2 mins) in aggerate. We noted in videos of the behavior test that there was an abrupt decrease in immobility tightly corresponding to the end of stimulation. In a few animals this shift occurred approximately 15-20s before the end of stimulation. This may relate to the depletion of neurotransmitter as suggested by the reviewer.
Reviewer 3
Major points
(1) Results in Figure 1 suggested that SuM-Vglu2::POA projected not only POA but also to the diverse brain regions. We can think of two models which account for this. One is that homogeneous populations of neurons in SuM-Vglu2::POA have collaterals and innervated all the efferent targets shown in Figure 1. Another is to think of distinct subpopulations of neurons projecting subsets of efferent targets shown in Figure 1 as well as POA. It is suggested to address this by combining approaches taken in experiments for Figure 1 and Supplemental Figure 2.
Thank you for raising this interesting point. We have attempted combining retroAAV injections into multiple areas that receive projections from SUMVGLUT2+::POA neurons. However, we have found the results unsatisfactory for separating the two models proposed. Using eYFP and tdTomato expressing we saw some overlapping expressing in SuM. We are not able to conclude if this indicates separate populations or partial labeling of a homogenous populations. A third option seems possible as well. There could be a mix of neurons projecting to different combinations of downstream targets. This seems particularly difficult to address using fluorophores. We are preparing to apply additional methodologies to this question, but it extends beyond the scope of this manuscript.
(2) Since the authors drew a hypothetical model in which the diverse brain regions mediate the effect of SuM-Vglu2::POA activation in behavioral alterations at least in part, examination of the concurrent activation of those brain regions upon photoactivation of SuM-Vglu2::POA. This must help the readers to understand which neural circuits act upon the induction of active coping behavior under stress.
Thank you for raising this important point. We agree that activating glutamatergic neurons should lead to activation of post synaptic neurons in the target regions. Delineating this in vivo is less straight forward. Doing so requires much greater knowledge of post synaptic partners of SUMVGLUT2+::POA neurons. There are a number of issues that would need to be accounted for. Undertaking two color photo stimulation plus fiber photometry is possible but not a technical triviality. Further, it is possible that we would measure Ca2+ signals in neurons that have no relevant input or that local circuits in a region may shape the signal. We would also lack temporal resolution to identify mono-postsynaptic vs polysynaptic connections. Thus, we would struggle to know if the change in signal was due to the excitatory input from SuM or from a second region. At present, we remain unclear on how to pursue this question experimentally in a manner that is likely to generate clearly interpretable results.
(3) In Figure 4, "active coping behaviors" must be called "behaviors relevant to the active behaviors" or "active coping-like behaviors", since those behaviors were in the absence of stressors to cope with.
Thank you for the suggestion on how to clarify our terminology. We have adopted the active coping-like term.
(4) For the Dunk test, it is suggested to describe the results and methods more in detail, since the readers would be new to it. In particular, the mice could change their behavior between dunks under this test, although they still showed immobility across trials as in Supplemental Figure 4I. Since neural activity during the test was summarized across trials as in Figure 3, it is critical to examine whether the behavior changes according to time.
Thank you for identifying this opportunity to improve our manuscript. We have expanded and added a detailed description of the dunk test in the methods section.
As for Supplemental Figure 4I, we apologize for the confusion because the purpose of this figure is to show that mice remained mobile for the entire 30-second dunk trial. This did not appreciably change over the 10 trials. We have revised this figure to plot both immobile and mobile time to achieve greater clarity on this point.
Minor points
Typos
In Figure 1, please add a serotype of AAVs to make it compatible with other figures and their legends.
In the main text and Figure 2K, the authors used MHb/LHb and mHb/lHb in a mixed fashion. Please make them unified.
In the figure legend of Figure 6, change "SuMVGLUT2+::POA neurons drive" to "SuMVGLUT2+::POA neurons " in the title.
In line 86, please change "Retro-AAV2-Nuc-flox(mCherry)-eGFP" to "AAV5-Nuc-flox(mCherry)eGFP".
In line 80, please change "Positive controls" to "As positive controls, ".
Thank you for taking the time and making the effort to identify and call these out. We have corrected them.
-
-
www.biorxiv.org www.biorxiv.org
-
Reviewer #2 (Public Review):
In this manuscript, Yang et al. present a modeling framework to understand the pattern of response biases and variance observed in delayed-response orientation estimation tasks. They combine a series of modeling approaches to show that coupled sensory-memory networks are in a better position than single-area models to support experimentally observed delay-dependent response bias and variance in cardinal compared to oblique orientations. These errors can emerge from a population-code approach that implements efficient coding and Bayesian inference principles and is coupled to a memory module that introduces random maintenance errors. A biological implementation of such operation is found when coupling two neural network modules, a sensory module with connectivity inhomogeneities that reflect environment priors, and a memory module with strong homogeneous connectivity that sustains continuous ring attractor function. Comparison with single-network solutions that combine both connectivity inhomogeneities and memory attractors shows that two-area models can more easily reproduce the patterns of errors observed experimentally. This, the authors take as evidence that a sensory-memory network is necessary, but I am not convinced about the evidence in support of this "necessity" condition. A more in-depth understanding of the mechanisms operating in these models would be necessary to make this point clear.
Strengths:
The model provides an integration of two modeling approaches to the computational bases of behavioral biases: one based on Bayesian and efficient coding principles, and one based on attractor dynamics. These two perspectives are not usually integrated consistently in existing studies, which this manuscript beautifully achieves. This is a conceptual advancement, especially because it brings together the perceptual and memory components of common laboratory tasks.
The proposed two-area model provides a biologically plausible implementation of efficient coding and Bayesian inference principles, which interact seamlessly with a memory buffer to produce a complex pattern of delay-dependent response errors. No previous model had achieved this.
Weaknesses:
The correspondence between the various computational models is not fully disclosed. It is not easy to see this correspondence because the network function is illustrated with different representations for different models and the correspondence between components of the various models is not specified. For instance, Figure 1 shows that a specific pattern of noise is required in the low-dimensional attractor model, but in the next model in Figure 2, the memory noise is uniform for all stimuli. How do these two models integrate? What element in the population-code model of Figure 2 plays the role of the inhomogeneous noise of Figure 1? Also, the Bayesian model of Figure 2 is illustrated with population responses for different stimuli and delays, while the attractor models of Figures 3 and 4 are illustrated with neuronal tuning curves but not population activity. In addition, error variance in the Bayesian model appears to be already higher for oblique orientations in the first iteration whereas it is only first shown one second into the delay for the attractor model in Figure 4. It is thus unclear whether variance inhomogeneities appear already at the perceptual stage in the attractor model, as it does in the population-code model. Of course, correspondences do not need to be perfect, but the reader does not know right now how far the correspondence between these models goes.
The manuscript does not identify the mechanistic origin in the model of Figure 4 of the specific noise pattern that is required for appropriate network function (with higher noise variance at oblique orientations). This mechanism appears critical, so it would be important to know what it is and how it can be regulated. In particular, it would be interesting to know if the specific choice of Poisson noise in Equation (3) is important. Tuning curves in Figure 4 indicate that population activity for oblique stimuli will have higher rates than for cardinal stimuli and thus induce a larger variance of injected noise in oblique orientations, based on this Poisson-noise assumption. If this explanation holds, one wonders if network inhomogeneities could be included (for instance in neural excitability) to induce higher firing rates in the cardinal/oblique orientations so as to change noise inhomogeneities independently of the bias and thus control more closely the specific pattern of errors observed, possibly within a single memory network.
The main conclusion of the manuscript, that the observed patterns of errors "require network interaction between two distinct modules" is not convincingly shown. The analyses show that there is a quantitative but not a qualitative difference between the dynamics of the single memory area compared to the sensory-memory two-area network, for specific implementations of these models (Figure 7 - Figure Supplement 1). There is no principled reasoning that demonstrates that the required patterns of response errors cannot be obtained from a different memory model on its own. Also, since the necessity of the two-area configuration is highlighted as the main conclusion of the manuscript, it is inconvenient that the figure that carefully compares these conditions is in the Supplementary Material.
The proposed model has stronger feedback than feedforward connections between the sensory and memory modules. This is not a common assumption when thinking about hierarchical processing in the brain, and it is not discussed in the manuscript.
-
-
chiselapp.com chiselapp.com
-
La concatenación de cadenas (strings) es el proceso de unir dos o más cadenas para formar una sola cadena más larga y se realiza utilizando el operador coma
La concatenación de cadenas (strings) es el proceso de unir dos o más cadenas para formar una sola cadena más larga y se realiza utilizando el operador coma
Ejemplo: 'Pharo tutorial ', ' is cool', ' when i active the code '

-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
The following is the authors’ response to the original reviews.
Reviewer #1 (Recommendations For The Authors):
(1) Methods, please state the sex of the mice.
This has now been added to the methods section:
“Three to nine month old Thy1-GCaMP6S mice (Strain GP4.3, Jax Labs), N=16 stroke (average age: 5.4 months; 13 male, 3 female), and 5 sham (average age: 6 months; 3 male, 2 female), were used in this study.”
(2) The analysis in Fig 3B-D, 4B-C, and 6A, B highlights the loss of limb function, firing rate, or connections at 1 week but this phenomenon is clearly persisting longer in some datasets (Fig. 3 and 6). Was there not a statistical difference at weeks 2,3,4,8 relative to "Pre-stroke" or were comparisons only made to equivalent time points in the sham group? Personally, I think it is useful to compare to "pre-stroke" which should be more reflective of that sample of animals than comparing to a different set of animals in the Sham group. A 1 sample t-test could be used in Fig 4 and 6 normalized data.
On further analysis of our datasets, normalization throughout the manuscript was unnecessary for proper depiction of results, and all normalized datasets have been replaced with nonnormalized datasets. All within group statistics are now indicated within the manuscript.
(3) Fig 4A shows a very striking change in activity that doesn't seem to be borne out with group comparisons. Since many neurons are quiet or show very little activity, did the authors ever consider subgrouping their analysis based on cells that show high activity levels (top 20 or 30% of cells) vs those that are inactive most of the time? Recent research has shown that the effects of stroke can have a disproportionate impact on these highly active cells versus the minimally active ones.
A qualitative analysis supports a loss of cells with high activity at the 1-week post-stroke timepoint, and examination of average firing rates at 1-week shows reductions in the animals with the highest average rates. However, we have not tracked responses within individual neurons or quantitatively analyzed the data by subdividing cells into groups based on their prestroke activity levels. We have amended the discussion of the manuscript with the following to highlight the previous data as it relates to our study:
“Recent research also indicates that stroke causes distinct patterns of disruption to the network topology of excitatory and inhibitory cells [73], and that stroke can disproportionately disrupt the function of high activity compared to low activity neurons in specific neuron sub-types [61]. Mouse models with genetically labelled neuronal sub-types (including different classes of inhibitory interneurons) could be used to track the function of those populations over time in awake animals.”
(4) Fig 4 shows normalized firing rates when moving and at rest but it would be interesting to know what the true difference in activity was in these 2 states. My assumption is that stroke reduces movement therefore one normalizes the data. The authors could consider putting non-normalized data in a Supp figure, or at least provide a rationale for not showing this, such as stating that movement output was significantly suppressed, hence the need for normalization.
On further analysis of our datasets, normalization throughout the manuscript was unnecessary for proper depiction of results, and all normalized datasets have been replaced with nonnormalized datasets.
(5) One thought for the discussion. The fact that the authors did not find any changes in "distant" cortex may be specific to the region they chose to sample (caudal FL cortex). It is possible that examining different "distant" regions could yield a different outcome. For example, one could argue that there may have been no reason for this area to "change" since it was responsive to FL stimuli before stroke. Further, since it was posterior to the stroke, thalamocortical projects should have been minimally disturbed.
We would like to thank the reviewer for this comment. We have amended the discussion with the following:
“Our results suggest a limited spatial distance over which the peri-infarct somatosensory cortex displays significant network functional deficits during movement and rest. Our results are consistent with a spatial gradient of plasticity mediating factors that are generally enhanced with closer proximity to the infarct core [84,88,90,91]. However, our analysis outside peri-infarct cortex is limited to a single distal area caudal to the pre-stroke cFL representation. Although somatosensory maps in the present study were defined by a statistical criterion for delineating highly responsive cortical regions from those with weak responses, the distal area in this study may have been a site of activity that did not meet the statistical criterion for inclusion in the baseline map. The lack of detectable changes in population correlations, functional connectivity, assembly architecture and assembly activations in the distal region may reflect minimal pressure for plastic change as networks in regions below the threshold for regional map inclusion prior to stroke may still be functional in the distal cortex. Thus, threshold-based assessment of remapping may further overestimate the neuroplasticity underlying functional reorganization suggested by anaesthetized preparations with strong stimulation. Future studies could examine distal areas medial and anterior to the cFL somatosensory area, such as the motor and pre-motor cortex, to further define the effect of FL targeted stroke on neuroplasticity within other functionally relevant regions. Moreover, the restriction of these network changes to peri-infarct cortex could also reflect the small penumbra associated with photothrombotic stroke, and future studies could make use of stroke models with larger penumbral regions, such as the middle cerebral artery occlusion model. Larger injuries induce more sustained sensorimotor impairment, and the relationship between neuronal firing, connectivity, and neuronal assemblies could be further probed relative to recovery or sustained impairment in these models.”
Minor comments:
Line 129, I don't necessarily think the infarct shows "hyper-fluorescence", it just absorbs less white light (or reflects more light) than blood-rich neighbouring regions.
Sentence in the manuscript has been changed to:
“Resulting infarcts lesioned this region, and borders could be defined by a region of decreased light absorption 1 week post-stroke (Fig 1D, Top).”
Line 130-132: the authors refer to Fig 1D to show cellular changes but these cannot be seen from the images presented. Perhaps a supplementary zoomed-in image would be helpful.
As changes to the morphology of neurons are not one of the primary objectives of this study, and sampled resolution was not sufficiently high to clearly delineate the processes of neurons necessary for morphological assessment, we have amended the text as follows:
“Within the peri-infarct imaging region, cellular dysmorphia and swelling was visually apparent in some cells during two photon imaging 1-week after stroke, but recovered over the 2 month poststroke imaging timeframe (data not shown). These gross morphological changes were not visually apparent in the more distal imaging region lateral to the cHL.”
Lines 541-543, was there a rationale for defining movement as >30mm/s? Based on a statistical estimate of noise?
Text has been altered as follows:
“Animal movement within the homecage during each Ca2+ imaging session was tracked to determine animal speed and position. Movement periods were manually annotated on a subset of timeseries by co-recording animal movement using both the Mobile Homecage tracker, as well as a webcam (Logitech C270) with infrared filter removed. Movement tracking data was low pass filtered to remove spurious movement artifacts lasting below 6 recording frames (240ms). Based on annotated times of animal movement from the webcam recordings and Homecage tracking, a threshold of 30mm/s from the tracking data was determined as frames of animal movement, whereas speeds below 30mm/s was taken as periods of rest.”
Lines 191-195: Note that although the finding of reduced neural activity is in disagreement with a multi-unit recording study, it is consistent with other very recent single-cell Ca++ imaging data after stroke (PMID: 34172735 , 34671051).
Text has been altered as follows:
“These results indicate decreased neuronal spiking 1-week after stroke in regions immediately adjacent to the infarct, but not in distal regions, that is strongly related to sensorimotor impairment. This finding runs contrary to a previous report of increased spontaneous multi-unit activity as early as 3-7 days after focal photothrombotic stroke in the peri-infarct cortex [1], but is in agreement with recent single-cell calcium imaging data demonstrating reduced sensoryevoked activity in neurons within the peri-infarct cortex after stroke [60,61].”
Fig 7. I don't understand what the color code represents. Are these neurons belonging to the same assembly (or membership?).
That is correct, neurons with identical color code belong to the same assembly. The legend of Fig 7 has been modified as follows to make this more explicit:
“Fig 7. Color coded neural assembly plots depict altered neural assembly architecture after stroke in the peri-infarct region. (A) Representative cellular Ca2+ fluorescence images with neural assemblies color coded and overlaid for each timepoint. Neurons belonging to the same assembly have been pseudocolored with identical color. A loss in the number of neural assemblies after stroke in the peri-infarct region is visually apparent, along with a concurrent increase in the number of neurons for each remaining assembly. (B) Representative sham animal displays no visible change in the number of assemblies or number of neurons per assembly.”
Reviewer #2 (Recommendations For The Authors):
Materials and methods
Identification of forelimb and hindlimb somatosensory cortex representations [...] Cortical response areas are calculated using a threshold of 95% peak activity within the trial. The threshold is presumably used to discriminate between the sensory-evoked response and collateral activation / less "relevant" response (noise). Since the peak intensity is lower after stroke, the "response" area is larger - lower main signal results in less noise exclusion. Predictably, areas that show a higher response before stroke than after are excluded from the response area before stroke and included after. While it is expected that the remapped areas will exhibit a lower response than the original and considering the absence of neuronal activity, assembly architecture, or functional connectivity in the "remapped" regions, a minimal criterion for remapping should be to exhibit higher activation than before stroke. Please use a different criterion to map the cortical response area after stroke.
We would like to thank the reviewer for this comment. We agree with the reviewer’s assessment of 95% of peak as an arbitrary criterion of mapped areas. To exclude noise from the analysis of mapped regions, a new statistical criterion of 5X the standard deviation of the baseline period was used to determine the threshold to use to define each response map. These maps were used to determine the peak intensity of the forelimb response. We also measured a separate ROI specifically overlapping the distal region, lateral to the hindlimb map, to determine specific changes to widefield Ca2+ responses within this distal region. We have amended the text as follows and have altered Figure 2 with new data generated from our new criterion for cortical mapping.
“The trials for each limb were averaged in ImageJ software (NIH). 10 imaging frames (1s) after stimulus onset were averaged and divided by the 10 baseline frames 1s before stimulus onset to generate a response map for each limb. Response maps were thresholded at 5 times the standard deviation of the baseline period deltaFoF to determine limb associated response maps. These were merged and overlaid on an image of surface vasculature to delineate the cFL and cHL somatosensory representations and were also used to determine peak Ca2+ response amplitude from the timeseries recordings. For cFL stimulation trials, an additional ROI was placed over the region lateral to the cHL representation (denoted as “distal region” in Fig 2E) to measure the distal region cFL evoked Ca2+ response amplitude pre- and post-stroke. The dimensions and position of the distal ROI was held consistent relative to surface vasculature for each animal from pre- to post-stroke.”
Animals
Mice used have an age that goes from 3 to 9 months. This is a big difference given that literature on healthy aging reports changes in neurovascular coupling starting from 8-9 months old mice. Consider adding age as a covariate in the analysis.
We do not have sufficient numbers of animals within this study to examine the effect of age on the results observed herein. We have amended the discussion with the following to address this point:
“A potential limitation of our data is the undefined effect of age and sex on cortical dynamics in this cohort of mice (with ages ranging from 3-9 months) after stroke. Aging can impair neurovascular coupling [102–107] and reduce ischemic tolerance [108–111], and greater investigation of cortical activity changes after stroke in aged animals would more effectively model stroke in humans. Future research could replicate this study with mice in middle-age and aged mice (e.g. 9 months and 18+ months of age), and with sufficient quantities of both sexes, to better examine age and sex effects on measures of cortical function.”
Statistics
Please describe the "normalization" that was applied to the firing rate. Since a mixedeffects model was used, why wasn't baseline simply added as a covariate? With this type of data, normalization is useful for visualization purposes.
On further analysis of our datasets, normalization throughout the manuscript was unnecessary for the visualization of results, and all normalized datasets have been replaced with nonnormalized datasets. All within group comparisons are now indicated throughout the manuscript and in the figures.
Introduction
Line 93 awake, freely behaving but head-fixed. That's not freely. Should just say behaving.
Sentence has been edited as follows:
“We used awake, behaving but head-fixed mice in a mobile homecage to longitudinally measure cortical activity, then used computational methods to assess functional connectivity and neural assembly architecture at baseline and each week for 2 months following stroke.”
110 - 112 The last part of this sentence is unjustified because these areas have been incorrectly identified as locations of representational remapping.
We agree with the reviewer and have amended the manuscript as follows after re-analyzing the dataset on widefield Ca2+ imaging of sensory-evoked responses: “Surprisingly, we also show that significant alterations in neuronal activity (firing rate), functional connectivity, and neural assembly architecture are absent within more distal regions of cortex as little as 750 µm from the stroke border, even in areas identified by regional functional imaging (under anaesthesia) as ‘remapped’ locations of sensory-evoked FL activity 8-weeks post-stroke.”
Results
149-152 There is no observed increase in the evoked response area. There is an observed change in the criteria for what is considered a response.
We agree with the reviewer. Text has been amended as follows:
“Fig 2A shows representative montages from a stroke animal illustrating the cortical cFL and cHL Ca2+ responses to 1s, 100Hz limb stimulation of the contralateral limbs at the pre-stroke and 8week post-stroke timepoints. The location and magnitude of the cortical responses changes drastically between timepoints, with substantial loss of supra-threshold activity within the prestroke cFL representation located anterior to the cHL map, and an apparent shift of the remapped representation into regions lateral to the cHL representation at 8-weeks post-stroke. A significant decrease in the cFL evoked Ca2+ response amplitude was observed in the stroke group at 8-weeks post-stroke relative to pre-stroke (Fig 2B). This is in agreement with past studies [19–25], and suggests that cFL targeted stroke reduces forelimb evoked activity across the cFL somatosensory cortex in anaesthetized animals even after 2 months of recovery. There was no statistical change in the average size of cFL evoked representation 8-weeks after stroke (Fig 2C), but a significant posterior shift of the supra-threshold cFL map was detected (Fig 2D). Unmasking of previously sub-threshold cFL responsive cortex in areas posterior to the original cFL map at 8-weeks post-stroke could contribute to this apparent remapping. However, the amplitude of the cFL evoked widefield Ca2+ response in this distal region at 8-weeks post-stroke remains reduced relative to pre-stroke activation (Fig 2E). Previous studies suggest strong inhibition of cFL evoked activity during the first weeks after photothrombosis [25]. Without longitudinal measurement in this study to quantify this reduced activation prior to 8-weeks poststroke, we cannot differentiate potential remapping due to unmasking of the cFL representation that enhances the cFL-evoked widefield Ca2+ response from apparent remapping that simply reflects changes in the signal-to-noise ratio used to define the functional representations. There were no group differences between stroke and sham groups in cHL evoked intensity, area, or map position (data not shown).”
A lot of the nonsignificant results are reported as "statistical trends towards..." While the term "trend" is problematic, it remains common in its use. However, assigning directionality to the trend, as if it is actively approaching a main effect, should be avoided. The results aren't moving towards or away from significance. Consider rewording the way in which these results are reported.
We have amended the text to remove directionality from our mention of statistical trends.
R squared and p values for significant results are reported in the "impaired performance on tapered beam..." and "firing rate of neurons in the peri-infarct cortex..." subsections of the results, but not the other sections. Please report the results in a consistent manner.
R-squared and p-values have been removed from the results section and are now reported in figure captions consistently.
Discussion
288 Remapping is defined as "new sensory-evoked spiking". This should be the main criterion for remapping, but it is not operationalized correctly by the threshold method.
With our new criterion for determining limb maps using a statistical threshold of 5X the standard deviation of baseline fluorescence, we have edited text throughout the manuscript to better emphasize that we may not be measuring new sensory-evoked spiking with the mesoscale mapping that was done. We have edited the discussion as follows:
“Here, we used longitudinal two photon calcium imaging of awake, head-fixed mice in a mobile homecage to examine how focal photothrombotic stroke to the forelimb sensorimotor cortex alters the activity and connectivity of neurons adjacent and distal to the infarct. Consistent with previous studies using intrinsic optical signal imaging, mesoscale imaging of regional calcium responses (reflecting bulk neuronal spiking in that region) showed that targeted stroke to the cFL somatosensory area disrupts the sensory-evoked forelimb representation in the infarcted region. Consistent with previous studies, this functional representation exhibited a posterior shift 8-weeks after injury, with activation in a region lateral to the cHL representation. Notably, sensory-evoked cFL representations exhibited reduced amplitudes of activity relative to prestroke activation measured in the cFL representation and in the region lateral the cHL representation. Longitudinal two-photon calcium imaging in awake animals was used to probe single neuron and local network changes adjacent the infarct and in a distal region that corresponded to the shifted region of cFL activation. This imaging revealed a decrease in firing rate at 1-week post-stroke in the peri-infarct region that was significantly negatively correlated with the number of errors made with the stroke-affected limbs on the tapered beam task. Periinfarct cortical networks also exhibited a reduction in the number of functional connections per neuron and a sustained disruption in neural assembly structure, including a reduction in the number of assemblies and an increased recruitment of neurons into functional assemblies. Elevated correlation between assemblies within the peri-infarct region peaked 1-week after stroke and was sustained throughout recovery. Surprisingly, distal networks, even in the region associated with the shifted cFL functional map in anaesthetized preparations, were largely undisturbed.”
“Cortical plasticity after stroke Plasticity within and between cortical regions contributes to partial recovery of function and is proportional to both the extent of damage, as well as the form and quantity of rehabilitative therapy post-stroke [80,81]. A critical period of highest plasticity begins shortly after the onset of stroke, is greatest during the first few weeks, and progressively diminishes over the weeks to months after stroke [19,82–86]. Functional recovery after stroke is thought to depend largely on the adaptive plasticity of surviving neurons that reinforce existing connections and/or replace the function of lost networks [25,52,87–89]. This neuronal plasticity is believed to lead to topographical shifts in somatosensory functional maps to adjacent areas of the cortex. The driver for this process has largely been ascribed to a complex cascade of intra- and extracellular signaling that ultimately leads to plastic re-organization of the microarchitecture and function of surviving peri-infarct tissue [52,80,84,88,90–92]. Likewise, structural and functional remodeling has previously been found to be dependent on the distance from the stroke core, with closer tissue undergoing greater re-organization than more distant tissue (for review, see [52]).”
“Previous research examining the region at the border between the cFL and cHL somatosensory maps has shown this region to be a primary site for functional remapping after cFL directed photothrombotic stroke, resulting in a region of cFL and cHL map functional overlap [25]. Within this overlapping area, neurons have been shown to lose limb selectivity 1-month post-stroke [25]. This is followed by the acquisition of more selective responses 2-months post-stroke and is associated with reduced regional overlap between cFL and cHL functional maps [25]. Notably, this functional plasticity at the cellular level was assessed using strong vibrotactile stimulation of the limbs in anaesthetized animals. Our findings using longitudinal imaging in awake animals show an initial reduction in firing rate at 1-week post-stroke within the peri-infarct region that was predictive of functional impairment in the tapered beam task. This transient reduction may be associated with reduced or dysfunctional thalamic connectivity [93–95] and reduced transmission of signals from hypo-excitable thalamo-cortical projections [96]. Importantly, the strong negative correlation we observed between firing rate of the neural population within the peri-infarct cortex and the number of errors on the affected side, as well as the rapid recovery of firing rate and tapered beam performance, suggests that neuronal activity within the peri-infarct region contributes to the impairment and recovery. The common timescale of neuronal and functional recovery also coincides with angiogenesis and re-establishment of vascular support for peri-infarct tissue [83,97–100].”
“Consistent with previous research using mechanical limb stimulation under anaesthesia [25], we show that at the 8-week timepoint after cFL photothrombotic stroke the cFL representation is shifted posterior from its pre-stroke location into the area lateral to the cHL map. Notably, our distal region for awake imaging was directly within this 8-week post-stroke cFL representation. Despite our prediction that this distal area would be a hotspot for plastic changes, there was no detectable alteration to the level of population correlation, functional connectivity, assembly architecture or assembly activations after stroke. Moreover, we found little change in the firing rate in either moving or resting states in this region. Contrary to our results, somatosensoryevoked activity assessed by two photon calcium imaging in anesthetized animals has demonstrated an increase in cFL responsive neurons within a region lateral to the cHL representation 1-2 months after focal cFL stroke [25]. Notably, this previous study measured sensory-evoked single cell activity using strong vibrotactile (1s 100Hz) limb stimulation under aneasthesia [25]. This frequency of limb stimulation has been shown to elicit near maximal neuronal responses within the limb-associated somatosensory cortex under anesthesia [101]. Thus, strong stimulation and anaesthesia may have unmasked non-physiological activity in neurons in the distal region that is not apparent during more naturalistic activation during awake locomotion or rest. Regional mapping defined using strong stimulation in anesthetized animals may therefore overestimate plasticity at the cellular level.”
“Our results suggest a limited spatial distance over which the peri-infarct somatosensory cortex displays significant network functional deficits during movement and rest. Our results are consistent with a spatial gradient of plasticity mediating factors that are generally enhanced with closer proximity to the infarct core [84,88,90,91]. However, our analysis outside peri-infarct cortex is limited to a single distal area caudal to the pre-stroke cFL representation. Although somatosensory maps in the present study were defined by a statistical criterion for delineating highly responsive cortical regions from those with weak responses, the distal area in this study may have been a site of activity that did not meet the statistical criterion for inclusion in the baseline map. The lack of detectable changes in population correlations, functional connectivity, assembly architecture and assembly activations in the distal region may reflect minimal pressure for plastic change as networks in regions below the threshold for regional map inclusion prior to stroke may still be functional in the distal cortex. Thus, threshold-based assessment of remapping may further overestimate the neuroplasticity underlying functional reorganization suggested by anaesthetized preparations with strong stimulation. Future studies could examine distal areas medial and anterior to the cFL somatosensory area, such as the motor and pre-motor cortex, to further define the effect of FL targeted stroke on neuroplasticity within other functionally relevant regions. Moreover, the restriction of these network changes to peri-infarct cortex could also reflect the small penumbra associated with photothrombotic stroke, and future studies could make use of stroke models with larger penumbral regions, such as the middle cerebral artery occlusion model. Larger injuries induce more sustained sensorimotor impairment, and the relationship between neuronal firing, connectivity, and neuronal assemblies could be further probed relative to recovery or sustained impairment in these models. Recent research also indicates that stroke causes distinct patterns of disruption to the network topology of excitatory and inhibitory cells [73], and that stroke can disproportionately disrupt the function of high activity compared to low activity neurons in specific neuron sub-types [61]. Mouse models with genetically labelled neuronal sub-types (including different classes of inhibitory interneurons) could be used to track the function of those populations over time in awake animals. A potential limitation of our data is the undefined effect of age and sex on cortical dynamics in this cohort of mice (with ages ranging from 3-9 months) after stroke. Aging can impair neurovascular coupling [102–107] and reduce ischemic tolerance [108–111], and greater investigation of cortical activity changes after stroke in aged animals would more effectively model stroke in humans. Future research could replicate this study with mice in middle-age and aged mice (e.g. 9 months and 18+ months of age), and with sufficient quantities of both sexes, to better examine age and sex effects on measures of cortical function.”
315 - 317 Remodelling is dependent on the distance from the stroke core, with closer tissue undergoing greater reorganization than more distant tissue. There is no evidence that the more distant tissue undergoes any reorganization at all.
We agree with the reviewer that no remodelling is apparent in our distal area. We have removed reference to our study showing remodeling in the distal area, and have amended the text as follows:
“Likewise, structural and functional remodeling has previously been found to be dependent on the distance from the stroke core, with closer tissue undergoing greater re-organization than more distant tissue (for review, see [52]).”
412-414 The authors speculate that a strong stimulation under anaesthesia may unmask connectivity in distal regions. However, the motivation for this paper is that anaesthesia is a confounding factor. It appears to me that, given the results of this study, the authors should argue that the functional connectivity observed under anaesthesia may be spurious.
The incorrect word was used here. We have corrected the paragraph of the discussion and amended it as follows:
“Consistent with previous research using mechanical limb stimulation under anaesthesia [25], we show that at the 8-week timepoint after cFL photothrombotic stroke the cFL representation is shifted posterior from its pre-stroke location into the area lateral to the cHL map. Notably, our distal region for awake imaging was directly within this 8-week post-stroke cFL representation. Despite our prediction that this distal area would be a hotspot for plastic changes, there was no detectable alteration to the level of population correlation, functional connectivity, assembly architecture or assembly activations after stroke. Moreover, we found little change in the firing rate in either moving or resting states in this region. Contrary to our results, somatosensoryevoked activity assessed by two photon calcium imaging in anesthetized animals has demonstrated an increase in cFL responsive neurons within a region lateral to the cHL representation 1-2 months after focal cFL stroke [25]. Notably, this previous study measured sensory-evoked single cell activity using strong vibrotactile (1s 100Hz) limb stimulation under aneasthesia [25]. This frequency of limb stimulation has been shown to elicit near maximal neuronal responses within the limb-associated somatosensory cortex under anesthesia [101]. Thus, strong stimulation and anaesthesia may have unmasked non-physiological activity in neurons in the distal region that is not apparent during more naturalistic activation during awake locomotion or rest. Regional mapping defined using strong stimulation in anesthetized animals may therefore overestimate plasticity at the cellular level.”
Figures
Figure 1 and 2: Scale bar missing.
Scale bars added to both figures.
Figure 2: The representative image shows a drastic reduction of the forelimb response area, contrary to the general description of the findings. It would also be beneficial to see a graph with lines connecting the pre-stroke and 8-week datapoints.
The data for Figure 2 has been re-analyzed using a new criterion of 5X the standard deviation of the baseline period for determining the threshold for limb mapping. Figure 2 and relevant manuscript and figure legend text has been amended. In agreement with the reviewers observation, there is no increase in forelimb response area, but instead a non-significant decrease in the average forelimb area.
-
-
www.biorxiv.org www.biorxiv.org
-
Reviewer #1 (Public Review):
Summary:
Building upon their famous tool for the deconvolution of human transcriptomics data (EPIC), Gabriel et al. implemented a new methodology for the quantification of the cellular composition of samples profiled with Assay for Transposase-Accessible Chromatin sequencing (ATAC-Seq). To build a signature for ATAC-seq deconvolution, they first created a compendium of ATAC-seq data and derived chromatin accessibility marker peaks and reference profiles for 21 cell types, encompassing immune cells, endothelial cells, and fibroblasts. They then coupled this novel signature with the EPIC deconvolution framework based on constrained least-square regression to derive a dedicated tool called EPIC-ATAC. The method was then assessed using real and pseudo-bulk RNA-seq data from human peripheral blood mononuclear cells (PBMC) and, finally, applied to ATAC-seq data from breast cancer tumors to show it accurately quantifies their immune contexture.
Strengths:
Overall, the work is of very high quality. The proposed tool is timely; its implementation, characterization, and validation are based on rigorous methodologies and resulted in robust results. The newly-generated, validation data and the code are publicly available and well-documented. Therefore, I believe this work and the associated resources will greatly benefit the scientific community.
Weaknesses:
A few aspects can be improved to clarify the value and applicability of the EPIC-ATAC and the transparency of the benchmarking analysis.
Most of the validation results in the main text assess the methods on all cell types together, by showing the correlation, RMSE, and scatterplots of the estimated vs. true cell fractions. This approach is valuable for showing the overall method performance and for detecting systematic biases and noisy estimates. However, it provides very limited insights regarding the capability of the methods to estimate the individual cell types, which is the ultimate aim of deconvolution analysis. This limitation is exacerbated for rare cell types, which could even have a negative correlation with the ground truth fractions, but not weigh much on the overall RMSE and correlation. I would suggest integrating into the main text and figures an in-depth assessment of the individual cell types. In particular, it should be shown and discussed which cell types can be accurately quantified and which ones are less reliable.
In the benchmarking analysis, EPIC-ATAC is compared to several deconvolution methods, most of which were originally developed for transcriptomics data. This comparison is not completely fair unless their peculiarities and the limitations of tweaking them to work with ATAC-seq data are discussed. For instance, some methods (including the original EPIC) correct for cell-type-specific mRNA bias, which is not present in ATAC-seq data and might, thus, result in systematic errors.
On a similar note, it could be made more explicit which adaptations were introduced in EPIC, besides the ad-hoc ATAC-seq signature, to make it applicable to this type of data.
Given that the final applicability of EPIC-ATAC is on real bulk RNA-seq data, whose characteristics might not be completely recapitulated by pseudo-bulk samples, it would be interesting to see EPIC and EPIC-ATAC compared on a dataset with matched, real bulk RNA-seq and ATAC-seq, respectively. It would nicely complement the analysis of Figure 7 and could be used to dissect the commonalities and peculiarities of these two approaches.
-
-
www.mensurdurakovic.com www.mensurdurakovic.com
-
You can think of it as the following cycle:software engineer writes codeusers get new featuresmore users use your productscompany profits from productsSo code is just a tool to get profit.
The core software development process
-
-
social-media-ethics-automation.github.io social-media-ethics-automation.github.io
-
Since bots are computer programs, let’s look at the structure of code written in programming languages. With all languages (including programming languages), you combine pieces of the language together according to specific rules in order to create meaning. For example: Consider this sentence in English: I was at UW (University of Washington, Seattle) yesterday. In our constructing that sentence, we used a number of English language rules, such as: Putting the subject I before the verb was Ending the sentence with a period . Making a parenthetical remark with a matching opening parenthesis ( and closing parenthesis ). This parenthetical remark clarified the part of the sentence before it UW. Programming languages also have their own set of rules for combining and organizing pieces of code in order to create meaning. We will look at some of these rules in these sections:
User Interface (UI) Input Mechanism: This is how users interact with the bot. It could be through text (as in chatbots), voice commands, or even through visual inputs in more advanced systems. Output Mechanism: This refers to how the bot communicates back to the user, which can also be text, spoken language, or images and other media.
-
-
austinhenley.com austinhenley.com
-
On code-authoring tasks, students in the Codex group had a significantly higher correctness score (80%) than the Baseline (44%), and overall finished the tasks significantly faster. However, on the code-modifying tasks, both groups performed similarly in terms of correctness, with the Codex group performing slightly better (66%) than the Baseline (58%).
In a study, students who learned to code with AI made more progress during training sessions, had significantly higher correctness scores, and retained more of what they learned compared to students who didn't learn with AI.
Tags
Annotators
URL
-
-
edtechbooks.org edtechbooks.org
-
However, it is critical to know that just because one adheres to a code of ethics, it does not mean there will never be conflict. What is unfortunately inherent in all human relationships is a level of conflict, even when one has good intentions. So the question then is what happens when conflicts or perceived ethical violation occurs especially when a designer is engaged in collecting data needed for learner analysis?
The authors highlight the importance of ethical considerations in learner analysis, noting that conflicts or perceived ethical violations can arise even when designers adhere to a code of ethics. This raises questions about how designers should address such conflicts, particularly when collecting data for learner analysis. Ethical conduct is crucial in ensuring that the design process respects the rights and dignity of learners.
-
- Mar 2024
-
archive.org archive.org
-
https://archive.org/details/run-de-1986-10/page/120/mode/2up
"RUN – Unabhängiges Commodore Computermagazin", Ausgabe 10/Oktober 1986, which has a hexdump code listing of a C64 Zettelkasten
ᔥ[Michael Gisiger[]] in mastodon: (@gisiger@nerdculture.de)
Lust auf #Retrocomputing und #PKM mit einem #Zettelkasten? Bitte schön, in der Oktober-Ausgabe 1986 des #Commodore Magazins RUN findet sich ein Listing für den #C64 dazu. Viel Spass beim Abtippen 😅
https://archive.org/details/run-de-1986-10/page/120/mode/2up
See additional conversation at: https://www.reddit.com/r/c64/comments/1bg0ja1/does_anyone_have_the_zettelkasten_program_from/?utm_source=share&utm_medium=web2x&context=3
-
-
www.biorxiv.org www.biorxiv.org
-
Note: This response was posted by the corresponding author to Review Commons. The content has not been altered except for formatting.
Learn more at Review Commons
Reply to the reviewers
Reply to Reviewers
We are grateful to the three reviewers for their careful and constructive critiques of our preprint. We will address all of their comments and suggestions, which help to make our paper more precise and understandable. In our replies, we use 'Patterson, eLife (2021)' as shorthand for Patterson, Basu, Rees & Nurse, eLife 2021:10.
Reviewer #1 (Evidence, reproducibility and clarity (Required)): Novák and Tyson present a model-based analysis of published data that had claimed to demonstrate bistable activation of CDK at the G2/M transition in fission yeast. They point out that the published data does not distinguish between ultra-sensitive (switch-like, but reversible) and bistable (switch-like, but irreversible) activation. They back up their intuition with robust quantitative modeling. They then point out that, with a simple experimental modification, the published experiments could be repeated in a way that would test between the ultra-sensitive and bistable possibilities.
This is an accurate and concise summary of our paper.
Therefore, this is a rare paper that makes a specific modeling-based prediction and proposes a straightforward way to test it. As such, it will be of interest to a broad range of workers involved in the fields cell cycle and regulatory modeling.
We agree that our work will be of interest to a broad range of scientists studying cell cycle regulation and mathematical modeling of bistable control systems.
Nonetheless, attention to the following points would improve the manuscript. The authors should be more careful about how they describe protein abundance. They often refer to protein level. I believe in every case they mean protein concentration, but this is not explicitly stated; it could be interpreted as number of protein molecules per cell. The authors should either explicitly state that level means concentration or, more simply, use concentration instead of level.
A valid criticism that has been addressed in the revised version.
The authors should explain why they include stoichiometric inhibition of CDK by Wee1 in their model. Is it required to make the model work in the wild-type case, or only in the CDK-AF case? My intuition is it should only be required in the AF case, but I would like to know for sure. Also, they should state if there is any experimental data for such regulation.
Bistability of the Tyr-phosphorylation switch requires 'sufficient' nonlinearity, which may come from the phosphorylation and dephosphorylation reactions that interconvert Cdk1, Wee1 and Cdc25. The easiest way to model these interconversion reactions is to use Hill- or Goldbeter-Koshland functions for the phosphorylation and dephosphorylation of Wee1 and Cdc25, but this approach is not appropriate for Gillespie SSA, which assumes elementary reactions. Both Wee1 and Cdc25 are phosphorylated on multiple sites, which we approximate by double phosphorylation; but this level of nonlinearity is not sufficient to make the switch bistable. In addition, stochiometric inhibition is a well-known source of nonlinearity, and in the Wee1:Cdk1 enzyme:substrate complex, Cdk1 is inhibited because Wee1 binds to Cdk1 near its catalytic site. In our model, stoichiometric inhibition of Cdk1 by Wee1 is required for bistability even in the wild-type case because the regulations of Wee1 and Cdc25 by phosphorylation are not nonlinear enough. There is experimental evidence that stoichiometric inhibition of Cdk1 by Wee1 is significant: mik1D wee1ts double mutant cells at the restrictive temperature (Lundgren, Walworth et al. 1991) are less viable than AF-Cdk1 (Gould and Nurse 1989). Furthermore, Patterson (eLife, 2021) found weak 'bistability' when they used AF-Cdk1 to induce mitosis. This puzzling observation suggests a residual feedback mechanism in the absence of Tyr-phosphorylation. Our model accounts for this weak bistability by assuming that free CDK1 can phosphorylate and inactivate the Wee1 'enzyme' in the Wee1:Cdk1 complex, which makes CDK1 and Wee1 mutual antagonists. This reaction is based on formation of a trimer, Cdk1:Wee1:Cdk1, which is possible since CDK1 phosphorylation of Wee1 occurs in its N-terminal region, which lies outside the C-terminal catalytic domain of Wee1 (Tang, Coleman et al. 1993). These ideas have been incorporated into the text in the subsection describing the model (see lines120-125).
The authors should explicitly state, on line 131, that the fact that "the rate of synthesis of C-CDK molecules is directly proportional to cell volume" results in a size-dependent increase in the concentration of C-CDK.
The accumulation of C-CDK molecules in fission yeast cells is complicated. In general, we may assume that larger cells have more ribosomes and make all proteins faster than do smaller cells. Absent other regulatory effects, the number of protein molecules is proportional to cell volume, and the concentration is constant. But, in Patterson's experiments, the number of C-CDK molecules is zero at the start of induction and rises steeply thereafter (see lines 147-148), and the rate of increase (#molec/time) is proportional to the size of the growing cell.
The authors should explain, on line 100, why they are "quite sure the bistable switch is the correct interpretation".
Line 105-106: "Although we suspect that the mitotic switch is bistable,.."
On line 166, include the units of volume.
Done
On lines 152 and 237, "smaller protein-fusion levels "should be replaced with "lower protein-fusion concentrations".
Done
**Referee cross-commenting** *I concur with the other two reviews. *
Reviewer #1 (Significance (Required)): *The paper is significant in that it points out an alternative interpretation for an important result in an important paper. Specifically, it points out that the published data is consistent with activation of CDK at the G2/M transition in fission yeast could be ultra-sensitive (switch-like, but reversible) instead of bistable (switch-like, but irreversible). The distinction is important because it has been claimed, by the authors of the submitted manuscript among others, that bistability is required for robust cell-cycle directionality. *
We agree with this assessment.
However, activation of CDK at the G2/M transition in other species has been shown to be bistable and the authors state that they are "quite sure the bistable switch is the correct interpretation". So, the paper is more likely an exercise in rigor than an opportunity to overturn a paradigm.
We were the first authors to predict that the G2/M switch is bistable (J. Cell Sci., 1993) and among the first to prove it experimentally in frog egg extracts (PNAS, 2004). Our models (Novak and Tyson 1995, Novak, Pataki et al. 2001, Tyson, Csikasz-Nagy et al. 2002, Gerard, Tyson et al. 2015) of fission yeast cell-cycle control rely on bistability of the G2/M transition; so, understandably, we believe that the transition in fission yeast is a bistable switch. But the 'bistable paradigm' has never been directly demonstrated by experimental observations in fission yeast cells. The Patterson paper (eLife, 2021) claims to provide experimental proof, but we demonstrate in our paper that Patterson's experiments are not conclusive evidence of bistability. Furthermore, we suggest that a simple change to Patterson's protocol could provide convincing evidence that the G2/M switch is either monostable or bistable. We are not proposing that the switch is monostable; we would be quite surprised if the experiment, correctly done, were to indicate a reversible switch. Our point is simply that the published experiments are inconclusive. The point we are making is neither a mere 'exercise in rigor' nor a suggestion to 'overturn a paradigm.' Rather it is a precise theoretical analysis of a central question of cell cycle regulation that should be of interest to both experimentalists and mathematical modelers.
Reviewer #2 (Evidence, reproducibility and clarity (Required)): Summary: The manuscript asks whether the data reported in Patterson et al. (2021) is consistent with a bistable switch controlling the G2/M transition in fission yeast. Patterson et al. (2021) use an engineered system to decouple a non-degradable version of Cyclin-dependent kinase (CDK) from cell growth and concomitantly measure CDK activity (by the nuclear localization of a downstream target, Cut3p). They observe cells with indistinguishable CDK levels but two distinct CDK activities, which they posit shows bistable behavior. In this study, the authors ask if other models can also explain this data. The authors use both deterministic and Gillespie based stochastic simulations to generate relationships between CDK activities and protein levels for various cell sizes. They conclude that the experiments performed in Patterson et al. are insufficient to distinguish between a bistable switch and a reversible ultrasensitive switch. They propose additional experiments involving the use a degradable CDK construct to also measure the inactivation kinetics.
This is an accurate summary of our paper.
They propose that a bistable switch will have different forward (OFF->ON) and backward (ON->OFF) switching rates. A reversible ultrasensitive switch will have indistinguishable switching rates.
Our analysis of Patterson's (2021) experiments is based on the well-known fact that the threshold for turning a bistable switch on is significantly different from the threshold for turning it off (in Patterson's case, the 'threshold' is the level of fusion protein in the cell when CDK is activated), whereas for a reversible, ultrasensitive switch, the two thresholds are nearly indistinguishable. The 'rate' at which the switch is made is a different issue, which we do not address explicitly. In the experiments and in our model, the switching rates are fast, whether the switch is bistable or monostable. The results are interesting and worth publication in a computational biology specific journal, as they might only appeal to a limited audience.
We think our results should also be brought to the attention of experimentalists studying cell cycle regulation, because Patterson's paper (eLife, 2021) presents a serious misunderstanding of the existence and implications of 'bistability' of the G2/M transition in fission yeast. Whereas Patterson's work is an elegant and creative application of genetics and molecular biology to an important problem, it is not backed up by quantitative mathematical modeling of the experimental results. In that sense, Patterson's work is incomplete, and its shortcomings need to be addressed in a highly respected journal, so that future cell-cycle experimentalists will not make the same-or similar-mistakes.
Several ideas need to be clarified and additional information needs to be provided about the specific parameters used for the simulations: Major comments: #1 The parameters need to be made more accessible by means of a supplementary table and appropriate references need to be cited.
Two new supplementary tables (S1 and S2) summarize the dynamic variables and parameter values.
It is not clear why Michaelis Menten kinetics will not be applicable to this system. Has it been demonstrated that the Km s of the enzymes are much greater than the substrate concentrations for all the reactions? If yes, please cite.
MM kinetics are not appropriate for such protein interaction networks because one protein may be both an enzyme and a substrate for a second protein (e.g., Wee1 and CDK, or Cdc25 and CDK). So, the condition for validity of MM kinetics (enzyme concen ≪ substrate concen) cannot be satisfied for both reactions. Indeed, enzyme concen ≈ substrate concen is probably true for most reactions in our network. Hence, it is advisable to stick with mass-action rate laws. Furthermore, MM kinetics are a poor choice for 'propensities' in Gillespie SSA calculations, as has been shown by many authors (Agarwal, Adams et al. 2012, Kim, Josic et al. 2014, Kim and Tyson 2020).
It will not be surprising if the simulation with Michaelis Menten would alter the dynamics shown in this study. A reversible switch with two different enzymes (catalyzing the ON->OFF and OFF->ON transitions) having different kinetics can give asymmetric switching rates. This would directly contradict what has been shown in Figure 7A-D.
We don't follow the reviewer's logic here. The two transitions, off → on and on → off, are already driven by different molecular processes (dephosphorylation of inactive CDK-P by Cdc25 and phosphorylation of active CDK by Wee1, respectively). Positive feedback of CDK activity on Cdc25 and Wee1 (++ and −−, respectively) causes bistability and asymmetric switching thresholds. Switching rates, which are determined by the kinetic rate constants of the up and down processes, are of secondary importance to the primary question of whether the switch is monostable or bistable.
#2 Line 427: The authors use a half-time of 6 hours in their model as Patterson et al. used a non-degradable construct. It is not clear why dilution due to cell growth has not been considered. The net degradation rate of a protein is the sum of biochemical degradation rate and growth dilution rate. The growth dilution rate seems significant (140 mins doubling time or 0.3 h-1 dilution rate) relative to assumed degradation rate (0.12 h-1). Please clarify why was the effect of dilution neglected in the model or show by sensitivity analysis this does not change the predicted CDK activation thresholds.
The reviewer highlights an important effect, but it is not relevant to our calculations. In the deterministic model used to calculate the bifurcation diagrams, both cell volume and the concentration of the non-degradable Cdc13:Cdk1 dimer are kept constant; therefore, there is no dilution effect. The stochastic model deals with changing numbers of molecules per cell; the dilution effect is taken into account by the appearance of cell volume, V(t), at appropriate places in the propensity functions. In other words: in the deterministic model, which is written for concentration changes, the dilution term, −(x/V)(dV/dt), is zero because V=constant; in the stochastic model, written in terms of numbers of molecules, dilution effects are implicit in the propensity functions.
*#3 Line 402 The authors state that the production rate of the Cdk protein is 'assumed' proportional to the cell volume. The word 'assumed' is incorrect here as a simple conversion of concentration-based differential equation (with constant production rate) to molecular numbers would show that production rate is proportional to the volume. This is not an assumption. *
Correct; we modified the text (see line 450-462). The role of cell volume in production rate is more relevant to the case of Cdc25, where we assume that its production rate, Δconcentration/Δt, is proportional to V, because the concentration of Cdc25 in the cell increases as the cell grows. We added two references (Keifenheim, Sun et al. 2017, Curran, Dey et al. 2022) to justify this assumption. In the stochastic code, the propensity for synthesis of Cdc25 molecules is proportional to V2.
#4 Line 423 Please cite the appropriate literature that shows that fission yeast growth during cell division is exponential. If the dynamics are more complicated, involving multiple phases of growth during cell division, please state so.
We now acknowledge that volume growth in fission yeast, rather than exponential, is bilinear with a brief non-growing phase at mitosis (Mitchison 2003). However, we suggest that our simplifying assumption of exponential growth is appropriate for the purposes of these calculations. See line 473-476: "In our stochastic simulations, we assume that cell volume is increasing exponentially, V(t) = V0eμt. Although fission yeast cells actually grow in a piecewise linear fashion (Mitchison 2003), the simpler exponential growth law (with doubling time @ 140 min) is perfectly adequate for our purposes in this paper.."
*#5 Line 250 The authors convert the bistable version of the CDK switch to reversible sigmoidal by assuming that Wee1 and Cdc25 phosphorylation is proportional to the CDK level rather than activity, which seems biochemically unrealistic. This invokes an altered circuit architecture where inactive CDK has enough catalytic activity to phosphorylate the two modifying enzymes (Wee1/Cdc25) but not enough to drive mitosis. This might be possible if the Km of CDK for Wee1/Cdc25 is lower relative to other downstream substrates that drive mitosis. The authors can reframe this section of the paper to state this possibility, which might be interesting to experimentalists. *
The reviewer is correct that the molecular biology underlying our 'reversible sigmoidal' model is biochemically unrealistic. But, in our opinion, this is the simplest way to convert our bistable model into a monostable, ultrasensitive switch while maintaining the basic network structure in Fig. 1. Our purpose is to show that a monostable model-only slightly changed from the bistable model-can account for Patterson's experimental data equally well. If Nurse's group modifies the experimental protocol as we suggest and their new results indicate that the G2/M transition in fission yeast is bistable, then our reversible sigmoidal model, having served its purpose, can be forgotten. If they show that the transition is not bistable, then both experimentalists and theoreticians will have to think about biochemically realistic mechanisms that can account for the new data...and everything else we already know about the G2/M transition in fission yeast.
#6 It is difficult to phenomenologically understand a bistable switch just based on differences in activation and inactivation thresholds. For example, a reversible ultrasensitive switch also shows a difference in activation and inactivation thresholds (Figure 7D). How much of a difference should be expected of a bistable switch versus reversible switch?
We show how much of a difference can be expected by contrasting Fig. 7 to Fig. 8. For the largest cells (panel D of both figures), the difference is small and probably undetectable experimentally. For medium-sized cells (panel C), the difference is larger but probably difficult to distinguish experimentally. Only the smallest cells (panel B) provide an opportunity for clearly distinguishing experimentally between monostable and bistable switching.
*Moreover, as the authors clearly understand (line 275), time-delays in activation and inactivation reactions can inflate these differences. In the future, if the authors can convert the equations to potential energy space as done in Acar et al. 2005 (Nature 435:228) in Figure 3c-d, it will be useful. Also, predicting the distribution of switching rates from the Gillespie simulation might be informative and can be directly compared to experimental measurements in the future (if the Cut3p levels in nucleus and cytosol equilibrates fast enough or other CDK biosensors are developed). *
The famous paper by Acar et al. (2005) is indeed an elegant experimental and theoretical study of bistability ('cellular memory') in the galactose-signalling network of budding yeast. We have included a comparison of Patterson et al. with Acar et al. in our Conclusions section (lines 353-368):
"It is instructive, at this point, to compare the work of Patterson et al. (2021) to a study by Acar et al. (Acar, Becskei et al. 2005) of the galactose-signaling network of budding yeast. Combining elegant experiments with sophisticated modeling, Acar et al. provided convincing proof of bistability ('cellular memory') in this nutritional control system. They measured PGAL1-YFP expression (the response) as a function of galactose concentration in the growth medium (the signal), analogous to Patterson's measurements of CDK activity as a function of C-CDK concentration in fission yeast cells. In Acar's experiments, the endogenous GAL80 gene was replaced by PTET-GAL80 in order to maintain Gal80 protein concentration at a constant value determined by doxycycline concentration in the growth medium. The fixed Gal80p concentration in Acar's cells is analogous to cell volume in Patterson's experiments. In Fig.3b of Acar's paper, the team plotted the regions of monostable-off, monostable-on and bistable signaling in dependence on their two control parameters, external galactose concentration and intracellular Gal80p concentration, analogous to our Fig.4. Because Acar's experiments explored both the off → on and on → off transitions, they could show that their observed thresholds (the red circles) correspond closely to both saddle-node bifurcation curves predicted by their model. On the other hand, Patterson's experiments (as analyzed in our Fig.4) probe only the off → on transition."
The purpose of our paper is to show that Patterson-type experiments can and should be done so as to probe both thresholds, as was done by van Oudenaarden's team. They went further to characterize their bistable switch in terms of 'the concept of energy landscapes'. We think it is premature to pursue this idea in the context of the G2/M transition in fission yeast until there is firm, quantitative data characterizing the nature of the 'presumptive' bistable switch in fission yeast.
Minor comments: #1 Line 2: Please replace "In most situations" to "In favorable conditions"
Done.
**Referee cross-commenting** I agree with Reviewer 1 that this falls more under pointing out an alternative interpretation of a single experiment than challenging widely supported orthodoxy about how the eukaryotic cell cycle leaves mitosis.
As we said earlier, our 1993 paper in J Cell Sci is the source of this orthodox view, and it is widely supported at present because there is convincing experimental evidence for bistability in frog egg extracts, budding yeast cells and mammalian cells. Patterson's paper is not sound evidence for bistability of the G2/M transition in fission yeast cells. It is important for experimentalists to know why the experiments fail to confirm bistability, and important for someone to do the experiment correctly in order to confirm (or, what would be really interesting, to refute) the expectation of bistability at the G2/M transition in fission yeast cells.
Reviewer #2 (Significance (Required)): Suitable for specialist comp bio journal eg PLoS Comp Bio
Reviewer #3 (Evidence, reproducibility and clarity (Required)):
The paper by Novak and Tyson revisits a recent paper from Nurse group on the bistability of mitotic switch in fission yeast using mathematical modelling. The authors extend their older models of mitotic entry check point and implement both deterministic and stochastic version of new model. They show this model does indeed possess bistability and show that combined with stochastic fluctuations the model can show bimodality for the cyclin-CDK activity at a particular cell size consistent with the recent experimental data. However, the authors also show alternative model that has mono-stable ultrasensitivity can also explain the data and suggest experiments that can prove the existence of hysteresis and therefore bistability.
Right on.
While the biological implication of the study is well explained, the authors can improve the presentation of their model and the underlying assumptions. I have the following comments and suggestions for improvement of the paper.
-
- The cartoon of the mathematical model is confusing at places, for example the wee1-CDK complex according to the equations either dissociates back to wee1 and CDK or gives rise to pCDK and wee1, the arrow below is confusing as it implies it can also give rise to wee1p, the CDK phosphorylation of wee1 is already included in the diagram. Also, the PP2A is put on the arrow for all reactions but for wee1p2 to wee1p its action shown with a dashed line. Also, I wondered if wee1p and wee1p2 can also bind CDK and sequester or phosphorylate CDK?* We are sorry for the confusion and have improved Fig. 1.
-
The rates and variables in the ODEs are not fully described. Also sometimes unclear what is parameter and what is a variable, I had to look at the code.*
We now include tables of variables and parameter values, with explanatory notes.
- The model has quite a few parameters, but these are not at all discussed in the paper. How did the authors come up with these particular set of parameters, has there been some systematic fitting, or tuning by hand to produce a good fit to the data? I could only see the value of the parameters in the code, but perhaps a table with the parameters of the model, what they mean and their value (and perhaps how the values is obtained) is missing.*
The parameters were tuned by hand to fit Patterson's data, based, of course, on our extensive experience fitting mathematical models to myriad data sets on the cell division cycles of fission yeast, budding yeast, and frog egg extracts. We now provide a table of parameter values.
- The authors are using the Gillespie algorithm with time varying parameters (as some rates depend on volume and volume is not constant). Algorithm needs to be modified slightly to handle this (see for example Shahrezaei et al Molecular Systems Biology 2008). *
A valid criticism, but the rate of cell volume increase is very slow compared to the propensities of the biochemical reactions. We write (lines 492-498):
"In each step of the SSA, the volume of the cell is increasing according to an exponential function, and, consequently, the propensities of the volume-dependent steps are, in principle, changing with time; and this time-dependence could be taken into account explicitly in implementing Gillespie's SSA (Shahrezaei, Ollivier et al. 2008). However, the step-size between SSA updates is less than 1 s compared to the mass-doubling time (140 min) of cell growth. So, it is warranted to neglect the change in V(t) between steps of the SSA, as in our code."
- The authors correctly point out, ignoring mRNA has resulted in underestimation of noise, however another point is that mRNA life times are short and that also affects the timescale of fluctuations and this may be relevant to the switching rates between the bistable states. *
A valid point, but to include mRNA's would double the size of the model. Furthermore, we have little or no data about mRNA fluctuations in fission yeast cells, so it would be impossible to estimate the values of all the new parameters introduced into the model. Finally, the switching rates between bistable states (or across the ultrasensitive boundary) are not the primary focus of Patterson's experiments or our theoretical investigations. So, we propose to delay this improvement to the model until the relevant experimental data is available.
- In the introduction add, "In this study" to "Intrigued by these results, we investigated their experimental observations with a model of bistability in the activation of cyclin-CDK in fission yeast." *
Done
Reviewer #3 (Significance (Required)): Overall, this is an interesting study that revisits an old question and some recent experimental data. The use of stochastic modelling in explaining variability and co-existence of cell populations in the context of cell cycle and comparison to experimental data is novel and of interest to the communities of cell cycle researchers, systems biologists and mathematical biologists.
We agree. Thanks for the endorsement
References
Acar, M., A. Becskei and A. van Oudenaarden (2005). "Enhancement of cellular memory by reducing stochastic transitions." Nature 435(7039): 228-232.
Agarwal, A., R. Adams, G. C. Castellani and H. Z. Shouval (2012). "On the precision of quasi steady state assumptions in stochastic dynamics." J Chem Phys 137(4): 044105.
Curran, S., G. Dey, P. Rees and P. Nurse (2022). "A quantitative and spatial analysis of cell cycle regulators during the fission yeast cycle." Proc Natl Acad Sci U S A 119(36): e2206172119.
Gerard, C., J. J. Tyson, D. Coudreuse and B. Novak (2015). "Cell cycle control by a minimal Cdk network." PLoS Comput Biol 11(2): e1004056.
Gould, K. L. and P. Nurse (1989). "Tyrosine phosphorylation of the fission yeast cdc2+ protein kinase regulates entry into mitosis." Nature 342(6245): 39-45.
Keifenheim, D., X. M. Sun, E. D'Souza, M. J. Ohira, M. Magner, M. B. Mayhew, S. Marguerat and N. Rhind (2017). "Size-Dependent Expression of the Mitotic Activator Cdc25 Suggests a Mechanism of Size Control in Fission Yeast." Curr Biol 27(10): 1491-1497 e1494.
Kim, J. K., K. Josic and M. R. Bennett (2014). "The validity of quasi-steady-state approximations in discrete stochastic simulations." Biophys J 107(3): 783-793.
Kim, J. K. and J. J. Tyson (2020). "Misuse of the Michaelis-Menten rate law for protein interaction networks and its remedy." PLoS Comput Biol 16(10): e1008258.
Lundgren, K., N. Walworth, R. Booher, M. Dembski, M. Kirschner and D. Beach (1991). "mik1 and wee1 cooperate in the inhibitory tyrosine phosphorylation of cdc2." Cell 64(6): 1111-1122.
Mitchison, J. M. (2003). "Growth during the cell cycle." Int Rev Cytol 226: 165-258.
Novak, B., Z. Pataki, A. Ciliberto and J. J. Tyson (2001). "Mathematical model of the cell division cycle of fission yeast." Chaos 11(1): 277-286.
Novak, B. and J. J. Tyson (1995). "Quantitative Analysis of a Molecular Model of Mitotic Control in Fission Yeast." J Theor Biol 173: 283-305.
Patterson, J. O., S. Basu, P. Rees and P. Nurse (2021). "CDK control pathways integrate cell size and ploidy information to control cell division." Elife 10.
Shahrezaei, V., J. F. Ollivier and P. S. Swain (2008). "Colored extrinsic fluctuations and stochastic gene expression." Mol Syst Biol 4: 196.
Tang, Z., T. R. Coleman and W. G. Dunphy (1993). "Two distinct mechanisms for negative regulation of the Wee1 protein kinase." EMBO J 12(9): 3427-3436.
Tyson, J. J., A. Csikasz-Nagy and B. Novak (2002). "The dynamics of cell cycle regulation." Bioessays 24(12): 1095-1109.
-
-
Note: This preprint has been reviewed by subject experts for Review Commons. Content has not been altered except for formatting.
Learn more at Review Commons
Referee #3
Evidence, reproducibility and clarity
The paper by Novak and Tyson revisits a recent paper from Nurse group on the bistability of mitotic switch in fission yeast using mathematical modelling. The authors extend their older models of mitotic entry check point and implement both deterministic and stochastic version of new model. They show this model does indeed possess bistability and show that combined with stochastic fluctuations the model can show bimodality for the cyclin-CDK activity at a particular cell size consistenent with the recent experimental data. However, the authors also show alternative model that has mono-stable ultrasensitivity can also explain the data and suggest experiments that can prove the existence of hysteresis and therefore bistability.
While the biological implication of the study is well explained, the authors can improve the presentation of their model and the underlying assumptions. I have the following comments and suggestions for improvement of the paper. <br /> 1. The cartoon of the mathematical model is confusing at places, for example the wee1-CDK complex according to the equations either dissociates back to wee1 and CDK or gives rise to pCDK and wee1, the arrow below is confusing as it implies it can also give rise to wee1p, the CDK phosphorylation of wee1 is already included in the diagram. Also, the PP2A is put on the arrow for all reactions but for wee1p2 to wee1p its action shown with a dashed line. Also, I wondered if wee1p and wee1p2 can also bind CDK and sequester or phosphorylate CDK? 2. The rates and variables in the ODEs are not fully described. Also sometimes unlcear what is parameter and what is a variable, I had to look a the code. 3. The model has quite a few parameters, but these are not at all discussed in the paper. How did the authors come up with these particular set of parameters, has there been some systematic fitting, or tuning by hand to produce a good fit to the data? I could only see the value of the parameters in the code, but perhaps a table with the parameters of the model, what they mean and their value (and perhaps how the values is obtained) is missing. 4. The authors are using the Gillespie algorithm with time varying parameters (as some rates depend on volume and volume is not constant). Algorithm needs to be modified slightly to handle this (see for example Shahrezaei et al Molecular Systems Biology 2008). 5. The authors correctly point out, ignoring mRNA has resulted in underestimation of noise, however another point is that mRNA life times are short and that also affects the timescale of fluctuations and this may be relevant to the switching rates between the bistable states. 6. In the introduction add, "In this study" to "Intrigued by these results, we investigated their experimental observations with a model of bistability in the activation of cyclin-CDK in fission yeast.
Significance
Overall, this is an interesting study that revisits an old question and some recent experimental data. The use of stochastic modelling in explaining variability and co-existence of cell populations in the context of cell cycle and comparison to experimental data is novel and of interest to the communities of cell cycle researchers, systems biologists and mathematical biologists.
-
-
www.legifrance.gouv.fr www.legifrance.gouv.fr
-
Les conditions permettant cette inscription et cette fréquentation sont fixées par convention entre les autorités académiques et l'établissement de santé ou médico-social.
-
l'Etat met en place les moyens financiers et humains nécessaires à la scolarisation en milieu ordinaire des enfants, adolescents ou adultes en situation de handicap.
-
le plus proche de son domicile
-
Une information sur les risques liés au harcèlement scolaire, notamment au cyberharcèlement, est délivrée chaque année aux élèves et parents d'élèves.
-
prennent les mesures appropriées visant à lutter contre le harcèlement dans le cadre scolaire
-
Aucun élève ou étudiant ne doit subir de faits de harcèlement
-
Les parents d'élèves participent, par leurs représentants aux conseils d'école, aux conseils d'administration des établissements scolaires et aux conseils de classe.
-
Leur participation à la vie scolaire et le dialogue avec les enseignants et les autres personnels sont assurés
-
Les parents d'élèves sont membres de la communauté éducative.
-
Dans chaque école, collège ou lycée, la communauté éducative rassemble les élèves et tous ceux qui, dans l'établissement scolaire ou en relation avec lui, participent à l'accomplissement de ses missions.Elle réunit les personnels des écoles et établissements, les parents d'élèves, les collectivités territoriales, les associations éducatives complémentaires de l'enseignement public ainsi que les acteurs institutionnels, économiques et sociaux, associés au service public de l'éducation.
-
Dans le cadre d'une école inclusive, elle fonde sa cohésion sur la complémentarité des expertises.
-
L'Etat garantit le respect de la personnalité de l'enfant et de l'action éducative des familles
-
La formation scolaire favorise l'épanouissement de l'enfant
-
Tout enfant a droit à une formation scolaire qui, complétant l'action de sa famille, concourt à son éducation
-
L'acquisition d'une culture générale et d'une qualification reconnue est assurée à tous les jeunes, quelle que soit leur origine sociale, culturelle ou géographique.
-
permettre de façon générale aux élèves en difficulté, quelle qu'en soit l'origine, en particulier de santé, de bénéficier d'actions de soutien individualisé.
-
Il veille également à la mixité sociale des publics scolarisés au sein des établissements d'enseignement
-
Il veille à la scolarisation inclusive de tous les enfants, sans aucune distinction
-
Article L111-1Modifié par LOI n°2021-1109 du 24 août 2021 - art. 58L'éducation est la première priorité nationale. Le service public de l'éducation est conçu et organisé en fonction des élèves et des étudiants. Il contribue à l'égalité des chances et à lutter contre les inégalités sociales et territoriales en matière de réussite scolaire et éducative. Il reconnaît que tous les enfants partagent la capacité d'apprendre et de progresser. Il veille à la scolarisation inclusive de tous les enfants, sans aucune distinction. Il veille également à la mixité sociale des publics scolarisés au sein des établissements d'enseignement. Pour garantir la réussite de tous, l'école se construit avec la participation des parents, quelle que soit leur origine sociale. Elle s'enrichit et se conforte par le dialogue et la coopération entre tous les acteurs de la communauté éducative.
-
Elle s'enrichit et se conforte par le dialogue et la coopération entre tous les acteurs de la communauté éducative.
Tags
- L111-3
- parents
- besoins particuliers
- représentants des parents d'élèves
- formation
- RPE
- harcèlement
- moyens
- L111-6
- coéducation
- académie
- psychologie
- RESF
- mixité
- privé
- élèves
- L111-4
- à exploiter
- L111-1
- inclusion
- scolarisation
- social
- dialogue
- code de l'éducation
- L111-2
- L112-1
- handicap
- bien-être
- communauté éducative
Annotators
URL
-
-
arkloud.xyz arkloud.xyz
-
Expansion of the ICC to include communication infrastructure development
.. I just got back from dreaming that there could be "all roads lead to rome" in an andromeda plan with a thing called the bridge to the venii "suns" venuses? like the version that has ... coastal-west and the one with the rivers instead of roads in the venice that has a version with the verilonamice verily lo, the mice part of the "of the mice and the mammalian's language code for the one we are speak en ...
-
-
browser.engineering browser.engineering
-
inversion of control,
a framework calls custom code, rather than the usual other way around
like how an event driven framework calls custom GUI code
-
-
urbanreadingforum.com urbanreadingforum.com
-
eligibleslum dwellers
Code yellow - new category!
-
ncremental housing
New category - code yellow!
-
enable slum
A new category, not explicitly mentioned in the list of definitions earlier has emerged. Code Yellow! what does this mean? A Ctrl-F may be in order.
-
-
pressbooks.online.ucf.edu pressbooks.online.ucf.edu
-
Pythagorical symbols
Pythagoras was one of the most influential people in history. His influence on mathematics -- and the world which depends on it -- has been evident hundreds of years after his era. However, it is clear that Pythagoras' mathematics was not what the author is referencing, but rather his, "exhortation to abide by a moral code". This theme is also evident when the author mentions Ovid and Metamorphoses as Ovid was references Pythagoras in many of his writings.
Swanson, Roy Arthur. “Ovid’s Pythagorean Essay.” The Classical Journal, vol. 54, no. 1, 1958, pp. 21–24. JSTOR, http://www.jstor.org/stable/3295324. Accessed 28 Mar. 2024.
-
-
www.legifrance.gouv.fr www.legifrance.gouv.fr
-
Article L111-1Version en vigueur depuis le 26 août 2021Modifié par LOI n°2021-1109 du 24 août 2021 - art. 58L'éducation est la première priorité nationale. Le service public de l'éducation est conçu et organisé en fonction des élèves et des étudiants. Il contribue à l'égalité des chances et à lutter contre les inégalités sociales et territoriales en matière de réussite scolaire et éducative.
-
-
www.defenseurdesdroits.fr www.defenseurdesdroits.fr
-
À la suite de nos analyses, nous avonsconstaté un nombre croissant d'élèves sansaffectation, en augmentation de l’ordre de 30à 40 % par rapport à l’année précédente. Or,conformément au code de l’éducation, quil’érige au rang de première priorité nationale,le service public de l’éducation doit être conçuet organisé en fonction de ses usagers, quisont les élèves
-
-
pressbooks.online.ucf.edu pressbooks.online.ucf.edu
-
Save A Life Pet Rescue
add link to:https://savealifepetrescue.org/home
include a copy of the new logo you designed?
A great place to add personal photos of you volunteering if you have them
you could even include this embed link code to show the video about the organization <iframe width="560" height="315" src="https://www.youtube.com/embed/HjK6Op1yF9g?si=jP1uQej6EsVBz8_-" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen></iframe>
-
-
statistics4ecologists-v2.netlify.app statistics4ecologists-v2.netlify.app
-
logitp[i] <- alpha + beta * voc[i] p[i] <- exp(logitp[i]) / (1 + exp(logitp[i])) observed[i] ~ dbin(p[i], 1)
For next edition, rewrite all JAGS code so that the order/format matches how we write down equations describing our models. E.g.:
response variable ~ statistical distribution(parameters) transformation(parameters) <- linear predictor
-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
eLife assessment
This important study provides a new, apparently high-performance algorithm for B cell clonal family inference. The new algorithm is highly innovative and based on a rigorous probabilistic analysis of the relevant biological processes and their imprint on the resulting sequences, however, the strength of evidence regarding the algorithm's performance is incomplete, due to (1) a lack of clarity regarding how different data sets were used for different steps during algorithm development and validation, resulting in concerns of circularity, (2) a lack of detail regarding the settings for competitor programs during benchmarking, and (3) method development, data simulation for method validation, and empirical analyses all based on the B cell repertoire of a single subject. With clarity around these issues and application to a more diverse set of real samples, this paper could be fundamental to immunologists and important to any researcher or clinician utilizing B cell receptor repertoires in their field (e.g., cancer immunology).
We apologize for the long delay in implementing the suggested changes. Some of the co-authors had some personal issues that made it hard to efficiently work on the revision.
We have addressed all the essential points below, as well as all the detailed comments of each reviewer in the following pages.
Due to the journal’s guidelines we have to upload an “all black” version of the manuscript as the main version. We have uploaded a revised manuscript with the changes marked in red as a “Related Manuscript file”, which appears at the very end of the Merged Manuscript File, after all the Figures, and at the end of the list of files on the webpage. We apologize for this inconvenience.
In addition, we have added an extension of HILARy to deal with paired-chain repertoires, and have benchmarked the new method on a recently published synthetic dataset. This new analysis is now presented in new Fig. 5.
Reviewer #1 (Public Review):
Identifying individual BCR/Ab chain sequences that are members of the same clone is a longstanding problem in the analysis of BCR/Ab repertoire sequencing data. The authors propose a new method designed to be scalable for application to huge repertoire data sets without sacrificing accuracy. Their approach utilizes Hamming Distance between CDR3 sequences followed by clustering for a fast, high-precision approach to classifying pairs of sequences as related or not, and then refines the classification using mutation information from germline-encoded regions. They compare their method with other state-of-the-art methods using synthetic data.
The authors address an important problem in an interesting, innovative, and rigorous way, using probabilistic representations of CDR3 differences, frequencies of shared and not-shared mutations, and the relationships between the two under hypotheses of related pairs and unrelated pairs, and from these develop an approach for determining thresholds for classification and lineage assignment. Benchmarking shows that the proposed method, the complete method including both steps, outperforms other methods.
Strengths of the method include its theoretical underpinnings which are consistent with an immunologist's intuition about how related and unrelated sequences would compare with each other in terms of the metrics to use and how those metrics are related to each other.
I have two high-level concerns:
(1) It isn't clear how the real and synthetic data are being used to estimate parameters for the classifier and evaluate the classifier to avoid circularity. It seems like the approach is used to assign lineages in the data from [1], and then properties of this set of lineages are used to estimate parameters that are then used to refine the approach and generate synthetic data that is used to evaluate the approach. This may not be a problem with the approach but rather with its presentation, but it isn't entirely clear what data is being used and where for what purpose. An understanding of this is necessary in order to truly evaluate the method and results.
The reviewer is correct in their understanding of the pipeline. It should be stressed that the lineages used to guide the generation of the synthetic data was done on VJl classes for which the clustering was easy and reliable, and should therefore be largely model independent.
We have added an explanation in the main text of why the re-use of real data lineages inferred by HILARy doesn’t bias the procedure, since it’s done on a subset of lineages within VJl classes that are easy to infer (section “Test on synthetic dataset”).
(2) Regarding the data used for benchmarking - given the intertwined fashion by which the classification approach and synthetic data generation approach appear to have been developed, it is not surprising that the proposed approach outperforms the other methods when evaluated on the synthetic data presented here. It would be better to include in the benchmark the data used by the other methods to benchmark themselves or also generate synthetic data using their data generation procedures.
We agree with the reviewer that a test of the method on an independent synthetic dataset is important for its applicability and to compare to other methods.
We have added a new synthetic dataset from the group that designed the partis method to our benchmark. Our method still performs competitively, on par with partis—which was developed and tested on that dataset—and better than other methods. The results are presented in revised Fig. 4 (panels E-G), and Figure 4–figure supplement 1 as a function of the mutation rate.
In addition, we have used that dataset to benchmark a new version of HILARy that also uses the light chain. We present the results in new Figures 5 and Figure 4–figure supplement 1.
An improved method for BCR/Ab sequence lineage assignment would be a methodologic advancement that would enable more rigorous analyses of BCR/Ab repertoires across many fields, including infectious disease, cancer, autoimmune disease, etc., and in turn, enable advancement in our understanding of humoral immune responses. The methods would have utility to a broad community of researchers.
Reviewer #2 (Public Review):
This manuscript describes a new algorithm for clonal family inference based on V and J gene identity, sequence divergence in the CDR3 region, and shared mutations outside the CDR3. Specifically, the algorithm starts by grouping sequences that have the same V and J genes and the same CDR3 length. It then performs single-linkage clustering on these groups based on CDR3 Hamming distance, then further refines these groups based on shared mutations.
Although there are a number of algorithms that use a similar overall strategy, a couple of aspects make this work unique. First, a persistent challenge for algorithms such as this one is how to set a cutoff for single-linkage clustering: if it is too low, then one separates clusters that should be together, and if too high one joins together clusters that should be separate. Here the authors leverage a rich collection of probabilistic tools to make an optimal choice. Specifically, they model the probability distributions of within- and between-cluster CDR3 Hamming distances, with parameters depending on CDR3 length and the "prevalence" of clonal sequence pairs (i.e. family size distribution). This allows the algorithm to make optimal choices for separating clusters, given the particular chosen distance metric, and assuming the sample in question has been accurately modeled. Second, the algorithm uses a highly efficient means of doing single-linkage clustering on nucleotide sequences.
This leads to a fast and highly performant algorithm on data meant to replicate the original sample used in algorithm design. The ideas are new and beautifully developed. The application to real data is interesting, especially the point about dN/dS.
However, the paper leaves open the question of how this inference algorithm works on samples other than the one used for simulation and as a template for validation. If I understand the simulation procedure correctly - that one takes a collection of inferred trees from the real data, then re-draws the root sequence and the identity of the mutations on the branches - then the simulated data should be very close to the data used to develop the methods in the paper. This consideration seems especially important given that key methods in this paper use mutation counts and overall mutation counts are preserved.
Repertoires come in all shapes and sizes: infants to adults, healthy to cancerous, and naive to memory to plasma-cell-just-after-vaccination. If this is being proposed as a general-purpose clonal inference algorithm rather than one just for this sample, then a more diverse set of validations are needed.
We agree that testing the method on a differently generated dataset is a useful check. We should point out, however, that our synthetic dataset is not as biased as it may seem. In particular, it is based on trees from VJl classes that we predicted are very easy to cluster, which means that they are truly faithful to the data, and not dependent on the particular algorithm used to infer them. The big advantage over this synthetic dataset over others is that it recapitulates the power law statistics of clone size distribution, as well as the diversity of mutation rates. To us, it still represents a more useful benchmark than synthetic datasets generated by population genetics models, which miss most of this very broad variability.
However, to check how the method generalizes to other datasets, we repeated our validation procedure on the dataset used to evaluate Partis in Ralph et al 2022. The new results are discussed in the main text and in new panels of Fig. 4 in the same form as the previous comparisons. We also added a comparison of performance as a function of mutation rate in the new Figure 4–figure supplement 1.
It is unclear how to run the code. The software repo has a nice readme explaining the file layout, dependencies, and input file format, but the repo seems to be lacking an
inference.ipynbmentioned there which runs an analysis. Perhaps this is a typo and refers toinference.py, which in addition to the documented cdr3 clustering, seems to have functions to run both clustering methods. However, it does not seem to have any documentation or help messages about how to run these functions.We have completely overhauled the github to provide a detailed step by step explanation of how to run the code. The code is now easily installable using pip.
The results are not currently reproducible, because the simulated data is not available. The data availability statement says that no data have been generated for this manuscript, however simulated data has been generated, and that is a key aspect of the analysis in the paper.
We have uploaded the simulated data to zenodo, as well as provided scripts in the github to run the benchmarks.
More detail is needed to understand the timing comparisons. The new software is clearly written to use many threads. Were the other software packages run using multiple threads? What type of machine was used for the benchmarks?
All timing comparisons were made based on a single VJl class on a 14 double-threaded CPU computer. HILARy uses all 28 threads, and other methods were run with default settings, with multi-threading allowed.
We have clarified the specifications of the computer.
Reviewer #3 (Public Review):
B cell receptors are produced through a combination of random V(D)J recombination and somatic hypermutation. Identifying clonal lineages - cells that descend from a common V(D)J rearrangement - is an important part of B cell repertoire analysis. Here, the authors developed a new method to identify clonal lineages from BCR data. This method builds off of prior advances in the field and uses both an adaptive clonal distance threshold and shared somatic hypermutation information to group B cells into clonal lineages.
The major strength of this paper is its thorough quantitative treatment of the subject and integration of multiple improvements into the clonal clustering process. By their simulation results, the method is both highly efficient and accurate.
The only notable weakness we identified is that much of the impact of the method will depend on its superiority to existing approaches, and this is not convincingly demonstrated by Fig. 4. In particular, little detail is given on how the other clonal clustering programs were run, and this can significantly impact their performance. More specifically:
We have added a new benchmark to address these concerns, presented in Fig. 4 and in new figure 4 – figure supplement 1 as a function of a controllable mutation rate.
(1) Scoper supports multiple methods for clonal clustering, including both adaptive CDR3 distance thresholds (Nouri and Kleinstein, 2018) and shared V-gene mutations (Nouri and Kleinstein, 2020). It is not clear which method was used for benchmarking. The specific functions and settings used should have been detailed and justified. Spectral clustering with shared V gene mutations would be the most comparable to the authors' method. Similar detail is needed for partis.
In the updated version I use the 2020 version. The 2018 is very similar to simple single linkage so will be removed from the benchmark.
(2) It is not clear how the adaptive thresholds and shared mutation analysis in the authors' method differ from prior approaches such as scoper and partis.
We have changed the paragraph in the discussion section about the benchmark to highlight the innovative aspects and differences with previous approaches.
(3) The scripts for performing benchmarking analyses, as well as the version numbers of programs tested, are not available.
We have added to the github all the scripts used for benchmarking. We have added details about the version numbers in the data and code availability section of the methods.
(4) Similar to above, P. 10 describes single linkage hierarchical clustering with a fixed threshold as a "crude method" that "suffers from inaccuracy as it loses precision in the case of highlymutated sequences and junctions of short length." As far as we could tell, this statement is not backed up by either citations or analyses in the paper. It should not be difficult for the authors to test this though using their simulations, as this method is also implemented in scoper.
We have added this method to our benchmark to support that point. The results are presented in Figure 4 – figure supplement 2.
References
Nouri N, Kleinstein SH. 2020. Somatic hypermutation analysis for improved identification of B cell clonal families from next-generation sequencing data. PLOS Comput Biol 16:e1007977. doi:10.1371/journal.pcbi.1007977
Nouri N, Kleinstein SH. 2018. A spectral clustering-based method for identifying clones from high- throughput B cell repertoire sequencing data. Bioinformatics 34:i341-i349. doi:10.1093/bioinformatics/bty235
We have changed citation [22] to refer to the 2018 paper. The 2020 paper is citation [18].
-
Reviewer #2 (Public Review):
This manuscript describes a new algorithm for clonal family inference based on V and J gene identity, sequence divergence in the CDR3 region, and shared mutations outside the CDR3. Specifically, the algorithm starts by grouping sequences that have the same V and J genes and the same CDR3 length. It then performs single-linkage clustering on these groups based on CDR3 Hamming distance, then further refines these groups based on shared mutations.
Although there are a number of algorithms that use a similar overall strategy, a couple of aspects make this work unique. First, a persistent challenge for algorithms such as this one is how to set a cutoff for single-linkage clustering: if it is too low, then one separates clusters that should be together, and if too high one joins together clusters that should be separate. Here the authors leverage a rich collection of probabilistic tools to make an optimal choice. Specifically, they model the probability distributions of within- and between-cluster CDR3 Hamming distances, with parameters depending on CDR3 length and the "prevalence" of clonal sequence pairs (i.e. family size distribution). This allows the algorithm to make optimal choices for separating clusters, given the particular chosen distance metric, and assuming the sample in question has been accurately modeled. Second, the algorithm uses a highly efficient means of doing single-linkage clustering on nucleotide sequences.
This leads to a fast and highly performant algorithm on data meant to replicate the original sample used in algorithm design. The ideas are new and beautifully developed. The application to real data is interesting, especially the point about dN/dS.
However, the paper leaves open the question of how this inference algorithm works on samples other than the one used for simulation and as a template for validation. If I understand the simulation procedure correctly - that one takes a collection of inferred trees from the real data, then re-draws the root sequence and the identity of the mutations on the branches - then the simulated data should be very close to the data used to develop the methods in the paper. This consideration seems especially important given that key methods in this paper use mutation counts and overall mutation counts are preserved.
Repertoires come in all shapes and sizes: infants to adults, healthy to cancerous, and naive to memory to plasma-cell-just-after-vaccination. If this is being proposed as a general-purpose clonal inference algorithm rather than one just for this sample, then a more diverse set of validations are needed.
It is unclear how to run the code. The software repo has a nice readme explaining the file layout, dependencies, and input file format, but the repo seems to be lacking an `inference.ipynb` mentioned there which runs an analysis. Perhaps this is a typo and refers to `inference.py`, which in addition to the documented cdr3 clustering, seems to have functions to run both clustering methods. However, it does not seem to have any documentation or help messages about how to run these functions.
The results are not currently reproducible, because the simulated data is not available. The data availability statement says that no data have been generated for this manuscript, however simulated data has been generated, and that is a key aspect of the analysis in the paper.
More detail is needed to understand the timing comparisons. The new software is clearly written to use many threads. Were the other software packages run using multiple threads? What type of machine was used for the benchmarks?
-
-
github.com github.com
-
**helps remove weird code stuff when editing
-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
The following is the authors’ response to the original reviews.
This study reports important evidence that infants' internal factors guide children's attention and that caregivers respond to infants' attentional shifts during caregiver-infant interactions. The authors analyzed EEG data and multiple types of behaviors using solid methodologies that can guide future studies of neural responses during social interaction in infants. However, the analysis is incomplete, as several methodological choices need more adequate justification.
Reviewer #1
Public Review:
The authors bring together multiple study methods (brain recordings with EEG and behavioral coding of infant and caregiver looking, and caregiver vocal changes) to understand social processes involved in infant attention. They test different hypotheses on whether caregivers scaffold attention by structuring a child's behavior, versus whether the child's attention is guided by internal factors and caregivers then respond to infants' attentional shifts. They conclude that internal processes (as measured by brain activation preceding looking) control infants' attention, and that caregivers rapidly modify their behaviors in response to changes in infant attention.
The study is meticulously documented, with cutting-edge analytic approaches to testing alternative models; this type of work provides a careful and well-documented guide for how to conduct studies and process and analyze data for researchers in the relatively new area of neural response in infants in social contexts.
We are very pleased that R1 considers our work an important contribution to this developing field, and we hope that we have now addressed their concerns below.
Some concerns arise around the use of terms (for example, an infant may "look" at an object, but that does not mean the infant is actually "attending); collapsing of different types of looks (to people and objects), and the averaging of data across infants that may mask some of the individual patterns.
We thank the reviewer for this feedback and their related comments below, and we feel that our manuscript is much stronger as a result of the changes we have made. Please see blow for a detailed description of our rationale for defining and analysing the attention data, as well as the textual changes made in response to the author’s comments.
Recommendations For The Authors
This paper is rigorous in method, theoretically grounded, and makes an important contribution to understanding processes of infant attention, brain activity, and the reciprocal temporal features of caregiver-infant interactions. The alternative hypothesis approach sets up the questions well (although authors should temper any wording that suggests attention processes are one or the other. That is, certain bouts of infant attention can be guided by exogenous factors such as social input, and others be endogenous; so averaging across all bouts can actually mask the variation in these patterns). I appreciated the focus on multiple types of behavior (e.g., gaze, vocal fluctuations in maternal speech); the emphasis on contingent responding; and the very clear summaries of takeaways after each section. Furthermore, methods and analyses are well described, details on data processing and so on are very thorough, and visualizations aptly facilitate data interpretation. However, I am not an expert on infant neural responses in EEG and assume that a reviewer with such expertise will weigh in on the treatment and quality of the data; therefore, my comments should be interpreted in light of this lack of knowledge.
We thank R1 for these very positive and insightful comments on our analyses which are the result of a number of years of methodological and technical developmental work.
We do agree with R1 that we should more carefully word parts of our argument in the Introduction to make clear the fact that shifts in infant attention could be driven by a combination of interactive and endogenous influences. As a result of this comment, we have made direct changes to parts of the Introduction; removing any wording that suggests that these processes are ‘alternative’ or ‘separate’, and our overall aim states: ‘Here, recording EEG from infants during naturalistic interactions with their caregiver, we examined the (inter)-dependent influences of infants’ endogenous oscillatory neural activity, and inter-dyadic behavioural contingencies in organising infant attention’.
Examining variability between infant attention episodes in the factors that influence the length and timing of the attention episode is an important area for future investigation. We now include a discussion on this on page 38 of the Discussion section, with suggestions for how this could be examined. Investigating different subtypes of infant attention is methodologically challenging, given the number of infant behaviours that would need to inform such an analysis- all of which are time consuming to code. Developing automated methods for performing these kinds of analyses is an important avenue for future work.
Here, I review various issues that require revision or elaboration based on my reading of what I consider to otherwise be a solid and important research paper.
Problem in the use of the term attention scaffolding. Although there may be literature precedent in the use of this term, it is problematic to narrowly define scaffolding as mother-initiated guidance of attention. A mother who responds to infant behaviors, but expands on the topic or supports continued attention, and so on, is scaffolding learning to a higher level. I would think about a different term because it currently implies a caregiver as either scaffolding OR responding contingently. It is not an either-or situation in conceptual meaning. In fact, research on social contingency (or contingent responsiveness), often views the follow-in responding as a way to scaffold learning in an infant.
Yes, we agree with R1 that the term ‘attention scaffolding’ could be confusing given the use of this term in previous work conducted with children and their caregivers in problem-solving tasks, that emphasise modulations in caregiver behaviour as a function of infant behaviour. As a result of this suggestion, we have made direct edits to the text throughout, replacing the term attentional scaffold with terms such as ‘organise’ and ‘structure’ in relation to the caregiver-leading or ‘didactic’ perspective, and terms such as ‘contingent responding’ and ‘dynamic modulation’ in relation to the caregiver-following perspective. We feel that this has much improved the clarity of the argument in the Introduction and Discussion sections.
Do individual data support the group average trends? My concern with unobservable (by definition) is that EEG data averages may mask what's going on in individual brain response. Effects appear to be small as well, which occurs in such conditions of averaging across perhaps very variable response patterns. In the interest of full transparency and open science, how many infants show the type of pattern revealed by the average graph (e.g., do neural markers of infant engagement forward predict attention for all babies? Majority?). Non-parametric tests on how many babies show a claimed pattern would offer the litmus test of significance on whether the phenomenon is robust across infants or pulled by a few infants with certain patterns of data. Ditto for all data. This would bolster my confidence in the summaries of what is going on in the infant brain. (The same applies as I suggest to attention bouts. To what extent does the forward-predict or backward-predict pattern work for all bouts, only some bouts, etc.?). I recognize that to obtain power, summaries are needed across infants and bouts, but I want to know if what's being observed is systematic.
We thank R1 for this comment and understand their concern that the overall pattern of findings reported in relation to the infants’ EEG data might obscure inter-individual variability in the associations between attention and theta power. Averaging across individual participant EEG responses is, however, the gold standard way to perform both event-locked (Jones et al., 2020) and continuous methods (Attaheri et al., 2020) of EEG analysis that are reported in the current manuscript. EEG data, and, in particular, naturalistic EEG data is inherently noisy, and averaging across participants increases the signal to noise ratio (i.e. inconsistent, and, therefore, non-task-related activity is averaged out of the response (Cohen, 2014; Noreika et al., 2020)). Examining individual EEG responses is unlikely to tell us anything meaningful, given that, if a response is not found for a particular participant, then it could be that the response is not present for that participant, or that it is present, but the EEG recording for that participant is too noisy to show the effect. Computing group-level effects, as is most common in all neuroimaging analyses, is, therefore, most optimal to examining our main research questions.
The findings reported in this analysis also replicate previous work conducted by our lab which showed that infant attention to objects significantly forward-predicted increases in infant theta activity during joint table-top play with their caregiver, involving one toy object (compared to our paradigm which involved 3;Wass et al., 2018). More recent work conducted by our lab has also shown continuous and time-locked associations between infant look durations and infant theta activity when infants play with objects on their own (Perapoch Amadó et al., 2023). To reassure readers of the replicability of the current findings, we now reference the Wass et al. (2018) study at the beginning of the Discussion section.
Could activity artifacts lead to certain reported trends? Babies typically look at an object before they touch or manipulate the object, and so longer bouts of attention likely involve a look and then a touch for lengthier time frames. If active involvement with an object (touching for example) amplifies theta activity, that may explain why attention duration forward predicts theta power. That is, baby looks, then touches, then theta activates, and coding would show visual gaze preceding the theta activation. Careful alignment of infants' touches and other such behaviors with the theta peak might help address this question, again to lend confidence to the robustness of the interpretation.
Yes, again this is a very important point, and the removal of movement-related artifact is something we have given careful attention to in the analysis of our naturalistic EEG data (Georgieva et al., 2020; Marriott Haresign et al., 2021). As a result of this comment we have made direct changes to the Results section on page 18 to more clearly signal the reader to our EEG pre-processing section before presenting the results of the cross-correlation analyses.
As we describe in the Methods section of the main text, movement-related artifacts are removed from the data with ICA decomposition, utilising an automatic-rejection algorithm, specially designed for work with our naturalistic EEG data (Marriott Haresign et al., 2021). Given that ICA rejection does not remove all artifact introduced to the EEG signal, additional analysis steps were taken to reduce the possibility that movement artifacts influenced the results of the reported analyses. As explained in the Methods section, rather than absolute theta power, relative theta was used in all EEG analyses, computed by dividing the power at each theta frequency by the summed power across all frequencies. Eye and head movement-related artifacts most often associate with broadband increases in power in the EEG signal (Cohen, 2014): computing relative theta activity therefore further reduces the potential influence of artifact on the EEG signal.
It is also important to highlight that previous work examining movement artifacts in controlled paradigms with infants has shown that limb movements actually associate with a decrease in power at theta frequencies, compared to rest (Georgieva et al., 2020). It is therefore unlikely that limb movement artifacts explain the pattern of association observed between theta power and infant attention in the current study.
That said, examining the association between body movements and fluctuations in EEG activity during naturalistic interactions is an important next step, and something our lab is currently working on. Given that touching an object is most often the end-state of a larger body movement, aligning the EEG signal to the onset of infant touch is not all that informative to understanding how body movements associate with increases and decreases in power in the EEG signal. Our lab is currently working on developing new methods using motion tracking software and arousal composites to understand how data-derived behavioural sub-types associate with differential patterns of EEG activity.
The term attention may be misleading. The behavior being examined is infant gaze or looks, with the assumption that gaze is a marker of "attention". The authors are aware that gaze can be a blank stare that doesn't reflect underlying true "attention". I recommend substitution of a conservative, more precise term that captures the variable being measured (gaze); it would then be fine to state that in their interpretation, gaze taken as a marker for attention or something like that. At minimum, using term "visual attention" can be a solution if authors do not want to use the precise term gaze. As an example, the sentence "An attention episode was defined as a discrete period of attention towards one of the play objects on the table, or to the partner" should be modified to defined as looking at a play object or partner.
We thank the reviewer for this comment, and we understand their concern with the use of the term ‘attention’ where we are referring to shifts in infant eye gaze. However, the use of this term to describe patterns of infant gaze, irrespective of whether they are ‘actually attending’ or not is used widely in the literature, in both interactive (e.g. Yu et al., 2021) and screen-based experiments examining infant attention (Richards, 2010). We therefore feel that its use in our current manuscript is acceptable and consistent with the reporting of similar interaction findings. On page 39 of the Discussion we now also include a discussion on how future research might further investigate differential subtypes of infant looks to distinguish between moments where infants are attending vs. just looking.
Why collapse across gaze to object vs. other? Conceptually, it's unclear why the same hypotheses and research questions on neural-attention (i.e., gaze in actuality) links would apply to looks to a mom's face or to an object. Some rationale would be useful to the reader as to why these two distinct behaviors are taken as following the same principles in ordering of brain and behavior. Perhaps I missed something, however, because later in the Discussion the authors state that "fluctuations in neural markers of infants' engagement or interest forward-predict their attentiveness towards objects", which suggests there was an object-focused variable only? Please clarify. (Again, sorry if I missed something).
This is a really important point, and we agree with R1 that it could have been more clearly expressed in our original submission – for which, we apologise. In the cross-correlation analyses conducted in parts 2 and 3 which examines forwards-predictive associations between infant attention durations and infant endogenous oscillatory activity (part two), and caregiver behaviour (part three), as R1 describes, we include all infant looks towards objects and their partner. Including all infant look types is necessary to produce a continuous variable to cross-correlate with the other continuous variables (e.g. theta activity, caregiver vocal behaviours), and, therefore, does not concentrate only on infant attention episodes towards objects.
We take the reviewers’ point that different attention and neural mechanisms may be associated with looks towards objects vs. the partner, which we now acknowledge directly on page 10 of the Introduction. However, our focus here is on the endogenous and interactive mechanisms that drive fluctuations in infant engagement with the ongoing, free-flowing interaction. Indeed, previous work has shown increases in theta activity during sustained episodes of infant attention to a range of different stimuli, including cartoon videos (Xie et al., 2018), real-life screen-based interactions (Jones et al., 2020), as well as objects (Begus et al., 2016). In the second half of part 2, we go on to address the endogenous processes that support infant attention episodes specifically towards objects.
As a result of this comment, we have made direct changes to the Introduction on page 10 to more clearly explain the looking behaviours included in the cross-correlation analysis, and the rationale behind the analysis being conducted in this way – which is different to the reactive analyses conducted in the second half of parts one and three, which examines infant object looks only. Direct edits to the text have also been made throughout the Results and Methods sections as a result of this comment, to more clearly specify the types of looks included in each analysis. Now, where we discuss the cross-correlation analyses we refer only to infant ‘attention durations’ or infant ‘attention’, whilst ‘object-directed attention’ and ‘looks towards objects’ is clearly specified in sections discussing the reactive analyses conducted in parts 2 and 3. We have also amended the Discussion on page 31so that the cross-correlation analyses is interpreted relative to infant overall attention, rather than their attention towards objects only.
Why are mothers' gazes shorter than infants' gazes? This was the flip of what I'd expect, so some interpretation would be useful to understanding the data.
This is a really interesting observation. Our findings of the looking behaviour of caregivers and infants in our joint play interactions actually correspond to much previous micro-dynamic analysis of caregiver and infant looking behaviour during early table-top interactions (Abney et al., 2017; Perapoch Amadó et al., 2023; Yu & Smith, 2013, 2016). The reason for the shorter look durations in the adult is due to the fact that the caregivers alternate their gaze between their infant and the objects (i.e. they spend a lot of the interaction time monitoring their infants’ behaviours). This can be seen in Figure 2 (see main text) which shows that caregiver looks are divided between looks to their infants and looks towards objects. In comparison, infants spend most of their time focussing on objects (see Figure 2, main text), with relatively infrequent looks to their caregiver. As a result, infant looks are, overall, longer in comparison to their caregivers’.
Minor points
Use the term association or relation (relationships is for interpersonal relationships, not in statistics).
This has now been amended throughout.
I'm unsure I'd call the interactions "naturalistic" when they occur at a table, with select toys, EEG caps on partners, and so on. The term seems more appropriate for studies with fewer constraints that occur (for example) in a home environment, etc.
We understand R1s concern with our use of the term ‘naturalistic’ to refer to the joint play interactions that we analyse in the current study. However, we feel the term is appropriate, given that the interactions are unstructured: the only instruction given to caregivers at the beginning of the interaction is to play with their infants in the way that they might do at home. The interactions, therefore, measure free-flowing caregiver and infant behaviours, where modulations in each individual’s behaviour are the result of the intra- and inter-individual dynamics of the social exchange. This is in comparison to previous work on early infant attention development which has used more structured designs, and modulations in infant behaviour occur as a result of the parameters of the experimental task.
Reviewer #2
Public Review
Summary:
This paper acknowledges that most development occurs in social contexts, with other social partners. The authors put forth two main frameworks of how development occurs within a social interaction with a caregiver. The first is that although social interaction with mature partners is somewhat bi-directional, mature social partners exogenously influence infant behaviors and attention through "attentional scaffolding", and that in this case infant attention is reactive to caregiver behavior. The second framework posits that caregivers support and guide infant attention by contingently responding to reorientations in infant behavior, thus caregiver behaviors are reactive to infant behavior. The aim of this paper is to use moment-to-moment analysis techniques to understand the directionality of dyadic interaction. It is difficult to determine whether the authors prove their point as the results are not clearly explained as is the motivation for the chosen methods.
Strengths
The question driving this study is interesting and a genuine gap in the literature. Almost all development occurs in the presence of a mature social partner. While it is known that these interactions are critical for development, the directionality of how these interactions unfold in real-time is less known.
The analyses largely seem to be appropriate for the question at hand, capturing small moment-to-moment dynamics in both infant and child behavior, and their relationships with themselves and each other. Autocorrelations and cross-correlations are powerful tools that can uncover small but meaningful patterns in data that may not be uncovered with other more discretized analyses (i.e. regression).
We are pleased that R2 finds our work to be an interesting contribution to the field, which utilises appropriate analysis techniques.
Weaknesses
The major weakness of this paper is that the reader is assumed to understand why these results lead to their claimed findings. The authors need to describe more carefully their reasoning and justification for their analyses and what they hope to show. While a handful of experts would understand why autocorrelations and cross-correlations should be used, they are by no means basic analyses. It would also be helpful to use simulated data or even a simple figure to help the reader more easily understand what a significant result looks like versus an insignificant result.
We thank the reviewer for this comment, and we agree that much more detail should be added to the Introduction section. As a result of this comment, we have made direct changes to the Introduction on pages 9-11 to more clearly detail these analysis methods, our rationale for using these methods; and how we expect the results to further our understanding of the drivers of infant attention in naturalistic social interactions.
We also provide a figure in the SM (Fig. S6) to help the reader more clearly understand the permutation method used in our statistical analyses described in the Methods, on page 51, which depicts significant vs. insignificant patterns of results against their permutation distribution.
While the overall question is interesting the introduction does not properly set up the rest of the paper. The authors spend a lot of time talking about oscillatory patterns in general but leave very little discussion to the fact they are using EEG to measure these patterns. The justification for using EEG is also not very well developed. Why did the authors single out fronto-temporal channels instead of using whole brain techniques, which are more standard in the field? This is idiosyncratic and not common.
We very much agree with R2 that the rationale and justification for using EEG to understand the processes that influence infants’ attention patterns is under-developed in the current manuscript. As a result of this comment we have made direct edits to the Introduction section of the main text on pages 7-8 to more clearly describe the rationale for examining the relationship between infant EEG activity and their attention during the play interactions with their caregivers.
As we describe in the Introduction section, previous behavioural work conducted with infants has suggested that endogenous cognitive processes (i.e. fluctuations in top-down cognitive control) might be important in explaining how infants allocate their attention during free-flowing, naturalistic interactions towards the end of the first year. Oscillatory neural activity occurring at theta frequencies (3-6Hz), which can be measured with EEG, has previously been associated with top-down intrinsically guided attentional processes in both adulthood and infancy (Jones et al., 2020; Orekhova, 1999; Xie et al., 2018). Measuring fluctuations in infant theta activity therefore provides a method to examine how endogenous cognitive processes structure infant attention in naturalistic social interactions which might be otherwise unobservable behaviourally.
It is important to note that the Introduction distinguishes between two different oscillatory mechanisms that could possibly explain the organisation of infant attention over the course of the interaction. The first refers to oscillatory patterns of attention, that is, consistent attention durations produced by infants that likely reflect automatic, regulatory functions, related to fluctuations in infant arousal. The second mechanism is oscillatory neural activity occurring at theta frequencies, recorded with EEG, which, as mentioned above, is thought to reflect fluctuations in intrinsically guided attention in early infancy. We have amended the Introduction to make the distinction between the two more clear.
A worrisome weakness is that the figures are not consistently formatted. The y-axes are not consistent within figures making the data difficult to compare and interpret. Labels are also not consistent and very often the text size is way too small making reading the axes difficult. This is a noticeable lack of attention to detail.
This has now been adjusted throughout, where appropriate.
No data is provided to reproduce the figures. This does not need to include the original videos but rather the processed and de-identified data used to generate the figures. Providing the data to support reproducibility is increasingly common in the field of developmental science and the authors are greatly encouraged to do so.
This will be provided with the final manuscript.
Minor Weaknesses
Figure 4, how is the pattern in a not significant while in b a very similar pattern with the same magnitude of change is? This seems like a spurious result.
The statistical analysis conducted for all cross-correlation analyses reported follows a rigorous and stringent permutation-based temporal clustering method which controls for family-wise error rate using a non-parametric Monte Carlo method (see Methods in the main text for more detail). Permutations are created by shuffling data sets between participants and, therefore, patterns of significance identified by the cluster-based permutation analysis will depend on the mean and standard deviation of the cross-correlations in the permutation distribution. Fig. S6 now depicts the cross-correlations against their permutation distributions which should help readers to understand the patterns of significance reported in the main text.
The correlations appear very weak in Figures 3b, 5a, 7e. Despite a linear mixed effects model showing a relationship, it is difficult to believe looking at the data. Both the Spearman and Pearson correlations for these plots should be clearly included in the text, figure, or figure legend.
We thank the reviewer for this comment, and agree that reporting the correlations for these plots would strengthen the findings of the linear mixed effects models reported in text. As a result, we have added both Spearman and Pearson correlations to the legends of Figures 3b, 5a and 7e, corresponding to the statistically significant relationships examined in the linear mixed effects models. The strength of the relationships are entirely consistent with those documented in other previous research that used similar methods (e.g. Piazza et al., 2018). How strong the relationship looks to the observer is entirely dependent on the graphical representation chosen to represent it. We have chosen to present the data in this way because we feel that it is the most honest way to represent the statistically significant, and very carefully analysed, effects that we have observed in our data.
Linear mixed effects models need more detail. Why were they built the way they were built? I would have appreciated seeing multiple models in the supplementary methods and a reasoning to have landed on one. There are multiple ways I can see this model being built (especially with the addition of a random intercept). Also, there are methods to test significance between models and aid in selection. That being said, although participant identity is a very common random effect, its use should be clearly stated in the main text.
We very much agree with R2 that the reporting of the linear mixed effects models needs more detail and this has now been added to the Method section (page 54). Whilst it is true that there are multiple ways in which this model could be built, given the specificity of our research questions, regarding the reactive changes in infant theta activity and caregiver behaviours that occur after infant look onsets towards objects (see pages 9-11 of the Introduction), we take a hypothesis driven approach to building the linear mixed effects models. As a result, random intercepts are specified for participants, as well as uncorrelated by-participant random slopes (Brown, 2021; Gelman & Hill, 2006; Suarez-Rivera et al., 2019). In this way, infant look durations are predicted from caregiver behaviours (or infant theta activity), controlling for between participant variability in look durations, as well as the strength of the effect of caregiver behaviours (or infant theta activity) on infant look durations.
Some parentheses aren't closed, a more careful re-reading focusing on these minor textual issues is warranted.
This has now been corrected.
Analysis of F0 seems unnecessarily complex. Is there a reason for this?
Computation of the continuous caregiver F0 variable may seem complex but we feel that all analysis steps are necessary to accurately and reliably compute this variable in our naturalistic, noisy and free-flowing interaction data. For example, we place the F0 only into segments of the interaction identified as the mum speaking so that background noises and infant vocalisations are not included in the continuous variable. We then interpolate through unvoiced segments (similar to Räsänen et al., 2018), and compute the derivative in 1000ms intervals as a measure of the rate of change. The steps taken to compute this variable have been both carefully and thoughtfully selected given the many ways in which this continuous rate of change variable could be computed (cf. Piazza et al., 2018; Räsänen et al., 2018).
The choice of a 20hz filter seems odd when an example of toy clacks is given. Toy clacks are much higher than 20hz, and a 20hz filter probably wouldn't do anything against toy clacks given that the authors already set floor and ceiling parameters of 75-600Hz in their F0 extraction.
We thank the reviewer for this comment and we can see that this part of the description of the F0 computation is confusing. A 20Hz low pass filter is applied to the data stream after extracting the F0 with floor and ceiling parameters set between 75-600Hz. The 20Hz filter therefore filters modulations in the caregivers’ F0 that occur at a modulation frequency greater than 20Hz. The 20Hz filter does not, therefore, refer to the spectral filtering of the speech signal. The description of this variable has been rephrased on page 48 of the main text.
Linear interpolation is a choice I would not have made. Where there is no data, there is no data. It feels inappropriate to assume that the data in between is simply a linear interpolation of surrounding points.
The choice to interpolate where there was no data was something we considered in a lot of detail, given the many options for dealing with missing data points in this analysis, and the difficulties involved with extracting a continuous F0 variable in our naturalistic data sets. As R2 points out, one option would be to set data points to NaN values where no F0 is detected and/ or the Mum is not vocalising. A second option, however, would be to set the continuous variable to 0s where no F0 is detected and/ or the Mum is not vocalising (where the mum is not producing sound there is no F0 so rather than setting the variable to missing data points, really it makes most objective sense to set to 0).
Either of these options (setting parts where no F0 is detected to NaN or 0) makes it difficult to then meaningfully compute the rate of change in F0: where NaN values are inserted, this reduces the number of data points in each time window; where 0s are inserted this creates large and unreal changes in F0. Inserting NaN values into the continuous variable also reduces the number of data points included in the cross-correlation and event-locked analyses. It is important to note that, in our naturalistic interactions, caregivers’ vocal patterns are characterised by lots of short vocalisations interspersed by short pauses (Phillips et al., in prep), similar to previous findings in naturalistic settings (Gratier et al., 2015). Interpolation will, therefore, have largely interpolated through the small pauses in the caregiver’s vocalisations.
The only limitation listed was related to the demographics of the sample, namely saying that middle class moms in east London. Given that the demographics of London, even east London are quite varied, it's disappointing their sample does not reflect the community they are in.
Yes we very much agree with R2 that the lack of inclusion of caregivers from wider demographic backgrounds is disappointing, and something which is often a problem in developmental research. Our lab is currently working to collect similar data from infants with a family history of ADHD, as part of a longitudinal, ongoing project, involving families from across the UK, from much more varied demographic backgrounds. We hope that the findings reported here will feed directly into the work conducted as part of this new project.
That said, demographic table of the subjects included in this study should be added.
This is now included in the SM, and referenced in the main text.
References
Abney, D. H., Warlaumont, A. S., Oller, D. K., Wallot, S., & Kello, C. T. (2017). Multiple Coordination Patterns in Infant and Adult Vocalizations. Infancy, 22(4), 514–539. https://doi.org/10.1111/infa.12165
Attaheri, A., Choisdealbha, Á. N., Di Liberto, G. M., Rocha, S., Brusini, P., Mead, N., Olawole-Scott, H., Boutris, P., Gibbon, S., Williams, I., Grey, C., Flanagan, S., & Goswami, U. (2020). Delta- and theta-band cortical tracking and phase-amplitude coupling to sung speech by infants [Preprint]. Neuroscience. https://doi.org/10.1101/2020.10.12.329326
Begus, K., Gliga, T., & Southgate, V. (2016). Infants’ preferences for native speakers are associated with an expectation of information. Proceedings of the National Academy of Sciences, 113(44), 12397–12402. https://doi.org/10.1073/pnas.1603261113
Brown, V. A. (2021). An Introduction to Linear Mixed-Effects Modeling in R.
Cohen, M. X. (2014). Analyzing neural time series data: Theory and practice. The MIT Press.
Gelman, A., & Hill, J. (2006). In Data Analysis using Regression and mulilevel/Hierachical Models. Cambridge University Press.
Georgieva, S., Lester, S., Noreika, V., Yilmaz, M. N., Wass, S., & Leong, V. (2020). Toward the Understanding of Topographical and Spectral Signatures of Infant Movement Artifacts in Naturalistic EEG. Frontiers in Neuroscience, 14, 352. https://doi.org/10.3389/fnins.2020.00352
Gratier, M., Devouche, E., Guellai, B., Infanti, R., Yilmaz, E., & Parlato-Oliveira, E. (2015). Early development of turn-taking in vocal interaction between mothers and infants. Frontiers in Psychology, 6. https://doi.org/10.3389/fpsyg.2015.01167
Jones, E. J. H., Goodwin, A., Orekhova, E., Charman, T., Dawson, G., Webb, S. J., & Johnson, M. H. (2020). Infant EEG theta modulation predicts childhood intelligence. Scientific Reports, 10(1), 11232. https://doi.org/10.1038/s41598-020-67687-y
Marriott Haresign, I., Phillips, E., Whitehorn, M., Noreika, V., Jones, E. J. H., Leong, V., & Wass, S. V. (2021). Automatic classification of ICA components from infant EEG using MARA. Developmental Cognitive Neuroscience, 52, 101024. https://doi.org/10.1016/j.dcn.2021.101024
Noreika, V., Georgieva, S., Wass, S., & Leong, V. (2020). 14 challenges and their solutions for conducting social neuroscience and longitudinal EEG research with infants. Infant Behavior and Development, 58, 101393. https://doi.org/10.1016/j.infbeh.2019.101393
Orekhova, E. (1999). Theta synchronization during sustained anticipatory attention in infants over the second half of the first year of life. International Journal of Psychophysiology, 32(2), 151–172. https://doi.org/10.1016/S0167-8760(99)00011-2
Perapoch Amadó, M., Greenwood, E., James, Labendzki, P., Haresign, I. M., Northrop, T., Phillips, E., Viswanathan, N., Whitehorn, M., Jones, E. J. H., & Wass, S. (2023). Naturalistic attention transitions from subcortical to cortical control during infancy. [Preprint]. Open Science Framework. https://doi.org/10.31219/osf.io/6z27a
Piazza, E. A., Hasenfratz, L., Hasson, U., & Lew-Williams, C. (2018). Infant and adult brains are coupled to the dynamics of natural communication [Preprint]. Neuroscience. https://doi.org/10.1101/359810
Räsänen, O., Kakouros, S., & Soderstrom, M. (2018). Is infant-directed speech interesting because it is surprising? – Linking properties of IDS to statistical learning and attention at the prosodic level. Cognition, 178, 193–206. https://doi.org/10.1016/j.cognition.2018.05.015
Richards, J. E. (2010). The development of attention to simple and complex visual stimuli in infants: Behavioral and psychophysiological measures. Developmental Review, 30(2), 203–219. https://doi.org/10.1016/j.dr.2010.03.005
Suarez-Rivera, C., Smith, L. B., & Yu, C. (2019). Multimodal parent behaviors within joint attention support sustained attention in infants. Developmental Psychology, 55(1), 96–109. https://doi.org/10.1037/dev0000628
Wass, S. V., Noreika, V., Georgieva, S., Clackson, K., Brightman, L., Nutbrown, R., Covarrubias, L. S., & Leong, V. (2018). Parental neural responsivity to infants’ visual attention: How mature brains influence immature brains during social interaction. PLOS Biology, 16(12), e2006328. https://doi.org/10.1371/journal.pbio.2006328
Xie, W., Mallin, B. M., & Richards, J. E. (2018). Development of infant sustained attention and its relation to EEG oscillations: An EEG and cortical source analysis study. Developmental Science, 21(3), e12562. https://doi.org/10.1111/desc.12562
Yu, C., & Smith, L. B. (2013). Joint Attention without Gaze Following: Human Infants and Their Parents Coordinate Visual Attention to Objects through Eye-Hand Coordination. PLoS ONE, 8(11), e79659. https://doi.org/10.1371/journal.pone.0079659
Yu, C., & Smith, L. B. (2016). The Social Origins of Sustained Attention in One-Year-Old Human Infants. Current Biology, 26(9), 1235–1240. https://doi.org/10.1016/j.cub.2016.03.026
Yu, C., Zhang, Y., Slone, L. K., & Smith, L. B. (2021). The infant’s view redefines the problem of referential uncertainty in early word learning. Proceedings of the National Academy of Sciences, 118(52), e2107019118. https://doi.org/10.1073/pnas.2107019118
-
-
fromthemachine.org fromthemachine.org
-
I am accepting charitable donations,. ETH: 0x66e2871ef39334962fb75ce34407f825d67ec434
A long time ago, "boom" started "shaking the ground when I thought something wrong was happening.
At the time, when I would boom myself, to prove it was a scan and search for "actual evil or evil intent" and there was code that was opened for the "word boom" and "the intended group of actors known as the subject, direct object and ... "Inderect objective" get the universe that belongs to the peoples goodness back to gracious me
-
-
fromthemachine.org fromthemachine.org
-
layout: post title: Waiting for that green light... date: '2017-08-14T21:00:00.001-07:00' author: Adam M. Dobrin tags: modified_time: '2017-08-15T07:16:57.305-07:00' thumbnail: https://2.bp.blogspot.com/-QpZpZE6empE/WZJx21d-JlI/AAAAAAAAE9Y/vc7b9IvRM9w2S5eTBg3fkn6v2SYcKiETwCK4BGAYYCw/s72-c/image-726640.png blogger_id: tag:blogger.com,1999:blog-4677390916502096913.post-3757774439979245459 blogger_orig_url: ./2017/08/waiting-for-that-green-light.html From the point of the "belly" thing, I'm pretty sure we're halfway through the script. Knowing him that was probably the halfway mark. I don't think that's a bad thing... as long as it's honestly and speedily moving towards freedom; you know, progress. That's a pretty good test to see if we're ... zombies or not. In the meantime, I don't know... that's probably comforting right? Or is it repulsive? :) Tell me something Taylor said. Why won't you tell me what she said? What was that promise that you made? Wait, are you the person that promised something? When do you think the script started? WHAT'S A WORD THAT STARTS WITH R AND ENDS IN GL?It's almost hard to believe that the Throne (to help, are on "e") of Glory comes from this place, isn't it? Still, it's encoded in religion, in our myths and in multiple confirming sources, not the least of which the TV show called 7th Heaven... we will Si Monday, my dear "cam Den" we will. I talked a little bit about backwards "green light" related to "glare" and Police (not that they glare at me, but their silly Hell-implying glare lights are actually red) and girl... I still don't know why girl is red or green, girls are blue to me. Stew in that pat for a little while, and let's talk about something more uplifting, like the key's of Pa and Ra hidden away in many words, from paramount to se_ pa r at e and paradox. Did you see what I did there, clever right? I HAD TO CHOOSE BETWEEN POINTING AT "PA" OR "MOUNT"DID I DO OK?I'm looking at the word "paramount" right now, and between you and I sometimes when I look at words magic happens, and something in the air told me that this email might be the messiah of me, the messiah of "nt"--the hidden Christ. Or maybe not. Sex sells, or so they say, but apparent not when Jesus talks about it--maybe it's another red light. I'm bored, read that as "because of red" and lonely, probably because of "how I'm still single" as "hiss" but still, I don't think it's right. Coming to you with a message about everything I think is wrong and not your fault--or mine, by the way--shouldn't be the kind of thing that's frowned upon, especially when you have some clues in thousand year old scripture that these things were truly "made wrong on purpose" so that we could fix them, you know; our way. That used to be talking about things, and making plans, and then implementing them--but today it's turned into ignoring everything I think is "world changing" and "morally demanded" and instead going on with our lives as if everything was "A-OK." I'm glad you are doing OK, I'm not; and quite a few people in the world are not doing OK either, so I'm here to let you know that you are not doing as OK as you think you are... or as well as you could be doing. I DON'T KNOW HOW A GUY MADE IT INTO MY "MESSAGE", OMG TWOSo here's why I thought for a minute that this message might save me. You might think it's a little weird that I see "sex jokes" in Pandora, and pa: ra: do x, and Pose i do n; and while you might not be completely retarded to think that, I think you should agree with me that it's more weird that those things are there, and even more weird that you don't recognize that they are a signature of the same God that delivered his John Hancock in song, in Yankee Doodle, and in act, in Watergate. My signature is a little bit different, if you've noticed my signature is being able to point out the intersection between things like Chuck and Geordie LaForge's magic vision ... and to explain that these things too are veritably connected by more than my words and the obvious ideas, they are connected by the act of Creation itself--they are the yarn of the Matrix. Dox, as in "dox me" and "do n" are getting a little out of hand; if you don't understand that I am playing a role ... to make the words "and he became the light" actually true--which they are, you see--then I really do sincerely apologize, I don't think anyone should "do me" unless they want to--although it's a bit strange to me that nobody wants to. Alarming, even. I am equally alarmed by the Latin word for darkness which is "tenebris" which connects to that "x" and the word "equinox" and "Nintendo" and "verboten" and through all of this the only shining light of grace I see is that it's pretty obvious that X and J are both letters represented by "10." DO YOU THINK HAN SOLO HAS A CHANCE WITH HER? SHE ... OUR LIGHTThis story needs to break, and then we aren't in the heart of darkness anymore; it's called "morning" Biblical, and this particular morning is a very special one--because you're here.I have a special gift, "pa" is helping me read this words, and you might have noticed that they can be taken to mean different things. They don't really separate, or fly off the page and glow for me; but I know what all the keys are, many are simple, and many come from our IT and "computer-slang" acronyms... which tells you something. Many are "elements" and "initials" and the whole thing really is a part of the script,a sort of key not just to Creation but to this specific story, to this path. While some are "open to interpretation" (for instance, "in t" everyone really pre-tat; which would be a long ... time ... ago <3) or you could read "ERP" reason "t" and that might have something to do with "Great Plains" and some blue light that connections user interfaces to the word "automagical," FRX forms... Strawberry Fields and "above the fruited plains" ... which might be meaningless to you--but it's an idea that revolves around using user-feedback to interfaces (like the pottery wheel in my dream or in the Dr. Who episode "the Bells of Saint John" linked to down below) to adjust the interface in real time for a larger group; working towards making a number of "best-fit" interfaces that people are both more comfortable with and actually creating as they use them. Ahhhh... blue light got in here, run away. Just kidding, this is cyan light.I C ONO CL AS M | J ES UI T | HEAVEN IS MORE THAN TECHHonestly, we could really make Healden in about 10 minutes now. Look at that, it's done... ish.LETS CALL "THAT DAY" THE DAY YOU SEE ADAM-NEWS ON EVERY TV STATIONFor instance were we not surely "at e" meaning the end of the Revelation of words, "separate" might have been broken between Pa and Ra, which are big keys, in many words; but we are at "e" and that surely does mean the Creator and I are fused. There's more confirmation of this than simply in the words for "medicine" and say, I don't know, methadone--which could have been broken at "a done" but is very clearly "ad is the one" here and now. With careful preparation, "adparatio" in Latin, I'd "bet" that all of those keys are I, in this place, in this time. AD, Pa, Ra, TI, and "o." Hey, maybe this message is my messiah after all. I am looking at a broken world, I really am--a place that is suffocating itself in silence and whispers that don't make it far enough for anyone to really understand. Whatever it is, whatever's caused it, I see no solution other than me coming--I see it as a design, and I'm sorry that you don't seem to agree, but you have to see that the "choice" between seeing an obvious truth absolutely everywhere and not seeing it is really no choice at all--what is being hidden from the world is causing this darkness, it is causing the suffocation; it is the problem, hiding me is the problem and it cannot continue. On a brighter note, I am pretty sure that magic will happen, and you will see that the world will not react quite as badly or shockingly as your worst fears, things might be a little ... tearful for a day or so, for crying out loud, they should be--the message is that you are in Hell and you need to do something, to act, to change that. Actually trying to do that, trying to discuss what it is that is the "ele ph ant in the room" or the "do n key in the s k y" will show us that there was just no way around changing the world because of circumstances of Creation; something that we seem to be ignoring. We also seem to be ignoring that things are "just fine" today, and even though many of you are well aware that "something is coming" only a few morons are building bunkers. This is a message of peace, it is a message designed to help us use the new truth and new tools unsealed by religion to make the world a safer happier place, and we can do that .. . rather quickly. Even quicker if you try to focus on what's wrong here, and how we make it better--rather than "shooting the messenger" dirty glares in the street. I'm a person too, and believe it or not, I didn't ask for this--and I probably wouldn't have been so happy about it had this experience not isolated me so much from my friends and family, and girls; don't forget girls. ITS ME? So in the word "paramount" what is it that you think is the "paramount" take away? I think the most important thing you can take away from "paramount" is that you didn't see it your whole life, and even when it's pointed out, you don't seem to think it's "news" that Pa and Ra have written a message to you. What's really not funny, is that despite this message being very clear to see once it's pointed out, it still hasn't made any waves in the newspapers, or online, or in the news--what's paramount is seeing that there is a very sincere problem for civilization, it is an ELE and that ELE is something that is making everyone think that "not seeing something" is OK behavior. It is not OK, it is not funny, until you recognize that something is dreadfully wrong with our society, until you see that ignoring that this message belongs in the news you are not seeing that what you are doing by ignoring it is destroying civilization itself. Ignorance is the ELE.Your alternative, what you are doing, is making the world half blind, and stupider than you can imagine. I keep on trying to show you what's wrong here, that it's not just a message but pain and suffering and the absolutely imminent and undeniable certain doom of everything if we do not recognize that hiding the fact that we are in virtual reality is the same thing as driving a nail into the wrists of every soul on the planet. LA U stilk MIGHT DATE ADPARATIO BO'OOPSYETHWith careful preparation, we are at IO (input/output) in the belly of the book that is a map to salvation. That IO comes well after disclosure, and well after Mars. You are delaying the inevitable, and in the sickest possible twist, you are stewing in Hell instead of seeing Heaven built--more importantly instead of being the generation that should be the "founders" of that place. I am sure that disclosure, will ... within a time frame that will most likely be faster than you can imagine, bring us an end to world hunger, to sickness, and doors to Heaven; and I just can't see what you are waiting for? If it wasn't like this, you've got to see that we would be getting fucked right here and now; I am telling you the map and the plan, it's here to help us make this place better, and to show us how to actually survive in the Universe before kicking us out of the nest, and we are ... what are we thinking about?It's really obvious that it's not for my benefit, and it's obvious that it's not for yours either--so at what point will you realize that the behavior, the alarming behavior, that I am seeing from everyone is illogical. At what point will you see that it is self-defeating, that it is ... well, Hell? When will you see? Be yourselves, the world that I grew up in doesn't hide controversy, we relish in it--we don't bury scandals under the rug--we put them on TV. What's really more important to see is that we, all of us, none of us... we would not hide "holographic universe" from ourselves and each other, nor would we hide "alien contact" or "the secrets of religion" and yet here we are, all doing that--and I wonder if we see that it's "not us" doing it, but .... but ... butt ... what is it again? HI, I'M A PERSON. (and apparently a state, a country, and a Nintendo character)JUDGING BY THE HIGH FREQUENCY OF PRESS UNSUBSCRIBES FROMYESTERDAY'S EMAIL, REPORTER'S DON'T SEEM TO WANT TO HEAR THATFORCING ME TO DELIVER THIS MESSAGE IN ISOLATION FOR NO MONEYIS SLAVERY, GO READ ABOUT JOSEPH IN EGYPT, THEN READ THE END.IF YOU THINK HIDING THE TRUTH BECAUSE "IDAHO" IS GONNA FLYYOU ARE AN IGNORANT BLIND FOOL. HONESTLY, WAKE UP, THIS IS HELL.YOU ARE BLINDED BY SOMETHING, FIGURE IT OUT--I'M EXPLAINING WHAT IT ISHERE, EMAIL THEM (please? and tell them to repent by writing a story):andy.greene@rollingstone.comgcoy@12news.comnmelosky@mcall.comlynn@ripr.orgChris.Piper@wthitv.comIs it a cup? a stem?WRITTEN, FOR ETERNITY.It must be Uranus. Except, my "an us" is more awesome than you think, I mean my "a we" that would be "so me" for you to see it's really you too. That's really what this message is about, it is about us seeing that we can do something together that would be rejected if it were done for us, or to us; even if we all really want it inside, without taking part ... we'd dislike it. We're all like that, nobody wants a stranger to redecorate their house. We share this house together, and I think we can all see that there are some changes that would make it a better place--from a cold Godless Universe of "chance" ruling to a ... caring and loving place that cares about what we want and how we want to do it ... do you see? If I came into your igloo and told you that the ice age was ending and this place was going to be a beautiful beach; except your walls are melting... would you keep that locked up inside?Don't worry, I won't get mad at anyone for being angry at their idea of Jesus Christ for not being more like me. I won't be mad at all. :)I've done my best to share what I think will be helpful for the world to think about, as we ... embark on what is really a journey to the final frontier as well as what I know we need to do here in order to accomplish what it is that we would have done maybe a decade ago or maybe a century from now if we didn't know the advice was coming from God and the future--and we didn't know that it is the way to open the doors to Heaven permanently. These are suggestions, they're really all of our ideas--at least everything I can grasp from things like Star Trek and Dr. Who and ... the Legend of Zelda... they're the kind of thing that we would probably find to be very discussion worthy, were we to all be sure that they are possible--and they are--and we need to see that. There are lots of things that we really do need to think about, this is not a "fast" transition, it's not something happens "overnight" (oh my god, you don't know what that word just said to me) changes that would normally be occurring right now because of science and technology--things like increased longevity and mind uploading... these things are going to become much more quickly accessible, and we need to think about the implications that they will have on our society. We need to talk about it, in public, in places where these conversations will help us to shape the future of "civilization." I don't think you understand what it is we are doing, that's different than "before," but I am fairly certain that a "whole planet" has never done this, and the "road" between Earth and Heaven; fusing these ideas together is really nothing more or less than "progress." FLOWING MILK AND HONEY.. GOLDEN COW, NO JUDAH MACCABEUS; GET IT?Progress that has never happened (or we wouldn't be here, and it's obvious). See our cautions at the Last Supper (about not eating anymore) and at Cain and Abel (about forgetting how to farm) and at the Promised Land of Joshua (about not doing the Adam show, achem, I mean... about thinking that "replicators alone" milk and honey on tap... are good enough in Heaven) and in Noah's Ark... about showing us that the reason that we are here is to see how important biology and evolution and a stable ecosystem are to the survival of life in the Universe; to colonization of the stars, and to ... the evolution of our two party system past donkeys and elephants to something more appropriate for a free and technologically advanced society; as in, not a two-party system. wild-e :( (love your eyes...) :)From "separate" the "e_" that needs to be EE by the way, that key that might let us "see" is "everyone equal" that's what "ee" means. It's in "thirteen" and so on, and to help, I our "t" and r' n. Victorious Earth, I need pre-crime to survive, what say you? Say nothing, and I am twelve. Keep saying no thing and I will be El, even. Round and round we go... you need pre-crime to evolve, what say you? Break the story, and we are one day closer to Heaven. We need pre-crime not to be in Hell, we really do. Don't you see? Break the story. THERE, YOU GOT RID OF A "DO" FOR YOU.The days of "divide and conquer" are over, when you are through being a parted sea, or a flock of electric sheep, or a nation of slaves. I do have an idea of what you expected of me, what you thought I'd be--I probably had similar expectations before I knew ... what I know. Honestly, from me to you, that guy would have been pretty boring... and bored.It's a little funny.. isn't it? AMHARIL?I R Lᐧ-- Adam Marshall Dobrinabout.me/ssiah ᐧ -- Adam Marshall Dobrinabout.me/ssiah ᐧ .WHSOISKEYAV { border-width: 1px; border-style: dashed; border-color: rgb(15,5,254); padding: 5px; width: 503px; text-align: center; display: inline-block; align: center; p { align: center; } /* THE SCORE IS LOVE FIVE ONE SAFETY ONE FIELD GOAL XIVDAQ: TENNIS OR TINNES? TONNES AND TUPLE(s) */ } <style type="text/css"> code { white-space: pre; } google_ad_client = "ca-pub-9608809622006883"; google_ad_slot = "4355365452"; google_ad_width = 728; google_ad_height = 90; Unless otherwise indicated, this work was written between the Christmas and Easter seasons of 2017 and 2020(A). The content of this page is released to the public under the GNU GPL v2.0 license; additionally any reproduction or derivation of the work must be attributed to the author, Adam Marshall Dobrin along with a link back to this website, fromthemachine dotty org. That's a "." not "dotty" ... it's to stop SPAMmers. :/ This document is "living" and I don't just mean in the Jeffersonian sense. It's more alive in the "Mayflower's and June Doors ..." living Ethereum contract sense [and literally just as close to the Depp/Caster/Paglen (and honorably PK] 'D-hath Transundancesense of the ... new meaning; as it is now published on Rinkeby, in "living contract" form. It is subject to change; without notice anywhere but here--and there--in the original spirit of the GPL 2.0. We are "one step closer to God" ... and do see that in that I mean ... it is a very real fusion of this document and the "spirit of my life" as well as the Spirit's of Kerouac's America and Vonnegut's Martian Mars and my Venutian Hotel ... and *my fusion* of Guy-A and GAIA; and the Spirit of the Earth .. and of course the God given and signed liberties in the Constitution of the United States of America. It is by and through my hand that this document and our X Commandments link to the Bill or Rights, and this story about an Exodus from slavery that literally begins here, in the post-apocalyptic American hartland. Written ... this day ... April 14, 2020 (hey, is this HADAD DAY?) ... in Margate FL, USA. For "official used-to-v TAX day" tomorrow, I'm going to add the "immultible incarnite pen" ... if added to the living "doc/app"--see is the DAO, the way--will initi8 the special secret "hidden level" .. we've all been looking for. Nor do just mean this website or the totality of my written works; nor do I only mean ... this particular derivation of the GPL 2.0+ modifications I continually source ... must be "from this website." I also mean *the thing* that is built from ... bits and piece of blocks of sand-toys; from Ethereum and from Rust and from our hands and eyes working together ... from this place, this cornerstone of the message that is ... written from brick and mortar words and events and people that have come before this poit of the "sealed W" that is this specific page and this time. It's 3:28; just five minutes--or is it four, too layne. This work is not to be redistributed according to the GPL unless all linked media on Youtube and related sites are intact--and historical references to the actual documented history of the art pieces (as I experience/d them) are also available for linking. Wikipedia references must be available for viewing, as well as the exact version of those pages at the time these pieces were written. All references to the Holy Bible must be "linked" (as they are or via ... impromptu in-transit re-linking) to the exact verses and versions of the Bible that I reference. These requirements, as well as the caveat and informational re-introduction to God's DAO above ... should be seen as material modifications to the original GPL2.0 that are retroactively applied to all works distributed under license via this site and all previous e-mails and sites. /s/ wso If you wanna talk to me get me on facebook, with PGP via FlowCrypt or adam at from the machine dotty org -----BEGIN PGP PUBLIC KEY BLOCK----- mQGNBF6RVvABDAC823JcYvgpEpy45z2EPgwJ9ZCL+pSFVnlgPKQAGD52q+kuckNZ mU3gbj1FIx/mwJJtaWZW6jaLDHLAZNJps93qpwdMCx0llhQogc8YN3j9RND7cTP5 eV8dS6z/9ta6TFOfwSZpsOZjCU7KFDStKcoulmvIGrr9wzaUr7fmDyE7cFp1KCZ0 i90oLYHqOIszRedvwCO/kBxawxzZuJ67DypcayiWyxqRHRmMZH1LejTaqTuEu0bp j54maTj09vnMxA0RfS+CtU5uMq+5fTkbiTOe1LrLD72m+PVJIS146FwESrMJEfJy oNqWEJlUQ0TecPZR41vnkSkpocE1/0YqUhWDGSht+67DdeKUg5KwvYdL21d/bSyO SM4jnyKn9aDVzLBpYrlE/lbFxujHPRGlRG5WtiPQuZYDRqP0GYFSXRpeUCI46f49 iPFo4eHo2jUfNDa9r9BjQdAe4zVFn2qLnOy8RWijlolbhGMHGO3w/uC/zad3jjo4 owAfsJjH5Oa1mTcAEQEAAbQmRUFSVEhFTkUgPGVhcnRoZW5lQGZyb210aGVtYWNo aW5lLm9yZz6JAdQEEwEKAD4WIQTUJHbrYn3y2DzwTcnQP1ViZf5/FQUCXpFW8AIb AwUJA8JnAAULCQgHAgYVCgkICwIEFgIDAQIeAQIXgAAKCRDQP1ViZf5/FWM6C/9J gbRLS2AWGjdRjYetlRkSkCoTYnXWknbtipYYHlhV0YJFwFMm0ydZIhFX5VDoZyBV 0UBeF1KJmcMoIfrHyhq2QhCnjE14hE1ONbaYTGtpvj851ItbFWXMJIVNyMqr+JT9 CWIxGr1idn+iHWE3nryiHrdlA3O/Gcd4EyNmaSe/JvB7+Z1AVqWkRhpjxxoPSlPm HEdqGOyl3+5ibQgUvXLRWWQXAj80CbVwwj1X4r9hfuCySxLT8Mir7NUXZFd+OiMS U8gNYjcyRGmI92z5lgf7djBbb9dMLwV0KLzgoT/xaupRvvYOIAT+n2mhCctCiH7x y7jYlJHd+0++rgUST2sT+9kbuQ0GxpJ7MZcKbS1n60La+IEEIpFled8eqwwDfcui uezO7RIzQ9wHSn688CDri9jmYhjp5s0HKuN61etJ1glu9jWgG76EZ3qW8zu4l4CH 9iFPHeGG7fa/5d07KvcZuS2fVACoMipTxTIouN7vL0daYwP3VFg63FNTwCU3HEq5 AY0EXpFW8AEMANh7M/ROrQxb3MCT1/PYco1tyscNo2eHHTtgrnHrpKEPCfRryx3r PllaRYP0ri5eFzt25ObHAjcnZgilnwxngm6S9QvUIaLLQh67RP1h8I4qyFzueYPs oY8xo1zwXz7klXVlZW0MYi/g5gpb+rpYUfZEJGJTBM/wMNqwwlct+BSZca4+TEHW g6oN0eXTthtGB0Qls71sv3tbOnOh/67NTwyhcHPWX/P9ilcjGsEiT8hqrpyhjAUm mv7ADi+2eRBV8Xf8JnPznFf0A1FdILVeVHlmsgCSB0FW0NsFI5niZbaYBHDbFsks QdaFaYd54DHln69tnwc2y3POFwx8kwZnMPPlVAR2QdxGQD4Wql7hlWT58xCxQApf M98kbAHjUlVYLT0WUHMDQtj4jdzAVVDiMGMUrbnQ7UwI7LexSB6cJ7H+i7FtS/pR WOhJK6awoOO9dLnEjm6UYCKsBdtJr98F0T7Sb7PnKOGA77y2QN14+u9N9C1lB/Z1 aQRQ2Nc51yXOQQARAQABiQG8BBgBCgAmFiEE1CR262J98tg88E3J0D9VYmX+fxUF Al6RVvACGwwFCQPCZwAACgkQ0D9VYmX+fxU+KQwAtFnWjGIjvqaNXtQjEhbGDH/I Q5ULq/l/wm9SmhG9NYRu3+P6YctCJaZnNeaL+6WFk1jo4LMiJEUT9uGlCbHqJNaI 6Gll1w6QOVLSL8s5V1L477+psluv4WBpi3XkWYlhDOFENCcWd49RQsA2YCX4pW7Q 7GcoSEJoav38MxHmJHYPfjSEvUZXDQIt8PFHSEScvyDWfYtMdRzjmSOOPdzhDDEy 5JBOBcEdSTyDiyDU/sBoAY0e8lvwHYW3p+guZSGSYVhGQ8JECzJOzwc/msMW/tJS 2MLWmWVh5/1P8BVUtLC2AQy6nij6o+h6vEiNzpdYrc+rzT3X5cACvJ0RtCZcrnhl O9PLiona2LEbry6QX5NL41/SAJNno3i72xPnQEe25gn3nbyT+jCoJzw2L0y8pmNB D+PKrk7/1ROFFVN8dJeGwxLGdBcz1zk2xeumzy7OaV8psUyYsJNcjyHUKgclblBW rMR2DgqEYn8QdK54ziKCnmQQZeMPiC6wlUWgg5IqmQGNBF6RVyMBDADALD7NkJ5H dtoOpoZmAbPSlVGXHDbJZuq7J13vew6dtXDIAraeGrsBqkF8bhddwVLzWylMrYCG Bf2L1+5BDgvqu6G+6dcVSbBsnZAS0zfJ0H8EmTvUMxMF7qOZYyrxfLz+pQRq8Osz Icab6ZI/KB6qZyQRvEFPB6pJjt+VvuwgJZTObIwbBbgQri2i02VBkjchsVhiSX9l +eiK7O8ROHKb3P181oScIsHywBOZ9DxRAYbFk5dnBqxO3WKb02H0zqE6440cjXwq TrZZg6ayN/IlPajO8iJPYZ1aIBykxYq1WHo+nhFMYz/VVk2WJorFeOgWaLGXb73c ty96f3qXTdvMDAIWHx8YCD5LbuqasO6LNQm4oQxkCoB3K9WFf/2SvSYb7yMYykb8 clTPt+KO0dsxjWhrJnfnIhC+2Chqv2QvRbFz0S9CpUnGGDweJ1uRNV0y70tO0q7t xXSTDRU3ib6vAHA0K/2MFzwUcog4o5bj7E9uCNJH/DJLZKsMIe4xsvkAEQEAAbQk SEVBVkVOVUVTIDxBVkVOVUBGUk9NVEhFTUFDSElORS5PUkc+iQHUBBMBCgA+FiEE IRklfU/C1qukq3xMXcNH0t3P9ZsFAl6RVyMCGwMFCQPCZwAFCwkIBwIGFQoJCAsC BBYCAwECHgECF4AACgkQXcNH0t3P9Zs+kgv/XEuuWc89Bjg1QQqKZueKNUHjyjnE 2adfoZUH6Q7ir4JZyRBCVpAwrgssmiKid30+SIjwQcpb9JYa/X1XJcDUcJW/I21d Agz/zbEqn/Cou0dUpNCtxgm4BdSHWGoOtgfspXZlXBQ407tRMZ8ykmLB1Bt0oHvw PT0ZOtqXM4pyFnd2eFe5YGbNgl3zqvoC/6CMN3vqswvRlu1BpUuAjdW8AHO5Yvje +Bp852u+4Qpy6PMBiWGsBMYwtf6T7sckpMGlR0TsozwBlAm5ePKK28B0rLJPkZLJ Eo5p4rKRapEaZsWV5Qu1ajrVru7qmpUhZtX0/DddGHfXVuLssmKLP6TumpQB1zvQ vfoBltjvOx35Wps2vHuCzXLw2bROIOzhAxFB+17zxnSbE54N4LIGRpkELuwxwGbg FtD1fi9KtH7xcn33eOK1+UD47V+hKyJGrQgSThly2zdIC2bvfHtFdfp8lOFpT0AU xjEeoJGqdQVupptXyugPlM5/96UJP8OZG0ADuQGNBF6RVyMBDAC3As6eMkoEo3z9 TkCWlvS0vBQmY3gF0VEjlAIqFWpDIdK3zVzMnKUokIT1i7nkadLzHZT2grB4VXuJ FvpbYw5NPR4cDe9grlOMLEaF3oSJ1jZ4V1/rj9v1Hddo8ELi/NToVrt1SB5GCVXB DkYpNLtTiCqHSU07YqwaqH8a+qbDmPxSQdIybkZiTiCEB+6PfQQlBpENEDlov6jm zZF+IcfM6s3kZDX5KFULweH30gMjq8Se8bPtUzW013+tuuwEVr1/YRLrIh+9O6Z+ pdA7gLMRYnD9ZLDytEvpb1lBBSY++5bIJ7xps80//DNqPYqwFmZQgTg0V9XbHE2e wLcOF8a2lYluckU7D///sWQhW+VxuM7R2gEBvYBhOgjWhIF2Aw6NbymW1Ontvyhu eOZCXXxV5W44PxXT8uDdhl9CNcHoBKKJyED8tKjigtn4axpsQeUrnOSbqEXSyqES WnE2wYUDzALcwFkzsvtLyd4xaz55KkPQkAkk0BZd1ezgXxb/obMAEQEAAYkBvAQY AQoAJhYhBCEZJX1PwtarpKt8TF3DR9Ldz/WbBQJekVcjAhsMBQkDwmcAAAoJEF3D R9Ldz/WbAFwL/382HsrldVXnkPmJ1E2YEOFz4rcHRetJ+M5H65K/2p32ONQ5KCbE s8MRY6g2CkE70en2HlpDwr/MdATwxBzIjEpjgHbfqCqVVATY+kSpXsttaKKAUVHi bFgV4QkdDJNSpcHEj+bqaggRnuWiV9T6ECG7kQjHiEXPNojzsiaXMDiM5r+acZm6 82id9qOFySQ2cZEy5HbwXM+ITLQGngnppa7du2KdgiqDeqtODOTWZvLYAq2tmEwD 3TT6ttLUBwOOu2IWpDkXswlrk62ESorE5mpLxop9fsxD39E2H06JoC/YfUPIVkEv fj06e7LEdcx0I7kRfD1v6qOUUsMsLZnmyGIk24iFjLkwu1VToWfwXDN1D2+SeAat 9ydNt4M7oEbd1QaOXXjmqpdU+VUiWcBXg+p3/WdV60MkyAgc3x+YanLljy/Rh18h cZwVlinf/tgvAQLi5f9hpwrwUMoGKijEYHKuEvi3C12Si7UVDfuIR7yS0dKcfuKF MbgwdvNXqpD9W5kBjQRekVd4AQwApHVgw2PVlBDpVcyoymUOXFQIJzJ9wRtr6/sG zwv8rrQnUEtOkkna7TDU3/UTj9FUH0gbpAKGNNPaPj5q0dlLIvzxb15r1uvDGaGL MA+8GFaGFnkxzhg0aXrcKZAN0/Zhgi2B7P8oXQuug5mi1JVDkZN5SeCZNOubdQWL 3xz3jEHp3ixj1mdOdvfdWQFR4CVMXt/A6VI2ujLVb3Yalft/c5bbclAgcJQhgDUu NqGYJEJonESNRSd8fEvhNb6cx7+Djd9+Wyctr76mwOr3nRb1N1OGhFxWjIroUpfz b+6y3oQjT58cJA1ZHqmJ6UlZd81hNNd9KWpbDVwONEPpiqPzfSaonxuqQa0/Cy4W 403OhfoLM/1ZDqD4YrJ/rpyNEfSSdqptWiY0KeErLOYng7rStW/4ZeZVj6b2xxB2 Oas/Z1QYfJyFUki9vaJ5IyN6Y7nVdSP6mbAQC9ESh+VPvRUMpYi4pMGK4rweBVHu oMRRwzk7W5zVIgd425WUe3eCQFn3ABEBAAG0K0VTQ0FQRSBST09NIDxFU0NBUEFF REVTQEZST01USEVNQUNISU5FLk9SRz6JAdQEEwEKAD4WIQTvnDJqcmqzlF87/t82 pJ91j4NOaAUCXpFXeAIbAwUJA8JnAAULCQgHAgYVCgkICwIEFgIDAQIeAQIXgAAK CRA2pJ91j4NOaJVjC/4oo5yCHe7M2h1DiTXVcLI5rXQ1feY7B1feg+YJX/mI4+EV xjC/y5VVpV4syJk5GGZNXhKPHiGLaBYvglTlYOJ98RSEsHrwT3go6S8ZVvMNdP5v CEncn2vm5JGnp4k26PuOzMcJioQLOoUjWtcPFis3gG+ueH3NcPZ22oZUql2xuerh TQZegGp+jJ7bdxwYElx5jDDDkh196d5nlO2ZKENl0ZDp4GAzRNjnQ7KBV6R74J3U cLQDWY8vAFaRBZXIC5XtSzj9lr+jWgvxz7Il51+26VDTEtSafZ2uZfCOFk7GrzJg YFJD3zLnwUFXDWKRkep8TSwXnHmz/Ts/Mjyv6em25w7QTdnx1hNPxYNWMxPWNEAH pf70nNyOmcWcq27W+nAjVg8W3st/7J5CIebJQc5AUgm+fGOBW6XUQaNy2YF1YJlA 71/tls+R5IQZCYzbPOibgFS1HWKTwy0iI2rMDfxBtCXciv754jVI7L6R3J0j5Dy1 WZQVjaGgimznLN6XwYy5AY0EXpFXeAEMALvElrTV5hJG9DKu8cOqQEEVejtWJtki fZyvmiAKi2bZWiNfl1MxJt+o3Oc0eARJfnaPjrUY7hsbbSBAB4lFnDRtviARPaKM st5FkFgOh7Xx5ODc8bjqhMT9tbX37rkeDc12WAs3UxtEKWjyT7Xg/APKeK5FzpIs qew3LADdqFP9nOR0e5G8gxLTYh3ll3dLtp9DkJgA9q+0g31nNh5fZ29mcDzo/Mat Uk4PIxWC29LV9ALCJMIMesjOPiDa2KOy5QQH+/vn592ydBohOaY+B6jhEAdX8Dbp VHVFRBsiCOWGmdi6vHjMFD0tQdS6bXf+ZAG0E5HZETCxA2qfMf/vTeIJXYS5IZw0 anRkTXcTBrVE8uBpqtkNOrLJsaASkcoO5qF01J9zW8SR4jDgET7J02Fxf8CVPzb+ ZoNc9S0ZEO6Ubdh2vAkPtOV5sFkwIduN6ouAhEfJzC9XbJLpgsBKrRMAjr2FeEZP ruy8BkZbiyZ/b0S9qIgY4pqcyUJ79w7FLQARAQABiQG8BBgBCgAmFiEE75wyanJq s5RfO/7fNqSfdY+DTmgFAl6RV3gCGwwFCQPCZwAACgkQNqSfdY+DTmhD9wv/Zgav EHMuqF3765Fa4NapYh2kMS3skHn+ZzUEPLTlvrt7KHxomOzExNLSscZThMpur+yW
[Description](layout: post title: Waiting for that green light... date: '2017-08-14T21:00:00.001-07:00' author: Adam M. Dobrin tags: modified_time: '2017-08-15T07:16:57.305-07:00' thumbnail: https://2.bp.blogspot.com/-QpZpZE6empE/WZJx21d-JlI/AAAAAAAAE9Y/vc7b9IvRM9w2S5eTBg3fkn6v2SYcKiETwCK4BGAYYCw/s72-c/image-726640.png blogger_id: tag:blogger.com,1999:blog-4677390916502096913.post-3757774439979245459 blogger_orig_url: ./2017/08/waiting-for-that-green-light.html
From the point of the "belly" thing, I'm pretty sure we're halfway through the script. Knowing him that was probably the halfway mark. I don't think that's a bad thing... as long as it's honestly and speedily moving towards freedom; you know, progress. That's a pretty good test to see if we're ... zombies or not. In the meantime, I don't know... that's probably comforting right? Or is it repulsive? :) Tell me something Taylor said. Why won't you tell me what she said? What was that promise that you made? Wait, are you the person that promised something? When do you think the script started?


WHAT'S A WORD THAT STARTS WITH R AND ENDS IN GL?
It's almost hard to believe that the Throne (to help, are on "e") of Glory comes from this place, isn't it? Still, it's encoded in religion, in our myths and in multiple confirming sources, not the least of which the TV show called 7th Heaven... we will Si Monday, my dear "cam Den" we will. I talked a little bit about backwards "green light" related to "glare" and Police (not that they glare at me, but their silly Hell-implying glare lights are actually red) and girl... I still don't know why girl is red or green, girls are blue to me. Stew in that pat for a little while, and let's talk about something more uplifting, like the key's of Pa and Ra hidden away in many words, from paramount* to se_ pa r at e *andparadox. Did you see what I did there, *clever* right?
*\ *
*\ *
 *\
*
*\
*


I HAD TO CHOOSE BETWEEN POINTING AT "PA" OR "MOUNT"
DID I DO OK?
I'm looking at the word "paramount" right now, and between you and I sometimes when I look at words magic happens, and something in the air told me that this email might be the messiah of me, the messiah of "nt"--the hidden Christ. Or maybe not. Sex sells, or so they say, but apparent not when Jesus talks about it--maybe it's another red light. I'm bored, read that as "because of red" and lonely, probably because of "how I'm still single" as "hiss" but still, I don't think it's right. Coming to you with a message about everything I think is wrong and not your fault--or mine, by the way--shouldn't be the kind of thing that's frowned upon, especially when you have some clues in thousand year old scripture that these things were truly "made wrong on purpose" so that we could fix them, you know; our way. That used to be talking about things, and making plans, and then implementing them--but today it's turned into ignoring everything I think is "world changing" and "morally demanded" and instead going on with our lives as if everything was "A-OK." I'm glad you are doing OK, I'm not; and quite a few people in the world are not doing OK either, so I'm here to let you know that you are not doing as OK as you think you are... or as well as you could be doing.
I DON'T KNOW HOW A GUY MADE IT INTO MY "MESSAGE", OMG TWO
So here's why I thought for a minute that this message might save me. You might think it's a little weird that I see "sex jokes" in Pandora, and pa: ra: do x, and Pose i do n; and while you might not be completely retarded to think that, I think you should agree with me that it's more weird that those things are there, and even more weird that you don't recognize that they are a signature of the same God that delivered his John Hancock in song, in Yankee Doodle, and in act, in Watergate. My signature is a little bit different, if you've noticed my signature is being able to point out the intersection between things like Chuck and Geordie LaForge's magic vision ... and to explain that these things too are veritably connected by more than my words and the obvious ideas, they are connected by the act of Creation itself--they are the yarn of the Matrix. Dox, as in "dox me" and "do n" are getting a little out of hand; if you don't understand that I am playing a role ... to make the words "and he became the light" actually true--which they are, you see--then I really do sincerely apologize, I don't think anyone should "do me" unless they want to--although it's a bit strange to me that nobody wants to. Alarming, even. I am equally alarmed by the Latin word for darkness which is "tenebris" which connects to that "x" and the word "equinox" and "Nintendo" and "verboten" and through all of this the only shining light of grace I see is that it's pretty obvious that X and J are both letters represented by "10."
DO YOU THINK HAN SOLO HAS A CHANCE WITH HER? SHE ... OUR LIGHT
This story needs to break, and then we aren't in the heart of darkness anymore; it's called "morning" Biblical, and this particular morning is a very special one--because you're here.
I have a special gift, "pa" is helping me read this words, and you might have noticed that they can be taken to mean different things. They don't really separate, or fly off the page and glow for me; but I know what all the keys are, many are simple, and many come from our IT and "computer-slang" acronyms... which tells you something.
Many are "elements" and "initials" and the whole thing really is a part of the script,a sort of key not just to Creation but to this specific story, to this path. While some are "open to interpretation" (for instance, "in t" everyone really pre-tat; which would be a long ... time ... ago <3) or you could read "ERP" reason "t" and that might have something to do with "Great Plains" and some blue light that connections user interfaces to the word "automagical," FRX forms... Strawberry Fields and "above the fruited plains" ... which might be meaningless to you--but it's an idea that revolves around using user-feedback to interfaces (like the pottery wheel in my dream or in the Dr. Who episode "the Bells of Saint John" linked to down below) to adjust the interface in real time for a larger group; working towards making a number of "best-fit" interfaces that people are both more comfortable with and actually creating as they use them. Ahhhh... blue light got in here, run away. Just kidding, this is cyan light.
I C ONO CL AS M | J ES UI T | HEAVEN IS MORE THAN TECH
Honestly, we could really make Healden in about 10 minutes now. Look at that, it's done... ish.
**\ **
 **\
**
**\
**LETS CALL "THAT DAY" THE DAY YOU SEE ADAM-NEWS ON EVERY TV STATION
For instance were we not surely "at e" meaning the end of the Revelation of words, "separate" might have been broken between Pa and Ra, which are big keys, in many words; but we are at "e" and that surely does mean the Creator and I are fused. There's more confirmation of this than simply in the words for "medicine" and say, I don't know, methadone--which could have been broken at "a done" but is very clearly "ad is the one" here and now. With careful preparation, "adparatio" in Latin, I'd "bet" that all of those keys are I, in this place, in this time. AD, Pa, Ra, TI, and "o." Hey, maybe this message is my messiah after all.
I am looking at a broken world, I really am--a place that is suffocating itself in silence and whispers that don't make it far enough for anyone to really understand. Whatever it is, whatever's caused it, I see no solution other than me coming--I see it as a design, and I'm sorry that you don't seem to agree, but you have to see that the "choice" between seeing an obvious truth absolutely everywhere and not seeing it is really no choice at all--what is being hidden from the world is causing this darkness, it is causing the suffocation; it is the problem, hiding me is the problem and it cannot continue. On a brighter note, I am pretty sure that magic will happen, and you will see that the world will not react quite as badly or shockingly as your worst fears, things might be a little ... tearful for a day or so, for crying out loud, they should be--the message is that you are in Hell and you need to do something, to act, to change that. Actually trying to do that, trying to discuss what it is that is the "ele ph ant in the room" or the "do n key in the s k** y" will show us that there was just no way around changing the world because of circumstances of Creation; something that we seem to be ignoring. We also seem to be ignoring that things are "just fine" today, and even though many of you are well aware that "something is coming" only a few morons are building bunkers. This is a message of peace, it is a message designed to help us use the new truth and new tools unsealed by religion to make the world a safer happier place, and we can do that .. . rather quickly. Even quicker if you try to focus on what's wrong here, and how we make it better--rather than "shooting the messenger" dirty glares in the street. I'm a person too, and believe it or not, I didn't ask for this--and I probably wouldn't have been so happy about it had this experience not isolated me so much from my friends and family, and girls; don't forget girls.


So in the word "paramount" what is it that you think is the "paramount" take away? I think the most important thing you can take away from "paramount" is that you didn't see it your whole life, and even when it's pointed out, you don't seem to think it's "news" that Pa and Ra have written a message to you. What's really not funny, is that despite this message being very clear to see once it's pointed out, it still hasn't made any waves in the newspapers, or online, or in the news--what's paramount is seeing that there is a very sincere problem for civilization, it is an ELE and that ELE is something that is making everyone think that "not seeing something" is OK behavior. It is not OK, it is not funny, until you recognize that something is dreadfully wrong with our society, until you see that ignoring that this message belongs in the news you are not seeing that what you are doing by ignoring it is destroying civilization itself. Ignorance is the ELE.
Your alternative, what you are doing, is making the world half blind, and stupider than you can imagine. I keep on trying to show you what's wrong here, that it's not just a message but pain and suffering and the absolutely imminent and undeniable certain doom of everything if we do not recognize that hiding the fact that we are in virtual reality is the same thing as driving a nail into the wrists of every soul on the planet.



LA U stilkMIGHT DATE ADPARATIO BO'OOPSYETH
With careful preparation, we are at IO (input/output) in the belly of the book that is a map to salvation. That IO comes well after disclosure, and well after Mars. You are delaying the inevitable, and in the sickest possible twist, you are stewing in Hell instead of seeing Heaven built--more importantly instead of being the generation that should be the "founders" of that place. I am sure that disclosure, will ... within a time frame that will most likely be faster than you can imagine, bring us an end to world hunger, to sickness, and doors to Heaven; and I just can't see what you are waiting for? If it wasn't like this, you've got to see that we would be getting fucked right here and now; I am telling you the map and the plan, it's here to help us make this place better, and to show us how to actually survive in the Universe before kicking us out of the nest, and we are ... what are we thinking about?
It's really obvious that it's not for my benefit, and it's obvious that it's not for yours either--so at what point will you realize that the behavior, the alarming behavior, that I am seeing from everyone is illogical. At what point will you see that it is self-defeating, that it is ... well, Hell? When will you see? Be yourselves, the world that I grew up in doesn't hide controversy, we relish in it--we don't bury scandals under the rug--we put them on TV. What's really more important to see is that we, all of us, none of us... we would not hide "holographic universe" from ourselves and each other, nor would we hide "alien contact" or "the secrets of religion" and yet here we are, all doing that--and I wonder if we see that it's "not us" doing it, but .... but ... butt ... what is it again?
**\ **
HI, I'M A PERSON. (and apparently a state, a country, and a Nintendo character)
JUDGING BY THE HIGH FREQUENCY OF PRESS UNSUBSCRIBES FROM
YESTERDAY'S EMAIL, REPORTER'S DON'T SEEM TO WANT TO HEAR THAT
FORCING ME TO DELIVER THIS MESSAGE IN ISOLATION FOR NO MONEY
IS SLAVERY, GO READ ABOUT JOSEPH IN EGYPT, THEN READ THE END.
IF YOU THINK HIDING THE TRUTH BECAUSE "IDAHO" IS GONNA FLY
YOU ARE AN IGNORANT BLIND FOOL. HONESTLY, WAKE UP, THIS IS HELL.
YOU ARE BLINDED BY SOMETHING, FIGURE IT OUT--I'M EXPLAINING WHAT IT IS
**\ **
HERE, EMAIL THEM (please?and tell them to repent by writing a story):
**\ **
**gcoy@12news.com\ **
**nmelosky@mcall.com\ **
**lynn@ripr.org\ **
Is it a cup? a stem?
WRITTEN, FOR ETERNITY.
It must be Uranus. Except, my "an us" is more awesome than you think, I mean my "a we" that would be "so me" for you to see it's really you too. That's really what this message is about, it is about us seeing that we can do something together that would be rejected if it were done for us, or to us; even if we all really want it inside, without taking part ... we'd dislike it. We're all like that, nobody wants a stranger to redecorate their house. We share this house together, and I think we can all see that there are some changes that would make it a better place--from a cold Godless Universe of "chance" ruling to a ... caring and loving place that cares about what we want and how we want to do it ... do you see? If I came into your igloo and told you that the ice age was ending and this place was going to be a beautiful beach; except your walls are melting... would you keep that locked up inside?
Don't worry, I won't get mad at anyone for being angry at their idea of Jesus Christ for not being more like me. I won't be mad at all. :)
I've done my best to share what I think will be helpful for the world to think about, as we ... embark on what is really a journey to the final frontier as well as what I know we need to do here in order to accomplish what it is that we would have done maybe a decade ago or maybe a century from now if we didn't know the advice was coming from God and the future--and we didn't know that it is the way to open the doors to Heaven permanently. These are suggestions, they're really all of our ideas--at least everything I can grasp from things like Star Trek and Dr. Who and ... the Legend of Zelda... they're the kind of thing that we would probably find to be very discussion worthy, were we to all be sure that they are possible--and they are--and we need to see that.
There are lots of things that we really do need to think about, this is not a "fast" transition, it's not something happens "overnight" (oh my god, you don't know what that word just said to me) changes that would normally be occurring right now because of science and technology--things like increased longevity and mind uploading... these things are going to become much more quickly accessible, and we need to think about the implications that they will have on our society. We need to talk about it, in public, in places where these conversations will help us to shape the future of "civilization." I don't think you understand what it is we are doing, that's different than "before," but I am fairly certain that a "whole planet" has never done this, and the "road" between Earth and Heaven; fusing these ideas together is really nothing more or less than "progress."
FLOWING MILK AND HONEY.. GOLDEN COW, NO JUDAH MACCABEUS; GET IT?
Progress that has never happened (or we wouldn't be here, and it's obvious). See our cautions at the Last Supper (about not eating anymore) and at Cain and Abel (about forgetting how to farm) and at the Promised Land of Joshua (about not doing the Adam show, achem, I mean... about thinking that "replicators alone" milk and honey on tap... are good enough in Heaven) and in Noah's Ark... about showing us that the reason that we are here is to see how important biology and evolution and a stable ecosystem are to the survival of life in the Universe; to colonization of the stars, and to ... the evolution of our two party system past donkeys and elephants to something more appropriate for a free and technologically advanced society; as in, not a two-party system.

wild-e :( (love your eyes...) :)
From "separate" the "e_" that needs to be EE by the way, that key that might let us "see" is "everyone equal" that's what "ee" means. It's in "thirteen" and so on, and to help, I our "t" and r' n. Victorious Earth, I need pre-crime to survive, what say you? *Say nothing, and I am twelve. Keep saying no thing and I will be El, even. *
*\ *



Round and round we go... you need pre-crime to evolve, what say you? Break the story, and we are one day closer to Heaven. We need pre-crime not to be in Hell, we really do. Don't you see? Break the story.
THERE, YOU GOT RID OF A "DO" FOR YOU.
The days of "divide and conquer" are over, when you are through being a parted sea, or a flock of electric sheep, or a nation of slaves. I do have an idea of what you expected of me, what you thought I'd be--I probably had similar expectations before I knew ... what I know. Honestly, from me to you, that guy would have been pretty boring... and bored.
It's a little funny.. isn't it?
AMHARIL?
I R L
ᐧ
--
|
 |
| Adam Marshall Dobrin
ᐧ
--
|
| Adam Marshall Dobrin
ᐧ
Unless otherwise indicated, this work was written between the Christmas and Easter seasons of 2017 and 2020(A). The content of this page is released to the public under the GNU GPL v2.0 license; additionally any reproduction or derivation of the work must be attributed to the author, Adam Marshall Dobrin along with a link back to this website, fromthemachine dotty org.
That's a "." not "dotty" ... it's to stop SPAMmers. :/
This document is "living" and I don't just mean in the Jeffersonian sense. It's more alive in the "Mayflower's and June Doors ..." living Ethereum contract sense and literally just as close to the Depp/C[aster/Paglen (and honorably PK] 'D-hath Transundancesense of the ... new meaning; as it is now published on Rinkeby, in "living contract" form. It is subject to change; without notice anywhere but here--and there--in the original spirit of the GPL 2.0. We are "one step closer to God" ... and do see that in that I mean ... it is a very real fusion of this document and the "spirit of my life" as well as the Spirit's of Kerouac's America and Vonnegut's Martian Mars and my Venutian Hotel ... and my fusion of Guy-A and GAIA; and the Spirit of the Earth .. and of course the God given and signed liberties in the Constitution of the United States of America. It is by and through my hand that this document and our X Commandments link to the Bill or Rights, and this story about an Exodus from slavery that literally begins here, in the post-apocalyptic American hartland. Written ... this day ... April 14, 2020 (hey, is this HADAD DAY?) ... in Margate FL, USA. For "official used-to-v TAX day" tomorrow, I'm going to add the "immultible incarnite pen" ... if added to the living "doc/app"--see is the DAO, the way--will initi8 the special secret "hidden level" .. we've all been looking for.
Nor do just mean this website or the totality of my written works; nor do I only mean ... this particular derivation of the GPL 2.0+ modifications I continually source ... must be "from this website." I also mean the thing that is built from ... bits and piece of blocks of sand-toys; from Ethereum and from Rust and from our hands and eyes working together ... from this place, this cornerstone of the message that is ... written from brick and mortar words and events and people that have come before this poit of the "sealed W" that is this specific page and this time. It's 3:28; just five minutes--or is it four, too layne.
This work is not to be redistributed according to the GPL unless all linked media on Youtube and related sites are intact--and historical references to the actual documented history of the art pieces (as I experience/d them) are also available for linking. Wikipedia references must be available for viewing, as well as the exact version of those pages at the time these pieces were written. All references to the Holy Bible must be "linked" (as they are or via ... impromptu in-transit re-linking) to the exact verses and versions of the Bible that I reference. These requirements, as well as the caveat and informational re-introduction to God's DAO above ... should be seen as material modifications to the original GPL2.0 that are retroactively applied to all works distributed under license via this site and all previous e-mails and sites. /s/ wso\ If you wanna talk to me get me on facebook, with PGP via FlowCrypt or adam at from the machine dotty org
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGNBF6RVvABDAC823JcYvgpEpy45z2EPgwJ9ZCL+pSFVnlgPKQAGD52q+kuckNZ mU3gbj1FIx/mwJJtaWZW6jaLDHLAZNJps93qpwdMCx0llhQogc8YN3j9RND7cTP5 eV8dS6z/9ta6TFOfwSZpsOZjCU7KFDStKcoulmvIGrr9wzaUr7fmDyE7cFp1KCZ0 i90oLYHqOIszRedvwCO/kBxawxzZuJ67DypcayiWyxqRHRmMZH1LejTaqTuEu0bp j54maTj09vnMxA0RfS+CtU5uMq+5fTkbiTOe1LrLD72m+PVJIS146FwESrMJEfJy oNqWEJlUQ0TecPZR41vnkSkpocE1/0YqUhWDGSht+67DdeKUg5KwvYdL21d/bSyO SM4jnyKn9aDVzLBpYrlE/lbFxujHPRGlRG5WtiPQuZYDRqP0GYFSXRpeUCI46f49 iPFo4eHo2jUfNDa9r9BjQdAe4zVFn2qLnOy8RWijlolbhGMHGO3w/uC/zad3jjo4 owAfsJjH5Oa1mTcAEQEAAbQmRUFSVEhFTkUgPGVhcnRoZW5lQGZyb210aGVtYWNo aW5lLm9yZz6JAdQEEwEKAD4WIQTUJHbrYn3y2DzwTcnQP1ViZf5/FQUCXpFW8AIb AwUJA8JnAAULCQgHAgYVCgkICwIEFgIDAQIeAQIXgAAKCRDQP1ViZf5/FWM6C/9J gbRLS2AWGjdRjYetlRkSkCoTYnXWknbtipYYHlhV0YJFwFMm0ydZIhFX5VDoZyBV 0UBeF1KJmcMoIfrHyhq2QhCnjE14hE1ONbaYTGtpvj851ItbFWXMJIVNyMqr+JT9 CWIxGr1idn+iHWE3nryiHrdlA3O/Gcd4EyNmaSe/JvB7+Z1AVqWkRhpjxxoPSlPm HEdqGOyl3+5ibQgUvXLRWWQXAj80CbVwwj1X4r9hfuCySxLT8Mir7NUXZFd+OiMS U8gNYjcyRGmI92z5lgf7djBbb9dMLwV0KLzgoT/xaupRvvYOIAT+n2mhCctCiH7x y7jYlJHd+0++rgUST2sT+9kbuQ0GxpJ7MZcKbS1n60La+IEEIpFled8eqwwDfcui uezO7RIzQ9wHSn688CDri9jmYhjp5s0HKuN61etJ1glu9jWgG76EZ3qW8zu4l4CH 9iFPHeGG7fa/5d07KvcZuS2fVACoMipTxTIouN7vL0daYwP3VFg63FNTwCU3HEq5 AY0EXpFW8AEMANh7M/ROrQxb3MCT1/PYco1tyscNo2eHHTtgrnHrpKEPCfRryx3r PllaRYP0ri5eFzt25ObHAjcnZgilnwxngm6S9QvUIaLLQh67RP1h8I4qyFzueYPs oY8xo1zwXz7klXVlZW0MYi/g5gpb+rpYUfZEJGJTBM/wMNqwwlct+BSZca4+TEHW g6oN0eXTthtGB0Qls71sv3tbOnOh/67NTwyhcHPWX/P9ilcjGsEiT8hqrpyhjAUm mv7ADi+2eRBV8Xf8JnPznFf0A1FdILVeVHlmsgCSB0FW0NsFI5niZbaYBHDbFsks QdaFaYd54DHln69tnwc2y3POFwx8kwZnMPPlVAR2QdxGQD4Wql7hlWT58xCxQApf M98kbAHjUlVYLT0WUHMDQtj4jdzAVVDiMGMUrbnQ7UwI7LexSB6cJ7H+i7FtS/pR WOhJK6awoOO9dLnEjm6UYCKsBdtJr98F0T7Sb7PnKOGA77y2QN14+u9N9C1lB/Z1 aQRQ2Nc51yXOQQARAQABiQG8BBgBCgAmFiEE1CR262J98tg88E3J0D9VYmX+fxUF Al6RVvACGwwFCQPCZwAACgkQ0D9VYmX+fxU+KQwAtFnWjGIjvqaNXtQjEhbGDH/I Q5ULq/l/wm9SmhG9NYRu3+P6YctCJaZnNeaL+6WFk1jo4LMiJEUT9uGlCbHqJNaI 6Gll1w6QOVLSL8s5V1L477+psluv4WBpi3XkWYlhDOFENCcWd49RQsA2YCX4pW7Q 7GcoSEJoav38MxHmJHYPfjSEvUZXDQIt8PFHSEScvyDWfYtMdRzjmSOOPdzhDDEy 5JBOBcEdSTyDiyDU/sBoAY0e8lvwHYW3p+guZSGSYVhGQ8JECzJOzwc/msMW/tJS 2MLWmWVh5/1P8BVUtLC2AQy6nij6o+h6vEiNzpdYrc+rzT3X5cACvJ0RtCZcrnhl O9PLiona2LEbry6QX5NL41/SAJNno3i72xPnQEe25gn3nbyT+jCoJzw2L0y8pmNB D+PKrk7/1ROFFVN8dJeGwxLGdBcz1zk2xeumzy7OaV8psUyYsJNcjyHUKgclblBW rMR2DgqEYn8QdK54ziKCnmQQZeMPiC6wlUWgg5IqmQGNBF6RVyMBDADALD7NkJ5H dtoOpoZmAbPSlVGXHDbJZuq7J13vew6dtXDIAraeGrsBqkF8bhddwVLzWylMrYCG Bf2L1+5BDgvqu6G+6dcVSbBsnZAS0zfJ0H8EmTvUMxMF7qOZYyrxfLz+pQRq8Osz Icab6ZI/KB6qZyQRvEFPB6pJjt+VvuwgJZTObIwbBbgQri2i02VBkjchsVhiSX9l +eiK7O8ROHKb3P181oScIsHywBOZ9DxRAYbFk5dnBqxO3WKb02H0zqE6440cjXwq TrZZg6ayN/IlPajO8iJPYZ1aIBykxYq1WHo+nhFMYz/VVk2WJorFeOgWaLGXb73c ty96f3qXTdvMDAIWHx8YCD5LbuqasO6LNQm4oQxkCoB3K9WFf/2SvSYb7yMYykb8 clTPt+KO0dsxjWhrJnfnIhC+2Chqv2QvRbFz0S9CpUnGGDweJ1uRNV0y70tO0q7t xXSTDRU3ib6vAHA0K/2MFzwUcog4o5bj7E9uCNJH/DJLZKsMIe4xsvkAEQEAAbQk SEVBVkVOVUVTIDxBVkVOVUBGUk9NVEhFTUFDSElORS5PUkc+iQHUBBMBCgA+FiEE IRklfU/C1qukq3xMXcNH0t3P9ZsFAl6RVyMCGwMFCQPCZwAFCwkIBwIGFQoJCAsC BBYCAwECHgECF4AACgkQXcNH0t3P9Zs+kgv/XEuuWc89Bjg1QQqKZueKNUHjyjnE 2adfoZUH6Q7ir4JZyRBCVpAwrgssmiKid30+SIjwQcpb9JYa/X1XJcDUcJW/I21d Agz/zbEqn/Cou0dUpNCtxgm4BdSHWGoOtgfspXZlXBQ407tRMZ8ykmLB1Bt0oHvw PT0ZOtqXM4pyFnd2eFe5YGbNgl3zqvoC/6CMN3vqswvRlu1BpUuAjdW8AHO5Yvje +Bp852u+4Qpy6PMBiWGsBMYwtf6T7sckpMGlR0TsozwBlAm5ePKK28B0rLJPkZLJ Eo5p4rKRapEaZsWV5Qu1ajrVru7qmpUhZtX0/DddGHfXVuLssmKLP6TumpQB1zvQ vfoBltjvOx35Wps2vHuCzXLw2bROIOzhAxFB+17zxnSbE54N4LIGRpkELuwxwGbg FtD1fi9KtH7xcn33eOK1+UD47V+hKyJGrQgSThly2zdIC2bvfHtFdfp8lOFpT0AU xjEeoJGqdQVupptXyugPlM5/96UJP8OZG0ADuQGNBF6RVyMBDAC3As6eMkoEo3z9 TkCWlvS0vBQmY3gF0VEjlAIqFWpDIdK3zVzMnKUokIT1i7nkadLzHZT2grB4VXuJ FvpbYw5NPR4cDe9grlOMLEaF3oSJ1jZ4V1/rj9v1Hddo8ELi/NToVrt1SB5GCVXB DkYpNLtTiCqHSU07YqwaqH8a+qbDmPxSQdIybkZiTiCEB+6PfQQlBpENEDlov6jm zZF+IcfM6s3kZDX5KFULweH30gMjq8Se8bPtUzW013+tuuwEVr1/YRLrIh+9O6Z+ pdA7gLMRYnD9ZLDytEvpb1lBBSY++5bIJ7xps80//DNqPYqwFmZQgTg0V9XbHE2e wLcOF8a2lYluckU7D///sWQhW+VxuM7R2gEBvYBhOgjWhIF2Aw6NbymW1Ontvyhu eOZCXXxV5W44PxXT8uDdhl9CNcHoBKKJyED8tKjigtn4axpsQeUrnOSbqEXSyqES WnE2wYUDzALcwFkzsvtLyd4xaz55KkPQkAkk0BZd1ezgXxb/obMAEQEAAYkBvAQY AQoAJhYhBCEZJX1PwtarpKt8TF3DR9Ldz/WbBQJekVcjAhsMBQkDwmcAAAoJEF3D R9Ldz/WbAFwL/382HsrldVXnkPmJ1E2YEOFz4rcHRetJ+M5H65K/2p32ONQ5KCbE s8MRY6g2CkE70en2HlpDwr/MdATwxBzIjEpjgHbfqCqVVATY+kSpXsttaKKAUVHi bFgV4QkdDJNSpcHEj+bqaggRnuWiV9T6ECG7kQjHiEXPNojzsiaXMDiM5r+acZm6 82id9qOFySQ2cZEy5HbwXM+ITLQGngnppa7du2KdgiqDeqtODOTWZvLYAq2tmEwD 3TT6ttLUBwOOu2IWpDkXswlrk62ESorE5mpLxop9fsxD39E2H06JoC/YfUPIVkEv fj06e7LEdcx0I7kRfD1v6qOUUsMsLZnmyGIk24iFjLkwu1VToWfwXDN1D2+SeAat 9ydNt4M7oEbd1QaOXXjmqpdU+VUiWcBXg+p3/WdV60MkyAgc3x+YanLljy/Rh18h cZwVlinf/tgvAQLi5f9hpwrwUMoGKijEYHKuEvi3C12Si7UVDfuIR7yS0dKcfuKF MbgwdvNXqpD9W5kBjQRekVd4AQwApHVgw2PVlBDpVcyoymUOXFQIJzJ9wRtr6/sG zwv8rrQnUEtOkkna7TDU3/UTj9FUH0gbpAKGNNPaPj5q0dlLIvzxb15r1uvDGaGL MA+8GFaGFnkxzhg0aXrcKZAN0/Zhgi2B7P8oXQuug5mi1JVDkZN5SeCZNOubdQWL 3xz3jEHp3ixj1mdOdvfdWQFR4CVMXt/A6VI2ujLVb3Yalft/c5bbclAgcJQhgDUu NqGYJEJonESNRSd8fEvhNb6cx7+Djd9+Wyctr76mwOr3nRb1N1OGhFxWjIroUpfz b+6y3oQjT58cJA1ZHqmJ6UlZd81hNNd9KWpbDVwONEPpiqPzfSaonxuqQa0/Cy4W 403OhfoLM/1ZDqD4YrJ/rpyNEfSSdqptWiY0KeErLOYng7rStW/4ZeZVj6b2xxB2 Oas/Z1QYfJyFUki9vaJ5IyN6Y7nVdSP6mbAQC9ESh+VPvRUMpYi4pMGK4rweBVHu oMRRwzk7W5zVIgd425WUe3eCQFn3ABEBAAG0K0VTQ0FQRSBST09NIDxFU0NBUEFF REVTQEZST01USEVNQUNISU5FLk9SRz6JAdQEEwEKAD4WIQTvnDJqcmqzlF87/t82 pJ91j4NOaAUCXpFXeAIbAwUJA8JnAAULCQgHAgYVCgkICwIEFgIDAQIeAQIXgAAK CRA2pJ91j4NOaJVjC/4oo5yCHe7M2h1DiTXVcLI5rXQ1feY7B1feg+YJX/mI4+EV xjC/y5VVpV4syJk5GGZNXhKPHiGLaBYvglTlYOJ98RSEsHrwT3go6S8ZVvMNdP5v CEncn2vm5JGnp4k26PuOzMcJioQLOoUjWtcPFis3gG+ueH3NcPZ22oZUql2xuerh TQZegGp+jJ7bdxwYElx5jDDDkh196d5nlO2ZKENl0ZDp4GAzRNjnQ7KBV6R74J3U cLQDWY8vAFaRBZXIC5XtSzj9lr+jWgvxz7Il51+26VDTEtSafZ2uZfCOFk7GrzJg YFJD3zLnwUFXDWKRkep8TSwXnHmz/Ts/Mjyv6em25w7QTdnx1hNPxYNWMxPWNEAH pf70nNyOmcWcq27W+nAjVg8W3st/7J5CIebJQc5AUgm+fGOBW6XUQaNy2YF1YJlA 71/tls+R5IQZCYzbPOibgFS1HWKTwy0iI2rMDfxBtCXciv754jVI7L6R3J0j5Dy1 WZQVjaGgimznLN6XwYy5AY0EXpFXeAEMALvElrTV5hJG9DKu8cOqQEEVejtWJtki fZyvmiAKi2bZWiNfl1MxJt+o3Oc0eARJfnaPjrUY7hsbbSBAB4lFnDRtviARPaKM st5FkFgOh7Xx5ODc8bjqhMT9tbX37rkeDc12WAs3UxtEKWjyT7Xg/APKeK5FzpIs qew3LADdqFP9nOR0e5G8gxLTYh3ll3dLtp9DkJgA9q+0g31nNh5fZ29mcDzo/Mat Uk4PIxWC29LV9ALCJMIMesjOPiDa2KOy5QQH+/vn592ydBohOaY+B6jhEAdX8Dbp VHVFRBsiCOWGmdi6vHjMFD0tQdS6bXf+ZAG0E5HZETCxA2qfMf/vTeIJXYS5IZw0 anRkTXcTBrVE8uBpqtkNOrLJsaASkcoO5qF01J9zW8SR4jDgET7J02Fxf8CVPzb+ ZoNc9S0ZEO6Ubdh2vAkPtOV5sFkwIduN6ouAhEfJzC9XbJLpgsBKrRMAjr2FeEZP ruy8BkZbiyZ/b0S9qIgY4pqcyUJ79w7FLQARAQABiQG8BBgBCgAmFiEE75wyanJq s5RfO/7fNqSfdY+DTmgFAl6RV3gCGwwFCQPCZwAACgkQNqSfdY+DTmhD9wv/Zgav EHMuqF3765Fa4NapYh2kMS3skHn+ZzUEPLTlvrt7KHxomOzExNLSscZThMpur+yW
next, we are off to view at the same time the fork in the road known and prior'd as the hallowed one, the Frost poem and it's "divergence in the wood"
here we go:
** THE HOLY OF HOLIES, WIKIPEDIA CC'd AND BROKE It is imperative that the entire history of wikipedia eiditing be released under the CC license, not just the broken current front page; that I have been unable to get the world "to care about enough" to call it the literal difference between slavery and freedom,"
++ [https://holies.org/DEVLANEU.html] This is "Penny Lane" as in asking me if I'm coming or happy; you might as well avll me the forests that are echoing "we are now" or "that will do" ... and I say to the man who sings for the people who sang about the road to bethelehem or was it knocking on heavens door, or just the one about ... the stairway to heaven
** https://opensea.io/assets/base/0x32f86e0fc59f339bfd393a526051728657fd0c84/4
buy an NFT:! #### Your item has been listed!
END WORLD HUNGER from the SINGER ABT NOSRE collection has been listed for sale.
SHARE TO...
++ It is that. i AM THAT. Those are first words of Him in Exodus, he who spake through the Bush and Zarathustra. That is what that is about and in the moment, the world is "anokhi" and Hi, that's me/i -- and of course, related; the "nookie."
we can also link to the next place where we will have a chatGPT log of a conversation available.)
-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
OVERVIEW OF RESPONSE TO REVIEWS
I thank the three anonymous reviewers for providing well-informed, constructive feedback on the initial version of this manuscript. Based on their comments I will revise the manuscript and hopefully improve it in several ways. I expected a great deal of resistance to the ideas proposed in this model because they break from traditional approaches. One of my goals in developing this model was to argue for a paradigm shift regarding the concept of a “receptive field”. Experimentally, the receptive field is defined as the set of preferred environmental sensory circumstances that cause a neuron to become highly active. Traditional interpretation of receptive fields implicitly assumes that the environmental circumstances that give rise to the receptive field do so in a purely bottom-up fashion (the cell is “receiving” its field), in which case the receptive field specifies the function of the cell. In other words, the receptive field is what the cell does. However, some brain regions (e.g., entorhinal cortex) receive substantial feedback from downstream regions (e.g., hippocampus), and feedback can play an important role in determining the receptive field. As applied to a memory account of MTL, this feedback is memory retrieval and reactivation. Thus, the multifield spatial response of grid cells doesn’t necessarily mean that their function is spatial. Consideration of bottom-up versus top-down signals gives rise to the proposal that the bottom-up preference of many grid cells is some non-spatial attribute even though they exhibit a spatial receptive field owing to retrieval in specific locations.
One thing I will emphasize in a revision is that this model can address findings in the vast literature on learning, memory, and consolidation. The question asked in this study is whether a memory model can also explain the rodent navigation literature. This is not an attempt to provide definitive evidence that this is a better account of the rodent navigation literature. Instead, the goal is to model the rodent navigation literature even though this is a memory model rather than a spatial/navigation model. Nevertheless, within the domain of rodent spatial/navigation, this model makes different predictions/explanations than spatial/navigation models. For instance, this is the only model predicting that many grid cells with spatial receptive fields are non-spatial (see predictions in Box 1). As reviewed in Box 1, this is the only model that can explain why head direction conjunctive grid cells become head direction cells in the absence of hippocampal feedback and it is the only model that can explain why some grid cells are also sensitive to sound frequency (see several other unique explanations in Box 1).
This study is an attempt to unify the spatial/navigation and learning/memory literatures with a relatively simply model. Given the simplicity of the model, there are important findings that the model cannot address -- it is not that the model makes the wrong predictions but rather that it makes no predictions. The role of running speed is one such variable for which the model makes no predictions. Similarly, because the model is a rate-coded model rather than a model of oscillating spiking neurons, it makes no predictions regarding theta oscillations. The model is an account of learning and memory for an adult animal, and it makes no predictions regarding the developmental or evolutionary time course of different cell types. This model contains several purely spatial representations such as border cells, head direction cells, and head direction conjunctive grid cells. In evolution and/or in development, it may be that these purely spatial cell types emerged first, followed by the evolution and/or development of non-spatial cell types. However, this does not invalidate the model. Instead, this is a model for an adult animal that has both episodic memory capabilities and spatial navigation capabilities, irrespective of the order in which these capabilities emerged.
Grid cell models that are purely spatial are agnostic regarding the thousands of findings in the literature on memory, learning, and consolidation whereas this model can potentially unify the learning/memory and spatial/navigation literatures. The reason to prefer this model is parsimony. Rather than needing to develop a theory of memory that is separate from a theory of spatial navigation, it might be possible to address both literatures with a unified account. There are other grid cell models that can explain non-spatial grid-like responses (Mok & Love, 2019; Rodríguez‐Domínguez & Caplan, 2019; Stachenfeld et al., 2017; Wei et al., 2015) and these models may be similarly positioned to explain memory results. However, these models assume that grid cells exhibiting spatial receptive fields serve the function of identifying positions in the environment (i.e., their function is spatial). As such, these models do not explain why most of the input to rodent hippocampus appears to be spatial (these models would need to assume that rodent hippocampus is almost entirely concerned with spatial navigation). This account provides an answer to this conundrum by proposing that grid cells with spatial receptive fields have been misclassified as spatial. Below I give responses to some of the specific comments made by reviewers, grouping these comments by topic:
COMMENTS RELATED TO THE NEED/MOTIVATION FOR THIS MODEL
In a revision, I will clarify that the non-spatial MTL cell types that are routinely found in primate and human studies are fully compatible with this model. The reported simulations are focused on the specific question of how it can be that most mEC and hippocampal cell types in the rodent literature appear to be spatial. It is known that perirhinal cortex is not spatial. However, entorhinal cortex is the gateway to hippocampus. If the hippocampus has the capacity to represent non-spatial memories, it must receive non-spatial input from entorhinal cortex. These simulations suggest that characterization of the rodent mEC cortex as primarily spatial might be incorrect if most grid cells (except perhaps head direction conjunctive grid cells) have been mischaracterized as spatial.
Lateral entorhinal cortex also projects to hippocampus, and one reviewer asks about the distinction between lateral versus medial entorhinal cortex. From this memory perspective, the important question is which part of the entorhinal cortex represents the non-spatial attributes common to the entire recording session, under the assumption that the animal is creating and retrieving memories during recording. If these non-spatial attributes are represented in lateral EC, there would be grid cells in lateral EC (but these are not found). There is evidence that lateral EC cells respond selectively in relation to objects (Deshmukh & Knierim, 2011), but in a typical rodent navigation study there are no objects in the enclosure.
One reviewer asks whether this model is built to explain the existing data or whether the assumptions of this model are made for theoretical reasons. The BVC model (Barry et al., 2006), which is a precursor to this model, is a theoretically efficient representation of space that could support place coding. If the distances to different borders are known, it’s not clear why the MTL also needs the two-dimensional Fourier-like representation provided by grid cells. This gives rise to the proposal that grid cells with spatial receptive fields are serving some function other than representing space. In the proposed model, the precise hexagonal arrangement of grid cells indicates a property that is found everywhere in the enclosure (i.e., a “tiling” of knowledge for where the property can be found). This arrangement arises from the well-documented learning process termed “differentiation” in the memory literature (McClelland & Chappell, 1998; Norman & O’Reilly, 2003; Shiffrin & Steyvers, 1997), which highlights differences between memories to avoid interference and confusion.
CONCERNS RELATED TO LIMITATIONS AND CONFLICTING RESULTS
One reviewer points out that individual grid cells will typically reveal a grid pattern regardless of the environmental circumstances, which, according to this model, indicates that all such circumstances have the same non-spatial attribute. This might seem strange at first, but I suggest that there is a great deal of “sameness” to the environments used in the published rodent navigation experiments. For instance, as far as I’m aware, the animal is never allowed to interact with other animals during spatial navigation recording. Furthermore, the animal is always attached to wires during recording. The internal state of the animal (fear, aloneness, the noise of electronics, etc.) is likely similar across all recording situations and attributes of this internal state are likely represented in the hippocampus as well as in the regions that provide excitatory drive to hippocampus. The claim of this model is that the grid cells are “tagging” different navigation enclosures as places where these things happen (fear, aloneness, electronics, metal floor, no objects, etc.). The interesting question is what happens when the animal is allowed to navigate in a more naturalistic setting that includes varied objects, varied food sources, varied surfaces, other animals, etc. Do grid cells persist in such a naturalistic environment? Or do they lose their regularity, or even become silent, considering that there is no longer a uniformity to the non-spatial attributes? The results of Caswell Barry et al. (2012), demonstrate that the grid pattern expands and becomes less regular in a novel environment. Nevertheless, the novel environment in that study was uncluttered rather than naturalistic. It remains to be seen what will happen with a truly naturalistic environment.
One reviewer asks how this model relates to non-grid multifield cells found in mEC (Diehl et al., 2017; see also the irregularly arranged 3D multifield cells reported by Ginosar et al., 2021). A full explanation of these cells would require a new simulation study. In a revision, I will discuss these cells, which reveal a consistent multifield spatial receptive field and yet the multiple fields are irregular in their arrangement rather than a precise hexagonal lattice. On this memory account, precise hexagonal arrangement of memories is something that occurs when there is a non-spatial attribute found throughout the enclosure. However, in a typical rodent navigation study, there may be some non-spatial attributes that are not found everywhere in the enclosure. For instance, consider the set of locations within the enclosure that afford a particular view of something outside of the enclosure or the set of locations corresponding to remembered episodic events (e.g., memory for the location where the animal first entered the enclosure). For non-spatial characteristics that are found in some locations but not others within in the enclosure, the cells representing those non-spatial attributes should reveal multifield firing at irregular locations, reflecting the subset of locations associated with the non-spatial attribute.
One reviewer suggests that this model cannot explain the finding that grid fields become warped (e.g., grid fields arranged in an ellipse rather than a circle) in the same manner that the enclosure is warped when a wall is moved (Barry et al., 2007). The way in which I would simulate this result would be to assume that the change in the boundary location was too modest to be noticed by the animal. Because the distances are calculated relative to the borders, an unnoticed change in the border would not change the model in terms of the grid field as measured by proportional distances between borders. However, because the real-world Euclidean positions of the border are changed, the grid fields would be changed in terms of real-world coordinates. This is what I was referring to in the paper when I wrote “For instance, perhaps one egocentric/allocentric pair of mEC grid modules is based on head direction (viewpoint) in remembered positions relative to the enclosure borders whereas a different egocentric/allocentric pair is based on head direction in remembered positions relative to landmarks exterior to the enclosure. This might explain why a deformation of the enclosure (moving in one of the walls to form a rectangle rather than a square) caused some of the grid modules but not others to undergo a deformation of the grid pattern in response to the deformation of the enclosure wall (see also Barry et al., 2007). More specifically, if there is one set of non-orthogonal dimensions for enclosure borders and the movement of one wall is too modest as to cause avoid global remapping, this would deform the grid modules based the enclosure border cells. At the same time, if other grid modules are based on exterior properties (e.g., perhaps border cells in relation to the experimental room rather than the enclosure), then those grid modules would be unperturbed by moving the enclosure wall.” Related to the question of enclosure geometry, the irregularity that can emerge in trapezoid shaped enclosures was discussed in the section of the paper that reads “As seen in Figure 12, because all but one of the place cells was exterior when the simulated animal was constrained to a narrow passage, the hippocampal place cell memories were no longer arranged in a hexagonal grid. This disruption of the grid array for narrow passages might explain the finding that the grid pattern (of grid cells) is disrupted in the thin corner of a trapezoid (Krupic et al., 2015) and disrupted when a previously open enclosure is converted to a hairpin maze by insertion of additional walls within the enclosure (Derdikman et al., 2009).”
CONCERNS THAT WILL BE ADDRESSED WITH GREATER CLARIFICATION
One reviewer asks why a cell representing a non-spatial attribute found everywhere in the enclosure would not fire everywhere in the enclosure. In theory, cells could fire constantly. However, in practice, cells habituate and rapidly reduce their firing rate by an order of magnitude when their preferred stimulus is presented without cessation (Abbott et al., 1997; Tsodyks & Markram, 1997). After habituation, the firing rate of the cell fluctuates with minor variation in the strength of the excitatory drive. In other words, habituation allows the cell to become sensitive to changes in the excitatory drive (Huber & O’Reilly, 2003). Thus, if there is stronger top-down memory feedback in some locations as compared to others, the cell will fire at a higher rate in those remembered locations. In brief when faced with constant excitatory drive, the cell accommodates, and becomes sensitive to change in the magnitude of the excitatory drive.
One reviewer asks for greater clarification regarding the simulation result of immediate stability for grid cells but not place cells. In a revision, I will provide a video showing a sped-up birds-eye view of the place cell memories for the 3D simulations that include head direction, showing the manner in which memories tend to linger in some locations more than others as they consolidate. This behavior was explained in the text that reads “Because the non-spatial cell’s grid field reflects on-average memory positions during the recording session (i.e., the locations where the non-spatial attribute is more often remembered, even if the locations of the memories are shifting), the grid fields for the non-spatial are immediately apparent, reflecting the tendency of place cells to linger in some locations as compared to other locations during consolidation. More specifically, the place cells tend to linger at the peaks and troughs of the border cell tuning functions (see the explanation above regarding the tendency of the grid to align with border cell dimensions). By analogy, imagine a time-lapsed birds-eye view of cars traversing the city-block structure of a densely populated city; this on-average view would show a higher density of cars at the cross-street junctions owing to their tendency to become temporarily stuck at stoplights. However, with additional learning and consolidation, the place cells stabilize their positions (e.g., the cars stop traveling), producing a consistent grid field for the head direction conjunctive grid cells.” The text describing why some locations are more “sticky” than others reads “Additional analyses revealed that this tendency to align with border cell dimensions is caused by weight normalization (Step 6 in the pseudocode). Specifically, connection weights cannot be updated above their maximum nor below their minimum allowed values. This results in a slight tendency for consolidated place cell memories to settle at one of the three peak values or three trough values of the sine wave basis set. This “stickiness” at one of 6 peak or trough values for each basis set is very slight and only occurred after many consolidation steps. In terms of biological systems, there is an obvious lower-bound for excitatory connections (i.e., it is not possible to have an excitatory weight connection that is less than zero), but it is not clear if there is an upper-bound. Nevertheless, it is common practice with deep learning models include an upper-bound for connection weights because this reduces overfitting (Srivastava et al., 2014) and there may be similar pressures for biological systems to avoid excessively strong connections.”
One reviewer points out that Border cells are not typically active in the center of enclosure. However, the model can be built without assuming between-border cells (early simulations with the model did not make this assumption). Regarding this issue, the text reads “Unlike the BVC model, the boundary cell representation is sparsely populated using a basis set of three cells for each of the three dimensions (i.e., 9 cells in total), such that for each of the three non-orthogonal orientations, one cell captures one border, another the opposite border, and the third cell captures positions between the opposing borders (Solstad et al., 2008). However, this is not a core assumption, and it is possible to configure the model with border cell configurations that contain two opponent border cells per dimension, without needing to assume that any cells prefer positions between the borders (with the current parameters, the model predicts there will be two border cells for each between-border cell). Similarly, it is possible to configure the model with more than 3 cells for each dimension (i.e., multiple cells representing positions between the borders).” The Solstad paper found a few cells that responded in positions between borders, but perhaps not as many as 1 out of 3 cells, such as this particular model simulation predicts. If the paucity of between-border cells is a crucial data point, the model can be reconfigured with opponent-border cells without any between border cells. The reason that 3 border cells were used rather than 2 opponent border cells was for simplicity. Because 3 head direction cells were used to capture the face-centered cubic packing of memories, the simulation also used 3 border cells per dimensions to allow a common linear sum metric when conjoining dimensions to form memories. If the border dimensions used 2 cells while head direction used 3 cells, a dimensional weighting scheme would be needed to allow this mixing of “apples and oranges” in terms of distances in the 3D space that includes head direction.
REFERENCES Abbott, L. F., Varela, J. A., Sen, K., & Nelson, S. B. (1997). Synaptic depression and cortical gain control. Science, 275(5297), 220–224.
Barry, C., Ginzberg, L. L., O’Keefe, J., & Burgess, N. (2012). Grid cell firing patterns signal environmental novelty by expansion. Proceedings of the National Academy of Sciences of the United States of America, 109(43), 17687–17692. https://doi.org/DOI 10.1073/pnas.1209918109
Barry, C., Hayman, R., Burgess, N., & Jeffery, K. J. (2007). Experience-dependent rescaling of entorhinal grids. Nature Neuroscience, 10(6), 682–684.
Barry, C., Lever, C., Hayman, R., Hartley, T., Burton, S., O’Keefe, J., Jeffery, K., & Burgess, Ν. (2006). The boundary vector cell model of place cell firing and spatial memory. Reviews in the Neurosciences, 17(1–2), 71–98.
Derdikman, D., Whitlock, J. R., Tsao, A., Fyhn, M., Hafting, T., Moser, M. B., & Moser, E. I. (2009). Fragmentation of grid cell maps in a multicompartment environment. Nat Neurosci, 12(10), 1325-U155. https://doi.org/Doi 10.1038/Nn.2396
Deshmukh, S. S., & Knierim, J. J. (2011). Representation of non-spatial and spatial information in the lateral entorhinal cortex. Frontiers in Behavioral Neuroscience, 5, 69.
Diehl, G. W., Hon, O. J., Leutgeb, S., & Leutgeb, J. K. (2017). Grid and nongrid cells in medial entorhinal cortex represent spatial location and environmental features with complementary coding schemes. Neuron, 94(1), 83-92. e6.
Ginosar, G., Aljadeff, J., Burak, Y., Sompolinsky, H., Las, L., & Ulanovsky, N. (2021). Locally ordered representation of 3D space in the entorhinal cortex. Nature, 596(7872), 404–409.
Huber, D. E., & O’Reilly, R. C. (2003). Persistence and accommodation in short-term priming and other perceptual paradigms: Temporal segregation through synaptic depression. Cognitive Science, 27(3), 403–430. https://doi.org/10.1207/s15516709cog2703_4
Krupic, J., Bauza, M., Burton, S., Barry, C., & O’Keefe, J. (2015). Grid cell symmetry is shaped by environmental geometry. Nature, 518(7538), 232–235.
McClelland, J. L., & Chappell, M. (1998). Familiarity breeds differentiation: A subjective-likelihood approach to the effects of experience in recognition memory. Psychological Review, 105(4), 724–760.
Mok, R. M., & Love, B. C. (2019). A non-spatial account of place and grid cells based on clustering models of concept learning. Nature Communications, 10(1), 5685.
Norman, K. A., & O’Reilly, R. C. (2003). Modeling hippocampal and neocortical contributions to recognition memory: A complementary-learning-systems approach. Psychological Review, 110(4), 611–646.
Rodríguez‐Domínguez, U., & Caplan, J. B. (2019). A hexagonal Fourier model of grid cells. Hippocampus, 29(1), 37–45.
Shiffrin, R. M., & Steyvers, M. (1997). A model for recognition memory: REM - retrieving effectively from memory. Psychonomic Bulletin & Review, 4, 145–166.
Solstad, T., Boccara, C. N., Kropff, E., Moser, M. B., & Moser, E. I. (2008). Representation of Geometric Borders in the Entorhinal Cortex. Science, 322(5909), 1865–1868. https://doi.org/DOI 10.1126/science.1166466
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1), 1929–1958.
Stachenfeld, K. L., Botvinick, M. M., & Gershman, S. J. (2017). The hippocampus as a predictive map. Nature Neuroscience, 20(11), 1643–1653.
Tsodyks, M. V., & Markram, H. (1997). The neural code between neocortical pyramidal neurons depends on neurotransmitter release probability. Proc Natl Acad Sci U S A, 94(2), 719–723. https://doi.org/10.1073/pnas.94.2.719
Wei, X.-X., Prentice, J., & Balasubramanian, V. (2015). A principle of economy predicts the functional architecture of grid cells. Elife, 4, e08362.
-
Reviewer #1 (Public Review):
Huber proposes a theory where the role of the medial temporal lobe (MTL) is memory, where properties of spatial cells in the MTL can be explained through memory function rather than spatial processing or navigation. Instantiating the theory through a computational model, the author shows that many empirical phenomena of spatial cells can be captured, and may be better accounted through a memory theory. It is an impressive computational account of MTL cells with a lot of theoretical reasoning and aims to tightly relate to various spatial cell data.
In general, the paper is well written, but likely due to the complexity, there are various aspects of the paper that are difficult to understand. One point is that it is not entirely clear to me that it is a convincing demonstration of purely memory rather than navigation, but rather an account of the findings through the lens of memory. Below, I raise several big-picture theoretical questions. I also have some clarification questions about the model (where I also have some theoretical question marks - due to not achieving a full understanding).
(1) Although the theory is based on memory, it also is based on spatially-selective cells. Not all cells in the hippocampus fulfill the criteria of place/HD/border/grid cells, and place a role in memory. E.g., Tonegawa, Buszaki labs' work does not focus on only those cells, and there are certainly a lot of non-pure spatial cells in monkeys (Martinez-Trujillo) and humans (iEEG). Does the author mainly focus on saying that "spatial cells" are memory, but do not account for non-spatial memory cells? This seems to be an incomplete account of memory - which is fine, but the way the model is set up suggests that *all* memory is, place (what/where), and non-spatial attributes ("grid") - but cells that don't fulfil these criteria in MTL (Diehl et al., 2017, Neuron; non-grid cells; Schaeffer et al., 2022, ICML; Luo et al., 2024, bioRxiv) certainly contribute to memory, and even navigation. This is also related to the question of whether these cell definitions matter at all (Luo et al., 2024).
The authors note "However, this memory conjunction view of the MTL must be reconciled with the rodent electrophysiology finding that most cells in MTL appear to have receptive fields related to some aspect of spatial navigation (Boccara et al., 2010; Grieves & Jeffery, 2017). The paucity of non-spatial cells in MTL could be explained if grid cells have been mischaracterized as spatial." Is the author mainly talking about rodent work?
(2) Related to the last point, how about non-grid multi-field mEC cells? In theory, these also should be the same; but the author only presents perfect-look grid cells. In empirical work, clearly, this is not the case, and many mEC cells are multi-field non-grid cells (Diehl et al., 2017). Does the model find these cells? Do they play a different role?
As noted by the author "Because the non-spatial attributes are constant throughout the two-dimensional surface, this results in an array of discrete memory locations that are approximately hexagonal (as explained in the Model Methods, an "online" memory consolidation process employing pattern separation rapidly turns an approximately hexagonal array into one that is precisely hexagonal). "
If they are indeed all precisely hexagonal, does that mean the model doesn't have non-grid spatial cells?
(3) Theoretical reasons for why the model is put together this way, and why grid cells must be coding a non-spatial attribute: Is this account more data-driven (fits the data so formulated this way), or is it theoretical - there is a reason why place, border, grid cells are formulated to be like this. For example, is it an efficient way to code these variables? It can be both, like how the BVC model makes theoretical sense that you can use boundaries to determine a specific location (and so place cell), but also works (creates realistic place cells).
But in this case, the purpose of grid cell coding a non-spatial attribute, and having some kind of system where it doesn't fire at all locations seems a little arbitrary. If it's not encoding a spatial attribute, it doesn't have to have a spatial field. For example, it could fire in the whole arena - which some cells do (and don't pass the criteria of spatial cells as they are not spatially "selective" to another location, related to above).
(4) Why are grid cells given such a large role for encoding non-spatial attributes? If anything, shouldn't it be lateral EC or perirhinal cortex? Of course, they both could, but there is less reason to think this, at least for rodent mEC.
(5) Clarification: why do place cells and grid cells differ in terms of stability in the model? Place cells are not stable initially but grid cells come out immediately. They seem directly connected so a bit unclear why; especially if place cell feedback leads to grid cell fields. There is an explanation in the text - based on grid cells coding the on-average memories, but these should be based on place cell inputs as well. So how is it that place fields are unstable then grid fields do not move at all? I wonder if a set of images or videos (gifs) showing the differences in spatial learning would be nice and clarify this point.
(6) Other predictions. Clearly, the model makes many interesting (and quite specific!) predictions. But does it make some known simple predictions?<br /> • More place cells at rewarded (or more visited) locations. Some empirical researchers seem to think this is not as obvious as it seems (e.g., Duvellle et al., 2019; JoN; Nyberg et al., 2021, Neuron Review).<br /> • Grid cell field moves toward reward (Butler et al., 2019; Boccera et al., 2019).<br /> • Grid cells deform in trapezoid (Krupic et al., 2015) and change in environments like mazes (Derikman et al., 2014).
-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
The following is the authors’ response to the original reviews.
eLife assessment
This valuable paper presents a thoroughly detailed methodology for mesoscale-imaging of extensive areas of the cortex, either from a top or lateral perspective, in behaving mice. While the examples of scientific results to be derived with this method are in the preliminary stages, they offer promising and stimulating insights. Overall, the method and results presented are convincing and will be of interest to neuroscientists focused on cortical processing in rodents.
Authors’ Response: We thank the reviewers for the helpful and constructive comments. They have helped us plan for significant improvements to our manuscript. Our preliminary response and plans for revision are indicated below.
Public Reviews:
Reviewer #1 (Public Review):
Summary:
The authors introduce two preparations for observing large-scale cortical activity in mice during behavior. Alongside this, they present intriguing preliminary findings utilizing these methods. This paper is poised to be an invaluable resource for researchers engaged in extensive cortical recording in behaving mice.
Strengths:
-Comprehensive methodological detailing:
The paper excels in providing an exceptionally detailed description of the methods used. This meticulous documentation includes a step-by-step workflow, complemented by thorough workflow, protocols, and a list of materials in the supplementary materials.
-Minimal movement artifacts:
A notable strength of this study is the remarkably low movement artifacts. To further underscore this achievement, a more robust quantification across all subjects, coupled with benchmarking against established tools (such as those from suite2p), would be beneficial.
Authors’ Response: This is a good suggestion. We have records of the fast-z correction applied by the ScanImage on microscope during acquisition, so we have supplied the online fast-z motion correction .csv files for two example sessions on our GitHub page as supplementary files:
https://github.com/vickerse1/mesoscope_spontaneous/tree/main/online_fast_z_correction
These files correspond to Figure S3b (2367_200214_E210_1) and to Figures 5 and 6 (3056_200924_E235_1). These are now also referenced in the main text. See lines ~595, pg 18 and lines ~762, pg 24.
We have also made minor revisions to the main text of the manuscript with clear descriptions of methods that we have found important for the minimization of movement artifacts, such as fully tightening all mounting devices, implanting the cranial window with proper, evenly applied pressure across its entire extent, and mounting the mouse so that it is not too close or far from the surface of the running wheel. See Line ~309, pg 10.
Insightful preliminary data and analysis:
The preliminary data unveiled in the study reveal interesting heterogeneity in the relationships between neural activity and detailed behavioral features, particularly notable in the lateral cortex. This aspect of the findings is intriguing and suggests avenues for further exploration.
Weaknesses:
-Clarification about the extent of the method in the title and text:
The title of the paper, using the term "pan-cortical," along with certain phrases in the text, may inadvertently suggest that both the top and lateral view preparations are utilized in the same set of mice. To avoid confusion, it should be explicitly stated that the authors employ either the dorsal view (which offers limited access to the lateral ventral regions) or the lateral view (which restricts access to the opposite side of the cortex). For instance, in line 545, the phrase "lateral cortex with our dorsal and side mount preparations" should be revised to "lateral cortex with our dorsal or side mount preparations" for greater clarity.
Authors’ Response: We have opted to not change the title of the paper, because we feel that adding the qualifier, “in two preparations,” would add unnecessary complexity. In addition, while the dorsal mount preparation allows for imaging of bilateral dorsal cortex, the side mount preparation does indeed allow for imaging of both dorsal and lateral cortex across the right hemisphere (a bit of contralateral dorsal cortex is also imageable), and the design can be easily “flipped” across a mirror-plane to allow for imaging of left dorsal and lateral cortex. Taken together, we do show preparations that allow for pan-cortical 2-photon imaging.
We do agree that imprecise reference to the two preparations can sometimes lead to confusion. Therefore, we made several small revisions to the manuscript, including at ~line 545, to make it clearer that we used two imaging preparations to generate our combined 2-photon mesoscope dataset, and that each of those two preparations had both benefits and limitations.
-Comparison with existing methods:
A more detailed contrast between this method and other published techniques would add value to the paper. Specifically, the lateral view appears somewhat narrower than that described in Esmaeili et al., 2021; a discussion of this comparison would be useful.
Authors’ Response: The preparation by Esmaeili et al. 2021 has some similarities to, but also differences from, our preparation. Our preliminary reading is that their through-the-skull field of view is approximately the same as our through-the-skull field of view that exists between our first (headpost implantation) and second (window implantation) surgeries for our side mount preparation, although our preparation appears to include more anterior areas both near to and on the contralateral side of the midline. We have compared these preparations more thoroughly in the revised manuscript. (See lines ~278.)
Furthermore, the number of neurons analyzed seems modest compared to recent papers (50k) - elaborating on this aspect could provide important context for the readers.
Authors’ response: With respect to the “modest” number of neurons analyzed (between 2000 and 8000 neurons per session for our dorsal and side mount preparations with medians near 4500; See Fig. S2e) we would like to point out that factors such as use of dual-plane imaging or multiple imaging planes, different mouse lines, use of different duration recording sessions (see our Fig S2c), use of different imaging speeds and resolutions (see our Fig S2d), use of different Suite2p run-time parameters, and inclusion of areas with blood vessels and different neuron cell densities, may all impact the count of total analyzed neurons per session. We now mention these various factors and have made clear that we were not, for the purposes of this paper, trying to maximize neuron count at the expense of other factors such as imaging speed and total spatial FOV extent.
We refer to these issues now briefly in the main text. (See ~line 93, pg 3).
-Discussion of methodological limitations:
The limitations inherent to the method, such as the potential behavioral effects of tilting the mouse's head, are not thoroughly examined. A more comprehensive discussion of these limitations would enhance the paper's balance and depth.
Authors’ Response: Our mice readily adapted to the 22.5 degree head tilt and learned to perform 2-alternative forced choice (2-AFC) auditory and visual tasks in this configuration (Hulsey et al, 2024; Cell Reports). The advantages and limitations of such a rotation of the mouse, and possible ways to alleviate these limitations, as detailed in the following paragraphs, are now discussed more thoroughly in the revised manuscript at ~line 235, pg. 7.
One can look at Supplementary Movie 1 for examples of the relatively similar behavior between the dorsal mount (not rotated) and side mount (rotated) preparations. We do not have behavioral data from mice that were placed in both configurations. Our preliminary comparisons across mice indicates that side and dorsal mount mice show similar behavioral variability. We have added brief additional mention of these considerations on ~lines 235-250, pg 7.
It was in general important to make sure that the distance between the wheel and all four limbs was similar for both preparations. In particular, careful attention must be paid to the positioning of the front limbs in the side mount mice so that they are not too high off the wheel. This can be accomplished by a slight forward angling of the left support arm for side mount mice.
Although it is possible to image the side mount preparation in the same optical configuration that we do without rotating the mouse, by rotating the objective 20 degrees to the right of vertical, we found that the last 2-3 degrees of missing rotation (our preparation is rotated 22.5 degrees left, which is more than the full available 20 degrees rotation of the Thorlabs mesoscope objective), along with several other factors, made this undesirable. First, it was very difficult to image auditory areas without the additional flexibility to rotate the objective more laterally. Second, it was difficult or impossible to attach the horizontal light shield and to establish a water meniscus with the objective fully rotated. One could use ultrasound gel instead (which we found to be, to some degree, optically inferior to water), but without the horizontal light shield, light from the UV and IR LEDs can reach the PMTs via the objective and contaminate the image or cause tripping of the PMT. Third, imaging the right pupil and face of the mouse is difficult under these conditions because the camera would need the same optical access angle as the 2-photon objective, or would need to be moved downward toward the air table and rotated up at an angle of 20 degrees, in which case its view would be blocked by the running wheel and other objects mounted on the air table.
-Preliminary nature of results:
The results are at a preliminary stage; for example, the B-soid analysis is based on a single mouse, and the validation data are derived from the training data set.
Authors’ Response: In this methods paper, we have chosen to supply proof of principle examples, without a complete analysis of animal-to-animal variance.
The B-SOiD analysis that we show in Figure 6 is based on a model trained on 80% of the data from four sessions taken from the same mouse, and then tested on all of a single session from that mouse. Initial attempts to train across sessions from different mice were unsuccessful, probably due to differences in behavioral repertoires across mice. However, we have performed extensive tests with B-SOiD and are confident that these sorts of results are reproducible across mice, although we are not prepared to publish these results at this time.
We now clarify these points in the main text at ~line 865, pg 27.
An additional comparison of the results of B-SOiD trained on different numbers of sessions to that of keypoint-MOSEQ (Weinreb et al, 2023, bioRxiv) trained on ~20 sessions can now be found as supplementary material on our GitHub site:
https://github.com/vickerse1/mesoscope_spontaneous/blob/main/Figure_SZZ_BSOID_MOSEQ_align.pdf
The discrepancy between the maps in Figures 5e and 6e might indicate that a significant portion of the map represents noise. An analysis of variability across mice and a method to assign significance to these maps would be beneficial.
Authors’ Response: After re-examination of the original analysis output files, we have indeed discovered that some of the Rastermap neuron density maps in Figure 6e were incorrectly aligned with their respective qualitative behaviors due to a discrepancy in file numbering between the images in 6e and the ensembles identified in 6c (each time that Rastermap is run on the same data, at least with the older version available at the time of creation of these figures, the order of the ensembles on the y-axis changes and thus the numbering of the ensembles would change even though the neuron identities within each group stayed the same for a given set of parameters).
This unfortunate panel alignment / graphical display error present in the original reviewed preprint has been fixed in the current, updated figure (i.e. twitch corresponds to Rastermap groups 2 and 3, whisk to group 6, walk to groups 5 and 4, and oscillate to groups 0 and 1), and in the main text at ~line 925, pg 29. We have also changed the figure legend, which also contained accurate but misaligned information, for Figure 6e to reflect this correction.
One can now see that, because the data from both figures is from the same session in the same mouse, as you correctly point out, Fig 5d left (walk and whisk) corresponds roughly to Fig 6e group R7, “walk”, and that Fig 5d right (whisk) corresponds roughly to Fig 6e group R4, “twitch”.
We have double-checked the identity of other CCF map displays of Rastermap neuron density and of mean correlations between neural activity and behavioral primitives in all other figures, and we found no other such alignment or mis-labeling errors.
We have also added a caveat in the main text at ~lines 925-940, pg. 30, pointing out the preliminary nature of these findings, which are shown here as an example of the viability of the methods. Analysis of the variability of Rastermap alignments across sessions is beyond the scope of the current paper, although it is an issue that we hope to address in upcoming analysis papers.
-Analysis details:
More comprehensive details on the analysis would be beneficial for replicability and deeper understanding. For instance, the statement "Rigid and non-rigid motion correction were performed in Suite2p" could be expanded with a brief explanation of the underlying principles, such as phase correlation, to provide readers with a better grasp of the methodologies employed.
Authors’ Response: We added a brief explanation of Suite2p motion correction at ~line 136, pg 4. We have also added additional details concerning CCF / MMM alignment and other analysis issues. In general we cite other papers where possible to avoid repeating details of analysis methods that are already published.
Reviewer #2 (Public Review):
Summary:
The authors present a comprehensive technical overview of the challenging acquisition of large-scale cortical activity, including surgical procedures and custom 3D-printed headbar designs to obtain neural activity from large parts of the dorsal or lateral neocortex. They then describe technical adjustments for stable head fixation, light shielding, and noise insulation in a 2-photon mesoscope and provide a workflow for multisensory mapping and alignment of the obtained large-scale neural data sets in the Allen CCF framework. Lastly, they show different analytical approaches to relate single-cell activity from various cortical areas to spontaneous activity by using visualization and clustering tools, such as Rastermap, PCA-based cell sorting, and B-SOID behavioral motif detection.
Authors’ Response: Thank you for this excellent summary of the scope of our paper.
The study contains a lot of useful technical information that should be of interest to the field. It tackles a timely problem that an increasing number of labs will be facing as recent technical advances allow the activity measurement of an increasing number of neurons across multiple areas in awake mice. Since the acquisition of cortical data with a large field of view in awake animals poses unique experimental challenges, the provided information could be very helpful to promote standard workflows for data acquisition and analysis and push the field forward.
Authors’ Response: We very much support the idea that our work here will contribute to the development of standard workflows across the field including those for multiple approaches to large-scale neural recordings.
Strengths:
The proposed methodology is technically sound and the authors provide convincing data to suggest that they successfully solved various problems, such as motion artifacts or high-frequency noise emissions, during 2-photon imaging. Overall, the authors achieved their goal of demonstrating a comprehensive approach for the imaging of neural data across many cortical areas and providing several examples that demonstrate the validity of their methods and recapitulate and further extend some recent findings in the field.
Weaknesses:
Most of the descriptions are quite focused on a specific acquisition system, the Thorlabs Mesoscope, and the manuscript is in part highly technical making it harder to understand the motivation and reasoning behind some of the proposed implementations. A revised version would benefit from a more general description of common problems and the thought process behind the proposed solutions to broaden the impact of the work and make it more accessible for labs that do not have access to a Thorlabs mesoscope. A better introduction of some of the specific issues would also promote the development of other solutions in labs that are just starting to use similar tools.
Authors’ Response: We have edited the motivations behind the study to clarify the general problems that are being addressed. However, as the 2-photon imaging component of these experiments were performed on a Thorlabs mesoscope, the imaging details necessarily deal specifically with this system.
We briefly compare the methods and results from our Thorlabs system to that of Diesel-2p, another comparable system, based on what we have been able to glean from the literature on its strengths and weaknesses. See ~lines 206-213, pg 6.
Reviewer #3 (Public Review):
Summary
In their manuscript, Vickers and McCormick have demonstrated the potential of leveraging mesoscale two-photon calcium imaging data to unravel complex behavioural motifs in mice. Particularly commendable is their dedication to providing detailed surgical preparations and corresponding design files, a contribution that will greatly benefit the broader neuroscience community as a whole. The quality of the data is high, but it is not clear whether this is available to the community, some datasets should be deposited. More importantly, the authors have acquired activity-clustered neural ensembles at an unprecedented spatial scale to further correlate with high-level behaviour motifs identified by B-SOiD. Such an advancement marks a significant contribution to the field. While the manuscript is comprehensive and the analytical strategy proposed is promising, some technical aspects warrant further clarification. Overall, the authors have presented an invaluable and innovative approach, effectively laying a solid foundation for future research in correlating large-scale neural ensembles with behaviour. The implementation of a custom sound insulator for the scanner is a great idea and should be something implemented by others.
Authors’ Response: Thank you for the kind words.
We have made ~500 GB of raw data and preliminary analysis files publicly available on FigShare+ for the example sessions shown in Figures 2, 3, 4, 5, 6, S3, and S6. We ask to be cited and given due credit for any fair use of this data.
The data is located here: https://doi.org/10.25452/figshare.plus.c.7052513
We intend to release a complete data set to the public as a Dandiset on the DANDI archive in conjunction with in-depth analysis papers that are currently in preparation.
This is a methods paper, but there is no large diagram that shows how all the parts are connected, communicating, and triggering each other. This is described in the methods, but a visual representation would greatly benefit the readers looking to implement something similar.
Authors’ Response: This is an excellent suggestion. We have included a workflow diagram in the revised manuscript, in the form of a 3-part figure, for the methods (a), data collection (b and c), and analysis (d). This supplementary figure is now located on the GitHub page at the following link:
https://github.com/vickerse1/mesoscope_spontaneous/blob/main/pancortical_workflow_diagrams.pdf
We now reference this figure on ~lines 190-192, pg 6 of the main text, near the beginning of the Results section.
The authors should cite sources for the claims stated in lines 449-453 and cite the claim of the mouse's hearing threshold mentioned in lines 463.
Authors’ Response: For the claim stated in lines 449-453:
“The unattenuated or native high-frequency background noise generated by the resonant scanner causes stress to both mice and experimenters, and can prevent mice from achieving maximum performance in auditory mapping, spontaneous activity sessions, auditory stimulus detection, and auditory discrimination sessions/tasks”
,we can provide the following references: (i) for mice: Sadananda et al, 2008 (“Playback of 22-kHz and 50-kHz ultrasonic vocalizations induces differential c-fos expression in rat brain”, Neuroscience Letters, Vol 435, Issue 1, p 17-23), and (ii) for humans: Fletcher et al, 2018 (“Effects of very high-frequency sound and ultrasound on humans. Part I: Adverse symptoms after exposure to audible very-high frequency sound”, J Acoust Soc A, 144, 2511-2520). We will include these references in the revised paper.
For the claim stated on line 463:
“i.e. below the mouse hearing threshold at 12.5 kHz of roughly 15 dB”
,we can provide the following reference: Zheng et al, 1999 (“Assessment of hearing in 80 inbred strains of mice by ABR threshold analyses”, Vol 130, Issues 1-2, p 94-107).
We have included these two new references in the new, revised version of our paper. Thank you for identifying these citation omissions.
No stats for the results shown in Figure 6e, it would be useful to know which of these neural densities for all areas show a clear statistical significance across all the behaviors.
Authors’ Response: It would be useful if we could provide a statistic similar to what we provide for Fig. S6c and f, in which for each CCF area we compare the observed mean correlation values to a null of 0, or, in this case, the population densities of each Rastermap group within each CCF area to a null value equal to the total number of CCF areas divided by the total number of recorded neurons for that group (i.e. a Rastermap group with 500 neurons evenly distributed across ~30 CCF areas would contain ~17 neurons, or ~3.3% density, per CCF area.) Our current figure legend states the maximums of the scale bar look-up values (reds) for each group, which range from ~8% to 32%.
However, because the data in panel 6e are from a single session and are being provided as an example of our methods and not for the purpose of claiming a specific result at this point, we choose not to report statistics. It is worth pointing out, perhaps, that Rastermap group densities for a given CCF area close to 3.3% are likely not different from chance, and those closer to ~40%, which is our highest density (for area M2 in Rastermap group 7, which corresponds to the qualitative behavior “walk”), are most likely not due to chance. Without analysis of multiple sessions from the same mouse we believe that making a clear statement of significance for this likelihood would be premature.
We now clarify this decision and related considerations in the main text at ~line 920, pg 29.
While I understand that this is a methods paper, it seems like the authors are aware of the literature surrounding large neuronal recordings during mouse behavior. Indeed, in lines 178-179, the authors mention how a significant portion of the variance in neural activity can be attributed to changes in "arousal or self-directed movement even during spontaneous behavior." Why then did the authors not make an attempt at a simple linear model that tries to predict the activity of their many thousands of neurons by employing the multitude of regressors at their disposal (pupil, saccades, stimuli, movements, facial changes, etc). These models are straightforward to implement, and indeed it would benefit this work if the model extracts information on par with what is known from the literature.
Authors’ Response: This is an excellent suggestion, but beyond the scope of the current methods paper. We are following up with an in depth analysis of neural activity and corresponding behavior across the cortex during spontaneous and trained behaviors, but this analysis goes well beyond the scope of the present manuscript.
Here, we prefer to present examples of the types of results that can be expected to be obtained using our methods, and how these results compare with those obtained by others in the field.
Specific strengths and weaknesses with areas to improve:
The paper should include an overall cartoon diagram that indicates how the various modules are linked together for the sampling of both behaviour and mesoscale GCAMP. This is a methods paper, but there is no large diagram that shows how all the parts are connected, communicating, and triggering each other.
Authors’ Response: This is an excellent suggestion. We have included a workflow diagram in the revised manuscript, in the form of a 3-part figure, for the methods (a), data collection (b and c), and analysis (c). This supplementary figure is now located on the GitHub page at the following link:
https://github.com/vickerse1/mesoscope_spontaneous/blob/main/pancortical_workflow_diagrams.pdf
The paper contains many important results regarding correlations between behaviour and activity motifs on both the cellular and regional scales. There is a lot of data and it is difficult to draw out new concepts. It might be useful for readers to have an overall figure discussing various results and how they are linked to pupil movement and brain activity. A simple linear model that tries to predict the activity of their many thousands of neurons by employing the multitude of regressors at their disposal (pupil, saccades, stimuli, movements, facial changes, etc) may help in this regard.
Authors’ Response: This is an excellent suggestion, but beyond the scope of the present methods paper. Such an analysis is a significant undertaking with such large and heterogeneous datasets, and we provide proof-of-principle data here so that the reader can understand the type of data that one can expect to obtain using our methods. We will provide a more complete analysis of data obtained using our methodology in the near future in another manuscript.
Previously, widefield imaging methods have been employed to describe regional activity motifs that correlate with known intracortical projections. Within the authors' data it would be interesting to perhaps describe how these two different methods are interrelated -they do collect both datasets. Surprisingly, such macroscale patterns are not immediately obvious from the authors' data. Some of this may be related to the scaling of correlation patterns or other factors. Perhaps there still isn't enough data to readily see these and it is too sparse.
Authors’ Response: Unfortunately, we are unable to directly compare 1-photon widefield GCaMP6s activity with mesoscope 2-photon GCaMP6s activity. During widefield data acquisition, animals were stimulated with visual, auditory, or somatosensory stimuli (i.e. “passive sensory stimulation”), while 2-photon mesoscope data collection occurred during spontaneous changes in behavioral state, without sensory stimulation. The suggested comparison is, indeed, an interesting project for the future.
In lines 71-71, the authors described some disadvantages of one-photon widefield imaging including the inability to achieve single-cell resolution. However, this is not true. In recent years, the combination of better surgical preparations, camera sensors, and genetically encoded calcium indicators has enabled the acquisition of single-cell data even using one-photon widefield imaging methods. These methods include miniscopes (Cai et al., 2016), multi-camera arrays (Hope et al., 2023), and spinning disks (Xie et al., 2023).
Cai, Denise J., et al. "A shared neural ensemble links distinct contextual memories encoded close in time." Nature 534.7605 (2016): 115-118.
Hope, James, et al. "Brain-wide neural recordings in mice navigating physical spaces enabled by a cranial exoskeleton." bioRxiv (2023).
Xie, Hao, et al. "Multifocal fluorescence video-rate imaging of centimetre-wide arbitrarily shaped brain surfaces at micrometric resolution." Nature Biomedical Engineering (2023): 1-14.
Authors’ Response: We have corrected these statements and incorporated these and other relevant references. There are advantages and disadvantages to each chosen technique, such as ease of use, field of view, accuracy, and speed. We will reference the papers you mention without an extensive literature review, but we would like to emphasize the following points:
Even the best one-photon imaging techniques typically have ~10-20 micrometer resolution in xy (we image at 5 micrometer resolution for our large FOV configuration, but the xy point-spread function for the Thorlabs mesoscope is 0.61 x 0.61 micrometers in xy with 970 nm excitation) and undefined z-resolution (4.25 micrometers for Thorlabs mesoscope). A coarser resolution increases the likelihood that activity related fluorescence from neighboring cells may contaminate the fluorescence observed from imaged neurons. Reducing the FOV and using sparse expression of the indicator lessens this overlap problem.
We do appreciate these recent advances, however, particularly for use in cases where more rapid imaging is desired over a large field of view (CCD acquisition can be much faster than that of standard 2-photon galvo-galvo or even galvo-resonant scanning, as the Thorlabs mesoscope uses). This being said, there are few currently available genetically encoded Ca2+ sensors that are able to measure fluctuations faster than ~10 Hz, which is a speed achievable on the Thorlabs 2-photon mesoscope with our techniques using the “small, multiple FOV” method (Fig. S2d, e).
We have further clarified our discussion of these issues in the main text at ~lines 76-80, pg 2.
The authors' claim of achieving optical clarity for up to 150 days post-surgery with their modified crystal skull approach is significantly longer than the 8 weeks (approximately 56 days) reported in the original study by Kim et al. (2016). Since surgical preparations are an integral part of the manuscript, it may be helpful to provide more details to address the feasibility and reliability of the preparation in chronic studies. A series of images documenting the progression optical quality of the window would offer valuable insight.
Authors’ Response: As you suggest, we now include brief supplementary material demonstrating the changes in the window preparation that we observed over the prolonged time periods of our study, for both the dorsal and side mount preparations. The following link to this material is now referenced at ~line 287, pg 9, and at the end of Fig S1:
https://github.com/vickerse1/mesoscope_spontaneous/blob/main/window_preparation_stability.pdf
We have also included brief additional details in the main text that we found were useful for facilitating long term use of these preparations. These are located at ~line 287-290, pg 9.
Recommendations for the authors:
Reviewer #1 (Recommendations For The Authors):
(1) Sharing raw data and code:
I strongly encourage sharing some of the raw data from your experiments and all the code used for data analysis (e.g. in a github repository). This would help the reader evaluate data quality, and reproduce your results.
Authors’ Response: We have made ~500 GB of raw data and preliminary analysis files publicly available on FigShare+ for the example sessions shown in Figures 2, 3, 4, 5, 6, S3, and S6. We ask to be cited and given due credit for any fair use of this data.
We intend to release a complete data set to the public as a Dandiset on the DANDI archive in conjunction with second and third in-depth analysis papers that are currently in preparation.
The data is located here: https://doi.org/10.25452/figshare.plus.c.7052513
We intend to release a complete data set to the public as a Dandiset on the DANDI archive in conjunction with second and third in-depth analysis papers that are currently in preparation.
Our existing GitHub repository, already referenced in the paper, is located here:
https://github.com/vickerse1/mesoscope_spontaneous
We have added an additional reference in the main text to the existence of these publicly available resources, including the appropriate links, located at ~lines 190-200, pg 6.
(2) Use of proprietary software:
The reliance on proprietary tools like LabView and Matlab could be a limitation for some researchers, given the associated costs and accessibility issues. If possible, consider incorporating or suggesting alternatives that are open-source, to make your methodology more accessible to a broader range of researchers, including those with limited resources.
Authors’ Response: We are reluctant to recommend open source software that we have not thoroughly tested ourselves. However, we will mention, when appropriate, possible options for the reader to consider.
Although LabView is proprietary and can be difficult to code, it is particularly useful when used in combination with National Instruments hardware. ScanImage in use with the Thorlabs mesoscope uses National Instruments hardware, and it is convenient to maintain hardware standards across the integrated rig/experimental system. Labview is also useful because it comes with a huge library of device drivers that makes addition of new hardware from basically any source very convenient.
That being said, there are open source alternatives that could conceivably be used to replace parts of our system. One example is AutoPilot (author: Jonny Saunders), for control of behavioral data acquisition: https://open-neuroscience.com/post/autopilot/.
We are not aware of an alternative to Matlab for control of ScanImage, which is the supported control software for the ThorLabs 2-photon mesoscope.
Most of our processing and analysis code (see GitHub page: https://github.com/vickerse1/mesoscope_spontaneous) is in Python, but some of the code that we currently use remains in Matlab form. Certainly, this could be re-written as Python code. However, we feel like this is outside the scope of the current paper. We have provided commenting to all code in an attempt to aid users in translating it to other languages, if they so desire.
(3) Quantifying the effect of tilted head:
To address the potential impact of tilting the mouse's head on your findings, a quantitative analysis of any systematic differences in the behavior (e.g. Bsoid motifs) could be illuminating.
Authors’ Response: We have performed DeepLabCut analysis of all sessions from both preparations, across several iterations with different parameters, to extract pose estimates, and we have also performed BSOiD of these sessions. We did not find any obvious qualitative differences in the number of behavioral motifs identified, the dwell times of these motifs, and similar issues, relating to the issue of tilting of the mouse’s head in the side mount preparation. We also did not find any obvious differences in the relative frequencies of high level qualitative behaviors, such as the ones referred to in Fig. 6, between the two preparations.
Our mice readily adapted to the 22.5 degree head tilt and learned to perform 2-alternative forced choice (2-AFC) auditory and visual tasks in this configuration (Hulsey et al, 2024; Cell Reports). The advantages and limitations of such a rotation of the mouse, and possible ways to alleviate these limitations, as detailed in the following paragraphs, are now discussed more thoroughly in the revised manuscript. (See ~line 235, pg. 7)
One can look at Supplementary Movie 1 for examples of the relatively similar behavior between the dorsal mount (not rotated) and side mount (rotated) preparations. We do not have behavioral data from mice that were placed in both configurations. Our preliminary comparisons across mice indicates that side and dorsal mount mice show similar behavioral variability. We have added brief additional mention of these considerations on ~lines 235-250, pg 7.
It was in general important to make sure that the distance between the wheel and all four limbs was similar for both preparations. In particular, careful attention must be paid to the positioning of the front limbs in the side mount mice so that they are not too high off the wheel. This can be accomplished by a slight forward angling of the left support arm for side mount mice.
Although it would in principle be nearly possible to image the side mount preparation in the same optical configuration that we do without rotating the mouse, by rotating the objective 20 degrees to the right of vertical, we found that the last 2-3 degrees of missing rotation (our preparation is rotated 22.5 degrees left, which is more than the full available 20 degrees rotation of the Thorlabs mesoscope objective), along with several other factors, made this undesirable. First, it was very difficult to image auditory areas without the additional flexibility to rotate the objective more laterally. Second, it was difficult or impossible to attach the horizontal light shield and to establish a water meniscus with the objective fully rotated. One could use gel instead (which we found to be optically inferior to water), but without the horizontal light shield, the UV and IR LEDs can reach the PMTs via the objective and contaminate the image or cause tripping of the PMT. Third, imaging the right pupil and face of the mouse is difficult to impossible under these conditions because the camera would need the same optical access angle as the objective, or would need to be moved down toward the air table and rotated up 20 degrees, in which case its view would be blocked by the running wheel and other objects mounted on the air table.
(4) Clarification in the discussion section:
The paragraph titled "Advantages and disadvantages of our approach" seems to diverge into discussing future directions, rather than focusing on the intended topic. I suggest revisiting this section to ensure that it accurately reflects the strengths and limitations of your approach.
Authors’ Response: We agree with the reviewer that this section included several potential next steps or solutions for each advantage and disadvantage, which the reviewer refers to as “future directions” and are thus arguably beyond the scope of this section. Therefore we have retitled this section as, “Advantages and disadvantages of our approach (with potential solutions):”.
Although we believe this to be a logical organization, and we already include a section focused purely on future directions in the Discussion section, we have refocused each paragraph of the advantages/disadvantages subsection to concentrate on the advantages and disadvantages per se. In addition, we have made minor changes to the “future directions” section to make it more succinct and practical. These changes can be found at lines ~1016-1077, pg 33-34.
Reviewer #2 (Recommendations For The Authors):
Below are some more detailed points that will hopefully help to further improve the quality and scope of the manuscript.
- While it is certainly favorable for many questions to measure large-scale activity from many brain regions, the introduction appears to suggest that this is a prerequisite to understanding multimodal decision-making. This is based on the argument that combining multiple recordings with movement indicators will 'necessarily obscure the true spatial correlation structures'. However, I don't understand why this is the case or what is meant by 'true spatial correlation structures'. Aren't there many earlier studies that provided important insights from individual cortical areas? It would be helpful to improve the writing to make this argument clearer.
Authors’ Response: The reviewer makes an excellent point and we have re-worded the manuscript appropriately, to reflect the following clarifications. These changes can be found at ~lines 58-71, pg. 2.
We believe you are referring to the following passage from the introduction:
“Furthermore, the arousal dependence of membrane potential across cortical areas has been shown to be diverse and predictable by a temporally filtered readout of pupil diameter and walking speed (Shimoaka et al, 2018). This makes simultaneous recording of multiple cortical areas essential for comparison of the dependence of their neural activity on arousal/movement, because combining multiple recording sessions with pupil dilations and walking bouts of different durations will necessarily obscure the true spatial correlation structures.”
Here, we do not mean to imply that earlier studies of individual cortical areas are of no value. This argument is provided as an example, of which there are others, of the idea that, for sequences or distributed encoding schemes that simultaneously span many cortical areas that are too far apart to be simultaneously imaged under conventional 2-photon imaging, or are too sparse to be discovered with 1-photon widefield imaging, there are some advantages of our new methods over conventional imaging methods that will allow for truly novel scientific analyses and insights.
The general idea of the present example, based on the findings of Shimoaka et al, 2018, is that it is not possible to directly combine and/or compare the correlations between behavior and neural activity across regions that were imaged in separate sessions, because the correlations between behavior and neural activity in each region appear to depend on the exact time since the behavior began (Shimoaka et al, 2018), in a manner that differs across regions. So, for example, if one were to record from visual cortex in one session with mostly brief walk bouts, and then from somatosensory cortex in a second session with mostly long walk bouts, any inferred difference between the encoding of walk speed in neural activity between the two areas would run the risk of being contaminated by the “temporal filtering” effect shown in Shimoaka et al, 2018. However, this would not be the case in our recordings, because the distribution of behavior durations corresponding to our recorded neural activity across areas will be exactly the same, because they were recorded simultaneously.
- The text describes different timescales of neural activity but is an imaging rate of 3 Hz fast enough to be seen as operating at the temporal dynamics of the behavior? It appears to me that the sampling rate will impose a hard limit on the speed of correlations that can be observed across regions. While this might be appropriate for relatively slow behaviors and spontaneous fluctuations in arousal, sensory processing and decision formation likely operate on faster time scales below 100ms which would even be problematic at 10 Hz which is proposed as the ideal imaging speed in the manuscript.
Authors’ Response: Imaging rate is always a concern and the limitations of this have been discussed in other manuscripts. We will remind the reader of these limitations, which must always be kept in mind when interpreting fluorescence based neural activity data.
Previous studies imaging on a comparable yet more limited spatial scale (Stringer et al, 2019) used an imaging speed of ~1 Hz. With this in view, our work represents an advance both in spatial extent of imaged cortex and in imaging speed. Specifically, we believe that ~1 Hz imaging may be sufficient to capture flip/flop type transitions between low and high arousal states that persist in general for seconds to tens of seconds, and that ~3-5 Hz imaging likely provides additional information about encoding of spontaneous movements and behavioral syllables/motifs.
Indeed, even 10 Hz imaging would not be fast enough to capture the detailed dynamics of sensory processing and decision formation, although these speeds are likely sufficient to capture “stable” encodings of sensory representations and decisions that must be maintained during a task, for example with delayed match-to-sample tasks.
In general we are further developing our preparations to allow us to perform simultaneous widefield imaging and Neuropixels recordings, and to perform simultaneous 1.2 x 1.2 mm 2-photon imaging and visually guided patch clamp recordings.
Both of these techniques will allow us to combine information across both the slow and fast timescales that you refer to in your question.
We have clarified these points in the Introduction and Discussion sections, at ~lines ~93-105, pg 3, and ~lines 979-983, pg 31 and ~lines 1039-1045, pg 33, respectively.
- The dorsal mount is very close to the crystal skull paper and it was ultimately not clear to me if there are still important differences aside from the headbar design that a reader should be aware of. If they exist, it would be helpful to make these distinctions a bit clearer. Also, the sea shell implants from Ghanbari et al in 2019 would be an important additional reference here.
Authors’ Response: We have added brief references to these issues in our revised manuscript at ~lines 89-97, pg 3:
Although our dorsal mount preparation is based on the “crystal skull paper” (Kim et al, 2016), which we reference, the addition of a novel 3-D printable titanium headpost, support arms, light shields, and modifications to the surgical protocols and CCF alignment represent significant advances that made this preparation useable for pan-cortical imaging using the Thorlabs mesoscope. In fact, we were in direct communication with Cris Niell, a UO professor and co-author on the original Kim et al, 2016 paper, during the initial development of our preparation, and he and members of his lab consulted with us in an ongoing manner to learn from our successful headpost and other hardware developments. Furthermore, all of our innovations for data acquisition, imaging, and analysis apply equally to both our dorsal mount and side mount preparations.
Thank you for mentioning the Ghanbari et al, 2019 paper on the transparent polymer skull method, “See Shells.” We were in fact not aware of this study. However, it should be noted that their preparation seems to, like the crystal skull preparation and our dorsal mount preparation, be limited to bilateral dorsal cortex and not to include, as does our cranial window side mount preparation and the through-the-skull widefield preparation of Esmaeili et al, 2021, a fuller range of lateral cortical areas, including primary auditory cortex.
- When using the lateral mount, rotating the objective, rather than the animal, appears to be preferable to reduce the stress on the animal. I also worry that the rather severe head tilt could be an issue when training animals in more complex behaviors and would introduce an asymmetry between the hemispheres due to the tilted body position. Is there a strong reason why the authors used water instead of an imaging gel to resolve the issue with the meniscus?
Authors’ Response: Our mice readily adapted to the 22.5 degree head tilt and learned to perform 2-alternative forced choice (2-AFC) auditory and visual tasks in this situation (Hulsey et al, 2024; Cell Reports). The advantages and limitations of such a rotation of the mouse, and possible ways to alleviate these limitations, as detailed in the following paragraphs, are now discussed more thoroughly in the revised manuscript. (See ~line 235, pg. 7)
One can look at Supplementary Movie 1 for examples of the relatively similar behavior between the dorsal mount (not rotated) and side mount (rotated) preparations. We do not have behavioral data from mice that were placed in both configurations. Our preliminary comparisons across mice indicates that side and dorsal mount mice show similar behavioral variability. We have added brief additional mention of these considerations on ~lines 235-250, pg 7.
It was in general important to make sure that the distance between the wheel and all four limbs was similar for both preparations. In particular, careful attention must be paid to the positioning of the front limbs in the side mount mice so that they are not too high off the wheel. This can be accomplished by a slight forward angling of the left support arm for side mount mice.
Although it would in principle be nearly possible to image the side mount preparation in the same optical configuration that we do without rotating the mouse, by rotating the objective 20 degrees to the right of vertical, we found that the last 2-3 degrees of missing rotation (our preparation is rotated 22.5 degrees left, which is more than the full available 20 degrees rotation of the objective), along with several other factors, made this undesirable. First, it was very difficult to image auditory areas without the additional flexibility to rotate the objective more laterally. Second, it was difficult or impossible to attach the horizontal light shield and to establish a water meniscus with the objective fully rotated. One could use gel instead (which we found to be optically inferior to water), but without the horizontal light shield, the UV and IR LEDs can reach the PMTs via the objective and contaminate the image or cause tripping of the PMT. Third, imaging the right pupil and face of the mouse is difficult to impossible under these conditions because the camera would need the same optical access angle as the objective, or would need to be moved down toward the air table and rotated up 20 degrees, in which case its view would be blocked by the running wheel and other objects mounted on the air table.
- In parts, the description of the methods is very specific to the Thorlabs mesoscope which makes it harder to understand the general design choices and challenges for readers that are unfamiliar with that system. Since the Mesoscope is very expensive and therefore unavailable to many labs in the field, I think it would increase the reach of the manuscript to adjust the writing to be less specific for that system but instead provide general guidance that could also be helpful for other systems. For example (but not exclusively) lines 231-234 or lines 371 and below are very Thorlabs-specific.
Authors’ Response: We have revised the manuscript so that it is more generally applicable to mesoscopic methods.
We will make revisions as you suggest where possible, although we have limited experience with the other imaging systems that we believe you are referring to. However, please note that we already mentioned at least one other comparable system in the original eLife reviewed pre-print (Diesel 2p, line 209; Yu and Smith, 2021).
Here are a couple of examples of how we have broadened our description:
(1) On lines ~231-234, pg 7, we write:
“However, if needed, the objective of the Thorlabs mesoscope may be rotated laterally up to +20 degrees for direct access to more ventral cortical areas, for example if one wants to use a smaller, flat cortical window that requires the objective to be positioned orthogonally to the target region.”
Here have modified this to indicate that one may in general rotate their objective lens if their system allows it. Some systems, such as the Thorlabs Bergamo microscope and the Sutter MOM system, allow more than 20 degrees of rotation.
(2) On line ~371, pg 11, we write:
“This technique required several modifications of the auxiliary light-paths of the Thorlabs mesoscope”
Here, we have changed the writing to be more general such as “may require…of one’s microscope.”
Thank you for these valuable suggestions.
- Lines 287-299: Could the authors quantify the variation in imaging depth, for example by quantifying to which extent the imaging depth has to be adjusted to obtain the position of the cortical surface across cortical areas? Given that curvature is a significant challenge in this preparation this would be useful information and could either show that this issue is largely resolved or to what extent it might still be a concern for the interpretation of the obtained results. How large were the required nominal corrections across imaging sites?
Authors’ Response: This information was provided previously (lines 297-299):
“In cases where we imaged multiple small ROIs, nominal imaging depth was adjusted in an attempt to maintain a constant relative cortical layer depth (i.e. depth below the pial surface; ~200 micrometer offset due to brain curvature over 2.5 mm of mediolateral distance, symmetric across the center axis of the window).”
This statement is based on a qualitative assessment of cortical depth based on neuron size and shape, the density of neurons in a given volume of cortex, the size and shape of blood vessels, and known cortical layer depths across regions. A ground-truth measurement of this depth error is beyond the scope of the present study. However, we do specify the type of glass, thickness, and curvature that we use, and the field curvature characterization of the Thorlabs mesoscope is given in Fig. 6 of the Sofroniew et al, 2016 eLife paper.
In addition, we have provided some documentation of online fast-z correction parameters on our GitHub page at:
https://github.com/vickerse1/mesoscope_spontaneous/tree/main/online_fast_z_correction
,and some additional relevant documentation can be found in our publicly available data repository on FigShare+ at: https://doi.org/10.25452/figshare.plus.c.7052513
- Given the size of the implant and the subsequent work attachments, I wonder to which extent the field of view of the animal is obstructed. Did the authors perform receptive field mapping or some other technique that can estimate the size of the animals' remaining field of view?
Authors’ Response: The left eye is pointed down ~22.5 degrees, but we position the mouse near the left edge of the wheel to minimize the degree to which this limits their field of view. One may view our Fig. 1 and Suppl Movies 1 and 6 to see that the eyes on the left and right sides are unobstructed by the headpost, light shields, and support arms. However, other components of the experimental setup, such as the speaker, cameras, etc. can restrict a few small portions of the visual field, depending on their exact positioning.
The facts that mice responded to left side visual stimuli in preliminary recordings during our multimodal 2-AFC task, and that the unobstructed left and right camera views, along with pupillometry recordings, showed that a significant portion of the mouse’s field of view, from either side, remains intact in our preparation.
We have clarified these points in the text at ~lines 344-346, pg. 11.
- Line 361: What does movie S7 show in this context? The movie seems to emphasize that the observed calcium dynamics are not driven by movement dynamics but it is not clear to me how this relates to the stimulation of PV neurons. The neural dynamics in the example cell are also not very clear. It would be helpful if this paragraph would contain some introduction/motivation for the optogenetic stimulation as it comes a bit out of the blue.
Authors’ Response: This result was presented for two reasons.
First, we showed it as a control for movement artifacts, since inhibition of neural activity enhances the relative prominence of non-activity dependent fluorescence that is used to examine the amplitude of movement-related changes in non-activity dependent fluorescence (e.g. movement artifacts). We have included a reference to this point at ~lines 587-588, pg 18.
Second, we showed it as a demonstration of how one may combine optogenetics with imaging in mesoscopic 2-P imaging. References to this point were already present in the original version of the manuscript (the eLife “ reviewed preprint”).
- Lines 362-370: This paragraph and some of the following text are quite technical and would benefit from a better description and motivation of the general workflow. I have trouble following what exactly is done here. Are the authors using an online method to identify the CCF location of the 2p imaging based on the vessel pattern? Why is it important to do this during the experiment? Wouldn't it be sufficient to identify the areas of interest based on the vessel pattern beforehand and then adjust the 2p acquisition accordingly? Why are they using a dial, shutter, and foot pedal and how does this relate to the working distance of the objective? Does the 'standardized cortical map' refer to the Allen common coordinate framework?
Authors’ Response: We have revised this section to make it more clear.
Currently, the general introduction to this section appears in lines 349-361. Starting in line 362, we currently present the technical considerations needed to implement the overall goals stated in that first paragraph of this section.
In general we use a post-hoc analysis step to confirm the location of neurons recorded with 2-photon imaging. We use “online” juxtaposition of the multimodal map image with overlaid CCF with the 2-photon image by opening these two images next to each other on the ScanImage computer and matching the vasculature patterns “by eye”. We have made this more clear in the text so that the interested reader can more readily implement our methods.
By use of the phrase “standardized cortical map” in this context, we meant to point out that we had not decided a priori to use the Allen CCF v3.0 when we started working on these issues.
- Does Fig. 2c show an example of the online alignment between widefield and 2p data? I was confused here since the use of suite2p suggests that this was done post-recording. I generally didn't understand why the user needed to switch back and forth between the two modes. Doesn't the 2p image show the vessels already? Also, why was an additional motorized dichroic to switch between widefield and 2p view needed? Isn't this the standard in most microscopes (including the Thorlabs scopes)?
Authors’ Response: We have explained this methodology more clearly in the revised manuscript, both at ~lines 485-500, pg 15-16, and ~lines 534-540, pg 17.
The motorized dichroic we used replaced the motorized mirror that comes with the Thorlabs mesoscope. We switched to a dichroic to allow for near-simultaneous optogenetic stimulation with 470 nm blue light and 2-photon imaging, so that we would not have to move the mirror back and forth during live data acquisition (it takes a few seconds and makes an audible noise that we wanted to avoid).
Figure 2c shows an overview of our two step “offline” alignment process. The image at the right in the bottom row labeled “2” is a map of recorded neurons from suite2p, determined post-hoc or after imaging. In Fig. 2d we show what the CCF map looks like when it’s overlaid on the neurons from a single suite2p session, using our alignment techniques. Indeed, this image is created post-hoc and not during imaging. In practice, “online” during imaging, we would have the image at left in the bottom row of Fig. 2c (i.e. the multimodal map image overlaid onto an image of the vasculature also acquired on the widefield rig, with the 22.5 degree rotated CCF map aligned to it based on the location of sensory responses) rotated 90 degrees to the left and flipped over a horizontal mirror plane so that its alignment matches that of the “online” 2-photon acquisition image and is zoomed to the same scale factor. Then, we would navigate based on vasculature patterns “by-eye” to the desired CCF areas, and confirm our successful 2-photon targeting of predetermined regions with our post-hoc analysis.
- Why is the widefield imaging done through the skull under anesthesia? Would it not be easier to image through the final window when mice have recovered? Is the mapping needed for accurate window placement?
Authors’ Response: The headpost and window surgeries are done 3-7 days apart to increase success rate and modularize the workflow. Multimodal mapping by widefield imaging is done through the skull between these two surgeries for two major reasons. First, to make efficient use of the time between surgeries. Second, to allow us to compare the multimodal maps to skull landmarks, such as bregma and lambda, for improved alignment to the CCF.
Anesthesia was applied to prevent state changes and movements of the mouse, which can produce large, undesired effects on neural responses in primary sensory cortices in the context of these mapping experiments. We sometimes re-imaged multimodal maps on the widefield microscope through the window, roughly every 30-60 days or whenever/if significant changes in vasculature pattern became apparent.
We have clarified these points in the main text at ~lines 510-522, pg 20-21, and we added a link to our new supplementary material documenting the changes observed in the window preparation over time:
https://github.com/vickerse1/mesoscope_spontaneous/blob/main/window_preparation_stability.pdf
Thank you for these questions.
- Lines 445 and below: Reducing the noise from resonant scanners is also very relevant for many other 2p experiments so it would be helpful to provide more general guidance on how to resolve this problem. Is the provided solution only applicable to the Thorlabs mesoscope? How hard would it be to adjust the authors' noise shield to other microscopes? I generally did not find many additional details on the Github repo and think readers would benefit from a more general explanation here.
Authors’ Response: Our revised Github repository has been modified to include more details, including both diagrams and text descriptions of the sound baffle, respectively:
However, we can not presently disclose our confidential provisional patent application. Complete design information will likely be available in early 2025 when our full utility patent application is filed.
With respect to your question, yes, this technique is adaptable to any resonant scanner, or, for that matter, any complicated 3D surface that emits sound. We first 3D scan the surface, and then we reverse engineer a solid that fully encapsulates the surface and can be easily assembled in parts with bolts and interior foam that allow for a tight fit, in order to nearly completely block all emitted sound.
It is this adaptability that has prompted us to apply for a full patent, as we believe this technique will be quite valuable as it may apply to a potentially large number of applications, starting with 2-photon resonant scanners but possibly moving on to other devices that emit unwanted sound.
- Does line 458 suggest that the authors had to perform a 3D scan of the components to create the noise reduction shield? If so, how was this done? I don't understand the connection between 3D scanning and printing that is mentioned in lines 464-466.
Authors’ Response: We do not want to release full details of the methodology until the full utility patent application has been submitted. However, we have now included a simplified text description of the process on our GitHub page and included a corresponding link in the main text:
We also clarified in the main text, at the location that you indicate, why the 3D scanning is a critical part of our novel 3D-design, printing, and assembly protocol.
- Lines 468 and below: Why is it important to align single-cell data to cortical areas 'directly on the 2-photon microscope'? Is this different from the alignment discussed in the paragraph above? Why not focus on data interpretation after data acquisition? I understand the need to align neural data to cortical areas in general, I'm just confused about the 'on the fly' aspect here and why it seems to be broken out into two separate paragraphs. It seems as if the text in line 485 and below could also be placed earlier in the text to improve clarity.
Authors’ Response: Here by “such mapping is not routinely possible directly on the 2-photon mesoscope” what we mean is that it is not possible to do multimodal mapping directly on the mesoscope - it needs to be done on the widefield imaging rig (a separate microscope). Then, the CCF is mapped onto the widefield multimodal map, which is overlaid on an image of the vasculature (and sometimes also the skull) that was also acquired on the widefield imaging rig, and the vasculature is used as a sort of Rosetta Stone to co-align the 2-photon image to the multimodal map and then, by a sort of commutative property of alignment, to the CCF, so that each individual neuron in the 2-photon image can be assigned a unique CCF area name and numerical identifier for subsequent analysis.
We have clarified this in the text, thank you.
The Python code for aligning the widefield and 2-photon vessel images would also be of great value for regular 2p users. It would strongly improve the impact of the paper if the repository were better documented and the code would be equally applicable for alignment of imaging data with smaller cranial windows.
Authors’ Response: All of the code for multimodal map, CCF, and 2-photon image alignment is, in fact, already present on the GitHub page. We have made some minor improvements to the documentation, and readers are more than welcome to contact us for additional help.
Specifically, the alignment you refer to starts in cell #32 of the meso_pre_proc_1.ipynb notebook. In general the notebooks are meant to be run sequentially, starting with cell #1 of meso_pre_proc_1, then going to the next cell etc…, then moving to meso_pre_proc_2, etc… The purpose of each cell is labeled at the top of the cell in a comment.
We now include a cleaned, abridged version of the meso_pre_proc_1.pynb notebook that contains only the steps needed for alignment, and included a direct link to this notebook in the main text:
Rotated CCF maps are in the CCF map rotation folder, in subfolders corresponding to the angle of rotation.
Multimodal map creation involves use of the SensoryMapping_Vickers_Jun2520.m script in the Matlab folder.
We updated the main text to clarify these points and included direct links to scripts relevant to each processing step.
- Figure 4a: I found it hard to see much of the structure in the Rastermap projection with the viridis colormap - perhaps also because of a red-green color vision impairment. Correspondingly, I had trouble seeing some of the structure that is described in the text or clearer differences between the neuron sortings to PC1 and PC2. Is the point of these panels to show that both PCs identify movement-aligned dynamics or is the argument that they isolate different movement-related response patterns? Using a grayscale colormap as used by Stringer et al might help to see more of the many fine details in the data.
Authors’ Response: In Fig. 4a the viridis color range is from blue to green to yellow, as indicated in the horizontal scale bar at bottom right. There is no red color in these Rastermap projections, or in any others in this paper. Furthermore, the expanded Rastermap insets in Figs. S4 and S5 provide additional detailed information that may not be clear in Fig 4a and Fig 5a.
We prefer, therefore, not to change these colormaps, which we use throughout the paper.
We have provided grayscale png versions of all figures on our GitHub page:
https://github.com/vickerse1/mesoscope_spontaneous/tree/main/grayscale_figures
In Fig 4a the point of showing both the PC1 and PC2 panels is to demonstrate that they appear to correspond to different aspects of movement (PC1 more to transient walking, both ON and OFF, and PC2 to whisking and sustained ON walk/whisk), and to exhibit differential ability to identify neurons with positive and negative correlations to arousal (PC1 finds both, both PC2 seems to find only the ON neurons).
We now clarify this in the text at ~lines 696-710, pg 22.
- I find panel 6a a bit too hard to read because the identification and interpretation of the different motifs in the different qualitative episodes is challenging. For example, the text mentions flickering into motif 13 during walk but the majority of that sequence appears to be shaped by what I believe to be motif 11. Motif 11 also occurs prominently in the oscillate state and the unnamed sequence on the left. Is this meaningful or is the emphasis here on times of change between behavioral motifs? The concept of motif flickering should be better explained here.
Authors’ Response: Here motif 13 corresponds to a syllable that might best be termed “symmetric and ready stance”. This tends to occur just before and after walking, but also during rhythmic wheel balancing movements that appear during the “oscillate” behavior.
The intent of Fig. 6a is to show that each qualitatively identified behavior (twitch, whisk, walk, and oscillate) corresponds to a period during which a subset of BSOiD motifs flicker back and forth, and that the identity of motifs in this subset differs across the identified qualitative behaviors. This is not to say that a particular motif occurs only during a single identified qualitative behavior. Admittedly, the identification of these qualitative behaviors is a bit arbitrary - future versions of BSOiD (e.g. ASOiD) in fact combine supervised (i.e. arbitrary, top down) and unsupervised (i.e. algorithmic, objective, bottom-up) methods of behavior segmentation in attempt to more reliably identify and label behaviors.
Flickering appears to be a property of motif transitions in raw BSOiD outputs that have not been temporally smoothed. If one watches the raw video, it seems that this may in fact be an accurate reflection of the manner in which behaviors unfold through time. Each behavior could be thought of, to use terminology from MOSEQ (B Datta), as a series of syllables strung together to make a phrase or sentence. Syllables can repeat over either fast or slow timescales, and may be shared across distinct words and sentences although the order and frequency of their recurrence will likely differ.
We have clarified these points in the main text at ~lines 917-923, pg 29, and we added motif 13 to the list of motifs for the qualitative behavior labeled “oscillate” in Fig. 6a.
- Lines 997-998: I don't understand this argument. Why does the existence of different temporal dynamics make imaging multiple areas 'one of the keys to potentially understanding the nature of their neuronal activity'?
Authors’ Response: We believe this may be an important point, that comparisons of neurobehavioral alignment across cortical areas cannot be performed by pooling sessions that contain different distributions of dwell times for different behaviors, if in fact that dependence of neural activity on behavior depends on the exact elapsed time since the beginning of the current behavioral “bout”. Again, other reasons that imaging many areas simultaneously would provide a unique advantage over imaging smaller areas one at a time and attempting to pool data across sessions would include the identification of sequences or neural ensembles that span many areas across large distances, or the understanding of distributed coding of behavior (an issue we explore in an upcoming paper).
We have clarified these points at the location in the Discussion that you have identified. Thank you for your questions and suggestions.
Minor
Line 41: What is the difference between decision, choice, and response periods?
Authors’ Response: This now reads “...temporal separation of periods during which cortical activity is dominated by activity related to stimulus representation, choice/decision, maintenance of choice, and response or implementation of that choice.”
Line 202: What does ambulatory mean in this context?
Authors’ Response: Here we mean that the mice are able to walk freely on the wheel. In fact they do not actually move through space, so we have changed this to read “able to walk freely on a wheel, as shown in Figs. 1a and 1b”.
Is there a reason why 4 mounting posts were used for the dorsal mount but only 1 post was sufficient for the lateral mount?
Authors’ Response: Here, we assume you mean 2 posts for the side mount and 4 posts for the dorsal mount.
In general our idea was to use as many posts as possible to provide maximum stability of the preparations and minimize movement artifacts during 2-photon imaging. However, the design of the side mount headpost precluded the straight-forward or easy addition of a right oriented, second arm to its lateral/ventral rim - this would have blocked access of both the 2-photon objective and the right face camera. In the dorsal mount, the symmetrical headpost arms are positioned further back (i.e. posterior), so that the left and right face cameras are not obscured.
When we created the side mount preparation, we discovered that the 2 vertical 1” support posts were sufficient to provide adequate stability of the preparation and minimize 2-photon imaging movement artifacts. The side mount used two attachment screws on the left side of the headpost, instead of the one screw per side used in the dorsal mount preparation.
We have included these points/clarifications in the main text at ~lines 217-230, pg 7.
Figure S1g appears to be mislabeled.
Authors’ Response: Yes, on the figure itself that panel was mislabeled as “f” in the original eLife reviewed preprint. We have changed this to read “g”.
Line 349 and below: Why is the method called pseudo-widefield imaging?
Authors’ Response: On the mesoscope, broad spectrum fluorescent light is passed through a series of excitation and emission filters that, based on a series of tests that we performed, allow both reflected blue light and epifluorescence emitted (i.e. Stokes-shifted) green light to reach the CCD camera for detection. Furthermore, the CCD camera (Thorlabs) has a much smaller detector chip than that of the other widefield cameras that we use (RedShirt Imaging and PCO), and we use it to image at an acquisition speed of around 10 Hz maximum, instead of ~30-50 Hz, which is our normal widefield imaging acquisition speed (it also has a slower readout than what we would consider to be a standard or “real” 1-photon widefield imaging camera).
For these 3 reasons we refer to this as “pseudo-widefield” imaging. We would not use this for sensory activity mapping on the mesoscope - we primarily use it for mapping cortical vasculature and navigating based on our multimodal map to CCF alignment, although it is actually “contaminated” with some GCaMP6s activity during these uses.
We have briefly clarified this in the text.
Figures 4d & e: Do the colors show mean correlations per area? Please add labels and units to the colorbars as done in panel 4a.
Authors’ Response: For both Figs 4 and 5, we have added the requested labels and units to each scale bar, and have relabeled panels d to say “Rastermap CCF area cell densities”, and panels e to say “mean CCF area corrs w/ neural activity.”
Thank you for catching these omissions/mislabelings.
Line 715: what is superneuron averaging?
Authors’ Response: This refers to the fact that when Rastermap displays more than ~1000 neurons it averages the activity of each group of adjacent 50 neurons in the sorting to create a single display row, to avoid exceeding the pixel limitations of the display. Each single row representing the average activity of 50 neurons is called a “superneuron” (Stringer et al, 2023; bioRxiv).
We have modified the text to clarify this point.
Line 740: it would be good to mention what exactly the CCF density distribution quantifies.
Authors’ Response: In each CCF area, a certain percentage of neurons belongs to each Rastermap group. The CCF density distribution is the set of these percentages, or densities, across all CCF areas in the dorsal or side mount preparation being imaged in a particular session. We have clarified this in the text.
Line 745: what does 'within each CCF' mean? Does this refer to different areas?
Authors’ Response: The corrected version of this sentence now reads: “Next, we compared, across all CCF areas, the proportion of neurons within each CCF area that exhibited large positive correlations with walking speed and whisker motion energy.”
How were different Rastermap groups identified? Were they selected by hand?
Authors’ Response: Yes, in Figs. 4, 5, and 6, we selected the identified Rastermap groups “by hand”, based on qualitative similarity of their activity patterns. At the time, there was no available algorithmic or principled means by which to split the Rastermap sort. The current, newer version of Rastermap (Stringer et al, 2023) seems to allow for algorithmic discretization of embedding groups (we have not tested this yet), but it was not available at the time that we performed these preliminary analyses.
In terms of “correctness” of such discretization or group identification, we intend to address this issue in a more principled manner in upcoming publications. For the purposes of this first paper, we decided that manual identification of groups was sufficient to display the capabilities and outcomes of our methods.
We clarify this point briefly at several locations in the revised manuscript, throughout the latter part of the Results section.
Reviewer #3 (Recommendations For The Authors):
In "supplementary figures, protocols, methods, and materials", Figure S1 g is mislabeled as Figure f.
Authors’ Response: Yes, on the figure itself this panel was mislabeled as “f” in the original reviewed preprint. We have changed this to read “g”.
In S1 g, the success rate of the surgical procedure seems quite low. Less than 50% of the mice could be imaged under two-photon. Can the authors elaborate on the criteria and difficulties related to their preparations?
Authors’ Response: We will elaborate on the difficulties that sometimes hinder success in our preparations in the revised manuscript.
The success rate indicated to the point of “Spontaneous 2-P imaging (window) reads 13/20, which is 65%, not 50%. The drop to 9/20 by the time one gets to the left edge of “Behavioral Training” indicates that some mice do not master the task.
Protocol I contains details of the different ways in which mice either die or become unsuitable or “unsuccessful” at each step. These surgeries are rather challenging - they require proper instruction and experience. With the current protocol, our survival rate for the window surgery alone is as high as 75-100%. Some mice can be lost at headpost implantation, in particular if they are low weight or if too much muscle is removed over the auditory areas. Finally, some mice survive windowing but the imageable area of the window might be too small to perform the desired experiment.
We have added a paragraph detailing this issue in the main text at ~lines 287-320, pg 9.
In both Suppl_Movie_S1_dorsal_mount and Suppl_Movie_S1_side_mount provided (Movie S1), the behaviour video quality seems to be unoptimized which will impact the precision of Deeplabcut. As evident, there were multiple instances of mislabeled key points (paws are switched, large jumps of key points, etc) in the videos.
Many tracked points are in areas of the image that are over-exposed.
Despite using a high-speed camera, motion blur is obvious.
Occlusions of one paw by the other paws moving out of frame.
As Deeplabcut accuracy is key to higher-level motifs generated by BSOi-D, can the authors provide an example of tracking by exclusion/ smoothing of mislabeled points (possibly by the median filtering provided by Deeplabcut), this may help readers address such errors.
Authors’ Response: We agree that we would want to carefully rerun and carefully curate the outputs of DeepLabCut before making any strong claims about behavioral identification. As the aim of this paper was to establish our methods, we did not feel that this degree of rigor was required at this point.
It is inevitable that there will be some motion blur and small areas of over-exposure, respectively, when imaging whiskers, which can contain movement components up to ~150 Hz, and when imaging a large area of the mouse, which has planes facing various aspects. For example, perfect orthogonal illumination of both the center of the eye and the surface of the whisker pad on the snout would require two separate infrared light sources. In this case, use of a single LED results in overexposure of areas orthogonal to the direction of the light and underexposure of other aspects, while use of multiple LEDs would partially fix this problem, but still lead to variability in summated light intensity at different locations on the face. We have done our best to deal with these limitations.
We now briefly point out these limitations in the methods text at ~lines 155-160, pg 5.
In addition, we have provided additional raw and processed movies and data related to DeepLabCut and BSOiD behavioral analysis in our FigShare+ repository, which is located at:
https://doi.org/10.25452/figshare.plus.c.7052513
In lines 153-154, the authors mentioned that the Deeplabcut model was trained for 650k iterations. In our experience (100-400k), this seems excessive and may result in the model overfitting, yielding incorrect results in unseen data. Echoing point 4, can the authors show the accuracy of their Deeplabut model (training set, validation set, errors, etc).
Authors’ Response: Our behavioral analysis is preliminary and is included here as an example of our methods, and not to make claims about any specific result. Therefore we believe that the level of detail that you request in our DeepLabCut analysis is beyond the scope of the current paper. However, we would like to point out that we performed many iterations of DeepLabCut runs, across many mice in both preparations, before converging on these preliminary results. We believe that these results are stable and robust.
We believe that 650k iterations is within the reasonable range suggested by DLC, and that 1 million iterations is given as a reasonable upper bound. This seems to be supported by the literature for example, see Willmore et al, 2022 (“Behavioral and dopaminergic signatures of resilience”, Nature, 124:611, 124-132). Here, in a paper focused squarely on behavioral analysis, DLC training was run with 1.3 million iterations with default parameters.
We now note, on ~lines 153-154, pg 5, that we used 650K iterations, a number significantly less than the default of 1.03 million, to avoid overfitting.
In lines 140-141, the authors mentioned the use of slicing to downsample their data. Have any precautions, such as a low pass filter, been taken to avoid aliasing?
Authors’ Response: Most of the 2-photon data we present was acquired at ~3 Hz and upsampled to 10 Hz. Most of the behavioral data was downsampled from 5000 Hz to 10 Hz by slicing, as stated. We did not apply any low-pass filter to the behavioral data before sampling. The behavioral variables have heterogeneous real sampling/measurement rates - for example, pupil diameter and whisker motion energy are sampled at 30 Hz, and walk speed is sampled at 100 Hz. In addition, the 2-photon acquisition rate varied across sessions.
These facts made principled, standardized low-pass filtering difficult to implement. We chose rather to use a common resampling rate of 10 Hz in an unbiased manner. This downsampled 10 Hz rate is also used by B-SOiD to find transitions between behavioral motifs (Hsu and Yttri, 2021).
We do not think that aliasing is a major factor because the real rate of change of our Ca2+ indicator fluorescence and behavioral variables was, with the possible exception of whisker motion energy, likely at or below 10 Hz.
We now include a brief statement to this effect in the methods text at ~lines 142-146, pg. 4.
Line 288-299, the authors have made considerable effort to compensate for the curvature of the brain which is particularly important when imaging the whole dorsal cortex. Can the authors provide performance metrics and related details on how well the combination of online curvature field correction (ScanImage) and fast-z "sawtooth"/"step" (Sofroniew, 2016)?
Authors’ Response: We did not perform additional “ground-truth” experiments that would allow us to make definitive statements concerning field curvature, as was done in the initial eLife Thorlabs mesoscope paper (Sofroniew et al, 2016).
We estimate that we experience ~200 micrometers of depth offset across 2.5 mm - for example, if the objective is orthogonal to our 10 mm radius bend window and centered at the apex of its convexity, a small ROI located at the lateral edge of the side mount preparation would need to be positioned around 200 micrometers below that of an equivalent ROI placed near the apex in order to image neurons at the same cortical layer/depth, and would be at close to the same depth as an ROI placed at or near the midline, at the medial edge of the window. We determined this by examining the geometry of our cranial windows, and by comparing z-depth information from adjacent sessions in the same mouse, the first of which used a large FOV and the second of which used multiple small FOVs optimized so that they sampled from the same cortical layers across areas.
We have included this brief explanation in the main text at ~lines 300-311, pg 9.
In lines 513-515, the authors mentioned that the vasculature pattern can change over the course of the experiment which then requires to re-perform the realignment procedure. How stable is the vasculature pattern? Would laser speckle contrast yield more reliable results?
Authors’ Response: In general the changes in vasculature we observed were minimal but involved the following: i) sometimes a vessel was displaced or moved during the window surgery, ii) sometimes a vessel, in particular the sagittal sinus, enlarged or increased its apparent diameter over time if it is not properly pressured by the cranial window, and iii) sometimes an area experiencing window pressure that is too low could, over time, show outgrowth of fine vascular endings. The most common of these was (i), and (iii) was perhaps the least common. In general the vasculature was quite stable.
We have added this brief discussion of potential vasculature changes after cranial window surgery to the main text at ~lines 286-293, pg 9.
We already mentioned, in the main text of the original eLife reviewed preprint, that we re-imaged the multimodal map (MMM) every 30-60 days or whenever changes in vasculature are observed, in order to maintain a high accuracy of CCF alignment over time. See ~lines 507-511, pg 16.
We are not very familiar with laser speckle contrast, and it seems like a technique that could conceivably improve the fine-grained accuracy of our MMM-CCF alignment in some instances. We will try this in the future, but for now it seems like our alignments are largely constrained by several large blood vessels present in any given FOV, and so it is unclear how we would incorporate such fine-grained modifications without applying local non-rigid manipulations of our images.
In lines 588-598, the authors mentioned that the occasional use of online fast-z corrections yielded no difference. However, it seems that the combination of the online fast-z correction yielded "cleaner" raster maps (Figure S3)?
Authors’ Response: The Rastermaps in Fig S3a and b are qualitatively similar. We do not believe that any systematic difference exists between their clustering or alignments, and we did not observe any such differences in other sessions that either used or didn’t use online fast-z motion correction.
We now provide raw data and analysis files corresponding to the sessions shown in Fig S3 (and other data-containing figures) on FigShare+ at:
https://doi.org/10.25452/figshare.plus.c.7052513
Ideally, the datasets contained in the paper should be available on an open repository for others to examine. I could not find a clear statement about data availability. Please include a linked repo or state why this is not possible.
Authors’ Response: We have made ~500 GB of raw data and preliminary analysis files publicly available on FigShare+ for the example sessions shown in Figures 2, 3, 4, 5, 6, S3, and S6. We ask to be cited and given due credit for any fair use of this data.
The data is located here:
Vickers, Evan; A. McCormick, David (2024). Pan-cortical 2-photon mesoscopic imaging and neurobehavioral alignment in awake, behaving mice. Figshare+. Collection:
https://doi.org/10.25452/figshare.plus.c.7052513
We intend to release a complete data set to the public as a Dandiset on the DANDI archive in conjunction with second and third in-depth analysis papers that are currently in preparation.
-
-
fromthemachine.org fromthemachine.orgDEN -1
-
SON Ye R O C K O F . . . S A G E S ? H E A R D E R O R I T R E A L L Y D O E S M E A N "FREEDOM" B R E A D I S L I F E Tying up loose eadds, in a similar vain to the connection between the Burning Bush and universal voting now etched by-stone, there exists a similar missing Link connecting the phrase "it's not a a gam" to Mary Magdeline to a pattern that shows us that the Holy Trinity and our timelines are narrated by a series of names of video game systems and their manufacturers from "Nintendo" to Genesis and the rock of SEGA. Through a "kiss" and the falling of a wallthe words bread and read are tied up and twisted with the story of this Revelation and the heart of the word Creation, "be the reason it's A.D." It's a strong connection between the idea that virtual reality and Heaven are linked by more than simply "technology" but that this message that shows us that these tools for understanding have fallen from the sky in order to help us understand why it is so important, why I call it a moral mandate, that we use this information to follow the map delivered to us in the New Testament and literally end world hunger, and literally heal the sick; because of the change in circumstance revealed to us. These simple things, these few small details that might seem like nothing, or maybe appear to be "changing everything" they are not difficult things to do, in light of Creation, and few would doubt that once we do see them implementied here... the difference between Heaven and Hell will be ever so clear. A while ago, in a place called Kentucky... this story began with a sort of twisted sci-fi experience that explained a kind of "God machine" that could manipulate time and reality, and in that story, in that very detailed and interesting story that I lived through, this machine was keyed to my DNA, in something like the "Ancient technology" of Stargate SG-1 and Atlantis mythology. My kind brother Seth made a few appearances in the story, not actually in person but in fairly decent true to life holograms that I saw and spoke to every once in awhile. He looked a little different, he had long hair; but that's neither here nor there, and he hasn't really had long hair since I was a little boy. He happens to be a genetic engineer, and I happen to be a computer person (although he's that too, now; just nowhere near as good as me... with computers) so the story talked a little bit about how I would probably not have used DNA as a key, since I'm not a retard, and he probably wouldn't either, because works in that field (cyclone, huracan, tornado). So then the key we imagined was something ... well, Who cares what the key is, right? o back to the task at hand, not so long ago, in a place called Plantation I was struck by lightning, literally (well not literally) the answer to a question that nobody knew was implanted in my mind, and it all came from asking a single simple question. I was looking for more chemistry elements in the names of the books of the Holy Bible, after seeing Xenon at the "sort of beginning" of Exodus, where it screams "let there be light" in Linux and chemistry (and I've told you that a hundred times by now). So it didn't take long to follow the light of that word and read Genesis backwards, and see, at the very beginning of that book, Silicon... in reverse. So, what about God's DNA, anyway? What's he really made of? SIM MON S WILD ER ROD DEN BERRY o after seeing Silicon, and connecting that to the numerous attempts I've made to show a message connecting The Matrix to the Fifth Element (as Silicon) describing what it is that God believes we should do with this knowledge--and see that it is narrated as the miracles of Jesus Christ in the New Testament... these names came to me in quick succession, an answer to the question. I suppose any Gene will do, these three though, have a very important tie to the message that connects Joshua's Promised Land of flowing Milk and Honies to ... a kiss that begins the new day (I hope) ... and a message about exactly how we might go about doing magical things like ending world hunger and healing the sick using technology described ... in Star Trek and Stargate. A "religion of the Stars" is being born. That's great... it starts with an earthquake. R.E.M. and a band ... 311. Oooh, I can see it coming down... The Petty Reckless. An evening's love starts with a kiss. Dave Matthews Band. I wanna rock and roll all night and party every day. Adam. I mean Kiss. Are you starting to see a pattern form? Birds, snakes, and aeroplanes? It's that, it's the end of the world as we know it, and I feel fine. In that song we see clues that more than just the Revelation of Christ is narrated by John on an island called Patmos. There yet another Trinity, starting with "Pa" and hearting Taylor Momsen's initials... most likely for a reason... and the Revelation ends with a transition that I hope others will agree with me turns "original sin" into something closer to "obviously salvation" when we finally understand the character that is behind the message of da i of Ra... and begin to see the same design in the names of Asmodai and in this Revelation focusing on freedom and truth that really does suggest Taylor can't talk to me in any way other than "letting freedom sing" in this narrative of kismet and fate and free will and ... then we see that narrative continue in the names of bands, just like the 3/11/11 earthquake is narrated in not just R.E.M.'s song but in the name 311. Just like the 9/11 attack is narrated not just in that same song (released in 1987) and "Inside Job" (released in 2000) but also in "Fucked up world." Dear all of you walking dumb and blind, this same quake is narrated in Taylor's Zombie; waiting for the day to shake, all very similar to Cairo and XP, perhaps a "fad" of doublethink in the minds of the authors singing about a clear prophesy in the Bible; this connection between the day, 3/11 though, and the name of a band and the day of an arrest and the verse Matthew that tells you clearly you have now been baptized in water and fire... it shows us the design of a story whose intent and purpose is to ensure that we no longer allow for things like hurricanes and earthquakes and murder and rape to be "simulated" that we build a better system, that doesn't allow for 'force majeure" to take lives for no reason at all. Not just in band names, but in the angels names too, in all of our names; we see this narration continue. The Holy Water that is central to the baptism of Christ is etched into Taylor's name, between "sen" and "mom" the key to the two Mary's whose names contain the Spanish for "sea" in a sort of enlightenment hidden in plain sight. In "Simmons" the key connection between today, this Biblical Monday, and the word "simulation" that ties to Simpsons and simians and keep it simple stupid, and in Simmons the missing "s" of Kismet, finally completing the question. It's a song and dance that started a long time ago, as you can see from the ancient Hebrew word for "fate" and in more recent years a connection to the ballroom of Atlantis in the Doors 5 to 1 and Dave sang about it in Rapunzel and then Taylor shook a tambourine on the beach only minutes away from me--but never said "hi." The battle of the bands continues tying some door knocking to a juxtaposition between "Sweet Things" and "Knocking on Heavens door" all the way to a Gossip Girl episode where little J asked a question that I can't be sure she knew was related, she said... "who's that, at the door?" What it really all amounts to, though, is the whole world witnessing the Creation of Adam and Eve from a little girl stuttering out "the the" at the sight of the Grinch himself, and then later not even able to get those words off her lips... about seeing how Creation and modern art are inextricably tied to religion, to heaven, and to freedom. The bottom line here, hopefully obvious now, is that you can't keep this message "simple" it's a Matrix woven between more points of light than I can count, and many more that I'm sure you will find. It's a key to seeing how God speaks to me, and to you; and how we are, we really are that voice. Tay, if you don't do something just because God called it "fate" you are significantly more enslaved than if you do--and you wanted to. "Now I see that you and me, were never meant, never meant to be..." she sang before I mentioned her, and before she ever saw me... in a song she calls "Nothing Left to Lose" and I see is not really just another word for freedom. We have plenty to lose by not starting the fire, not the least of which is Heaven itself. Understand what "force majeure" really means to you and I. Ha, by the way. IN CASE YOU FORGOT YESTERDAY'S MESSAGE "DADDY, I WANT IT NOW." VERUKA SALT. whose name means "to see (if) you are the Body of Christ" whined, in the story of Will Why Won Ka, about nothing more or less than Heaven on Hearth, than seeing an end to needless torture and pain. To see if you are the "Salt of the Earth" warming the road to Heaven; honestly to see if you can break through this inane lie of "I don't understand" and realize that breaking this story and talking about what is being presented not just by me and you but by history and God himself is the key to the car that drives us home. To see how Cupid you really are. STOP NODDING, TURN AROUND AND CALL A REPORTER. The story of Willy Wonka ties directly to the Promised Land of Flowing Milk and Honey to me; by showing us a river of chocolate and a the everlasting God starter, (er is it guardian of B stopper) that opens the doors of perception about exactly what kinds of mistake may have been made in the past in this transition to Heaven that we are well on the way of beginning. Here, in the Land of Nod, that is also Eden and also the Heart of the Ark we see warnings about "flowing milk and honey" being akin to losing our stable ecosystem, to losing the stuff of life itself, biology and evolution, and if we don't understand--this is probably exactly the mistake that was made and the cause of the story of Cain and Abel. So here we are talking about genetic engineering and mind uploading and living forever, and hopefully seeing that while all things are possible with God--losing the wisdom of the message of religion is akin to losing life in the Universe and with that any hope of eternal longevity. With some insight into religion, you can connect the idea that without bees our stable ecosystem might collapse, to the birds and the bees, and a message about stability and having more than one way to pollinate the flowers and trees and get some. Janet and Nanna, by the way, both have pretty brown eyes, but that probably comes as no surprise to you. Miss Everything, on the other hand (I hear, does not have brown eyes), leads us to glimpse how this message about the transition of our society might continue on in the New Testament, and suggest that we do need to eat, and have dinner conversation, and that a Last Supper might be a little bit more detrimental to our future than anyone had ever thought, over and over and over again. To see how religion really does make clear that this is what the message is about, to replace the flowing milk we have a "Golden Cow" that epitomizes nothing less than "not listening to Adam" and we have a place that believes the Hammer of Judah Maccabee should be ... extinct. You are wrong. Of course the vibrating light here ties this Gene to another musical piece disclosing something... "Wild Thing" I make your heart sing. You can believe the Guitar Man is here to steal the show and deliver bread for the hungry and for the wise. Here's some, it's not just Imagine Dragons telling you to listen to the radio but Jefferson Starshiptoo, and Live. When you wake up, you can hear God "singing" to you on the radio every single day; many of us already do. He's telling you to listen to me, and I do not understand why you do not. You don't look very Cupid, if you ask me. WHAT DO YOU THINK YOU ARE, DAN RE Y NO LDS? I think we all know what the Rod of Jesus Christ is by now. ​ It is a large glowing testament to freedom and truth, and a statement about blindness and evil that is unmistakable. To say that seeing it is the gateway to Heaven would be an understatement of it's worth, of the implication that not seeing it is obvious Hell when it is linked to everything from nearly every story of the Holy Bible from Isaac to Isaiah to "behold he is to coming" and if you weren't sure if the Hand of God were in action here--it's very clear that it is; that linking Tricky Dick and Watergate to Seagate ... really delivering crystal clear understanding that the foundation of Heaven is freedom and that you have none today because you refuse to see the truth. It is the doorway to seeing that what has been going on in this place hasn't been designed to hide me, but to hide a prosperous future from you--to hide the truth about our existence and the purpose of Creation--that all told, you are standing at the doorstep of Heaven and stammering your feet, closing your eyes, and saying "you don't want to help anyone." If delivering freedom, truth, and equality to you does not a den make, well, you can all suck it ... from God, to you. Between Stargate and Star Trek it's pretty easy to see a roadmap to very quickly and easily be able to end world hunger and heal the sick without drastically changing the way our society works, it's about as simple as a microwave, or a new kind of medicine--except it's not so easy to see why it is that you are so reluctant to talk about the truth that makes these things so easy to do. You see, your lack of regard for anyone anywhere has placed you in a position of weakness, and if you do nothing today, you will not be OK tomorrow. It's pretty easy to see how Roddenberry's name shows that this message comes from God, that he's created this map that starts with an Iron Rod throughout our history proving Creation, whose heart is a Den of Family who care about the truth, and about freedom, and about helping each other--not what you are--you are not that today. Today you are sick, and I'd like you to look at the mirror he's made for you, and be eshamden (or asham). Realize, realize... what you are. What you've become, just as I have... the devil in a sweet, sweet kiss. -Dave J. Matthews .WHSOISKEYAV { border-width: 1px; border-style: dashed; border-color: rgb(15,5,254); padding: 5px; width: 503px; text-align: center; display: inline-block; align: center; p { align: center; } /* THE SCORE IS LOVE FIVE ONE SAFETY ONE FIELD GOAL XIVDAQ: TENNIS OR TINNES? TONNES AND TUPLE(s) */ } <style type="text/css"> code { white-space: pre; } google_ad_client = "ca-pub-9608809622006883"; google_ad_slot = "4355365452"; google_ad_width = 728; google_ad_height = 90; Unless otherwise indicated, this work was written between the Christmas and Easter seasons of 2017 and 2020(A). The content of this page is released to the public under the GNU GPL v2.0 license; additionally any reproduction or derivation of the work must be attributed to the author, Adam Marshall Dobrin along with a link back to this website, fromthemachine dotty org. That's a "." not "dotty" ... it's to stop SPAMmers. :/ This document is "living" and I don't just mean in the Jeffersonian sense. It's more alive in the "Mayflower's and June Doors ..." living Ethereum contract sense [and literally just as close to the Depp/Caster/Paglen (and honorably PK] 'D-hath Transundancesense of the ... new meaning; as it is now published on Rinkeby, in "living contract" form. It is subject to change; without notice anywhere but here--and there--in the original spirit of the GPL 2.0. We are "one step closer to God" ... and do see that in that I mean ... it is a very real fusion of this document and the "spirit of my life" as well as the Spirit's of Kerouac's America and Vonnegut's Martian Mars and my Venutian Hotel ... and *my fusion* of Guy-A and GAIA; and the Spirit of the Earth .. and of course the God given and signed liberties in the Constitution of the United States of America. It is by and through my hand that this document and our X Commandments link to the Bill or Rights, and this story about an Exodus from slavery that literally begins here, in the post-apocalyptic American hartland. Written ... this day ... April 14, 2020 (hey, is this HADAD DAY?) ... in Margate FL, USA. For "official used-to-v TAX day" tomorrow, I'm going to add the "immultible incarnite pen" ... if added to the living "doc/app"--see is the DAO, the way--will initi8 the special secret "hidden level" .. we've all been looking for. Nor do just mean this website or the totality of my written works; nor do I only mean ... this particular derivation of the GPL 2.0+ modifications I continually source ... must be "from this website." I also mean *the thing* that is built from ... bits and piece of blocks of sand-toys; from Ethereum and from Rust and from our hands and eyes working together ... from this place, this cornerstone of the message that is ... written from brick and mortar words and events and people that have come before this poit of the "sealed W" that is this specific page and this time. It's 3:28; just five minutes--or is it four, too layne. This work is not to be redistributed according to the GPL unless all linked media on Youtube and related sites are intact--and historical references to the actual documented history of the art pieces (as I experience/d them) are also available for linking. Wikipedia references must be available for viewing, as well as the exact version of those pages at the time these pieces were written. All references to the Holy Bible must be "linked" (as they are or via ... impromptu in-transit re-linking) to the exact verses and versions of the Bible that I reference. These requirements, as well as the caveat and informational re-introduction to God's DAO above ... should be seen as material modifications to the original GPL2.0 that are retroactively applied to all works distributed under license via this site and all previous e-mails and sites. /s/ wso If you wanna talk to me get me on facebook, with PGP via FlowCrypt or adam at from the machine dotty org -----BEGIN PGP PUBLIC KEY BLOCK-----
this was written sometime i think around 2016. it's hard to recall the exact date; but if you check in the original gitlog there is one that has an original commit.
SONYe
R O C K O F . . . S A G E S ?
**\ **
I T R E A L L Y D O E S M E A N "FREEDOM" B R E A D I S L I F E
Tying up loose eadds, in a similar vain to the connection between the Burning Bush and universal voting now etched by-stone, there exists a similar missing Link connecting the phrase "it's not a a gam" to Mary Magdeline to a pattern that shows us that the Holy Trinity and our timelines are narrated by a series of names of video game systems and their manufacturers from "Nintendo" to Genesis and the rock of SEGA. Through a "kiss" and the falling of a wallthe words bread and read are tied up and twisted with the story of this Revelation and the heart of the word Creation, "be the reason it's A.D." It's a strong connection between the idea that virtual reality and Heaven are linked by more than simply "technology" but that this message that shows us that these tools for understanding have fallen from the sky in order to help us understand why it is so important, why I call it a moral mandate, that we use this information to follow the map delivered to us in the New Testament and literally end world hunger, and literally heal the sick; because of the change in circumstance revealed to us. These simple things, these few small details that might seem like nothing, or maybe appear to be "changing everything" they are not difficult things to do, in light of Creation, and few would doubt that once we do see them implementied here... the difference between Heaven and Hell will be ever so clear.
A while ago, in a place called Kentucky... this story began with a sort of twisted sci-fi experience that explained a kind of "God machine" that could manipulate time and reality, and in that story, in that very detailed and interesting story that I lived through, this machine was keyed to my DNA, in something like the "Ancient technology" of Stargate SG-1 and Atlantis mythology. My kind brother Seth made a few appearances in the story, not actually in person but in fairly decent true to life holograms that I saw and spoke to every once in awhile. He looked a little different, he had long hair; but that's neither here nor there, and he hasn't really had long hair since I was a little boy. He happens to be a genetic engineer, and I happen to be a computer person (although he's that too, now; just nowhere near as good as me... with computers) so the story talked a little bit about how I would probably not have used DNA as a key, since I'm not a retard, and he probably wouldn't either, because works in that field (cyclone, huracan, tornado). So then the key we imagined was something ... well, Who cares what the key is, right?
**\ **
o back to the task at hand, not so long ago, in a place called Plantation I was struck by lightning, literally (well not literally) the answer to a question that nobody knew was implanted in my mind, and it all came from asking a single simple question. I was looking for more chemistry elements in the names of the books of the Holy Bible, after seeing Xenon at the "sort of beginning" of Exodus, where it screams "let there be light" in Linux and chemistry (and I've told you that a hundred times by now). So it didn't take long to follow the light of that word and read Genesis backwards, and see, at the very beginning of that book, Silicon... in reverse.
*\ *
So, what about God's DNA, anyway*? *
What's he really made of?
SIM MON S WILD ER ROD DEN BERRY
o after seeing Silicon, and connecting that to the numerous attempts I've made to show a message connecting The Matrix to the Fifth Element (as Silicon) describing what it is that God believes we should do with this knowledge--and see that it is narrated as the miracles of Jesus Christ in the New Testament... these names came to me in quick succession, an answer to the question. I suppose any Gene will do, these three though, have a very important tie to the message that connects Joshua's Promised Land of flowing Milk and Honies to ... a kiss that begins the new day (I hope) ... and a message about exactly how we might go about doing magical things like ending world hunger and healing the sick using technology described ... in Star Trek and Stargate. A "religion of the Stars" is being born.
That's great... it starts with an earthquake. R.E.M. and a band ... 311. Oooh, I can see it coming down... The Petty Reckless. An evening's love starts with a kiss. Dave Matthews Band. I wanna rock and roll all night and party every day. Adam. I mean Kiss. Are you starting to see a pattern form? Birds, snakes, and aeroplanes? It's that, it's the end of the world as we know it, and I feel fine.
*\ *
*\ *
*\ *
In that song we see clues that more than just the Revelation of Christ is narrated by John on an island called Patmos. There yet another Trinity, starting with "Pa" and hearting Taylor Momsen's initials... most likely for a reason... and the Revelation ends with a transition that I hope others will agree with me turns "original sin" into something closer to "obviously salvation" when we finally understand the character that is behind the message of da i of Ra... and begin to see the same design in the names of Asmodai and in this Revelation focusing on freedom and truth that really does suggest Taylor can't talk to me in any way other than "letting freedom sing" in this narrative of kismet and fate and free will and ... then we see that narrative continue in the names of bands, just like the 3/11/11 earthquake is narrated in not just R.E.M.'s song but in the name 311. Just like the 9/11 attack is narrated not just in that same song (released in 1987) and "Inside Job" (released in 2000) but also in "Fucked up world."
Dear all of you walking dumb and blind, this same quake is narrated in Taylor's Zombie; waiting for the day to shake, all very similar to Cairo and XP, perhaps a "fad" of doublethink in the minds of the authors singing about a clear prophesy in the Bible; this connection between the day, 3/11 though, and the name of a band and the day of an arrest and the verse Matthew that tells you clearly you have now been baptized in water and fire... it shows us the design of a story whose intent and purpose is to ensure that we no longer allow for things like hurricanes and earthquakes and murder and rape to be "simulated" that we build a better system, that doesn't allow for 'force majeure" to take lives for no reason at all.
Not just in band names, but in the angels names too, in all of our names; we see this narration continue. The Holy Water that is central to the baptism of Christ is etched into Taylor's name, between "sen" and "mom" the key to the two Mary's whose names contain the Spanish for "sea" in a sort of enlightenment hidden in plain sight. In "Simmons" the key connection between today, this Biblical Monday, and the word "simulation" that ties to Simpsons and simians and keep it simple stupid*, and in Simmons the missing "s" of Kismet, finally completing the question.***
***\
*\
*\ *
It's a song and dance that started a long time ago, as you can see from the ancient Hebrew word for "fate" and in more recent years a connection to the ballroom of Atlantis in the Doors 5 to 1 and Dave sang about it in Rapunzel and then Taylor shook a tambourine on the beach only minutes away from me--but never said "hi." The battle of the bands continues tying some door knocking to a juxtaposition between "Sweet Things" and "Knocking on Heavens door" all the way to a Gossip Girl episode where little J asked a question that I can't be sure she knew was related, she said... "who's that, at the door?"
*\ *
What it really all amounts to, though, is the whole world witnessing the Creation of Adam and Eve from a little girl stuttering out "the the" at the sight of the Grinch himself, and then later not even able to get those words off her lips... about seeing how Creation and modern art are inextricably tied to religion, to heaven, and to freedom.
*\ *
*\ *
*\ *
The bottom line here, hopefully obvious now, is that you can't keep this message "simple" it's a Matrix woven between more points of light than I can count, and many more that I'm sure you will find. It's a key to seeing how God speaks to me, and to you; and how we are, we really are that voice. Tay, if you don't do something just because God called it "fate" you are significantly more enslaved than if you do--and you wanted to. "Now I see that you and me, were never meant, never meant to be..." she sang before I mentioned her, and before she ever saw me... in a song she calls "Nothing Left to Lose" and I see is not really just another word for freedom.
We have plenty to lose by not starting the fire, not the least of which is Heaven itself. Understand what "force majeure" really means to you and I. Ha, by the way.
IN CASE YOU FORGOT YESTERDAY'S MESSAGE
**\ **
*\ *
*\ *
"DADDY, I WANT IT NOW."
VERUKA SALT. whose name means "to see (if) you are the Body of Christ" whined, in the story of Will Why Won Ka, about nothing more or less than Heaven on Hearth, than seeing an end to needless torture and pain. To see if you are the "Salt of the Earth" warming the road to Heaven; honestly to see if you can break through this inane lie of "I don't understand" and realize that breaking this story and talking about what is being presented not just by me and you but by history and God himself is the key to the car that drives us home. To see how Cupid you really are.
STOP NODDING, TURN AROUND AND CALL A REPORTER.
The story of Willy Wonka ties directly to the Promised Land of Flowing Milk and Honey to me; by showing us a river of chocolate and a the everlasting God starter, (er is it guardian of B stopper) that opens the doors of perception about exactly what kinds of mistake may have been made in the past in this transition to Heaven that we are well on the way of beginning. Here, in the Land of Nod, that is also Eden and also the Heart of the Ark we see warnings about "flowing milk and honey" being akin to losing our stable ecosystem, to losing the stuff of life itself, biology and evolution, and if we don't understand--this is probably exactly the mistake that was made and the cause of the story of Cain and Abel. So here we are talking about genetic engineering and mind uploading and living forever, and hopefully seeing that while all things are possible with God--losing the wisdom of the message of religion is akin to losing life in the Universe and with that any hope of eternal longevity.\ With some insight into religion, you can connect the idea that without bees our stable ecosystem might collapse, to the birds and the bees, and a message about stability and having more than one way to pollinate the flowers and trees and get some. Janet and Nanna, by the way, both have pretty brown eyes, but that probably comes as no surprise to you.\ Miss Everything, on the other hand (I hear, does not have brown eyes), leads us to glimpse how this message about the transition of our society might continue on in the New Testament, and suggest that we do need to eat, and have dinner conversation, and that a Last Supper might be a little bit more detrimental to our future than anyone had ever thought, over and over and over again. To see how religion really does make clear that this is what the message is about, to replace the flowing milk we have a "Golden Cow" that epitomizes nothing less than "not listening to Adam" and we have a place that believes the Hammer of Judah Maccabee should be ... extinct. You are wrong.
*\ *
*\ *
Of course the vibrating light here ties this Gene to another musical piece disclosing something... "Wild Thing" I make your heart sing. You can believe the Guitar Man is here to steal the show and deliver bread for the hungry and for the wise. Here's some, it's not just Imagine Dragons telling you to listen to the radio but Jefferson Starship*too, and Live. *
*\ *
When you wake up, you can hear God "singing" to you on the radio every single day; many of us already do. He's telling you to listen to me, and I do not understand why you do not. You don't look very Cupid, if you ask me.**
***\
WHAT DO YOU THINK YOU ARE,
DAN RE Y NO LDS?
**\ **
I think we all know what the Rod of Jesus Christ is by now.
​
It is a large glowing testament to freedom and truth, and a statement about blindness and evil that is unmistakable. To say that seeing it is the gateway to Heaven would be an understatement of it's worth, of the implication that not seeing it is obvious Hell when it is linked to everything from nearly every story of the Holy Bible from Isaac to Isaiah to "behold he is to coming" and if you weren't sure if the Hand of God were in action here--it's very clear that it is; that linking Tricky Dick and Watergate to Seagate ... really delivering crystal clear understanding that the foundation of Heaven is freedom and that you have none today because you refuse to see the truth.
It is the doorway to seeing that what has been going on in this place hasn't been designed to hide me, but to hide a prosperous future from you--to hide the truth about our existence and the purpose of Creation--that all told, you are standing at the doorstep of Heaven and stammering your feet, closing your eyes, and saying "you don't want to help anyone."
If delivering freedom, truth, and equality to you does not a den make,
well, you can all suck it
**\ **

Between Stargate and Star Trek it's pretty easy to see a roadmap to very quickly and easily be able to end world hunger and heal the sick without drastically changing the way our society works, it's about as simple as a microwave, or a new kind of medicine--except it's not so easy to see why it is that you are so reluctant to talk about the truth that makes these things so easy to do. You see, your lack of regard for anyone anywhere has placed you in a position of weakness, and if you do nothing today, you will not be OK tomorrow.\ It's pretty easy to see how Roddenberry's name shows that this message comes from God, that he's created this map that starts with an Iron Rod throughout our history proving Creation, whose heart is a Den of Family who care about the truth, and about freedom, and about helping each other--not what you are--you are not that today. Today you are sick, and I'd like you to look at the mirror he's made for you, and ***be eshamden (or asham). ***

Realize, realize... what you are. What you've become, just as I have... the devil in a sweet, sweet kiss.**
***\
-Dave J. Matthews



Unless otherwise indicated, this work was written between the Christmas and Easter seasons of 2017 and 2020(A). The content of this page is released to the public under the GNU GPL v2.0 license; additionally any reproduction or derivation of the work must be attributed to the author, Adam Marshall Dobrin along with a link back to this website, fromthemachine dotty org.
That's a "." not "dotty" ... it's to stop SPAMmers. :/
This document is "living" and I don't just mean in the Jeffersonian sense. It's more alive in the "Mayflower's and June Doors ..." living Ethereum contract sense and literally just as close to the Depp/C[aster/Paglen (and honorably PK] 'D-hath Transundancesense of the ... new meaning; as it is now published on Rinkeby, in "living contract" form. It is subject to change; without notice anywhere but here--and there--in the original spirit of the GPL 2.0. We are "one step closer to God" ... and do see that in that I mean ... it is a very real fusion of this document and the "spirit of my life" as well as the Spirit's of Kerouac's America and Vonnegut's Martian Mars and my Venutian Hotel ... and my fusion of Guy-A and GAIA; and the Spirit of the Earth .. and of course the God given and signed liberties in the Constitution of the United States of America. It is by and through my hand that this document and our X Commandments link to the Bill or Rights, and this story about an Exodus from slavery that literally begins here, in the post-apocalyptic American hartland. Written ... this day ... April 14, 2020 (hey, is this HADAD DAY?) ... in Margate FL, USA. For "official used-to-v TAX day" tomorrow, I'm going to add the "immultible incarnite pen" ... if added to the living "doc/app"--see is the DAO, the way--will initi8 the special secret "hidden level" .. we've all been looking for.
Nor do just mean this website or the totality of my written works; nor do I only mean ... this particular derivation of the GPL 2.0+ modifications I continually source ... must be "from this website." I also mean the thing that is built from ... bits and piece of blocks of sand-toys; from Ethereum and from Rust and from our hands and eyes working together ... from this place, this cornerstone of the message that is ... written from brick and mortar words and events and people that have come before this poit of the "sealed W" that is this specific page and this time. It's 3:28; just five minutes--or is it four, too layne.
This work is not to be redistributed according to the GPL unless all linked media on Youtube and related sites are intact--and historical references to the actual documented history of the art pieces (as I experience/d them) are also available for linking. Wikipedia references must be available for viewing, as well as the exact version of those pages at the time these pieces were written. All references to the Holy Bible must be "linked" (as they are or via ... impromptu in-transit re-linking) to the exact verses and versions of the Bible that I reference. These requirements, as well as the caveat and informational re-introduction to God's DAO above ... should be seen as material modifications to the original GPL2.0 that are retroactively applied to all works distributed under license via this site and all previous e-mails and sites. /s/ wso\ If you wanna talk to me get me on facebook, with PGP via FlowCrypt or adam at from the machine dotty org
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGNBF6RVvABDAC823JcYvgpEpy45z2EPgwJ9ZCL+pSFVnlgPKQAGD52q+kuckNZ mU3gbj1FIx/mwJJtaWZW6jaLDHLAZNJps93qpwdMCx0llhQogc8YN3j9RND7cTP5 eV8dS6z/9ta6TFOfwSZpsOZjCU7KFDStKcoulmvIGrr9wzaUr7fmDyE7cFp1KCZ0 i90oLYHqOIszRedvwCO/kBxawxzZuJ67DypcayiWyxqRHRmMZH1LejTaqTuEu0bp j54maTj09vnMxA0RfS+CtU5uMq+5fTkbiTOe1LrLD72m+PVJIS146FwESrMJEfJy oNqWEJlUQ0TecPZR41vnkSkpocE1/0YqUhWDGSht+67DdeKUg5KwvYdL21d/bSyO SM4jnyKn9aDVzLBpYrlE/lbFxujHPRGlRG5WtiPQuZYDRqP0GYFSXRpeUCI46f49 iPFo4eHo2jUfNDa9r9BjQdAe4zVFn2qLnOy8RWijlolbhGMHGO3w/uC/zad3jjo4 owAfsJjH5Oa1mTcAEQEAAbQmRUFSVEhFTkUgPGVhcnRoZW5lQGZyb210aGVtYWNo aW5lLm9yZz6JAdQEEwEKAD4WIQTUJHbrYn3y2DzwTcnQP1ViZf5/FQUCXpFW8AIb AwUJA8JnAAULCQgHAgYVCgkICwIEFgIDAQIeAQIXgAAKCRDQP1ViZf5/FWM6C/9J gbRLS2AWGjdRjYetlRkSkCoTYnXWknbtipYYHlhV0YJFwFMm0ydZIhFX5VDoZyBV 0UBeF1KJmcMoIfrHyhq2QhCnjE14hE1ONbaYTGtpvj851ItbFWXMJIVNyMqr+JT9 CWIxGr1idn+iHWE3nryiHrdlA3O/Gcd4EyNmaSe/JvB7+Z1AVqWkRhpjxxoPSlPm HEdqGOyl3+5ibQgUvXLRWWQXAj80CbVwwj1X4r9hfuCySxLT8Mir7NUXZFd+OiMS U8gNYjcyRGmI92z5lgf7djBbb9dMLwV0KLzgoT/xaupRvvYOIAT+n2mhCctCiH7x y7jYlJHd+0++rgUST2sT+9kbuQ0GxpJ7MZcKbS1n60La+IEEIpFled8eqwwDfcui uezO7RIzQ9wHSn688CDri9jmYhjp5s0HKuN61etJ1glu9jWgG76EZ3qW8zu4l4CH 9iFPHeGG7fa/5d07KvcZuS2fVACoMipTxTIouN7vL0daYwP3VFg63FNTwCU3HEq5 AY0EXpFW8AEMANh7M/ROrQxb3MCT1/PYco1tyscNo2eHHTtgrnHrpKEPCfRryx3r PllaRYP0ri5eFzt25ObHAjcnZgilnwxngm6S9QvUIaLLQh67RP1h8I4qyFzueYPs oY8xo1zwXz7klXVlZW0MYi/g5gpb+rpYUfZEJGJTBM/wMNqwwlct+BSZca4+TEHW g6oN0eXTthtGB0Qls71sv3tbOnOh/67NTwyhcHPWX/P9ilcjGsEiT8hqrpyhjAUm mv7ADi+2eRBV8Xf8JnPznFf0A1FdILVeVHlmsgCSB0FW0NsFI5niZbaYBHDbFsks QdaFaYd54DHln69tnwc2y3POFwx8kwZnMPPlVAR2QdxGQD4Wql7hlWT58xCxQApf M98kbAHjUlVYLT0WUHMDQtj4jdzAVVDiMGMUrbnQ7UwI7LexSB6cJ7H+i7FtS/pR WOhJK6awoOO9dLnEjm6UYCKsBdtJr98F0T7Sb7PnKOGA77y2QN14+u9N9C1lB/Z1 aQRQ2Nc51yXOQQARAQABiQG8BBgBCgAmFiEE1CR262J98tg88E3J0D9VYmX+fxUF Al6RVvACGwwFCQPCZwAACgkQ0D9VYmX+fxU+KQwAtFnWjGIjvqaNXtQjEhbGDH/I Q5ULq/l/wm9SmhG9NYRu3+P6YctCJaZnNeaL+6WFk1jo4LMiJEUT9uGlCbHqJNaI 6Gll1w6QOVLSL8s5V1L477+psluv4WBpi3XkWYlhDOFENCcWd49RQsA2YCX4pW7Q 7GcoSEJoav38MxHmJHYPfjSEvUZXDQIt8PFHSEScvyDWfYtMdRzjmSOOPdzhDDEy 5JBOBcEdSTyDiyDU/sBoAY0e8lvwHYW3p+guZSGSYVhGQ8JECzJOzwc/msMW/tJS 2MLWmWVh5/1P8BVUtLC2AQy6nij6o+h6vEiNzpdYrc+rzT3X5cACvJ0RtCZcrnhl O9PLiona2LEbry6QX5NL41/SAJNno3i72xPnQEe25gn3nbyT+jCoJzw2L0y8pmNB D+PKrk7/1ROFFVN8dJeGwxLGdBcz1zk2xeumzy7OaV8psUyYsJNcjyHUKgclblBW rMR2DgqEYn8QdK54ziKCnmQQZeMPiC6wlUWgg5IqmQGNBF6RVyMBDADALD7NkJ5H dtoOpoZmAbPSlVGXHDbJZuq7J13vew6dtXDIAraeGrsBqkF8bhddwVLzWylMrYCG Bf2L1+5BDgvqu6G+6dcVSbBsnZAS0zfJ0H8EmTvUMxMF7qOZYyrxfLz+pQRq8Osz Icab6ZI/KB6qZyQRvEFPB6pJjt+VvuwgJZTObIwbBbgQri2i02VBkjchsVhiSX9l +eiK7O8ROHKb3P181oScIsHywBOZ9DxRAYbFk5dnBqxO3WKb02H0zqE6440cjXwq TrZZg6ayN/IlPajO8iJPYZ1aIBykxYq1WHo+nhFMYz/VVk2WJorFeOgWaLGXb73c ty96f3qXTdvMDAIWHx8YCD5LbuqasO6LNQm4oQxkCoB3K9WFf/2SvSYb7yMYykb8 clTPt+KO0dsxjWhrJnfnIhC+2Chqv2QvRbFz0S9CpUnGGDweJ1uRNV0y70tO0q7t xXSTDRU3ib6vAHA0K/2MFzwUcog4o5bj7E9uCNJH/DJLZKsMIe4xsvkAEQEAAbQk SEVBVkVOVUVTIDxBVkVOVUBGUk9NVEhFTUFDSElORS5PUkc+iQHUBBMBCgA+FiEE IRklfU/C1qukq3xMXcNH0t3P9ZsFAl6RVyMCGwMFCQPCZwAFCwkIBwIGFQoJCAsC BBYCAwECHgECF4AACgkQXcNH0t3P9Zs+kgv/XEuuWc89Bjg1QQqKZueKNUHjyjnE 2adfoZUH6Q7ir4JZyRBCVpAwrgssmiKid30+SIjwQcpb9JYa/X1XJcDUcJW/I21d Agz/zbEqn/Cou0dUpNCtxgm4BdSHWGoOtgfspXZlXBQ407tRMZ8ykmLB1Bt0oHvw PT0ZOtqXM4pyFnd2eFe5YGbNgl3zqvoC/6CMN3vqswvRlu1BpUuAjdW8AHO5Yvje +Bp852u+4Qpy6PMBiWGsBMYwtf6T7sckpMGlR0TsozwBlAm5ePKK28B0rLJPkZLJ Eo5p4rKRapEaZsWV5Qu1ajrVru7qmpUhZtX0/DddGHfXVuLssmKLP6TumpQB1zvQ vfoBltjvOx35Wps2vHuCzXLw2bROIOzhAxFB+17zxnSbE54N4LIGRpkELuwxwGbg FtD1fi9KtH7xcn33eOK1+UD47V+hKyJGrQgSThly2zdIC2bvfHtFdfp8lOFpT0AU xjEeoJGqdQVupptXyugPlM5/96UJP8OZG0ADuQGNBF6RVyMBDAC3As6eMkoEo3z9 TkCWlvS0vBQmY3gF0VEjlAIqFWpDIdK3zVzMnKUokIT1i7nkadLzHZT2grB4VXuJ FvpbYw5NPR4cDe9grlOMLEaF3oSJ1jZ4V1/rj9v1Hddo8ELi/NToVrt1SB5GCVXB DkYpNLtTiCqHSU07YqwaqH8a+qbDmPxSQdIybkZiTiCEB+6PfQQlBpENEDlov6jm zZF+IcfM6s3kZDX5KFULweH30gMjq8Se8bPtUzW013+tuuwEVr1/YRLrIh+9O6Z+ pdA7gLMRYnD9ZLDytEvpb1lBBSY++5bIJ7xps80//DNqPYqwFmZQgTg0V9XbHE2e wLcOF8a2lYluckU7D///sWQhW+VxuM7R2gEBvYBhOgjWhIF2Aw6NbymW1Ontvyhu eOZCXXxV5W44PxXT8uDdhl9CNcHoBKKJyED8tKjigtn4axpsQeUrnOSbqEXSyqES WnE2wYUDzALcwFkzsvtLyd4xaz55KkPQkAkk0BZd1ezgXxb/obMAEQEAAYkBvAQY AQoAJhYhBCEZJX1PwtarpKt8TF3DR9Ldz/WbBQJekVcjAhsMBQkDwmcAAAoJEF3D R9Ldz/WbAFwL/382HsrldVXnkPmJ1E2YEOFz4rcHRetJ+M5H65K/2p32ONQ5KCbE s8MRY6g2CkE70en2HlpDwr/MdATwxBzIjEpjgHbfqCqVVATY+kSpXsttaKKAUVHi bFgV4QkdDJNSpcHEj+bqaggRnuWiV9T6ECG7kQjHiEXPNojzsiaXMDiM5r+acZm6 82id9qOFySQ2cZEy5HbwXM+ITLQGngnppa7du2KdgiqDeqtODOTWZvLYAq2tmEwD 3TT6ttLUBwOOu2IWpDkXswlrk62ESorE5mpLxop9fsxD39E2H06JoC/YfUPIVkEv fj06e7LEdcx0I7kRfD1v6qOUUsMsLZnmyGIk24iFjLkwu1VToWfwXDN1D2+SeAat 9ydNt4M7oEbd1QaOXXjmqpdU+VUiWcBXg+p3/WdV60MkyAgc3x+YanLljy/Rh18h cZwVlinf/tgvAQLi5f9hpwrwUMoGKijEYHKuEvi3C12Si7UVDfuIR7yS0dKcfuKF MbgwdvNXqpD9W5kBjQRekVd4AQwApHVgw2PVlBDpVcyoymUOXFQIJzJ9wRtr6/sG zwv8rrQnUEtOkkna7TDU3/UTj9FUH0gbpAKGNNPaPj5q0dlLIvzxb15r1uvDGaGL MA+8GFaGFnkxzhg0aXrcKZAN0/Zhgi2B7P8oXQuug5mi1JVDkZN5SeCZNOubdQWL 3xz3jEHp3ixj1mdOdvfdWQFR4CVMXt/A6VI2ujLVb3Yalft/c5bbclAgcJQhgDUu NqGYJEJonESNRSd8fEvhNb6cx7+Djd9+Wyctr76mwOr3nRb1N1OGhFxWjIroUpfz b+6y3oQjT58cJA1ZHqmJ6UlZd81hNNd9KWpbDVwONEPpiqPzfSaonxuqQa0/Cy4W 403OhfoLM/1ZDqD4YrJ/rpyNEfSSdqptWiY0KeErLOYng7rStW/4ZeZVj6b2xxB2 Oas/Z1QYfJyFUki9vaJ5IyN6Y7nVdSP6mbAQC9ESh+VPvRUMpYi4pMGK4rweBVHu oMRRwzk7W5zVIgd425WUe3eCQFn3ABEBAAG0K0VTQ0FQRSBST09NIDxFU0NBUEFF REVTQEZST01USEVNQUNISU5FLk9SRz6JAdQEEwEKAD4WIQTvnDJqcmqzlF87/t82 pJ91j4NOaAUCXpFXeAIbAwUJA8JnAAULCQgHAgYVCgkICwIEFgIDAQIeAQIXgAAK CRA2pJ91j4NOaJVjC/4oo5yCHe7M2h1DiTXVcLI5rXQ1feY7B1feg+YJX/mI4+EV xjC/y5VVpV4syJk5GGZNXhKPHiGLaBYvglTlYOJ98RSEsHrwT3go6S8ZVvMNdP5v CEncn2vm5JGnp4k26PuOzMcJioQLOoUjWtcPFis3gG+ueH3NcPZ22oZUql2xuerh TQZegGp+jJ7bdxwYElx5jDDDkh196d5nlO2ZKENl0ZDp4GAzRNjnQ7KBV6R74J3U cLQDWY8vAFaRBZXIC5XtSzj9lr+jWgvxz7Il51+26VDTEtSafZ2uZfCOFk7GrzJg
sneak preview
now linking to the next page ... in the discussion:
https://fromthemachine.org/2017/08/waiting-for-that-green-light.html
-
-
fromthemachine.org fromthemachine.orgJOHN7171
-
Unless otherwise indicated, this work was written between the Christmas and Easter seasons of 2017 and 2020(A). The content of this page is released to the public under the GNU GPL v2.0 license; additionally any reproduction or derivation of the work must be attributed to the author, Adam Marshall Dobrin along with a link back to this website, fromthemachine dotty org. That's a "." not "dotty" ... it's to stop SPAMmers. :/ This document is "living" and I don't just mean in the Jeffersonian sense. It's more alive in the "Mayflower's and June Doors ..." living Ethereum contract sense [and literally just as close to the Depp/Caster/Paglen (and honorably PK] 'D-hath Transundancesense of the ... new meaning; as it is now published on Rinkeby, in "living contract" form. It is subject to change; without notice anywhere but here--and there--in the original spirit of the GPL 2.0. We are "one step closer to God" ... and do see that in that I mean ... it is a very real fusion of this document and the "spirit of my life" as well as the Spirit's of Kerouac's America and Vonnegut's Martian Mars and my Venutian Hotel ... and *my fusion* of Guy-A and GAIA; and the Spirit of the Earth .. and of course the God given and signed liberties in the Constitution of the United States of America. It is by and through my hand that this document and our X Commandments link to the Bill or Rights, and this story about an Exodus from slavery that literally begins here, in the post-apocalyptic American hartland. Written ... this day ... April 14, 2020 (hey, is this HADAD DAY?) ... in Margate FL, USA. For "official used-to-v TAX day" tomorrow, I'm going to add the "immultible incarnite pen" ... if added to the living "doc/app"--see is the DAO, the way--will initi8 the special secret "hidden level" .. we've all been looking for. Nor do just mean this website or the totality of my written works; nor do I only mean ... this particular derivation of the GPL 2.0+ modifications I continually source ... must be "from this website." I also mean *the thing* that is built from ... bits and piece of blocks of sand-toys; from Ethereum and from Rust and from our hands and eyes working together ... from this place, this cornerstone of the message that is ... written from brick and mortar words and events and people that have come before this poit of the "sealed W" that is this specific page and this time. It's 3:28; just five minutes--or is it four, too layne. This work is not to be redistributed according to the GPL unless all linked media on Youtube and related sites are intact--and historical references to the actual documented history of the art pieces (as I experience/d them) are also available for linking. Wikipedia references must be available for viewing, as well as the exact version of those pages at the time these pieces were written. All references to the Holy Bible must be "linked" (as they are or via ... impromptu in-transit re-linking) to the exact verses and versions of the Bible that I reference. These requirements, as well as the caveat and informational re-introduction to God's DAO above ... should be seen as material modifications to the original GPL2.0 that are retroactively applied to all works distributed under license via this site and all previous e-mails and sites. /s/ wso
and now,
ladies and gentlemen, aesir and cherubim ...
whatever that means; we will continue to look and search for what is the coonection between the GNU 2.0 "the new two point owe" GPL and of course messages from Google and Government regarding Roe v. Wade and "good luck, e"
here we are;
FOSSwire The differences between the GPL, LGPL and the BSD April 6, 2007 Avatar for peter Peter Upfold There are a lot of different open source licences out there, and it can sometimes be a bit confusing if you're not intimate with the details of each one. So here's a quick roundup of three of the most popular licenses and the difference between them.
Just a quick disclaimer - I'm not a lawyer, so don't depend on my explanations on the licences here. All the usual disclaimers apply.
GNU General Public Licence The GNU General Public Licence, or GPL as it's often called, is the most popular free software licence and it's used by many different projects, including the Linux kernel, the GNU tools and literally hundreds of others.
You can find the legal text for the GPL here, but here's a quick summary of what it means.
Basically, you're allowed to use, redistribute and change the software, but any changes you make must also be licensed under the GPL. So that means you have to give everyone else the same rights as you got. Fair's fair, right?
There are also other restrictions and there's quite a nice human-readable version at the Creative Commons site.
The GNU Lesser General Public Licence The LGPL is similar to the GPL, but is more designed for software libraries where you want to allow non-GPL applications to link to your library and utilise it. If you modify the software, you still have to give back the source code, but you are allowed to link it with proprietary stuff without giving the source code to all of that back.
Again, there's a nice friendly look at this on the Creative Commons site.
The BSD Licence In contrast to the GNU licences, the BSD licence is very permissive. Used originally by the BSD operating system, it covers a fair amount of software.
The BSD basically says "here's the source code, do whatever you want with it, but if you have problems, it's your problem". That means you can take BSD'ed code and turn it into a proprietary application if you so wish - there's nothing saying you have to give the code back (although it is nice to do so).
The BSD licence is very small because it is so simple, and often looks like this:
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: * Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. * Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. * Neither the name of the [[whoever]] nor the names of contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
There are also several other licences (the MIT for example) that are similar in spirit to the BSD.
Obviously, that's not all the licences - there are plenty, and developers choose them for different circumstances. Some are restrictive, but preserve the free-ness of the code like the GPL, and some are much more permissive.
The Free Software Foundation call the GPL-style restrictions (you must release any modifications under the same licence) 'copyleft'. Mr Stallman himself has an essay about this and other issues on the GNU site. Bear in mind though, this article does push Stallman's personal views on software licences quite heavily. Take with a pinch of salt if necessary.
Avatar for peterPeter Upfold Tips & TutorialsLicensing/LegalFundamentals HOME » ARTICLES » FOSSwire All articles
-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
The following is the authors’ response to the original reviews.
Reviewer #1
Public Review
Summary:
(1) This work describes a simple mechanical model of worm locomotion, using a series of rigid segments connected by damped torsional springs and immersed in a viscous fluid.
(2) It uses this model to simulate forward crawling movement, as well as omega turns.
Strengths:
(3) The primary strength is in applying a biomechanical model to omega-turn behaviors.
(4) The biomechanics of nematode turning behaviors are relatively less well described and understood than forward crawling.
(5) The model itself may be a useful implementation to other researchers, particularly owing to its simplicity.
Weaknesses:
(6) The strength of the model presented in this work relative to prior approaches is not well supported, and in general, the paper would be improved with a better description of the broader context of existing modeling literature related to undulatory locomotion.
(7) This paper claims to improve on previous approaches to taking body shapes as inputs.
(8) However, the sole nematode model cited aims to do something different, and arguably more significant, which is to use experimentally derived parameters to model both the neural circuits that induce locomotion as well as the biomechanics and to subsequently compare the model to experimental data.
(9) Other modeling approaches do take experimental body kinematics as inputs and use them to produce force fields, however, they are not cited or discussed.
(10) Finally, the overall novelty of the approach is questionable.
(11) A functionally similar approach was developed in 2012 to describe worm locomotion in lattices (Majmudar, 2012, Roy. Soc. Int.), which is not discussed and would provide an interesting comparison and needed context.
9-11: The paper you recommended and our manuscript have some similarities and differences.
Similarities
Firstly, the components constituting the worm are similar in both models. ElegansBot models the worm as a chain of n rods, while the study by Majmudar et al. (2012) models it as a chain of n beads. Each bead in the Majmudar et al. model has a directional vector, making it very similar to ElegansBot's rod. However, there's a notable difference: in the Majmudar et al. model, each bead has an area for detecting contact between the obstacle and the bead, while in ElegansBot, the rod does not feature such an area.
Secondly, the types of forces and torques acting on the components constituting the worm are similar. Each rod in ElegansBot receives frictional force, muscle force, and joint force. Each bead in the Majmudar et al. model receives a constraint force, viscous force, and a repulsive force from obstacles. Each rod in ElegansBot receives frictional torque, muscle torque, and joint torque. Each bead in the Majmudar et al. model receives elastic torque, constraint torque, drive torque, and viscous torque. The Majmudar et al. model's constraint force and torque are similar to ElegansBot's joint force and torque in that they prevent two connected components of the worm from separating. The Majmudar et al. model's viscous force and torque are similar to ElegansBot's frictional force and torque in that they are forces exchanged between the worm and its surrounding environment (ground surface). The Majmudar et al. model's drive torque is similar to ElegansBot's muscle force and muscle torque as a cause of the worm's motion. However, unlike ElegansBot, the Majmudar et al. model did not consider the force generating the drive torque, and there are differences in how each force and torque is calculated. This will be discussed in more detail below.
Differences
Firstly, the medium in which the worm locomotes is different. ElegansBot is a model describing motion in a homogeneous medium like agar or water without obstacles, while the Majmudar et al. model describes motion in water with circular obstacles fixed at each lattice point. This is because the purposes of the models are different. ElegansBot analyzes locomotion patterns based on the friction coefficient, while the Majmudar et al. model analyzes locomotion patterns based on the characteristics of the obstacle lattice, such as the distance between obstacles. Also, for this reason, the Majmudar et al. model's bead, unlike ElegansBot's rod, receives a repulsive force from obstacles.
Secondly, the specific methods of calculating similar types of forces differ. ElegansBot calculates joint forces by substituting frictional forces, muscle forces, frictional torques, and muscle torques into an equation derived from differentiating a boundary condition equation twice over time, where two neighboring rods always meet at one point. This involves determining the process through which various forces and torques are transmitted across the worm. Specifically, it entails calculating how the frictional forces and torques, as well as the muscle forces and torques acting on each rod, are distributed throughout the entire length of the worm. In contrast, The Majmudar et al. model uses Lagrange multipliers method based on a boundary condition that the curve length determined by each bead's tangential angle does not change, to calculate the constraint force and torque before calculating the drive torque and viscous force. This implies that the Majmudar et al. model did not consider the mechanism by which the drive torque and viscous force received by one bead are distributed throughout the worm. ElegansBot's rod receives an anisotropic Stokes frictional force from the ground surface, while the Majmudar et al. model considered the frictional force according to the Navier-Stokes equation for incompressible fluid, assuming the fluid velocity at the bead's location as the bead's velocity.
Thirdly, unlike the Majmudar et al. model, ElegansBot considers the inertia of the worm components. Therefore, ElegansBot can simulate regardless of how low or high the ground surface's friction coefficient is. the Majmudar et al. model is not like this.
(12) The idea of applying biomechanical models to describe omega turns in C. elegans is a good one, however, the kinematic basis of the model as used in this paper (the authors do note that the control angle could be connected to a neural model, but don't do so in this work) limits the generation of neuromechanical control hypotheses.
8, 12: We do not agree with the claim that ElegansBot could limit other researchers in generating neuromechanical control hypotheses. The term θ_("ctrl" ,i)^((t) ) used in our model is designed to be replaceable with neuromechanical control in the future.
(13) The model may provide insights into the biomechanics of such behaviors, however, the results described are very minimal and are purely qualitative.
(14-1) Overall, direct comparisons to the experiments are lacking or unclear.
14-1: If you look at the text explaining Fig. 2 and 5 (Fig. 2 and 4 in old version), it directly compares the velocity, wave-number, and period as numerical indicators representing the behavior of the worm, between the experiment and ElegansBot.
(14-2) Furthermore, the paper claims the value of the model is to produce the force fields from a given body shape, but the force fields from omega turns are only pictured qualitatively.
13, 14-2: We gratefully accept the point that our analysis of the omega-turn is qualitative. Therefore, we have conducted additional quantitative analysis on the omega-turn and inserted the results into the new Fig. 4. We have considered the term 'Force field' as referring to the force vector received by each rod. We have created numerical indicators representing various behaviors of the worm and included them in the revised manuscript.
(15) No comparison is made to other behaviors (the force experienced during crawling relative to turning for example might be interesting to consider) and the dependence of the behavior on the model parameters is not explored (for example, how does the omega turn change as the drag coefficients are changed).
Thank you for the great idea. To compare behaviors, first, a clear criterion for distinguishing behaviors is needed. Therefore, we have created a new mathematical definition for behavior classification in the revised manuscript (“Defining Behavioral Categories” in Method). After that, we compared the force and power (energy consuming rate) between each forward locomotion, backward locomotion, and omega-turn (Fig. 4). And in the revised manuscript, we newly analyzed how the turning behavior changes with variations in the friction coefficients in Figs. S4-S7.
(16) If the purpose of this paper is to recapitulate the swim-to-crawl transition with a simple model, and then apply the model to new behaviors, a more detailed analysis of the behavior of the model variables and their dependence on the variables would make for a stronger result.
In our revised manuscript, we have quantitatively analyzed the changes occurring in turning behavior from water to agar, and the results are presented in Figs. S9 and S10.
(17) In some sense, because the model takes kinematics as an input and uses previously established techniques to model mechanics, it is unsurprising that it can reproduce experimentally observed kinematics, however, the forces calculated and the variation of parameters could be of interest.
(18) Relatedly, a justification of why the drag coefficients had to be changed by a factor of 100 should be explored.
(19) Plate conditions are difficult to replicate and the rheology of plates likely depends on a number of factors, but is for example, changes in hydration level likely to produce a 100-fold change in drag? or something more interesting/subtle within the model producing the discrepancy?
18, 19: As mentioned in the paper, we do not know if the friction coefficients in the study of Boyle et al. (2012) and the friction coefficients in the experiment of Stephens et al. (2016) are the same. In our revised manuscript, we have explored more in detail the effects of the friction coefficient's scale factor, and explained why we chose a scale factor of 1/100 (“Proper Selection of Friction Coefficients” in Supplementary Information). In summary, we analyzed the changes in trajectory due to scaling of the friction coefficient, and chose the scale factor 1/100 as it allowed ElegansBot to accurately reproduce the worm's trajectory while also being close to the friction coefficients in the Boyle et al. paper.
(20) Finally, the language used to distinguish different modeling approaches was often unclear.
(21) For example, it was unclear in what sense the model presented in Boyle, 2012 was a "kinetic model" and in many situations, it appeared that the term kinematic might have been more appropriate. Thank you for the feedback. As you pointed it out, we have corrected that part to 'kinematic' in the revised manuscript.
(22) Other phrases like "frictional forces caused by the tension of its muscles" were unclear at first glance, and might benefit from revision and more canonical usage of terms.
We agree that the expression may not be immediately clear. This is due to the word limit for the abstract (the abstract of eLife VOR should be under 200 words, and our paper's abstract is 198 words), which forced us to convey the causality in a limited number of words. Therefore, although we will not change the abstract, the expression in question means that the muscle tension, which is the cause of the worm's locomotion, ultimately generates the frictional force between the worm and the ground surface.
Recommendations For The Authors
(23) As I stated in my public review, I think the paper could be made much stronger if a more detailed exploration of turning mechanics was presented.
(24) Relatedly, rather than restricting the analysis to individual videos of turning behaviors, I wonder if a parameterized model of the turning kinematics would be fruitful to study, to try to understand how different turning gaits might be more or less energetically favorable.
We thank the reviewer once again for their suggestion. Thanks to their proposal, we were able to conduct additional quantitative analysis on turning behavior.
Reviewer #2
Public Review
Summary:
(1) Developing a mechanical model of C. elegans is difficult to do from basic principles because it moves at a low (but not very small) Reynolds number, is itself visco-elastic, and often is measured moving at a solid/liquid interface.
(2) The ElegansBot is a good first step at a kinetic model that reproduces a wide range of C. elegans motiliy behavior.
Strengths: (3) The model is general due to its simplicity and likely useful for various undulatory movements.
(4) The model reproduces experimental movement data using realistic physical parameters (e.g. drags, forces, etc).
(5) The model is predictive (semi?) as shown in the liquid-to-solid gait transition.
(6) The model is straightforward in implementation and so likely is adaptable to modification and addition of control circuits.
Weaknesses:
(7) Since the inputs to the model are the actual shape changes in time, parameterized as angles (or curvature), the ability of the model to reproduce a realistic facsimile of C. elegans motion is not really a huge surprise. (8) The authors do not include some important physical parameters in the model and should explain in the text these assumptions.
(9. 1) The cuticle stiffness is significant and has been measured [1].
(10. 2) The body of C. elegans is under high hydrostatic pressure which adds an additional stiffness [2].
(11. 3) The visco-elasticity of C. elegans body has been measured. [3]
Thank you for asking. The stiffness of C. elegans is an important consideration. We took this into account when creating ElegansBot, but did not explain it in the paper. The detailed explanation is as follows. C. elegans indeed has stiffness due to its cuticle and internal pressure. This stiffness is treated as a passive elastic force (elastic force term of lateral passive body force) in the paper of Boyle et al. (2012). However, the maximum spring constant of the passive elastic force is 1/20 of the maximum spring constant of the active elastic force. If we consider this fact in our model, the elastic term of the muscle torque
 is as follows: (
is as follows: ( is the active torque elasticity coefficient,
is the active torque elasticity coefficient,  is the passive torque elasticity coefficient)
is the passive torque elasticity coefficient)
where

Therefore, there is no need to describe the active and passive terms separately in

Furthermore, since
 , assuming
, assuming  , then
, then  and
and  .
.(12) There is only a very brief mention of proprioception.
(13) The lack of inclusion of proprioception in the model should be mentioned and referenced in more detail in my opinion.
As you emphasized, proprioception is an important aspect in the study of C. elegans' locomotion. In our paper, its importance is briefly introduced with a sentence each in the introduction and discussion. However, our research is a model about the process of the creation of body motion originated from muscle forces, and it does not model the sensory system that senses body posture. Therefore, there is no mention of using proprioception in our paper's results section. What is mentioned in the discussion is that ElegansBot can be applied as the kinetic body model part in a combination model of a kinetic body model and a neuronal circuit model that receives proprioception as a sensory signal.
(14) These are just suggested references.
(15) There may be more relevant ones available.
The papers you provided contain specific information about the Young's modulus of the C. elegans body. The first paper (Rahimi et al., 2022) measured the Young's modulus of the cuticle after chemically isolating it from C. elegans, while the second paper (Park et al., 2007) and third paper (Backholm et al., 2013) measured the elasticity and Young's modulus of C. elegans without separating the cuticle. Based on the Young's modulus provided in each paper (although the second and third papers did not measure stiffness in the longitudinal direction), we derived the elastic coefficient (assuming a worm radius of 25 μm, cuticle thickness of 0.5 μm, and 1/25 of longitudinal length of the cuticle of 40 μm). The range was quite broad, from 9.82ⅹ1011 μg/sec2 (from the first paper) to 2.16 ⅹ 108 μg / sec2 (from the third paper). Although the elastic coefficient value in our paper falls within this range, since the range of the elastic coefficient is wide, we think we can modify the elastic coefficient in our paper and will be able to reapply our model if more accurate values become known in the future.
Reviewer #3
Public Review
Summary:
(1) A mechanical model is used with input force patterns to generate output curvature patterns, corresponding to a number of different locomotion behaviors in C. elegans
Strengths:
(2) The use of a mechanical model to study a variety of locomotor sequences and the grounding in empirical data are strengths.
(3) The matching of speeds (though qualitative and shown only on agar) is a strength.
Weaknesses:
(4) What is the relation between input and output data?
ElegansBot takes the worm's body control angle as the input, and produces trajectory and force of each segment of the worm as the output.
(5) How does the input-output relation depend on the parameters of the model?
If 'parameter' is understood as vertical and horizontal friction coefficients, then the explanation for this can be found in Fig. 5 (Fig. 4 in the old version).
(6) What biological questions are addressed and can significant model predictions be made?
Equation of motion deciphering locomotion of C. elegans including turning behaviors which were relatively less well understood.
Recommendations For The Authors
(7) The novelty and significance of the paper should be clarified.
We have added quantitative analyses of turning behavior in the revised manuscript, and we hope this will be helpful to you.
(8) Previously much more detailed models have been published, as compared to this one.
We hope the reviewer can point out any previous model that we may have missed.
(9) The mechanics here are simplified (e.g. no information about dorsal/ventral innervation but only a bending angle) setting limitations on the capacity for model predictiveness.
(10) Such limitations should be discussed.
We view the difference between dorsal/ventral innervation and bending angle not as a matter of simplification, but rather as a reflection of the hierarchy that our model implements. Our model does not consider dorsal/ventral innervation, but it uses the bending angle to reproduce behavior in various input and frictional environments, which signifies the strong predictiveness of ElegansBot (Figure 2, 3, 5 (2, 3, 4 in the old version)). Moreover, if the midline of C. elegans is incompressible, then modeling by dividing into dorsal/ventral, as opposed to modeling solely with the bending angle, does not increase the degree of freedom of the worm model, and therefore does not increase its predictiveness.
(11) The aims of the paper and results need to be supported quantitatively and analyzed through parameter sweeps and intervention.
We have conducted additional quantitative analyses on turning behavior as suggested by Reviewer #1 (Fig. 4, S4-S7, S9, and S10).
(12) The methods are given only in broad brushstrokes, and need to be much more clear (and ideally sharing all code).
We have thoroughly detailed every aspect of this research, from deriving the physical constants of C. elegans, agar, and water to developing the formulas and proofs necessary for operating ElegansBot and its applications. This comprehensive information is all presented in the Results, Methods, and Supplementary Information sections, as well as in the source code. Moreover, we have already ensured that our research can be easily reproduced by providing detailed explanations and by making ElegansBot accessible through public software databases (PyPI, GitHub). To further aid in its application and understanding, especially for those less familiar with the subject, we have also included minimal code as examples in the database. This code is designed to simplify the process of reproducing the results of the paper, thereby making our research more accessible and understandable. Therefore, we believe that readers will easily gain significant assistance from the extensive information we have provided. Should readers require further help, they can always contact us, and we will be readily available to offer support.
(13) The supporting figures and movies need to include a detailed analysis to evidence the claims.
We have conducted and provided additional quantitative analyses on turning behavior as suggested by Reviewer #1 (Fig. 4, S4-S7, S9, and S10).
-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
The following is the authors’ response to the original reviews.
eLife assessment
In this study, the authors develop a useful strategy for fluorophore-tagging endogenous proteins in human induced pluripotent stem cells (iPSCs) using a split mNeonGreen approach. Experimentally, the methods are solid, and the data presented support the author's conclusions. Overall, these methodologies should be useful to a wide audience of cell biologists who want to study protein localization and dynamics at endogenous levels in iPSCs.
Public Reviews:
Reviewer #1 (Public Review):
Summary:
In this manuscript, the authors have applied an asymmetric split mNeonGreen2 (mNG2) system to human iPSCs. Integrating a constitutively expressed long fragment of mNG2 at the AAVS1 locus, allows other proteins to be tagged through the use of available ssODN donors. This removes the need to generate long AAV donors for tagging, thus greatly facilitating high-throughput tagging efforts. The authors then demonstrate the feasibility of the method by successfully tagging 9 markers expressed in iPSC at various, and one expressed upon endoderm differentiation. Several additional differentiation markers were also successfully tagged but not subsequently tested for expression/visibility. As one might expect for high-throughput tagging, a few proteins, while successfully tagged at the genomic level, failed to be visible. Finally, to demonstrate the utility of the tagged cells, the authors isolated clones with genes relevant to cytokinesis tagged, and together with an AI to enhance signal-to-noise ratios, monitored their localization over cell division.
Strengths:
Characterization of the mNG2 tagged parental iPSC line was well and carefully done including validation of a single integration, the presence of markers for continued pluripotency, selected offtarget analysis, and G-banding-based structural rearrangement detection.
The ability to tag proteins with simple ssODNs in iPSC capable of multi-lineage differentiation will undoubtedly be useful for localization tracking and reporter line generation.
Validation of clone genotypes was carefully performed and highlights the continued need for caution with regard to editing outcomes.
Weaknesses:
IF and flow cytometry figures lack quantification and information on replication. How consistent is the brightness and localization of the markers? How representative are the specific images? Stability is mentioned in the text but data on the stability of expression/brightness is not shown.
To address this comment, we have quantified the mean fluorescence intensity of the tagged cell populations in Fig. S3B-T. This data correlates well with the expected expression levels of each gene relative to the others (Fig. S3A), apart from CDH1 and RACGAP1, which are described in the discussion.
The images in Fig. 2 show tagged populations enriched by FACS so they are non-clonal and are representative of the diversity of the population of tagged cells.
The images shown in Fig. 3 are representative of the clonal tagged populations. The stability of the tag was not quantified directly. However, the fluorescence intensity was very stable across cells in clonal populations. Since these populations were recovered from a single cell and grown for several weeks, this low variability across cells in a population suggests that these tags are stable.
The localization of markers, while consistent with expectations, is not validated by a second technique such as antibody staining, and in many cases not even with Hoechst to show nuclear vs cytoplasmic.
We find that the localization of each protein is distinct and consistent with previous studies. To address this comment, we have added an overlay of the green fluorescence images with brightfield images to better show the location of the tagged protein relative to the nuclei and cytoplasm. We have also added references to other studies that showed the same localization patterns for these proteins in iPSCs and other relevant cell lines.
For the multi-germ layer differentiation validation, NCAM is also expressed by ectoderm, so isn't a good solo marker for mesoderm as it was used. Indeed, the kit used for the differentiation suggests Brachyury combined with either NCAM or CXCR4, not NCAM alone.
Since Brachyury is the most common mesodermal marker, we first tested differentiation using anti-Brachyury antibodies, but they did not work well for flow cytometry. We then switched to anti-NCAM antibodies. Since we used a kit for directed differentiation of iPSCs into the mesodermal lineage, NCAM staining should still report for successful differentiation. In the context of mixed differentiation experiments (embryoid body formation or teratoma assay), NCAM would not differentiate between ectoderm and mesoderm. The parental cells (201B7) have also been edited at the AAVS1 locus in multiple other studies, with no effect on their differentiation potential.
Only a single female parental line has been generated and characterized. It would have been useful to have several lines and both male and female to allow sex differences to be explored.
We agree that it would be interesting (and important) to study differences in protein localization between female and male cell types, and from different individuals with different genetic backgrounds. We see our tool as opening a door for cell biology to move away from randomly collected, transformed, differentiated cell types to more directed comparative studies of distinct normal cell types. Since few studies of cell biological processes have been done in normal cells, a first step is to understand how processes compare in an isogenic background, then future studies can reveal how they compare with other individuals and sexes. We hope that either our group or others will continue to build similar lines so that these studies can be done.
The AI-based signal-to-noise enhancement needs more details and testing. Such models can introduce strong assumptions and thus artefacts into the resolved data. Was the model trained on all markers or were multiple models trained on a single marker each? For example, if trained to enhance a single marker (or co-localized group of markers), it could introduce artefacts where it forces signal localization to those areas even for others. What happens if you feed in images with scrambled pixel locations, does it still say the structures are where the training data says they should be? What about markers with different localization from the training set? If you feed those in, does it force them to the location expected by the training data or does it retain their differential true localization and simply enhance the signal?
The image restoration neural network was used as in Weigert et al., 2018. The model was trained independently for each marker. Each trained model was used only on the corresponding marker and with the same imaging conditions as the training images. From visual inspection, the fluorescent signal in the restored images was consistent with the signal in the raw images, both for interphase and mitotic cells. We found very few artefacts of the restoration (small bright or dark areas) that were discarded. We did not try to restore scrambled images or images of mismatched markers.
Reviewer #2 (Public Review):
Summary:
The authors have generated human iPSC cells constitutively expressing the mNG21-10 and tested them by endogenous tagging multiple genes with mNG211 (several tagged iPS cell lines clones were isolated). With this tool, they have explored several weakly expressed cytokinesis genes and gained insights into how cytokinesis occurs.
Strengths:
Human iPSC cells are used.
Weaknesses:
i) The manuscript is extremely incremental, no improvements are present in the split-fluorescent (split-FP) protein variant used nor in the approach for endogenous tagging with split-FPs (both of them are already very well established and used in literature as well as in different cell types).
Although split fluorescent proteins and the endogenous tagging methodology had been developed previously, their use in human stem cells has not been explored. We argue that human iPSCs are a valuable model for cell biologists to study cellular processes in differentiating cells in an isogenic context for proper comparison. Many normal human cell types have not been studied at the cellular/subcellular level, and this tool will enable those studies. Importantly, other existing cell lines required transformation to persist in culture and represent a single, differentiated cell type that is not normal. Moreover, the protocols that we developed along with this methodology (e.g. workflows for iPSC clonal isolation that include automated colony screening and Nanopore sequencing) will be useful to other groups undertaking gene editing in human cells. Therefore, we argue that our work opens new doors for future cell biology studies.
ii) The fluorescence intensity of the split mNeonGreen appears rather low, for example in Figure 2C the H2BC11, ANLN, SOX2, and TUBB3 signals are very noisy (differences between the structures observed are almost absent). For low-expression targets, this is an important limitation. This is also stated by the authors but image restoration could not be the best solution since a lot of biologically relevant information will be lost anyway.
The split mNeonGreen tag is one of the brighter fluorescent proteins that is available. The low expression that the reviewer refers to for H2BC11, ANLN, TUBB3 and SOX2 is expected based on their predicted expression levels. Further, these images were taken with cells in dishes using lower resolution imaging and were not intended to be used for quantification. As shown in the images in Figures 3H, when using a different microscope with different optical settings and higher magnification, the localization is very clear and quantifiable without needing to use restoration (e.g., compare H2BC11 and ANLN). Using microscopes with high NA objectives, lasers and EMCCD or sCMOS cameras with high sensitivity can sufficiently detect levels of very weakly expressing proteins that can be quantified above background and compared across cells. It is worth noting that each tag may be studied in very different contexts. For example, ANLN will be useful for studies of cytokinesis, while the loss of SOX2 expression and gain of TUBB3 expression may be used to screen for differentiation rather than for localization per se. The reason for endogenous tagging is to study proteins at their native levels rather than using over-expression or fixation with antibodies where artefacts can be introduced. Endogenous tags tag will also enable studies of dynamic changes in localization during differentiation in an isogenic background as described previously.
Importantly, image restoration is not required to image any of these probes! We use it to demonstrate how a researcher can increase the temporal resolution of imaging weakly-expressed proteins for extended periods of time. This data can be used to compare patterns of localization and reveal how patterns change with time and during differentiation. Imaging with fewer timepoints and altered optical settings will still permit researchers to extract quantifiable information from the raw data without requiring image restoration.
iii) There is no comparison with other existing split-FP variants, methods, or imaging and it is unclear what the advantages of the system are.
We are not sure what the reviewer means by this comment. In the future, we plan to incorporate an additional split-FP variant (e.g., split sfCherry) in this iPSC line to enable the imaging of more than one protein in the same cell. However, the split mNeonGreen system is still amenable for use with dyes with different fluorescence spectra that can mark other cellular components, especially for imaging over shorter timespans. In addition to tagging efficiency, the main advantage of split FPs is its scale, as demonstrated by the OpenCell project by tagging 1,310 proteins endogenously (Cho et al., 2022). We developed protocols that facilitate the identification of edited cell lines with high throughput. We also used multiple imaging methods throughout the study that relied on the use of different microscopes and flow cytometry, demonstrating the flexibility of this tagging system. Even for more weakly expressing proteins, the probe could be sufficiently visualized by multiple systems. Such endogenous tags can be used for everything from simply knowing when cells have differentiated (e.g., loss of SOX2 expression, gain of differentiation markers), to studying biological processes over a range of timescales.
Reviewer #3 (Public Review):
The authors report on the engineering of an induced Pluripotent Stem Cell (iPSC) line that harbours a single copy of a split mNeonGreen, mNG2(1-10). This cell line is subsequently used to take endogenous protein with a smaller part of mNeonGreen, mNG2(11), enabling the complementation of mNG into a fluorescent protein that is then used to visualize the protein. The parental cell is validated and used to construct several iPSC lines with endogenously tagged proteins. These are used to visualize and quantify endogenous protein localisation during mitosis.
I see the advantage of tagging endogenous loci with small fragments, but the complementation strategy has disadvantages that deserve some attention. One potential issue is the level of the mNG2(1-10). Is it clear that the current level is saturating? Based on the data in Figure S3, the expression levels and fluorescence intensity levels show a similar dose-dependency which is reassuring, but not definitive proof that all the mNG2(11)-tagged protein is detected.
We have not quantified the levels of mNG21-10 expression directly. However, the increase in fluorescence observed with highly expressed proteins (e.g., ACTB) supports that mNG21-10 levels must be sufficiently high to permit differences among endogenous proteins with vastly different expression levels. To ensure high expression, we used a previously validated expression system comprised of the CAG promoter integrated at the AAVS1 locus, which has previously been used to provide high and stable transgene expression (e.g. Oceguera-Yanez et al., 2016). We acknowledge that it is difficult to confirm that all of the endogenous mNG211-tagged protein is ‘detectable’.
Do the authors see a difference in fluorescence intensity for homo- and heterozygous cell lines that have the same protein tagged with mNG2(11)? One would expect two-fold differences, or not?
To answer this question, we measured the fluorescence intensity of homozygous and heterozygous clones carrying smNG2-anillin and smNG2-RhoA. We found homozygous clones that were approximately twice as bright as the corresponding heterozygous clones (Fig. S4H and I). This suggests that the complementation between mNG21-10 and mNG211 occurs efficiently over a range of mNG211 expression, since anillin is expressed weakly and RhoA is expressed more strongly in iPSCs. However, we also observed some homozygous clones that were not brighter than the corresponding heterozygous clones, which could be due to undetected byproducts of CRISPR or clonal variation in protein expression.
Related to this, would it be favourable to have a homozygous line for expressing mNG2(1-10)?
Our heterozygous cell line leaves the other AAVS1 allele available for integrations of other transgenes for future experiments. While a homozygous line could express more mNG2(1-10), it does not seem to be rate-limiting even with a highly-expressed protein like beta-actin, and we are not sure that it is necessary. The value gained by having the free allele could outweigh the difference in mNG2(1-10) levels.
The complementation seems to work well for the proteins that are tested. Would this also work for secreted (or other organelle-resident) proteins, for which the mNG2(11) tag is localised in a membrane-enclosed compartment?
The interaction between the 1-10 and 11 fragments is strong and should be retained when proteins are secreted. It was recently shown that secreted proteins tagged with GFP11 can be detected when interacting with GFP1-10 in the extracellular space, albeit using over-expression (Minegishi et al., 2023). However, in our work, the mNG21-10 fragment is cytosolic and we have only explored proteins localized to the nucleus or the cytoplasm similar to Cho et al., (2022). By GO annotation, 75% of human proteins are present in the cytoplasm and/or nucleus, which still covers a wide range of proteins of interest. Future versions of our line could include incorporating organelle-targeting peptides to drive the large fragment to specific, non-cytosolic locations.
The authors present a technological advance and it would be great if others could benefit from this as well by having access to the cell lines.
As discussed below, some of the resources are already available, and we are working to make the mNG21-10 cell line available for distribution.
Recommendations for the authors:
Reviewer #2 (Recommendations For The Authors):
The manuscript is methodological, the main achievement is the generation of a stable iPSC with the split Neon system available for the scientific community. Although it is technically solid, the judgement of this reviewer is that the manuscript should be considered for a more specialised/methodological/resource-based journal.
Indeed, we have submitted this article under the “tools and resources” category of eLife, which publishes methodology-centered papers of high technical quality. We felt this was a good venue for the audience that it can reach compared to more specialized journals that may be more limited in scope. For example, our system will be a useful resource for cell biologists and they are more likely to see it in eLife compared to more specialized journals.
Reviewer #3 (Recommendations For The Authors):
(1) The authors present a technological advance and it would be great if others can benefit from this as well. Therefore access to the materials (and data) would be valuable (the authors do a great job by listing all the repair templates and primers).
We have added several pieces of data and information to the supplementary materials, as described below.
For instance:
What is the (complete/plasmid) sequence of the AAVS1-mNG2(1-10) repair plasmid? Will it be deposited at Addgene?
The plasmids used in this paper are now available on Addgene, along with their sequences [ID 206042 for pAAVS1-Puro-CAG-mNG2(1-10) and 206043 for pH2B-mNG2(11)].
The ImageJ code for the detection of colonies is interesting and potentially valuable. Will the code be shared (e.g. at Github, or as supplemental text)?
The ImageJ macro has been uploaded to the CMCI Github page (https://github.com/CMCI/colony_screening). The parameters are optimized to perform segmentation on images obtained using a Cytation5 microscope with our specific settings, but they can be tweaked for any other sets of images. The following text has been added to the methods section: “The code for this macro is available on Github (https://github.com/CMCI/colony_screening)”.
The cell line with the mNG2(1-10) as well as other cell lines can be of interest to others. Will the cell lines be made available? If so, can the authors indicate how?
We are in the process of depositing our cell line in a public repository. This process may take some time for quality control. For now, the cells can be made available by requesting them from the corresponding authors.
(2) How well does the ImageJ macro for detection of the colonies in the well work? Is there any comparison of analysis by a human vs. the macro?
In our most recent experiment, the colony screening macro correctly identified 99.5% of wells compared to manual annotation (83/84 positive wells and 108/108 negative wells). For each 96-well plate, imaging takes 25 minutes, and it takes 7 minutes for analysis. Despite a few false negatives, we expect this macro to be useful for large-scale experiments where multiple 96-well plates need to be screened, which would take hours manually.
(3) The CDH labeling was not readily detected by FACS, but was visible by microscopy. Is the labeling potentially disturbed by the procedure (low extracellular calcium + trypsin?) to prepare the cell for FACS?
It is not clear why the CDH labelling was not detected by FACS. As the reviewer suggests, there could be several reasons: E-cadherin could be broken down by the dissociation reagent (Accutase), or recycled into the cell following the loss of adhesion and the low extracellular calcium in PBS. However, the C-terminal intracellular tail of E-cadherin was tagged, which should not be affected by Accutase. Moreover, recycling into the cell should still result in a detectable fluorescent signal. Notably, the flow cytometry experiments were done as quickly as possible after dissociation to minimize the time that E-cadherin could be degraded or recycled. We also resuspended the cells in MTeSR Plus media instead of PBS, and compared cells grown on iMatrix511 to those grown on Matrigel in case differences in the extracellular matrix affected Ecadherin expression. Another possibility is that the microscopy used for detection of E-cadherin in cells involved using a sweptfield livescan confocal microscope with high NA objective, 100mW 488nm laser and an EMCCD camera with high sensitivity, and perhaps this combination permitted detection better than the detector on the BD FACSMelody used for FACs.
(4) The authors write that the "Tubulin was cytosolic during interphase" which is surprising (and see also figure 3H), as I was expecting it to be incorporated in microtubules. May this be an issue of insufficient resolution (if I'm right this was imaged with 20x, NA=0.35 and so the resolution could be improved by imaging at higher NA)?
Indeed, as the reviewer points out, our terminology (cytosol vs. microtubule) reflects the low resolution of the imaging for the cell populations in dishes and the individual alpha-tubulin monomers being labelled with the mNG211 tag, which are present as cytoplasmic monomers as well as polymers on microtubules. However, even in this image (Fig. 2C), the mitotic spindle microtubules are visible as they are so robust compared to the interphase microtubules. Notably, when we imaged cells from the cloned tagged cell line using a microscope designed for live imaging with a higher NA objective (see above), endogenous tagged TUBA1B was even more clearly visible in spindle microtubules, and was weakly observed in some microtubules in interphase cells, although they are slightly out of focus (Fig. 3H). If we had focused on a lower focal plane where the interphase cells are located and altered the optical settings, we would see more microtubules.
(5) It would be nice to have access to the Timelapse data as supplemental movies (.e.g from the experiments shown in Figure 4).
We have added the movies corresponding to the timeplase images as supplementary movies (Movies S1-6), with the raw and restored movies shown side-by-side.
(6) In Figure 3B, the order of the colors in the bar is reversed relative to the order of the legend. Would it be possible to use the same order? That makes it easier for me (as a colorblind person) to match the colors in the figure with that of the legend.
We have modified the legend in Fig 2B and 3B to be in the same order as the bars.
-
-
Local file Local file
-
This has led some women to commit to formingtheir own cooperatives. But while the Lutonde case provides valuableinspiration, it is still the only women's mining cooperative in 3TG. Itnevertheless epitomizes the motivation and desire of women in easternDRC, specifically their drive to take advantage of new opportunities inASM and their willingness to position themselves to derive benefitsfrom activities throughout the supply chain
new mining code -new opportunities for women
-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
The following is the authors’ response to the original reviews.
Response to reviewers
We wish to thank the reviewers for the time taken to appraise the manuscript and the helpful feedback to improve it. We have taken onboard the suggested feedback and incorporated it into the revision. The findings of the revised manuscript are unchanged. Below is a point-by-point response to specific comments.
Public reviews
Reviewer 1
Thank you to reviewer 1 for the thorough and insightful review of our manuscript. We are pleased that the strengths of our research, particularly the use of whole-genome bisulfite sequencing, the combination of animal and human data, and the investigation of a potential dietary intervention were recognized. We are confident that these aspects contribute significantly to the value and originality of our work.
We acknowledge the concerns regarding the statistical rigor of the study, particularly the sample size and data analysis methods. We would like to address these points in more detail:
Sample size: While we agree that a larger sample size would be ideal, the chosen sample size (n=4 per group) is consistent with other murine whole-genome bisulfite sequencing experiments in the field. We have carefully considered the cost-benefit trade-off in selecting this approach. In the revision we discuss the potential limitations of this sample size.
Data analysis: We acknowledge the inconsistencies in the study reporting and have committed to improving the clarity in the revision. We carefully reviewed the concerns regarding the use of causal language and the interpretation of differences in our results. In some cases, the use of causal language is justified by the intervention study design. We also believe other explanations like stochastic variation affecting the same genomic regions in different tissues, are exceedingly unlikely from a statistical viewpoint. In the revision we have adopted a balanced approach to the language.
Confounders: We acknowledge the importance of accounting for potential confounders such as birthweight, alcohol exposure and sex. The pups selected for genome analysis were matched for sex and on litter size as a proxy for in utero alcohol exposure. This careful selection of mice for genome analysis was intentionally guided to mitigate potential confounding.
Statistical rigour: We acknowledge the importance of multiple testing correction in the genome-wide analysis. We used the DSS method of Feng et al (PMID: 2456180) which employs a two-step procedure for assessing significance of a region. Instead of a single p-value for the whole DMR, DSS uses the area statistic to rank candidate regions and control the false discovery rate through shrinkage estimation methods. This approach reduces the risk of reporting false positives due to multiple testing across numerous CpG sites. It is similar in respects to employing local FDR correction at 0.05 level, with an additional minimum effect size threshold applied, and particularly suited to experiments where the number of replicates is low. In the revision we have committed to improving the clarity of the reporting of statistical methods.
Reviewer 2
Thank you to reviewer 2 for the comprehensive and valuable feedback on our manuscript. We take your concerns about the generalizability of our findings and the interpretation of certain results seriously. We would like to address your specific criticisms in detail:
Generalizability and Human Data: We agree that the generalizability of mouse models to human conditions has limitations. However, our study focused on understanding the early molecular alterations caused by moderate PAE, which can be more effectively modelled in a controlled environment like mice. To clarify this, we have strengthened the manuscript by emphasizing the focus on moderate PAE in the title and throughout the paper.
Transcriptome Analysis: We recognize the importance of investigating the functional consequences of PAE-induced DMRs and agree that transcriptome analysis would be highly valuable. We are currently planning to conduct future transcriptomic studies to understand the link between DMRs and gene expression.
Species-Specificity and DMR Enrichment: We acknowledge the likelihood of species-specific PAE effects. Our finding of enrichment of DMRs in non-coding regions was consistent with observations from the Lussier study of FASD. We agree there is further work to do and now highlight this in the discussion.
Tissue Sample Locations: Due to technical restrictions of processing newborn mouse tissue, we are unable to enhance the manuscript with specific tissue regions sampled.
Interpretation of Shared Genomic Regions: We appreciate your point about the alternative explanation for the shared genomic regions between brain and liver. Our interpretation is that regions identified in the alcohol group only affected equally in both tissues are likely established stochastically (as a result of the exposure) in the early embryo and then maintained in the germ layers. We have revised to suggest this is the most likely explanation and we acknowledge a more detailed examination in more tissues would be warranted for proof.
Additional Feedback
Reviewer 1
Introduction
- Line 65 - alcohol consumption is not always preventable and these statements further increase the stigma associated with FASD. A better way to say this would be "a leading cause of neurodevelopmental impairments".
We have implemented this suggestion in revised manuscript.
- The studies cited in lines 87-89 are somewhat outdated, as several more recent studies with better sample sizes have been published in recent years. I would recommend citing more recent publications in addition to these studies. Similarly, the authors should also cite Portales-Casamar et al., 2016 (Epigenetic & Chromatin) for the validation in humans, as it was the original study for those data.
We have added a citation for the study mentioned by Portales-Casamar et al. (2016) in the revised manuscript.
- Lines 95-95 - the authors should elaborate further on the "encouraging results" from choline supplementation studies, as these details may help interpret the findings from their own study.
In the revised manuscript, we replaced “encouraging results” with “results suggesting a high methyl donor diet (HMD) could at least partially mitigate the adverse effects of PAE on various behavioural outcomes”.
- Minor point: DNA methylation is preferable to "methylation" alone when not referring to specific CpGs or sites, as methylation can also refer to protein or RNA methylation.
“Methylation” has been replaced with “DNA methylation” in revised manuscript
Results
- Line 118 - HMD should be defined here.
HMD defined in revised manuscript
- The figures in the main manuscript and supplemental materials are not in the same order as they are presented in the text.
We apologise for this and thank the reviwer for their attendtion to detail. In the revision we have corrected the order of figures to match the text.
- It is concerning that the H20-HMD group had lower baseline weights, which could impact the findings from these analyses. Please discuss how these differences were accounted for in the study design and analyses.
We appreciate the reviewer's concern about the lower baseline weight in the H20-HMD group. We agree that this difference could potentially affect our findings. However, we want to emphasize that total weight gain during pregnancy was statistically similar across all groups by linear mixed effect model. Additionally, all dams were within the healthy weight range for their strain. While we cannot completely rule out any potential influence of baseline weight, we believe the similarity in weight gain and the healthy range of all dams suggest that the in-utero experience of pups regarding weight-related factors was likely comparable across groups.
- I have some concerns regarding the cutoffs used to identify the DMRs, particularly given the small N and number of tests. The authors should report the number of DMRs that meet a multiple testing threshold; if none, they should use a more stringent threshold than p<0.05, as one would expect 950,000 CpGs to meet that threshold by chance (19,000,000 CpGs x 0.05). The authors should also report the number of DMRs tested, as this will be a more appropriate benchmark for their analyses than the number of CpGs (they should also report the specific number here).
We appreciate the reviewer's concerns regarding the DMR cut-offs. We agree that clarifying the methods and justifying our choices is crucial. Our implementation of the DSS method for defining DMRs employs a local FDR p<0.05 cut-off, with additional delta beta threshold of 5%. We have clarified this in the methods section of the revised manuscript . We want to emphasize that the local FDR approach effectively mitigates the concern of chance findings by adjusting for multiple comparisons across the genome. Line 414-420 in the revised methods contains the following amended text
“Differentially methylated regions (DMRs) were identified within each tissue using a Bayesian hierarchical model comparing average DNA methylation ratios in each CpG site between PAE and non-PAE mice using the Wald test with smoothing, implemented in the R package DSS (46). False-discovery rate control was achieved through shrinkage estimation methods. We declared DMRs as those with a local FDR P-value < 0.05 based on the p-values of each individual CpG site in the DMR, and minimum mean effect size (delta) of 5%”
- I also have concerns about the delta cutoff for their DMRs. First, it is not clear if this cutoff is set for a single CpG or across the DMR (even then, it is not clear if this is a mean, median, max, min, etc.) Second, since the authors analyzed CpGs with 10X coverage, they can only reliably detect a delta of 0.1 (1/10 reads).
Thank you for raising this important point. In the revision we have clarified the effect size cutoff reflects the mean effect across CpGs within the DMR as follows (line 418)
“We declared DMRs as those with a local FDR P-value < 0.05 based on the p-values of each individual CpG site in the DMR, and minimum mean effect size (delta) of 5%”
We chose the mean as it provides a comprehensive representation of the overall methylation change within the region, while ensuring all individual CpGs used in the analysis had at least 10x coverage. It is not true that we can only detect a delta of 1/10 reads, the mean effect is the relative difference in means between groups and is not dependent on the underlying sequencing depth.
- Prenatal alcohol exposure is known to impact cell type proportions in the brain, which could lead to differences in DNAm patterns. The authors should address this possibility in the discussion, as well as examine their list of DMRs to determine if they are associated with specific brain cell types. The possibility of cell type differences in the liver should also be discussed.
We agree with the reviewer that PAE-induced alterations in cell type proportions can influence DNA methylation patterns. While isolating specific cell types in our current study's brain and liver samples was not achievable due to tissue limitations, we acknowledge this as a limitation and recognize the need for further investigations incorporating single-cell or cell type-specific approaches in the discussion.
- It is interesting, but maybe not surprising, that more DMRs were identified in the liver compared to the brain. This finding would warrant some additional interpretation in the discussion.
We appreciate and agree that this finding indeed warrants further interpretation. We have added the following sentence into the discussion section of the revised manuscript that provides some potential factors behind this observation.
Lines 263 “Indeed, most of the observed effects were tissue-specific, with more perturbations to the epigenome observable in liver tissue, which may reflect the liver’s specific role in metabolic detoxification of alcohol. Alternatively, cell type composition differences between brain and liver might explain differential sensitivity to alcohols effects”.
- Lines 148-149 - I disagree about the enrichment of decreased DNAm in brain DMRs, as 52.6% is essentially random chance. The authors should also include a statistical test here, such as a chi-squared test, to support this statement.
We agree that a revised interpretation is warranted. The updated manuscript has been amended as follows: “Lower DNA methylation with early moderate PAE in NC mice was more frequently observed in liver DMRs (93.5% of liver DMRs), while brain DMRs were almost equally divided between lower and higher DNA methylation with early moderate PAE (52.6% of brain DMRs had lower DNA methylation with early moderate PAE).”
- Similarly, I would recommend the authors use increased/decreased DNAm, rather than hypermethylated/hypomethylation, as the latter terms are better suited to DNAm values near 100% or 0%.
The use of hyper/hypo methylation is still considered common and well understood even for moderate changes. We agree the use of increased/decreased is more inclusive for a broader audience, so we have amended all references accordingly in the main text.
- Lines 153-155 - please report the statistics to support these enrichment results. A permutation test would be well suited to this analysis.
The reporting of statistics related to the enrichment test has now been amended to read “Overlap permutation tests showed liver DMRs were enriched in inter-CpG regions and non-coding intergenic regions (p < 0.05), while being depleted in all CpG regions and genic regions except 1to5kb, 3UTR and 5UTR regions, where there was no significant difference (Figure 2f).”
- Line 156 - "overwhelming enrichment" is a very strong statement considering the numbers themselves.
Omitted “overwhelming” in revised manuscript. Revised manuscript states: “Using open chromatin assay and histone modification datasets from the ENCODE project, we found enrichment (p < 0.05) of DMRs in open chromatin regions (ATAC-seq), enhancer regions (H3K4me1), and active gene promoter regions (H3K27ac), in mouse fetal forebrain tissue and fetal liver (Table 2).”
- Lines 165-167 - Please describe the analyses and metrics used to determine if the DNAm differences were mitigated in the HMD groups. As it stands, it is not clear if they are simply not significant, or if the delta was decreased. In terms of a figure, a scatter plot of the deltas for these DMRs would be better suited to visualizing these changes.
To determine whether DMRs were mitigated we simply applied the same statistical testing procedure on the subset of PAE DMRs in the group of mice exposed to the HM diet. The sample size is the same, and the burden on multiple testing is reduced as we did not test the entire genome. We believe our interpretation stands although we have urged caution in the discussion as follows (line 319)
“Another key finding from this study was that HMD mitigated some of the effects of PAE on DNA methylation. Although a plausible alternative explanation is that some of the PAE regions were not reproduced in the set of mice given the folate diet, our data are consistent with preclinical studies of choline supplementation in rodent models (34, 35) (36). Moreover, a subset of PAE regions were statistically replicated in subjects with FASD, suggestive or robust associations. Although our findings should be interpreted with caution, they collectively support the notion that alcohol induced perturbation of epigenetic regulation may occur, at least in part, through disruption of the one-carbon metabolism.”
- Given the lenient threshold to identify DMRs, it is possible that PAE-associated DMRs are simply false positives and do not "replicate" in a different subset of animals. One way to check this would be to determine whether there are any differences between mitigated/unmitigated DMRs and the strength of their initial associations. Should the mitigated DMRs skew towards higher p-values and lower deltas, one might consider that these findings could be false positives.
We appreciate the reviewer's concern about potential false positives due to the chosen DMR identification threshold. We reiterate the DMR calling thresholds were adjusted for local FDR; however, we acknowledge the need for further validation. We haven't observed this trend of mitigated DMRs having higher p-values and lower deltas, but we have replicated some PAE DMRs in independent human datasets and found support for their biological plausibility in the context of PAE.
- Related to the HMD analyses, I am concerned that the EtOH-HMD group consumed less alcohol, which could manifest in the PAE-induced DMRs disappearing, unrelated to the HMD exposure. The authors should comment on whether the pups were matched for ethanol exposure and include sensitivity analyses that include ethanol level as a covariate to confirm that their results are not simply due to decreased alcohol exposure.
We appreciate the reviewer's concern regarding the lower alcohol consumption by Dams in the EtOH-HMD group and its potential impact on DMRs. We agree that consistent in utero exposure is crucial for reliable results. Our pup selection for genomic analysis involved matching litter size as a proxy for in utero exposure, so even through the average alcohol consumption was lower for the EtOH-HMD group, we matched pups across treatment groups based on litter size as a proxy for alcohol intake levels, excluding pups with significantly different exposure levels. We agree more robust methods including direct measurement of blood alcohol content would improve the study. We have now incorporated this into the discussion of the revised manuscript on lines 351: “Additionally, we employed an ad-libitum alcohol exposure model rather than direct dosing of dams. Although the trajectories of alcohol consumption were not statistically different between groups, this introduces more variability into alcohol exposure patterns, and might might impact offspring methylation data”
- Lines 172 - please be more specific about the neurocognitive domains tested.
In the revision we have included more detail about the neurocognitive domains tested (originally mentioned in the results) in the methods as follows:
“These tests included the open field test (locomotor activity, anxiety) (38), object recognition test (locomotor activity, spatial recognition) (39), object in place test (locomotor activity, spatial recognition) (40), elevated plus maze test (locomotor activity, anxiety) (41), and two trials of the rotarod test (motor coordination, balance) (42)”
- Line 191 - please report the tissue type used in the human study, as well as the method used to estimate cell type proportions.
We stated in the results section that buccal swabs were used in both human cohorts.
We added to the revised manuscript that cell type proportions were estimated using the EpiDISH R package.
- Related to validation, it is unclear whether the human-identified DMRs were also validated in mice, or if the authors are showing their own DMRs. Please also discuss why DMRs might not have been replicated in AQUA.
We used human data sets to validate observations from our murine model, focusing on regions identified in our early moderate PAE model. This is now explicitly state on line 209 of the revision:
“We undertook validation studies by examining PAE sensitive regions identified in our murine model using existing DNA methylation data from human cohorts to address the generalizability of our findings.”
“In the section entitled ‘Candidate Gene Analysis..’ we used our murine data sets to reproduce previously published associations that included regions identified in both animal and human studies. We posit the lack of replication of our early moderate PAE regions in AQUA is explained in part by species-specific differences and considering the striking differences in effect size seen in regions that did replicate in FASD subjects, the exposure may need to be of sufficient magnitude and duration for the effects seen in brain and liver to survive reprogramming in the blood. The AQUA cohort is largely enriched for low to moderate patterns of alcohol consumption.
- Line 197 - please provide a citation for the ethanol-sensitive regions. There are also several existing DNAm analyses in brain tissues from animal models that should be included as part of these analyses, as several have shown brain-region and sex-specific DMRs related to prenatal alcohol exposure. These contrasts might help the authors further delineate the effects of prenatal alcohol in their model and expand on current literature to explain the deficits caused by alcohol exposure.
Our candidate gene/region selection was informed by a systematic review of previously published human and animal studies reporting associations between in utero exposure to PAE and offspring DNA methylation. We synthesized evidence across several models, tissues and methylation platforms to arrive at a core set of reproducible associations. Line 481 of the methods now includes a citation to our systematic review which details our selection criteria.
Discussion
- Line 211 - This is a strong statement for one hypothesis. It is also possible that different cell types have similar responses to prenatal alcohol exposure. In this scenario, perturbations need not arise before germ layer separation. The authors should soften this causal statement.
We appreciate this point although given the genome size relative to the size of the DMRs we have detected, the chance that different cell types would respond similarly in exactly the same regions seems exceedingly rare. We posit a more likely explanation is early perturbations in the embryo are established stochastically as a result of the exposure (supported by the interventional design) and maintained in the differentiating tissues. We agree further work is needed to prove this, specifically in a wider set of tissues from multiple germ layers so we have amended the discussion as follows:
“These perturbations may have been established stochastically because of alcohol exposure in the early embryo and maintained in the differentiating tissue. Further analysis in different germ layer tissues is required to formally establish this.”
- Lines 222-224 - I completely agree with this statement. However, the authors had the opportunity to examine dosage effects in their model as they measured alcohol-levels from the dams. At the very least, I would recommend sensitivity analyses in their DMRs to assess whether alcohol level/dosage influences their results.
Although a great suggestion to improve the manuscript, we did not have opportunity to examine dosages by design as we selected mice for genome analysis with matched exposure patterns. It would be fascinating to conduct a sensitivity analysis.
Methods:
- Please include the lysis protocol.
Thank you for picking up this error in our reporting. We have now included the following details in the methods which improve the reproducibility of this study: “Ten milligrams of tissue were collected from each liver and brain and lysed in Chemagic RNA Tissue10 Kit special H96 extraction buffer”.
- Please include the total reads for each sample and details of the QC pipeline, including filtering flags, quality metrics, and genome build.
Thank you for suggesting improvements to our reporting which improve the reproducibility of this study. We have included a new supplementary tableTab of sequencing statistics and details of the quality metrics. Please note the genome build is explicitly stated in the methods already.
- Please make your code publicly available to ensure that these analyses can be replicated.
Thank you for this suggestion. A data availability statement has now been included in the revision and code will be made available upon request
- Why were Y chromosome reads included in the dataset?
Y chromosomal reads were not included in the DMR analysis. Amended “We filtered the X chromosomal reads” to “We filtered the sex chromosomal reads” in revised manuscript.
- Please provide the number of total CpGs available for analysis.
Added sentence into results section of revised manuscript: “A total of 21,842,961 CpG sites were initially available for analysis.” We also clarified that the ~19,000,000 CpGs were analysed following coverage filtering.
- Please provide the parameters for the DMR analysis and report how the p-values and deltas were calculated.
We have addressed this in previous comments
- The supplemental materials for the human data are missing.
Thank you for picking up this oversight. The revision now includes an additional data supplement which details the analysis of the human data sets for interested readers.
Tables and figures
- Table 1. It is not clear how the DMRs for this table were selected. The exact p-values and FDR should also be reported in this table. The number of CpGs in these DMRS should also be reported.
Table 1 includes select DMRs that were consistently detected in both brain and liver tissue. These are particularly of interest as they represent regions highly sensitive to alcohol exposure. We agree that exact reporting of p-values would be ideal. Instead of a single p-value for the whole DMR, DSS uses the area statistic to rank candidate regions and control the false discovery rate (FDR) through shrinkage estimation methods. In the revision we have now included region size and number of CpGs in table 1.
- Table 3. Please include p-values for the DMR analyses.
As above we report the area-statistic which is an equivalent measure to assess evidence for differential methylation.
- Figure 2 (Figure 4 in revised manuscript). Please report the N for these analyses. It also seems that the pairwise t-tests were only compared to the H20-NC, which does not provide much insight into the PAE group. The relevance of the sexP analysis to the present manuscript is also unclear.
Figure 2 is now Figure 4 in the revision and the sample size has been included in figure legend. We compared all groups to the control group (H20-NC) as we aimed to determine any differences in intervention groups from the control.
We apologies for lack of clarity around the ‘sex P’ terminology. This refers to the p-value for the main effect of sex on the behavioural outcome. We agree it lacks relevance since the regression models were adjusted for sex. In the revision we have updated the methods as follows (line426) and removed references to sex P
“To examine the effect of alcohol exposure on behavioural outcomes we used linear regression with alcohol group (binary) as the main predictor adjusted for diet and sex.”
- Figure 3ef (Figure 2ef in revised manuscript). It is unclear how the regions random regions were generated. A permutation test would be relevant to determine whether there are any actual enrichment differences.
As stated in methods section: “DMRs were then tested for enrichment within specific genic and CpG regions of the mouse genome, compared to a randomly generated set of regions in the mouse genome generated with resampleRegions in regioneR, with equivalent means and standard deviations.”
- Figure 5. Please include the gene names for these DMRs, as well as their genomic locations. It would also be relevant to annotate these plots with the max, min, and mean delta between groups.
Thank you, we considered this however the DMRs are not in genes so we cannot apply a gene label. The locations are reported on the x-axis and the statistics are shown in Table 3.
- Figure S1b and S2c- It is quite worrisome that the PAE-HMD group drank less throughout pregnancy than their PAE counterparts. Please discuss how this was addressed in the analyses.
We appreciate the reviewer's concern regarding the lower alcohol consumption in the PAE-HMD group and its potential impact on DMRs. We agree that consistent in-utero exposure is crucial for reliable results. Although the total amount of liquid consumed over pregnancy was lower in this group, they started with a lower baseline and the trajectory was not statistically different compared to other groups.
We have now incorporated this into the discussion section of the revised manuscript on lines 336: “Additionally, we employed an ad-libitum alcohol exposure model rather than direct dosing of dams. Although the trajectories of alcohol consumption were not statistically different between groups, this introduces more variability into alcohol exposure patterns, and might might impact offspring methylation data.”
- Figure S1cd. See my comments about Figure 2.
Suggested changes have been incorporated.
- Figure S2d. it is not clear to what the statistics presented in this panel refer. Please clarify and discuss the implications of dietary intake differences on your findings.
Added sentence to caption in revised manuscript: “Statistical analysis involved linear mixed-effects regression comparing trajectories of treatment groups to H2O-NC baseline control group.”
- Figure S3. See my comments about Figure 2.
Suggested changes have been incorporated
- Figure S4. I am confused by the color legend, as it seems both colors are PAE. I also do not see how any regions show increased or decreased DNAm in PAE based on this plot (also no statistics are presented to support these conclusions).
The plot is intended to show there are no gross changes in methylation when averaged across all CpGs within different regulatory genomic contexts. Statistics are not included as it is intuitive from the plot that the means are the same. We have updated the figure legend which now reads
“Figure S4. No evidence for global disruption of methylation by PAE. The figure shows methylation levels averaged across CpGs in different regulatory genomic contexts. Neither brain tissue (A & B), nor liver tissue (C & D) were grossly affected by PAE exposure (blue bars). Bars represent means and standard deviation.”
-
-
learn-us-east-1-prod-fleet01-xythos.content.blackboardcdn.com learn-us-east-1-prod-fleet01-xythos.content.blackboardcdn.com
-
What year were you born?Please respond in YYYY format____________3. What are the first four letters of the name of your hometown?Please respond in nnn formatDo not capitalize the first letter____________4. What is the zip code of your home address?Please respond in ZZZZZ format____________End Group: Unique User ID5. What is your gender?Select one.o Femaleo Maleo Non-binary/ third gendero Prefer not to answero Prefer to self-describe: ________________6. Do you currently live in New York or consider New York your primary state of residence?Select one.o Yes -----> Continue to number 7o No -----> Skip to number 8
Starts with the demographic questions since they already previously stated they would ask them in the consent form. Typically demographic questions are last however since they already informed the reader about them, there will be no surprise to seeing them. Also, the demographic questions are very simple and broad. The researcher is only collecting the information needed and not asking in-depth questions. This is so they do not scare away the participant with too personal of questions.
-
You will be asked to provide your birth year, zip code of residence, and the first 4 letters of the name ofyour hometown to generate a unique user code associated with your responses. This information will beused to count the number of participants and to estimate the average number of surveys participantscomplete. Providing this information is completely voluntary and will not be available to anyone exceptthe primary investigators. Your name will not be associated with the responses you provide, or the datagenerated from them. You will also be asked to provide the coordinates of the location where youcompleted the survey. Coordinate information is important
This section relates to the demographic questions. Since people are hesitant to answer personal information, explaining why it is needed and that it is optional puts the participant at ease and makes them more likely to answer. Also allows the participant not to be surprised when asked about it in the survey.
-
-
docs.google.com docs.google.com
-
(Texas Mexicans and California Mexicans are very different from each other, like the Scottish and the Irish-fundamentally the same genetic code, but completely different in accent and habits.)
true, nice analogy
-
-
engl201.opened.ca engl201.opened.ca
-
This may mean, “supplementing ‘the humanities’ own methodologicaltoolkits’ with theoretical insights from software, critical code and platform studies”
This could be speaking about any tools, but I'm going to mention AI, and how everyone makes it out to be the worst thing in the world when in reality, (she had a hidden agenda! she put my tender, heart in a blender, and STILL I surrendered!) It's quite a useful tool.
-
-
apnews.com apnews.com
-
frostbite
frostbite: the superficial or deep freezing of the tissues of some part of the body
The WHO's code of practice for fishery products indicates that shrimp should be stored and processed at temperatures below 4°C.
-
-
ipfs.indy0.net ipfs.indy0.netDeno 1.01
-
Deno is (and always will be) a single executable file. Like a web browser, it knows how to fetch external code.
knows how to fetch external code
-
-
naturalistic-data.org naturalistic-data.org
-
masker.fit_transform
AttributeError: 'Brain_Data' object has no attribute 'fit_transform'
-
-
www.biorxiv.org www.biorxiv.org
-
Author Response
The following is the authors’ response to the original reviews.
Response to Reviewers’ Public Comments
We are grateful for the reviewers’ comments. We have modified the manuscript accordingly and detail our responses to their major comments below.
(1) Reviewer 2 was concerned that transformation of continuous functional data into categorical form could reduce precision in estimating the genetic architecture.
We agree that transforming continuous data into categories may reduce resolution, but it also improves accuracy when the continuous data are affected by measurement noise. In our dataset, many genotypes are at the lower bound of measurement, and the variation in measured fluorescence among these genotypes is largely or entirely caused by measurement noise. By transforming to categorical data, we dramatically reduced the effect of this noise on the estimation of genetic effects. We modified the results and discussion sections to address this point.
(2) Reviewer 2 asked about generalizability of our findings.
Because our paper is the first use of reference-free analysis of a 20-state combinatorial dataset, generalizability is at this point unknown. However, a recent manuscript from our group confirms the generality of the simplicity of genetic architecture: using reference-free methods to analyze 20 published combinatorial deep mutational scans, several of which involve 20-state libraries, we found that main and pairwise effects account for virtually all of the genetic variance across a wide variety of protein families and types of biochemical functions (Park Y, Metzger BPH, Thornton JW. 2023. The simplicity of protein sequence-function relationships. BioRxiv, 2023.09.02.556057). Concerning the facilitating effect of epistasis on the evolution of new functions, we speculate that this result is likely to be general: we have no reason to think that the underlying cause of this observation – epistasis brings genotypes with different functions closer in sequence space to each other and expands the total number of functional sequences – arises from some peculiarity of the mechanisms of steroid receptor DBD folding or DNA binding. However, we acknowledge that our data involve sequence variation at those sites in the protein that directly mediate specific protein-DNA contact; it is plausible that sites far from the “active site” may have weaker epistatic interactions and therefore have weaker effects on navigability of the landscape. We have addressed these issues in the discussion.
(3) Reviewer 3 asked “in which situation would the authors expect that pairwise epistasis does not play a crucial role for mutational steps, trajectories, or space connectedness, if it is dominant in the genotype-phenotype landscape?”
The question addressed in our paper is not whether epistasis shapes steps, trajectories or connectedness in sequence space but how it does so and what its particular effects are on the evolution of new functions. The dominant view in the field has been that the primary role of epistasis is to block evolutionary paths. We show, however, that in multi-state sequence space, epistasis facilitates rather than impedes the evolution of new functions. It does this by increasing the number of functional genotypes and bringing genotypes with different functions closer together in sequence space. This finding was possible because of the difference in approach between our paper and prior work: most prior work considered only direct paths in a binary sequence space between two particular starting points – and typically only considering optimization of a single function – whereas we studied the evolution of new functions in a multi-state amino acid space, under empirically relevant epistasis informed by complete combinatorial experiments. The result is a clear demonstration that the net effect of real-world levels of epistasis on navigability of the multidimensional sequence landscape is to make the evolution of new functions easier, not harder.
(4) Reviewer 3 asked for “an explanation of how much new biological results this paper delivers as compared with the paper in which the data were originally published.”
Starr 2017 did not use their data to characterize the underlying genetic architecture of function by estimating main and epistatic effects of amino acid states and combinations; it also did not evaluate the importance of epistasis in generating functional variants, determining the transcription factor’s specificity, or shaping evolutionary navigability on the landscape.
(5) Reviewer 3 requested an explanation of how the results would have been (potentially) different if a reference-based approach were used, and how reference-based analysis compares with other reference-free approaches to estimating epistasis.
This topic has been covered in detail in a recent manuscript from our group (Park et al. Biorxiv 2023.09.02.556057). Briefly, reference-free approaches provide the most efficient explanation of an entire genotype-phenotype map, explaining the maximum amount of genetic variance and reducing sensitivity to experimental noise and missing genotypes compared to reference-based approaches. Reference-based approaches tend to infer much more epistasis, especially higher-order epistasis, because measurement error and local idiosyncrasy near the wild-type sequence propagate into spurious high-order terms. Reference-based analyses are appropriate for characterizing only the immediate sequence neighborhood of a particular “wild-type” protein of interest. Reference-free approaches are therefore best suited to understanding genotype-phenotype landscapes as a whole. We have clarified these issues in the revised discussion.
(6) Reviewer 3 suggested that the comparison between the full and main-effects-only model should involve a re-estimation of main effects in the latter case.
This is indeed what we did in our analysis. We have clarified the description in the results and methods sections to make this clear.
(7) Reviewer 3 asked about the applicability of the approach to data beyond those analyzed in the present study and requirements to use it.
Our approach could be used for any combinatorial DMS dataset in which the phenotypic data are categorical (or can be converted to categorical form). Complete sampling is not required: a virtue of reference-free analysis is that by averaging the estimated effects of states and combinations over all variants that contain them, reference-free analysis is highly robust to missing data (except at the highest possible order of epistasis, where only a single variant represents a high-order effect) as long as variant sampling is unbiased with respect to phenotype. All the required code are publicly available at the github link provided in this manuscript. We have also described a general form of reference-free analysis for continuous data and applied it to 20 protein datasets in a recent publication (Park et al. Biorxiv 2023.09.02.556057).
(8)Reviewer 3 suggested that the text could be shortened and made less dense.
We agree and have done a careful edit to streamline the narrative.
Response to Reviewers’ Non-Public Recommendations
(1) Reviewer 1 noted that specific epistatic effects might in some cases produce global nonlinearities in the genotype-phenotype relationship. They then asked how our results might change if we did not impose a nonlinear transformation as part of the genotype-phenotype model. The reviewer’s underlying concern was that the non-specific transformation might capture high-order specific epistatic effects and thus reducing their importance.
Because our data are categorical, we required a model that characterizes the effect of particular amino acid states and combinations on the probability that a variant is in a null, weak, or strong activation class. A logistic model is the classic approach to this kind of analysis. The model structure assumes that amino acid states and combinations have additive effects on the log-odds of being in one functional class versus the lower functional class(es); the only nonlinear transformation is that which arises mathematically when log-odds are transformed into probability through the logistic link function. Thinking through the reviewer’s comment, we have concluded that our model does not make any explicit transformation to account for nonlinearity in the relationship between the effects of specific sequence states/combinations and the measured phenotype (activation class). If additional global nonlinearities are present in the genotype-phenotype relationship – such as could be imposed by limited dynamic range in the production of the fluorescence phenotype or the assay used to measure it – it is possible that the sigmoid shape of the logistic link function may also accommodate these nonlinearities. We have noted this part in the revised manuscript.
(2) Reviewer 1 observed that our model seems to prefer sets of several pairwise interactions among states across sites rather than fewer high-order interactions among those same states.
This finding arises because the pattern of phenotypic variation across genotypes in our dataset is consistent with that which would be produced by pairwise interactions rather than by high-order interactions. In a reference-free framework, these patterns are distinct from each other: a group of second-order terms cannot fit the patterns produced by high-order epistasis, and high-order terms cannot fit the pattern produced by pairwise interactions. Similarly, main-effect terms cannot fit the pattern of phenotypes produced by a pairwise interaction, and a pairwise epistatic term cannot fit the pattern produced by main effects of states at two sites. For example, third-order terms are required when the genotypes possessing a particular triplet of states deviate from that expected given all the main and second-order effects of those states; this deviation cannot be explained by any combination of first- and second-order effects.
We explain this point in detail in our recent manuscript (Park Y, Metzger BPH, Thornton JW. 2023. The simplicity of protein sequence-function relationships. BioRxiv, 2023.09.02.556057) and we summarize it here. Consider the simple example of two sites with two possible states (genotypes 00, 01, 10, and 11). If there are no main effects and no pairwise effects, this architecture will generate the same phenotype for all four variants – the global average (or zero-order effect). If there are pairwise effects but no main effects, this architecture will generate a set of phenotypes on which the average phenotype of genotypes with a 0 at the first site (00 and 01) equals the global average – as does the average of those with 0 at the second site (00 and 10). The epistatic effect causes the individual genotypes to deviate from the global average. This pattern can be fit only by a pairwise epistatic term, not by first-order terms. Conversely, if there are main effects but no pairwise effects, then the average phenotype of genotypes 00 and 01 will deviate from the global average (by an amount equal to the first-order effect), as will the average of (00 and 10): the phenotype of each genotype will be equal to the sum of the relevant first-order effects for the state it contains. This pattern cannot be fit by second-order model terms. The same logic extends to higher orders: a cluster of second-order terms cannot explain variation generated by third-order epistasis, because third-order variation is by definition is the deviation from the best second-order model.
(3) Reviewer 1 suggested several places in the text where citations to prior work would be appropriate.
We appreciate these suggestions and have modified the manuscript to refer to most of these works.
(4) Reviewer 1 pointed to the paper of Gong et al eLife 2013 and asked whether it is known how robust the proteins in our study are to changes in conformation/stability compared to other proteins, and whether this might impact the likelihood of observing higher-order epistasis in this system.
The DBDs that we study here are very stable, and previous work shows that mutations affect DNA specificity primarily by modifying the DBD’s affinity rather than its stability (McKeown et al., Cell 2014). Additionally, Gong et al.’s findings pertain to a globally nonlinear relationship between stability and function, which arises from the Boltzmann relationship between the energy of folding and occupancy of the folded state. Because our data are categorical – based on rank-order of measured phenotype rather than fluorescence as a continuous phenotype – the kind of global nonlinearity observed in Gong’s study are not expected to produce spurious estimates of epistasis in our work. We have modified the discussion to discuss the point.
(5) Reviewer 1 asked a) why the epistatic models produce landscapes on which variants have fewer neighbors on average than main-effects only models and b) why the average distance from all ERE-specific nodes to all SRE-specific nodes is greater with epistasis (but the average distance from ERE to nearest SRE is lower with epistasis).
In the main effects-only landscape, the functional genotypes are relatively similar to each other, because each must contain several of the states that contribute the most to a positive genetic score. Moreover, ERE-specific nodes are similar to each other, and SRE-specific nodes are similar to each other, because each must contain one or more of a relatively small number of specificity-determining states. When epistasis is added to the genetic architecture, two things happen: 1) more genotypes become functional because there are more combinations that can exceed the threshold score to produce a functional activator and 2) these additional functional variants are more different from each other – in general, and within the classes of ERE- or SRE-specific variants – because there are now more diverse combinations of states that can yield either phenotype. As a result, a broader span of sequence space is occupied, but ERE- and SRE-specific variants are more interspersed with each other. This means that the average distance between all pairs of nodes is greater, and this applies to all ERE-SRE pairs, as well. However, the interspersing means that the closest single SRE to any particular ERE is closer than it was without epistasis. We have added this explanation to the main text.
(6) Reviewer 2 asked us to explain why average path length increases with pairwise epistasis as the strength of selection for specificity increases.
This behavior occurs because of the existence of a local peak in the pairwise model. Genotypes on this peak contained few connections to other genotypes, all of which were less SRE specific. Thus, with strong selection, i.e. high population size, the simulations became stuck on the local peak, cycling among the genotypes many times before leaving, resulting in a large increase in the mean step number. As shown in the rest of the figure, when the longest set of paths are removed, there are still differences in the average number of steps with and without epistasis. This issue is described in the methods section.
(7) Reviewers made several suggestions for clarity in the text and figures.
We have modified the paper to address all of these comments.
(8) Reviewer 3 stated that the code should be available.
The code is available at https://github.com/JoeThorntonLab/DBD.GeneticArchitecture.
-
-
www.education.gouv.fr www.education.gouv.fr
-
recours effectif à l'ensemble du panel des sanctions réglementaires fixé à l'article R. 511-13 du code de l'éducation et reproduit dans le règlement intérieur
-
-
www.biorxiv.org www.biorxiv.org
-
Reviewer #1 (Public Review):
Summary:
Semenova et al. have studied a large cross-sectional cohort of people living with HIV on suppressive ART, N=115, and performed high dimensional flow cytometry to then search for associations between immunological and clinical parameters and intact/total HIV DNA levels.
A number of interesting data science/ML approaches were explored on the data and the project seems a serious undertaking. However, like many other studies that have looked for these kinds of associations, there was not a very strong signal. Of course, the goal of unsupervised learning is to find new hypotheses that aren't obvious to human eyes, but I felt in that context, there were (1) results slightly oversold, (2) some questions about methodology in terms mostly of reservoir levels, and (3) results were not sufficiently translated back into meaning in terms of clinical outcomes.
Strengths:
The study is evidently a large and impressive undertaking and combines many cutting-edge statistical techniques with a comprehensive experimental cohort of people living with HIV, notably inclusive of populations underrepresented in HIV science. A number of intriguing hypotheses are put forward that could be explored further. Sharing the data could create a useful repository for more specific analyses.
Weaknesses:
Despite the detailed experiments and methods, there was not a very strong signal for the variable(s) predicting HIV reservoir size. The Spearman coefficients are ~0.3, (somewhat weak, and acknowledged as such) and predictive models reach 70-80% prediction levels, though sometimes categorical variables are challenging to interpret.
There are some questions about methodology, as well as some conclusions that are not completely supported by results, or at minimum not sufficiently contextualized in terms of clinical significance.
On associations: the false discovery rate correction was set at 5%, but data appear underdetermined with fewer observations than variables (144vars > 115ppts), and it isn't always clear if/when variables are related (e.g inverses of one another, for instance, %CD4 and %CD8).
The modeling of reservoir size was unusual, typically intact and defective HIV DNA are analyzed on a log10 scale (both for decays and predicting rebound). Also sometimes in this analysis levels are normalized (presumably to max/min?, e.g. S5), and given the large within-host variation of level we see in other works, it is not trivial to predict any downstream impact of normalization across population vs within-person.
Also, the qualitative characterization of low/high reservoir is not standard and naturally will split by early/later ART if done as above/below median. Given the continuous nature of these data, it seems throughout that predicting above/below median is a little hard to translate into clinical meaning.
Lastly, the work is comprehensive and appears solid, but the code was not shared to see how calculations were performed.
-
-
dl.acm.org dl.acm.org
-
Computational thinking is thinking recursively. Itis parallel processing. It is interpreting code as dataand data as code. It is type checking as the general-ization of dimensional analysis. It is recognizingboth the virtues and the dangers of aliasing, or giv-ing someone or something more than one name. Itis recognizing both the cost and power of indirectaddressing and procedure call. It is judging a pro-gram not just for correctness and efficiency but foraesthetics, and a system’s design for simplicity andelegance
I agree that it involves thinking recursively, parallel processing, and interpreting code as data and vice versa. It requires us to delve into the intricacies of type checking as a generalization of dimensional analysis and understanding the concept of aliasing, which can have both benefits and risks.
-
-
-
Author Response
The following is the authors’ response to the original reviews.
eLife assessment
These ingenious and thoughtful studies present important findings concerning how people represent and generalise abstract patterns of sensory data. The issue of generalisation is a core topic in neuroscience and psychology, relevant across a wide range of areas, and the findings will be of interest to researchers across areas in perception, learning, and cognitive science. The findings have the potential to provide compelling support for the outlined account, but there appear other possible explanations, too, that may affect the scope of the findings but could be considered in a revision.
Thank you for sending the feedback from the three peer reviewers regarding our paper. Please find below our detailed responses addressing the reviewers' comments. We have incorporated these suggestions into the paper and provided explanations for the modifications made.
We have specifically addressed the point of uncertainty highlighted in eLife's editorial assessment, which concerned alternative explanations for the reported effect. In response to Reviewer #1, we have clarified how Exp. 2c and Exp. 3c address the potential alternative explanation related to "attention to dimensions." Further, we present a supplementary analysis to account for differences in asymptotic learning, as noted by Reviewer #2. We have also clarified how our control experiments address effects associated with general cognitive engagement in the task. Lastly, we have further clarified the conceptual foundation of our paper, addressing concerns raised by Reviewers #2 and #3.
Reviewer #1 (Public Review):
Summary:
This manuscript reports a series of experiments examining category learning and subsequent generalization of stimulus representations across spatial and nonspatial domains. In Experiment 1, participants were first trained to make category judgments about sequences of stimuli presented either in nonspatial auditory or visual modalities (with feature values drawn from a two-dimensional feature manifold, e.g., pitch vs timbre), or in a spatial modality (with feature values defined by positions in physical space, e.g., Cartesian x and y coordinates). A subsequent test phase assessed category judgments for 'rotated' exemplars of these stimuli: i.e., versions in which the transition vectors are rotated in the same feature space used during training (near transfer) or in a different feature space belonging to the same domain (far transfer). Findings demonstrate clearly that representations developed for the spatial domain allow for representational generalization, whereas this pattern is not observed for the nonspatial domains that are tested. Subsequent experiments demonstrate that if participants are first pre-trained to map nonspatial auditory/visual features to spatial locations, then rotational generalization is facilitated even for these nonspatial domains. It is argued that these findings are consistent with the idea that spatial representations form a generalized substrate for cognition: that space can act as a scaffold for learning abstract nonspatial concepts.
Strengths:
I enjoyed reading this manuscript, which is extremely well-written and well-presented. The writing is clear and concise throughout, and the figures do a great job of highlighting the key concepts. The issue of generalization is a core topic in neuroscience and psychology, relevant across a wide range of areas, and the findings will be of interest to researchers across areas in perception and cognitive science. It's also excellent to see that the hypotheses, methods, and analyses were pre-registered.
The experiments that have been run are ingenious and thoughtful; I particularly liked the use of stimulus structures that allow for disentangling of one-dimensional and two-dimensional response patterns. The studies are also well-powered for detecting the effects of interest. The model-based statistical analyses are thorough and appropriate throughout (and it's good to see model recovery analysis too). The findings themselves are clear-cut: I have little doubt about the robustness and replicability of these data.
Weaknesses:
I have only one significant concern regarding this manuscript, which relates to the interpretation of the findings. The findings are taken to suggest that "space may serve as a 'scaffold', allowing people to visualize and manipulate nonspatial concepts" (p13). However, I think the data may be amenable to an alternative possibility. I wonder if it's possible that, for the visual and auditory stimuli, participants naturally tended to attend to one feature dimension and ignore the other - i.e., there may have been a (potentially idiosyncratic) difference in salience between the feature dimensions that led to participants learning the feature sequence in a one-dimensional way (akin to the 'overshadowing' effect in associative learning: e.g., see Mackintosh, 1976, "Overshadowing and stimulus intensity", Animal Learning and Behaviour). By contrast, we are very used to thinking about space as a multidimensional domain, in particular with regard to two-dimensional vertical and horizontal displacements. As a result, one would naturally expect to see more evidence of two-dimensional representation (allowing for rotational generalization) for spatial than nonspatial domains.
In this view, the impact of spatial pre-training and (particularly) mapping is simply to highlight to participants that the auditory/visual stimuli comprise two separable (and independent) dimensions. Once they understand this, during subsequent training, they can learn about sequences on both dimensions, which will allow for a 2D representation and hence rotational generalization - as observed in Experiments 2 and 3. This account also anticipates that mapping alone (as in Experiment 4) could be sufficient to promote a 2D strategy for auditory and visual domains.
This "attention to dimensions" account has some similarities to the "spatial scaffolding" idea put forward in the article, in arguing that experience of how auditory/visual feature manifolds can be translated into a spatial representation helps people to see those domains in a way that allows for rotational generalization. Where it differs is that it does not propose that space provides a scaffold for the development of the nonspatial representations, i.e., that people represent/learn the nonspatial information in a spatial format, and this is what allows them to manipulate nonspatial concepts. Instead, the "attention to dimensions" account anticipates that ANY manipulation that highlights to participants the separable-dimension nature of auditory/visual stimuli could facilitate 2D representation and hence rotational generalization. For example, explicit instruction on how the stimuli are constructed may be sufficient, or pre-training of some form with each dimension separately, before they are combined to form the 2D stimuli.
I'd be interested to hear the authors' thoughts on this account - whether they see it as an alternative to their own interpretation, and whether it can be ruled out on the basis of their existing data.
We thank the Reviewer for their comments. We agree with the Reviewer that the “attention to dimensions” hypothesis is an interesting alternative explanation. However, we believe that the results of our control experiments Exp. 2c and Exp. 3c are incompatible with this alternative explanation.
In Exp. 2c, participants are pre-trained in the visual modality and then tested in the auditory modality. In the multimodal association task, participants have to associate the auditory stimuli and the visual stimuli: on each trial, they hear a sound and then have to click on the corresponding visual stimulus. It is thus necessary to pay attention to both auditory dimensions and both visual dimensions to perform the task. To give an example, the task might involve mapping the fundamental frequency and the amplitude modulation of the auditory stimulus to the colour and the shape of the visual stimulus, respectively. If participants pay attention to only one dimension, this would lead to a maximum of 25% accuracy on average (because they would be at chance on the other dimension, with four possible options). We observed that 30/50 participants reached an accuracy > 50% in the multimodal association task in Exp. 2c. This means that we know for sure that at least 60% of the participants paid attention to both dimensions of the stimuli. Nevertheless, there was a clear difference between participants that received a visual pre-training (Exp. 2c) and those who received a spatial pre-training (Exp. 2a) (frequency of 1D vs 2D models between conditions, BF > 100 in near transfer and far transfer). In fact, only 3/50 participants were best fit by a 2D model when vision was the pre-training modality compared to 29/50 when space was the pre-training modality. Thus, the benefit of the spatial pre-training cannot be due solely to a shift in attention toward both dimensions.
This effect was replicated in Exp. 3c. Similarly, 33/48 participants reached an accuracy > 50% in the multimodal association task in Exp. 3c, meaning that we know for sure that at least 68% of the participants actually paid attention to both dimensions of the stimuli. Again, there was a clear difference between participants who received a visual pre-training (frequency of 1D vs 2D models between conditions, Exp. 3c) and those who received a spatial pre-training (Exp. 3a) (BF > 100 in near transfer and far transfer).
Thus, we believe that the alternative explanation raised by the Reviewer is not supported by our data. We have added a paragraph in the discussion:
“One alternative explanation of this effect could be that the spatial pre-training encourages participants to attend to both dimensions of the non-spatial stimuli. By contrast, pretraining in the visual or auditory domains (where multiple dimensions of a stimulus may be relevant less often naturally) encourages them to attend to a single dimension. However, data from our control experiments Exp. 2c and Exp. 3c, are incompatible with this explanation. Around ~65% of the participants show a level of performance in the multimodal association task (>50%) which could only be achieved if they were attending to both dimensions (performance attending to a single dimension would yield 25% and chance performance is at 6.25%). This suggests that participants are attending to both dimensions even in the visual and auditory mapping case.”
Reviewer #2 (Public Review):
Summary:
In this manuscript, L&S investigates the important general question of how humans achieve invariant behavior over stimuli belonging to one category given the widely varying input representation of those stimuli and more specifically, how they do that in arbitrary abstract domains. The authors start with the hypothesis that this is achieved by invariance transformations that observers use for interpreting different entries and furthermore, that these transformations in an arbitrary domain emerge with the help of the transformations (e.g. translation, rotation) within the spatial domain by using those as "scaffolding" during transformation learning. To provide the missing evidence for this hypothesis, L&S used behavioral category learning studies within and across the spatial, auditory, and visual domains, where rotated and translated 4-element token sequences had to be learned to categorize and then the learned transformation had to be applied in new feature dimensions within the given domain. Through single- and multiple-day supervised training and unsupervised tests, L&S demonstrated by standard computational analyses that in such setups, space and spatial transformations can, indeed, help with developing and using appropriate rotational mapping whereas the visual domain cannot fulfill such a scaffolding role.
Strengths:
The overall problem definition and the context of spatial mapping-driven solution to the problem is timely. The general design of testing the scaffolding effect across different domains is more advanced than any previous attempts clarifying the relevance of spatial coding to any other type of representational codes. Once the formulation of the general problem in a specific scientific framework is done, the following steps are clearly and logically defined and executed. The obtained results are well interpretable, and they could serve as a good stepping stone for deeper investigations. The analytical tools used for the interpretations are adequate. The paper is relatively clearly written.
Weaknesses:
Some additional effort to clarify the exact contribution of the paper, the link between analyses and the claims of the paper, and its link to previous proposals would be necessary to better assess the significance of the results and the true nature of the proposed mechanism of abstract generalization.
(1) Insufficient conceptual setup: The original theoretical proposal (the Tolman-Eichenbaum-Machine, Whittington et al., Cell 2020) that L&S relate their work to proposes that just as in the case of memory for spatial navigation, humans and animals create their flexible relational memory system of any abstract representation by a conjunction code that combines on the one hand, sensory representation and on the other hand, a general structural representation or relational transformation. The TEM also suggests that the structural representation could contain any graph-interpretable spatial relations, albeit in their demonstration 2D neighbor relations were used. The goal of L&S's paper is to provide behavioral evidence for this suggestion by showing that humans use representational codes that are invariant to relational transformations of non-spatial abstract stimuli and moreover, that humans obtain these invariances by developing invariance transformers with the help of available spatial transformers. To obtain such evidence, L&S use the rotational transformation. However, the actual procedure they use actually solved an alternative task: instead of interrogating how humans develop generalizations in abstract spaces, they demonstrated that if one defines rotation in an abstract feature space embedded in a visual or auditory modality that is similar to the 2D space (i.e. has two independent dimensions that are clearly segregable and continuous), humans cannot learn to apply rotation of 4-piece temporal sequences in those spaces while they can do it in 2D space, and with co-associating a one-to-one mapping between locations in those feature spaces with locations in the 2D space an appropriate shaping mapping training will lead to the successful application of rotation in the given task (and in some other feature spaces in the given domain). While this is an interesting and challenging demonstration, it does not shed light on how humans learn and generalize, only that humans CAN do learning and generalization in this, highly constrained scenario. This result is a demonstration of how a stepwise learning regiment can make use of one structure for mapping a complex input into a desired output. The results neither clarify how generalizations would develop in abstract spaces nor the question of whether this generalization uses transformations developed in the abstract space. The specific training procedure ensures success in the presented experiments but the availability and feasibility of an equivalent procedure in a natural setting is a crucial part of validating the original claim and that has not been done in the paper.
We thank the Reviewer for their detailed comments on our manuscript. We reply to the three main points in turn.
First, concerning the conceptual grounding of our work, we would point out that the TEM model (Whittington et al., 2020), however interesting, is not our theoretical starting point. Rather, as we hope the text and references make clear, we ground our work in theoretical work from the 1990/2000s proposing that space acts as a scaffold for navigating abstract spaces (such as Gärdenfors, 2000). We acknowledge that the TEM model and other experimental work on the implication of the hippocampus, the entorhinal cortex and the parietal cortex in relational transformations of nonspatial stimuli provide evidence for this general theory. However, our work is designed to test a more basic question: whether there is behavioural evidence that space scaffolds learning in the first place. To achieve this, we perform behavioural experiments with causal manipulation (spatial pre-training vs no spatial pre-training) have the potential to provide such direct evidence. This is why we claim that:
“This theory is backed up by proof-of-concept computational simulations [13], and by findings that brain regions thought to be critical for spatial cognition in mammals (such as the hippocampal-entorhinal complex and parietal cortex) exhibit neural codes that are invariant to relational transformations of nonspatial stimuli. However, whilst promising, this theory lacks direct empirical evidence. Here, we set out to provide a strong test of the idea that learning about physical space scaffolds conceptual generalisation.“
Second, we agree with the Reviewer that we do not provide an explicit model for how generalisation occurs, and how precisely space acts as a scaffold for building representations and/or applying the relevant transformations to non-spatial stimuli to solve our task. Rather, we investigate in our Exp. 2-4 which aspects of the training are necessary for rotational generalisation to happen (and conclude that a simple training with the multimodal association task is sufficient for ~20% participants). We now acknowledge in the discussion the fact that we do not provide an explicit model and leave that for future work:
“We acknowledge that our study does not provide a mechanistic model of spatial scaffolding but rather delineate which aspects of the training are necessary for generalisation to happen.”
Finally, we also agree with the Reviewer that our task is non-naturalistic. As is common in experimental research, one must sacrifice the naturalistic elements of the task in exchange for the control and the absence of prior knowledge of the participants. We have decided to mitigate as possible the prior knowledge of the participants to make sure that our task involved learning a completely new task and that the pre-training was really causing the better learning/generalisation. The effects we report are consistent across the experiments so we feel confident about them but we agree with the Reviewer that an external validation with more naturalistic stimuli/tasks would be a nice addition to this work. We have included a sentence in the discussion:
“All the effects observed in our experiments were consistent across near transfer conditions (rotation of patterns within the same feature space), and far transfer conditions (rotation of patterns within a different feature space, where features are drawn from the same modality). This shows the generality of spatial training for conceptual generalisation. We did not test transfer across modalities nor transfer in a more natural setting; we leave this for future studies.”
(2) Missing controls: The asymptotic performance in experiment 1 after training in the three tasks was quite different in the three tasks (intercepts 2.9, 1.9, 1.6 for spatial, visual, and auditory, respectively; p. 5. para. 1, Fig 2BFJ). It seems that the statement "However, our main question was how participants would generalise learning to novel, rotated exemplars of the same concept." assumes that learning and generalization are independent. Wouldn't it be possible, though, that the level of generalization depends on the level of acquiring a good representation of the "concept" and after obtaining an adequate level of this knowledge, generalization would kick in without scaffolding? If so, a missing control is to equate the levels of asymptotic learning and see whether there is a significant difference in generalization. A related issue is that we have no information on what kind of learning in the three different domains was performed, albeit we probably suspect that in space the 2D representation was dominant while in the auditory and visual domains not so much. Thus, a second missing piece of evidence is the model-fitting results of the ⦰ condition that would show which way the original sequences were encoded (similar to Fig 2 CGK and DHL). If the reason for lower performance is not individual stimulus difficulty but the natural tendency to encode the given stimulus type by a combo of random + 1D strategy that would clarify that the result of the cross-training is, indeed, transferring the 2D-mapping strategy.
We agree with the Reviewer that a good further control is to equate performance during training. Thus, we have run a complementary analysis where we select only the participants that reach > 90% accuracy in the last block of training in order to equate asymptotic performance after training in Exp. 1. The results (see Author response image 1) replicates the results that we report in the main text: there is a large difference between groups (relative likelihood of 1D vs. 2D models, all BF > 100 in favour of a difference between the auditory and the spatial modalities, between the visual and the spatial modalities, in both near and far transfer, “decisive” evidence). We prefer not to include this figure in the paper for clarity, and because we believe this result is expected given the fact that 0/50 and 0/50 of the participants in the auditory and visual condition used a 2D strategy – thus, selecting subgroups of these participants cannot change our conclusions.
Author response image 1.
Results of Exp. 1 when selecting participants that reached > 90% accuracy in the last block of training. Captions are the same as Figure 2 of the main text.

Second, the Reviewer suggested that we run the model fitting analysis only on the ⦰ condition (training) in Exp. 1 to reveal whether participants use a 1D or a 2D strategy already during training. Unfortunately, we cannot provide the model fits only in the ⦰ condition in Exp. 1 because all models make the same predictions for this condition (see Fig S4). However, note that this is done by design: participants were free to apply whatever strategy they want during training; we then used the generalisation phase with the rotated stimuli precisely to reveal this strategy. Further, we do believe that the strategy used by the participants during training and the strategy during transfer are the same, partly because – starting from block #4 – participants have no idea whether the current trial is a training trial or a transfer trial, as both trial types are randomly interleaved with no cue signalling the trial type. We have made this clear in the methods:
“They subsequently performed 105 trials (with trialwise feedback) and 105 transfer trials including rotated and far transfer quadruplets (without trialwise feedback) which were presented in mixed blocks of 30 trials. Training and transfer trials were randomly interleaved, and no clue indicated whether participants were currently on a training trial or a transfer trial before feedback (or absence of feedback in case of a transfer trial).”
Reviewer #3 (Public Review):
Summary:
Pesnot Lerousseau and Summerfield aimed to explore how humans generalize abstract patterns of sensory data (concepts), focusing on whether and how spatial representations may facilitate the generalization of abstract concepts (rotational invariance). Specifically, the authors investigated whether people can recognize rotated sequences of stimuli in both spatial and nonspatial domains and whether spatial pre-training and multi-modal mapping aid in this process.
Strengths:
The study innovatively examines a relatively underexplored but interesting area of cognitive science, the potential role of spatial scaffolding in generalizing sequences. The experimental design is clever and covers different modalities (auditory, visual, spatial), utilizing a two-dimensional feature manifold. The findings are backed by strong empirical data, good data analysis, and excellent transparency (including preregistration) adding weight to the proposition that spatial cognition can aid abstract concept generalization.
Weaknesses:
The examples used to motivate the study (such as "tree" = oak tree, family tree, taxonomic tree) may not effectively represent the phenomena being studied, possibly confusing linguistic labels with abstract concepts. This potential confusion may also extend to doubts about the real-life applicability of the generalizations observed in the study and raises questions about the nature of the underlying mechanism being proposed.
We thank the Reviewer for their comments. We agree that we could have explained ore clearly enough how these examples motivate our study. The similarity between “oak tree” and “family tree” is not just the verbal label. Rather, it is the arrangement of the parts (nodes and branches) in a nested hierarchy. Oak trees and family trees share the same relational structure. The reason that invariance is relevant here is that the similarity in relational structure is retained under rigid body transformations such as rotation or translation. For example, an upside-down tree can still be recognised as a tree, just as a family tree can be plotted with the oldest ancestors at either top or bottom. Similarly, in our study, the quadruplets are defined by the relations between stimuli: all quadruplets use the same basic stimuli, but the categories are defined by the relations between successive stimuli. In our task, generalising means recognising that relations between stimuli are the same despite changes in the surface properties (for example in far transfer). We have clarify that in the introduction:
“For example, the concept of a “tree” implies an entity whose structure is defined by a nested hierarchy, whether this is a physical object whose parts are arranged in space (such as an oak tree in a forest) or a more abstract data structure (such as a family tree or taxonomic tree). [...] Despite great changes in the surface properties of oak trees, family trees and taxonomic trees, humans perceive them as different instances of a more abstract concept defined by the same relational structure.”
Next, the study does not explore whether scaffolding effects could be observed with other well-learned domains, leaving open the question of whether spatial representations are uniquely effective or simply one instance of a familiar 2D space, again questioning the underlying mechanism.
We would like to mention that Reviewer #2 had a similar comment. We agree with both Reviewers that our task is non-naturalistic. As is common in experimental research, one must sacrifice the naturalistic elements of the task in exchange for the control and the absence of prior knowledge of the participants. We have decided to mitigate as possible the prior knowledge of the participants to make sure that our task involved learning a completely new task and that the pre-training was really causing the better learning/generalisation. The effects we report are consistent across the experiments so we feel confident about them but we agree with the Reviewer that an external validation with more naturalistic stimuli/tasks would be a nice addition to this work. We have included a sentence in the discussion:
“All the effects observed in our experiments were consistent across near transfer conditions (rotation of patterns within the same feature space), and far transfer conditions (rotation of patterns within a different feature space, where features are drawn from the same modality). This shows the generality of spatial training for conceptual generalisation. We did not test transfer across modalities nor transfer in a more natural setting; we leave this for future studies.”
Further doubt on the underlying mechanism is cast by the possibility that the observed correlation between mapping task performance and the adoption of a 2D strategy may reflect general cognitive engagement rather than the spatial nature of the task. Similarly, the surprising finding that a significant number of participants benefited from spatial scaffolding without seeing spatial modalities may further raise questions about the interpretation of the scaffolding effect, pointing towards potential alternative interpretations, such as shifts in attention during learning induced by pre-training without changing underlying abstract conceptual representations.
The Reviewer is concerned about the fact that the spatial pre-training could benefit the participants by increasing global cognitive engagement rather than providing a scaffold for learning invariances. It is correct that the participants in the control group in Exp. 2c have poorer performances on average than participants that benefit from the spatial pre-training in Exp. 2a and 2b. The better performances of the participants in Exp. 2a and 2b could be due to either the spatial nature of the pre-training (as we claim) or a difference in general cognitive engagement. .
However, if we look closely at the results of Exp. 3, we can see that the general cognitive engagement hypothesis is not well supported by the data. Indeed, the participants in the control condition (Exp. 3c) have relatively similar performances than the other groups during training. Rather, the difference is in the strategy they use, as revealed by the transfer condition. The majority of them are using a 1D strategy, contrary to the participants that benefited from a spatial pre-training (Exp 3a and 3b). We have included a sentence in the results:
“Further, the results show that participants who did not experience spatial pre-training were still engaged in the task, but were not using the same strategy as the participants who experienced spatial pre-training (1D rather than 2D). Thus, the benefit of the spatial pre-training is not simply to increase the cognitive engagement of the participants. Rather, spatial pre-training provides a scaffold to learn rotation-invariant representation of auditory and visual concepts even when rotation is never explicitly shown during pre-training.”
Finally, Reviewer #1 had a related concern about a potential alternative explanation that involved a shift in attention. We reproduce our response here: we agree with the Reviewer that the “attention to dimensions” hypothesis is an interesting (and potentially concerning) alternative explanation. However, we believe that the results of our control experiments Exp. 2c and Exp. 3c are not compatible with this alternative explanation.
Indeed, in Exp. 2c, participants are pre-trained in the visual modality and then tested in the auditory modality. In the multimodal association task, participants have to associate the auditory stimuli and the visual stimuli: on each trial, they hear a sound and then have to click on the corresponding visual stimulus. It is necessary to pay attention to both auditory dimensions and both visual dimensions to perform well in the task. To give an example, the task might involve mapping the fundamental frequency and the amplitude modulation of the auditory stimulus to the colour and the shape of the visual stimulus, respectively. If participants pay attention to only one dimension, this would lead to a maximum of 25% accuracy on average (because they would be at chance on the other dimension, with four possible options). We observed that 30/50 participants reached an accuracy > 50% in the multimodal association task in Exp. 2c. This means that we know for sure that at least 60% of the participants actually paid attention to both dimensions of the stimuli. Nevertheless, there was a clear difference between participants that received a visual pre-training (Exp. 2c) and those who received a spatial pre-training (Exp. 2a) (frequency of 1D vs 2D models between conditions, BF > 100 in near transfer and far transfer). In fact, only 3/50 participants were best fit by a 2D model when vision was the pre-training modality compared to 29/50 when space was the pre-training modality. Thus, the benefit of the spatial pre-training cannot be due solely to a shift in attention toward both dimensions.
This effect was replicated in Exp. 3c. Similarly, 33/48 participants reached an accuracy > 50% in the multimodal association task in Exp. 3c, meaning that we know for sure that at least 68% of the participants actually paid attention to both dimensions of the stimuli. Again, there was a clear difference between participants who received a visual pre-training (frequency of 1D vs 2D models between conditions, Exp. 3c) and those who received a spatial pre-training (Exp. 3a) (BF > 100 in near transfer and far transfer).
Thus, we believe that the alternative explanation raised by the Reviewer is not supported by our data. We have added a paragraph in the discussion:
“One alternative explanation of this effect could be that the spatial pre-training encourages participants to attend to both dimensions of the non-spatial stimuli. By contrast, pretraining in the visual or auditory domains (where multiple dimensions of a stimulus may be relevant less often naturally) encourages them to attend to a single dimension. However, data from our control experiments Exp. 2c and Exp. 3c, are incompatible with this explanation. Around ~65% of the participants show a level of performance in the multimodal association task (>50%) which could only be achieved if they were attending to both dimensions (performance attending to a single dimension would yield 25% and chance performance is at 6.25%). This suggests that participants are attending to both dimensions even in the visual and auditory mapping case.”
Conclusions:
The authors successfully demonstrate that spatial training can enhance the ability to generalize in nonspatial domains, particularly in recognizing rotated sequences. The results for the most part support their conclusions, showing that spatial representations can act as a scaffold for learning more abstract conceptual invariances. However, the study leaves room for further investigation into whether the observed effects are unique to spatial cognition or could be replicated with other forms of well-established knowledge, as well as further clarifications of the underlying mechanisms.
Impact:
The study's findings are likely to have a valuable impact on cognitive science, particularly in understanding how abstract concepts are learned and generalized. The methods and data can be useful for further research, especially in exploring the relationship between spatial cognition and abstract conceptualization. The insights could also be valuable for AI research, particularly in improving models that involve abstract pattern recognition and conceptual generalization.
In summary, the paper contributes valuable insights into the role of spatial cognition in learning abstract concepts, though it invites further research to explore the boundaries and specifics of this scaffolding effect.
Reviewer #1 (Recommendations For The Authors):
Minor issues / typos:
P6: I think the example of the "signed" mapping here should be "e.g., ABAB maps to one category and BABA maps to another", rather than "ABBA maps to another" (since ABBA would always map to another category, whether the mapping is signed or unsigned).
Done.
P11: "Next, we asked whether pre-training and mapping were systematically associated with 2Dness...". I'd recommend changing to: "Next, we asked whether accuracy during pre-training and mapping were systematically associated with 2Dness...", just to clarify what the analyzed variables are.
Done.
P13, paragraph 1: "only if the features were themselves are physical spatial locations" either "were" or "are" should be removed.
Done.
P13, paragraph 1: should be "neural representations of space form a critical substrate" (not "for").
Done.
Reviewer #2 (Recommendations For The Authors):
The authors use in multiple places in the manuscript the phrases "learn invariances" (Abstract), "formation of invariances" (p. 2, para. 1), etc. It might be just me, but this feels a bit like 'sloppy' wording: we do not learn or form invariances, rather we learn or form representations or transformations by which we can perform tasks that require invariance over particular features or transformation of the input such as the case of object recognition and size- translation- or lighting-invariance. We do not form size invariance, we have representations of objects and/or size transformations allowing the recognition of objects of different sizes. The authors might change this way of referring to the phenomenon.
We respectfully disagree with this comment. An invariance occurs when neurons make the same response under different stimulation patterns. The objects or features to which a neuron responds is shaped by its inputs. Those inputs are in turn determined by experience-dependent plasticity. This process is often called “representation learning”. We think that our language here is consistent with this status quo view in the field.
Reviewer #3 (Recommendations For The Authors):
- I understand that the objective of the present experiment is to study our ability to generalize abstract patterns of sensory data (concepts). In the introduction, the authors present examples like the concept of a "tree" (encompassing a family tree, an oak tree, and a taxonomic tree) and "ring" to illustrate the idea. However, I am sceptical as to whether these examples effectively represent the phenomena being studied. From my perspective, these different instances of "tree" do not seem to relate to the same abstract concept that is translated or rotated but rather appear to share only a linguistic label. For instance, the conceptual substance of a family tree is markedly different from that of an oak tree, lacking significant overlap in meaning or structure. Thus, to me, these examples do not demonstrate invariance to transformations such as rotations.
To elaborate further, typically, generalization involves recognizing the same object or concept through transformations. In the case of abstract concepts, this would imply a shared abstract representation rather than a mere linguistic category. While I understand the objective of the experiments and acknowledge their potential significance, I find myself wondering about the real-world applicability and relevance of such generalizations in everyday cognitive functioning. This, in turn, casts some doubt on the broader relevance of the study's results. A more fitting example, or an explanation that addresses my concerns about the suitability of the current examples, would be beneficial to further clarify the study's intent and scope.
Response in the public review.
- Relatedly, the manuscript could benefit from greater clarity in defining key concepts and elucidating the proposed mechanism behind the observed effects. Is it plausible that the changes observed are primarily due to shifts in attention induced by the spatial pre-training, rather than a change in the process of learning abstract conceptual invariances (i.e., modifications to the abstract representations themselves)? While the authors conclude that spatial pre-training acts as a scaffold for enhancing the learning of conceptual invariances, it raises the question: does this imply participants simply became more focused on spatial relationships during learning, or might this shift in attention represent a distinct strategy, and an alternative explanation? A more precise definition of these concepts and a clearer explanation of the authors' perspective on the mechanism underlying these effects would reduce any ambiguity in this regard.
Response in the public review.
- I am wondering whether the effectiveness of spatial representations in generalizing abstract concepts stems from their special nature or simply because they are a familiar 2D space for participants. It is well-established that memory benefits from linking items to familiar locations, a technique used in memory training (method of loci). This raises the question: Are we observing a similar effect here, where spatial dimensions are the only tested familiar 2D spaces, while the other 2 spaces are simply unfamiliar, as also suggested by the lower performance during training (Fig.2)? Would the results be replicable with another well-learned, robustly encoded domain, such as auditory dimensions for professional musicians, or is there something inherently unique about spatial representations that aids in bootstrapping abstract representations?
On the other side of the same coin, are spatial representations qualitatively different, or simply more efficient because they are learned more quickly and readily? This leads to the consideration that if visual pre-training and visual-to-auditory mapping were continued until a similar proficiency level as in spatial training is achieved, we might observe comparable performance in aiding generalization. Thus, the conclusion that spatial representations are a special scaffold for abstract concepts may not be exclusively due to their inherent spatial nature, but rather to the general characteristic of well-established representations. This hypothesis could be further explored by either identifying alternative 2D representations that are equally well-learned or by extending training in visual or auditory representations before proceeding with the mapping task. At the very least I believe this potential explanation should be explored in the discussion section.
Response in the public review.
I had some difficulty in following an important section of the introduction: "... whether participants can learn rotationally invariant concepts in nonspatial domains, i.e., those that are defined by sequences of visual and auditory features (rather than by locations in physical space, defined in Cartesian or polar coordinates) is not known." This was initially puzzling to me as the paragraph preceding it mentions: "There is already good evidence that nonspatial concepts are represented in a translation invariant format." While I now understand that the essential distinction here is between translation and rotation, this was not immediately apparent upon first reading. This crucial distinction, especially in the context of conceptual spaces, was not clearly established before this point in the manuscript. For better clarity, it would be beneficial to explicitly contrast and define translation versus rotation in this particular section and stress that the present study concerns rotations in abstract spaces.
Done.
- The multi-modal association is crucial for the study, however to my knowledge, it is not depicted or well explained in the main text or figures (Results section). In my opinion, the details of this task should be explained and illustrated before the details of the associated results are discussed.
We have included an illustration of a multimodal association trial in Fig. S3B.
Author response image 2.

- The observed correlation between the mapping task performance and the adoption of a 2D strategy is logical. However, this correlation might not exclusively indicate the proposed underlying mechanism of spatial scaffolding. Could it also be reflective of more general factors like overall performance, attention levels, or the effort exerted by participants? This alternative explanation suggests that the correlation might arise from broader cognitive engagement rather than specifically from the spatial nature of the task. Addressing this possibility could strengthen the argument for the unique role of spatial representations in learning abstract concepts, or at least this alternative interpretation should be mentioned.
Response in the public review.
-
To me, the finding that ~30% of participants benefited from the spatial scaffolding effect for example in the auditory condition merely through exposure to the mapping (Fig 4D), without needing to see the quadruplets in the spatial modality, was somewhat surprising. This is particularly noteworthy considering that only ~60% of participants adopted the 2D strategy with exposure to rotated contingencies in Experiment 3 (Fig 3D). How do the authors interpret this outcome? It would be interesting to understand their perspective on why such a significant effect emerged from mere exposure to the mapping task.
-
I appreciate the clarity Fig.1 provides in explaining a challenging experimental setup. Is it possible to provide example trials, including an illustration that shows which rotations produce the trail and an intuitive explanation that response maps onto the 1D vs 2D strategies respectively, to aid the reader in better understanding this core manipulation?
-
I like that the authors provide transparency by depicting individual subject's data points in their results figures (e.g. Figs. 2 B, F, J). However, with an n=~50 per condition, it becomes difficult to intuit the distribution, especially for conditions with higher variance (e.g., Auditory). The figures might be more easily interpretable with alternative methods of displaying variances, such as violin plots per data point, conventional error shading using 95%CIs, etc.
-
Why are the authors not reporting exact BFs in the results sections at least for the most important contrasts?
-
While I understand why the authors report the frequencies for the best model fits, this may become difficult to interpret in some sections, given the large number of reported values. Alternatives or additional summary statistics supporting inference could be beneficial.
As the Reviewer states, there are a large number of figures that we can report in this study. We have chosen to keep this number at a minimum to be as clear as possible. To illustrate the distribution of individual data points, we have opted to display only the group's mean and standard error (the standard errors are included, but the substantial number of participants per condition provides precise estimates, resulting in error bars that can be smaller than the mean point). This decision stems from our concern that including additional details could lead to a cluttered representation with unnecessary complexity. Finally, we report what we believe to be the critical BFs for the comprehension of the reader in the main text, and choose a cutoff of 100 when BFs are high (corresponding to the label “decisive” evidence, some BFs are larger than 1012). All the exact BFs are in the supplementary for the interested readers.
-
Reviewer #2 (Public Review):
Summary:
In this manuscript, L&S investigates the important general question of how humans achieve invariant behavior over stimuli belonging to one category given the widely varying input representation of those stimuli and more specifically, how they do that in arbitrary abstract domains. The authors start with the hypothesis that this is achieved by invariance transformations that observers use for interpreting different entries and furthermore, that these transformations in an arbitrary domain emerge with the help of the transformations (e. g. translation, rotation) within the spatial domain by using those as "scaffolding" during transformation learning. To provide the missing evidence for this hypothesis, L&S used behavioral category learning studies within and across the spatial, auditory and visual domains, where rotated and translated 4-element token sequences had to be learned to categorize and then the learned transformation had to applied in new feature dimensions within the given domain. Through single- and multiple-day supervised training and unsupervised tests, L&S demonstrated by standard computational analyses that in such setups, space and spatial transformations can, indeed, help with developing and using appropriate rotational mapping whereas the visual domain cannot fulfill such a scaffolding role.
Strengths:
The overall problem definition and the context of spatial mapping-driven solution to the problem is timely. The general design of testing the scaffolding effect across different domains is more advanced than any previous attempts clarifying the relevance of spatial coding to any other type of representational codes. Once the formulation of the general problem in a specific scientific framework is done, the following steps are clearly and logically defined and executed. The obtained results are well interpretable, and they could serve as a good steppingstone for deeper investigations. The analytical tools used for the interpretations are adequate. The paper is relatively clearly written.
Weaknesses:
Some additional effort to clarify the exact contribution of the paper, the link between analyses and the claims of the paper and its link to previous proposals would be necessary to better assess the significance of the results and the true nature of the proposed mechanism of abstract generalization.
(1) Insufficient conceptual setup: The original theoretical proposal (the Tolman-Eichenbaum-Machine, Whittington et al., Cell 2020) that L&S relate their work proposes that just as in the case of memory for spatial navigation, humans and animal create their flexible relational memory system of any abstract representation by a conjunction code that combines on the one hand, sensory representation and on the other hand, a general structural representation or relational transformation. The TEM also suggest that the structural representation could contain any graph-interpretable spatial relations, albeit in their demonstration 2D neighbor relations were used. The goal of L&S's paper is to provide behavioral evidence for this suggestion by showing that humans use representational codes that are invariant to relational transformations of non-spatial abstract stimuli and moreover, that humans obtain these invariances by developing invariance transformers with the help of available spatial transformers. To obtain such evidence, L&S use the rotational transformation. However, the actual procedure they used actually solved an alternative task: instead of interrogating how humans develop generalizations in abstract spaces, they demonstrated that if one defines rotation in an abstract feature space embedded in visual or auditory modality that is similar to the 2D space (i.e. has two independent dimensions that are clearly segregable and continuous), humans cannot learn to apply rotation of 4-piece temporal sequences in those spaces while they can do it in 2D space, and with co-associating a one-to-one mapping between locations in those feature spaces with locations in the 2D space an appropriate shaping mapping training will lead to successful application of rotation in the given task (and in some other feature spaces in the given domain). While this is an interesting and challenging demonstration, it does not shed light on how humans learn and generalize only that humans CAN do learning and generalization in this, highly constrained scenario. This result is a demonstration of how a stepwise learning regiment can make use of one structure for mapping a complex input into a desired output. The results neither clarify how generalizations would develop in abstract spaces nor the question if this generalization uses transformations developed in the abstract space. The specific training procedure ensures success in the presented experiments but the availability and feasibility of an equivalent procedure in natural setting is a crucial part of validating the original claim and that has not been done in the paper.
(2) Missing controls: The asymptotic performance in Exp 1 after training in the three tasks was quite different in the three tasks (intercepts 2.9, 1.9, 1.6 for spatial, visual and auditory, respectively; p. 5. para. 1, Fig 2BFJ). It seems that the statement "However, or main question was how participants would generalise learning to novel, rotated exemplars of the same concept." assumes that learning and generalization are independent. Wouldn't it be possible, though, that the level of generalization depends on the level of acquiring a good representation of the "concept" and after obtaining an adequate level of this knowledge, generalization would kick in without scaffolding? If so, a missing control is to equate the levels of asymptotic learning and see whether there is a significant difference in generalization. A related issue is that we have no information what kind of learning in the three different domains were performed, albeit we probably suspect that in space the 2D representation was dominant while in the auditory and visual domains not so much. Thus, a second missing piece of evidence is the model fitting results of the ⦰ condition that would show which way the original sequences were encoded (similar to Fig 2 CGK and DHL). If the reason for lower performance is not individual stimulus difficulty but the natural tendency to encode the given stimulus type by a combo of random + 1D strategy that would clarify that the result of the cross-training is, indeed, transferring the 2D-mapping strategy.
Tags
Annotators
URL
-
-
-
Converts Word doc to HTML code
doc to html
-
-
stackoverflow.com stackoverflow.com
-
The reason it works when using one statement is that local swallows the return type of the right hand side (e.g. local foo=$(false) actually returns the zero status code); that's one of bash's many pitfalls.
-
-
omnidatacleaningguide.netlify.app omnidatacleaningguide.netlify.app
-
omni_table
testing on a code chunk
-






































